目录
- 摘要
- Abstract
- 一、文献阅读
- 1.1 摘要
- 1.2 背景
- 1.3 论文方法
- 1.3.1 局部特征提取
- 1.3.2 局部特征转换器 (LoFTR) 模块
- 1.3.4 建立粗粒度匹配
- 1.3.5 精细匹配
- 1.4 损失
- 1.5 实现细节
- 1.6 实验
- 1.6.1 单应性估计
- 1.6.2 相对位姿估计
- 二、论文代码
- 总结
摘要
本周阅读了一篇特征匹配领域的论文。LoFTR,一种创新的局部图像特征匹配方法,为3D计算机视觉领域带来革命性突破。它摒弃了传统特征检测、描述和匹配的繁琐步骤,通过像素级的粗粒度密集匹配,优化了良好匹配的效果。该方法利用Transformer中的自注意力和交叉注意力层,获取全局感受野,解决了低纹理区域匹配难题,性能优于最先进方法。在复杂的室内和室外环境中,LoFTR展现出强大的匹配能力,特别是在处理重复纹理和模式时,其优势更为显著。相比基于检测器的SuperGlue方法,LoFTR克服了检测器在寻找对应关系时的局限性,实现了更全面的特征提取和匹配。LoFTR的成功不仅在于其创新的设计,更在于其深入理解了图像匹配的本质。它借鉴了人类视觉系统的特点,能够结合局部和全局信息进行匹配,从而提高了对应点的准确性。这一特点使得LoFTR在应对复杂环境中的匹配难题时,能够展现出更强大的能力。此外,LoFTR还通过采用线性Transformer等优化手段,降低了计算复杂度,提高了实际应用价值。这一优势使得LoFTR在保持高性能的同时,也能够满足实时性要求较高的应用场景。
Abstract
This week, I read a paper on feature matching in the field. LoFTR, an innovative local image feature matching method, has brought revolutionary breakthroughs to the 3D computer vision field. It abandons the cumbersome steps of traditional feature detection, description, and matching, and optimizes the effect of good matches through pixel-level coarse-grained dense matching. This method utilizes self-attention and cross-attention layers in Transformer to obtain global receptive fields, addressing the challenge of matching in low-texture areas and outperforming state-of-the-art methods.In complex indoor and outdoor environments, LoFTR demonstrates strong matching capabilities, especially when dealing with repetitive textures and patterns. Compared to the detector-based SuperGlue method, LoFTR overcomes the limitations of detectors in finding correspondences, achieving more comprehensive feature extraction and matching.The success of LoFTR lies not only in its innovative design but also in its deep understanding of the essence of image matching. It draws inspiration from the characteristics of the human visual system, able to combine local and global information for matching, thereby improving the accuracy of corresponding points. This characteristic enables LoFTR to demonstrate greater capabilities when dealing with matching challenges in complex environments.
Furthermore, LoFTR reduces computational complexity and enhances practical application value by adopting optimization techniques such as linear Transformer. This advantage allows LoFTR to maintain high performance while meeting the real-time requirements of demanding applications.
一、文献阅读
题目:LoFTR: Detector-Free Local Feature Matching with Transformers
1.1 摘要
