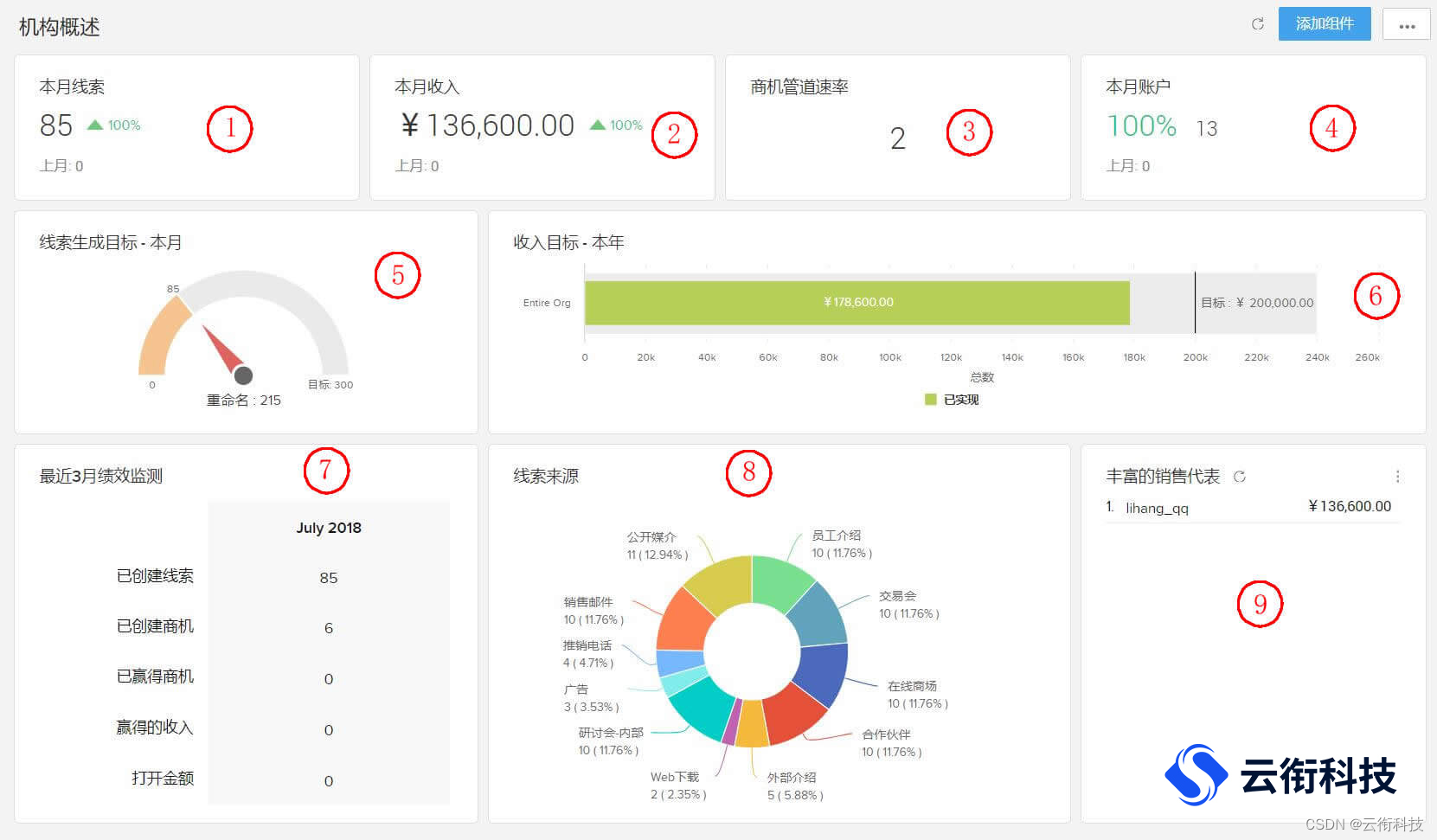
背景
dev环境新买了一块固态,插到pve主板的第二个M.2槽位不能识别,通过其他机器排查后确定是这台pve的槽位问题。
同时这台pve还有一些其他的lvm历史遗留问题,具体表现是每次开机很长,因为要扫描那块机械硬盘做的lvm
所以决定将这台pve重新安装到新买的固态盘中,并重新加入集群
实施
制作PVE启动盘,查到机器上安装,常规操作,没对pve的启动grub等做定制化。
配置IP,掩码,域名,主机名,重启机器,进入网页,一切正常,配置允许ssh远程连接,修改root密码
踢出集群
将旧的pve踢出集群,
登录集群中任意一台存活的pve
# 查看pve的版本
root@dev-pve-node2:~# pveversion -v
root@dev-pve-node2:~# pveversion -v
proxmox-ve: 7.1-1 (running kernel: 5.13.19-2-pve)
pve-manager: 7.1-7 (running version: 7.1-7/df5740ad)
# 由于操作的过程中未记录,这里是操作完成后记录
root@dev-pve-node2:~# pvecm status
Cluster information
-------------------
Name: dev-pve-group
Config Version: 7
Transport: knet
