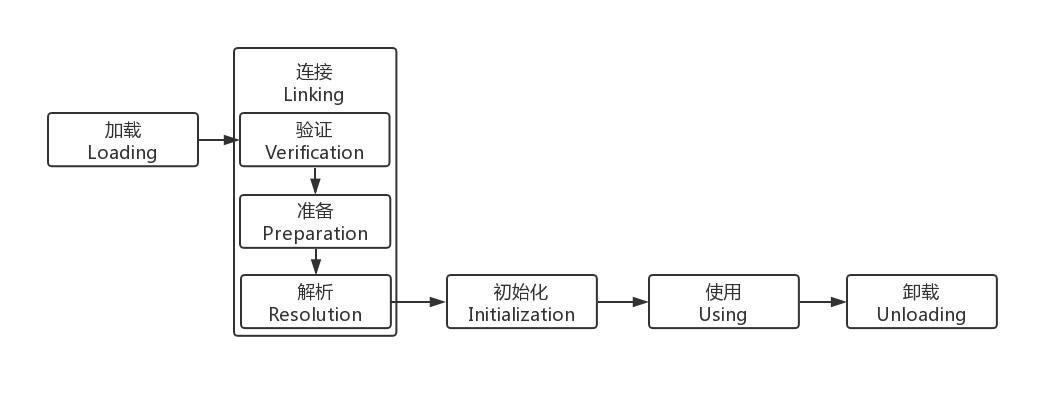
目录
一、概述
二、编程模型
2.1 High-Level Collection
2.2 Low level Interface
三、调度框架
3.1 任务图
3.2 调度
3.3 优化
3.4 动态任务图
一、概述
Dask是一个灵活的Python并行计算库。
Dask由两部分组成:
-
为计算优化的动态任务调度:和Airflow,Luigi,Celery,Make很相似,但是专门为交互式的工作负载进行了优化。
-
大数据集合:像并行数组、数据帧和列表,将NumPy、Pandas或Python迭代器等常见接口扩展到大于内存或分布式环境。这些并行集合在动态任务调度器之上运行。
Dask强调了以下特质:
-
通用:提供并行的Numpy array和Pandas DataFrame objects。
-
灵活:为更多的自定义工作负载和与其他项目的整合提供了一个任务调度接口。
-
原生:在纯Python中实现分布式计算,可以访问PyData栈。
-
快速:以低开销、低延迟和快速数字算法所需的最小序列化进行操作。
-
大规模:可以在拥有1000个内核的集群上弹性运行
-
小规模:只需要一个进程就能在笔记本电脑上设置和运行,非常简单。
-
响应性:设计时考虑到交互计算,为用户提供了快速的反馈和诊断。
二、编程模型
Dask的编程模型可以分为两大类:high level的数据集集合,和low level的接口。
High level Collection提供了3种实现:
-
Array:Dask Array使用阻塞式算法实现了NumPy ndarray接口的一个子集,将大数组切割成许多小数组。这让我们可以使用所有的内核对大于内存的数组进行计算。我们使用Dask图来协调这些分块算法。
-
Bag:Dask Bag实现了对通用Python对象集合的map、filter、fold和groupby等操作。它通过使用Python迭代器以较小的内存占用来完成这些操作。它类似于PyToolz的并行版本或PySpark RDD的Pythonic版本。
-
DataFrame:Dask DataFrame是由许多较小的Pandas DataFrame组成的大型并行DataFrame,沿着索引分割。这些Pandas DataFrame可以住在磁盘上,以便在一台机器上进行大于内存的计算,或者在集群中的许多不同机器上进行计算。一个Dask DataFrame操作会触发对组成的Pandas DataFrame的许多操作。
除此之外,Dask还允许自定义Collection,只需实现Dask为Collection所定义的接口即可。
