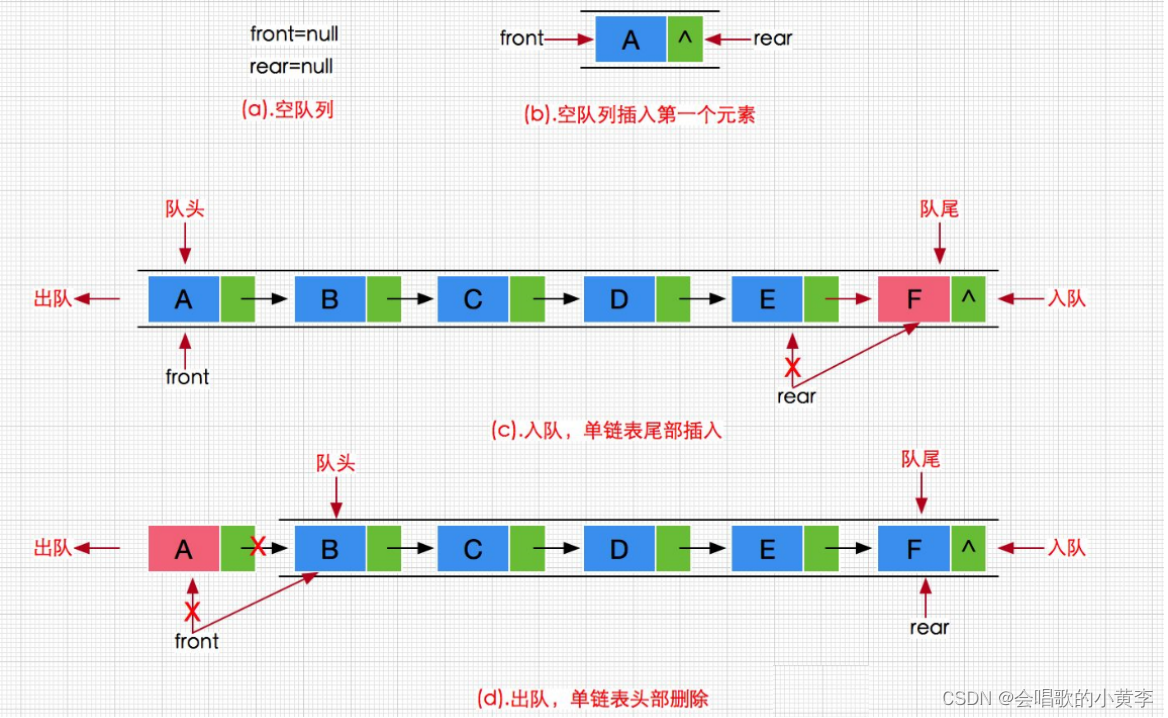
| 时间 | 版本 | 修改人 | 描述 |
|---|---|---|---|
| 2024年5月13日11:27:25 | V0.1 | 宋全恒 | 新建文档 |
| 2024年5月14日16:21:20 | V1.0 | 宋全恒 | 了解 |
简介
神经网络在运行时有较高的计算成本,而且随着大模型时代的到来,知识由一个巨大的LLM存储,为了获取知识,即使用模型进行推理或者以会话的方式获取想要搜索的答案,都变得简单。但深入到计算层面,就可以看到,这些推理的计算对于内存带宽和算力都有较高的要求,如何降低神经网络的功劳和latency,是一个非常热门的话题。
量化意义
量化的意义在于加速推理,减少内存占用和访存带宽需求,降低功耗和面积。
结论
**量化过程和硬件非强相关,在NN网络中,param的量化对整网精度影响更大,所以一般采用per channel的量化方式,**而activation的量化对整网精度的影响没有param大,一般采用per tensor(又称per layer)的方式进行量化。
从量化精度来看,kl散度>histogram>max_min,目前还有一种对数量化,但nvgpu,x86,arm三大平台上暂时都还没有对数量化的库,只有海思351x系列上有。
模型量化(pytorch)-CSDN博客
<1>一般我们都将float32量化到qint8。<2>模型参数中的bias一般是不进行量化操作的,仍然保持float32的数据类型。<3>weight在浮点模型训练收敛之后一般就已经固定住了,所以根据原始数据就可以直接量化。<4>activation会因为每次输入数据的不同,导致数据范围每次都是不同的,所以针对这个问题,在量化过程中专门会有一个校准过程,即提前准备一个小的校准数据集,在测试这个校准数据集的时候会记录每一次的activation的数据范围,然后根据记录值确定一个固定的范围。
量化Quantization
定义
量化概念
量化: 量化实际上就是把高位宽表示的权值和激活值用更低位宽来表示。定点运算指令比浮点运算指令在单位时间内能处理更多数据,同时,量化后的模型可以减少存储空间。 深度学习量化总结(PTQ、QAT)_ptq量化-CSDN博客
深度学习模型量化(低精度推理)大总结_深度学习 量化-CSDN博客给出了一个定义:
维基百科中关于量化(quantization)的定义是: 量化是将数值 x 映射到 y 的过程,其中 x 的定义域是一个大集合(通常是连续的),而 y 的定义域是一个小集合(通常是可数的)【1】。8-bit 低精度推理中, 我们将一个原本 FP32 的 weight/activation 浮点数张量转化成一个 int8/uint8 张量来处理。模型量化会带来如下两方面的好处:量化基础总结_线性量化-CSDN博客提出,**模型量化方法本质上是函数映射。**量化建立了高精度的浮点数值和量化后低精度的定点数值之间的数据映射。
在论文中RPTQ: Reorder-based Post-training Quantization for Large Language Models,
Quantization is an important technique for reducing the computational and memory requirements of deep neural networks (DNNs). There are two main categories of quantization methods for DNNs: posttraining quantization (PTQ) [41; 33; 25; 20; 38] and quantization-aware training (QAT) [8; 42; 5; 17]. PTQ methods involve quantizing pre-trained models, while QAT methods involve training models with quantization constraints.
