Java零基础系列课程-JavaSE基础篇
Lecture:波哥

Java 是第一大编程语言和开发平台。它有助于企业降低成本、缩短开发周期、推动创新以及改善应用服务。如今全球有数百万开发人员运行着超过 51 亿个 Java 虚拟机,Java 仍是企业和开发人员的首选开发平台。
一、 集合框架概述
1. 集合的引入
我们为什么要学习集合框架呢?
我们前面学习了Java的基本数据类型,引用类型都是可以用来存储我们的数据的,但是仅仅只能存储单个,我们可以通过数组的形式来存储多个数据,但是数据有个特点是长度是不能改变的,那也就意味着数组在处理需要对数组中的数据做添加和删除操作的时候就会显得非常麻烦。案例如下:
package com.bobo.collection;import java.util.Arrays;public class CollectionDemo01 {/*** 有个问题* 全班有20个学生,要通过Java对来来存储相关的学生的信息** 基本数据类型* byte short int long float double char boolean** 引用数据类型* Student*** 数组* double[] scores = new double[20];* Student[] students = new Student[20];* 数组的长度是不可变的哦* 有个学员中途转学进到了我们班 怎么讲这个新的学员信息添加到班级信息中去呢?* 学习到了中期,有个学员要转学走了,怎么更新数组中的信息?** @param args*/public static void main(String[] args) {double[] scores = new double[20];for(int i = 0 ; i < scores.length ; i ++){if(i == 14){scores[i] = 66;continue;}scores[i] = 78;}System.out.println(Arrays.toString(scores));// 新加一个成员double[] s1 = new double[21];// 复制原来数组中的信息到新的数组中去for(int i = 0 ; i < scores.length ; i ++){s1[i] = scores[i];}s1[20] = 99;System.out.println(Arrays.toString(s1));// 有一个学员离开了班级, 编号为15的学员double[] s2 = new double[20];for(int i = 0 ; i < s1.length-1 ; i ++){if(i < 14){s2[i] = s1[i];}else{s2[i] = s1[i+1];}}System.out.println(Arrays.toString(s2));}
}所以Java给我们提供了集合类来解决这个问题
2. 集合的概念
JavaAPI所提供的一系列类的实例,可以用来动态的存放多个对象。Java集合框架提供了一套性能优良,使用方便的接口和类,位于java.util包中。
集合的特点:长度不固定,只能存储引用类型的对象。
3. 集合和数组的区别
| 类型 | 说明 |
|---|---|
| 长度 | 数组:长度固定不可改变 集合:长度是可以根据实际的需求变动的 |
| 内容 | 数组:数组中存储的是同一种类型的数据 集合:可以存储不同类型的数据 |
| 数据类型 | 数组:可以存储基本数据类型和引用数据类型 集合:只能存储引用数据类型 |
4. 集合的框架图
集合其实是由一系列的Java类和接口组成的,结构如下:
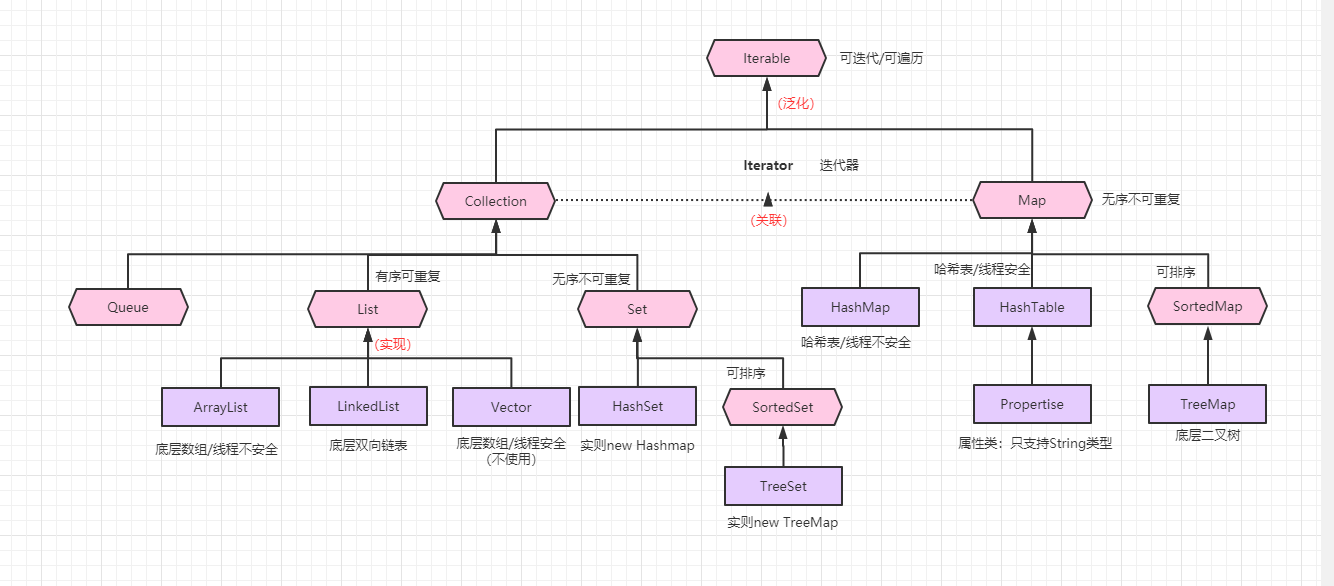
二、 Collection接口
1. 集合的设计理念
结合集合的框架结构,我们可以推演下集合的设计,因为集合有多 增删改查的方法,而且集合是一套框架,既然是框架那么每一种集合在处理增删改查的时候的方式会不一样。
Collection的特点:
- 有序:部分集合实现是有序的,部分集合实现是无序的。这里的有序指的是存储的顺序
- 可排序:部分集合实现是可排序的,部分集合实现是不可排序的
- 可重复:部分集合是可重复的,部分集合是不可重复的
既然每一个集合的特点不一样,那么就取决于所有子类的实现方法不一样,但是我们知道,在集合中所有的集合应该具有集合共有特点:
- 长度可变
- 能够存储任意的引用类型
- 具备很多对象的
增删改查的方法 - 集合也能够存储基本数据类的包装类
只是说每一个集合类的实现方式不一样罢了。实现方式其实就取决于底层的数据结构
2.Collection接口的常用方法
2.1 添加功能
boolean add(E e)
//确保此集合包含指定的元素(可选操作)。
boolean addAll(Collection<? extends E> c)
//将指定集合中的所有元素添加到此集合(可选操作)。
2.2 删除功能
void clear()
// 从此集合中删除所有元素(可选操作)。
boolean remove(Object o)
// 从该集合中删除指定元素的单个实例(如果存在)(可选操作)。
boolean removeAll(Collection<?> c)
// 删除指定集合中包含的所有此集合的元素(可选操作)。
2.3 修改功能
修改功能 在Collection接口中并没有提供直接修改的方法,如果你要修改那么可以先删除,再添加
System.out.println(c1);
c1.remove(3);
c1.add(5);
System.out.println(c1);
2.4 遍历功能
Object[] toArray()
// 返回一个包含此集合中所有元素的数组。
Iterator<E> iterator()
// 返回此集合中的元素的迭代器。
2.5 判断功能
boolean isEmpty()
// 如果此集合不包含元素,则返回 true 。
boolean contains(Object o)
// 如果此集合包含指定的元素,则返回 true 。
boolean containsAll(Collection<?> c)
// 如果此集合包含指定 集合中的所有元素,则返回true。
2.6 其他功能
int size()
// 返回此集合中的元素数。
boolean retainAll(Collection<?> c)
// 仅保留此集合中包含在指定集合中的元素(可选操作)。
// retainAll 求交集 返回的结果是观察原集合是否发生了改变,true改变 false 没有改变
案例代码:
package com.bobo.collection;import java.util.ArrayList;
import java.util.Collection;public class CollectionDemo02 {/*** Collection接口中的常用方法* 1. 长度可变* 2. 能够存储任意的引用类型* 3. 具备很多对象的`增删改查`的方法* 4. 集合也能够存储基本数据类的包装类* @param args*/public static void main(String[] args) {// 获取一个Collection接口对象 alt + enterCollection c1 = new ArrayList();// 添加的功能c1.add("张三");System.out.println(c1.size());c1.add("李四");System.out.println(c1.size());c1.add("王五");System.out.println(c1.size());c1.add(true); // 集合不是只能存储 引用类型吗?c1.add(3); // 基本数据类型和包装类有自动装箱和拆箱的操作System.out.println(c1);Collection c2 = new ArrayList();c2.add("小明");c2.addAll(c1);System.out.println(c2);// 删除功能 如果不存在 返回false 删除成功返回truec2.remove("李四1");System.out.println(c2);c2.removeAll(c1);System.out.println(c2);//c2.clear();System.out.println(c2);// 修改功能 在Collection接口中并没有提供直接修改的方法,如果你要修改那么可以先删除,再添加System.out.println(c1);c1.remove(3);c1.add(5);System.out.println(c1);// 遍历功能Object[] objects = c1.toArray();for(Object o : objects){System.out.println(o);}// 判断功能System.out.println(c1.contains("王五"));System.out.println(c1.contains("王五1"));System.out.println(c1.containsAll(c2));System.out.println(c2.isEmpty());// 获取集合元素的个数System.out.println(c1.size());System.out.println(c2.size());Collection c3 = new ArrayList();c3.add(1);c3.add(2);c3.add(4);c3.add(6);Collection c4 = new ArrayList();c4.add(2);c4.add(4);c4.add(6);c4.add(8);c4.add(10);// retainAll 求交集 返回的结果是观察原集合是否发生了改变,true改变 false 没有改变System.out.println("----------------");boolean flag = c3.retainAll(c4);System.out.println(flag);System.out.println(c3);System.out.println(c4);}
}输出结果:
1
2
3
[张三, 李四, 王五, true, 3]
[小明, 张三, 李四, 王五, true, 3]
[小明, 张三, 李四, 王五, true, 3]
[小明]
[小明]
[张三, 李四, 王五, true, 3]
[张三, 李四, 王五, true, 5]
张三
李四
王五
true
5
true
false
false
false
5
1
----------------
true
[2, 4, 6]
[2, 4, 6, 8, 10]Process finished with exit code 03. Iterator接口
所有的实现了Collection接口的集合类都有一个iterator()方法,该方法返回一个Iterator接口对象。提供的有集合数据遍历的方式。
boolean hasNext()
//如果迭代具有更多元素,则返回 true 。
E next()
//返回迭代中的下一个元素。
default void remove()
// 从底层集合中删除此迭代器返回的最后一个元素(可选操作)。
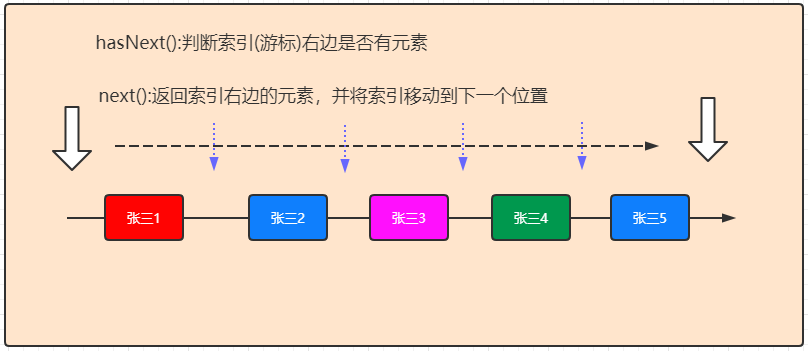
3.1 遍历集合元素
我们需要结合hasNext方法和next方法一块来实现
package com.bobo.collection;import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;public class CollectionDemo04 {/*** Iterator接口** @param args*/public static void main(String[] args) {Collection c1 = new ArrayList();c1.add("张三1");c1.add("张三2");c1.add("张三3");c1.add("张三4");c1.add("张三5");System.out.println(c1);// 通过Iterator迭代遍历集合Iterator iterator = c1.iterator();while(iterator.hasNext()){ // 判断是否有下一个元素// 条件成立 获取下一个元素 并移动游标位置Object o = iterator.next();System.out.println(o);}}
}3.2 移除集合元素
通过循环的方式移除所有的元素同样需要结合hasNext方法next方法以及remove方法来实现
package com.bobo.collection;import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;public class CollectionDemo06 {/*** Iterator接口** @param args*/public static void main(String[] args) {Collection c1 = new ArrayList();c1.add("张三1");c1.add("张三2");c1.add("张三3");c1.add("张三4");c1.add("张三5");System.out.println(c1);// 通过Iterator迭代遍历集合Iterator iterator = c1.iterator();/*iterator.next(); // 将游标移动到第一个元素的右侧iterator.remove(); // 移除游标左侧的元素System.out.println(c1);*/while(iterator.hasNext()){iterator.next(); // 将游标移动在元素的右侧iterator.remove(); // 删除元素}System.out.println(c1);}
}4.foreach循环
在Collection接口中我们是可以通过foreach循环来实现遍历集合中的元素的
package com.bobo.collection;import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;public class CollectionDemo07 {/*** Iterator接口** @param args*/public static void main(String[] args) {Collection c1 = new ArrayList();c1.add("张三1");c1.add("张三2");c1.add("张三3");c1.add("张三4");c1.add("张三5");System.out.println(c1);// foreach循环来实现遍历for(Object o : c1){System.out.println(o);}}
}
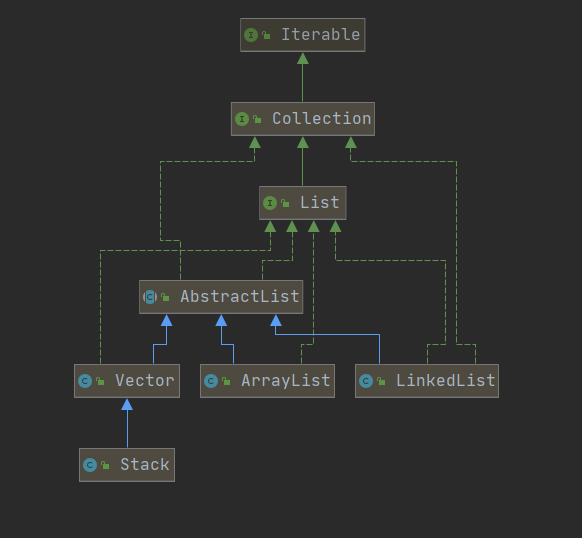
三、List接口
1.List 概念介绍
有序集合(也称为序列 )。 该界面的用户可以精确控制列表中每个元素的插入位置。 用户可以通过整数索引(列表中的位置)访问元素,并搜索列表中的元素
有序集合,List集合有一个下标(索引),我们可以根据索引来操作集合中的元素
List接口是Collection接口的子接口
实现了List接口的集合类中是有序的,且允许重复
List集合中的元素都对应一个整数型的序号,记载了其在集合中的位置,可以根据序号存取集合中的元素
2. 常用的方法介绍
2.1 重复元素和null
在List接口中是可以存储重复元素和null值的
/*** List接口* @param args*/public static void main(String[] args) {// 获取一个List接口对象List list1 = new ArrayList();list1.add(1);list1.add(1); // 存储重复的元素list1.add(2);list1.add(null); // 添加 nullSystem.out.println(list1);}
输出结果
[1, 1, 2, null]
2.2 添加功能
Collection接口中提供的功能
boolean add(E e)
//确保此集合包含指定的元素(可选操作)。
boolean addAll(Collection<? extends E> c)
//将指定集合中的所有元素添加到此集合(可选操作)。List接口中 新增的功能
void add(int index, E element)
// 将指定的元素插入此列表中的指定位置(可选操作)
boolean addAll(int index, Collection<? extends E> c)
//将指定集合中的所有元素插入到此列表中的指定位置(可选操作)。
package com.bobo.list;import java.util.ArrayList;
import java.util.List;public class ListDemo02 {/*** List接口* @param args*/public static void main(String[] args) {// 获取一个List接口对象List list1 = new ArrayList();list1.add(1);list1.add(1); // 存储重复的元素list1.add(2);list1.add(null); // 添加 nullSystem.out.println(list1);list1.add(2,"张三");System.out.println(list1);List list2 = new ArrayList();list2.add("小明"); // 添加第一个元素System.out.println(list2);list2.add(0,"小李"); // 在集合的第一个位置添加一个元素System.out.println(list2);list2.addAll(1,list1); // 将list1集合中的元素插入到 list2集合的第一个元素之后System.out.println(list2);}
}输出代码
[1, 1, 2, null]
[1, 1, 张三, 2, null]
[小明]
[小李, 小明]
[小李, 1, 1, 张三, 2, null, 小明]
2.3 删除功能
肯定具有Collection接口中定义的删除方法
void clear()
// 从此集合中删除所有元素(可选操作)。
boolean remove(Object o)
// 从该集合中删除指定元素的单个实例(如果存在)(可选操作)。
boolean removeAll(Collection<?> c)
// 删除指定集合中包含的所有此集合的元素(可选操作)。
List接口中特有的删除方法
E remove(int index)
// 删除该列表中指定位置的元素(可选操作)。
2.4 修改功能
在Collection接口中针对修改并不友好,但是在List接口中修改就非常的方便了,我们可以同下标可以直接来修改
E set(int index, E element)
用指定的元素(可选操作)替换此列表中指定位置的元素。
package com.bobo.list;import java.util.ArrayList;
import java.util.List;public class ListDemo04 {/*** List接口* @param args*/public static void main(String[] args) {// 获取一个List接口对象List list1 = new ArrayList();list1.add(1);list1.add(1); // 存储重复的元素list1.add(2);list1.add(null); // 添加 nullSystem.out.println(list1);list1.set(1,666);System.out.println(list1);}
}输出结果
[1, 1, 2, null]