Secure auth: onQuorum information
------------------
Date: Tue May 14 17:31:59 2024
Quorum provider: corosync_votequorum
Nodes: 3
Node ID: 0x00000002
Ring ID: 1.ee0
Quorate: YesVotequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate Membership information
----------------------Nodeid Votes Name
0x00000001 1 192.168.1.74 # 这台是新家的
0x00000002 1 192.168.1.75 (local)
0x00000003 1 192.168.3.222# 从集群中删除
root@dev-pve-node2:~# pvecm delnode dev-pve-node01
# 删除node01的密钥
root@dev-pve-node2:~# vim /etc/pve/priv/authorized_keys
root@dev-pve-node2:~# vim /etc/pve/priv/known_hosts# 移除配置文件
root@dev-pve-node2:~# cd /etc/pve/nodes/
root@dev-pve-node2:~# mv dev-pve-node01/ /tmp/
然后登陆网页端过一会刷新一下,可以看到退出集群的pve node消失不见
配置新的pve
将遗留问题 机械硬盘中的lvm删除,
root@pve-node01:~# lvdisplay
root@pve-node01:~# lvchange -ay vmdata/vmstore01
root@pve-node01:~# lvremove /dev/vmdata/vm-113-disk-1
root@pve-node01:~# lvremove /dev/vmdata/vm-113-disk-1
root@pve-node01:~# lvremove /dev/vmdata/vm-113-disk-2
root@pve-node01:~# lvremove /dev/vmdata/base-124-disk-0
root@pve-node01:~# lvremove /dev/vmdata/vm-201-disk-0
root@pve-node01:~# lvremove /dev/vmdata/vm-101-disk-0
# 移除vg
root@pve-node01:~# vgremove vmdata
# 移除pv
root@pve-node01:~# pvremove /dev/sda1
# 关闭swap
swapoff -a
重启机器测试开机是否仍然会卡在lvm扫描阶段,预期结果:不会;事实:不会。
将新的pve节点加入集群