基本上上述描述两种深度神经网络DNNs的量化方法: PTQ(训练后量化),QAT(量化感知的训练)
在深度学习中,基本运算的单位为向量或矩阵,规模比较大。这里会存在一个浮点比例因子,一般的,可以使用均匀量化技术,
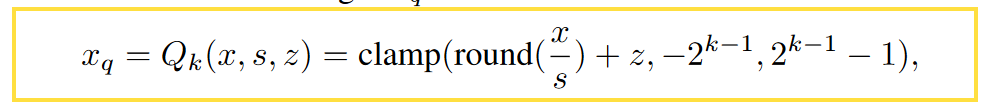
where s represents the scaling factor, z denotes the zero point, and the clamp function constrains the value within the range of a k-bit integer, specifically [−2k−1, 2k−1 − 1]. For a 4-bit integer, the range is [-8, 7]. The integer xq can be de-quantized to ˆ x = s(xq − z) ≈ x. The de-quantized value ˆ x is a float. The quantization parameters, scale factor s, and zero point z must be stored in memory for both quantization and de-quantization processes. To further reduce the storage and computational overhead of quantization, multiple weights or activation values X = {x1, ..., xn} share the same quantization parameters.
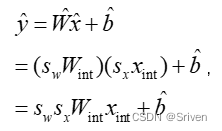
对权重和激活分别使用单独的比例因子sx和sw。这提供了灵活性并减少了量化误差。而量化的关键,在于确定比例因子。
Quantization — PyTorch 2.3 documentation 关于量化后模型如下描述
Quantization refers to techniques for performing computations and storing tensors at lower bitwidths than floating point precision. A quantized model executes some or all of the operations on tensors with reduced precision rather than full precision (floating point) values. # PyTorch 支持INT8量化。INT8模型量化,模型减少4倍,内存占用带宽需求。
PyTorch supports INT8 quantization compared to typical FP32 models allowing for a 4x reduction in the model size and a 4x reduction in memory bandwidth requirements.
