在我们的项目中,我们研究了数百万级 3D 点云上的空间局部计算,并提出了两种主要方法,可以提高 GPU 的速度/吞吐量,同时保持最终结果的性能准确性。
通过空间局部,我们的意思是每个像素独立地基于其局部邻域中的点执行计算。我们想在这里强调两个主要贡献。首先,我们展示了近似局部邻域到 CUDA 线程块的映射,以在保持准确性的同时加速 GPU 吞吐量。其次,我们实现了本文提出的轮廓保留重采样器的快速并行版本,以对点云进行二次采样(仅保留 5% 的点效果很好!),同时保留重要特征。这有助于减轻高冗余的成本,同时仍然保持输出精度。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
具体来说,我们选择研究分割的关键问题,这是许多计算机视觉应用程序流程中的重要一步。即,将点云“聚类”成多个同质区域,同一区域内的点将具有相同的属性。这个问题在机器人技术中有很多应用,如智能车辆、自主测绘、导航、家务劳动等。点云是一个特殊的挑战,因为它们通常具有不均匀的点密度、高冗余,并且含有许多异常值。
由于尚不清楚评估分割的最佳“指标”是什么,因此我们构建了一个简单的对象检测器(通过计算特征并在预先计算的对象特征数据库中查找最近邻居)。在较高的层面上,如果它能够可靠地检测我们训练过的对象,我们就说分割质量很好。我们想在这里强调,对象检测不是我们项目的主要焦点。相反,我们展示了如何在 GPU 上快速处理点云数据。
我们主要使用 RGB-D 对象数据库,其中包含具有如下所示对象的场景点云以及我们用来训练特征的对象本身的模型(使用点云库):

1、设计方案A

初步设计的框图如上。我们使用快速移位算法来执行图像分割。由于其计算特性和内存访问模式,它适合并行性,如下所述:
1.1 快速移位细分
快速移位分割(fast shift segmentation)分两步进行,它首先计算局部密度估计,然后将父节点分配给每个节点。这两个步骤都是空间局部的,因为每个点都通过迭代其局部邻域来执行计算。我们选择邻域大小不仅是为了确保准确性,也是为了控制分割的粒度。
function compute_density() {for each point p in pointcloud:for each neighbor x in neighborhood(p):density[p] += dist_estimate(p,x);endend
}function construct_tree(){for each point p in pointcloud:for each neighbor x in neighborhood(p):if(density[x] > density[p] && dist(x,p) < min_dist)parents[p] = x;min_dist = dist(x,p)endend
}1.2 实现细节
第一个贡献是利用计算的空间局部特征来体素化点云并将每个体素映射到 CUDA 线程块。这样,体素中的每个点都会对其邻域执行相同的计算,并拥有相同的内存访问模式。对原始框架的这种更改使其非常适合快速 CUDA 实现。我们通过立方点云的最小边界框来进行体素化。体素的邻域是它的邻近体素。
我们注意到,为了公平地与顺序版本进行比较,我们使用 k-d 树(对于空间本地数据访问有效)来存储点云。

