今天我们一起来探讨一个分布式环境下的常见问题,这个问题与数据的一致性有关。那么,什么是数据一致性呢?要回答这个问题,需要我们回顾一下单块系统和分布式系统中对于数据处理的不同需求。
我们知道,传统的单块系统通常都只与一个数据库进行交互,所有的数据处理过程都位于一个进程中,因此数据一致性可以直接通过数据库的本地事务进行实现。为保证数据的一致性,我们只需要开启一个事务、执行各种数据更新操作、然后提交或回滚事务就可以了。

但在分布式环境下,事情就会变得比较复杂。这时候,假设我们有多个独立的服务,称为服务A和服务B,然后每个服务都会有自己的数据库。从架构设计上讲,服务A与服务B之间应该通过接口进行交互,而不应该直接操作数据库。在这种情况下,数据库的本地事务显然无法保证数据在各个服务之间的一致性。怎么办呢?
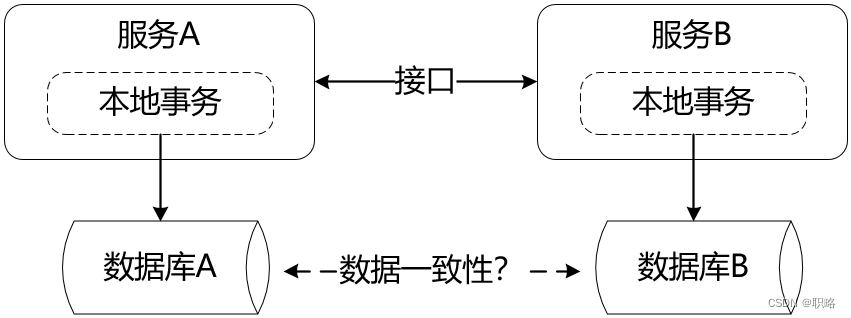
要想实现分布式环境下的数据一致性,一种方法就是采用分布式事务,也就是我们通常所说的两阶段提交和三阶段提交。虽然通过引入这些机制在一定程度上实现了数据之间的一致性,但在很多分布式应用场景下,基于数据强一致性管理方式的分布式事务并不一定合适。一方面,分布式事务在应对复杂多变的数据访问场景时缺乏灵活性;另一方面,事务中锁定资源和序列化数据的成本也很高。而对于像NoSQL等不支持多阶段提交的数据库而言,显然也就无法实现数据的一致性。