我们提出了一种局部图像特征匹配的新方法。 我们建议首先在粗略水平上建立像素级密集匹配,然后在精细水平上细化良好的匹配,而不是依次执行图像特征检测、描述和匹配。 与使用成本量来搜索对应关系的密集方法相比,我们在 Transformer 中使用自注意力层和交叉注意力层来获取以两张图像为条件的特征描述符。 Transformer 提供的全局感受野使我们的方法能够在低纹理区域产生密集匹配,而特征检测器通常很难在这些区域产生可重复的兴趣点。 室内和室外数据集的实验表明,LoFTR 的性能大幅优于最先进的方法。
1.2 背景
大多数现有的匹配方法由三个独立的部分组成 阶段:特征检测、特征描述和特征匹配。
- 特征检测:从图像中提取显著且可重复的兴趣点,例如角点、边缘等。
- 特征描述:为每个检测到的兴趣点生成一个独特的描述子,以便在后续步骤中与其他图像的特征进行比较。
- 特征匹配:通过比较描述子,找到两幅图像之间的对应特征点。
特征检测器的使用减少了匹配的搜索空间。 然而,由于各种因素,例如不良纹理、重复图案、视点变化、照明变化和运动模糊等,特征检测器可能无法提取足够多的图像之间可重复的兴趣点。 这个问题在室内环境中尤其突出,低纹理区域或重复图案有时占据视野中的大部分区域。 图 1 显示了一个示例。 如果没有可重复的兴趣点,即使有完美的描述符也无法找到正确的对应关系。

最近的几项工作试图通过建立像素密集匹配来解决这个问题。 可以从密集匹配中选择具有高置信度分数的匹配,从而避免特征检测。 然而,这些作品中卷积神经网络(CNN)提取的密集特征的感受野有限,可能无法区分不明显的区域。 相反,人类在这些不明显的区域中不仅基于当地社区,而且还基于更大的全球背景来寻找对应关系。 例如,图1中的低纹理区域可以根据它们与边缘的相对位置来区分。 这一观察结果告诉我们,特征提取网络中较大的感受野至关重要。
1.3 论文方法
给定图像对 IA 和 IB,现有的局部特征匹配方法使用特征检测器来提取兴趣点。 我们建议通过无检测器设计来解决特征检测器的可重复性问题。 图 2 概述了所提出的 LoFTR 方法。
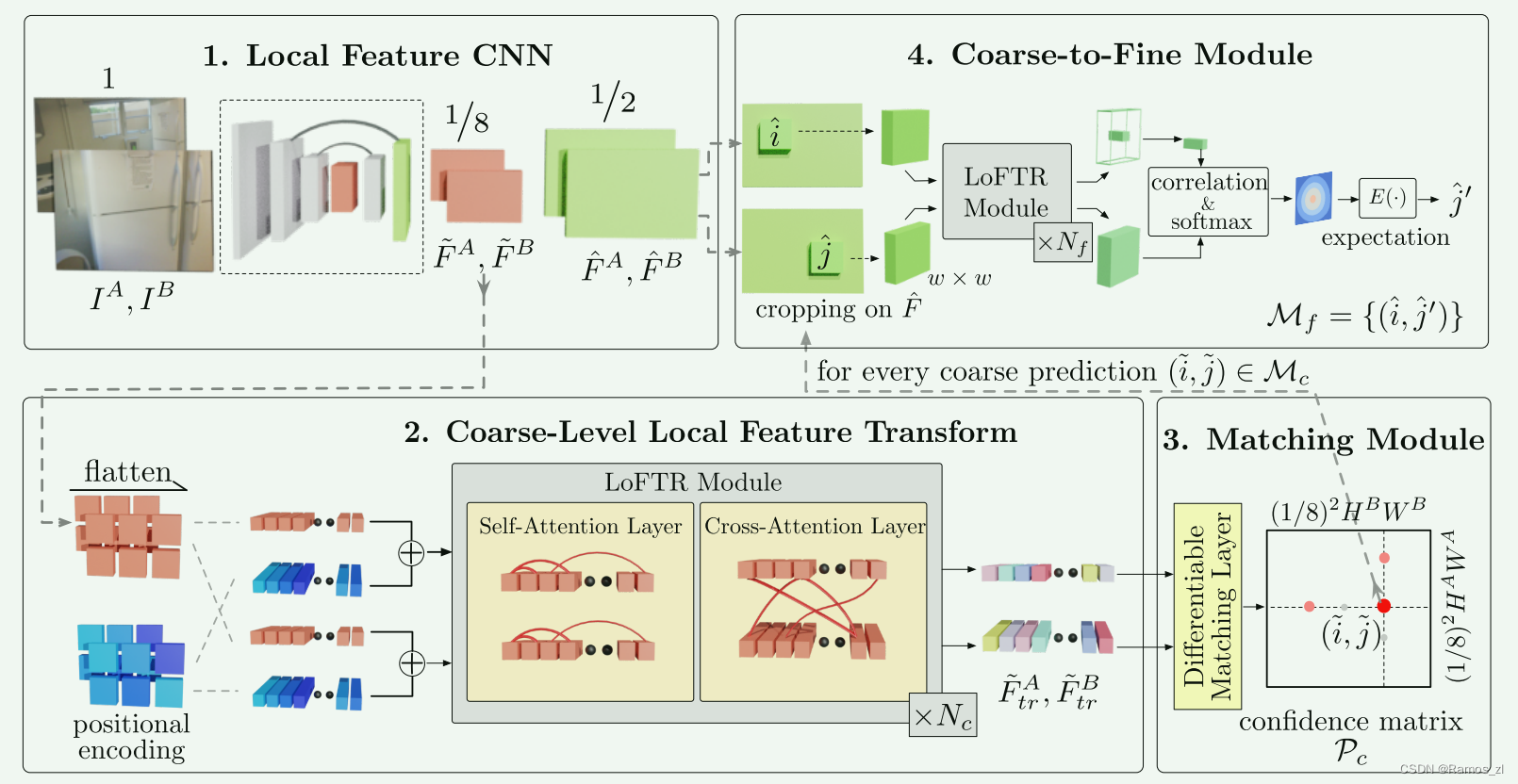
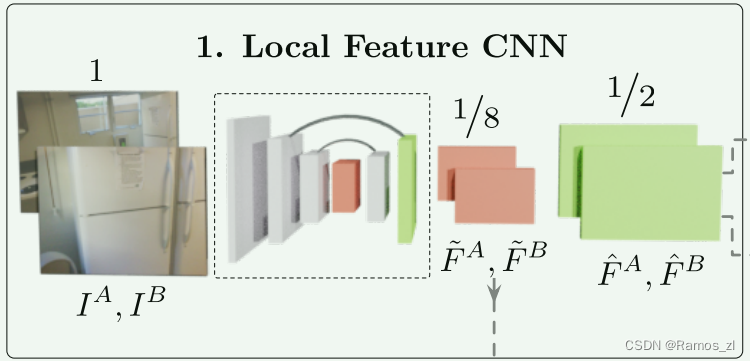
1.3.1 局部特征提取
我们使用带有 FPN [22](表示为局部特征 CNN)的标准卷积架构从两个图像中提取多级特征。 我们使用 ~FA 和 ~FB表示原始图像维度1/8处的粗级特征,并且 ^FA 和 ^FB表示原始图像维度1/2处的精细级特征。 卷积神经网络(CNN)具有平移等方差和局部性的归纳偏差,非常适合局部特征提取。 CNN 引入的下采样还减少了 LoFTR 模块的输入长度,这对于确保可管理的计算成本至关重要。
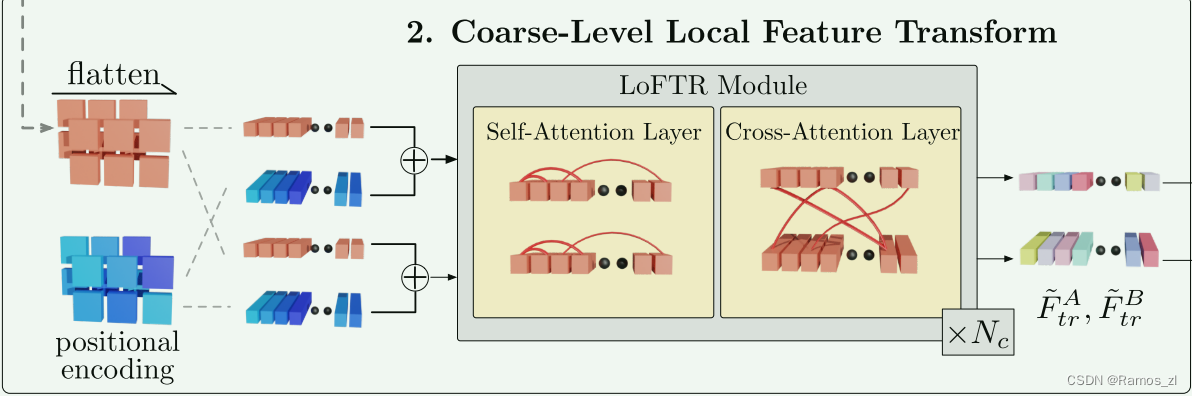
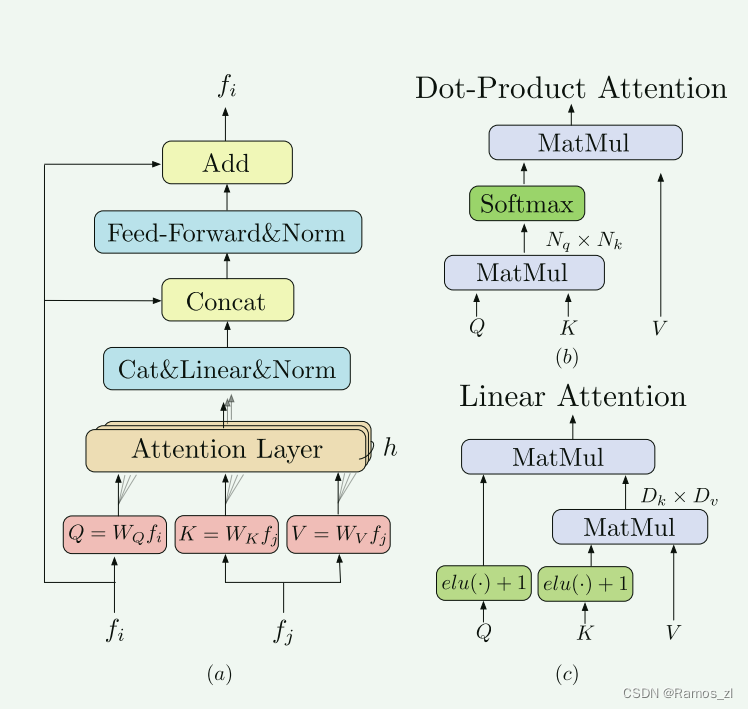
1.3.2 局部特征转换器 (LoFTR) 模块
在局部特征提取之后, ~FA 和 ~FB通过LoFTR模块来提取位置和上下文相关的局部特征。 直观上,LoFTR 模块将特征转换为易于匹配的特征表示。 我们将变换后的特征表示为 F ~A tr 和 ~FB tr。
 Transformer 编码器由顺序连接的编码器层组成。 图3(a)显示了编码器层的架构。 编码器层的关键元素是注意力层。 注意力层的输入向量通常称为查询、键和值。 与信息检索类似,查询向量 Q 根据 Q 和每个值 V 对应的关键向量 K 的点积计算出的注意力权重,从值向量 V 中检索信息。注意力层的计算图如下所示 图3(b)。 形式上,注意力层表示为:
Transformer 编码器由顺序连接的编码器层组成。 图3(a)显示了编码器层的架构。 编码器层的关键元素是注意力层。 注意力层的输入向量通常称为查询、键和值。 与信息检索类似,查询向量 Q 根据 Q 和每个值 V 对应的关键向量 K 的点积计算出的注意力权重,从值向量 V 中检索信息。注意力层的计算图如下所示 图3(b)。 形式上,注意力层表示为:
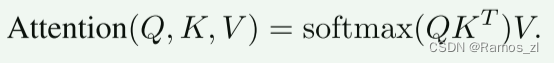
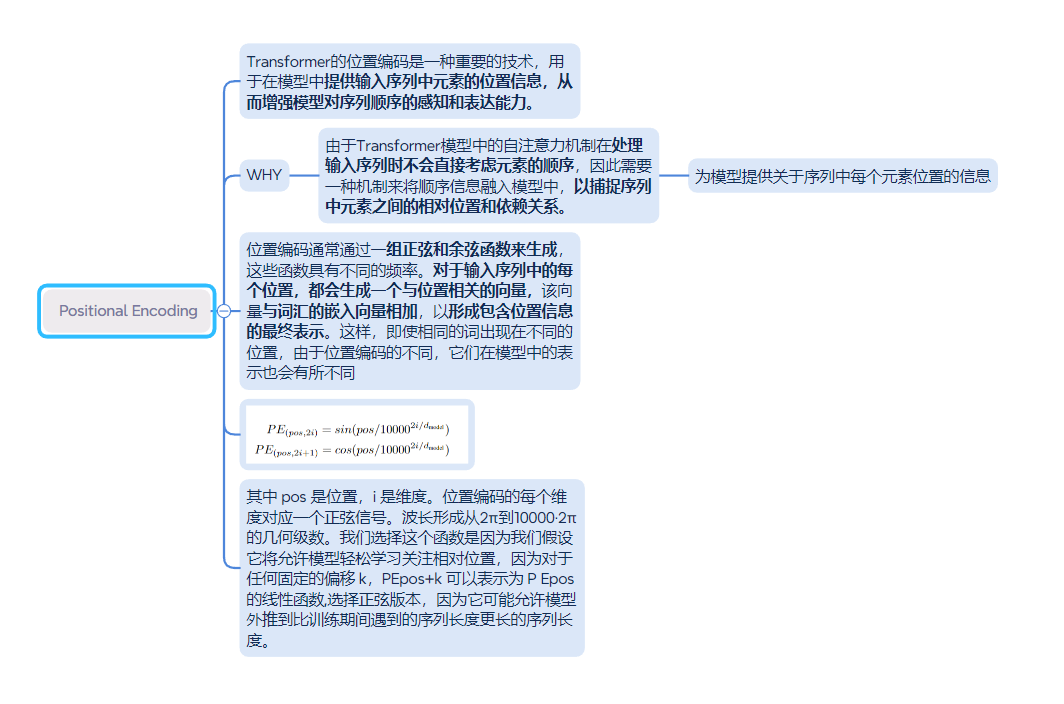
位置编码: 我们按照 DETR 在 Transformers 中使用标准位置编码的 2D 扩展。 与 DETR 不同,我们只将它们添加到骨干输出一次。 我们将位置编码的正式定义留在补充材料中。 直观上,位置编码以正弦格式为每个元素提供唯一的位置信息。 通过将位置编码添加到 F~A 和 F~B,变换后的特征将变得位置相关,这对于 LoFTR 在不明显的区域中产生匹配的能力至关重要。 如图 4© 的底行所示,虽然输入 RGB 颜色在白墙上是均匀的,但平滑颜色梯度所展示的每个位置的变换特征 F~ A tr 和 F~ B tr 都是唯一的。 图 6 提供了更多可视化效果。
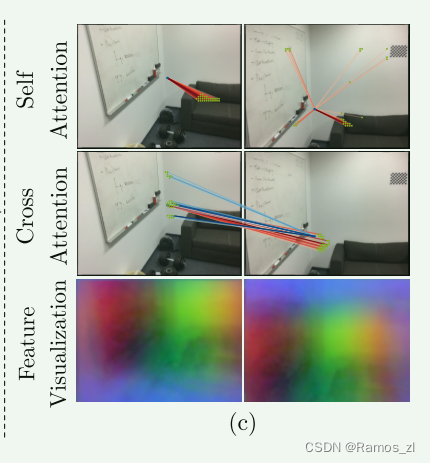
自注意力和交叉注意力层: 对于自注意力层,输入特征 fi 和 fj (如图 3 所示)是相同的(〜FA 或〜FB)。 对于交叉注意力层,输入特征 fi 和 fj 要么是( FA 和 F B),要么是(FB 和 F A),具体取决于交叉注意力的方向。 遵循[37],我们将 LoFTR 模块中的自注意力层和交叉注意力层交错 Nc 次。 LoFTR 中自注意力层和交叉注意力层的注意力权重在图 4© 的前两行中可视化。
将粗略特征图输入至粗特征提取的transformer提取匹配特征,该transformer由多个交替的自注意力和交叉注意力层构成,自注意力层使得每个点关注其周围所有点的关联,交叉注意力层使得点关注与另一幅图上的所有点的关联
1.3.4 建立粗粒度匹配
