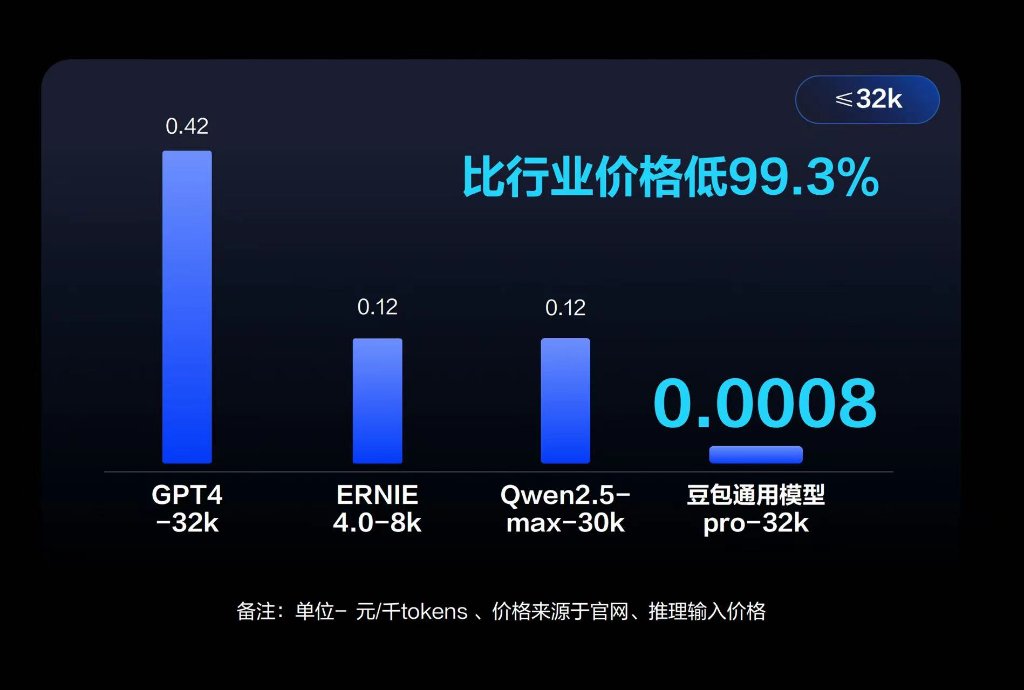
引言
随着“软件定义万物”的时代到来,软件在我们生活中扮演着不可或缺的角色。然而,不严格的软件设计、开发人员的能力限制,以及编程语言本身的不安全性,都可能导致软件出现缓冲区溢出、整型溢出、格式化字符串攻击等缺陷。这些漏洞不仅严重威胁系统安全,还常被不法分子利用,从而进行勒索敲诈,威胁社会秩序的稳定。因此,软件安全分析成为了研究人员的热点关注领域。
软件安全分析通常包括源代码级别和二进制级别两个方面。源代码级别分析由于能直观准确地访问程序全貌,而被认为更为有效。然而,大多数商业软件并非开源,使得终端用户通常只能接触到编译后的二进制代码。这不仅增加了跨语言分析的难度,也揭示了源代码级分析的局限性。此外,许多遗留软件只以二进制形式存在,没有源代码支持,这更强调了基于二进制的安全分析的必要性和普遍性。
目前,二进制代码分析面临的主要挑战包括:二进制可执行程序的可读性差,以及编译过程中可能丢失的结构和类型信息,这都增加了分析的复杂度。此外,程序中的直接和间接跳转构建了执行流程的极大挑战。不同架构的调用约定也增加了恢复程序调用流的复杂性。同时,为了增强安全性,开发者可能采取内存地址随机化、代码加密和混淆等措施,这些都进一步增加了分析二进制代码的难度。
在这种背景下,大模型技术作为人工智能领域的重大进展,展现了其在二进制安全领域的独特优势。借助巨大的参数量和海量数据训练,这些模型能够显著提速二进制文件的分析过程,实现从二进制到高级编程语言的直接转换、无源码的自动漏洞检测与修复、恶意样本的自动分析归因,以及对二进制软件成分的分析以预防供应链安全风险。大模型的应用不仅提高了任务执行的效率,还降低了人力和成本投入,推动了二进制安全领域的研究与应用,使之变得更为高效和创新。