量化主要是一种加快推理的技术,对于量化的算子来说,仅仅支持钱箱传递。。
分类
饱和量化和非饱和量化
参考深度学习量化策略 - 知乎
a)非饱和量化方法(No Saturation):map |max| to 127
非饱和量化方法计算 FP32 类型 Tensor 中绝对值的最大值 abs_max,将其映射为 127,则量化scale等于 abs_max/127。
非饱和量化的问题在深度学习量化总结(PTQ、QAT)_ptq量化-CSDN博客有阐述,关键是量化区间的浪费的问题。
b)饱和量化方法(Saturation):above |threshold| to 127
饱和量化方法使用 KL 散度计算一个合适的阈值 T(0 < T < map_max),将其映射为 127,则量化scale等于 T/127

静态量化和动态量化
训练后量化和训练感知量化
技术
量化参数
有三个量化参数,比例因子s,零点z,和比特宽度b。
比例因子和零点用于将浮点值映射到整数网格,其size取决于比特宽度。比例因子通常表示为浮点数,并指定量化器的步长。
零点是一个整数,确保实零(real zero)被量化而没有误差。这对于确保诸如零填充或ReLU之类的常见操作不会引起量化误差非常重要。
实际上,浮点型的0会映射到零点,这个零点是一个整型数,用来确保0没有量化误差。具体就是,0有特殊意义,比如padding时,0值也是参与计算的,浮点型的0进行8bit量化后还是0就不对了,所以加上这个零点后,浮点型0就会被映射到0-255这个区间内的一个数,这样的量化就更精确。就相当于让映射后区间整体偏移,浮点最小值对应0。计算完量化因子,再从浮点区间任取一值的量化过程,具体参见深度学习量化总结(PTQ、QAT)_ptq量化-CSDN博客
。z通常是一个整数,即 zp_x= rounding(q_x * min_x_f)。因此,在量化之后,浮点数中的 0 刚好对应这个整数。这也意味着 zero_point 可以无误差地量化浮点数中的数据 0,从而减少补零操作(比如卷积中的padding zero)在量化中产生额外的误差,参见深度学习模型量化(低精度推理)大总结_深度学习 量化-CSDN博客。
Uniform Affine Quantizer(非对称量化)
非对称量化的意义,是将浮点数映射到不对称的区间,比如说映射到uint8,而uint8的数值表示区间为
0-255,一共256个数。

分为两个步骤:
- 首先要计算比例因子,包括步长和零点两个参数, s和z
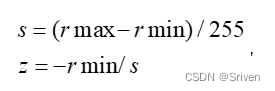
- 计算完量化因子,从浮点区间任取一值的量化过程,得到xq
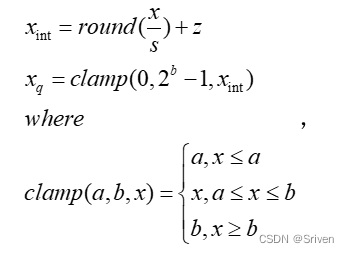
clamp用于将超出范围的值阶段,因为可能会溢出。上述图中clamp将xint 限制在0到2b-1。round是四舍五入。
而反量化公式为:
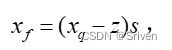
注,定点量化,应该指的是整数量化。
讲真没有看的特别懂。
这个是Sriven大神提供的例子。
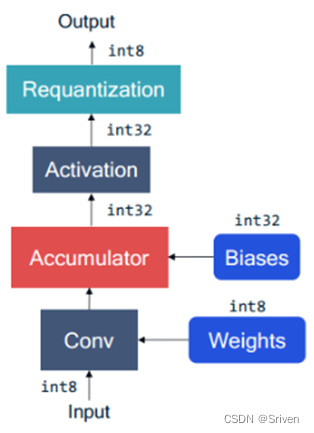
对于上图的理解,可以看到输入,输出,以及权重参数均为量化的int8的格式(为啥Biases为int32,不解)
非对称量化算法一般能较好的处理数据分布不均匀的情况。
深度学习模型量化(低精度推理)大总结_深度学习 量化-CSDN博客提供了一个实例:
由对称算法(symmetric)产生的 量化数据绝大部分都位于[0,127] 这个表示范围内,而 0 的左侧有相当于一部分范围内没有任何的数据。int8 本来在数据的表示范围上就明显少于 FP32,现在又有一部分表示范围没发挥左右,这将进一步减弱量化数据的表示能力,影响量化模型的精度。与之相反,非对称算法(asymmetric)则能较好地解决 FP32 数据分布不明显倾向于一侧的问题,量化数据的分布与原始数据分布情况大致相似,较好地保留了 FP32 数据信息。
Unfiorm symmetric quantizer(对称量化)
对称量化是非对称量化的简单版本。对称量化即零点z=0的情况。如INT8量化:
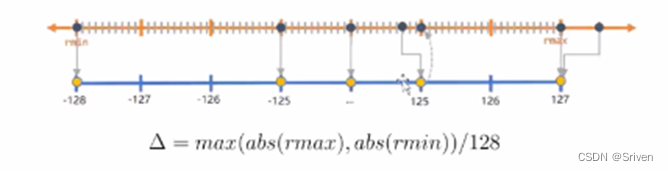
取值范围[-128, 127]。
图示还是很简单的。