使用乘积的方式先计算所有位置的匹配得分矩阵 S,然后计算最优匹配,可以通过最优传输OT算法或者dual-softmax方法,文中使用的是dual-softmax, 然后再通过互近邻MNN算法过滤掉一些离群匹配对。
匹配概率Pc由下式获得:
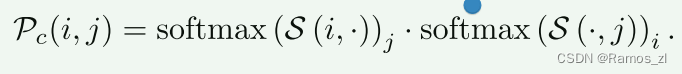
1.3.5 精细匹配
通过粗匹配得到粗粒度的匹配结果,例如匹配点对(i1,j1),(i2,j2), 将其映射到对应的精细特征图,并且将其(w,w)领域裁剪出来(相当于裁剪出来了w*w个位置的特征),输入至精细特征提取的transformer提取匹配特征,得到FA和FB,然后计算FA中心特征与FB中所有特征的匹配概率(即相似度),再计算该概率分布即可计算出FB中的亚像素精度的匹配点位置(应该是通过领域(5,5)以及对应的概率,加权相加计算出精细位置,是亚像素级别的)
1.4 损失
最终的coarse-to-fine上的代价由如下组成:
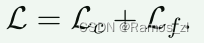
粗粒度代价:通过在置信矩阵Pc上使用负对数似然得到最终的代价,两个网格之间的距离是由其中心位置的重投影距离来衡量的。在使用双软性匹配时,我们将Mgt中网格的负对数可能性损失降到最低。
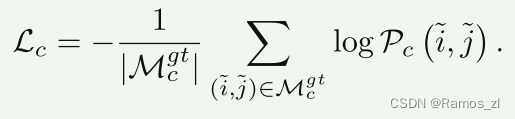
细粒度代价:我们使用ℓ2损失来进行精细的精细化。按照,对于每个查询点i,我们也通过计算总方差σ2(ˆi)来衡量其不确定性。我们的目标是要优化具有低不确定性的精炼位置,结果是形成最终的加权损失函数。
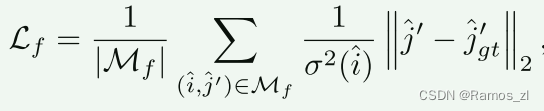
1.5 实现细节
我们在ScanNet数据集上训练了LoFTR的室内模型,并在MegaDepth上训练了室外模型,按照的方法进行。在ScanNet上,模型使用Adam进行训练,初始学习率为1×10−3,批次大小为64。经过64张GTX1080Ti GPU的24小时训练后模型收敛。局部特征CNN使用修改版的ResNet-18 [12]作为骨干网络。整个模型的权重是随机初始化的并进行端到端的训练。Nc设置为4,Nf设置为1,θc选择0.2。窗口大小w等于5。在实现中,将F˜Atr和F˜Btr上采样并与FˆA和FˆB进行拼接,然后通过细匹配级别的LoFTR。使用双向softmax匹配的完整模型在一对640×480的图像上运行时间为116毫秒,使用RTX 2080Ti。在最优传输设置下,我们使用三个Sinkhorn迭代,模型运行时间为130毫秒。更多训练和计时分析的细节请参见补充材料。
1.6 实验
1.6.1 单应性估计
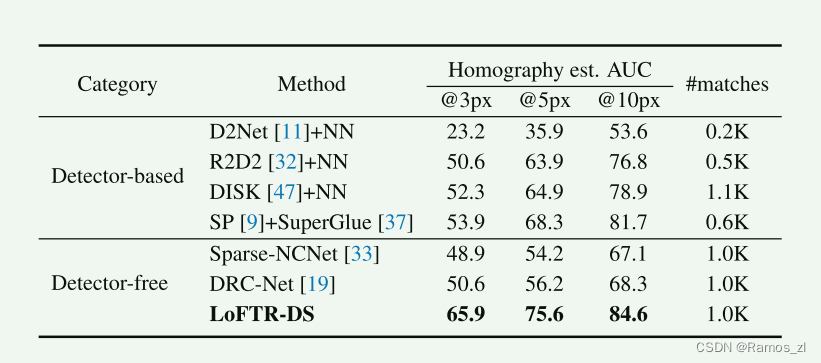
评估协议:在每个测试序列中,将一个参考图像与其他五个图像配对。所有图像的尺寸调整为较短边等于480像素。对于每对图像,我们使用在MegaDepth数据集上训练的LoFTR提取一组匹配点。我们使用OpenCV计算采用RANSAC作为鲁棒估计器的单应性矩阵估计。为了与产生不同数量匹配点的方法进行公平比较,我们使用角点误差来衡量通过估计的Hˆ对图像进行变换后与真实H之间的差异,与中的正确性指标一致。按照的做法,我们分别报告了3、5和10像素阈值下角点误差累积曲线下面积(AUC)。我们报告LoFTR输出最多1K匹配点时的结果。
基准方法:我们将LoFTR与三类方法进行比较:1)基于检测器的局部特征方法,包括R2D2、D2Net和DISK;2)基于检测器的局部特征匹配方法,即SuperGlue在SuperPoint特征上的扩展;3)无需检测器的匹配方法,包括Sparse-NCNet和DRC-Net。对于局部特征方法,我们最多提取2K个特征,并提取相互最近邻作为最终匹配点。对于直接输出匹配点的方法,我们限制最多1K个匹配点,与LoFTR一样。对于所有基准方法,我们使用原始实现中的默认超参数。
结果。表1显示,LoFTR在所有误差阈值下明显优于其他基准方法。具体而言,随着正确性阈值越来越严格,LoFTR与其他方法之间的性能差距增大。我们将顶级性能归因于无需检测器的设计提供的更多匹配候选项以及Transformer带来的全局感受野。此外,粗到精模块通过将匹配点细化到亚像素级别也有助于估计的准确性。
1.6.2 相对位姿估计
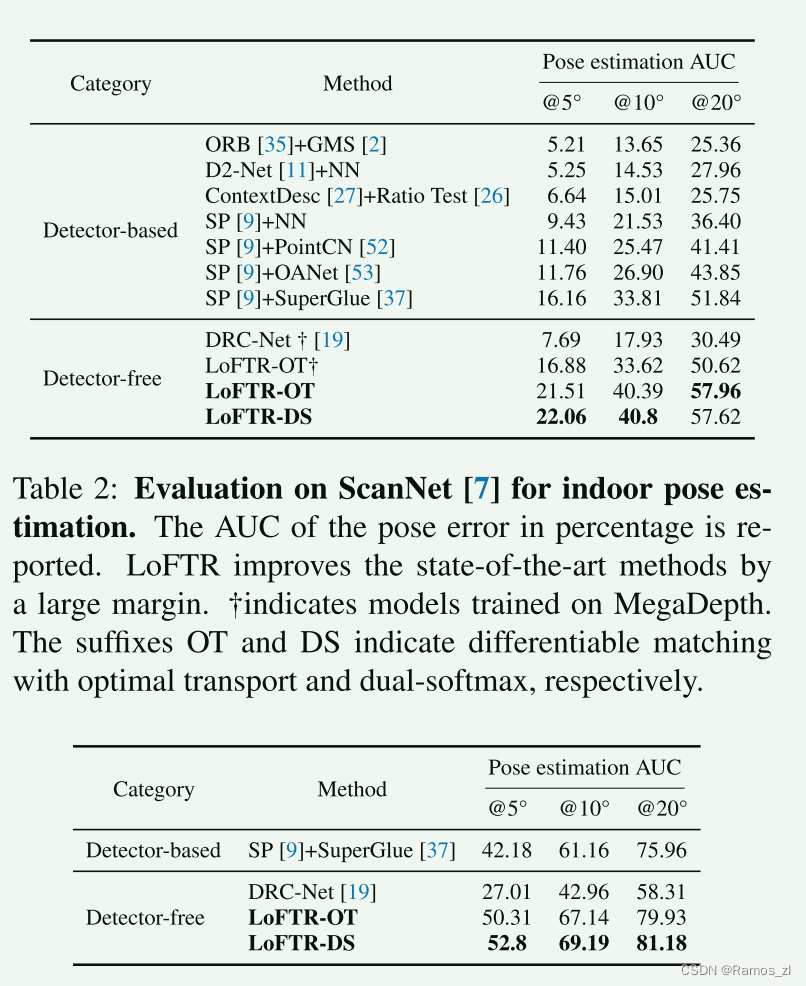
数据集:我们使用ScanNet和MegaDepth数据集分别展示LoFTR在室内和室外场景中进行位姿估计的效果。
ScanNet包含1613个带有地面真实位姿和深度图的单目序列。按照SuperGlue的步骤,我们对训练集采样了230M对图像,其重叠得分在0.4到0.8之间。我们在中的1500个测试图像对上评估我们的方法。所有图像和深度图的尺寸调整为640×480像素。该数据集包含了基线较大和纹理缺失区域较多的图像对。
MegaDepth由196个不同室外场景的100万张互联网图像组成。作者还提供了使用COLMAP进行稀疏重建和使用多视图立体法计算深度图的数据。我们按照DISK的方法,只使用"Sacre Coeur"和"St. Peter’s Square"两个场景进行验证,并从中采样了1500对图像用于公平比较。训练时,图像的较长边被调整为840像素,验证时调整为1200像素。MegaDepth的关键挑战是在极端视点变化和重复纹理的情况下进行匹配。
评估协议:按照的做法,我们报告在阈值为5°、10°和20°时的位姿误差的AUC,其中位姿误差定义为旋转和平移中角度误差的最大值。为了恢复相机位姿,我们使用RANSAC从预测的匹配点中求解本质矩阵。由于无需检测器的图像匹配方法缺乏定义明确的度量(如匹配得分或召回率),我们不对LoFTR和其他基于检测器的方法进行匹配精度比较。我们将DRC-Net视为无需检测器方法中的最先进方法。
