✨✨欢迎👍👍点赞☕️☕️收藏✍✍评论
个人主页:秋邱'博客
所属栏目:C语言


前言
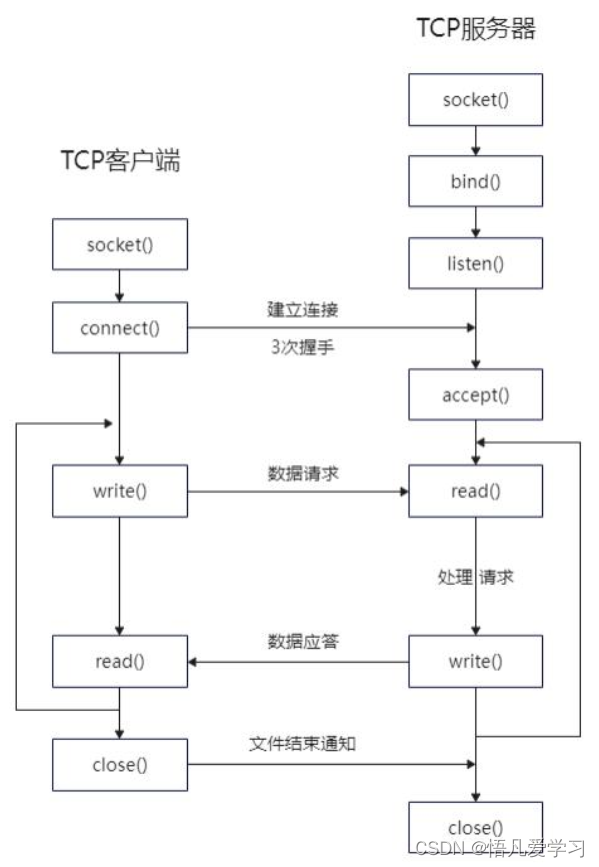
内存函数不止malloc、calloc、realloc、free还有memcpy、memmove、memset、memcmp。前四个的头文件是<stdlib.h>,后四个的头文件是<string.h>。
1.0 memcpy()
函数声明:
void * memcpy ( void * destination, const void * source, size_t num );destination:指向要复制内容的目标数组的指针,类型转换为void*类型的指针。
source:指向被复制的目标数组的指针,类型转换为const void*类型的指针。(const指针内容不能被修改)
num:字节个数。
返回值:返回一个类型的指针。
注意:
- 函数memcpy从source的位置开始向后复制num个字节的数据到destination指向的内存位置。
- 这个函数在遇到 '\0' 的时候并不会停下来。
- 如果source和destination有任何的重叠,复制的结果都是未定义的。
1.1 函数使用
int main()
{int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };int arr2[20] = { 0 };int num = sizeof(arr1) / sizeof(arr1[0]);MyMemcpy(arr1, arr2, num * sizeof(int));for (int i = 0; i < num; i++){printf("%d ", arr2[i]);}return 0;
}打印结果:

1.2 模拟实现
前面对memcpy进行了使用,发现memcpy就是将原内存拷贝到目标内存去的一个函数。
这里用void*来接收指针的地址,因为并不清楚传入函数的是声明类型,所以用void*来接收(void*可以接收任意类型)
#include<stdio.h>
void* my_memcopy(void* dest,const void* src, size_t num)
//const这里是拷贝,只需要原地址空间的数据,并不需要修改
{void* ret = dest;while (num--){*(char*)src = *(char*)dest;//将原地址的数据放入目的地址src = (char*)src + 1;//对src和dest为(char*)+1跳过一个字节dest = (char*)dest + 1;}return ret;
}
int main()
{int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };int arr2[20] = { 0 };int num = sizeof(arr1) / sizeof(arr1[0]);my_memcopy(arr1, arr2, num * sizeof(int));for (int i = 0; i < num; i++){printf("%d ", arr2[i]);}return 0;
}分析:
dest和src均为void*类型,在解引用需要将它们转化为(char*),因为在函数拷贝过程中,并不清楚传入的是int*还是char*等类型,这就需要char*一个一个字节的搬运。
强制类型转换只是临时的,下一次的使用还是原来的类型,也就是dest和src下一次使用还是void*的类型。src = (char*)src + 1将src强换为(char*)赋给src。
开辟一个void*的函数,来存dest的初始地址,最后返回。
对于重叠的内存,交给memmove来处理。
2.0 memmove()
memmove的destination和source相同的
函数声明:
void * memmove ( void * destination, const void * source, size_t num );destination:指向要复制内容的目标数组的指针,类型转换为void*类型的指针。
source:指向被复制的目标数组的指针,类型转换为const void*类型的指针。(const指针内容不能被修改)
num:字节个数。
返回值:返回一个类型的指针。
2.1 函数使用
int main()
{int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };//代码1memmove(arr+2, arr, sizeof(int)*5);//代码2memmove(arr, arr+2, sizeof(int)*5);for (int i = 0; i < 10; i++){printf("%d ", arr[i]);}return 0;
}
打印结果:
代码1
代码2

可以看到,代码1和代码2的打印结果不同,这跟dest在前还是在后有关系,到模拟实现的时候就要分情况来讨论。
2.2 模拟实现
2.2.1 分析
2.2.1.1 dest在前,src在后,且有重叠(dest < src)
前向后遍历:3 4 5 6 7 6 7 8 9 10 √
后向前遍历:7 6 7 6 7 6 7 8 9 10 ×
很明显,从前向后遍历才是正确的。
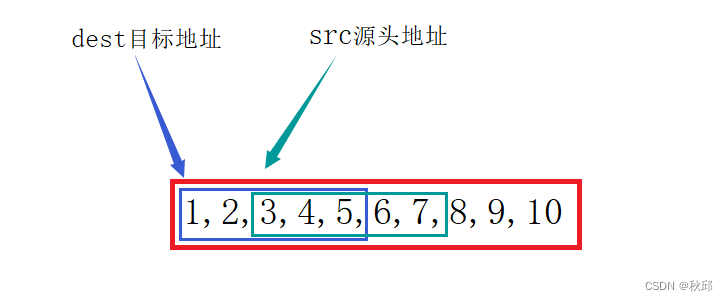
2.2.1.2 src在前,dest在后,且有重叠(dest > src)
前向后遍历:1 2 1 2 1 2 1 8 9 10 ×
后向前遍历:1 2 1 2 3 4 5 8 9 10 √
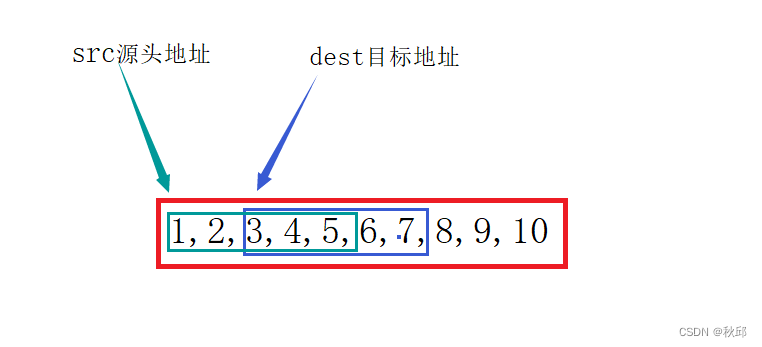
2.2.1.3 无重叠
前向后遍历=后向前遍历:1 2 3 4 5 1 2 3 4 5
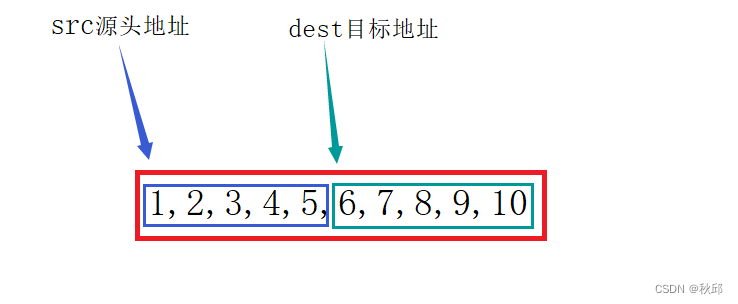
前向后遍历=后向前遍历:5 6 7 8 9 10 5 6 7 8 9 10

