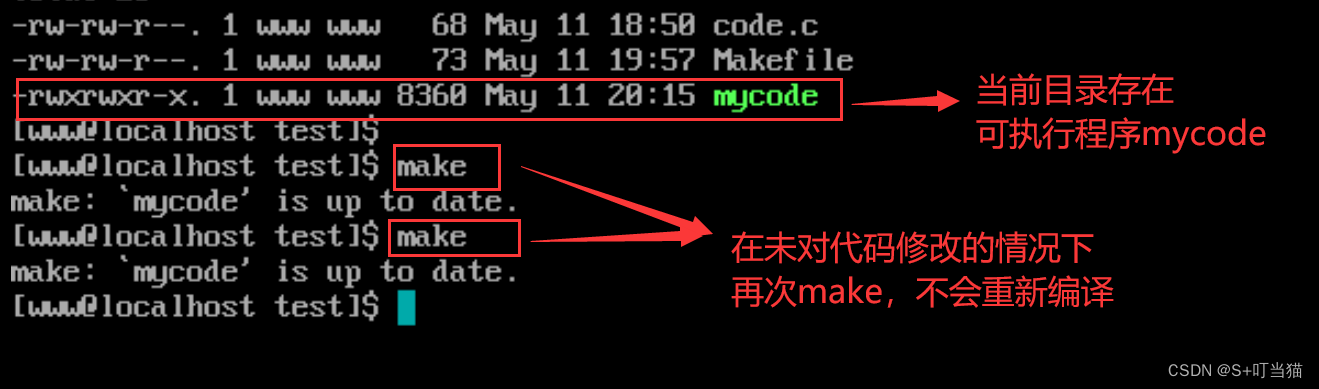
源码
CC ?= clang
CFLAGS = -Ofast -Wno-unused-result -Wno-ignored-pragmas -Wno-unknown-attributes
LDFLAGS =
LDLIBS = -lm
INCLUDES =
CFLAGS_COND = -march=native# Find nvcc
SHELL_UNAME = $(shell uname)
REMOVE_FILES = rm -f
OUTPUT_FILE = -o $@
CUDA_OUTPUT_FILE = -o $@# NVCC flags
# -t=0 is short for --threads, 0 = number of CPUs on the machine
NVCC_FLAGS = -O3 -t=0 --use_fast_math
NVCC_LDFLAGS = -lcublas -lcublasLt
NVCC_INCLUDES =
NVCC_LDLIBS =
NCLL_INCUDES =
NVCC_CUDNN =
# overridable flag for multi-GPU training. by default we won't build with cudnn
# because it bloats up the compile time from a few seconds to ~minute
USE_CUDNN ?= 0# autodect a lot of various supports on current platform
$(info ---------------------------------------------)ifneq ($(OS), Windows_NT)NVCC := $(shell which nvcc 2>/dev/null)# Function to test if the compiler accepts a given flag.define check_and_add_flag$(eval FLAG_SUPPORTED := $(shell printf "int main() { return 0; }\n" | $(CC) $(1) -x c - -o /dev/null 2>/dev/null && echo 'yes'))ifeq ($(FLAG_SUPPORTED),yes)CFLAGS += $(1)endifendef# Check each flag and add it if supported$(foreach flag,$(CFLAGS_COND),$(eval $(call check_and_add_flag,$(flag))))
elseCFLAGS :=REMOVE_FILES = del *.exe,*.obj,*.lib,*.exp,*.pdb && delSHELL_UNAME := Windowsifneq ($(shell where nvcc 2> nul),"")NVCC := nvccelseNVCC :=endifCC := clCFLAGS = /Idev /Zi /nologo /Wall /WX- /diagnostics:column /sdl /O2 /Oi /Ot /GL /D _DEBUG /D _CONSOLE /D _UNICODE /D UNICODE /Gm- /EHsc /MD /GS /Gy /fp:fast /Zc:wchar_t /Zc:forScope /Zc:inline /permissive- \/external:W3 /Gd /TP /wd4996 /Fd$@.pdb /FC /openmp:llvmLDFLAGS :=LDLIBS :=INCLUDES :=NVCC_FLAGS += -I"dev"ifeq ($(WIN_CI_BUILD),1)$(info Windows CI build)OUTPUT_FILE = /link /OUT:$@CUDA_OUTPUT_FILE = -o $@else$(info Windows local build)OUTPUT_FILE = /link /OUT:$@ && copy /Y $@ $@.exeCUDA_OUTPUT_FILE = -o $@ && copy /Y $@.exe $@endif
endif# Check and include cudnn if available
# Currently hard-coding a bunch of stuff here for Linux, todo make this better/nicer
# You need cuDNN from: https://developer.nvidia.com/cudnn
# Follow the apt-get instructions
# And the cuDNN front-end from: https://github.com/NVIDIA/cudnn-frontend/tree/main
# For this there is no installation, just download the repo to your home directory
# and then we include it below (see currently hard-coded path