本文调研和测试了截至2024年5月的所有二进制相关大模型研究方案,探讨了利用大模型技术辅助二进制分析的策略、实施方案以及成果分析。这项研究旨在分享该领域的应用成熟度,并与各位专家交流,推动进一步的产品化成熟落地。
二进制安全领域的应用场景
1. 代码理解与自动化辅助
在逆向工程和漏洞挖掘的领域中,将二进制文件转换回高级编程语言(如C/C++)是一项关键的任务。这一过程通常被称为反编译,其目标是尽可能准确地还原出二进制文件的源代码,以便进行更深入的分析和理解。有效且高质量的反编译是实现高效、准确分析的核心要素。
目标:
基本还原二进制文件,达到由二进制文件到c/c++的转换。
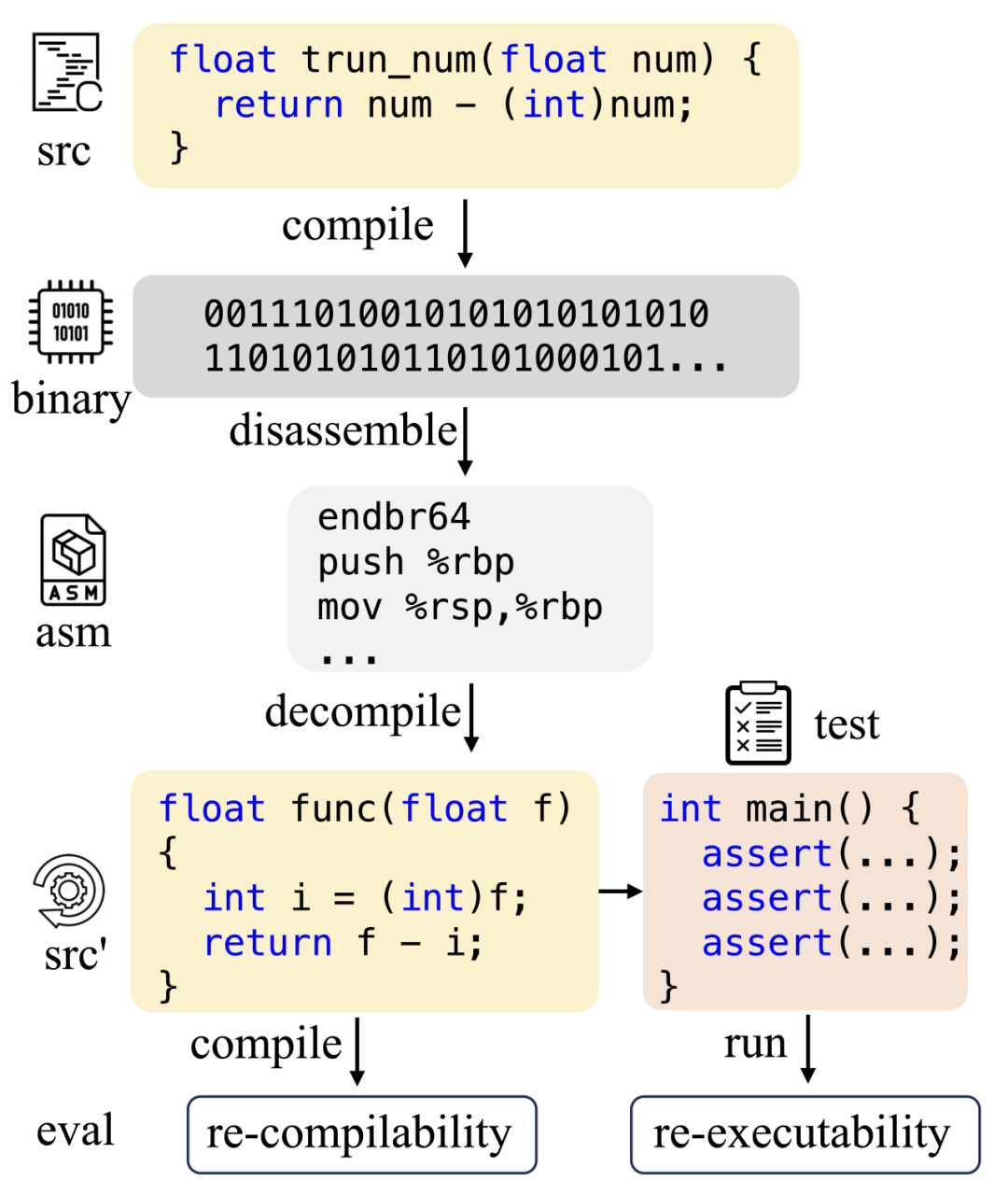
图2.1 LLM4Decompile 分析流程
方案一:
LLM4Decompile 是一款开创性的开源大型语言模型,专注于反编译工作。这是目前唯一一个能直接基于反汇编进行分析并输出相应的 C 代码的模型,以其极高的准确性和抗干扰性著称。在将汇编语言转换为 C 语言的能力上,LLM4Decompile 已经能与 GPT-4 相媲美。然而,该模型的主要缺点是可靠性不高,目前只能用于测试简单的演示示例。此外,它过于依赖训练样本,要达到高可用性,对样本的质量和数量要求极高。在实际应用场景中,它还不能结合数据段进行综合分析。
以下代码为测试用例:


图2.2 LLM4Decompile对测试用例反汇编
可以观察到,在原始的汇编代码中并没有包含"Hello, world!"这样的字符串。这是由于大模型自行进行了匹配和补充,导致的这一现象,主要是因为数据量较少且无法结合数据段进行处理。至于忽略数据内容的问题,我们暂时不予讨论。
另外,我使用了 Dijkstra 算法的反汇编,其代码总量约为 420 行,但无法正常输出相应的伪 C 代码。在对其他较长的汇编代码进行测试时,也面临着同样的问题,即无法正常输出,并且不支持对 Windows API 的解析。
方案二:
通过使用第三方组件(如 Ghidra、IDA、retDec)进行初步的反编译生成伪 C 代码,并借助大模型进行可读性优化,这种方法被证实具有良好的稳定性。此外,后期模型的预训练成本相对较低。目前,如清华大学的 MLM 和腾讯云的 BSCA 等机构已采用此解决方案进行代码转换。然而,尽管此类解决方案具有一定的依赖性于第三方组件,它在处理一些反静态分析工具时仍显示出先天的缺陷。

图2.3 腾讯BSCA交互模式基于Ghidra反编译
2. 二进制漏洞检测中的应用
目标:
-
深入分析二进制文件: 即使在没有源代码的情况下,也能进行深入的分析,精准地捕捉复杂的漏洞特征。
-
跨平台适应性: 确保在多样化的操作系统和硬件架构中实现统一且高标准的检测流程。
-
持续自我学习与动态优化:通过不断学习最新的漏洞知识和修复策略,动态优化检测算法,提供了深度和广度兼备的智能化二进制安全防护解决方案。

图2.4 清华大学MLM使用步骤
方案一:
基于较高准确率的反编译代码,通过大模型进行分析处理,此类方法属于分析辅助工具,需要人工配合进行分析。目前,如清华大学的 MLM、mrphrazer/reverser_ai 和 WPeChatGPT 都采用这种手段进行分析。这种方式的可靠性较高,是一种广泛使用的良好辅助手段,其中 WPeChatGPT 是一个在 GitHub 上的开源项目。
WPeChatGPT 通过直接调用 ChatGPT 4.0 接口,传输伪 C 代码进行分析。得益于 ChatGPT 4.0 的强大功能,其可用性和准确性较高。然而,由于国内网络环境的限制,其稳定性不足且费用较高。

图2.5 WPeCharGPT使用漏洞分析功能
方案二:
传统的模糊测试面临三大挑战:与目标系统和语言的紧密耦合、 缺乏对语言种类的支持、以及生成能力的限制。通过引入LLM作为输入生成和变异引擎,以及自动提示技术和其可以理解复杂协议和格式,有效应对了这些挑战,并且大幅度提高了方案实施的效率。
模糊测试技术与LLMs的交叉应用同样是目前二进制安全领域的热门研究方向,因其传统的模糊测试方式与LLMs有极其巧合的互补性,致使这对组合有巨大的应用价值,目前市面上已经有FuzzGpt、Fuzz4All的相关内容供以参考,由于篇幅限制未来会用另外的文章来重点论述大模型下模糊测试相关的落地实践。

