Kafka基础架构
Kafka概述
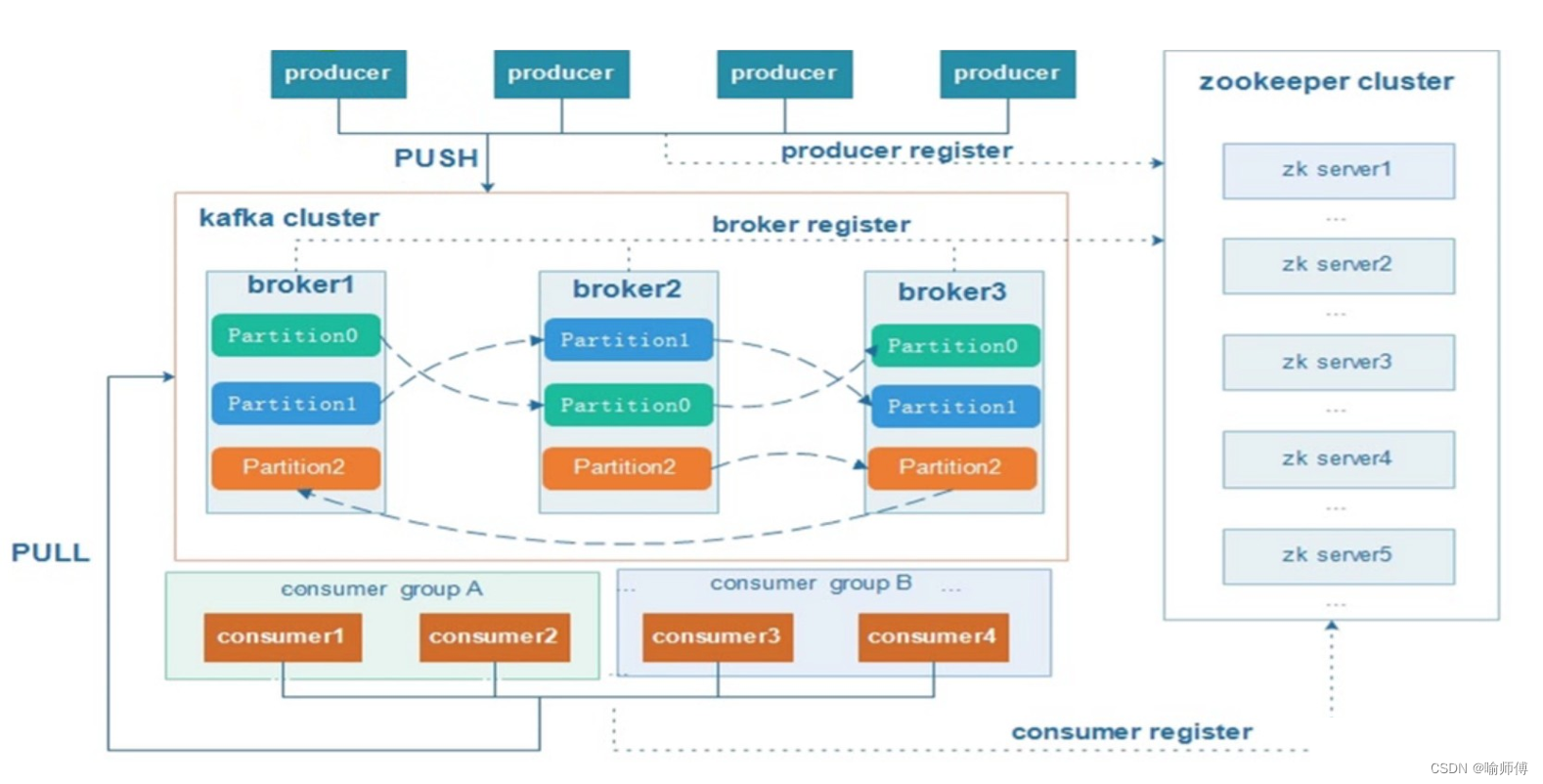
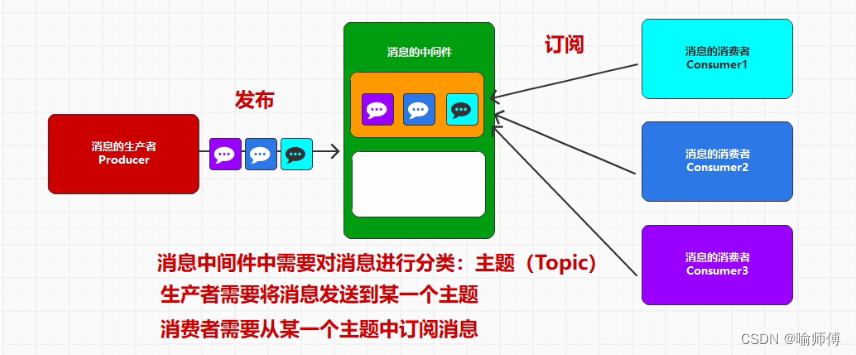
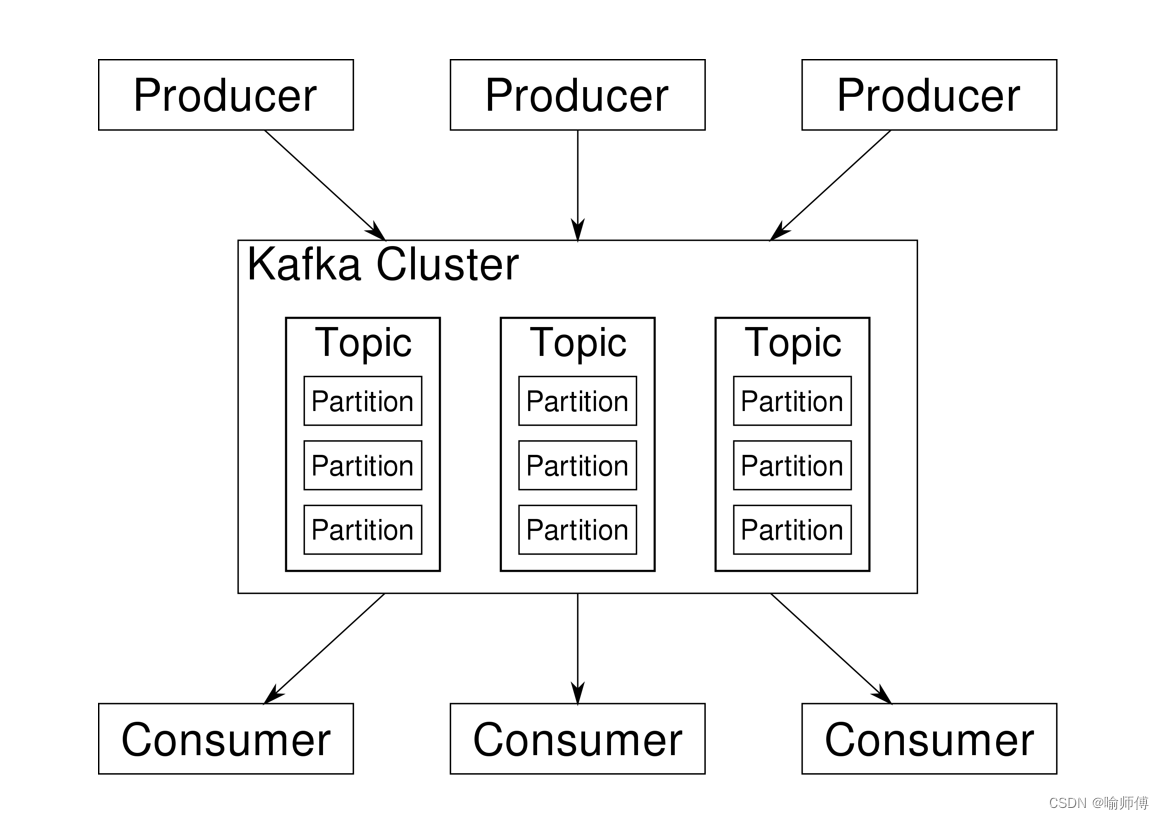
1. Producer(生产者):
- 生产者是向 Kafka broker 发送消息的客户端。它负责将消息发布到指定的主题(Topic),并可以选择将消息发送到特定的分区(Partition)。
- 生产者通常是数据源,如应用程序、传感器、日志系统等。
- 生产者可以以异步或同步的方式发送消息,并且可以配置消息发送的确认机制以确保消息的可靠性。
2. Consumer(消费者):
-
消费者负责从 Kafka 主题订阅并消费消息。
-
消费者通过消费者组协调器(Consumer Group Coordinator)协调消费进度,并且每个消费者组只能消费主题中的特定分区,以确保消息被均匀地消费。
-
消费者是从 Kafka broker 拉取消息的客户端。它负责订阅一个或多个主题,并消费这些主题中的消息。
-
消费者以消费者组(Consumer Group)的形式组织,每个消费组可以包含一个或多个消费者,每个消费者组内的消费者协作地消费主题中的消息。
