目录
- 前言
- 时间复杂度
前言
算法在运行的过程中要消耗时间资源和空间资源
所以衡量一个算法的好坏要看空间复杂度和时间复杂度,
时间复杂度衡量一个算法的运行快慢
空间复杂度是一个算法运行所需要的额外的空间
一个算法中我们更关心的是时间复杂度
时间复杂度
时间复杂度计算的不是时间,是程序的运行次数
计算时间复杂度的方法是大O的渐进表示法:
计算的是程序大概的运算次数
看影响最大的项,计算的都是N很大的情况
因为N很小CPU跑的很快,算法时间上没有差异
大O指的是函数渐进行为的数学符号
1.用常数1代表运算中所有加法常数 例如: O(1)代表常数次,不是1次,100 --> O(1)
2.保留对结果影响最大的项,保留最高阶项
3.与最高阶相乘的系数如果是常数,就去除这个常数,保留最高阶的项
时间复杂度还有平均情况,最好情况,最坏情况找到
但我们关心的是最坏情况
例如:一个数组中搜查一个数据x,最坏的情况是找n次,找到最后一个数据才找到

例如: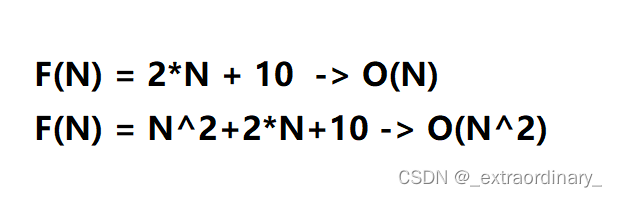 下面举几个例子:
下面举几个例子:
// 计算strchr的时间复杂度?
const char * strchr ( const char * str, int character );
strchr是在一个字符串中找一个字符
strchr的实现也比较简单
如果*str等于要找的字符就跳出来,否则++继续找
while(*str)
{if(*str == x)break;elsestr++;
}
这样时间复杂度就容易看出来了:O(n)
// 计算Func4的时间复杂度?
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++ k)
{
++count;
}
printf("%d\n", count);
}
100次为常数次O(1)
// 计算Func3的时间复杂度?
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++ k)
{
++count;
}
for (int k = 0; k < N ; ++ k)
{
++count;
}
printf("%d\n", count);
}
O(M+N) 或 O(max(M,N))
如果M远大于N,O(M)
如果N远大于M,O(N)
// 计算BubbleSort的时间复杂度?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
冒泡排序的时间复杂度:O(N^2)
N*(N-1) - >N^2
// 计算BinarySearch的时间复杂度?
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n-1;
// [begin, end]:begin和end是左闭右闭区间,因此有=号
while (begin <= end)
{
int mid = begin + ((end-begin)>>1);
if (a[mid] < x)
begin = mid+1;
else if (a[mid] > x)
end = mid-1;
else
return mid;
}
return -1;
}
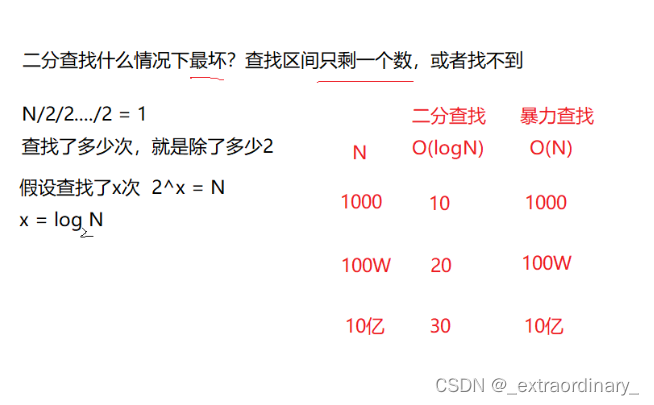
二分查找的时间复杂度:O(logN)
一直二分二分,二分到最后一个数据才找到(最坏情况)


二分查找又叫作区间查找
可以分为左闭右闭 [ ] , 左闭右开[ ) ,
左开右闭( ] ,左开右开(),下一篇博客详细介绍
二分查找的缺点:
外强中干,实际中不太使用
a.排序 (对数据进行移动)(例如快排,冒泡)
b.数组结构(不方便插入删除)
插入删除每次都要移动数据
后续我们学的二叉搜索树
红黑树,AVL树
B树系列适合求解这类问题
暴力查找:最朴素,最直接的方式求解
在N个数据中一个一个地找,最坏情况就找到最后一个数据
最后一个数据找到
或最后一个数据也找不到