在旧的pve集群web界面点击datacen,点击cluster,点击join information
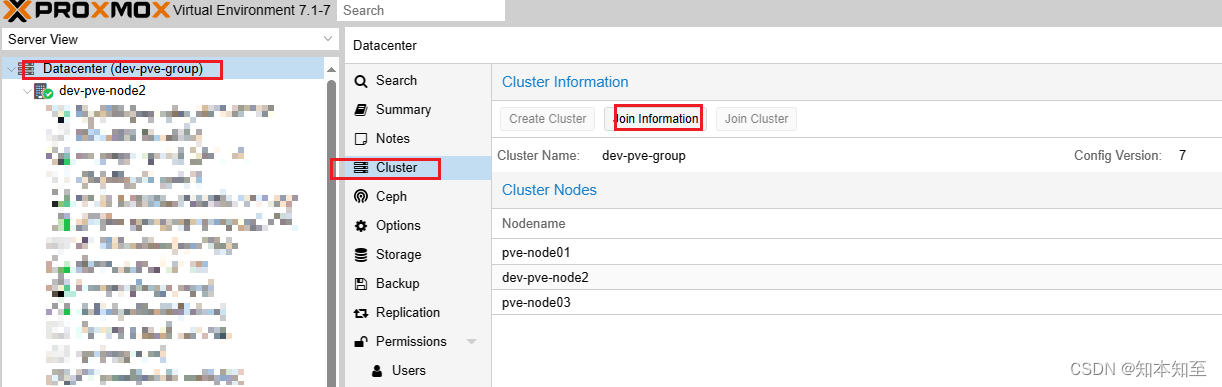
点击复制按钮,到新节点的web界面粘贴,过一会就加入成功了。root密码可以验证一下再粘贴进去
重建k8s集群中的位于pve-node1上的master节点
由于k8s的其中一个master节点是放在pve-node1上的,重新安装了pve,所以需要重新部署master节点
下载免安装镜像配合pve的cloud init用于在pve中安装ubuntu系统,这里同集群保持一致,使用1804版本
https://cloud-images.ubuntu.com/
下载好的镜像xftp上传至pve
web界面新建机器,删掉磁盘,删掉cdrom,
进入命令行导入下载的img文件
qm importdisk 101 bionic-server-cloudimg-amd64.img local-lvm
导入之后,web界面的101虚拟机会显示有一块unused的磁盘,双击启用,
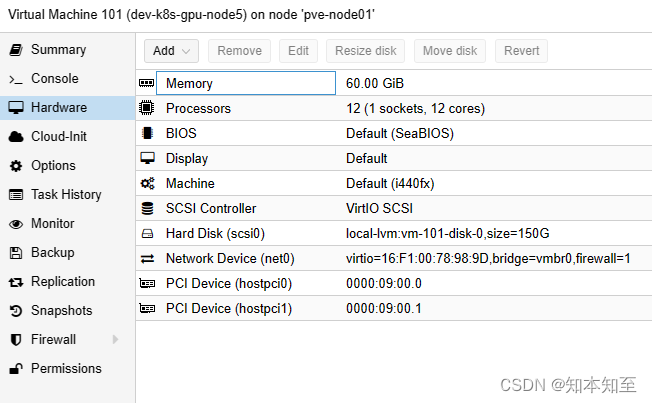
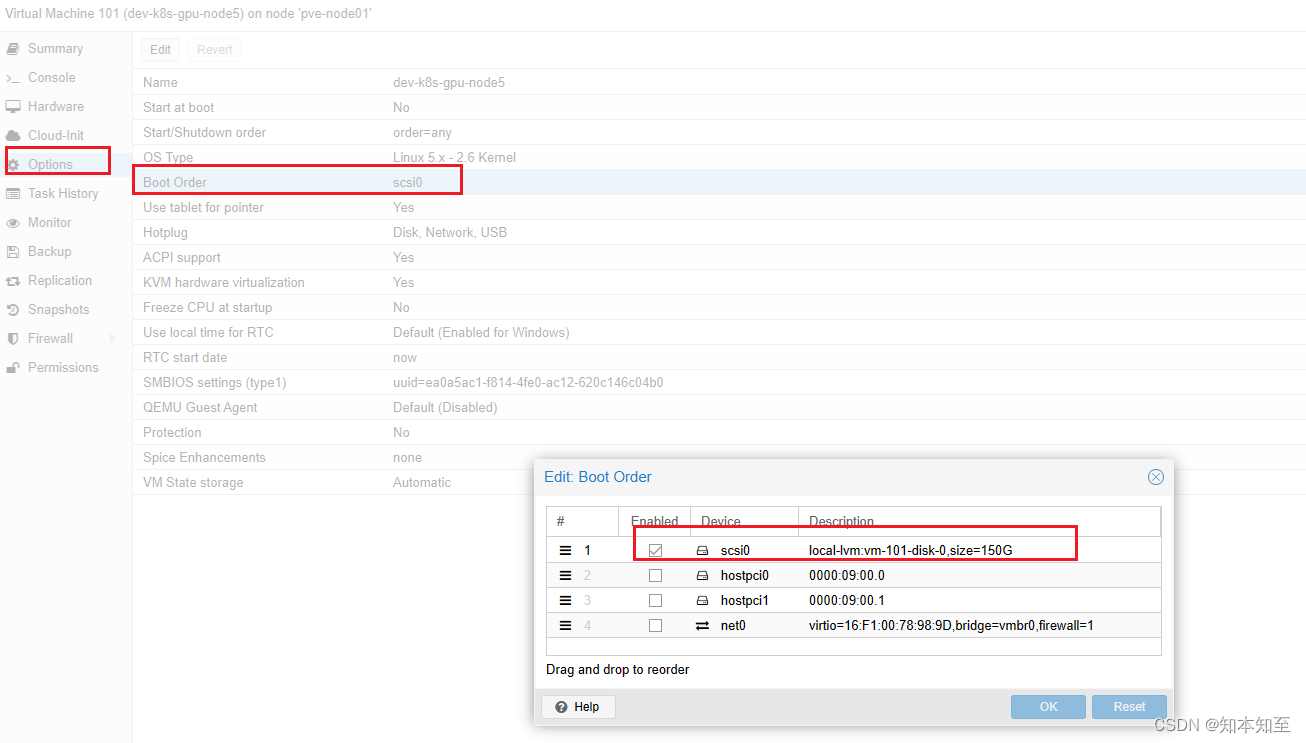
配置启动顺序,
添加硬件cloud init
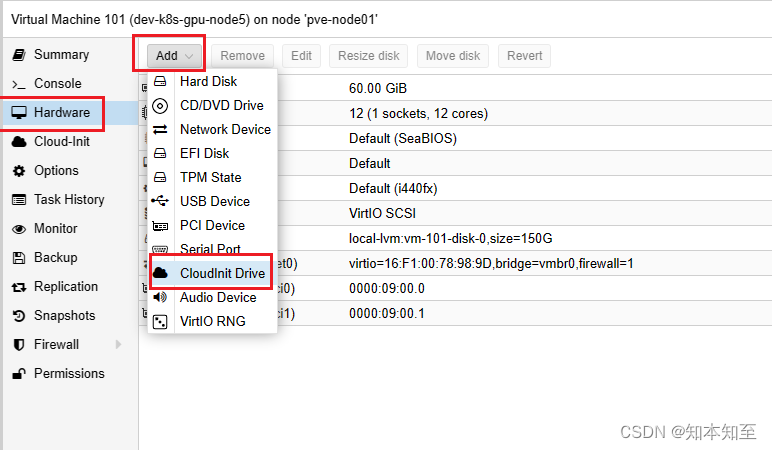
配置cloud init注入内容.