使用第三种情况已经被第一二种情况包括了,就不需要拿出来分析了。 只需要讨论前两种就行了。
void* my_memmove(void* dest, const void* src, size_t num)
{void* ret = dest;if (dest < src)//dest在前,src在后{while(num--){*(char*)dest = *(char*)src;dest = (char*)dest + 1;src = (char*)src + 1;}}else{//src在前,dest在后dest = (char*)dest + num-1;src = (char*)src + num-1;while (num--){*(char*)dest = *(char*)src;dest = (char*)dest - 1;//指向末尾src = (char*)src - 1;//指向末尾}}return ret;
}
int main()
{int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };my_memmove(arr+2, arr, sizeof(int)*5);for (int i = 0; i < 10; i++){printf("%d ", arr[i]);}return 0;
}dest在前,src在后,且有重叠(dest < src)这个情况跟memcpy的写法一样,只需用if判断dest是否小于src即可。else里只需要将,src里的数据一个字节一个字节的放进dest就可以了。
3.0 memset()
函数声明:
void * memset ( void * ptr, int value, size_t num )ptr:指向需要被放置的指针。
value:该值作为int类型传递,但函数使用该值的unsigned char转换来填充内存块。
num:字节个数。
返回值:返回一个类型的指针。
3.1 函数使用
int main()
{char ptr[] = "hello world";memset(ptr, 'x', 6);printf("%s", ptr);return 0;
}
打印结果:

3.2 模拟实现
void* my_memset(void* ptr, int value, size_t num)
{void* ret = ptr;//while(num--)//{// *(char*)ptr = (char)value;// ptr = (char*)ptr + 1;//}for (int i = 0; i < num; i++){*(char*)ptr = (char)value;ptr = (char*)ptr + 1;}return ret;
}
int main()
{char ptr[] = "hello world";my_memset(ptr, 'x', 6);printf("%s", ptr);return 0;
}
分析: 这个函数的实现比较简单,给定一个指针ptr开始,逐个字节地将值(char*)value设置到后续的内存位置,循环执行num次。
4.0 memcmp()
函数声明:
int memcmp ( const void * ptr1, const void * ptr2, size_t num );ptr1:指向内存块的指针。
ptr2:指向内存块的指针。
num:字节个数。
返回值:
返回值 意思(如果作为unsigned char值计算) <0 ptr1的值小于ptr2的值 =0 ptr1的值等于ptr2的值 >0 ptr1的值大于ptr2的值
4.1 模拟实现
int memcmp(const void* ptr1, const void* ptr2, size_t num)
{if (*(char*)ptr1 > *(char*)ptr2)return 1;else if (*(char*)ptr1 < *(char*)ptr2)return -1;else{ptr1 = *(char*)ptr1 + 1;ptr2 = *(char*)ptr2 + 1;}return 0;
}
int main()
{char arr1[] = "Hello Qiu";char arr2[] = "Hello qiu";int ret = memcmp(arr1, arr2, sizeof(arr1));if (ret > 0)printf("'%s' is greater than '%s'.\n", arr1, arr2);else if (ret < 0)printf("'%s' is less than '%s'.\n", arr1, arr2);elseprintf("'%s' is the same as '%s'.\n", arr1, arr2);return 0;
}将传入的指向用void*接收,ptr1和ptr2一个字节一个字节的进行比较,若ptr1大,则返回大于0的值;ptr1相等ptr2,且*ptr1+1、*ptr2+1直到全部比完相同,返回0;ptr2大,返回小于0的值。
感谢各位大佬莅临,如有错误欢迎指出,共同学习进步。