注意,前面我们说到,大数据集合运行在动态任务调度器之上,但当前Dask默认提供的三种Collection虽然运行在动态任务调度器之上,但在调度时也对任务图做了一些封装和限制,使之更偏向于批量同步处理。其原因在于,这些默认提供的Collection的目的是为了解决分布式的大数据计算,而数据计算的特质,例如同构任务、阶段拆分等特性不需要非常灵活的动态任务调度,更偏向于一个BSP模型。但自定义的high level Collection可以打破这一约束,直接使用最底层的动态任务调度。
除了High level Collection之外,Dask也提供了low level interface,它的使用场景主要是对现有代码库进行并行化或是构建自定义算法时,可以直接使用底层灵活的动态任务调度能力,在集合的数据计算基础之上提供了更灵活的工作模式。
这两种编程模式总结如下:
-
High-Level Collection:用于分布式数据集的计算,任务依赖关系可以拆分为不同的layer,调度时的单元为layer。无法处理过于复杂的任务依赖关系和执行逻辑。适合于为算法进行数据预处理。
-
Low-Level Interface:用于代码/算法的并行化,可以直接使用任务调度,直接基于task级别进行调度。可以执行复杂的任务依赖关系和算法逻辑,适合于分布式算法的实现。可以利用Collection为算法进行数据计算。但Low-Level对丢失Collection的规范数据模型定义,需要用户自行控制计算过程中的各种数据结构。
2.1 High-Level Collection
这里我们暂不对多种High-Level Collection所提供的具体能力进行介绍,而是介绍这一类编程模型的执行时特性。
High level Collection通过编程API,可以构建Task Graph。但注意,Dask内置Collection的API无法构建出能完全和单机串行程序能做到的复杂的任务图,这样意味着,如果我们想实现一个复杂的算法,不应该完全依赖于Collection,而是将Collection作为算法的数据处理工具使用。
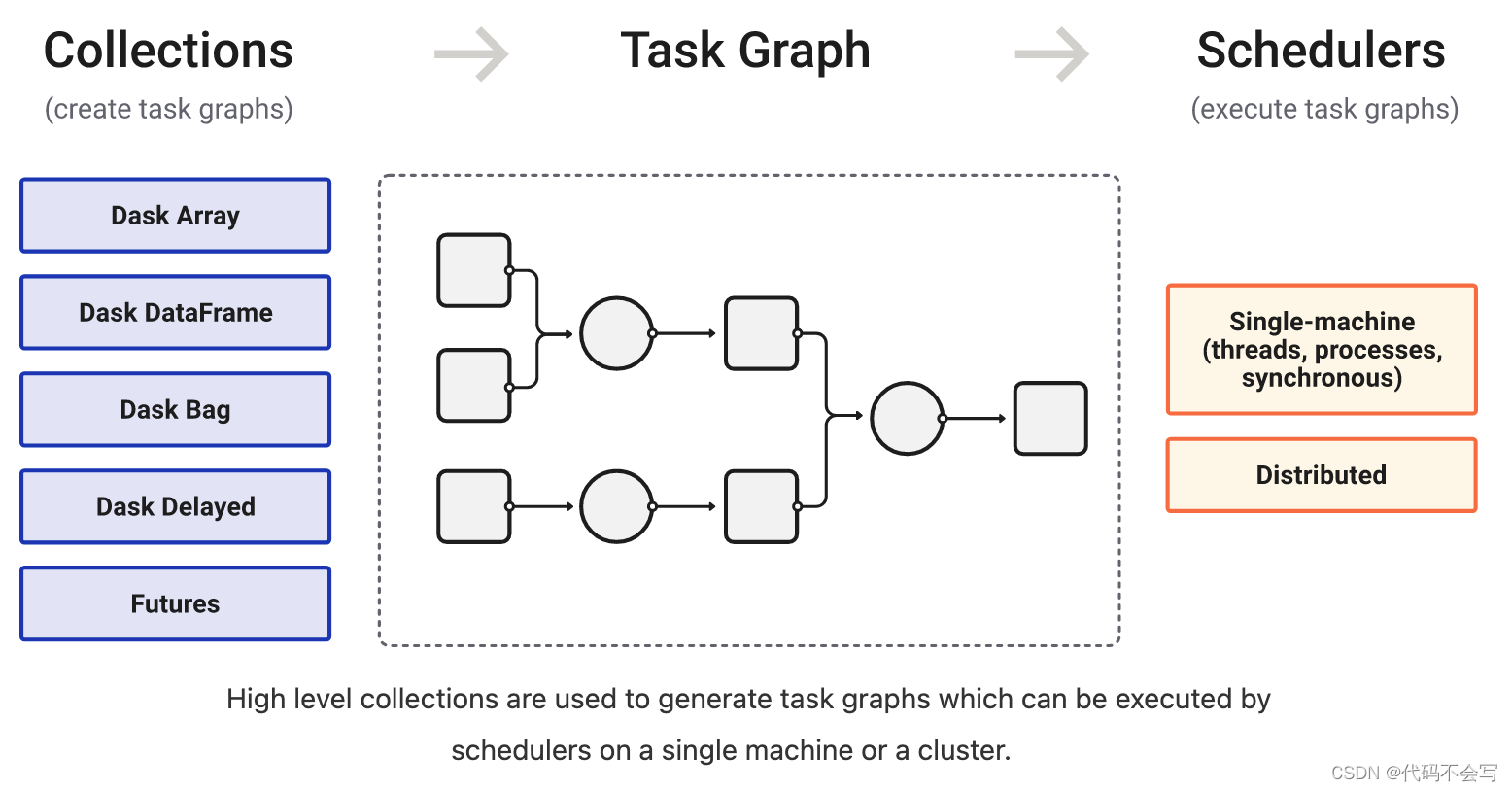
Dask内置的Collection产生任务图会被显式地编码成为HighLevelGraph对象。在大数据集进行计算时,我们可以根据数据集级别的操作将任务图进行分类,因为大数据集的每一个操作都会产生数千个任务。通过这样分类的高层次任务图结构,我们可以更容易理解执行过程,同时可以进行高层次的优化。Dask的HighLevelGraph帮助我们明确地将任务图结构进行编码,并存储在一个称之为layer的对象中,layer之间有依赖关系。如下图,我们可以发现layer的定义,和数据集级别的操作是一一对应的。