[1, 666, 2, null]
2.5 遍历功能
遍历获取集合中的相关元素,当然肯定可以使用Collection接口中定义的方式及foreach循环
Object[] toArray()
// 返回一个包含此集合中所有元素的数组。
Iterator<E> iterator()
// 返回此集合中的元素的迭代器。
还可以使用List接口中定义的新的方式,接口下标通过普通for循环来实现
package com.bobo.list;import java.util.ArrayList;
import java.util.List;public class ListDemo05 {/*** List接口* @param args*/public static void main(String[] args) {// 获取一个List接口对象List list1 = new ArrayList();list1.add(1);list1.add(1); // 存储重复的元素list1.add(2);list1.add(null); // 添加 null// 循环获取集合中的元素// System.out.println(list1.get(2));for(int i = 0 ; i < list1.size() ; i ++){System.out.println(list1.get(i));}}
}输出结果:
1
1
2
null
迭代功能在List接口中也有扩展
ListIterator<E> listIterator()
//返回列表中的列表迭代器(按适当的顺序)。
ListIterator<E> listIterator(int index)
//从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。
2.6 其他功能
E get(int index)
// 返回此列表中指定位置的元素。int indexOf(Object o)
// 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。
int lastIndexOf(Object o)
// 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。
List<E> subList(int fromIndex, int toIndex)
// 返回此列表中指定的 fromIndex (含)和 toIndex之间的视图。
package com.bobo.list;import java.util.ArrayList;
import java.util.List;public class ListDemo06 {/*** List接口* @param args*/public static void main(String[] args) {// 获取一个List接口对象List list1 = new ArrayList();list1.add(1);list1.add(3); // 存储重复的元素list1.add(2);list1.add(null); // 添加 nulllist1.add("张三");list1.add("李四");list1.add(3);System.out.println(list1.indexOf(3));System.out.println(list1.lastIndexOf(3));System.out.println(list1.subList(2,4));}
}输出结果:
1
6
[2, null]
3.ListIterator接口
ListIterator接口是Iterator接口的子接口,在Iterator正向迭代的基础上扩展了逆向迭代的操作
package com.bobo.list;import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;public class ListDemo07 {/*** List接口* @param args*/public static void main(String[] args) {// 获取一个List接口对象List list1 = new ArrayList();list1.add(1);list1.add(3); // 存储重复的元素list1.add(2);list1.add(null); // 添加 nulllist1.add("张三");list1.add("李四");list1.add(3);// 获取ListIterator接口实例ListIterator li = list1.listIterator();System.out.println(li.previousIndex()+ ":" +li.hasPrevious()); // 游标指向了第一个元素的左侧while(li.hasNext()){ // 正向迭代 判断是否有下一个元素System.out.println(li.nextIndex() + ":" + li.next());}//System.out.println(li.previousIndex()+ ":" +li.hasPrevious()); // 游标指向了最后一个元素的右侧//System.out.println(li.previousIndex()+ ":" +li.hasPrevious()); // 游标指向了最后一个元素的右侧System.out.println("***************************");while(li.hasPrevious()){System.out.println(li.previousIndex() + ":" + li.previous());}}
}输出结果
-1:false
0:1
1:3
2:2
3:null
4:张三
5:李四
6:3
***************************
6:3
5:李四
4:张三
3:null
2:2
1:3
0:1
4.List接口的小结
4.1 List接口遍历方式
- toArray
- Iterator
- foreach
- 普通的for循环
- ListIterator
4.2 List接口去除重复元素
方式一:创建一个新的集合来存储去除重复元素。
package com.bobo.list;import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;public class ListDemo08 {/*** List接口* @param args*/public static void main(String[] args) {// 获取一个List接口对象List list1 = new ArrayList();list1.add(1);list1.add(3); // 存储重复的元素list1.add(2);list1.add(null); // 添加 nulllist1.add("张三");list1.add("李四");list1.add(3);// 获取ListIterator接口实例System.out.println(list1);List list2 = new ArrayList();for(Object o : list1){ // 遍历原来的集合if(!list2.contains(o)){ // 判断新的集合中是否包含的有遍历的元素list2.add(o); // 新的集合中不含有该元素,就直接添加进新的集合中}}System.out.println(list2);}
}
输出结果
[1, 3, 2, null, 张三, 李四, 3]
[1, 3, 2, null, 张三, 李四]
方式二:在原有集合的基础上使用选择排序的思想来去除重复元素【单纯的准备面试】
package com.bobo.list;import java.util.ArrayList;
import java.util.List;public class ListDemo09 {/*** List接口* 在不创建新的集合的基础上我们来去除重复的元素* @param args*/public static void main(String[] args) {// 获取一个List接口对象List list1 = new ArrayList();list1.add(1);list1.add(3); // 存储重复的元素list1.add(3);list1.add(3);list1.add(3);list1.add("aa"); // 添加 nulllist1.add("张三");list1.add("李四");list1.add(3);// 获取ListIterator接口实例System.out.println(list1);for(int i = 0 ; i < list1.size() - 1;i++){for(int j = i + 1; j < list1.size() ; j++){if(list1.get(i).equals(list1.get(j))){list1.remove(j);j--;}}}System.out.println(list1);}
}输出结果
[1, 3, 3, 3, 3, aa, 张三, 李四, 3]
[1, 3, aa, 张三, 李四]
5.List接口的相关实现类
5.1 ArrayList
可调整大小的数组的实现
List接口。 实现所有可选列表操作,并允许所有元素,包括null。 除了实现List接口之外,该类还提供了一些方法来操纵内部使用的存储列表的数组的大小。 (这个类是大致相当于Vector,不同之处在于它是不同步的)。
5.1.1 ArrayList的特点
特点:
- 底层的数据结构是数组
- 能够存储null值
- 线程不安全,效率高
- 底层是数组结构,那么就意味着查询和修改的效率高,而增加和删除的效率就低了
- 有索引,能够方便的检索
- 元素是可以重复的,我们可以自己通过选择排序法去重
- 不可排序。
注:ArrayList中常用的方法全部来自于 父类 Collection、List、Object。我们都介绍过,所以在次就不再重复了
课堂案例:
存储多个员工信息(包括工号、姓名、年龄,入职时间),逐条打印所有员工姓名,并输出员工的个数
使用ArrayList存储数据
元素个数不确定
要求获得元素的实际个数
按照存储顺序获取并打印元素信息
代码
package com.bobo.arraylist;import java.util.ArrayList;
import java.util.Date;public class ArrayListDemo02 {/*** 存储多个员工信息(包括工号、姓名、年龄,入职时间),逐条打印所有员工姓名,并输出员工的个数* 使用ArrayList存储数据* 元素个数不确定* 要求获得元素的实际个数* 按照存储顺序获取并打印元素信息* @param args*/public static void main(String[] args) {ArrayList list = new ArrayList();for(int i = 0 ; i < 10 ; i ++){Employee e = new Employee("emp"+i,"张三"+i,10+i,new Date());list.add(e);}System.out.println(list);// 逐条打印员工的信息for (Object o:list) {if(o instanceof Employee){Employee e = (Employee) o;System.out.println(e);}}// 员工的个数System.out.println("员工的个数是:" + list.size());}
}/*** 员工类*/
class Employee{private String empNo; // 员工编号private String empName; // 员工姓名private Integer age; // 在成员变量中如果是基本数据类型 我们推荐使用包装类声明private Date entryDate; // 入职时间public Employee(String empNo, String empName, Integer age) {this.empNo = empNo;this.empName = empName;this.age = age;}public Employee(String empNo, String empName, Integer age, Date entryDate) {this(empNo,empName,age);this.entryDate = entryDate;}public String getEmpNo() {return empNo;}public void setEmpNo(String empNo) {this.empNo = empNo;}public String getEmpName() {return empName;}public void setEmpName(String empName) {this.empName = empName;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public Date getEntryDate() {return entryDate;}public void setEntryDate(Date entryDate) {this.entryDate = entryDate;}@Overridepublic String toString() {return "Employee{" +"empNo='" + empNo + '\'' +", empName='" + empName + '\'' +", age=" + age +", entryDate=" + entryDate +'}';}
}输出结果
[Employee{empNo='emp0', empName='张三0', age=10, entryDate=Tue Dec 08 14:43:44 CST 2020}, Employee{empNo='emp1', empName='张三1', age=11, entryDate=Tue Dec 08 14:43:44 CST 2020}, Employee{empNo='emp2', empName='张三2', age=12, entryDate=Tue Dec 08 14:43:44 CST 2020}, Employee{empNo='emp3', empName='张三3', age=13, entryDate=Tue Dec 08 14:43:44 CST 2020}, Employee{empNo='emp4', empName='张三4', age=14, entryDate=Tue Dec 08 14:43:44 CST 2020}, Employee{empNo='emp5', empName='张三5', age=15, entryDate=Tue Dec 08 14:43:44 CST 2020}, Employee{empNo='emp6', empName='张三6', age=16, entryDate=Tue Dec 08 14:43:44 CST 2020}, Employee{empNo='emp7', empName='张三7', age=17, entryDate=Tue Dec 08 14:43:44 CST 2020}, Employee{empNo='emp8', empName='张三8', age=18, entryDate=Tue Dec 08 14:43:44 CST 2020}, Employee{empNo='emp9', empName='张三9', age=19, entryDate=Tue Dec 08 14:43:44 CST 2020}]
Employee{empNo='emp0', empName='张三0', age=10, entryDate=Tue Dec 08 14:43:44 CST 2020}
Employee{empNo='emp1', empName='张三1', age=11, entryDate=Tue Dec 08 14:43:44 CST 2020}
Employee{empNo='emp2', empName='张三2', age=12, entryDate=Tue Dec 08 14:43:44 CST 2020}
Employee{empNo='emp3', empName='张三3', age=13, entryDate=Tue Dec 08 14:43:44 CST 2020}
Employee{empNo='emp4', empName='张三4', age=14, entryDate=Tue Dec 08 14:43:44 CST 2020}
Employee{empNo='emp5', empName='张三5', age=15, entryDate=Tue Dec 08 14:43:44 CST 2020}
Employee{empNo='emp6', empName='张三6', age=16, entryDate=Tue Dec 08 14:43:44 CST 2020}
Employee{empNo='emp7', empName='张三7', age=17, entryDate=Tue Dec 08 14:43:44 CST 2020}
Employee{empNo='emp8', empName='张三8', age=18, entryDate=Tue Dec 08 14:43:44 CST 2020}
Employee{empNo='emp9', empName='张三9', age=19, entryDate=Tue Dec 08 14:43:44 CST 2020}
员工的个数是:10
5.1.2 ArrayList原理分析
ArrayList的本质就是 动态数据,动态扩容
初始的属性了解
/*** 集合默认的容量 10*/private static final int DEFAULT_CAPACITY = 10;/*** 空数组*/private static final Object[] EMPTY_ELEMENTDATA = {};/*** 默认容量的空的数组*/private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};/** * 集合中真实的存储数据的 数组*/transient Object[] elementData; // non-private to simplify nested class access/*** 集合中的元素的个数,注意 不是数组的长度!!!!* @serial*/private int size;
1.初始化操作
构造方法
无参构造方法: 创建了一个空的数组
/*** Constructs an empty list with an initial capacity of ten.*/public ArrayList() {// 将属性中的默认的空的数组赋值给了 存储数据的变量this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;// this.elementData = {}}
有参构造方法: 创建了一个指定容量的数组
public class ArrayListDemo03 {public static void main(String[] args) {ArrayList list = new ArrayList(20);}
}
源码:
// initialCapacity = 20
public ArrayList(int initialCapacity) {if (initialCapacity > 0) {// 创建了一个长度为20的数组this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {// 如果传递的是0 就将{}赋值给 elementDatathis.elementData = EMPTY_ELEMENTDATA;// this.elementData = {}} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}