3. Consumer Group(消费者组):
- 消费者组由多个消费者组成,每个消费者负责消费不同分区的数据。
- 一个分区只能由同一消费者组内的一个消费者消费,这确保了消费者之间的负载均衡和高可用性。
- 不同消费者组之间相互独立,不会相互影响。
- 所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
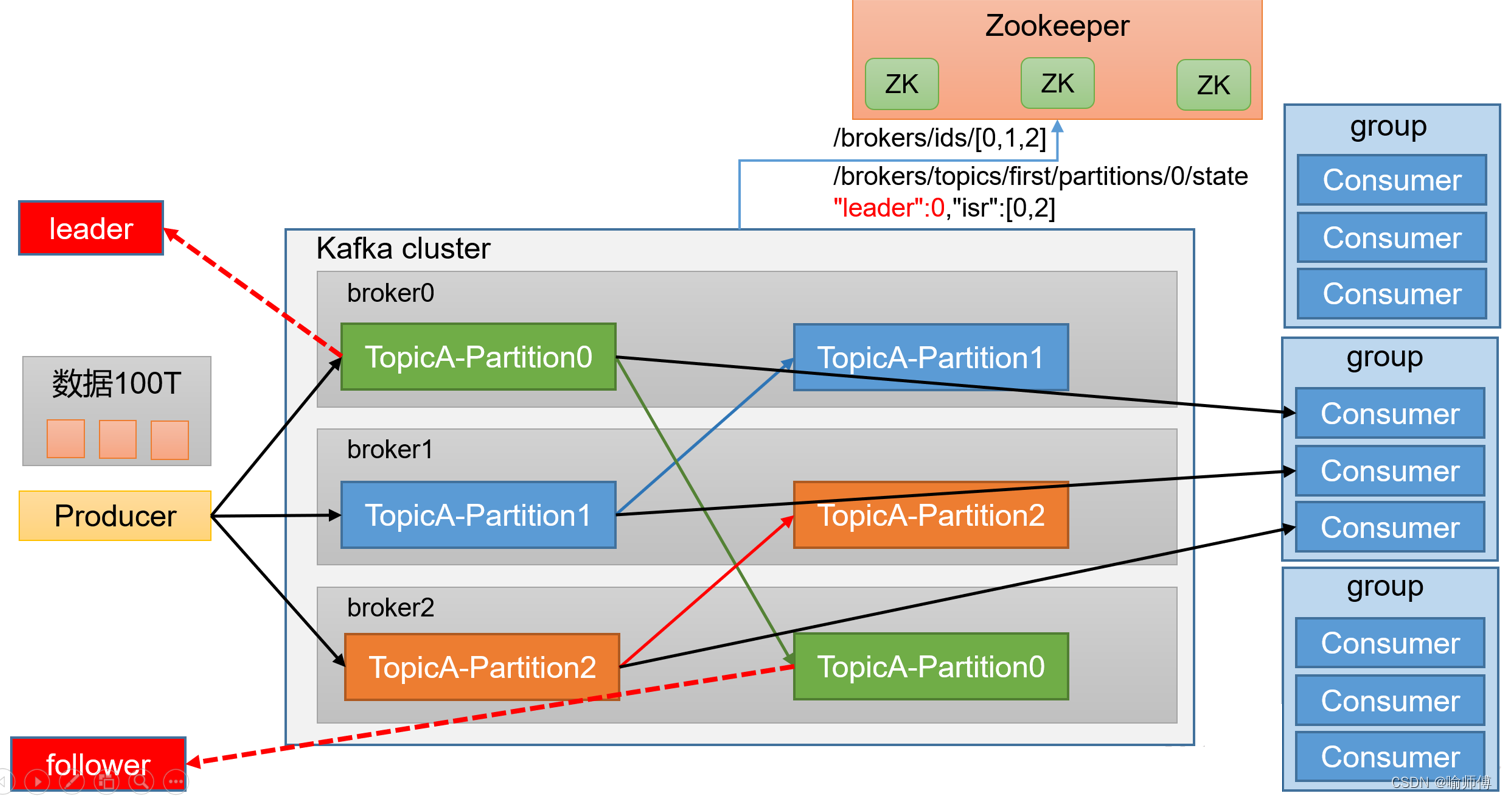
4. Broker(代理服务器):
- 代理服务器是 Kafka 集群中的节点,每个Broker(代理服务器)就是一个 Kafka 服务器。
- 一个 Kafka 集群由多个Broker(代理服务器)组成,它们负责存储和处理消息数据。
- 每个Broker(代理服务器)可以容纳多个主题(Topic)。
5. Topics(主题):
- 主题是 Kafka 中的基本数据分类单位,每条消息都属于一个主题。
- 主题通常用于标识消息的类型或者来源。例如,一个电商应用可以有一个主题用于存储订单信息,另一个主题用于存储用户活动日志等。
- Topic(主题)可以理解为消息的分类单元,生产者和消费者面向的都是一个Topic(主题)。
- 一个主题可以分为多个分区(Partition),用于提高消息的并发处理能力和扩展性。