虽然Dask内置的Collection(Array、DataFrame、Bag)使用HighLevelGraph来表达集合的任务图,但是我们也可以自定义Collection,在自定义的时候使用LowLeveGraph来表达计算任务图。
2.2 Low level Interface
有时候计算问题并不适合使用dask.array或是dask.dataframe这样的集合来抽象。在这样的场景下,用户可以使用更简单的dask.delayed或是dask.futures接口来并行化自定义算法。这使得人们可以直接使用普通python代码的轻度注释来创建图形。在这种完全通用的情况下,Dask调度器预期接收的是任意的任务图,其中每个节点是一个Python函数调用,每个边是两个函数调用之间的依赖关系。
Dask Delayed和Dask Futures的主要区别如下:
-
Dask Delayed允许用户将一个独立的函数调用封装到一个延迟执行的任务图中。
-
Dask Futures则会在函数提交时立刻执行。
Delayed和Futrues作为可以直接构建低层task的low level interface,对于任务的控制可以做到更细粒度,具体的API可以参考官方文档。这里简单对典型的细粒度控制举例,如下:
-
Delayed可以为任务之间创建间接依赖,即,后一个task不依赖于前一个task的输出数据,但是依赖于前一个task的执行影响。这样的模式能更好地单机自定义算法的需求。
-
Futures提交任务时可以控制数据移动策略,gather或是scatter
-
Futures可以针对单个任务进行cancel、定义cancel时的覆盖强制策略、获取异常值、定义等待的超时时间等策略
-
Futures可以在Task内提交Task,注意,只有Futures模式才支持
-
在Task中提交Task,首先需要从Task中获取Client,再提交任务,也就是在Task中创建和集中式Scheduler再次发送控制信息的路径。
-
只有Futures才支持嵌套Task提交,即意味着嵌套Task只能eager执行。这是因为Dask是集中式调度,在Task执行时无法再次独立构建任务图,只能委托给集中调度器。
-
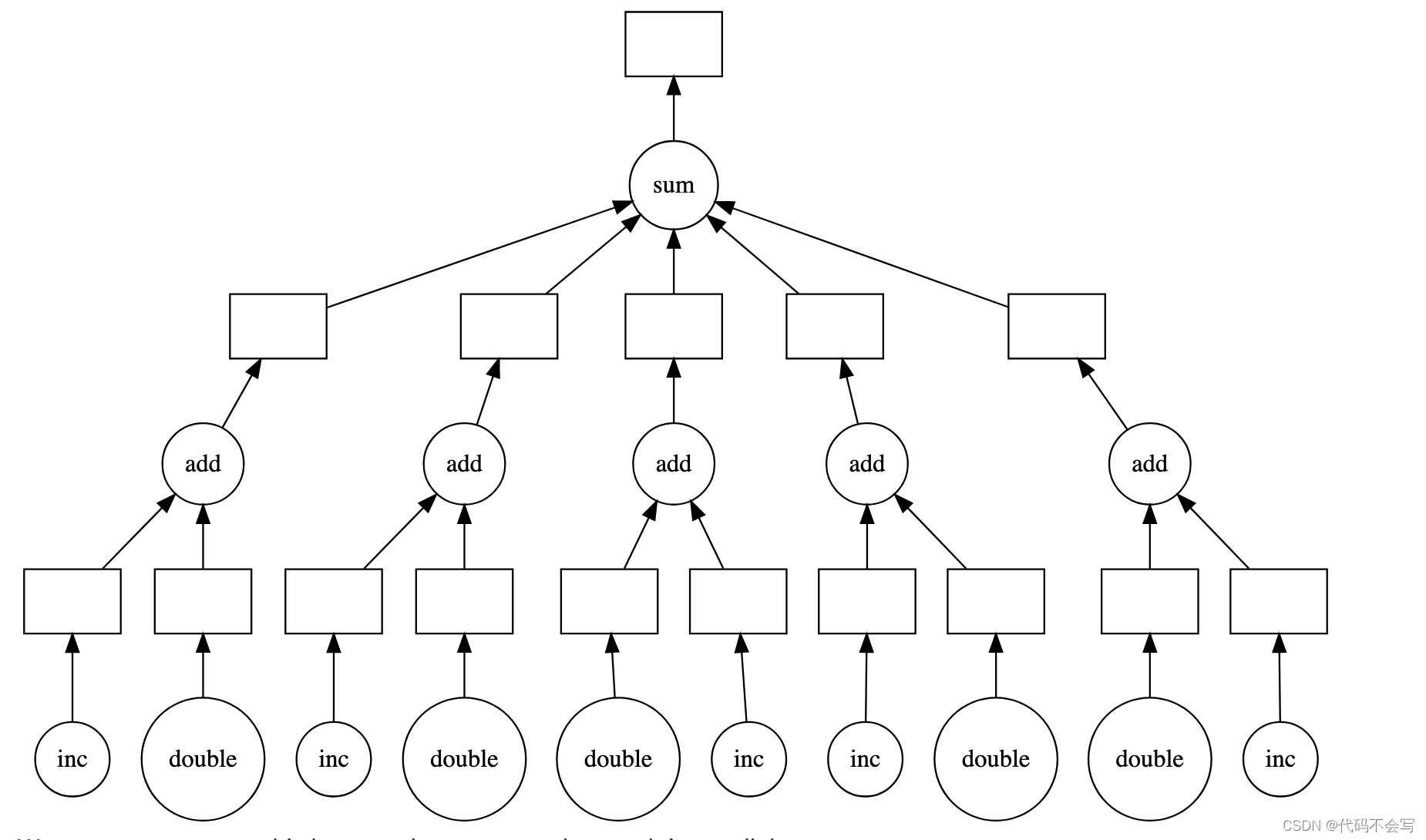