assumed in home directory)
ifeq ($(USE_CUDNN), 1)ifeq ($(SHELL_UNAME), Linux)# hard-coded path for nowCUDNN_FRONTEND_PATH := $(HOME)/cudnn-frontend/includeifeq ($(shell [ -d $(CUDNN_FRONTEND_PATH) ] && echo "exists"), exists)$(info ✓ cuDNN found, will run with flash-attention)NVCC_INCLUDES += -I$(CUDNN_FRONTEND_PATH)NVCC_LDFLAGS += -lcudnnNVCC_FLAGS += -DENABLE_CUDNNNVCC_CUDNN = cudnn_att.oelse$(error ✗ cuDNN not found. See the Makefile for our currently hard-coded paths / install instructions)endifelse$(info → cuDNN is not supported right now outside of Linux)endif
else$(info → cuDNN is manually disabled by default, run make with `USE_CUDNN=1` to try to enable)
endif# Check if OpenMP is available
# This is done by attempting to compile an empty file with OpenMP flags
# OpenMP makes the code a lot faster so I advise installing it
# e.g. on MacOS: brew install libomp
# e.g. on Ubuntu: sudo apt-get install libomp-dev
# later, run the program by prepending the number of threads, e.g.: OMP_NUM_THREADS=8 ./gpt2
# First, check if NO_OMP is set to 1, if not, proceed with the OpenMP checks
ifeq ($(NO_OMP), 1)$(info OpenMP is manually disabled)
elseifneq ($(OS), Windows_NT)# Detect if running on macOS or Linuxifeq ($(SHELL_UNAME), Darwin)# Check for Homebrew's libomp installation in different common directoriesifeq ($(shell [ -d /opt/homebrew/opt/libomp/lib ] && echo "exists"), exists)# macOS with Homebrew on ARM (Apple Silicon)CFLAGS += -Xclang -fopenmp -DOMPLDFLAGS += -L/opt/homebrew/opt/libomp/libLDLIBS += -lompINCLUDES += -I/opt/homebrew/opt/libomp/include$(info ✓ OpenMP found)else ifeq ($(shell [ -d /usr/local/opt/libomp/lib ] && echo "exists"), exists)# macOS with Homebrew on IntelCFLAGS += -Xclang -fopenmp -DOMPLDFLAGS += -L/usr/local/opt/libomp/libLDLIBS += -lompINCLUDES += -I/usr/local/opt/libomp/include$(info ✓ OpenMP found)else$(info ✗ OpenMP not found)endifelse# Check for OpenMP support in GCC or Clang on Linuxifeq ($(shell echo | $(CC) -fopenmp -x c -E - > /dev/null 2>&1; echo $$?), 0)CFLAGS += -fopenmp -DOMPLDLIBS += -lgomp$(info ✓ OpenMP found)else$(info ✗ OpenMP not found)endifendifendif
endif# Check if OpenMPI and NCCL are available, include them if so, for multi-GPU training
ifeq ($(NO_MULTI_GPU), 1)$(info → Multi-GPU (OpenMPI + NCCL) is manually disabled)