- Topic(主题)通常代表着应用程序的某个数据源或数据流。
6. Partition(分区):
-
为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。
-
Partition(分区)是主题的子集,用于组织和存储消息。
-
一个Topic(主题)可以分为多个Partition(分区),每个Partition(分区)是一个有序的消息队列。
-
Partition(分区)的数量通常与 Kafka 集群中的节点数量相关,它们共同构成了整个数据流的分布式存储。
-
主题可以被分成一个或多个分区,每个分区是一个有序的队列,其中存储着消息记录。
-
分区允许数据水平扩展,可以分布在 Kafka 集群的不同节点上,提高了系统的可伸缩性和容错性。
-
每个消息在发送到主题时,都会被分配到一个特定的分区中,并且在该分区中按照顺序存储。
7. Replication(副本):
- 为了提高数据的可靠性和容错性,Kafka 允许为每个分区创建多个副本。
- 副本是分区的备份,其中的消息与主分区中的消息保持同步。
- 副本通常分布在 Kafka 集群的不同节点上,以防止单点故障、提高系统的可用性并提高数据的可靠性和容错性。
- 每个分区的副本中都有一个 Leader 和若干个 Follower,用于实现数据的同步和故障转移。
8. Leader(领导者):
- 每个分区的多个副本中有一个被选举为 Leader,它是生产者发送数据的对象,以及消费者消费数据的对象。
- Leader 负责处理分区中的所有读写操作,其他副本则作为 Follower 实时从 Leader 中同步数据。
9. Follower(跟随者):
- 每个分区的多个副本中的非 Leader 副本称为 Follower,它们实时从 Leader 中同步数据,保持和 Leader 数据的一致性。
- 当 Leader 发生故障时,某个 Follower 会成为新的 Leader,确保数据的可用性和持久性。
10. Zookeeper:
- Kafka 使用 Zookeeper 来协调和管理集群中的各个节点。
- Zookeeper 负责维护集群的元数据(metadata),例如主题、分区、消费者组等的信息。
- Zookeeper 还负责监控集群中节点的状态,并协调分区的分配和副本的同步。
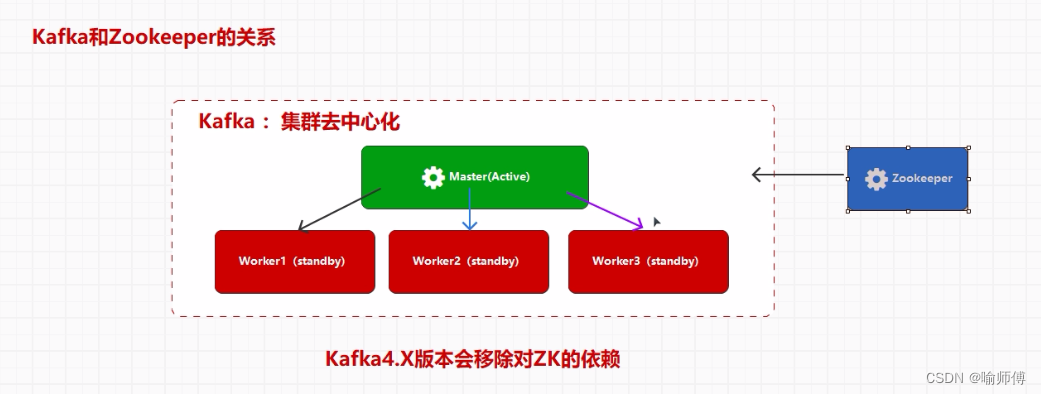
Apache Kafka 4.x 版本计划中的一个重要变化是移除对 Apache ZooKeeper 的依赖。这个变化旨在简化 Kafka 的架构和部署,并提高其可维护性和可扩展性。
