作业①:
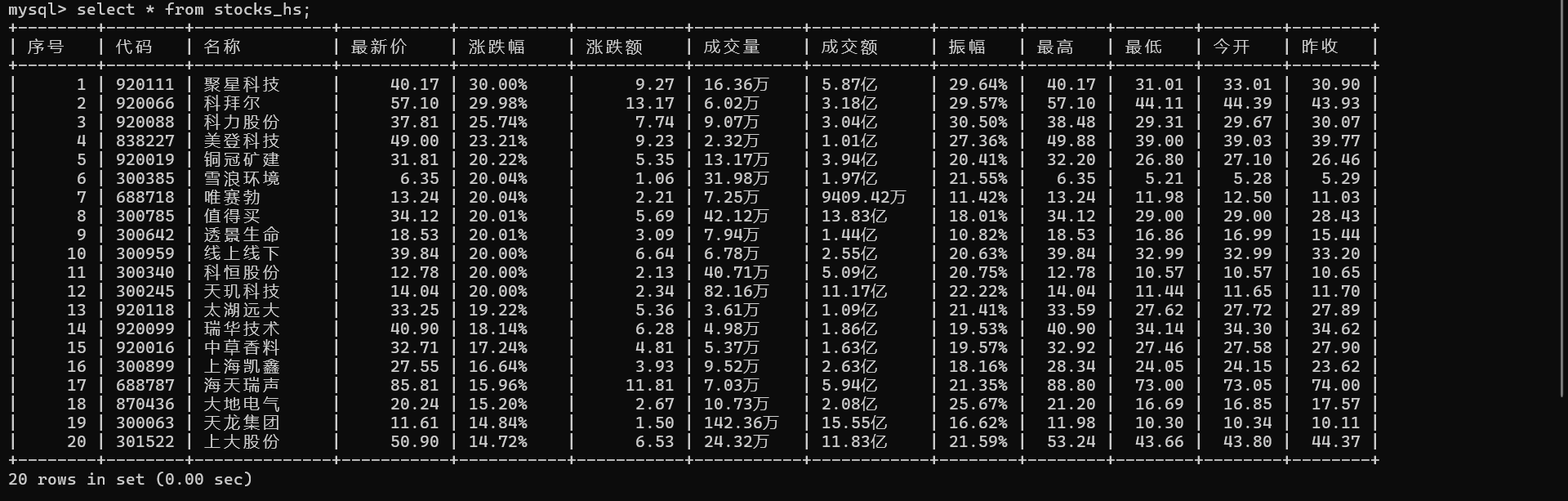
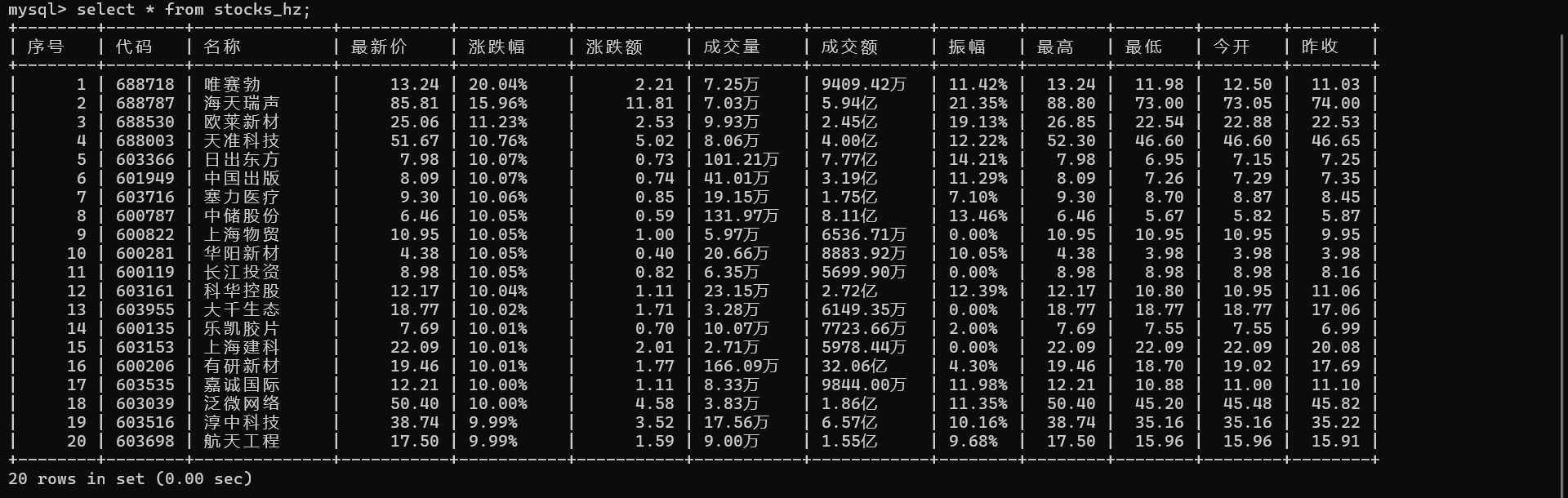
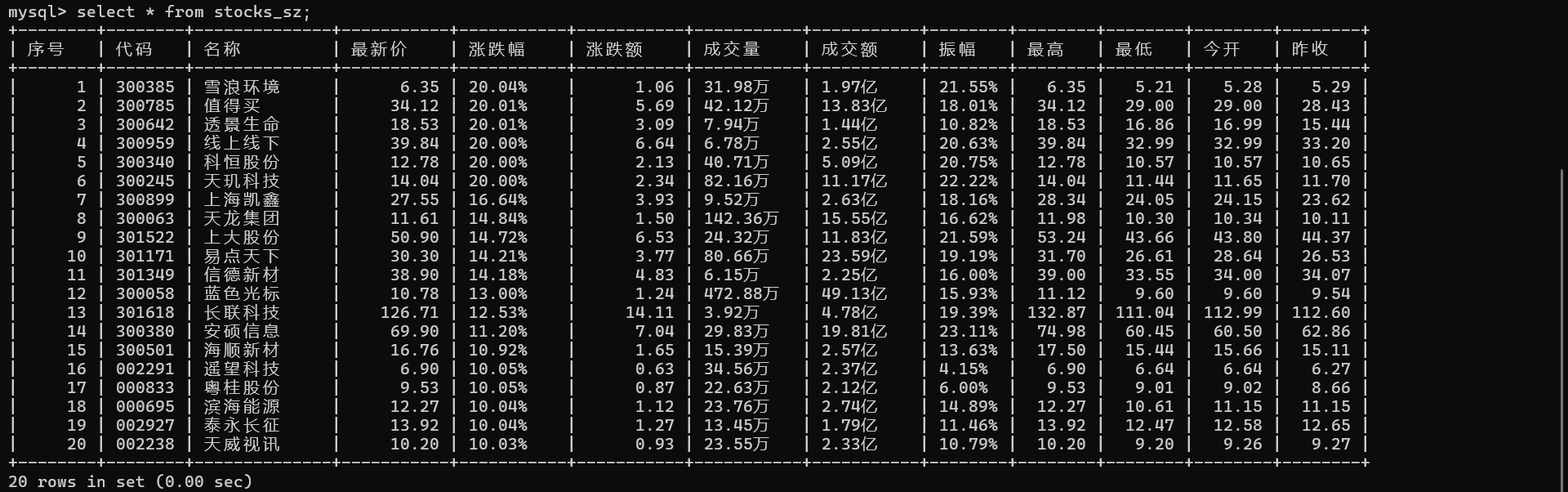
1)使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
1.核心代码描述
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
import pymysql# 建表操作
table_names=['stocks_hs','stocks_hz','stocks_sz'] #分别对应三个板块的表名
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='******', charset='utf8')
conn.autocommit(True)
with conn.cursor() as cursor:cursor.execute('USE homework')for table_name in table_names:#建三张表cursor.execute(f'drop table {table_name}') #因为我之前已经建了,为了调试程序直接删了重建,第一次运行可注释掉这行cursor.execute(f"""CREATE TABLE IF NOT EXISTS {table_name} (序号 INT,代码 VARCHAR(10),名称 VARCHAR(255),最新价 DECIMAL(10,2),涨跌幅 VARCHAR(10),涨跌额 DECIMAL(8,2),成交量 VARCHAR(10),成交额 VARCHAR(10),振幅 VARCHAR(10),最高 DECIMAL(10,2),最低 DECIMAL(10,2),今开 DECIMAL(10,2),昨收 DECIMAL(10,2));""") #成交量和成交额里都有汉字,振幅涨跌幅有百分号,这里为了方便直接使用字符串类型了oringinal_url = 'https://quote.eastmoney.com/center/gridlist.html#hs_a_board'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options)