基于这样的Low Level Interface,我们就可以直接和Dask Scheduler进行交互,这样的分离机制为复杂场景提供了解决方案,允许高级的项目有更多机会来并行执行。最简单的例子如下所示,我们可以将这样一段原生的Python计算进行并行化构建和执行。从左到右分别为:原生Python计算、Dask Delayed API计算、并行执行任务图。

三、调度框架
3.1 任务图
通常情况下,人类编写程序,然后由编译器/解释器对其进行解释(例如,python、javac、clang)。有时人类不统一这些编译器/解释器选择如何解释和执行他们的程序。在这些情况下,人类经常将代码的分析、优化和执行带入代码本身。
常见的是对并行执行的渴望导致了这种从编译器到人类开发者的责任转移。在这些情况下,我们经常把程序的结构明确地表示为程序本身的数据。
在用户空间中并行执行的一个常见方法是任务调度。在任务调度中,我们把程序分成许多中等规模的任务或计算单元,通常是对非微不足道的数据进行函数调用。我们将这些任务表示为图中的节点,如果一个任务依赖于另一个任务产生的数据,则节点之间有边。我们呼吁任务调度器以尊重这些数据依赖关系的方式来执行这个图,并尽可能地利用并行性,因此多个独立的任务可以同时运行。
下图是一系列不同的的任务调度方法,包括并行、MapReduce和全任务调度。
任务调度有许多解决方案,这是并行执行框架中的一种常见方法。通常,任务调度逻辑是在框架中内置的(例如Luigi、Storm、Spark等等),因此经常需要被重新开发。而Dask是一个规范,它用所有Python项目的通用术语,即dicts、tuples和callables,以最小的附带复杂性编码了完整的任务调度。理想情况下,这种最小的解决方案很容易被广泛的社区采用和理解。
一个Dask graph是由一个将key映射到计算的字典组成的,如下:
一个key可以是任何的hash值,它不代表一个task
一个task是一个元组,它的一个元素一定是一个可调用对象,后面的元素是可调用对象的参数,一个参数可以是任意有效的computation。task代表了由单个worker节点运行的原子级工作单位。
一个computation可以是以下任一种:
-
Dask graph中的任意key,例如'x'
-
任意其他值,例如1,按字面意思解释
-
一个任务,例如(inc, 'x')
-
一个computation列表,例如[1, 'x', (inc, 'x')]
任务图的抽象同时支持了编程模型的High level Collection和Low level Interface,只是Collection的操作因为更具有业务特殊性,因此抽象了HighLevelGraph,即在原子的task之上抽象出layer的概念来执行。Low level Interface则是直接和原子的task graph进行交互。