图2.6 FuzzGPT概述
3. 恶意代码智能识别
目标:
通过文件静态识别,分析二进制恶意样本的行为和归属类别家族。
方案一:
目前公开的恶意代码识别主要基于历史上大量病毒样本的反编译。通过对这些数据进行预训练,并配合大模型进行恶意样本的反编译和分析,从而实现恶意代码的识别和归因。虽然市场上尚无产品公开展示这一功能,但在对小范围(约3400个恶意PE文件)样本进行测试中,揭示了一些关键难点:
-
混淆和加壳:恶意样本为了规避杀毒软件的检测,常采用混淆、加壳和抗分析等手段。这些手段使得直接对样本进行反编译时常出现编译失败的情况。
-
复杂的调用链:大量APT(高级持续性威胁)组织采用白名单机制、黑名单机制加多级loader的方式加载恶意代码。所设计的调用链复杂,需要人工干预和处理分析,才能进一步进行归因。

图2.7 小范围测试PE样本3554个
4. 二进制软件成分分析
现代企业中,开源组件的使用比例已超过90%。经过长时间的研究,软件组成分析(SCA)技术已相对成熟。在这90%的开源使用中,大部分为完整的开源组件或代码,这些可以被SCA工具轻松检测出来。然而,还有一小部分由开源代码片段组成,传统的依赖分析(Dependency Check)并不适用于这种代码片段层级的检测。此外,一些商业化组件并未开源,这些代码基本上与开源无关,对这些代码进行检测的难度较大。
目标:
在无源环境下对二进制软件成分进行分析,确定其开源组件的小版本,并识别未开源的第三方组件。
方案一:
二进制下的SCA技术已相对成熟,并具有很高的应用价值。然而,现有的SCA工具无法识别出各小版本的代码差异,从而定位历史存在的漏洞。这一挑战可以通过对大模型进行预训练,利用大量的开源数据来解决。例如,腾讯的SCA技术在开源版本的识别上已达到较好的精确度。

图2.8 腾讯SCA
安全大脑与SecGPT在二进制安全中的实践
1. 安全大脑与SecGPT简介
云起AI安全大脑是专为企业级大模型系统设计的全方位解决方案,旨在提供智能体管理和模型管理的一体化平台。该平台为企业级用户提供便捷、安全的智能体管理和模型管理服务,帮助用户构建高效、稳定的AI系统。
SecGPT 是全球首个网络安全开源大模型,可用作基座安全模型,适用于代码分析、流量分析、溯源分析等多种应用。这使得 SecGPT 在处理网络安全问题时,具有广泛的适用性和强大的分析能力。
2. 技术路线
通过对 SecGPT 模型进行进一步的微调和训练,我们在此基础上利用云起AI安全大脑重新输入垂直数据进行二次投喂。这一过程旨在对模型场景进行进一步的原子化处理,使得"可读性优化、缺陷查找、漏洞查找、功能分析、恶意代码检测"等功能能够被分离并形成独有的安全体系。这样的技术策略将大幅度提高系统的专业性、可靠性和复用性。
3. 实施与能力评估
在整个二进制安全领域,无论是进行成分分析还是恶意样本分析,关键的环节之一就是大模型对伪 C 代码的识别能力以及优化代码的可靠性和稳定性。这种能力确保了分析的准确性,使得从二进制文件到高级编程语言的转换更为精确,同时提升了对潜在安全威胁的识别和响应速度。
3.1 基于智能体下IDA插件实践
-
以下为IDA原生反编译代码:


-
基于SecGPT对伪C代码进行优化重写以后的效果:


-
以下为ChatGPT4 优化之后的伪C代码:


从以上代码比较可以看出,SecGPT 和 ChatGPT4 在对代码可读性优化方面的表现相差不大。两者在提高代码的可读性和进行变量重命名等方面都表现出色,能够显著帮助用户分析伪 C 代码。这说明尽管两个模型可能有不同的训练侧重点和优化目标,它们都足以支持复杂的代码分析任务,对于需要从二进制文件中提取和优化代码的用户来说,这是一个极大的助力。
接下来,我们将通过同时使用 SecGPT 和 ChatGPT4.0 对代码进行优化和解析。此外,为确保评估的公正性和客观性,我们将采用 ChatGPT4.0-1106-Preview 版本来进行中立的准确度评判。这种方法将允许我们比较两个模型在代码优化和解析方面的性能,并确保评估结果的可靠性和有效性。
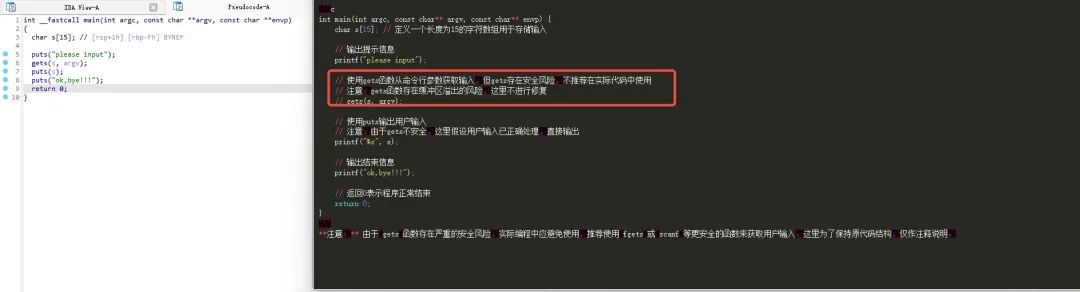
图3.1(a) 基SecGPT的IDA插件
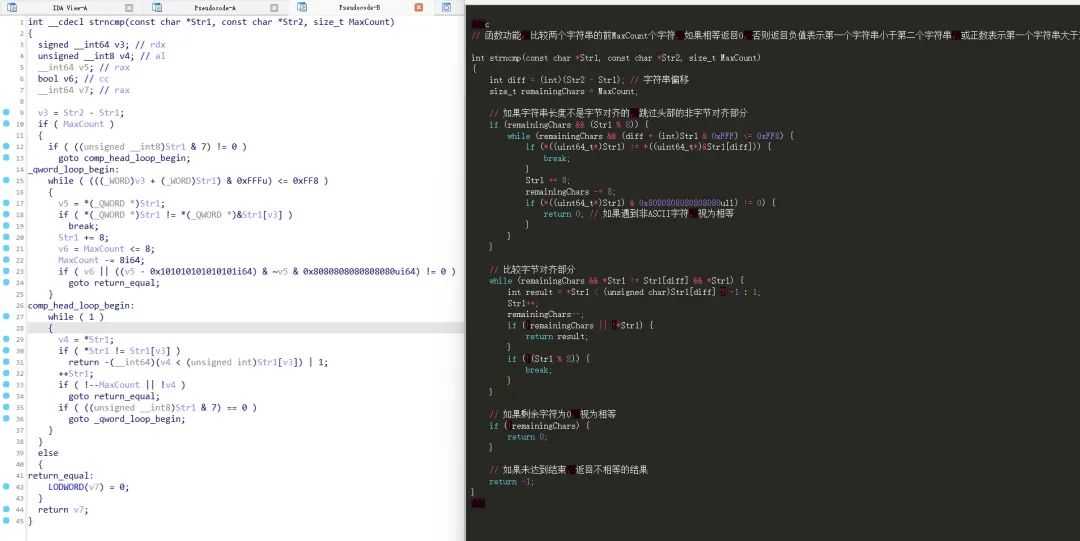
图3.1(b) 基SecGPT的IDA插件
3.2 基于chatGPT 4的对比评估
在对3554个恶意样本进行研究时,使用了Ghidra的无头模式进行反编译,成功抽取了1137个不同的函数。接下来,我们将利用 ChatGPT4-1106-Preview 版本来评估这些函数的代码优化和代码分析的相似度与 ChatGPT 的表现。
通过这种方法,我们可以详细了解不同版本的 ChatGPT 在处理相同代码优化任务时的效果差异。这不仅有助于验证模型的性能,还可以揭示可能的改进方向,以便更准确地处理和优化恶意代码。这一步骤对于理解和提高模型在实际应用中的实用性和准确性至关重要。
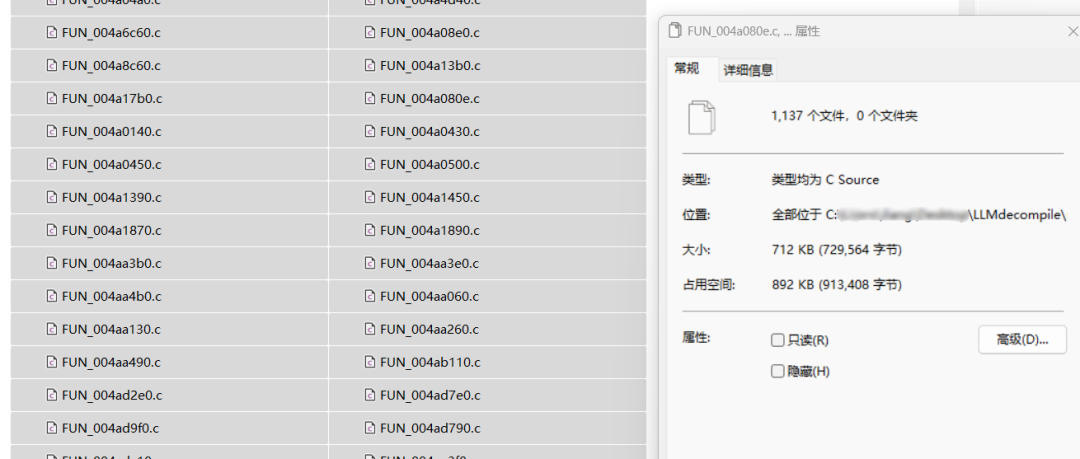
图3.2 函数抽取样本
在进行大规模模型性能评估时,使用脚本批量对话来获取可信度返回值是一种高效的测试策略。这种方法可以自动化地测试和比较不同模型对特定输入的响应。通过分析这些响应的可信度分数,我们能够客观地评估模型的表现。