driver.get(oringinal_url)
for i in range(0,3):stockBotton = driver.find_elements(By.XPATH, "//*[@id='tab']/ul/li")[i].find_element(By.XPATH,"./a") #对应板块按钮stockBotton.click()#点击按钮driver.refresh()#刷新网页WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'td')))stocks=driver.find_elements(By.XPATH,"//table[@id='table_wrapper-table']/tbody/tr")#查找表格for stock in stocks:td1 = stock.find_element(By.XPATH,'./td[1]').text#序号td2 = stock.find_element(By.XPATH, './td[2]/a').text#代码td3 = stock.find_element(By.XPATH, './td[3]/a').text#名称td5 = stock.find_element(By.XPATH, './td[5]/span').text#最新价td6 = stock.find_element(By.XPATH, './td[6]/span').text#涨跌幅td7 = stock.find_element(By.XPATH, './td[7]/span').text#涨跌额td8 = stock.find_element(By.XPATH, './td[8]').text#成交量td9 = stock.find_element(By.XPATH, './td[9]').text#成交额td10 = stock.find_element(By.XPATH, './td[10]').text#振幅td11 = stock.find_element(By.XPATH, './td[11]/span').text#最高td12 = stock.find_element(By.XPATH, './td[12]/span').text#最低td13 = stock.find_element(By.XPATH, './td[13]/span').text#今开td14 = stock.find_element(By.XPATH, './td[14]').text#昨收#将对应元素插入表中sql = f"""INSERT INTO {table_names[i]} (序号,代码,名称,最新价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收)VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""data = (td1, td2, td3, td5, td6,td7, td8, td9, td10, td11,td12, td13, td14)with conn.cursor() as cursor:try:cursor.execute(sql, data)except Exception as e:print(e)print(f'{table_names[i]}数据存储成功')
driver.quit()
2.输出信息

3.Gitee文件夹链接
作业4/1 · 舒锦城/2022级数据采集与融合技术 - 码云 - 开源中国
作业②:
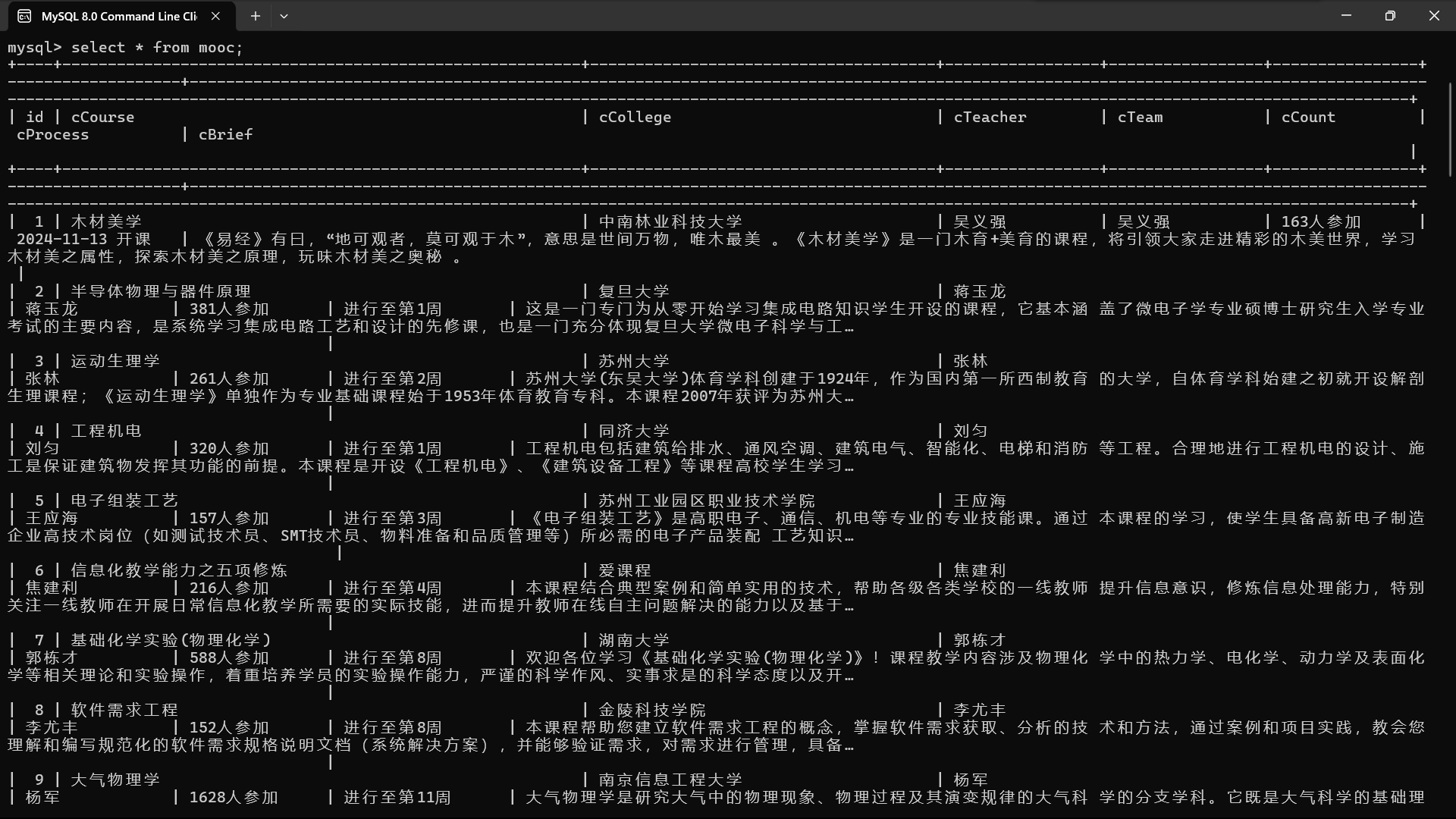
1)使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
1.核心代码描述
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import pymysql