elseifneq ($(OS), Windows_NT)# Detect if running on macOS or Linuxifeq ($(SHELL_UNAME), Darwin)$(info ✗ Multi-GPU on CUDA on Darwin is not supported, skipping OpenMPI + NCCL support)else ifeq ($(shell [ -d /usr/lib/x86_64-linux-gnu/openmpi/lib/ ] && [ -d /usr/lib/x86_64-linux-gnu/openmpi/include/ ] && echo "exists"), exists)$(info ✓ OpenMPI found, OK to train with multiple GPUs)NVCC_INCLUDES += -I/usr/lib/x86_64-linux-gnu/openmpi/includeNVCC_LDFLAGS += -L/usr/lib/x86_64-linux-gnu/openmpi/lib/NVCC_LDLIBS += -lmpi -lncclNVCC_FLAGS += -DMULTI_GPUelse$(info ✗ OpenMPI is not found, disabling multi-GPU support)$(info ---> On Linux you can try install OpenMPI with `sudo apt install openmpi-bin openmpi-doc libopenmpi-dev`)endifendif
endif# Precision settings, default to bf16 but ability to override
PRECISION ?= BF16
VALID_PRECISIONS := FP32 FP16 BF16
ifeq ($(filter $(PRECISION),$(VALID_PRECISIONS)),)$(error Invalid precision $(PRECISION), valid precisions are $(VALID_PRECISIONS))
endif
ifeq ($(PRECISION), FP32)PFLAGS = -DENABLE_FP32
else ifeq ($(PRECISION), FP16)PFLAGS = -DENABLE_FP16
elsePFLAGS = -DENABLE_BF16
endif# PHONY means these targets will always be executed
.PHONY: all train_gpt2 test_gpt2 train_gpt2cu test_gpt2cu train_gpt2fp32cu test_gpt2fp32cu profile_gpt2cu# Add targets
TARGETS = train_gpt2 test_gpt2# Conditional inclusion of CUDA targets
ifeq ($(NVCC),)$(info ✗ nvcc not found, skipping GPU/CUDA builds)
else$(info ✓ nvcc found, including GPU/CUDA support)TARGETS += train_gpt2cu test_gpt2cu train_gpt2fp32cu test_gpt2fp32cu
endif$(info ---------------------------------------------)all: $(TARGETS)train_gpt2: train_gpt2.c$(CC) $(CFLAGS) $(INCLUDES) $(LDFLAGS) $< $(LDLIBS) $(OUTPUT_FILE)test_gpt2: test_gpt2.c$(CC) $(CFLAGS) $(INCLUDES) $(LDFLAGS) $< $(LDLIBS) $(OUTPUT_FILE)cudnn_att.o: cudnn_att.cu$(NVCC) -c $(NVCC_FLAGS) $(PFLAGS) $< $(NVCC_LDFLAGS) $(NVCC_INCLUDES) $(NVCC_LDLIBS)train_gpt2cu: train_gpt2.cu $(NVCC_CUDNN)$(NVCC) $(NVCC_FLAGS) $(PFLAGS) $< $(NVCC_LDFLAGS) $(NVCC_INCLUDES) $(NVCC_LDLIBS) $(CUDA_OUTPUT_FILE) $(NVCC_CUDNN)train_gpt2fp32cu: train_gpt2_fp32.cu$(NVCC) $(NVCC_FLAGS) $< $(NVCC_LDFLAGS) $(NVCC_INCLUDES) $(NVCC_LDLIBS) $(CUDA_OUTPUT_FILE)test_gpt2cu: test_gpt2.cu $(NVCC_CUDNN)$(NVCC) $(NVCC_FLAGS) $(PFLAGS) $< $(NVCC_LDFLAGS) $(NVCC_INCLUDES) $(NVCC_LDLIBS) $(CUDA_OUTPUT_FILE) $(NVCC_CUDNN)test_gpt2fp32cu: test_gpt2_fp32.cu$(NVCC) $(NVCC_FLAGS) $< $(NVCC_LDFLAGS) $(NVCC_INCLUDES) $(NVCC_LDLIBS) $(CUDA_OUTPUT_FILE)profile_gpt2cu: profile_gpt2.cu $(NVCC_CUDNN)$(NVCC) $(NVCC_FLAGS) $(PFLAGS) -lineinfo $< $(NVCC_LDFLAGS) $(NVCC_INCLUDES) $(NVCC_LDLIBS) $(CUDA_OUTPUT_FILE) $(NVCC_CUDNN)clean:$(REMOVE_FILES) $(TARGETS)