二、论文代码
基础特征提取模块Local Feature CNN
通过CNN提取特征图
# 1. Local Feature CNNdata.update({'bs': data['image0'].size(0),'hw0_i': data['image0'].shape[2:], 'hw1_i': data['image1'].shape[2:]})if data['hw0_i'] == data['hw1_i']: # faster & better BN convergenceprint(torch.cat([data['image0'], data['image1']], dim=0).shape)feats_c, feats_f = self.backbone(torch.cat([data['image0'], data['image1']], dim=0))print(feats_c.shape) # 1/8print(feats_f.shape) # 1/2(feat_c0, feat_c1), (feat_f0, feat_f1) = feats_c.split(data['bs']), feats_f.split(data['bs'])print(feat_c0.shape)print(feat_c1.shape)print(feat_f0.shape)print(feat_f1.shape)else: # handle different input shapes(feat_c0, feat_f0), (feat_c1, feat_f1) = self.backbone(data['image0']), self.backbone(data['image1'])print(feat_c0.shape)print(feat_c1.shape)print(feat_f0.shape)print(feat_f1.shape)data.update({'hw0_c': feat_c0.shape[2:], 'hw1_c': feat_c1.shape[2:],'hw0_f': feat_f0.shape[2:], 'hw1_f': feat_f1.shape[2:]})这里的backbone就是一系列的卷积和连接操作,可以跳入self.backbone中去:
def forward(self, x):# ResNet Backbonex0 = self.relu(self.bn1(self.conv1(x)))x1 = self.layer1(x0) # 1/2x2 = self.layer2(x1) # 1/4x3 = self.layer3(x2) # 1/8# FPNx3_out = self.layer3_outconv(x3)x3_out_2x = F.interpolate(x3_out, scale_factor=2., mode='bilinear', align_corners=True)x2_out = self.layer2_outconv(x2)x2_out = self.layer2_outconv2(x2_out+x3_out_2x)x2_out_2x = F.interpolate(x2_out, scale_factor=2., mode='bilinear', align_corners=True)x1_out = self.layer1_outconv(x1)x1_out = self.layer1_outconv2(x1_out+x2_out_2x)return [x3_out, x1_out]注意力机制应用 coarse-level loftr module
# 2. coarse-level loftr module# add featmap with positional encoding, then flatten it to sequence [N, HW, C]# 添加位置编码feat_c0 = rearrange(self.pos_encoding(feat_c0), 'n c h w -> n (h w) c')print(feat_c0.shape)feat_c1 = rearrange(self.pos_encoding(feat_c1), 'n c h w -> n (h w) c')print(feat_c1.shape)mask_c0 = mask_c1 = None # mask is useful in trainingif 'mask0' in data:mask_c0, mask_c1 = data['mask0'].flatten(-2), data['mask1'].flatten(-2)# 进入transformer模块,这是论文的核心模块feat_c0, feat_c1 = self.loftr_coarse(feat_c0, feat_c1, mask_c0, mask_c1)print(feat_c0.shape)print(feat_c1.shape)进入self.loftr_coarse模块,这里需要计算自身的attention注意力,还需要将两张图像计算cross attention,从代码中的循环中可以看到,self和cross两种操作分别是自己和自己计算注意力以及自己和其他特征图计算注意力,从layer的计算参数可以明确这一点。