from bs4 import BeautifulSoup# 设置Chrome浏览器为无头模式(即不显示浏览器窗口)并禁用GPU加速,这样可以在后台运行浏览器操作
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')# 创建一个Chrome浏览器驱动实例,并传入设置好的选项
driver = webdriver.Chrome(options=chrome_options)# 登录操作
driver.get('https://www.icourse163.org/')time.sleep(2)
# 将浏览器窗口最大化,有些页面在不同窗口大小下可能显示效果不同,最大化可尽量保证页面元素正常显示
driver.maximize_window()# 通过XPath找到并点击页面上的登入按钮
next_button = driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
next_button.click()
# 再次等待2秒,确保点击按钮后的页面加载或相关操作完成
time.sleep(2)frame = driver.find_element(By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(frame)# 输入账号操作
# 通过ID找到账号输入框元素,并使用send_keys方法输入指定的账号
account = driver.find_element(By.ID, 'phoneipt').send_keys('******')# 输入密码操作
# 通过XPath找到密码输入框元素,并使用send_keys方法输入指定的密码
password = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys("******")# 获取登录按钮操作
# 通过XPath找到登录按钮元素,后续将点击这个按钮来完成登录
logbutton = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a')# 点击按钮操作
# 点击找到的登录按钮,触发登录行为
logbutton.click()
# 等待2秒,让登录后的页面加载完成,可能会有登录后的跳转或相关数据加载等操作
time.sleep(2)# 抓取课程信息操作# 打开课程搜索页面的网址
driver.get('https://www.icourse163.org/search.htm?search=%20#/')
# 等待2秒,确保搜索页面加载完成
time.sleep(2)next_button = driver.find_element(By.XPATH, '/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[1]/div[1]/label/div')
next_button.click()
time.sleep(2)# 定义一段JavaScript代码,用于实现页面滚动操作
# 这段代码的目的是模拟用户不断滚动页面,以加载更多课程信息(因为很多网页是滚动加载更多内容的)
js = '''timer = setInterval(function(){var scrollTop=document.documentElement.scrollTop||document.body.scrollTop;var ispeed=Math.floor(document.body.scrollHeight / 100);if(scrollTop > document.body.scrollHeight * 90 / 100){clearInterval(timer);}console.log('scrollTop:'+scrollTop)console.log('scrollHeight:'+document.body.scrollHeight)window.scrollTo(0, scrollTop+ispeed)}, 20)'''# 循环执行页面滚动操作,这里循环4次,每次执行滚动脚本后等待4秒,让页面有足够时间加载更多课程信息