}
如果在构造器中传递的是一个负数就会抛如下的异常
java.lang.IllegalArgumentException: Illegal Capacity: -20
2.添加方法
添加方法
public class ArrayListDemo03 {public static void main(String[] args) {ArrayList list1 = new ArrayList();list1.add(1); // 开始添加数据ArrayList list2 = new ArrayList(20);}
}
第一次添加数据
public boolean add(E e) {// 确认内部的容量 0 + 1ensureCapacityInternal(size + 1); // Increments modCount!!// 将我们要添加的元素添加的数组的有数据的下一个位置elementData[size++] = e;return true;
}
ensureCapacityInternal
private void ensureCapacityInternal(int minCapacity) { // 1// {} = {} 有参 new Object[10] != {}if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {// 10 10 1minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}// 明确数组的容量ensureExplicitCapacity(minCapacity);
}
ensureExplicitCapacity
private void ensureExplicitCapacity(int minCapacity) {modCount++; // 记录我对当前集合操作的次数// 集合中的元素的个数 等于数组的长度 我们才需要扩容 10 - 0 > 0 if (minCapacity - elementData.length > 0)// 扩容grow(minCapacity);
}
grow
private void grow(int minCapacity) { // 10// overflow-conscious code elementData = {}// 原来的容量 0int oldCapacity = elementData.length; // 0// 新的容量 0int newCapacity = oldCapacity + (oldCapacity >> 1);// 0 - 10 < 0 if (newCapacity - minCapacity < 0)// newCapacity = 10newCapacity = minCapacity;// 10 -21亿 < 0if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// 将{} 赋值到 一个长度为 10的新的数组中 然后将新的数组赋值给了 elementData = {,,,,,} length=10 size= 0elementData = Arrays.copyOf(elementData, newCapacity);
}
然后执行的就是向数组中添加数据的操作
public boolean add(E e) {// 确认内部的容量 0 + 1ensureCapacityInternal(size + 1); // Increments modCount!!// 将我们要添加的元素添加的数组的有数据的下一个位置elementData[size++] = e; // elementData={e,,,,,,} 数组的length=10 size=1return true;
}
第二次添加数据
public boolean add(E e) {ensureCapacityInternal(size + 1); // 2 Increments modCount!!elementData[size++] = e;return true;
}
private void ensureCapacityInternal(int minCapacity) { // 2// {1,,,,,} {}if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}// 2ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) { // 2modCount++; // 2// 2 - 10 < 0if (minCapacity - elementData.length > 0)grow(minCapacity);
}
public boolean add(E e) {ensureCapacityInternal(size + 1); // 2 Increments modCount!!elementData[size++] = e; // {1,2 ,,,,} length = 10; size=2return true;
}
第十一次
public boolean add(E e) {// {1,2,3,4,5,6,7,8,9,10} size = 10 length = 10ensureCapacityInternal(size + 1); // 11 Increments modCount!!elementData[size++] = e;return true;
}
ensureCapacityInternal
private void ensureCapacityInternal(int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}ensureExplicitCapacity(minCapacity);
}
ensureExplicitCapacity
private void ensureExplicitCapacity(int minCapacity) {modCount++; // 11// 11 - 10if (minCapacity - elementData.length > 0)grow(minCapacity);
}
grow
private void grow(int minCapacity) { // 11// overflow-conscious code// oldCapacity = 10int oldCapacity = elementData.length;// newCapacity = 10 + 5 = 15 10010 >> 1 -- > 1001=5 (oldCapacity >> 1) 取原来值的一半// 新的容量是在原有容量的基础上扩容1.5倍int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// {1,2,3,4,5,6,7,8,9,10} --》 {1,2,3,4,5,6,7,8,9,10,,,,,}elementData = Arrays.copyOf(elementData, newCapacity);
}
在去执行向数组中添加数据的逻辑
public boolean add(E e) {// {1,2,3,4,5,6,7,8,9,10} size = 10 length = 10ensureCapacityInternal(size + 1); // 11 Increments modCount!!{1,2,3,4,5,6,7,8,9,10,11,,,,}elementData[size++] = e; // size = 11 length = 15return true;
}
3.get方法
public E get(int index) {// 检查下标是否合法rangeCheck(index);// 通过下标获取数组中对应的元素return elementData(index);
}
4.set方法
public E set(int index, E element) {rangeCheck(index); // 检查下标的合法性// 获取原来下标对应的元素E oldValue = elementData(index);// 将新的元素设置到数组中对应的下标位置elementData[index] = element;// 返回原来的值return oldValue;
}
5.remove方法
public E remove(int index) {rangeCheck(index);// 检查下标的合法性modCount++; // 修改记录次数E oldValue = elementData(index); // 获取原来下标对应的元素// 计算要移动的元素的个数 {1,2,3,4,5,6,7,8,9} index = 3 size = 9// {1,2,3,5,6,7,8,9,null}int numMoved = size - index - 1;if (numMoved > 0)// System.arraycopy(elementData // 源数组, index+1 // 开始的下标 5,6,7,8,9, elementData // 目标数组 {1,2,3,4,5,6,7,8,9}, index // 开始的下标 {1,2,3,5,6,7,8,9,9},numMoved // 要移动的元素的个数);// {1,2,3,5,6,7,8,9,null}elementData[--size] = null; // clear to let GC do its workreturn oldValue;
}
5.1.3 ArrayList作业
ArrayList集合练习:
(1)创建一个Person类,添加属性:name,age; 封装这些属性并分别设置各个属性的方法。
(2)根据用户输入的对象个数创建Person对象,接收用户在控制台上输入的每个对象的信息。(注意,将有些Person对象的名字和年龄设置相同)
(3)创建一个ArrayList集合,将Person对象添加到ArrayList集合中。
(4)使用迭代器迭代输出该List集合
(5)写一个方法,可以去除ArrayList集合中重复的Person对象。姓名和年龄相同视为重复的Person对象
Person类
package com.bobo.arraylist;public class Person {private String name;private Integer age;public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}
}案例代码
package com.bobo.arraylist;import java.sql.SQLOutput;
import java.util.ArrayList;
import java.util.ListIterator;
import java.util.Scanner;public class ArrayListHomeWork {/*** ArrayList集合练习:* (1)创建一个Person类,添加属性:name,age; 封装这些属性并分别设置各个属性的方法。* (2)根据用户输入的对象个数创建Person对象,接收用户在控制台上输入的每个对象的信息。* (注意,将有些Person对象的名字和年龄设置相同)* (3)创建一个ArrayList集合,将Person对象添加到ArrayList集合中。* (4)使用迭代器迭代输出该List集合* (5)写一个方法,可以去除ArrayList集合中重复的Person对象。姓名和年龄相同视为重复的Person对象* @param args*/public static void main(String[] args) {Scanner in = new Scanner(System.in);System.out.println("请输入Person对象的个数:");int number = in.nextInt();System.out.println("Person的姓名:");String name = in.next();System.out.println("Person的年龄:" );Integer age = in.nextInt();// 创建一个ArrayList集合ArrayList list = new ArrayList();for(int i = 0 ; i < number ; i ++){Person person = new Person(name,age);// 将创建的Person对象添加到list集合中去list.add(person);}// 使用迭代器 输出集合printIteratorList(list);System.out.println("*************");// 移除重复的元素removeRepetitionElement(list);// 使用迭代器 输出集合printIteratorList(list);}/*** 移除重复元素* 通过选择排序的方式来移除重复的元素* 姓名和年龄相同表示是重复的元素* @param list*/public static void removeRepetitionElement(ArrayList list){for(int i = 0 ; i < list.size() - 1 ; i ++){for(int j = i + 1 ; j < list.size() ; j ++){Person p1 = (Person) list.get(i);Person p2 = (Person)list.get(j);if(p1.getName().equals(p2.getName()) && p1.getAge() == p2.getAge()){list.remove(j);j--;}}}}/*** 迭代输出集合中的信息* @param list*/private static void printIteratorList(ArrayList list) {ListIterator listIterator = list.listIterator();while(listIterator.hasNext()){Object next = listIterator.next();if(next instanceof Person){Person p = (Person) next;System.out.println(p);}}}
}
请输入Person对象的个数:
5
Person的姓名:
lisi
Person的年龄:
18
Person{name='lisi', age=18}
Person{name='lisi', age=18}
Person{name='lisi', age=18}
Person{name='lisi', age=18}
Person{name='lisi', age=18}
*************
Person{name='lisi', age=18}
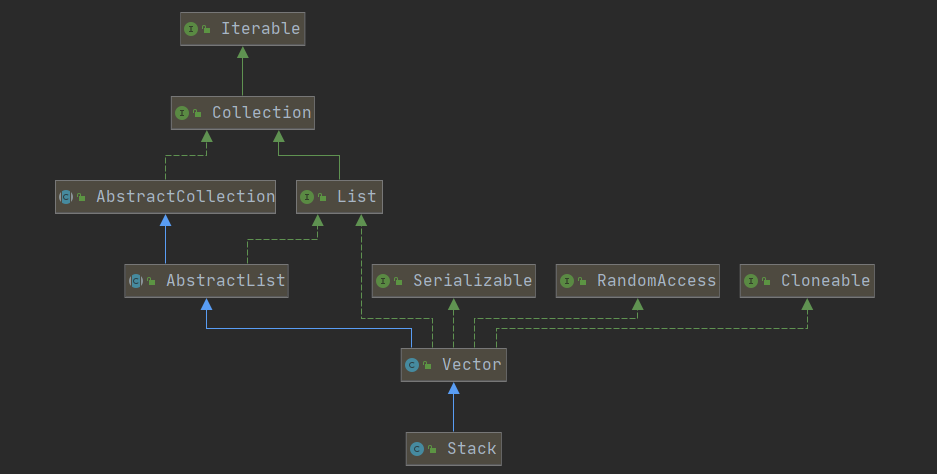
5.2 Vector
概述
Vector类实现了可扩展的对象数组。 像数组一样,它包含可以使用整数索引访问的组件。 但是,Vector的大小可以根据需要增长或缩小,以适应在创建Vector之后添加和删除项目。
常用方法:
增加
public synchronized void addElement(E obj) 添加元素 obj 到集合中
public synchronized void insertElementAt(E obj, int index) 在指定索引 index 处插入元素 obj
删除
public synchronized void removeElementAt(int index) 移除指定索引 index 处的元素
public synchronized void removeAllElements() 移除所有元素
修改
public synchronized void setElementAt(E obj, int index) 修改指定索引 index 的元素为 obj
遍历
public synchronized E elementAt(int index) + size() for循环遍历集合中的所有元素
public synchronized Enumeration<E> elements() 使用 Enumeration 迭代器遍历集合中的元素
获取
public synchronized E firstElement() 获取集合中的第一个元素
public synchronized E lastElement() 获取集合中的最后一个元素
public synchronized E elementAt(int index) 获取指定索引 index 的元素
案例代码
package com.bobo.vector;import java.util.Enumeration;
import java.util.Vector;public class VectorDemo01 {/*** Vector:向量** @param args*/public static void main(String[] args) {Vector v = new Vector();v.add("a");v.addElement("b");v.add("c");v.add("d");System.out.println(v);// 删除操作//v.removeElementAt(2);// 修改操作// v.setElementAt("f",2);// 遍历 Collection接口提供的遍历方式【toArray Iterator foreach】// List接口提供的遍历方式【index ListIterator】Enumeration elements = v.elements();System.out.println("****************");while(elements.hasMoreElements()){System.out.println(elements.nextElement());}System.out.println("****************");// 获取集合中元素的方法Object first = v.firstElement();Object last = v.lastElement();Object obj = v.elementAt(1);System.out.println(v);}
}输出结果:
[a, b, c, d]
****************
a
b
c
d
****************
[a, b, c, d]
特点
- 底层数据结构是数组
- 有索引,能够方便检索
- 增加和删除的效率低,查询和修改的效率高
- 线程安全,效率低
- 能够存储null
- 元素可重复
- 不可以排序
5.3 Stack
概念
Stack类代表最先进先出(LIFO)堆栈的对象。 它扩展了类别Vector与五个操作,允许一个向量被视为堆栈。 涉及在通常的push和pop操作,以及作为一种方法来peek在堆栈,以测试堆栈是否为empty的方法,以及向search在栈中的项目的方法在顶部项目和发现多远它是从顶部。
特点
- 基于栈结构的集合,先进后出
- Stack类是Vector的子类,所以该类也是线程安全的,效率低
常用方法
E push(E item) 将元素压入栈底
E pop() 将元素从栈结构中弹出,并作为此函数的值返回该对象,此方法会影响栈结构的大小
E peek() 查看堆栈顶部的对象,但不从栈中移除它。
boolean empty() 测试栈是否为空。
int search(Object o) 返回对象在栈中的位置,以 1 为基数。
注意:如果栈中的元素为空,那么再次尝试弹栈(pop方法),将会抛出EmptyStackException.