解读
这是一个使用 CUDA 和一些可选的其他库(如 cuDNN、OpenMPI、NCCL)的项目的 Makefile,它用于编译和链接 C 和 CUDA 程序。以下是主要部分的中文解读:
- 定义了一些变量,用于存储编译器选项(如 CFLAGS)、库(`LDLIBS`)、包含文件路径(`INCLUDES`),以及一些条件编译标志(`CFLAGS_COND`)。
- 检测系统类型,配置对应的命令和变量,比如在 Windows 系统上使用 cl 编译器和删除文件的命令。
- 通过命令查找 nvcc 编译器的路径,这是 NVIDIA 的 CUDA 编译器。
- 检查并且添加支持的编译器标志。
- 如果设置了 USE_CUDNN 变量,并且在 Linux 系统上找到了 cuDNN 库和头文件路径,那么就将 cuDNN 加入编译选项中。
- 检查 OpenMP 支持,如果支持,那么添加 OpenMP 相关的编译选项。
- 检查是否存在 OpenMPI 和 NCCL 支持,这两者用于多 GPU 训练。
- 设置精度选项,可以是 FP32(单精度)、`FP16`(半精度)或 BF16(谷歌的半精度格式)。
- 定义了一系列的伪目标(`.PHONY`),用于编译和测试不同配置下的项目。
- 根据环境配置和 nvcc 的存在与否,确定要构建的目标(`TARGETS`)。
- 最后,定义了各种编译目标的规则,用于编译和链接程序,以及一个 clean 目标用于清除生成的文件。
整个 Makefile 通过多个检测和条件判断,智能地配置了编译环境,并提供了灵活的编译选项,以便利用 CUDA 加速 GPU 编程。

为了将上面提供的NVIDIA CUDA GPU Makefile修改为适用于AMD GPU平台的Makefile,我们需要使用AMD的ROCm工具链而不是NVIDIA的 CUDA 和 cuDNN 库。下面是如何进行一些基本转换的一个示例:
# ROCm configuration
ROCm_PATH ?= /opt/rocm
HIPCC := $(ROCm_PATH)/bin/hipcc# Common flags
CFLAGS = -O3 -Wall -Wextra
LDFLAGS =
LDLIBS = -lm# AMD GPU specific flags
HIPCC_FLAGS = -O3 --amdgpu-target=gfx803 # You might want to specify your own GPU architecture here
HIPCC_LDFLAGS =
HIPCC_INCLUDES =
HIPCC_LDLIBS =# PHONY targets - these recipes will always be run
.PHONY: all clean# Add targets
TARGETS = train_gpt2 test_gpt2all: $(TARGETS)train_gpt2: train_gpt2.cpp$(HIPCC) $(CFLAGS) $(HIPCC_INCLUDES) $(LDFLAGS) $< $(LDLIBS) -o $@test_gpt2: test_gpt2.cpp$(HIPCC) $(CFLAGS) $(HIPCC_INCLUDES) $(LDFLAGS) $< $(LDLIBS) -o $@clean:rm -f $(TARGETS)这个示例 Makefile 使用了 hipcc 编译器,它是ROCm工具链的一部分,用以支持AMD GPU上的GPU计算。请注意以下几点:
1. $(ROCm_PATH) 为ROCm安装路径,默认通常为 /opt/rocm,但你需要根据管路上具体的安装位置进行相应调整。
2. $(HIPCC) 被设置成ROCm工具链中的 hipcc 编译器的路径。
3. 我们为 HIPCC_FLAGS 添加了一个 -O3 优化标志和一个 --amdgpu-target 参数,该参数后跟的是你期望代码运行的具体AMD GPU架构,如 gfx803。基于你使用的GPU,你可能需要更改这个参数。
4. 所有原有的CUDA相关变量和规则(例如 NVCC_FLAGS、`NVCC_LDLIBS`、`cudnn_att.o`、`train_gpt2cu` 等)都被移除或替换为适合AMD平台的变量和规则。
5. 目标名称(train_gpt2、test_gpt2等)和源文件名现在反映了其作为C++源的性质。
6. 由于AMD GPU不支持cuDNN,所以我们移除了所有与cuDNN相关的配置项。
对于其他使用了 (CUDA_)OUTPUT_FILE 和 REMOVE_FILES 变量的规则,需要根据上下文具体情况进行必要的调整。
这个Makefile还十分简化,以说明AMD GPU 平台的CPU/GPU编译过程。在实际情况中,你可能需要进一步适应其他库的链接(例如 ROCm 的 rocBLAS、`MIOpen` 等等),并进行跟你的应用相关的其他调整。请参照ROCm官方文档获取更多信息。