for i in range(1, 5):driver.execute_script(js)time.sleep(4)# 获取当前页面的源代码,后续将使用BeautifulSoup解析这些源代码来提取课程信息html = driver.page_sourcesoup = BeautifulSoup(html, 'lxml')course_cards = soup.find_all('div', class_='u-course-card')# 遍历找到的每一个课程卡片元素for card in course_cards:a_tag = card.find('a', class_='f-thide', attrs={'data-v-55c26986': True})# 如果找到的a标签存在且其文本内容为'国家精品',则进行以下信息提取和数据库插入操作if a_tag and a_tag.text == '国家精品':# 提取课程名称b = card.find('a', class_='f-thide', attrs={'data-v-55c26986': True}).textc = card.find('a', class_='f-fc9', attrs={'data-v-55c26986': True}).textd = card.find('a', class_='f-fc9', attrs={'data-v-55c26986': True}).texte = card.find('a', class_='f-fc9', attrs={'data-v-55c26986': True}).text# 提取课程的选课人数信息f = card.find('span', class_='u-course-card__num').text# 找到课程卡片底部的元素,用于后续提取课程状态信息g_tag = card.find('div', class_='u-course-card__bottom')# 如果找到底部元素,则提取课程状态信息,否则设置为'已结束'(可能是默认状态假设)g = g_tag.find('span', class_='u-course-card__status').text if g_tag else '已结束'# 