package com.bobo.stack;import java.util.Stack;public class StackDemo1 {/*** Stack栈* 先进后出的特点 LIFO* @param args*/public static void main(String[] args) {Stack s = new Stack();// 压栈s.push("a");s.push("b");s.push("c");s.push("d");System.out.println(s);// peek()获取的是栈顶的元素// System.out.println(s.peek());// pop() 弹栈 获取栈顶的元素并且弹出while(!s.isEmpty()){System.out.println(s.pop());}/*System.out.println(s.pop());System.out.println(s.peek());System.out.println(s.pop());System.out.println(s.peek());System.out.println(s.pop());System.out.println(s.peek());System.out.println(s.pop());System.out.println(s.peek());*/}
}5.4 Queue
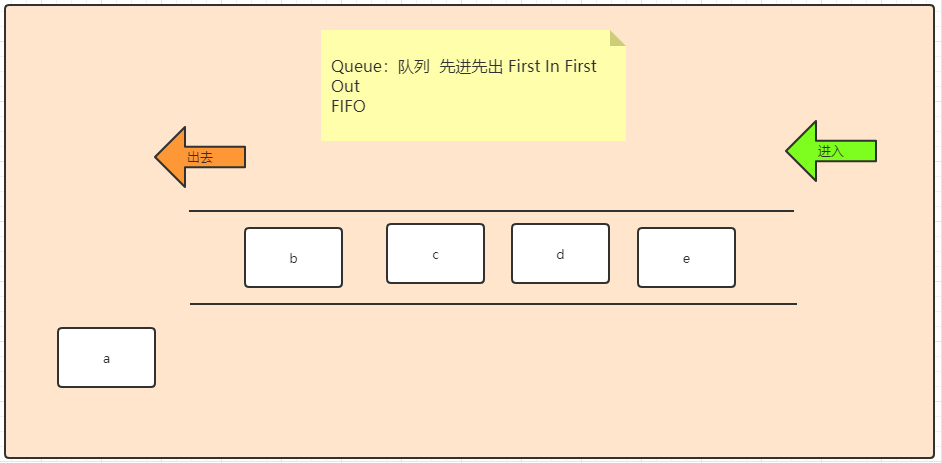
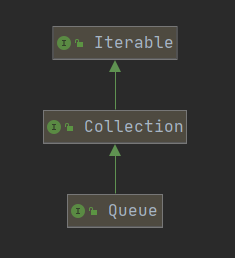
概念
设计用于在处理之前保留元素的集合。 除了基本的
Collection操作之外,队列还提供额外的插入,提取和检查操作。 这些方法中的每一种都有两种形式:如果操作失败,则抛出一个异常,另一种返回一个特殊值(null或false,具体取决于操作)。 插入操作的后一种形式专门设计用于容量限制的Queue实现; 在大多数实现中,插入操作不能失败。
特点
- 该接口是队列接口的跟接口,先进先出
- 该接口提供队列相关的两种形式的方法,一种抛异常,一种返回一个特殊的值(null或者false)
常用方法
| 抛出异常 | 返回特殊值 | |
|---|---|---|
| 插入 | add(e) | offer(e) |
| 移除 | remove() | poll() |
| 检查 | element() | peek() |
实例代码:
package com.bobo;import java.util.ArrayDeque;
import java.util.Queue;public class QueueDemo1 {/*** Queue对象 FIFO* @param args*/public static void main(String[] args) {Queue q = new ArrayDeque(2);System.out.println(q.add("a"));System.out.println(q.add("b"));System.out.println(q.offer("c"));System.out.println(q.offer("d"));/*for(int i = 0 ; i < 15; i ++){System.out.println(q.offer("d"));}*/System.out.println(q);// 移除//q.remove();/*q.poll();System.out.println(q);// q.remove();q.poll();System.out.println(q);//q.remove();q.poll();System.out.println(q);//q.remove();q.poll();System.out.println(q);//q.remove();// q.poll();System.out.println(q.poll());System.out.println(q);*/// 检查 只会去数据 不会弹出
/* System.out.println(q.element());System.out.println(q.element());System.out.println(q.peek());System.out.println(q.peek());*/while(!q.isEmpty()){System.out.println(q.poll());}System.out.println(q);}
}5.5 Deque
概述
一个线性 collection,支持在两端插入和移除元素。名称 deque 是“double ended queue(双端队列)”的缩写,通常读为“deck”。大多数
Deque实现对于它们能够包含的元素数没有固定限制,但此接口既支持有容量限制的双端队列,也支持没有固定大小限制的双端队列。
特点
Deque是一个Queue的子接口,是一个双端队列,支持在两端插入和移除元素deque支持索引值直接存取。Deque头部和尾部添加或移除元素都非常快速。但是在中部安插元素或移除元素比较费时。- 插入、删除、获取操作支持两种形式:快速失败和返回null或true/false
- 不推荐插入null元素,null作为特定返回值表示队列为空
常用方法
| 第一个元素(头部) | 最后一个元素(尾部) | |||
|---|---|---|---|---|
| 抛出异常 | 特殊值 | 抛出异常 | 特殊值 | |
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 移除 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 检查 | getFirst() | peekFirst() | getLast() | peekLast() |
双向队列操作
插入元素
- addFirst(): 向队头插入元素,如果元素为null,则发生空指针异常
- addLast(): 向队尾插入元素,如果为空,则发生空指针异常
- offerFirst(): 向队头插入元素,如果插入成功返回true,否则返回false
- offerLast(): 向队尾插入元素,如果插入成功返回true,否则返回false
移除元素
- removeFirst(): 返回并移除队头元素,如果该元素是null,则发生NoSuchElementException
- removeLast(): 返回并移除队尾元素,如果该元素是null,则发生NoSuchElementException
- pollFirst(): 返回并移除队头元素,如果队列无元素,则返回null
- pollLast(): 返回并移除队尾元素,如果队列无元素,则返回null
获取元素
- getFirst(): 获取队头元素但不移除,如果队列无元素,则发生NoSuchElementException
- getLast(): 获取队尾元素但不移除,如果队列无元素,则发生NoSuchElementException
- peekFirst(): 获取队头元素但不移除,如果队列无元素,则返回null
- peekLast(): 获取队尾元素但不移除,如果队列无元素,则返回null
栈操作
pop(): 弹出栈中元素,也就是返回并移除队头元素,等价于removeFirst(),如果队列无元素,则发生NoSuchElementException
push(): 向栈中压入元素,也就是向队头增加元素,等价于addFirst(),如果元素为null,则发生NoSuchElementException,如果栈空间受到限制,则发生IllegalStateException
引用场景
- 满足FIFO场景时
- 满足LIFO场景时,曾经在解析XML按标签时使用过栈这种数据结构,但是却选择
Stack类,如果在进行栈选型时,更推荐使用Deque类,应为Stack是线程同步
5.6 ArrayDeque
概述
Deque接口的大小可变数组的实现。数组双端队列没有容量限制;它们可根据需要增加以支持使用。它们不是线程安全的;在没有外部同步时,它们不支持多个线程的并发访问。禁止 null 元素。此类很可能在用作堆栈时快于Stack,在用作队列时快于LinkedList。
特点
ArrayDeque是Deque接口的一种具体实现,是依赖于可变数组来实现的ArrayDeque没有容量限制,可根据需求自动进行扩容ArrayDeque不支持值为 null 的元素。ArrayDeque可以作为栈来使用,效率要高于 StackArrayDeque也可以作为队列来使用,效率相较于基于双向链表的 LinkedList 也要更好一些
5.7 LinkedList
链表结构
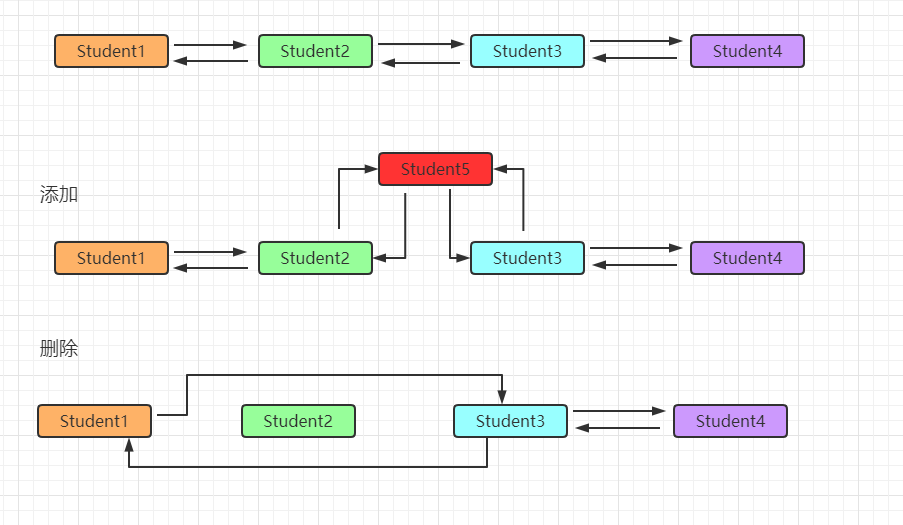
特点:
- 灵活的空间要求,存储空间不要求连续
- 不支持下标访问,支持顺序遍历
- 针对增删效率会高一些,只和操作节点的前后节点有关系,无需移动元素
LinkedList
类图结构
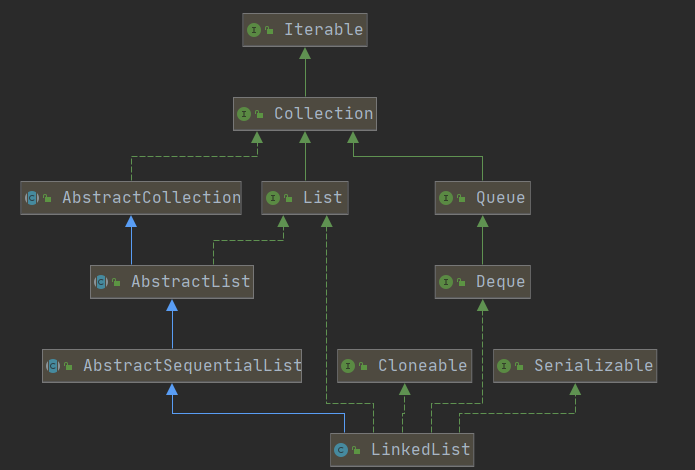
LinkedList描述
双链表实现了
List和Deque接口。 实现所有可选列表操作,并允许所有元素(包括null)。所有的操作都能像双向列表一样预期。 索引到列表中的操作将从开始或结束遍历列表,以更接近指定的索引为准。
请注意,此实现不同步。如果多个线程同时访问链接列表,并且至少有一个线程在结构上修改列表,则必须在外部进行同步。
特点:
- LinkedList底层的数据结构是一个双向链表,元素有序,可重复
- LinkedList在实现数据的添加和删除效率高,查询和修改效率低,顺序访问会非常高效,而随机访问效率会比较低
- LinkedList 实现了List接口,支持使用索引访问元素
- LinkedList实现Deque接口,所以LinkedList也可以当做双端队列使用
- LinkedList是线程不安全的,效率高
6.泛型
6.1 泛型概念
为什么要使用泛型:集合中是可以存储任意的引用类型数据的,如果同一个集合中存储的数据类型不一致,那么我在操作数据的时候有可能出现数据类型安全问题,这时我们可以通过泛型来解决这个问题
问题还原:
package com.bobo.genericity;import java.util.ArrayList;
import java.util.List;public class GenericityDemo01 {/*** 集合中可以存储任意 引用类型的数据* 数组:在存储数据的时候只能存储指定类型的数据* Person[] ps = new Person[10];* String[] str = new String[10];* int[] arrs= new int[];* 在JDK1.5之前 我们还是只能通过Object 多态来实现,但是为会在数据类型的安全隐患* 在JDK1.5之后提供了泛型,来帮助我们解决这个问题* @param args*/public static void main(String[] args) {List list = new ArrayList();list.add(1);list.add("张三");list.add(new Person());System.out.println(list);System.out.println("*********");for(Object o : list){//System.out.println(o);//String str = (String) o;if(o instanceof String){String str = (String) o;}if(o instanceof Person){Person p = (Person)o;}}}
}
class Person{}集合中泛型的使用:
package com.bobo.genericity;import java.lang.reflect.Array;
import java.util.ArrayList;
import java.util.List;public class GenericityDemo02 {/*** 集合 泛型的使用* @param args*/public static void main(String[] args) {// 泛型的使用 表示该集合只能存放String类型的数据List<String> list = new ArrayList();list.add("张三1");list.add("张三2");list.add("张三3");// list.add(1);//list.add(new ArrayList());for (int i = 0; i < list.size(); i++) {// 通过泛型的使用,我们在获取数据的使用就不需要向上转型和向下转型了String s = list.get(i);System.out.println(s);}System.out.println("__________________");for(String s : list){System.out.println(s);}}
}泛型的概念:
在编译时就确定类型的一种技术,注意:泛型是JDK1.5之后引入的新特性,是一种将引用类型当做参数传递的参数化类型,在编译时期就确定了集合存储的元素类型
格式: <数据类型> 这里面的类型必须是引用类型
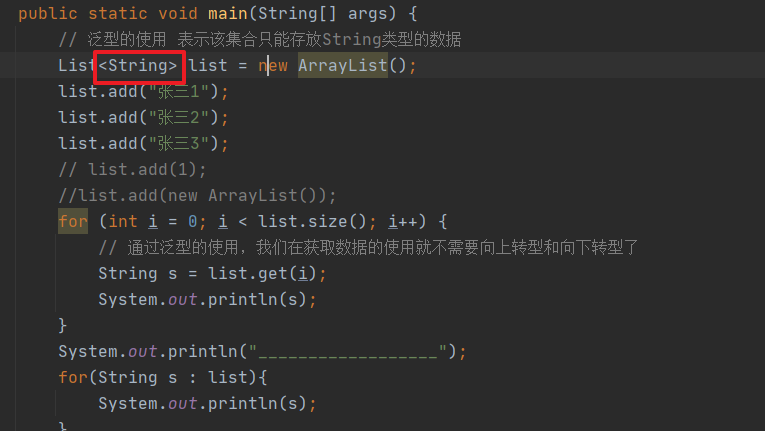
泛型的好处:
-
提高程序的安全性
-
消除了黄色警告线(Eclipse中)
-
在编译时期将类型确定,减少了不必要的强转代码
6.2 泛型的分类
根据泛型的不同使用位置我们可以将泛型分为三种:
- 泛型类
- 泛型方法
- 泛型接口
6.2.1 泛型类
package com.bobo.genericity;/*** 泛型类* 1.声明泛型 我们可以声明多个类型 大写的英文字母* 2.使用泛型*/
public class Student <T,V,K> {// private Object o;private T o;public T getO() {return o;}public void setO(T o) {this.o = o;}
}使用:
public static void main(String[] args) {Student<String,Integer,String> s = new Student();s.setO("张三");String str = (String)s.getO();String s1 = s.getO();
}
6.2.2 泛型方法
我们在方法的形参和返回结果都可以使用泛型类定义,好处是增加了方法的灵活性
案例代码
package com.bobo.genericity;public class GenericityDemo04<K> {public static void main(String[] args) {GenericityDemo04<Integer> d = new GenericityDemo04();d.method3("abc",11);}public static Object method1(Object o){System.out.println(o);return o;}/*** 泛型的使用必须是先声明 在使用*/public <T> T method2(T t){System.out.println(t);return t;}/*** 普通方法中 我们可以使用在类中声明的泛型* @param t* @param k* @param <T>* @return*/public <T> T method3(T t, K k){System.out.println( t+ " " + k);return t;}/*** 在静态方法中 我们是不能使用泛型类的,因为 泛型类类型是在实例化对象的时候我们才能确定* 而静态方法我们是通过类型来直接执行的,此时类泛型的类型并没有确认,所以不能使用* @param t* @param <T>* @return*/public static <T> T method4(T t//,K k){return t;}}注意点:
- 泛型使用之前必须要声明
- 普通方法可以使用方法声明的泛型或者类泛型
- 静态方法是不能够使用在类名处声明的泛型
6.2.3 泛型接口
/*** 泛型接口* @param <T>*/
public interface CalGeneric <T> {T add(T a,T b);T sub(T a,T b);T mul(T a,T b);T div(T a,T b);
}
应用
package com.bobo.genericity;public class GenericityDemo05 {public static void main(String[] args) {}
}class DoubleCalc implements CalGeneric<Double>{@Overridepublic Double add(Double a, Double b) {return a+b;}@Overridepublic Double sub(Double a, Double b) {return a-b;}@Overridepublic Double mul(Double a, Double b) {return a*b;}@Overridepublic Double div(Double a, Double b) {return a/b;}
}class IntegerCalc implements CalGeneric<Integer>{@Overridepublic Integer add(Integer a, Integer b) {return a+b;}@Overridepublic Integer sub(Integer a, Integer b) {return a-b;}@Overridepublic Integer mul(Integer a, Integer b) {return a*b;}@Overridepublic Integer div(Integer a, Integer b) {return a/b;}
}泛型接口的使用大大的提高了代码的灵活性
6.3 泛型的通配符
前面所介绍的泛型的使用都是在编译的时候能确定一种类型,我们其实在泛型中还是可以借鉴多态的思想,那么这时我们就需要使用到通配符( ? )
- ? 无界(无边界)通配符
- ? extends E 上边界通配符
- ? super E 下边界通配符
案例代码
package com.bobo.genericity;import java.util.ArrayList;
import java.util.List;public class GenericityDemo06 {public static void main(String[] args) {GenericityDemo06 d = new GenericityDemo06();List<String> list = new ArrayList<>();list.add("a");list.add("b");d.fun1(list);List<Integer> list1 = new ArrayList<>();list1.add(1);list1.add(2);list1.add(3);d.fun2(list1);List<Number> list2 = new ArrayList<>();list2.add(3);d.fun3(list2);}public <T> void fun1(T t){}public <T> void fun1(T t,List<T> list){}public <T> void fun1(T t,List<T> list,List<?> list1){}/*** 无边界通配符* @param list* List<?> list ? 表示的是任意的类型 无边界通配符* @param <T>*/public <T> void fun1(List<?> list){}/*** 上边界通配符* @param list* List<? extends Number> ? extends 表示的是调用是传递类型必须是 Number类型或者其子类* @param <T>*/public <T> void fun2(List<? extends Number> list){}/*** 下边界通配符* @param list* List<? super Number> list* 调用是传递的参数的类型必须是 Number 类型或者是 Object类型* @param <T>*/public <T> void fun3(List<? super Number> list){}
}List接口案例
一个学校有两个班级,一个班级有3个学生…,一个班级有2个学生。使用集合存储这个学校的所有的学生,再遍历出来
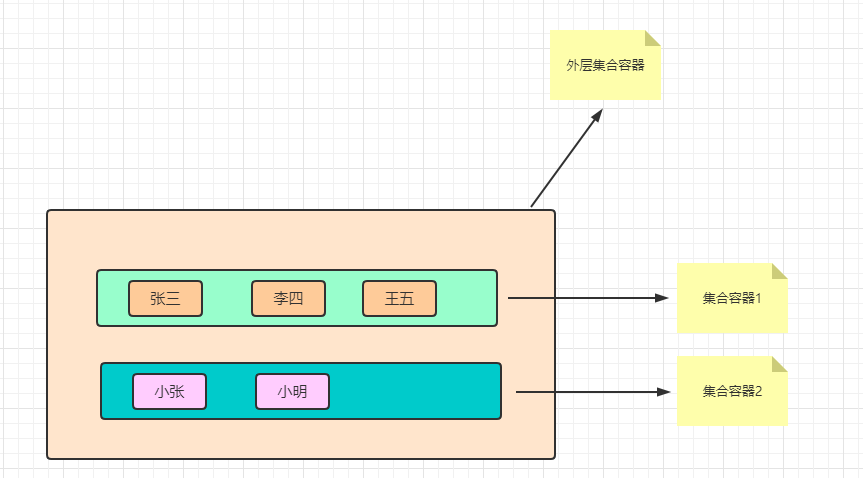
package com.bobo.genericity;import java.util.ArrayList;
import java.util.List;public class ListDemo {/*** 一个学校有两个班级,一个班级有3个学生....,一个班级有2个学生。* 使用集合存储这个学校的所有的学生,再遍历出来* @param args*/public static void main(String[] args) {// 存储第一个班级的学生信息List<StudentNew> list1 = new ArrayList<>();list1.add(new StudentNew("张三",18));list1.add(new StudentNew("李四",19));list1.add(new StudentNew("王五",20));// 存储第二个班级的学生信息List<StudentNew> list2 = new ArrayList<>();list2.add(new StudentNew("小明",22));list2.add(new StudentNew("小张",24));// 存储学校所有班级学生信息的集合List<List<StudentNew>> gradeList = new ArrayList<>();gradeList.add(list1);gradeList.add(list2);int i = 1;// 遍历集合的所有元素for(List<StudentNew> list : gradeList){// 外层循环获取每个班级for(StudentNew stu:list){// 内存循环获取每个班级中的所以的学生System.out.println("班级" + i + ":"+stu);}i++;}}
}class StudentNew{private String name;private Integer age;public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public StudentNew() {}public StudentNew(String name, Integer age) {this.name = name;this.age = age;}@Overridepublic String toString() {return "StudentNew{" +"name='" + name + '\'' +", age=" + age +'}';}
}四、Set接口
1.Set接口介绍
有别于List(有序可重复)接口,Set接口是无序不可重复的
Set的类结构
在次类结构中我们没有发现Set接口自己声明的方法和属性
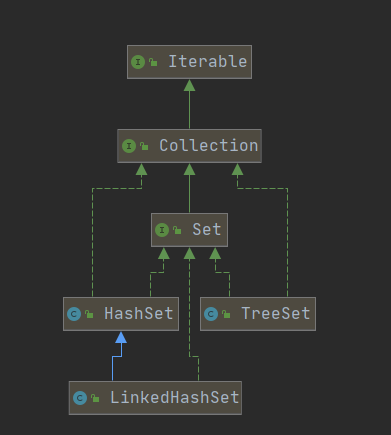
Set的类图结构
演示代码
package com.bobo.set;import java.util.HashSet;
import java.util.Set;public class SetDemo01 {/*** Set 接口* 无序不可重复 null只能存储一个* @param args*/public static void main(String[] args) {Set set = new HashSet();set.add(1);set.add(9);set.add(5);set.add(null);set.add(3);set.add(8);set.add(new Person());set.add(9);set.add(null);set.add(new Person());System.out.println(set);}
}class Person{}输出结果
[null, 1, 3, com.bobo.set.Person@74a14482, 5, 8, com.bobo.set.Person@4554617c, 9]
Set集合的特点:
- 集合中的元素不重复
- 存储的元素是无序的
2.HashSet
2.1 HashSet的概念
此类实现Set接口,由哈希表(实际为HashMap实例)支持。 对集合的迭代次序不作任何保证; 特别是,它不能保证订单在一段时间内保持不变。 这个类允许null元素。
2.2 HashSet的特点
HashSet是实现了Set接口,所以具备Set接口的特点。
- 集合中的元素不重复
- 存储的元素是无序的
HashSet是一个具体的实现类,那么HashSet是怎么实现以上特点的?这个就和HashSet的底层数据结构有关系了,HashSet的底层实现是哈希表(HashTable,散列表)
2.3 什么是散列表
数组:查询和修改效率高,添加和删除效率低

链表:添加和删除效率高,查询和修改效率低

散列表:查询、修改、添加、删除的效率都还可以
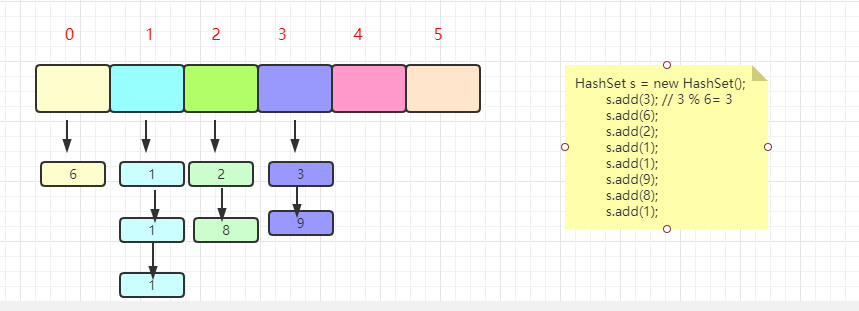
数据结构的演示网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
2.4 HashSet 的实现原理
我们通过上面的介绍知道了HashSet的底层是通过散列表实现的,但是HashSet和散列表的特点还有点区别的。散列表是可以存储重复元素的,但是HashSet是不存储重复元素的,那么HashSet实现有何不同呢?