def forward(self, feat0, feat1, mask0=None, mask1=None):"""Args:feat0 (torch.Tensor): [N, L, C]feat1 (torch.Tensor): [N, S, C]mask0 (torch.Tensor): [N, L] (optional)mask1 (torch.Tensor): [N, S] (optional)"""assert self.d_model == feat0.size(2), "the feature number of src and transformer must be equal"for layer, name in zip(self.layers, self.layer_names):if name == 'self':feat0 = layer(feat0, feat0, mask0, mask0)print(feat0.shape)feat1 = layer(feat1, feat1, mask1, mask1)print(feat1.shape)elif name == 'cross':feat0 = layer(feat0, feat1, mask0, mask1)print(feat0.shape)feat1 = layer(feat1, feat0, mask1, mask0)print(feat1.shape)else:raise KeyErrorprint(feat0.shape)print(feat1.shape)return feat0, feat1具体的计算layer在LoFTREncoderLayer定义中,这里就是基本的attention计算方法,主要是QKV的计算和一些线性计算、连接操作。
def forward(self, x, source, x_mask=None, source_mask=None):"""Args:x (torch.Tensor): [N, L, C]source (torch.Tensor): [N, S, C]x_mask (torch.Tensor): [N, L] (optional)source_mask (torch.Tensor): [N, S] (optional)"""bs = x.size(0)query, key, value = x, source, source# multi-head attentionquery = self.q_proj(query).view(bs, -1, self.nhead, self.dim) # [N, L, (H, D)]key = self.k_proj(key).view(bs, -1, self.nhead, self.dim) # [N, S, (H, D)]value = self.v_proj(value).view(bs, -1, self.nhead, self.dim)message = self.attention(query, key, value, q_mask=x_mask, kv_mask=source_mask) # [N, L, (H, D)]message = self.merge(message.view(bs, -1, self.nhead*self.dim)) # [N, L, C]message = self.norm1(message)# feed-forward networkmessage = self.mlp(torch.cat([x, message], dim=2))message = self.norm2(message)return x + message粗粒度匹配模块 match coarse-level
# 3. match coarse-levelself.coarse_matching(feat_c0, feat_c1, data, mask_c0=mask_c0, mask_c1=mask_c1)跟入coarse_matching模块
通过注意力机制获取到两个图像的特征图,进入到粗粒度匹配模块,粗粒度匹配是采用的内积的计算方式,即下面代码的torch.einsum计算,然后通过softmax转成概率值。
def forward(self, feat_c0, feat_c1, data, mask_c0=None, mask_c1=None):"""Args:feat0 (torch.Tensor): [N, L, C]feat1 (torch.Tensor): [N, S, C]data (dict)mask_c0 (torch.Tensor): [N, L] (optional)mask_c1 (torch.Tensor): [N, S] (optional)Update:data (dict): {'b_ids' (torch.Tensor): [M'],'i_ids' (torch.Tensor): [M'],'j_ids' (torch.Tensor): [M'],'gt_mask' (torch.Tensor): [M'],'mkpts0_c' (torch.Tensor): [M, 2],'mkpts1_c' (torch.Tensor): [M, 2],'mconf' (torch.Tensor): [M]}NOTE: M' != M during training."""N, L, S, C = feat_c0.size(0), feat_c0.size(1), feat_c1.size(1), feat_c0.size(2)# normalizefeat_c0, feat_c1 = map(lambda feat: feat / feat.shape[-1]**.5,[feat_c0, feat_c1])if self.match_type == 'dual_softmax':sim_matrix = torch.einsum("nlc,nsc->nls", feat_c0,feat_c1) / self.temperatureprint(sim_matrix.shape)if