由于零点为0,量化的过程,在确定浮点因子时,只需要确定步长s即可。
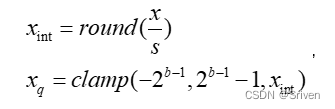
相应的反量化公式
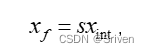
整个过程步骤也是两个步骤,但由于不考虑零点, 公式更加简单。
y = Clamp(Round([(scale_x*x)*(scale_weight*w)+(scale_x*scale_w)*b]/scale_y))
= Clamp(Round( (x*w+b)*(scale_x*scale_w)/scale_y))
= Clamp(Round( (x*w+b)*scale))
可以看到,虽然重要的模型参数已经量化后的,但在计算过程中,需要反量化为浮点型。
- 可以通过这个博客了解计算过程,已经量化的的模型那些参数需要量化,
- 量化的过程,
-
- 先确定步长s和零点z
- 根据量化方法得到量化后的值。
-
在 深度学习量化总结(PTQ、QAT)_ptq量化-CSDN博客中Srivin还给出确定比例因子如何确定的方式的阐述。具体就是饱和量化和不饱和量化。饱和量化算法是找到一个合适的阈值,如右图,把超出范围的噪声点的值都设为[T],然后量化之后,值会非常均匀的分布在(-127-127)这个区间。
scale和zero_point,这个比例因子,许多文章称为缩放因子和零点。
量化策略 的描述感觉也很关键 。
量化策略,是为了确定最大和最小值,也即为了确定步长s和零点z。
对于推理过程来说,weights是一个常量张量,不需要额外数据集进行采样即可确定实际的动态范围。但是activation的实际动态范围则必须经过采样获取(一般把这个过程称为数据校准(calibration))。目前各个深度学习框架中,使用最多的有最大最小值(MinMax),滑动平均最大最小值(MovingAverageMinMax)和KL距离(Kullback–Leibler divergence)三种
随机量化
量化发生位置
仅对权重量化
只量化权重和偏置,权重和偏置的比例因子一致
量化权重和激活值
需要标定数据。
一般来说在PTQ中,权重使用MinMax量化,激活值使用滑动平均最大最小值或KL散度量化,偏置的比例因子为权重和激活值的比例因子的乘积。
量化方法
按照量化阶段的不同,一般将量化分为 quantization aware training(QAT) 和 post-training quantization(PTQ)。QAT 需要在训练阶段就对量化误差进行建模,这种方法一般能够获得较低的精度损失。PTQ 直接对普通训练后的模型进行量化,过程简单,不需要在训练阶段考虑量化问题,因此,在实际的生产环境中对部署人员的要求也较低,但是在精度上一般要稍微逊色于 QAT。
下图是量化方法的分类场景

下图是根据需要选择量化方法

PTQ
字面意思,整个模型(浮点型的)训练完成后再单独把权值和激活值拿出来量化。过程中无需对原始模型进行任何训练,只对几个超参数调整就可完成量化过程。
动态量化
在深度学习量化策略 - 知乎,PTQ Dynamic定义如下:
动态离线量化仅将模型中特定算子的权重从FP32类型映射成 INT8/16 类型,bias和激活在推理过程中动态量化。但是对于不同的输入值来说,其scale是动态计算的。动态量化是几种量化方法中性能最差的,常用于非常大的模型。
Dynamic Quantization — PyTorch Tutorials 2.3.0+cu121 documentation是Torch官方的动态量化介绍。
torch.quantization.quantize_dynamic()
Class torch.quantization.quantize_dynamic(model, qconfig_spec=None, dtype=torch.qint8, mapping=None, inplace=False)动态量化系统自动选择最合适的scale (标度)和 zero_point(零点位置),不需要自定义。量化后的模型,可以推理运算,但不能训练(不能反向传播)
# Init asr model from configs
model = init_asr_model(configs)
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)静态量化