通过构造方法我们能够发现HashSet实例化的时候其实是创建了一个HashMap实例
public HashSet() {map = new HashMap<>();
}
在调用add方法的时候其本质是调用了HashMap的put方法
public boolean add(E e) {return map.put(e, PRESENT)==null;
}
通过以上可知,HashSet的本质是通过HashMap来实现的
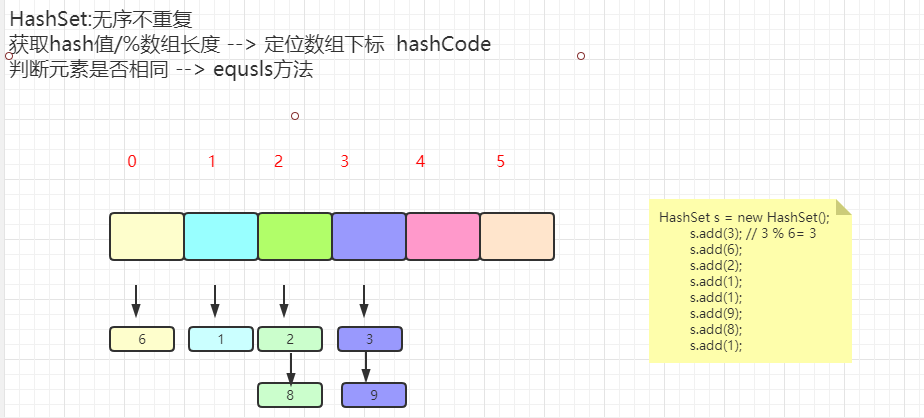
HashSet添加元素时保证元素一维,本质底层依赖的是两个方法
int hashCode(); // 确定散列表中数组的下标
boolean equals(Object o); // 同一个下标对应的链表中的数据是否相等
案例代码:
package com.bobo.set.hashset;import java.util.HashSet;
import java.util.Objects;public class HashSetDemo03 {/*** 自定义类型 HashSet* @param args*/public static void main(String[] args) {// 保存 存储的学生信息中 姓名和年龄相同的数据不重复HashSet<Student> s = new HashSet();Student s1 = new Student("张三",18);Student s2 = new Student("李四",18);Student s3 = new Student("李四",18);Student s4 = new Student("张三",18);s.add(s1);s.add(s2);s.add(s3);s.add(s4);System.out.println(s1.hashCode());System.out.println(s2.hashCode());System.out.println(s3.hashCode());System.out.println(s4.hashCode());System.out.println(s);}
}class Student{private String name;private Integer age;/*** hash值相同保证的是会保存到散列表的同一个数组中去* @return*/@Overridepublic int hashCode() {return Objects.hash(name, age);}/*** 两个对象的name和age都相等就表示是同一个对象* @param o* @return*/@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return Objects.equals(name, student.name) &&Objects.equals(age, student.age);}public Student(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}
}输出结果:
24022538
26104870
26104870
24022538
[Student{name='张三', age=18}, Student{name='李四', age=18}]
2.5 课堂案例
随机获取6个20~50之间的不重复的随机数
package com.bobo.set.hashset;import java.util.HashSet;public class HashSetDemo04 {/*** 随机获取6个20~50之间的不重复的随机数* @param args*/public static void main(String[] args) {// 获取HashSet对象HashSet s = new HashSet();while(s.size() < 6){s.add(getRandomNumber(20,50));}System.out.println(s);}/*** 生成一个start到end之间的随机整数* @param start* @param end* @return*/public static int getRandomNumber(int start,int end){return (int)(Math.random()*(end-start + 1) + start);}
}输出结果:
[32, 49, 34, 38, 40, 26]
3. TreeSet
3.1 TreeSet的概念
基于TreeMap的NavigableSet的实现,使用元素的自然顺序对元素进行排序。或者根据创建 set 时提供的Comparator进行排序,具体取决于使用的构造方法
实例代码
public class TreeSetDemo01 {public static void main(String[] args) {// 获取一个TreeSet实例TreeSet s = new TreeSet();s.add(3);s.add(6);s.add(9);s.add(2);s.add(3);s.add(4);System.out.println(s);}
}
输出结果
[2, 3, 4, 6, 9]
public class TreeSetDemo02 {public static void main(String[] args) {// 获取一个TreeSet实例TreeSet<String> s = new TreeSet();s.add("ab");s.add("aa");s.add("bb");s.add("ac");s.add("dd");s.add("ab");s.add("ad");//s.add(null);System.out.println(s);}
}
输出结果
[aa, ab, ac, ad, bb, dd]
TreeSet的特点
- 满足Set接口的特点(无序不重复)
- 存储的数据排序
- 不能存储null
所以 我们就要考虑TreeSet是如何实现以上特点的?
3.2 TreeSet的实现原理
3.2.1 TreeSet在API层面
在构造器层面创建一个TreeMap实例
public TreeSet() {this(new TreeMap<E,Object>());
}
在调用add方法的时候,本质是调用了TreeMap的put方法
public boolean add(E e) {return m.put(e, PRESENT)==null;
}
所以TreeSet的实现的本质是TreeMap。
3.2.2 TreeSet数据结构实现
TreeSet的底层实现的数据结构红黑树。
二叉树

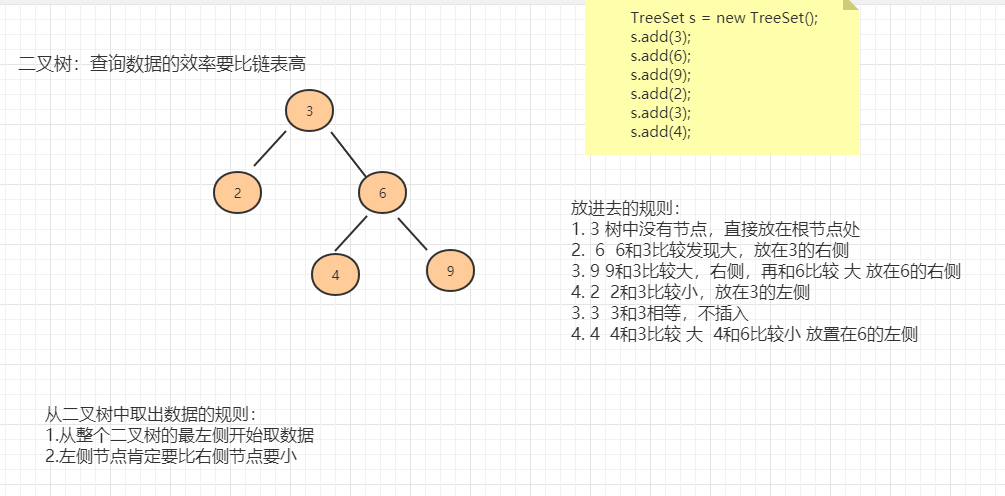
二叉树的缺点:不平衡二叉树
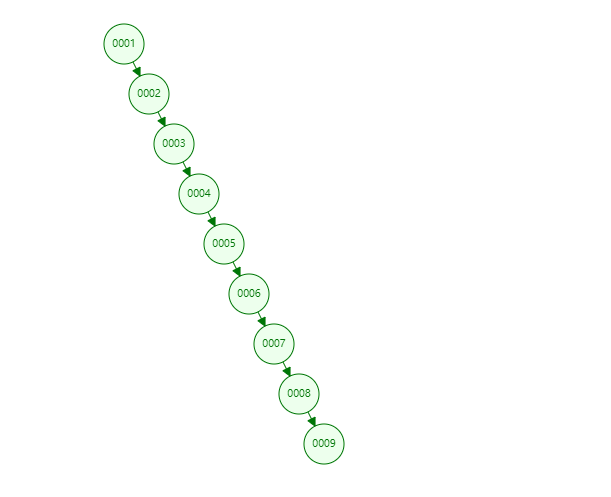
查询效率不高,这时我们可以考虑红黑树或者平衡二叉树
平衡二叉树
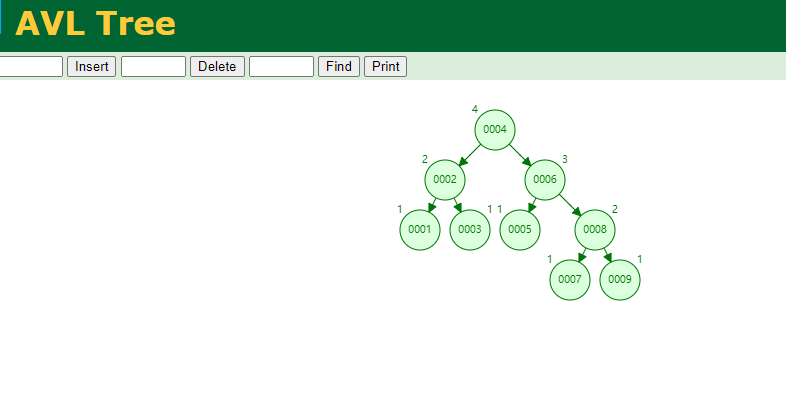
红黑树
红黑树,Red-Black Tree [RBT] 是一个自平衡(不是绝对平衡)的二叉查找数,树上的每个节点都遵循如下规则
- 每个节点要么是黑色,要么是红色
- 跟节点是黑色
- 每一个叶子节点(NIL)是黑色
- 每个红色结点的两个子节点一定是黑色的
- 任意一个结点到每个叶子节点的路径包含数量相同的黑色节点
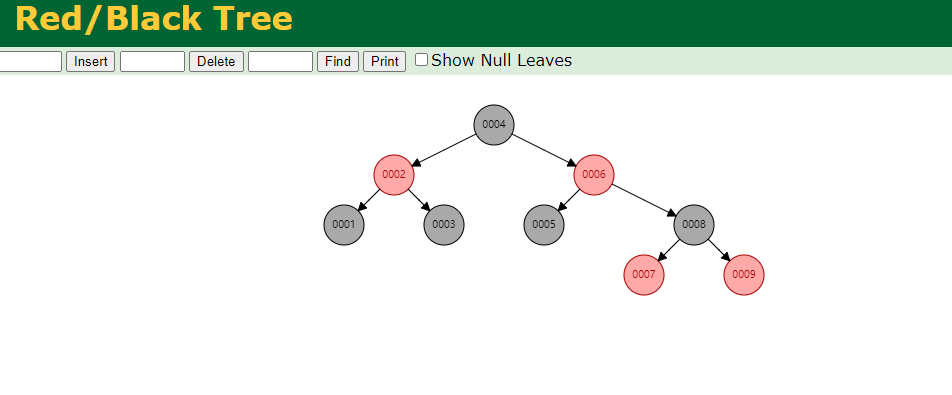
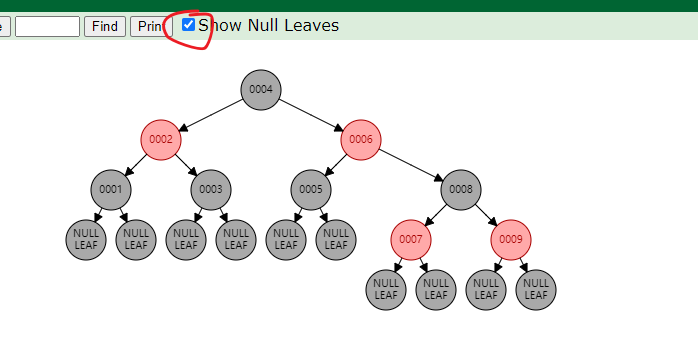
红黑树满足以上的规则,是通过如下的两个操作来实现
- recolor 重新标记颜色
- rotation 旋转 这个树达到平衡的关键
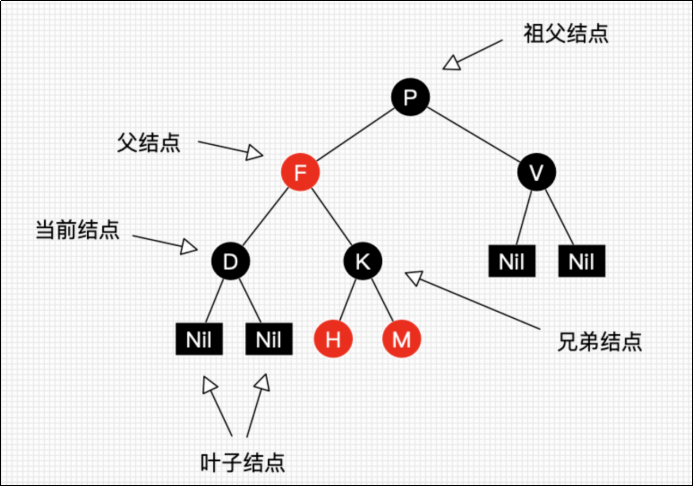
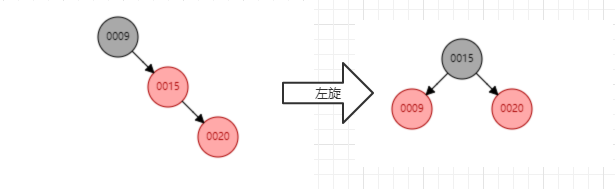
红黑树能够自平衡的三个操作:
1、左旋:以某个结点作为支点(旋转结点),其右子结点变为旋转结点的父结点,右子结点的左子结点变为旋转结点的右子结点,左子结点保持不变。
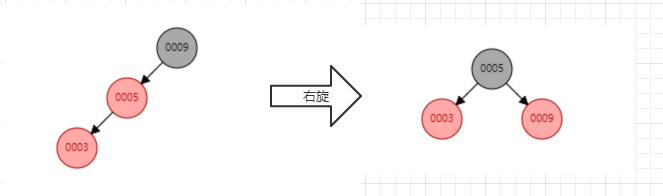
2、右旋:以某个结点作为支点(旋转结点),其左子结点变为旋转结点的父结点,左子结点的右子结点变为旋转结点的左子结点,右子结点保持不变。
变色:结点的颜色由红变黑或由黑变红。
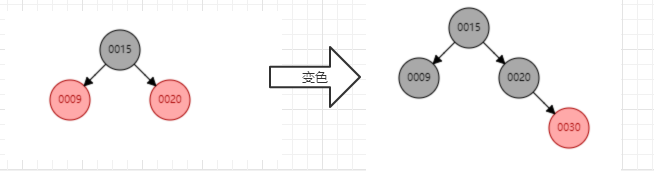
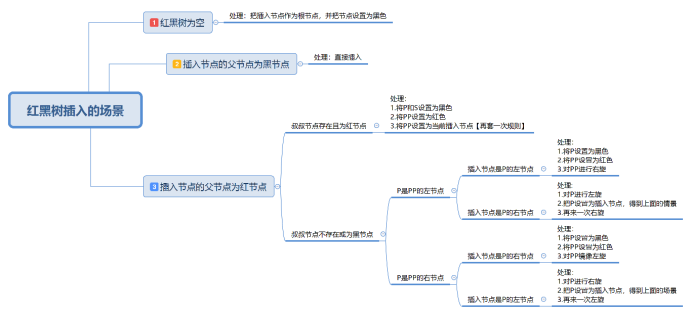
红黑树插入节点的规则:
3.3 Compareable接口
自定义的引用类型,是没有排序规则的,我们可以通过实现Compareable接口来重写 compareTo方法来指定特定的排序规则
package com.bobo.set.hashset.treeset;import java.util.Objects;/*** 学生类* Comparable可以指定自定义类型的排序规则* 但是指定之后就不可以改变了,或者说只能指定一种排序规则**/
public class Student implements Comparable<Student>
{private String name;private Integer age;private Double score;public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public Double getScore() {return score;}public void setScore(Double score) {this.score = score;}public Student(String name, Integer age) {this.name = name;this.age = age;}public Student(String name, Integer age, Double score) {this(name,age);this.score = score;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +", score=" + score +'}';}/*** Student对象相同的规则是 姓名和年龄相同 就是同一个对象* @param o* @return*/
/* @Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return Objects.equals(name, student.name) &&Objects.equals(age, student.age);}*//*** hashCode 和 name和age有关* @return*//* @Overridepublic int hashCode() {return Objects.hash(name, age);}*//*** 定义Student 排序的规则* 首先根据姓名来排序 然后根据年龄来排序* @param o* @return*/@Overridepublic int compareTo(Student o) {// return this.getAge() - o.getAge();// return this.getAge() - o.getAge();if(this.getName().compareTo(o.getName()) ==0){// 姓名是相同的return this.getAge() - o.getAge();}return this.getName().compareTo(o.getName());}
}输出结果
Student{name='张三', age=16, score=null}
Student{name='张三', age=17, score=null}
Student{name='张三', age=18, score=null}
Student{name='李四', age=22, score=null}
Student{name='王五', age=19, score=null}
3.4 Comparator接口