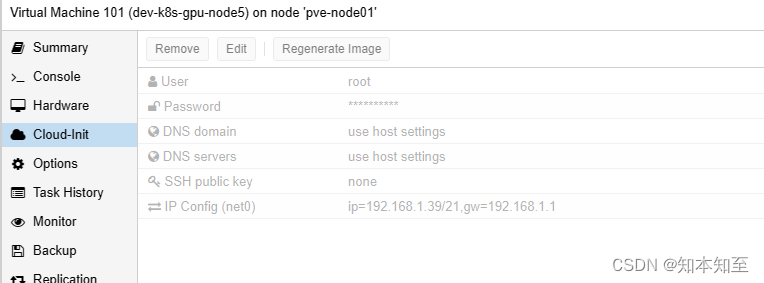 开机
开机
如果cloud init未添加ssh公钥,则需要用控制台修改一下机器的sshd服务配置允许root用户远程密码登录
注意:默认导入的只有2G的磁盘文件,关机之后选中磁盘点击resize disk进行扩容,再到机器中扩容分区及文件系统
验证注入的内容
root@k8s-gpu-node5:~# cat /etc/netplan/50-cloud-init.yaml
# This file is generated from information provided by the datasource. Changes
# to it will not persist across an instance reboot. To disable cloud-init's
# network configuration capabilities, write a file
# /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following:
# network: {config: disabled}
network:version: 2ethernets:eth0:addresses:- 192.168.1.39/21match:macaddress: 16:f1:00:78:98:9dnameservers:addresses:- 192.168.1.220routes:- to: 0.0.0.0/0via: 192.168.1.1set-name: eth0
调优master节点
timedatectl set-timezone Asia/Shanghairoot@dev-k8s-master02:~# tail -n 20 /etc/sysctl.conf
#kernel.sysrq=1###################################################################
# Protected links
#
# Protects against creating or following links under certain conditions
# Debian kernels have both set to 1 (restricted)
# See https://www.kernel.org/doc/Documentation/sysctl/fs.txt
#fs.protected_hardlinks=0
#fs.protected_symlinks=0
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-arptables = 1
net.ipv4.tcp_tw_reuse = 0
net.core.somaxconn = 32768
net.netfilter.nf_conntrack_max = 1000000
vm.swappiness = 0
vm.max_map_count = 655360
fs.file-max = 6553600# 加载内核中的模块
modprobe br_netfilter
modprobe ip_conntrack
# 配置生效
sysctl -p
配置docker,由于内网中配置了全局科学上网代理工具,此处直接把网关暂时指向机器即可按照docker官方配置来复制粘贴
apt -y install apt-transport-https ca-certificates curl software-properties-common
# 添加apt证书
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg |sudo apt-key add -
# 若机器有安装,则先卸载
for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; doneinstall -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 验证源
root@dev-k8s-master02:~# cat /etc/apt/sources.list.d/docker.list
deb [arch=amd64 signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu bionic stable
# 执行更新
sudo apt-get update
# 查看版本
apt-cache madison docker-ce
apt-cache madison containerd.io
# 安装指定版本
apt install docker-ce=5:20.10.11~3-0~ubuntu-bionic docker-ce-cli=5:20.10.11~3-0~ubuntu-bionic containerd.io=1.6.4-1 docker-buildx-plugin docker-compose-plugin# 开机自启
systemctl enable --now docker.service
# 配置 Cgroup Driver驱动为systemd,这个配置也可以写到/etc/docker/daemon.json中
root@dev-k8s-master02:~# vim /lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --exec-opt native.cgroupdriver=systemd
## 验证正常启动
systemctl daemon-reload && systemctl restart docker && systemctl status docker.service
## 验证驱动
root@dev-k8s-master02:~# docker info |grep -i CgroupCgroup Driver: systemdCgroup Version: 1