首先用校准数据集进行fp32正向推理,得到一组真实概率分布。然后选取不同的threshold,分别得到量化成对应int数据下的近似概率分布,选取能使KL散度最小的threshold,计算对应的scale,完成模型量化。
PyTorch Static Quantization with Eager Mode in PyTorch — PyTorch Tutorials 2.3.0+cu121 documentation,本教程显示了如何进行训练后静态量化,并说明了两种更先进的技术 - 每通道量化和量化感知训练 - 以进一步提高模型的准确性。
结论
总之,静态量化与动态量化的区别在于其输入的缩放因子计算方法不同,静态量化的模型在使用前有校准过程:准备部分输入校准数据,使用静态量化后的模型进行预测,在此过程中量化模型的scale会根据输入数据的分布进行调整。一旦校准完成,权重和输入的scale都固定(即静态)。静态量化的性能一般比动态量化好,因此实际场景中基本都是在用静态量化。
QAT
概念:量化训练让模型感知量化运算对模型精度带来的影响,通过 finetune 训练降低量化误差。这种方法会降低训练速度,但是能够获得更高的精度。
from pytorch_quantization import quant_models
quant_models.initialize()
这是NV发布的QAT库。
精度
模型量化有 8/4/2/1 bit
实践
Pytorch模型量化 - 凌逆战 - 博客园 提供了一个边训练边量化的例子
代码实践
pytorch量化中torch.quantize_per_tensor()函数参数详解_把32位浮点数转换为8位定点数的python函数-CSDN博客对于torch.quantize_per_tensor函数参数进行了解释。
量化工具/框架整理
深度学习量化策略 - 知乎中提供了一个量化工具表格,从公司,量化工具,推理引擎,部署平台等角度阐述。
Nvidia使用TensorRT进行量化,
而Meta使用pytorch作为量化工具,
华为团队使用MindSPore Lite套件,支持部署在端边缘。
TVM团队,使用TVM框架,可以部署在端边云上。
在硬件支持的情况下,量化时对激活值X使用非对称量化,对权重值W使用对称量化(谷歌白皮书建议)
TensorRT量化思路:使用校准数据集,对权重用的minmax算法(per channel),激活用的KL散度算法(per tensor), 注意TensorRT里bias是不量化的
总结
参考
| 参考博客 | 描述 |
|---|---|
| 深度学习量化总结(PTQ、QAT)_ptq量化-CSDN博客 | 👍👍👍👍👍博客真的很用心,从这个博客中了解到 量化有两个步骤,三个重要的参数 即缩放因子,零点和比特宽度。 确定缩放因子有三个量化策略, 而量化类型分为了均匀量化和非均匀量化, Sriven写的超级用心。 |
| 深度学习量化策略 - 知乎 | 对于量化分类,提供了图示 |
| 模型量化(pytorch)-CSDN博客 | 描述了量化的一些基本结论 |
| Quantization — PyTorch 2.3 documentation | PyTorch支持IN*量化和QAT。 |
| 量化基础总结_线性量化-CSDN博客 | 👍👍👍里面对于量化基础进行总结,提出线性量化和非线性量化, 并且对于PyTorch支持的量化方式进行了整理。 最重要的事,给出了训练后量化和训练感知量化的步骤 |
| (六) 量化研究_对称量化-CSDN博客 | 三河提供了量化和反量化的图示,理解直观有效。 对于对称量化和非对称量化描述的比较清晰。间隔是相等的。 提供了关于卷积核操作的理解 |
| 深度学习编译器入坑指北(Q5)模型量化-PTQ与QAT - 简书 | 提供了关于PTQ与QAT量化的过程图示。 |
| 详解pytorch动态量化-CSDN博客 | 👍👍👍直接用数据进行了演示,并且有PyTorch对于量化支持的时间轴。对于Tensor的量化支持模式 per tensor和per channel 进行了描述。 介绍了quantize_dynamic的各个参数。 对于动态量化感觉介绍的比较深入。 |
| Pytorch模型量化 - 凌逆战 - 博客园 | 提供了量化函数公式 |
| Pytorch模型量化 - 凌逆战 - 博客园 | 图示per-Tensor量化和per-Channel量化 |