- 1.简化架构:
在之前的版本中,Kafka 使用 ZooKeeper 来管理集群元数据和协调功能。但随着版本的演进,Kafka 内部实现了自己的元数据管理和协调机制。因此,Kafka 4.x 版本将简化架构,去除对 ZooKeeper 的依赖。 - 2.集成 KRaft 协议:
Kafka 4.x 版本引入了 KRaft 协议,这是一种新的复制协议,用于管理 Kafka 的元数据和集群的一致性。KRaft 协议取代了之前使用 ZooKeeper 进行复制和协调的机制。 - 3.简化部署和运维:
移除对 ZooKeeper 的依赖简化了 Kafka 的部署和运维。不再需要独立管理 ZooKeeper 集群,减少了部署的复杂性,同时简化了监控和维护 Kafka 集群。 - 4.提高可扩展性和性能:
Kafka 4.x 版本通过移除对 ZooKeeper 的依赖,减少了对外部依赖的关联,提高了系统的可扩展性和性能。Kafka 可以更好地利用现代硬件和网络,在大规模环境中高效运行。
尽管 Kafka 4.x 版本移除了对 ZooKeeper 的依赖,但仍然需要进行平滑的升级过程,并且需要在现有环境中仔细评估和测试新版本的兼容性和性能。Apache Kafka 官方文档提供了关于新版本升级和使用的详细指南,建议参考官方文档获取更准确和最新的信息。