配置k8s 1.22版本
# 安装源 可自行搜索curl -x参数使用代理 密钥是通用的
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
# 官方及ustc的仓库中未找到1.22版本,阿里云有
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
root@dev-k8s-master02:~# cat /etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main# 安装
apt install kubeadm=1.22.4-00 kubelet=1.22.4-00 kubectl=1.22.4-00 -y
这里有一个比较坑的地方是
由于我们的集群运行了2年了,最早有一个master,后面扩展到5个master,后面又缩到3个master,导致集群中的主节点的信息跟现有的不一致,进一步导致了master节点加入集群的时候的报错。
就是比如搭建集群时候的master节点1也就是kubeadm执行init命令时指定的IP地址是192.168.1.14,现在这台机器已经不在集群中了,但是集群的配置信息没有更改过,导致执行kubeadm添加节点到集群中的时候仍然会去找1.14这个IP去链接api server。而且还有一个诡异的现象,我在交换机上查看arp解析记录是没有1.14这条记录的,但是在k8s集群中是能够ping通这个IP的。
具体的报错信息由于未保存ssh连接导致报错信息丢失
执行加入集群命令
kubeadm join 192.168.7.173:6443 --token 8tuq2n.rwxxxxdfa --discovery-token-ca-cert-hash sha256:b4c244215e5x6cf397255ff13c179e --control-plane --certificate-key 2d88deaxxxxxxafd04f4 --v=6
I0514 17:08:00.503834 3476 token.go:80] [discovery] Created cluster-info discovery client, requesting info from “192.168.1.38:6443”
I0514 17:08:00.518160 3476 round_trippers.go:454] GET https://192.168.1.38:6443/api/v1/namespaces/kube-public/configmaps/cluster-info?timeout=10s 200 OK in 13 milliseconds
I0514 17:08:00.520059 3476 token.go:118] [discovery] Requesting info from “192.168.1.38:6443” again to validate TLS against the pinned public key
I0514 17:08:00.526153 3476 round_trippers.go:454] GET https://192.168.1.38:6443/api/v1/namespaces/kube-public/configmaps/cluster-info?timeout=10s 200 OK in 5 milliseconds
I0514 17:08:00.526423 3476 token.go:135] [discovery] Cluster info signature and contents are valid and TLS certificate validates against pinned roots, will use API Server “192.168.1.38:6443”
I0514 17:08:00.526436 3476 discovery.go:52] [discovery] Using provided TLSBootstrapToken as authentication credentials for the join process
I0514 17:08:00.526449 3476 join.go:489] [preflight] Fetching init configuration
I0514 17:08:00.526457 3476 join.go:534] [preflight] Retrieving KubeConfig objects
[preflight] Reading configuration from the cluster…
[preflight] FYI: You can look at this config file with ‘kubectl -n kube-system get cm kubeadm-config -o yaml’
I0514 17:08:00.528095 3476 round_trippers.go:454] GET https://192.168.1.38:6443/api/v1/namespaces/kube-system/configmaps/kubeadm-config?timeout=10s 200 OK in 1 milliseconds
I0514 17:08:00.530254 3476 round_trippers.go:454] GET https://192.168.1.38:6443/api/v1/namespaces/kube-system/configmaps/kube-proxy?timeout=10s 200 OK in 1 milliseconds