2、设计方案B
在我们的第一次设计之后,我们希望通过利用点云中的冗余来加速分割。即我们问,我们处理的点是否超出了我们需要的数量?
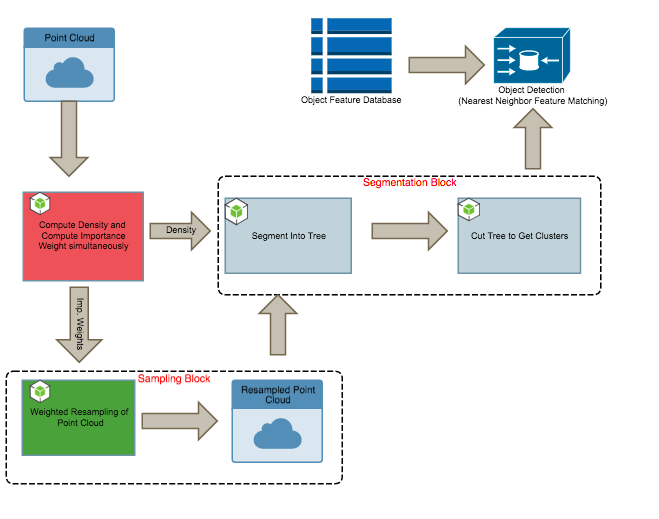
在这里,我们介绍我们的第二个主要贡献,即我们设计中的重采样块。采样步骤分两个阶段进行,我们首先需要为每个点分配一个重要性权重(实际上是一个局部高通滤波器,又是一个空间局部计算),然后再对点进行加权采样。
后者可以借助 CUDA thrust库快速实现。事实证明,我们可以通过保留最多 5% 的总点数来进行二次采样,并保持检测性能。
2.1 重要性权重采样算法
下面我们展示了非常基本的伪代码来展示权重分配算法的结构。如下所示,权重计算又是空间局部计算,因为每个点都会迭代其局部邻域来计算其重要性权重。
function compute_weight() {for each point p in pointcloud:weighted_sum =0; for each neighbor x in neighborhood(p):weighted_sum += weighted_neighbor(p,x);endweight[p] = dist(x, weighted_sum)end
}然后我们根据这些权重对点进行采样。我们在这里提到一个警告;也就是说,我们基于 CPU 的加权顺序采样器以 O(KN)(K 是样本数)简单地执行采样。 采样器预先计算归一化权重的滚动总和,然后对均匀随机数进行采样并查看它落在哪个容器中(二分搜索)。
虽然我们在 CUDA 上实现相同的算法来执行采样,但这并不是在 CPU 上执行加权采样的最快方法。更快的基于 CPU 的实现将基于 Alias-Walker 方法,该方法的采样时间为 O(K+N)。另一个有趣的点是采样器有助于平滑空间中不均匀的点密度。
3、性能评估
下面是厨房场景分割结果的图像。原始点云大约有 300 万个点,我们只保留 80000 个样本。
我们还使用点云分割框架生成的片段显示了谷物盒的对象检测阶段的输出。报告的结果对应于在 GHC 集群上运行我们的实现,该集群具有 8 个用于多线程实现的 2 路超线程核心,以及具有 CUDA 功能 6.0 的 NVidia GeForce GTX1080 GPU。