对于Compareable接口定义的排序规则的缺点是我们只能定义一种规则,不太灵活,这时我们可以通过Comparator接口来完善。
同时Comparator接口的实现会覆盖掉Compareable接口的实现
package com.bobo.set.hashset.treeset;import java.util.Comparator;
import java.util.TreeSet;public class TreeSetDemo04 {/*** TreeSet 中添加自定义引用类型* TreeSet中存储的数据会排序* @param args*/public static void main(String[] args) {TreeSet<Student> set = new TreeSet<>(new Comparator<Student>() {/*** 创建一个TreeSet对象的同时我们传递一个比较器给该对象* @param o1* @param o2* @return*/@Overridepublic int compare(Student o1, Student o2) {return -(o1.getAge() - o2.getAge());}});set.add(new Student("张三",18));set.add(new Student("李四",22));set.add(new Student("王五",19));set.add(new Student("张三",16));set.add(new Student("张三",17));for (Student s: set) {System.out.println(s);}}
}输出结果
Student{name='李四', age=22, score=null}
Student{name='王五', age=19, score=null}
Student{name='张三', age=18, score=null}
Student{name='张三', age=17, score=null}
Student{name='张三', age=16, score=null}
第二种规则
package com.bobo.set.hashset.treeset;import java.util.Comparator;
import java.util.TreeSet;public class TreeSetDemo05 {/*** TreeSet 中添加自定义引用类型* TreeSet中存储的数据会排序* 通过Comparator定义的排序规则会覆盖掉对象通过实现Compareable接口定义的排序规则* @param args*/public static void main(String[] args) {TreeSet<Student> set = new TreeSet<>(new Comparator<Student>() {/*** 创建一个TreeSet对象的同时我们传递一个比较器给该对象* @param o1* @param o2* @return*/@Overridepublic int compare(Student o1, Student o2) {return o1.getName().compareTo(o2.getName());}});set.add(new Student("张三",18));set.add(new Student("李四",22));set.add(new Student("王五",19));set.add(new Student("张三",16));set.add(new Student("张三",17));for (Student s: set) {System.out.println(s);}}
}输出结果
Student{name='张三', age=18, score=null}
Student{name='李四', age=22, score=null}
Student{name='王五', age=19, score=null}
针对本身的数据结构并没有提供排序功能的集合,我们同样可以通过Comparator来实现排序
package com.bobo.set.hashset.treeset;import java.util.*;public class TreeSetDemo06 {/*** TreeSet 中添加自定义引用类型* TreeSet中存储的数据会排序* @param args*/public static void main(String[] args) {List<Student> list = new ArrayList();list.add(new Student("张三",18));list.add(new Student("李四",22));list.add(new Student("王五",19));list.add(new Student("张三",16));list.add(new Student("张三",17));Collections.sort(list, new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return o1.getAge() - o2.getAge();}});for (Student s: list) {System.out.println(s);}}
}
输出结果
Student{name='张三', age=16, score=null}
Student{name='张三', age=17, score=null}
Student{name='张三', age=18, score=null}
Student{name='王五', age=19, score=null}
Student{name='李四', age=22, score=null}
4.TreeSet 课后作业
键盘录入5个学生信息(姓名,年龄,语文成绩,数学成绩,英语成绩),按照总分从高到低输出到控制台,注意:如果总分相同那么按照语文成绩排序其次数学成绩,英语成绩,年龄,姓名排序。
package com.bobo.set;import java.util.Comparator;
import java.util.TreeSet;public class HomeWork {/*** 键盘录入5个学生信息(姓名,年龄,语文成绩,数学成绩,英语成绩),按照总分从高到低输出到控制台,* 注意:如果总分相同那么按照语文成绩排序其次数学成绩,英语成绩,年龄,姓名排序。* @param args*/public static void main(String[] args) {// 创建5个学生信息,TreeSet集合来存储着5个学生信息TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() {/*** Student的比较器* @param o1* @param o2* @return*/@Overridepublic int compare(Student o1, Student o2) {// 注意:如果总分相同那么按照语文成绩排序其次数学成绩,英语成绩,年龄,姓名排序。// 1.比较两个学生的总成绩double num1 = o1.getTotalScore() - o2.getTotalScore();// 如果总成绩相同那么就比较语文成绩num1 = (num1 == 0 ) ? (o1.getChineseScore()- o2.getChineseScore()) :num1;num1 = (num1 == 0 ) ? (o1.getMathScore() - o2.getMathScore()) : num1;num1 = (num1 == 0 ) ? (o1.getEnglishScore() - o2.getEnglishScore()):num1;num1 = (num1 == 0) ? (o1.getAge() - o2.getAge()) : num1;num1 = (num1 == 0) ? (o1.getName().compareTo(o2.getName())) : num1;return num1 > 0 ? 1:( (num1 < 0) ? -1 : 0) ;}});// 录入5个学生成绩for( int i = 0 ; i < 100 ; i ++){Student s = new Student();s.setName("张三");s.setAge(getRandomNum(18,20));s.setChineseScore(Double.valueOf(getRandomNum(88,91)));s.setMathScore(Double.valueOf(getRandomNum(88,91)));s.setEnglishScore(Double.valueOf(getRandomNum(88,91)));// 将学生信息添加到集合中ts.add(s);}for (Student s:ts) {System.out.println(s + " -- > " + s.getTotalScore());}}public static int getRandomNum(int start,int end){return (int)(Math.random()*(end-start + 1) + start);}
}class Student{private String name;private Integer age;private Double chineseScore;private Double mathScore;private Double englishScore;public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public Double getChineseScore() {return chineseScore;}public void setChineseScore(Double chineseScore) {this.chineseScore = chineseScore;}public Double getMathScore() {return mathScore;}public void setMathScore(Double mathScore) {this.mathScore = mathScore;}public Double getEnglishScore() {return englishScore;}public void setEnglishScore(Double englishScore) {this.englishScore = englishScore;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +", chineseScore=" + chineseScore +", mathScore=" + mathScore +", englishScore=" + englishScore +'}';}/*** 返回学生的总成绩* @return*/public Double getTotalScore(){return this.getChineseScore() + this.getMathScore() + this.getEnglishScore();}
}
五、Map接口
1.Map接口的相关概念
1.1 为什么要学习Map 集合?
存储班级学生的信息
学生id 姓名 年龄 成绩
20200001 张三1 18 88
20200001 张三2 18 88
20200001 张三3 18 88
20200001 张三4 18 88
20200001 张三5 18 88
我们通过前面的List集合和Set集合来存储
HashSet<String> idList;
ArrayList<String> nameList;
ArrayList<Integer> ageList;
ArrayList<Double> scoreList;
ArrayList<Object> --> [idList,nameList,ageList,scoreList]
新的需求:请通过学号查询某个学生的信息?