I0514 17:08:00.532541 3476 round_trippers.go:454] GET https://192.168.1.38:6443/api/v1/namespaces/kube-system/configmaps/kubelet-config-1.22?timeout=10s 200 OK in 1 milliseconds
I0514 17:08:00.533583 3476 interface.go:431] Looking for default routes with IPv4 addresses
代码块版本
I0514 17:08:00.503834 3476 token.go:80] [discovery] Created cluster-info discovery client, requesting info from "192.168.1.38:6443"
I0514 17:08:00.518160 3476 round_trippers.go:454] GET https://192.168.1.38:6443/api/v1/namespaces/kube-public/configmaps/cluster-info?timeout=10s 200 OK in 13 milliseconds
I0514 17:08:00.520059 3476 token.go:118] [discovery] Requesting info from "192.168.1.38:6443" again to validate TLS against the pinned public key
I0514 17:08:00.526153 3476 round_trippers.go:454] GET https://192.168.1.38:6443/api/v1/namespaces/kube-public/configmaps/cluster-info?timeout=10s 200 OK in 5 milliseconds
I0514 17:08:00.526423 3476 token.go:135] [discovery] Cluster info signature and contents are valid and TLS certificate validates against pinned roots, will use API Server "192.168.1.38:6443"
I0514 17:08:00.526436 3476 discovery.go:52] [discovery] Using provided TLSBootstrapToken as authentication credentials for the join process
I0514 17:08:00.526449 3476 join.go:489] [preflight] Fetching init configuration
I0514 17:08:00.526457 3476 join.go:534] [preflight] Retrieving KubeConfig objects
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
I0514 17:08:00.528095 3476 round_trippers.go:454] GET https://192.168.1.38:6443/api/v1/namespaces/kube-system/configmaps/kubeadm-config?timeout=10s 200 OK in 1 milliseconds
I0514 17:08:00.530254 3476 round_trippers.go:454] GET https://192.168.1.38:6443/api/v1/namespaces/kube-system/configmaps/kube-proxy?timeout=10s 200 OK in 1 milliseconds
I0514 17:08:00.532541 3476 round_trippers.go:454] GET https://192.168.1.38:6443/api/v1/namespaces/kube-system/configmaps/kubelet-config-1.22?timeout=10s 200 OK in 1 milliseconds
I0514 17:08:00.533583 3476 interface.go:431] Looking for default routes with IPv4 addresses
根据日志浅析使用kubeadm将master&node节点加入现有集群的过程
- 通过指定的master节点的api信息及token认证信息创建client连接api server
- 获取ns kube-public下的cm信息cluster-info中的集群的master信息
- 连接获取的master信息去找kube-system下的cm kubeadm-config信息执行加入集群操作
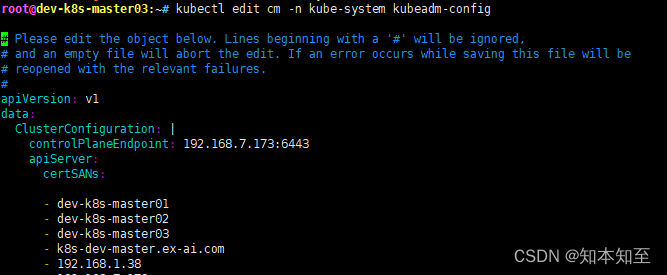
根据加入集群时候加的–v=6参数提示出来的报错信息一直让我以为是这个kubeadm-config配置文件有问题。
root@dev-k8s-master03:~# kubectl get cm -n kube-system|grep kubeadm-config
kubeadm-config 1 2y69d
改了这里信息之后发现一样的报错,跟这里的controlPlaneEndpoint并无关系
root@dev-k8s-master03:~# kubectl get cm -n kube-public
NAME DATA AGE
cluster-info 2 2y69d
这里看到这个cm文件已经2y没有动过了。执行kube edit发现坑
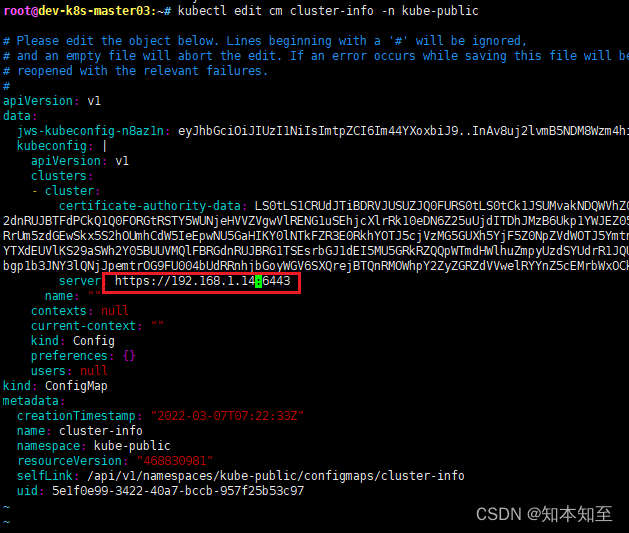
将这里改为现有存在的master节点之后,再执行加入节点即正常