mask_c0 is not None:sim_matrix.masked_fill_(~(mask_c0[..., None] * mask_c1[:, None]).bool(),-INF)conf_matrix = F.softmax(sim_matrix, 1) * F.softmax(sim_matrix, 2)print(conf_matrix.shape)elif self.match_type == 'sinkhorn':# sinkhorn, dustbin includedsim_matrix = torch.einsum("nlc,nsc->nls", feat_c0, feat_c1)if mask_c0 is not None:sim_matrix[:, :L, :S].masked_fill_(~(mask_c0[..., None] * mask_c1[:, None]).bool(),-INF)# build uniform prior & use sinkhornlog_assign_matrix = self.log_optimal_transport(sim_matrix, self.bin_score, self.skh_iters)assign_matrix = log_assign_matrix.exp()conf_matrix = assign_matrix[:, :-1, :-1]# filter prediction with dustbin score (only in evaluation mode)if not self.training and self.skh_prefilter:filter0 = (assign_matrix.max(dim=2)[1] == S)[:, :-1] # [N, L]filter1 = (assign_matrix.max(dim=1)[1] == L)[:, :-1] # [N, S]conf_matrix[filter0[..., None].repeat(1, 1, S)] = 0conf_matrix[filter1[:, None].repeat(1, L, 1)] = 0if self.config['sparse_spvs']:data.update({'conf_matrix_with_bin': assign_matrix.clone()})data.update({'conf_matrix': conf_matrix})# predict coarse matches from conf_matrixdata.update(**self.get_coarse_match(conf_matrix, data))跟入get_coarse_match模块
通过softmax获取到概率值之后,然后根据阈值使用mask矩阵过滤掉低于阈值的值,然后使用互最近邻来确定互相匹配关系。
def get_coarse_match(self, conf_matrix, data):"""Args:conf_matrix (torch.Tensor): [N, L, S]data (dict): with keys ['hw0_i', 'hw1_i', 'hw0_c', 'hw1_c']Returns:coarse_matches (dict): {'b_ids' (torch.Tensor): [M'],'i_ids' (torch.Tensor): [M'],'j_ids' (torch.Tensor): [M'],'gt_mask' (torch.Tensor): [M'],'m_bids' (torch.Tensor): [M],'mkpts0_c' (torch.Tensor): [M, 2],'mkpts1_c' (torch.Tensor): [M, 2],'mconf' (torch.Tensor): [M]}"""axes_lengths = {'h0c': data['hw0_c'][0],'w0c': data['hw0_c'][1],'h1c': data['hw1_c'][0],'w1c': data['hw1_c'][1]}_device = conf_matrix.device# 1. confidence thresholdingmask = conf_matrix > self.thrprint(mask.shape)mask = rearrange(mask, 'b (h0c w0c) (h1c w1c) -> b h0c w0c h1c w1c',**axes_lengths)print(mask.shape)if 'mask0' not in data:mask_border(mask, self.border_rm, False)else:mask_border_with_padding(mask, self.border_rm, False,data['mask0'], data['mask1'])mask = rearrange(mask, 'b h0c w0c h1c w1c -> b (h0c w0c) (h1c w1c)',**axes_lengths)print(mask.shape)# 2. mutual nearestprint(conf_matrix.max(dim=2, keepdim=True)[0].shape)mask = mask \* (conf_matrix == conf_matrix.max(dim=2, keepdim=True)[0]) \* (conf_matrix == conf_matrix.max(dim=1, keepdim=True)[0])print(mask.shape)# 3. find all valid coarse matches# this only works when at most one `True` in each rowmask_v, all_j_ids = mask.max(dim=2)print(mask_v.shape)print(all_j_ids.shape)b_ids, i_ids = torch.where(mask_v)print(b_ids.shape)print(i_ids.shape)j_ids = all_j_ids[b_ids, i_ids]print(j_ids.shape)mconf = conf_matrix[b_ids, i_ids, j_ids]print(mconf.shape)# 4. Random sampling of training samples for fine-level LoFTR# (optional) pad samples with gt coarse-level matchesif self.training:# NOTE:# The sampling is performed across all pairs in a batch without manually balancing# #samples for fine-level increases w.r.t. batch_sizeif 'mask0' not in data:num_candidates_max = mask.size(0) * max(mask.size(1), mask.size(2))else:num_candidates_max = compute_max_candidates(data['mask0'], data['mask1'])num_matches_train = int(num_candidates_max *self.train_coarse_percent)num_matches_pred = len(b_ids)assert self.train_pad_num_gt_min < num_matches_train, "min-num-gt-pad should be less than num-train-matches"# pred_indices is to select from predictionif num_matches_pred <= num_matches_train - self.train_pad_num_gt_min:pred_indices = torch.arange(num_matches_pred, device=_device)else:pred_indices = torch.randint(num_matches_pred,(num_matches_train - self.train_pad_num_gt_min, ),device=_device)# gt_pad_indices is to select from gt padding. e.g. max(3787-4800, 200)gt_pad_indices = torch.randint(len(data['spv_b_ids']),(max(num_matches_train - num_matches_pred,self.train_pad_num_gt_min), ),device=_device)mconf_gt = torch.zeros(len(data['spv_b_ids']), device=_device) # set conf of gt paddings to all zerob_ids, i_ids, j_ids, mconf = map(lambda x, y: torch.cat([x[pred_indices], y[gt_pad_indices]],dim=0),*zip([b_ids, data['spv_b_ids']], [i_ids, data['spv_i_ids']],[j_ids, data['spv_j_ids']], [mconf, mconf_gt]))# These matches select patches that feed into fine-level networkcoarse_matches = {'b_ids': b_ids, 'i_ids': i_ids, 'j_ids': j_ids}# 4. Update with matches in original image resolutionscale = data['hw0_i'][0] / data['hw0_c'][0]scale0 = scale * data['scale0'][b_ids] if 'scale0' in data else scalescale1 = scale * data['scale1'][b_ids] if 'scale1' in data else scalemkpts0_c = torch.stack([i_ids % data['hw0_c'][1], i_ids // data['hw0_c'][1]],dim=1) * scale0mkpts1_c = torch.stack([j_ids % data['hw1_c'][1], j_ids // data['hw1_c'][1]],dim=1) * scale1# These matches is the current prediction (for visualization)coarse_matches.update({'gt_mask': mconf == 0,'m_bids': b_ids[mconf != 0], # mconf == 0 => gt matches'mkpts0_c': mkpts0_c[mconf != 0],'mkpts1_c': mkpts1_c[mconf != 0],'mconf': mconf[mconf != 0]})return coarse_matches精细化调整 fine-level refinement