1.2 Map集合
针对这种情况,Java设计了Map集合
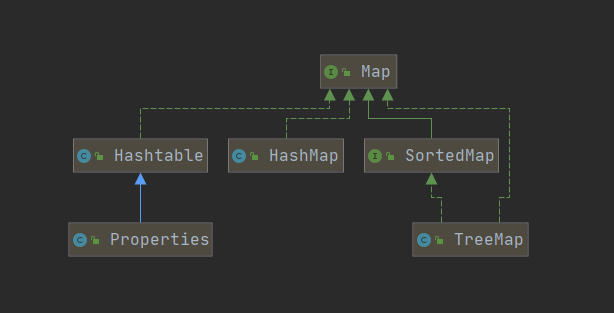
Map集合提供了集合之间的一种映射关系。让集合与集合之间产生关联。
将键映射到值的对象。 地图不能包含重复的键; 每个键可以映射到最多一个值
Map集合常用API
1.添加功能
v put(K key,V value);
void putAll(Map<? extends K, ? extends V> m);
2.删除功能
v remove(Object key);
void clear();
3.遍历功能
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K,V>> entrySet();
4.获取功能
V get(Oject key);
5.判断功能
boolean containsKey(Object key);
boolean containsValue(Object value);
6.长度功能
int size();
package com.bobo.set.map;import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;public class MapDemo01 {/*** Map接口** @param args*/public static void main(String[] args) {// 获取一个Map实例Map<String,Object> map = new HashMap<>();// 添加数据的功能map.put("id",1001);Map<String,Object> m = new HashMap<>();m.put("name","张三");map.putAll(m);// 删除功能//System.out.println(map.remove("id"));// 清空集合中的数据//map.clear();map.put("id",1003) ;// 遍历Map集合map.put("name","李四");map.put("age" ,18);map.put("score",88);map.put("age",22);map.put(null,"abc");//map.put(null,"abc1");map.put("address",null);map.put("desc","abc");// toStringSystem.out.println(map);// 遍历获取Map集合中的每个元素// 遍历的第一种方式// 获取Map集合中的所有的Key对应的一个Set集合Set<String> keys = map.keySet();for (String key:keys) {// 根据Key去Map中获取对应的值System.out.println(key + ":" + map.get(key));}System.out.println("***************");// 第二种遍历方式// 获取所有的Map集合中的value值 但是获取不到对应的KeyCollection<Object> values = map.values();for(Object o : values){System.out.println(o);}System.out.println("****************");// 第三种遍历方式 将每一个KV对封装为了一个Entry对象Set<Map.Entry<String, Object>> entries = map.entrySet();for(Map.Entry<String,Object> entry: entries){// 获取KeyString key = entry.getKey();// 获取ValueObject value = entry.getValue(); // map.get(key);System.out.println(key + " : " + value);}System.out.println("****************");// 获取功能Object id = map.get("id");System.out.println(id);// 判断功能System.out.println(map.containsKey("ids"));System.out.println(map.containsValue("abcs"));//map.clear();System.out.println(map.isEmpty());// 长度System.out.println(map.size());}
}输出结果
{null=abc, score=88, address=null, name=李四, id=1003, age=22, desc=abc}
null:abc
score:88
address:null
name:李四
id:1003
age:22
desc:abc
***************
abc
88
null
李四
1003
22
abc
****************
null : abc
score : 88
address : null
name : 李四
id : 1003
age : 22
desc : abc
****************
1003
false
false
false
7
1.3 Map集合的特点
- 能够存储唯一的列的数据(唯一,不可重复) Set
- 能够存储重复的值 List
- 值的顺序是取决于key的顺序
- key和value都可以存储null值
2. HashMap
基于哈希表的实现的
Map接口。 此实现提供了所有可选的Map操作,并允许null的值和null键。 (HashMap类大致相当于Hashtable,除了它是不同步的,并允许null)。这个类不能保证Map的顺序; 特别是,它不能保证订单在一段时间内保持不变。
HashMap中的Key的存储方式是基于哈希表(HashTable 散列表)
HashMap的特点:
- 键无序,唯一,类似于Set集合(HashSet)
- 值有序,可重复,类似于List
- 底层的数据结构是哈希表,包装Key唯一
代码演示:使用HashMap存储学生信息(要求key存储学生的id,值存储学生的对象)
学生id 姓名 年龄 成绩2018050401 张三 18 80.02018050402 李四 20 85.02018050403 李四 21 89.02018050404 王五 21 89.0
package com.bobo.set.map.hashmap;import java.util.Objects;/*** 学生id* 姓名* 年龄* 成绩*/
public class Student {private String id;private String name;private Integer age;private Double score;@Overridepublic String toString() {return "Student{" +"id='" + id + '\'' +", name='" + name + '\'' +", age=" + age +", score=" + score +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return Objects.equals(name, student.name) &&Objects.equals(age, student.age) &&Objects.equals(score, student.score);}@Overridepublic int hashCode() {return Objects.hash(name, age, score);}public String getId() {return id;}public void setId(String id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public Double getScore() {return score;}public void setScore(Double score) {this.score = score;}public Student(String id, String name, Integer age, Double score) {this.id = id;this.name = name;this.age = age;this.score = score;}
}package com.bobo.set.map.hashmap;import java.util.HashMap;
import java.util.Set;public class HashMapDemo01 {/*** 代码演示:使用HashMap存储学生信息(要求key存储学生的id,值存储学生的对象)* 学生id 姓名 年龄 成绩* 2018050401 张三 18 80.0* 2018050402 李四 20 85.0* 2018050403 李四 21 89.0* 2018050404 王五 21 89.0** @param args*/public static void main(String[] args) {HashMap<String,Student> map = new HashMap<>();map.put("2018050401",new Student("2018050401","张三",18,(double)80));map.put("2018050402",new Student("2018050402","李四",20,(double)85));map.put("2018050403",new Student("2018050403","李四",21,(double)89));map.put("2018050404",new Student("2018050404","王五",21,(double)89));// 获取学生编号为2018050403的学生信息System.out.println(map.get("2018050403"));System.out.println("-----------");// 通过key找值的方式Set<String> keys = map.keySet();for(String key:keys){System.out.println(key + ":" + map.get(key));}}
}package com.bobo.set.map.hashmap;import java.util.HashMap;
import java.util.Map;
import java.util.Set;public class HashMapDemo02 {/*** 代码演示:使用HashMap存储学生信息(要求key存储学生的id,值存储学生的对象)* 学生id 姓名 年龄 成绩* 2018050401 张三 18 80.0* 2018050402 李四 20 85.0* 2018050403 李四 21 89.0* 2018050404 王五 21 89.0** @param args*/public static void main(String[] args) {// 以学生对象为key 以学生编号为valueHashMap<Student,String> map = new HashMap<>();map.put(new Student("2018050401","张三",18,(double)80),"2018050401");map.put(new Student("2018050402","李四",18,(double)80),"2018050402");map.put(new Student("2018050403","李四",18,(double)80),"2018050403");map.put(new Student("2018050404","王五",18,(double)80),"2018050404");map.put(new Student("2018050405","王五",18,(double)80),"2018050405");// 遍历输出学生信息Set<Map.Entry<Student, String>> entries = map.entrySet();for(Map.Entry<Student,String> entry:entries){Student key = entry.getKey();String value = entry.getValue();System.out.println(value + ": " + key);}}
}课堂案例:使用HashMap类实例化一个Map类型的对象m1,键(String类型)和值(Integer型)分别 用于存储员工的姓名和工资,存入数据如下:
张三–800元;李四–1500元;王五–3000元;
1)将张三的工资更改为2600元
2)为所有员工工资加薪100元;
3)遍历集合中所有的员工
4)遍历集合中所有的工资
package com.bobo.set.map.hashmap;import java.util.Collection;
import java.util.HashMap;
import java.util.Set;public class HashMapDemo03 {/*** 课堂案例:使用HashMap类实例化一个Map类型的对象m1,键(String类型)和值(Integer型)分别* 用于存储员工的姓名和工资,存入数据如下:* 张三--800元;李四--1500元;王五--3000元;* 1)将张三的工资更改为2600元* 2)为所有员工工资加薪100元;* 3)遍历集合中所有的员工* 4)遍历集合中所有的工资* @param args*/public static void main(String[] args) {// 存储相关的数据HashMap<String,Integer> map = new HashMap<>();map.put("张三",800);map.put("李四",1500);map.put("王五",3000);System.out.println(map);// 1)将张三的工资更改为2600元map.put("张三",2600);System.out.println(map);// 2)为所有员工工资加薪100元;Set<String> keys = map.keySet();for (String key:keys) {// 将当前key对应的值+100Integer value = map.get(key)+100;map.put(key,value);}System.out.println(map);// 3)遍历集合中所有的员工for (String key:keys) {System.out.println(key);}// 4)遍历集合中所有的工资Collection<Integer> values = map.values();for (Integer v:values) {System.out.println(v);}}
}输出结果
{李四=1500, 张三=800, 王五=3000}
{李四=1500, 张三=2600, 王五=3000}
{李四=1600, 张三=2700, 王五=3100}
李四
张三
王五
1600
2700
3100
3.TreeMap
一个红黑树基于
NavigableMap实现。该映射根据其键的自然顺序进行排序,或者根据创建映射是提供的 Comparator进行排序
案例代码
package com.bobo.set.map.treemap;import java.util.Set;
import java.util.TreeMap;public class TreeMapDemo01 {/*** TreeMap* 底层是基于红黑树实现的 key* @param args*/public static void main(String[] args) {TreeMap<Integer,String> map = new TreeMap<>();map.put(1,"hello1");map.put(3,"hello2");map.put(2,"hello3");map.put(7,"hello4");map.put(22,"hell5");map.put(1,"hello6");map.put(25,"hello7");map.put(1,"hello8");map.put(2,"hello9");Set<Integer> integers = map.keySet();for(Integer key:integers){String value = map.get(key);System.out.println(key + "|" + value);}}
}输出结果
1|hello8
2|hello9
3|hello2
7|hello4
22|hell5
25|hello7
TreeMap的特点:
- 键是可以排序的,唯一
- 值有序,可重复
- 底层数据结构是红黑树,可排序
- 排序的方式类似于TreeSet
案例代码
package com.bobo.set.map.treemap;import java.util.Comparator;
import java.util.Set;
import java.util.TreeMap;public class TreeMapDemo02 {/*** TreeMap* key 自定义类型 我们要提供比较的方法* 要么实现Comparable接口要么提供一个* Comparator比较器* value String* @param args*/public static void main(String[] args) {TreeMap<Student,String> map = new TreeMap<Student,String>(new Comparator<Student>() {/*** 比较规则:* 先比较年龄 再比较姓名* @param o1* @param o2* @return*/@Overridepublic int compare(Student o1, Student o2) {return o1.getAge()-o2.getAge() == 0? (o1.getName().compareTo(o2.getName())): (o1.getAge()-o2.getAge());}});map.put(new Student("zhangsan",18),"19970101");map.put(new Student("lisi",18),"19970102");map.put(new Student("zhangsan",19),"19970103");map.put(new Student("zhangsan",18),"19970104");map.put(new Student("lisi",20),"19970105");map.put(new Student("zhangsan",22),"19970106");Set<Student> students = map.keySet();for(Student key:students){String value = map.get(key);System.out.println(key + " : " + value);}}
}package com.bobo.set.map.treemap;public class Student implements Comparable<Student>{private String name;private Integer age;public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}public Student(String name, Integer age) {this.name = name;this.age = age;}/*** 比较的规则* 先比较姓名* 再比较年龄* @param o* @return*/@Overridepublic int compareTo(Student o) {return this.getName().compareTo(o.getName() ) == 0? (this.getAge() - o.getAge()): this.getName().compareTo(o.getName()) ;}
}输出结果
Student{name='lisi', age=18} : 19970102
Student{name='zhangsan', age=18} : 19970104
Student{name='zhangsan', age=19} : 19970103
Student{name='lisi', age=20} : 19970105
Student{name='zhangsan', age=22} : 19970106
课堂案例:
“abcdefsassdsdfesdfasd获取字符串中字符出现的个数,希望打印的结果为: a(2)b(3)d(5)…
package com.bobo.set.map.treemap;import java.util.HashMap;
import java.util.Set;
import java.util.TreeMap;public class TreeMapDemo03 {/*** “abcdefsassdsdfesdfasd获取字符串中字符出现的个数,* 希望打印的结果为: a(2)b(3)d(5)...* 通过分析我们发现使用TreeMap解决这个问题会比较合适* @param args*/public static void main(String[] args) {String s = "abcdefsassdsdfesdfasd";// 存储数据TreeMap<Character,Integer> map = new TreeMap<>();// 将字符串转换为字符数组char[] chars = s.toCharArray();for(Character c:chars){boolean flag = map.containsKey(c);if(flag){// 存在map.put(c,map.get(c) + 1) ;}else{// 不存在map.put(c,1);}}// 希望打印的结果为: a(2)b(3)d(5)...StringBuilder sb = new StringBuilder();// 遍历TreeMap中的数据Set<Character> characters = map.keySet();for(Character key:characters){Integer value = map.get(key);sb.append(key).append("(").append(value).append(")");}System.out.println(sb.toString());}
}输出结果
a(3)b(1)c(1)d(5)e(2)f(3)s(6)
4.HashTable
此类是一个哈希表的实现,数据同步
面试题:HashMap和HashTable的区别
HashMap是不安全的不同步的效率高,允许null键和null值
HashTable是安全的同步的效率低,不允许null键和null值
特点:
- 不允许null键和null值
- 线程安全的,效率低
package com.bobo.set.map.hashtable;import java.util.Hashtable;public class HashTableDemo01 {/*** HashTable* @param args*/public static void main(String[] args) {Hashtable<String,String> map = new Hashtable<>();map.put("张三1","哈哈");map.put("张三2","哈哈");map.put("张三3","哈哈");map.put("张三4","哈哈");// map.put(null,"aaa"); null 不能作为 key值// map.put("lisi",null); null 也不能作为 value值System.out.println(map);// 独特的遍历方式Enumeration<String> keys = map.keys();while(keys.hasMoreElements()){String key = keys.nextElement();System.out.println(key+ ":" + map.get(key));}}
}{张三4=哈哈, 张三3=哈哈, 张三2=哈哈, 张三1=哈哈}
张三4:哈哈
张三3:哈哈
张三2:哈哈
张三1:哈哈
六、常用的工具类
1.Arrays
此类包含了用来操作数组的各种方法
package com.bobo.set.tools;import java.util.Arrays;
import java.util.List;public class ArraysDemo01 {/*** Arrays工具类* @param args*/public static void main(String[] args) {int[] a1 = {1,2,3,4,5,6,7,8,9};System.out.println(Arrays.binarySearch(a1,8));System.out.println(Arrays.toString(a1));// 快速将一个数组转换为List集合List<String> list = Arrays.asList("a","b","c","d");}
}2.Collections
操作集合的工具类,提供了一系列的静态方法实现了基于集合的一些常用操作
package com.bobo.set.tools;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;public class CollectionsDemo01 {/*** Collections 工具类介绍* @param args*/public static void main(String[] args) {List<String> list = Arrays.asList("ab","ba","ac","dd","ad");System.out.println(list);// 排序Collections.sort(list);System.out.println(list);// 对集合中的元素随机排列Collections.shuffle(list);System.out.println(list);// 反转,倒置的方法Collections.reverse(list);System.out.println(list);// 集合的复制List<String> list2 = new ArrayList<>();list2.add("ff");list2.add("ff");list2.add("ff");list2.add("ff");list2.add("ff");list2.add("ff");System.out.println(list2);Collections.copy(list2,list);System.out.println(list2);System.out.println(list);// 对不同步的集合进行同步处理List<String> strings = Collections.synchronizedList(list);System.out.println(strings);}
}输出结果
[ab, ba, ac, dd, ad]
[ab, ac, ad, ba, dd]
[dd, ba, ab, ad, ac]
[ac, ad, ab, ba, dd]
[ff, ff, ff, ff, ff, ff]
[ac, ad, ab, ba, dd, ff]
[ac, ad, ab, ba, dd]
[ac, ad, ab, ba, dd]
课堂小案例
有一组字符串”lili”,”meimei”,”bingbing”,”zhenzhen”,”xixi”。要求使用TreeSet存储,实现按照字母长度排序
package com.bobo.set.tools;import java.util.Comparator;
import java.util.TreeSet;public class ToolsDemo01 {/*** 有一组字符串”lili”,”meimei”,”bingbing”,”zhenzhen”,”xixi”。* 要求使用TreeSet存储,实现按照字母长度排序* @param args*/public static void main(String[] args) {TreeSet<String> set = new TreeSet<String>(new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {return (o1.length() - o2.length()) == 0 ? (o1.compareTo(o2)) : (o1.length() - o2.length());}});set.add("lili");set.add("meimei");set.add("bingbing");set.add("zhenzhen");set.add("xixi");for (String s:set) {System.out.println(s);}}
}输出结果
lili
xixi
meimei
bingbing
zhenzhen




![[C语言]典型例题:小蚂蚁爬橡皮筋、买汽水问题、导致单词块、菱形打印……](https://img-blog.csdnimg.cn/direct/559c20ed0664420cbe8d06083f39d0a0.png)