本文给出一个 GPT4 模型可视化token的工具网站,大家可以去上面测试一下效果。
网址:
https://platform.openai.com/tokenizer
使用说明
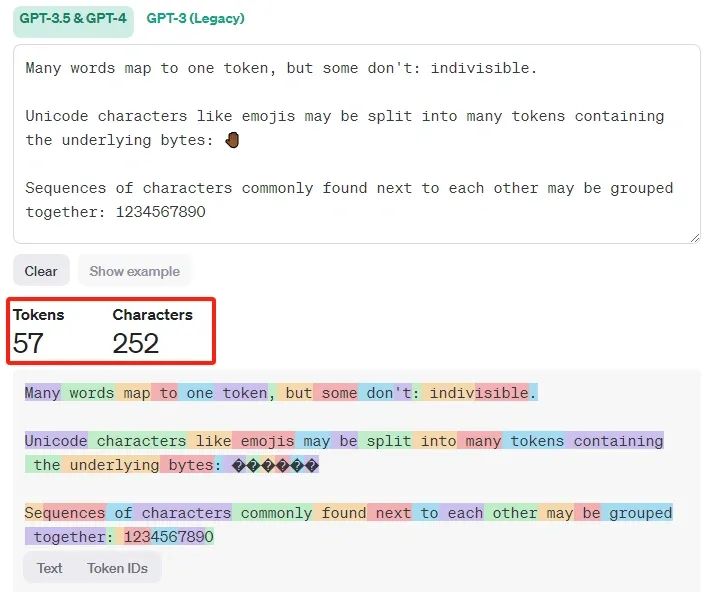
通过该网站工具,你可以了解一段文本如何被GPT-4模型token化的,以及文本的被token化之后的token总数是多少。
比如像下面这样:
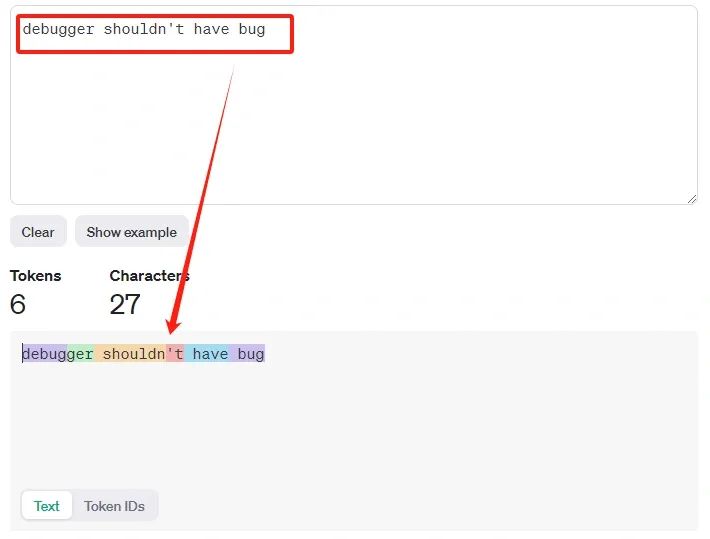
当输入文本中含有debugger时,同样被拆分为了debug和##ger,这和之前介绍token的文章时提到的是一致的,比如这篇文章:利用bert对文本token化。
这说明debug确实是一个非常常见的基础子词。
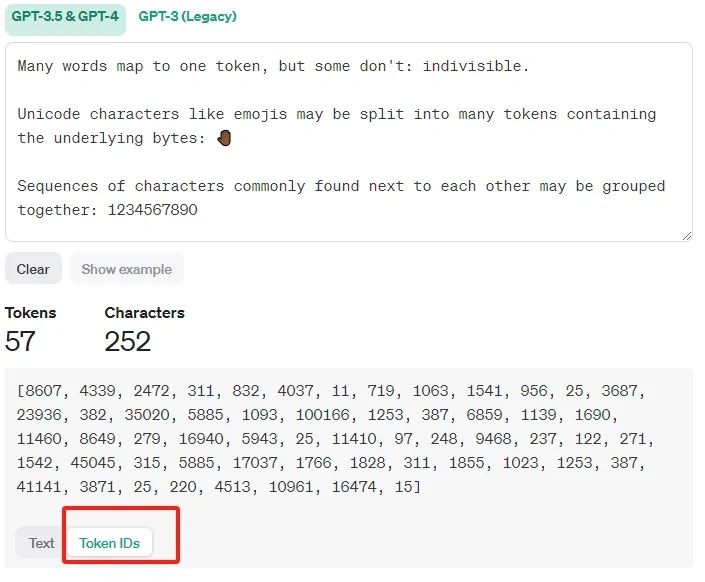
当然你也可以将token转换为tokenID来查看。关于tokenID,后面会详细介绍其作用。
需要注意的是,具体的文本token化结果与模型有关。
像GPT-3.5和GPT-4这样的模型使用的方法与旧模型(比如GPT-2)会有不同,不同的token算法对于相同的输入文本会产生不同的token序列。
按照GPT-4官方给出的经验数据:对于常见的英文文本,一个tokne大概对应4个英文字符,大约相当于 3/4 个单词。
所以100个token大约等于75个单词。
本节为一个工具介绍,仅做了解即可。
最近开始撰写《Transformer专栏》了,会以最通俗的讲解方式来讲透其中的所有算法原理和使用动机。欢迎关注。移步:我的 Transformer 专栏来了
我的Transformer专栏来啦-CSDN博客文章浏览阅读558次,点赞11次,收藏5次。现在很多主流的大语言模型,比如chatGPT都是基于该架构进行的模型设计,可以说Transformer顶起了AI的半壁江山。对于这些有些枯燥的概念,有些乏味的数学表达,我会尽可能说的直白和通俗易懂,打通理解Transformer的最后一公里。我会在本公众号进行文章的首发,相关文章会添加标签“Transformer专栏”,可点击文章左下角的标签查看所有文章。巧的是,下班路上刚手敲完大纲,晚上一个小伙伴来咨询学习LLM的事情,问我之前写的《五一节前吹的牛,五一期间没完成,今天忙里偷闲,给完成了。https://blog.csdn.net/dongtuoc/article/details/138633936?spm=1001.2014.3001.5501