找到课程卡片的图片链接相关元素,用于后续提取课程简介信息h_tag = card.find('a', class_='u-course-card__img-link')# 如果找到图片链接相关元素,则提取课程简介信息,否则设置为'空'h = h_tag.find('span', class_='u-course-card__img-text').text if h_tag else '空'# 连接到本地的MySQL数据库mydb = pymysql.connect(host="localhost",user="root",password="******",database="homework",charset='utf8mb4')try:# 创建一个数据库游标对象,用于执行SQL语句with mydb.cursor() as cursor:# 定义要插入数据的SQL语句,将提取到的课程相关信息插入到名为'mooc'的表中sql = "INSERT INTO mooc (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) VALUES (%s, %s, %s, %s, %s, %s, %s)"val = (b, c, d, e, f, g, h)# 执行SQL插入语句,将数据插入到数据库表中cursor.execute(sql, val)# 提交数据库事务,使插入操作生效mydb.commit()print(b, c, d, e, f, g, h)except Exception as e:print(f"Error: {e}")finally:# 关闭数据库连接,释放资源mydb.close()# 通过XPath找到并点击页面上的下一页按钮(用于切换到课程列表的下一页继续抓取信息)next_button = driver.find_element(By.XPATH, '//*[@id="j-courseCardListBox"]/div[2]/ul/li[10]')next_button.click()time.sleep(2)
2.输出信息
3.Gitee文件夹链接
作业4/2 · 舒锦城/2022级数据采集与融合技术 - 码云 - 开源中国
作业③:
1)完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
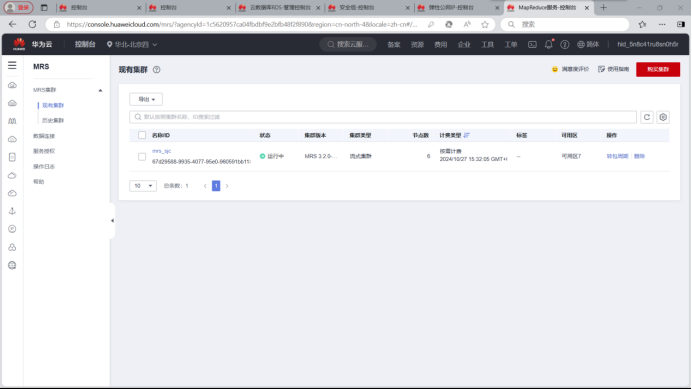
1.开通MapReduce服务
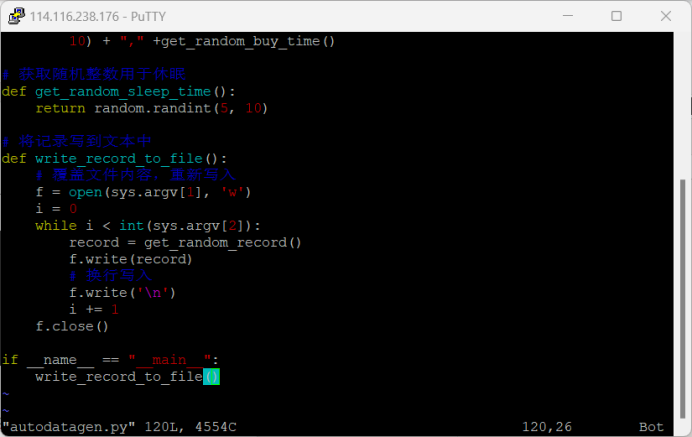
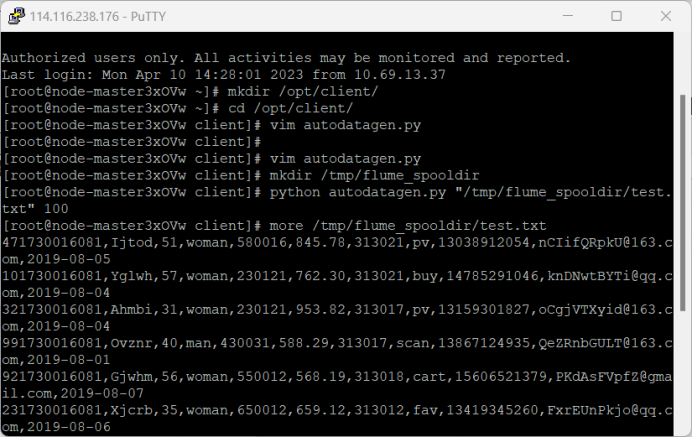
2.Python脚本生成测试数据
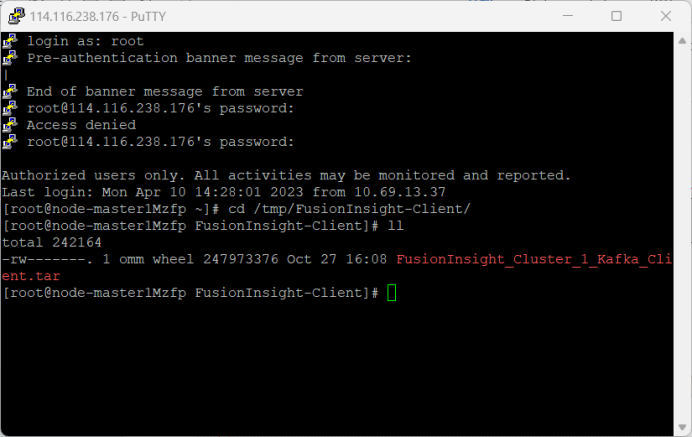
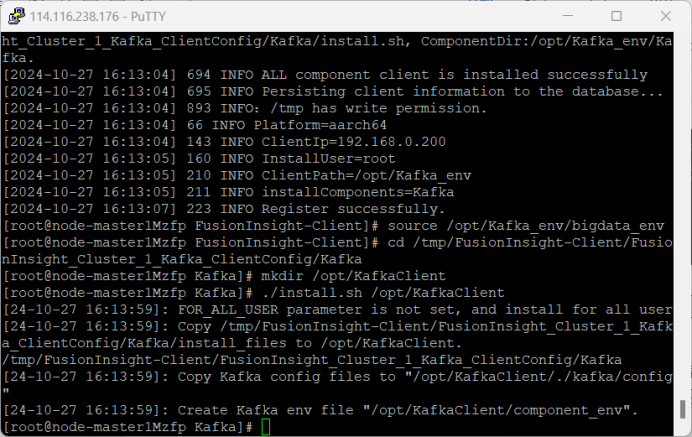
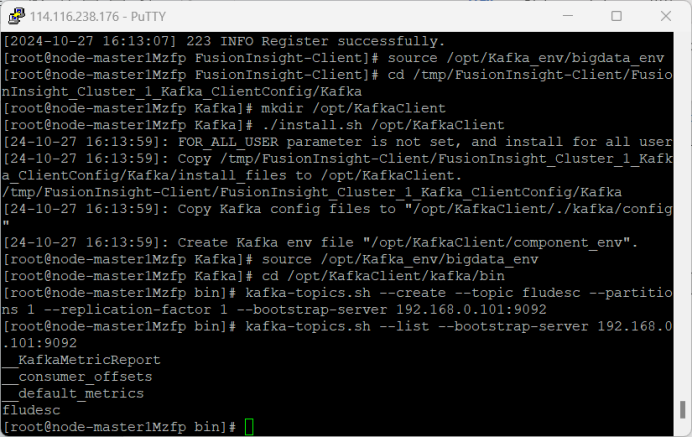
3.配置Kafka
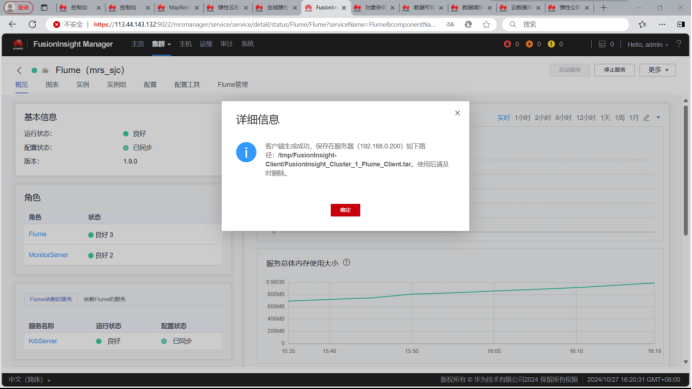
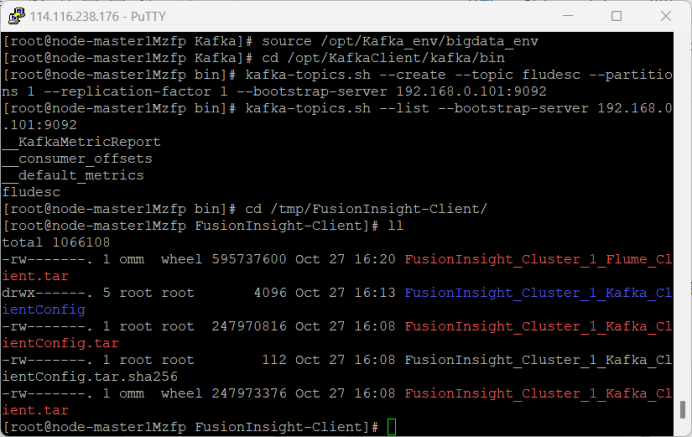
4.安装Flume客户端
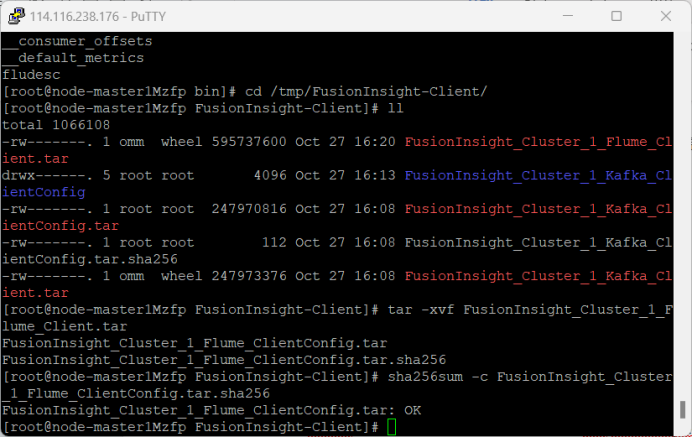
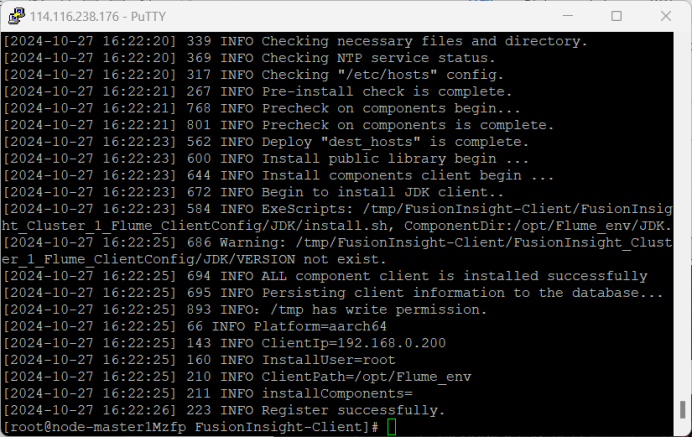
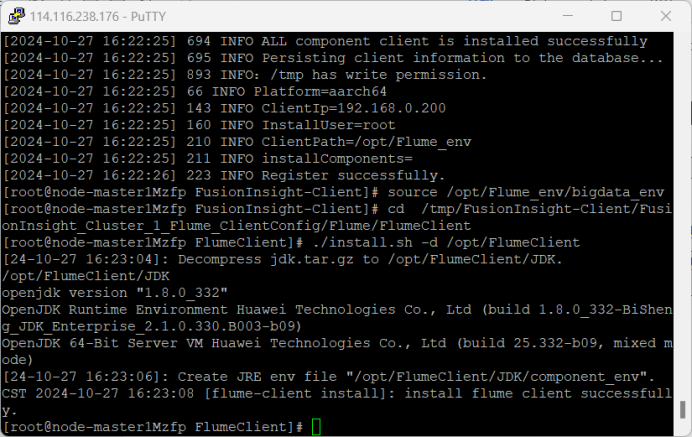

5.配置Flume采集数据
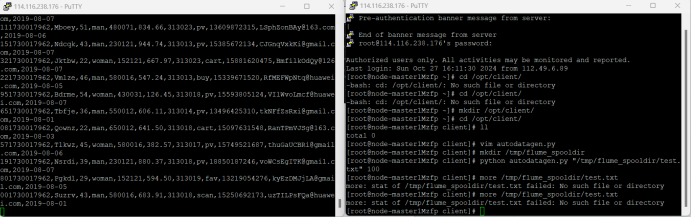
心得体会:
1.selenium的使用
对于selenium的使用更加熟练了,而且个人感觉使用selenium爬取股票数据相比于使用scrapy框架要方便很多,对于不同网站数据的爬取,应当选择合适的技术手段,才能做到方便快捷的爬取到我们想要的数据,并且使用selenium不需要设置用户头和cookie,以及被检测到的风险会小很多,更方便我们调试程序。
2.Flume日志采集
在最后产生实时的可视化数据图像感到很有成就感,深感Flume日志采集的功能强大,同时对海量数据的快速处理有了更深的了解,希望以后能更加熟练运用这些工具带来更多的价值。