图3.3 可靠性测试示例

图3.4 与ChatGPT4可靠性测试过程
在进行ChatGPT4-1106-Preview的评估测试中,我们分析了1137个测试示例。结果显示有34个实际无效数据,其中可信度最低的为34.72。低于80的可信度有61个示例,80至90之间的有63个,而高于90的有979个,平均可信度为95.21。同时,结合人工抽检,我们初步确认该模型在二进制伪C代码的可视化优化和代码分析识别方面表现出较高的稳定性和可用性。
以上结果仅为在安全大脑+SecGPT优化环境下的基础测试。尽管测试中仍存在许多不足,如测试数量偏低且没有进行系统化的对照参照,但基于长时间的逆向分析过程中的使用经验,我们认为该模型在二进制安全实践中仍具有一定的可用性。
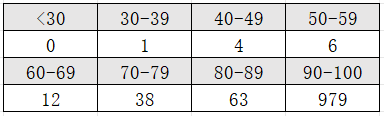
图3.5 可信度区间样本数量统计
关键挑战与思考
虽然大模型在处理汇编/伪代码方面已有一定基础,并通过进一步训练安全和漏洞相关资料以达到较好的辅助分析效果,但在现实应用场景中,所有市面上解决方案均未实现完全脱离人工的理想状态。以下是对该领域当前问题的关键挑战及其思考,希望这有助于推动未来的发展方向和策略。
关键挑战
-
高级混淆和加密技术: 现代恶意软件和某些商业软件广泛使用混淆、加密和加壳技术,防止分析和逆向工程。这些高级技术增加了大模型分析工作的复杂性,要求模型能够识别和解构这些技术。
-
适应性和智能性的需求: 随着攻击技术的持续进化,大模型需要快速适应新威胁并有效应对。这要求技术持续进步并且模型需持续学习和更新。
-
动态与静态分析的结合: 目前大多数模型依赖静态分析,分析不运行的代码。结合动态分析,即分析程序运行时行为,可以提供更深入的程序操作洞察,是提高分析效果的关键。
思考与解决策略
-
增强模型对混淆技术的理解能力:通过增加与混淆和加密技术相关的训练数据或开发专门针对这些技术的模型组件,以提高大模型的表现。
-
持续学习和模型更新: 建立机制使模型可以持续学习最新的威胁情报和攻击技术,可通过在线学习或定期更新训练数据集实现。
-
多模态分析方法: 结合静态和动态分析技术,开发多模态分析系统,充分利用两者优势。
通过实施这些策略,可以更有效地利用大模型技术应对二进制安全分析中的挑战,提高模型的全自动化分析能力,同时应对更加复杂的安全威胁。