# 4. fine-level refinement# 预处理操作,拆解特征图,提取匹配到的候选点feat_f0_unfold, feat_f1_unfold = self.fine_preprocess(feat_f0, feat_f1, feat_c0, feat_c1, data)if feat_f0_unfold.size(0) != 0: # at least one coarse level predictedfeat_f0_unfold, feat_f1_unfold = self.loftr_fine(feat_f0_unfold, feat_f1_unfold)细粒度匹配 match fine-level
跳入FineMatching的forward函数中
原文中使用55的矩阵进行细粒度匹配,这里匹配的时候会计算55矩阵中各个点与中间点的关系,生成热度图heatmap,然后计算这个热度图的期望dsnt.spatial_expectation2d,然后还原到图像中即可。
def forward(self, feat_f0, feat_f1, data):"""Args:feat0 (torch.Tensor): [M, WW, C]feat1 (torch.Tensor): [M, WW, C]data (dict)Update:data (dict):{'expec_f' (torch.Tensor): [M, 3],'mkpts0_f' (torch.Tensor): [M, 2],'mkpts1_f' (torch.Tensor): [M, 2]}"""M, WW, C = feat_f0.shapeW = int(math.sqrt(WW))scale = data['hw0_i'][0] / data['hw0_f'][0]self.M, self.W, self.WW, self.C, self.scale = M, W, WW, C, scale# corner case: if no coarse matches foundif M == 0:assert self.training == False, "M is always >0, when training, see coarse_matching.py"# logger.warning('No matches found in coarse-level.')data.update({'expec_f': torch.empty(0, 3, device=feat_f0.device),'mkpts0_f': data['mkpts0_c'],'mkpts1_f': data['mkpts1_c'],})returnfeat_f0_picked = feat_f0_picked = feat_f0[:, WW//2, :]print(feat_f0_picked.shape)sim_matrix = torch.einsum('mc,mrc->mr', feat_f0_picked, feat_f1)print(sim_matrix.shape)softmax_temp = 1. / C**.5heatmap = torch.softmax(softmax_temp * sim_matrix, dim=1).view(-1, W, W)print(heatmap.shape)# compute coordinates from heatmapcoords_normalized = dsnt.spatial_expectation2d(heatmap[None], True)[0] # [M, 2]print(coords_normalized.shape)grid_normalized = create_meshgrid(W, W, True, heatmap.device).reshape(1, -1, 2) # [1, WW, 2]print(grid_normalized.shape)# compute std over <x, y>var = torch.sum(grid_normalized**2 * heatmap.view(-1, WW, 1), dim=1) - coords_normalized**2 # [M, 2]std = torch.sum(torch.sqrt(torch.clamp(var, min=1e-10)), -1) # [M] clamp needed for numerical stability# for fine-level supervisiondata.update({'expec_f': torch.cat([coords_normalized, std.unsqueeze(1)], -1)})# compute absolute kpt coordsself.get_fine_match(coords_normalized, data)总结
本周我阅读了LoFTR方法,该方法为局部图像特征匹配领域带来了一种新颖的思路。传统的图像特征匹配流程通常包括特征检测、特征描述和特征匹配三个独立阶段。然而,LoFTR打破了这一传统框架,通过结合Transformer架构,直接在像素级别上建立粗匹配,并随后在精细级别上优化这些匹配。下一周我将开始EfficientLoFTR的学习。