3.2 调度
在Dask生成这些任务图之后,它需要在并行硬件上执行它们。这就是任务调度器的工作。存在不同的任务调度器,每个调度器都会消耗一个任务图并计算相同的结果,但性能特征不同。
Dask有两种常见的task schduler:
-
Single-machine scheduler:在本地进程或是线程池之上提供基础特性。
-
Distributed Scheduler:更复杂,提供了更多特性,需要初始搭建。它可以本地运行或是在一个集群内运行。
调度器可以选择多种不同的策略,例如优先级策略等,具体信息可参考官方文档,这里不做详细说明。
3.3 优化
在不同的情况下,通过在调用调度器之前对Dask graph进行小的优化,可以显著提高性能。
一般来说,进行graph优化时有两个目标:
-
简化计算:简化计算可以在graph层面上通过移除不必要的任务(cull)来完成,也可以在task层面上通过用便宜的操作替换昂贵的操作(RewriteRule)来完成。
-
提高并行性:并行性可以通过减少任务间的通信来改善,无论是通过将许多任务融合成一个任务(fuse),还是通过内联廉价操作(inline,inline_functions)。
对于每一种Collection,Dask定义了一个默认的优化策略,同时也支持用户自定义。如果想要自定义task graph,可以直接使用优化函数:cull/ inline/ inline_functions/ fuse。也可以自定义优化函数,替换默认的,一个优化函数接收一个任务图和所需键的列表,并返回一个新的任务图。
3.4 动态任务图
动态任务是常规任务,它们被优化、调度,并作为常规任务在工作者上执行。只有当它们使用检查点时才会有所不同。下面是一个正在运行的任务调用检查点时的逻辑流程。
-
一个运行在一个worker节点上的task发送一个task update消息给scheduler,其中包含。(下面的key可以理解为一个graph中的任务标识,可能还没运行起来)
-
当前在worker内存中的新key
-
task当前依赖的新key
-
task不再依赖的现有key
-
取代当前任务的新任务(函数&key/ 文本参数)
-
-
scheduler会更新相关的任务状态,并释放不再依赖的key
-
如果所有依赖都满足了,那么该任务可以从新状态中重新调度。如果没有,则会转入waiting 状态
这里需要注意的一点,动态任务,即在任务中,通过获取Client,再次提交一个Task,如下。