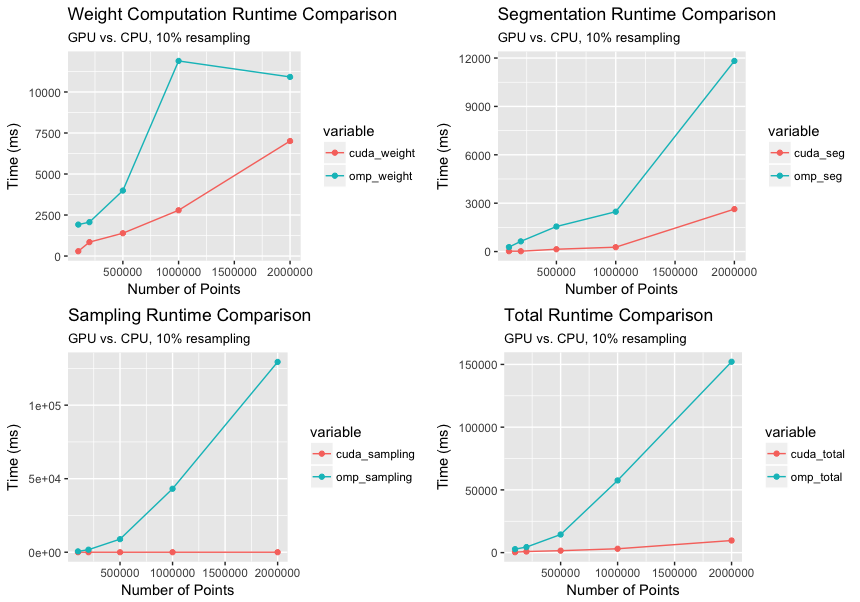
3.1 GPU vs. CPU
我们的主要重点是最大化 GPU 上的分段吞吐量,因此,尽管我们使用 openMP 编译指令优化了 CPU 实现以在 16 个线程上运行,但它仍然不是最佳的 CPU 实现。
下图比较了我们的 openMP 和 CUDA 实现的分割过程的各个计算步骤的运行时间。 CUDA 实现相对于 openMP 实现的整体加速从 10 万点的 8 倍增加到 200 万点的约 20 倍。这种加速比的非线性增加与我们的预期是同步的,因为增加点的数量会增加点密度,从而以立方顺序增加每个体素的计算。此外,由于我们使用高度优化的推力库函数进行并行扫描和收集操作,因此采样步骤的加速比超过 1000 倍。
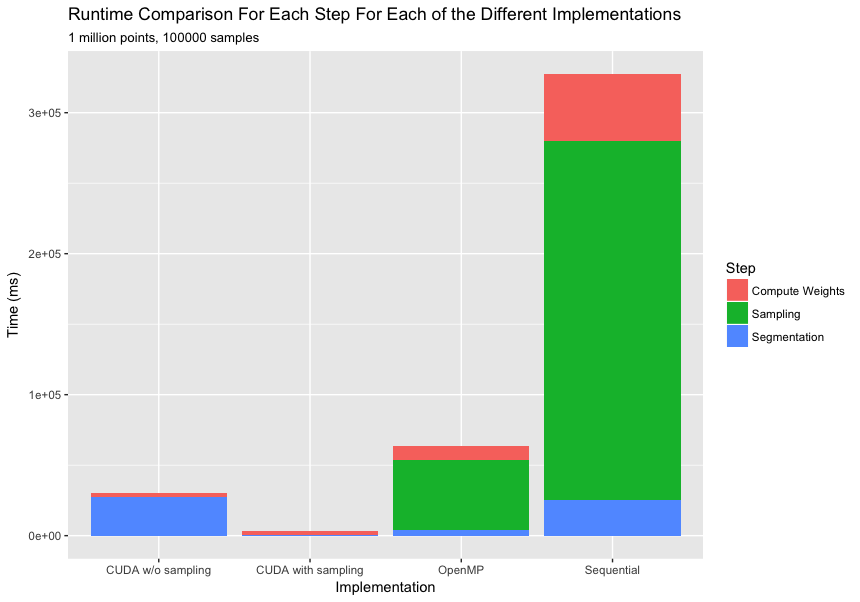
3.2 采样 vs. 不采样
该图比较了多线程 openMP 实现中带采样和不带采样的 CUDA 加速情况。如果不进行采样,CUDA 实现的速度仅提高 2 倍,但是将采样步骤合并到 CUDA 中可将速度提高约 20 倍。
我们注意到,与分割块的大幅加速相比,采样的开销在很大程度上可以忽略不计。我们注意到,我们采样了从 10k 到 100k 点的一系列点,这保留了检测性能。此外,在进行粗分割时,采样特别有用,因为我们需要搜索更大的邻域,更高的密度意味着极其昂贵的计算。
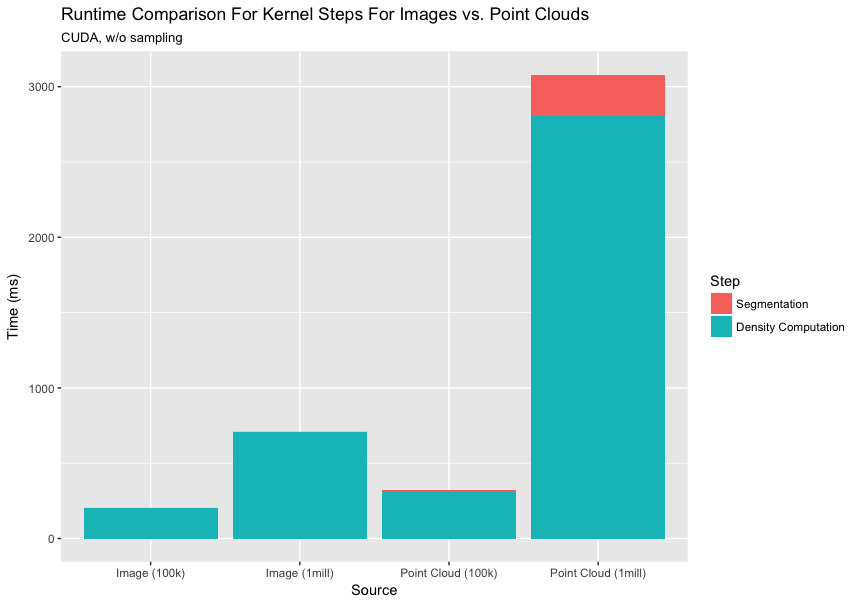
3.3 与图像分割的比较
与表现出高度不规则性的点云相反,图像是高度规则的。在这里,我们打算分析空间中点的密度不均匀对我们的性能有多大影响。这种不均匀性会影响每个块/体素处理的点数,进而导致工作负载不平衡模式极度倾斜。我们均衡图像中的像素数量和点云中的点数以进行公平比较。
图像分割示例,原始图像和分割图像:

4、结束语
我们研究了点云的快速并行分割问题,并实现了能够在几秒钟内分割由数百万个点组成的点云的框架。
具体来说,我们设计了多线程 CPU 和优化的 GPU 实现,这使我们的速度提高了 20 倍左右。一个关键的贡献是在实际分割之前合并了子采样阶段,这有助于进一步加速分割阶段而不影响分割质量。
原文链接:3D点云处理的并行化 - BimAnt