- 12种算法优化TCN-BiGRU-Attention模型预测的代码。其中Attention模型可以改为单头或者多头,在代码中就是改个数字而已。代码注释已写好如何更改。

- 主要功能为:采用12种算法优化TCN-BiGRU-Attention模型的四个参数,分别是,biGRU的神经元个数,注意力机制的键值, 正则化参数。并进行了优化前后的结果比较。
- 12种算法如下:北方苍鹰算法(NGO)、蜕螂优化算法(DBO)、灰狼优化算法(GWO)、鱼鹰优化算法(OOA)、粒子群算法(PSO)、减法优化器算法(SABO)、沙猫群优化算法(SCSO)、麻雀优化算法(SSA)、白鲸优化算法(BWO)、霜冰优化算法(RIME)、鲸鱼优化算法(WOA)、哈里斯鹰优化算法(HHO)。代码中12种算法可以随意切换!
“TCN-BiGRU-Attention”模型是一种深度学习模型,主要用于时间序列预测任务。该模型结合了时间卷积网络(TCN)、双向门控循环单元(BiGRU)和注意力机制(Attention)来捕捉时间序列数据中的复杂模式和依赖关系。以下是对该模型结构的详细解释:
- 时间卷积网络(TCN):
- 功能:TCN是一种用于处理序列数据的卷积神经网络结构,它通过一维卷积操作来捕捉时间序列数据中的局部依赖关系。
- 结构:TCN通常包含多个卷积层,每个卷积层使用一维卷积核来提取时间序列数据中的特征。此外,TCN还通过引入因果卷积和扩张卷积来捕捉长期依赖关系。
- 作用:TCN从原始时间序列数据中提取有用的特征,为后续的BiGRU和注意力机制提供输入。
- 双向门控循环单元(BiGRU):
- 功能:BiGRU是循环神经网络(RNN)的一种变体,能够同时捕捉序列数据中的正向和反向依赖关系。这使得BiGRU在处理时间序列数据时具有更强的表征能力。
- 结构:BiGRU包含两个独立的GRU网络,一个用于处理正向序列,另一个用于处理反向序列。这两个网络将各自的输出合并起来,以捕捉时间序列中的长期依赖关系。
- 作用:在TCN提取的特征基础上,BiGRU进一步处理这些特征,并捕捉时间序列中的长期依赖关系。
- 注意力机制(Attention):
- 功能:注意力机制允许模型在预测时,将更多的关注力放在重要的时间步上,而忽略无关的信息。
- 工作原理:注意力机制通过对BiGRU输出的隐藏层状态参数进行重新分配权值,实现对重要时间步的关注。具体来说,注意力机制会计算一个权重向量,用于衡量每个时间步对预测结果的贡献程度。
- 作用:注意力机制能够进一步提高模型对关键时间步的关注度,从而提升预测的准确性。
- 输出层:
- 结构:输出层通常是一个全连接层,用于将模型学习到的特征映射到预测结果上。
- 功能:输出层将经过TCN、BiGRU和注意力机制处理后的特征进行整合,并输出最终的预测结果。
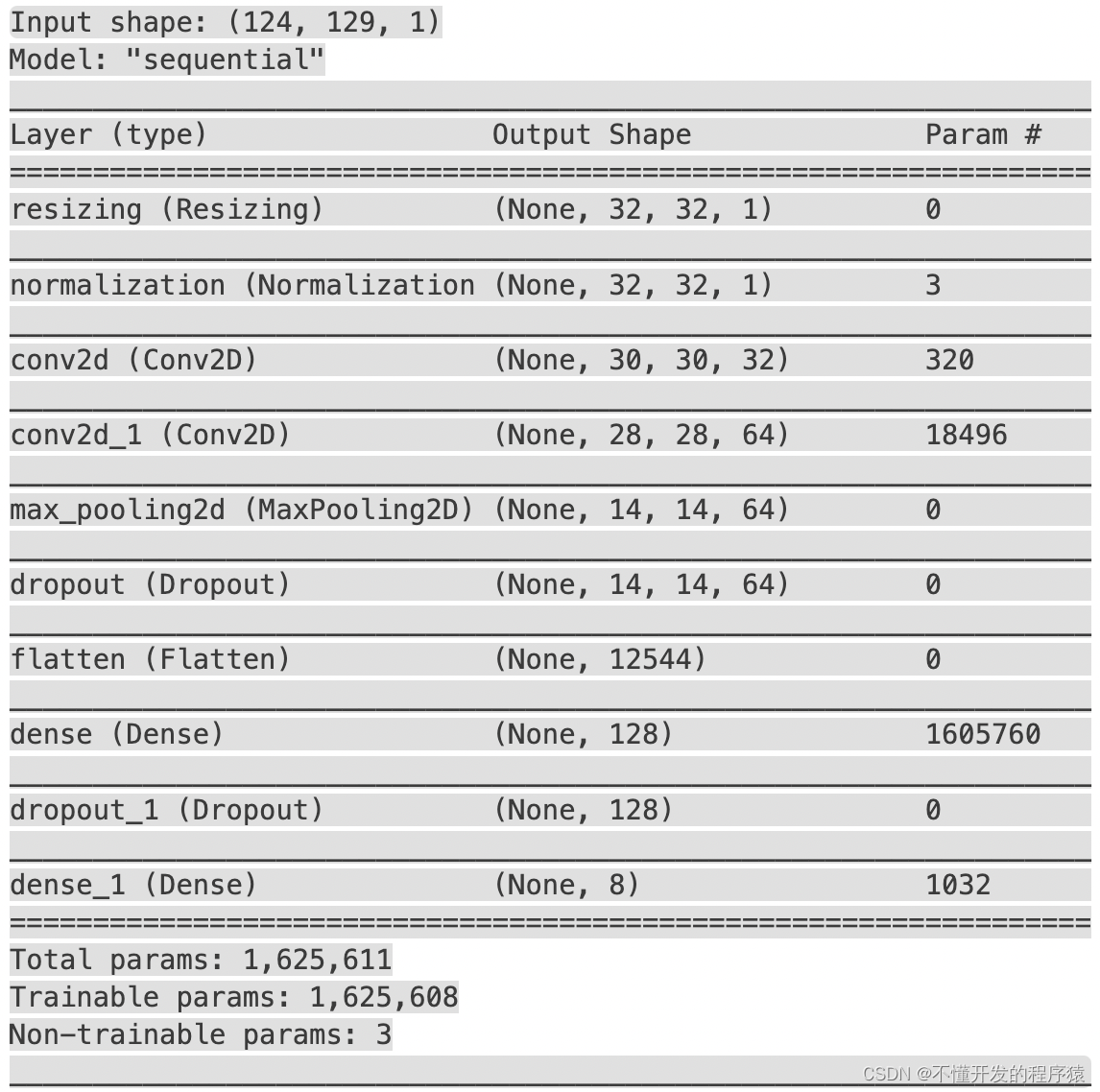
网络结构:

数据集:

以GWO优化TCN-BiGRU-Attention进行效果展示: