List是Redis中的列表,按照插入顺序保存数据,插入顺序是什么样的,数据就怎么保存。可以添加一个元素到列表的头部(左边)或者尾部(右边)。一个列表最多可以包含232-1个元素(4294967295,每个列表超过40亿个元素)。是一种双向列表结构。
1、List列表命令
- blpop key1[key2…] timeout:从头部(左边)移出并获取一个元素,如果列表没有元素会阻塞到列表有元素或者超时。
- brpop key1[key2…] timeout:从尾部(右边)移出并获取一个元素,如果列表没有元素会阻塞到列表有元素或者超时。
- brpoplpush source destination timeout:从尾部(右边)移出一个元素,并添加到另一个列表的头部并返回。如果列表没有元素会阻塞到列表有元素或者超时。
- lindex key index:通过索引(下标)获取列表中的元素。index可以为负,-1表示最后一个元素,-2表示倒数第二个元素。以此类推
- linsert key before|after pivot value:将值value插入到列表key中,位于pivot之前或者之后。
当指定的元素不在列表或者列表为空时不执行任何操作,如果key不是列表类型,则返回一个错误
- llen key:获取列表的长度
- lpop key:从列表的头部(左边)移出并获取列表一个元素。如果列表没有元素,不会阻塞。
- lpush key value1[value2]:将一个或者多个值插入到列表头部(左边)。多个元素一起插入时,后面的头部。
如果插入的key不存在,将创建一个空的列表,并执行lpush操作。当key不是列表类型时,会报错。
- lpushx key value:将一个值插入到列表的头部(左边),当列表不存在时操作无效。
- lrange key start end:返回列表中指定区间的元素,从0开始,当end为-1时表示到最后一个元素,-2为倒数第二个元素。
- lren key count value:移出列表中值和value相等的值。
count的值有如下几种情况:
- count>0:从列表的头部(左)到尾部(右)搜索,移出值与value相等的元素,数量为count。
- count<0:从列表的尾部(右)到头部(做)搜索,移出值与value相等的元素,数量为count的绝对值。
- count=0:移出列表中所有与value相等的元素。
- lset key index value:通过索引(下标)设置元素的值。当下标超出范围(超过列表的已有数量)或者列表为空,进行lset操作会报错。
- ltrim key start end:对一个列表进行修剪,让列表只存在指定区间内的元素,以外的全删除。0表示第一个元素,1表示第二个,-1表示最后一个,-2表示倒数第二个。以此类推。
- rpop key:移出列表的最后一个元素(最右边)。不会阻塞。
- rpoplpush source destination:移出source列表的最后一个元素,插入到destination的头部,并返回。
- rpush key value1[value2]:在列表尾部添加一个或者多个元素。后边的在最后。
- roushx key value:将值添加到已存在列表的尾部。
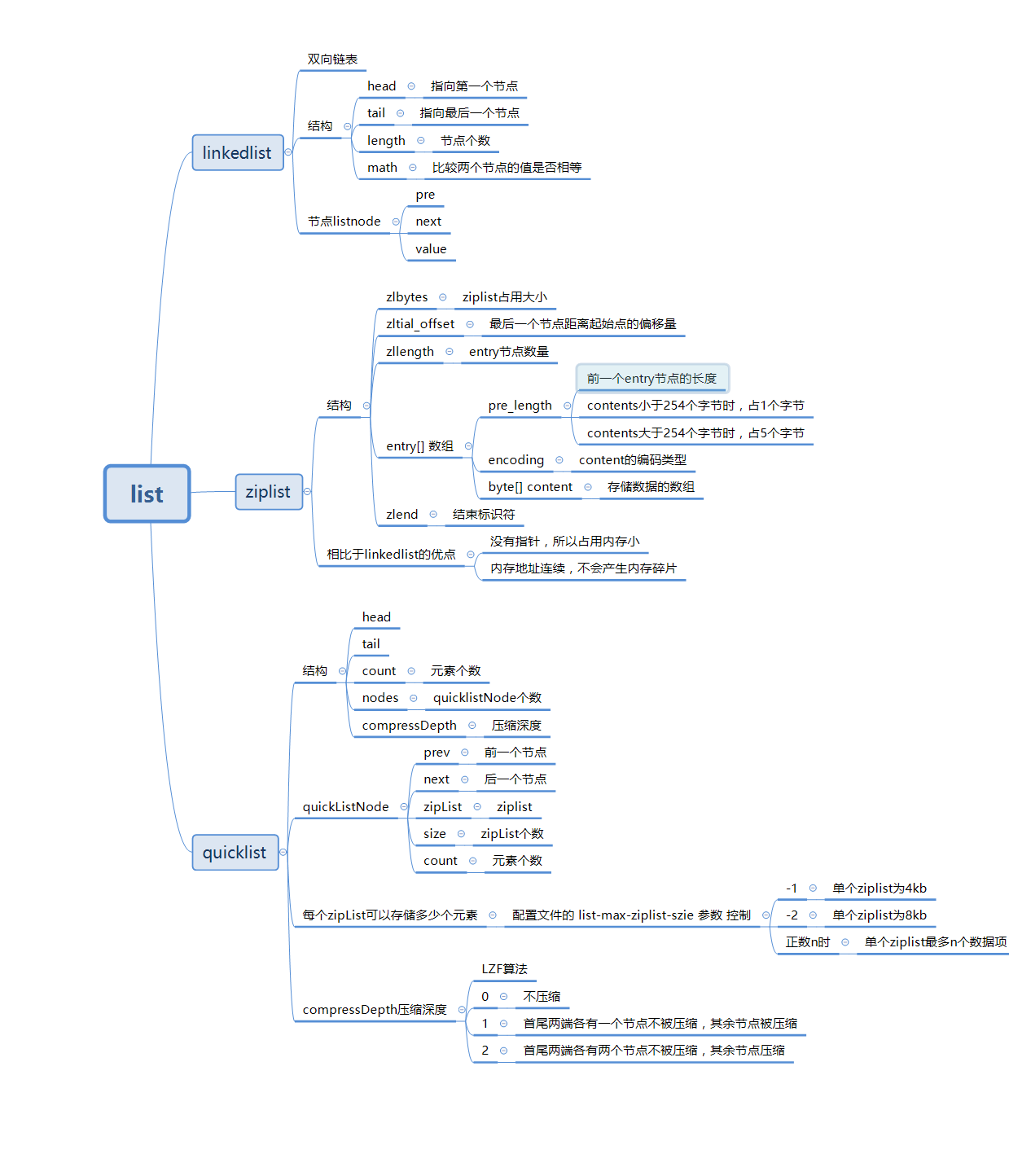
2、底层结构
2.1、linkedList
与Java中的LinkedList类似,Redis中的linkedList是一个双向链表,也是由一个个的节点组成。Redis借助c语言的链表节点结构如下:
typedf struct listNode{//前一个节点struct listNode *prev;//后一个节点struct listNode *next;//当前节点的值的指针void *value;
}listNode;
prev指向前一个节点,next指向下一个节点,value保存着当前节点对应的数据对象。listNode结构示意图如下:
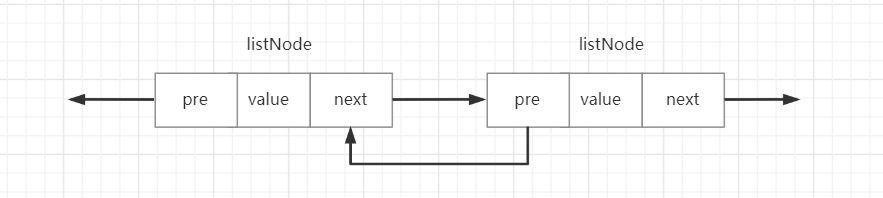
链表的结构如下:
typedf struct list{//头指针listNode *head;//尾指针listNode *tail;//节点拷贝函数void *(*dup)(void *ptr);//释放节点函数void *(*free)(void *ptr);//判断两个节点是否相等函数int (*match)(void *ptr,void *key);//链表长度unsigned long len;
}list;
head指向链表的头结点,tail指向链表的尾节点。len表示链表有多少个节点,这样可以在O(1)的时间复杂度内获得链表的长度。
链表的结构示意图如下:
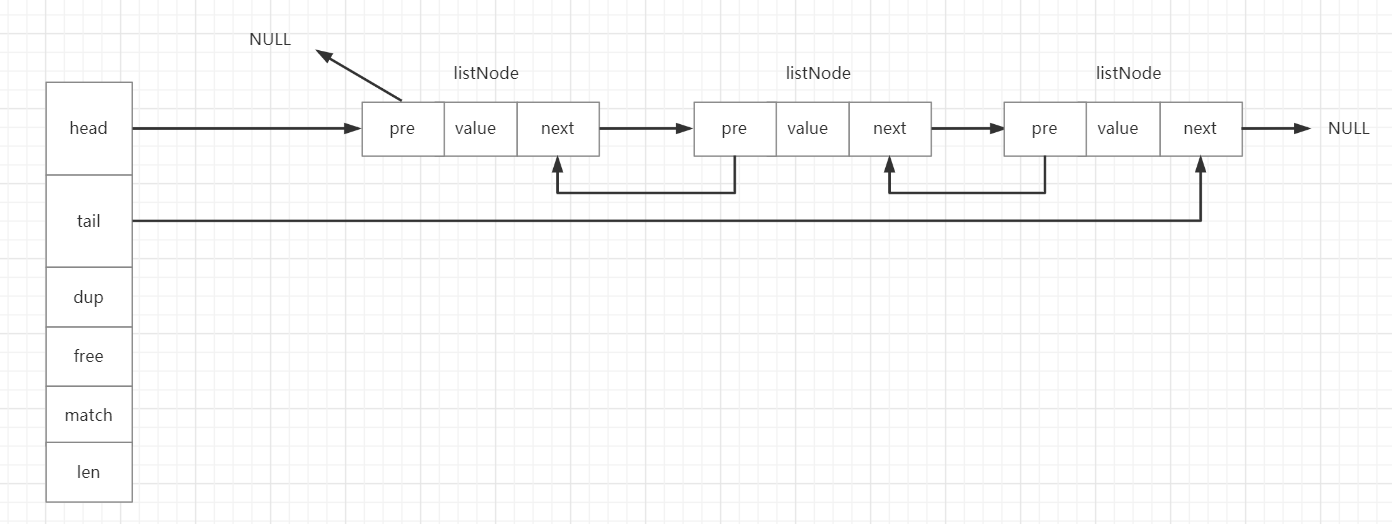
2.2、zipList
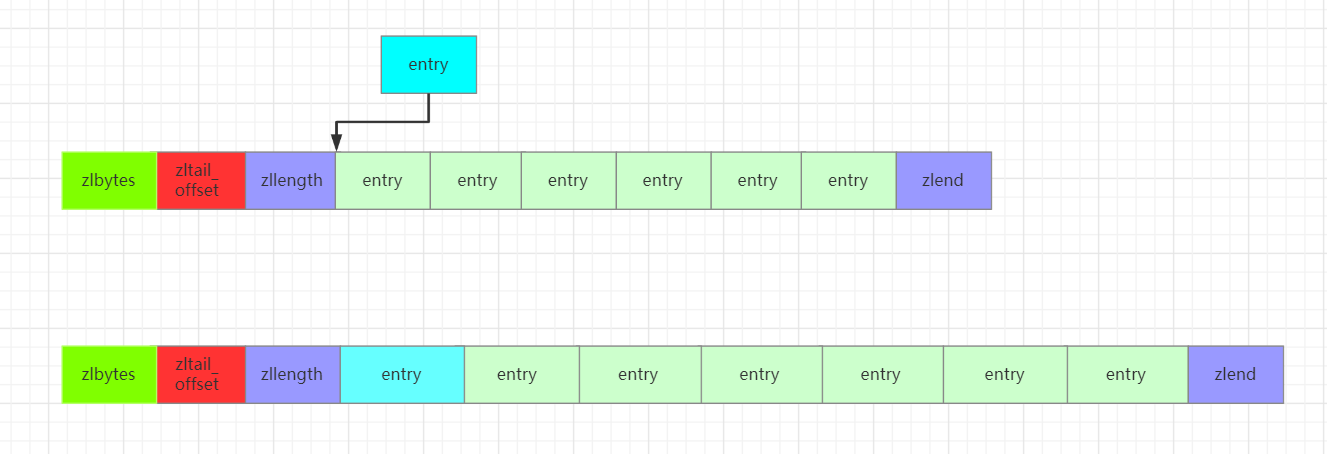
Redis的zipList结构如下:
typedf struct ziplist<T>{//压缩列表占用字符数int32 zlbytes;//最后一个元素距离起始位置的偏移量,用于快速定位最后一个节点int32 zltail_offset;//元素个数int16 zllength;//元素内容T[] entries;//结束位 0xFFint8 zlend;
}ziplist
zipList结构示意图如下:
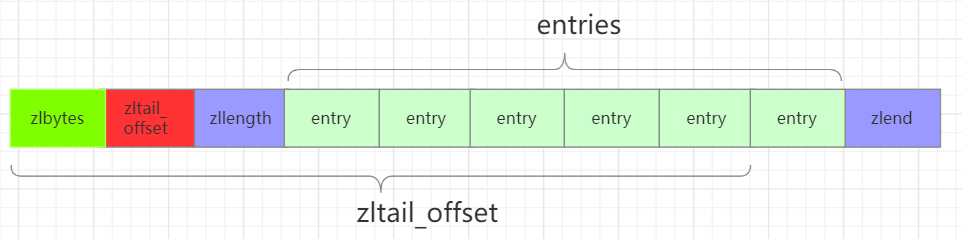
根据zltail_offset字段就可以快速定位到最后一个entry的位置,这样配合Entry结构中的prelen字段,就可以实现链表的倒序遍历。
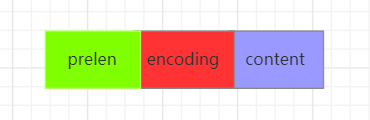
下面是entry的结构:
typed struct entry{//前一个entry的长度int<var> prelen;//元素编码类型int<var> encoding;//元素内容optional byte[] content;
}entry
prelen保存了前一个entry的长度,这样就可以在倒序遍历时就可以根据此字段来获取到前一个entry的位置。encoding保存了content内容的编码类型。content是保存的内容,其类型是optional,表示这个字段是可选的。当content是很小的整数时,他会内连到content的尾部。entry结构示意图如下:
思考题:为什么有了**linkedList**还要设计一个**zipList**呢?
- 就像
zipList的名字一样,他是一个压缩列表,相比较于linkedList,其少了pre和next两个指针。Redis中两个指针就要占用16个字节(64位操作系统的一个指针就是8字节)。 linkedList每个节点的内存都是单独分配,加速了内存的碎片化,影响内存的管理。zipList的内存都是连续组成的,这样一来,由于内存是连续就减少了许多内存的碎片化和指针的内存占用。
zipList遍历时,先根据zlbytes和zltail_offset定位到最后一个entry的位置,然后根据最后一个entry的prelen确定前一个entry的位置。
连锁更新
前面说到,Entry结构中有个prelen字段,表示其前一个entry的长度,他的长度要么是1个字节,要么是5个字节:
- 前一个
entry的长度小于254字节,则prelen的长度为1字节(8位,最大可表示255); - 前一个
entry的长度大于254字节,则prelen的长度为5字节;
假设有一组压缩列表的长度都在250~253之间,突然增加一个entry长度大于254字节。由于新的entry的长度大于254字节,那么原链表的首节点的prelen的长度就会为5个字节,随后会导致其他的所有entry的prelen都增大为5个字节,每次prelen的增大,都需要一次内存的再分配操作。
linkedList和zipList的对比
- 当列表的长度或者数量较少时,通常采用
zipList,当列表的长度较大或者数量较多时,通常采用linkedList存储。 - 双向链表
linkedList方便与在列表上增加或者删除操作,也即push和pop操作。但是其内存的开销比较大。一方面其比zipList多了两个指针。且其每个节点的内存都是独立的,地址不连续,容易形成内存碎片。 zipList存储在一块连续的内存上,其查询速度较快,但是不利于修改操作,插入和删除操作需要频繁的申请和释放内存。特别是当zipList很大时,一次realloc可能会导致大量的拷贝。
2.3、quickList
在Redis3.2版本后,list的底层实现又多了一种,quickList。quickList是zipList和linkedList的混合体,它将linkedList按段切分,每一段使用zipList来存储数据。每个quickList之间用双向指针串接起来。示意图如下:
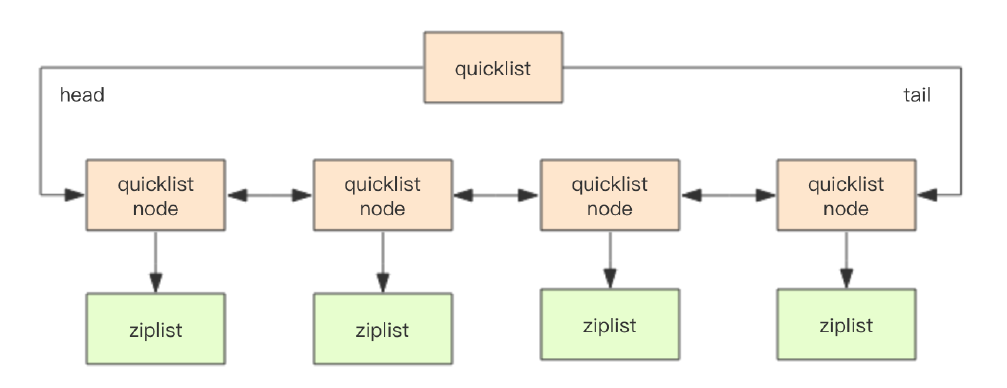
节点quickList结构如下:
typedf struct quicklistNode{//前一个节点quicklistNode *prev;//后一个节点quicklistNode *next;//压缩列表ziplist* zl;//ziplist大小int32 size;//ziplist中元素数量int16 count;//编码形式 存储ziplist还是LZF压缩存的ziplistint2 encoding;...
}quicklistNode;
quickList的结构如下:
typedf struct quicklist{//头节点quicklistNode* head;//尾节点quicklistNode* tail;//元素总数long count;//quicklistNode节点总数int nodes;//压缩深度算法int compressDepth;...
}quicklist;
为了进一步节约空间,Redis还会对ziplist进行压缩存储,使用LZF算法进行压缩,可以选择压缩深度。
每个zipList可以存储元素的个数
Redis.conf文件,在DVANCE CONFIG下面有着清晰记载:
# Lists are also encoded in a special way to save a lot of space.
# The number of entries allowed per internal list node can be specified
# as a fixed maximum size or a maximum number of elements.
# For a fixed maximum size, use -5 through -1, meaning:
# -5: max size: 64 Kb <-- not recommended for normal workloads
# -4: max size: 32 Kb <-- not recommended
# -3: max size: 16 Kb <-- probably not recommended
# -2: max size: 8 Kb <-- good
# -1: max size: 4 Kb <-- good
# Positive numbers mean store up to _exactly_ that number of elements
# per list node.
# The highest performing option is usually -2 (8 Kb size) or -1 (4 Kb size),
# but if your use case is unique, adjust the settings as necessary.
list-max-ziplist-size -2
quicklist内部默认单个ziplist的长度为8K字节,即list-max-ziplist-size的值设置为-2,超出这个阈值,就会重新生成一个新的ziplist来存储数据。根据注释可知,性能最好的时候就是list-max-ziplist-size为-1和-2时,即分别是4Kb和8Kb。当然这个值也可以是正数,当值为正数n时,表示每个quicklist上的ziplist最多包含n个数据项。
压缩深度
在quickList中可以使用压缩算法对zipList进行进一步的压缩,这个算法就是LZF算法,这是一种无损压缩算法。使用压缩算法对zipList进行压缩后,zipList结构如下:
typedf struct zoplist_compressed{//元素个数int32 size;//元素内容byte[] compressed_data;
}
压缩后的quickList结构如下:
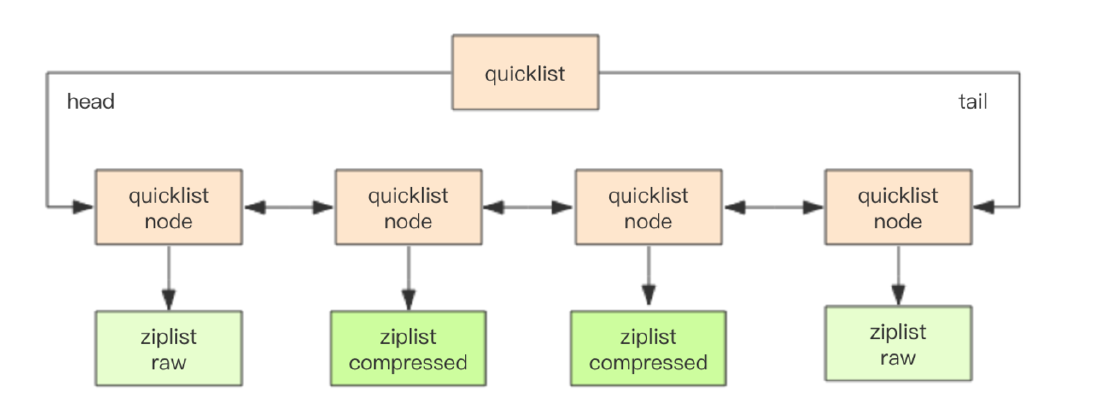
在Redis.conf配置文件中对其进行配置
# Lists may also be compressed.
# Compress depth is the number of quicklist ziplist nodes from *each* side of
# the list to *exclude* from compression. The head and tail of the list
# are always uncompressed for fast push/pop operations. Settings are:
# 0: disable all list compression
# 1: depth 1 means "don't start compressing until after 1 node into the list,
# going from either the head or tail"
# So: [head]->node->node->...->node->[tail]
# [head], [tail] will always be uncompressed; inner nodes will compress.
# 2: [head]->[next]->node->node->...->node->[prev]->[tail]
# 2 here means: don't compress head or head->next or tail->prev or tail,
# but compress all nodes between them.
# 3: [head]->[next]->[next]->node->node->...->node->[prev]->[prev]->[tail]
# etc.
list-compress-depth 0
list-compress-depth这个参数表示一quickList**两端不被压缩的节点个数,**实际上这里的节点个数指的是quickList的节点个数,而不是zipList里面的数据项个数。
quickList默认的压缩深度为0,也就是不开启压缩。- 当
list-compress-depth为1时,表示首尾各有一个节点不进行压缩,中间节点进行压缩。 - 当
list-compress-depth为2时,表示首尾各有两个节点不行压缩,中间节点进行压缩。 - 以此类推。
从上面可以看到quickList的首尾两个节点永远不会被压缩。
3、总结