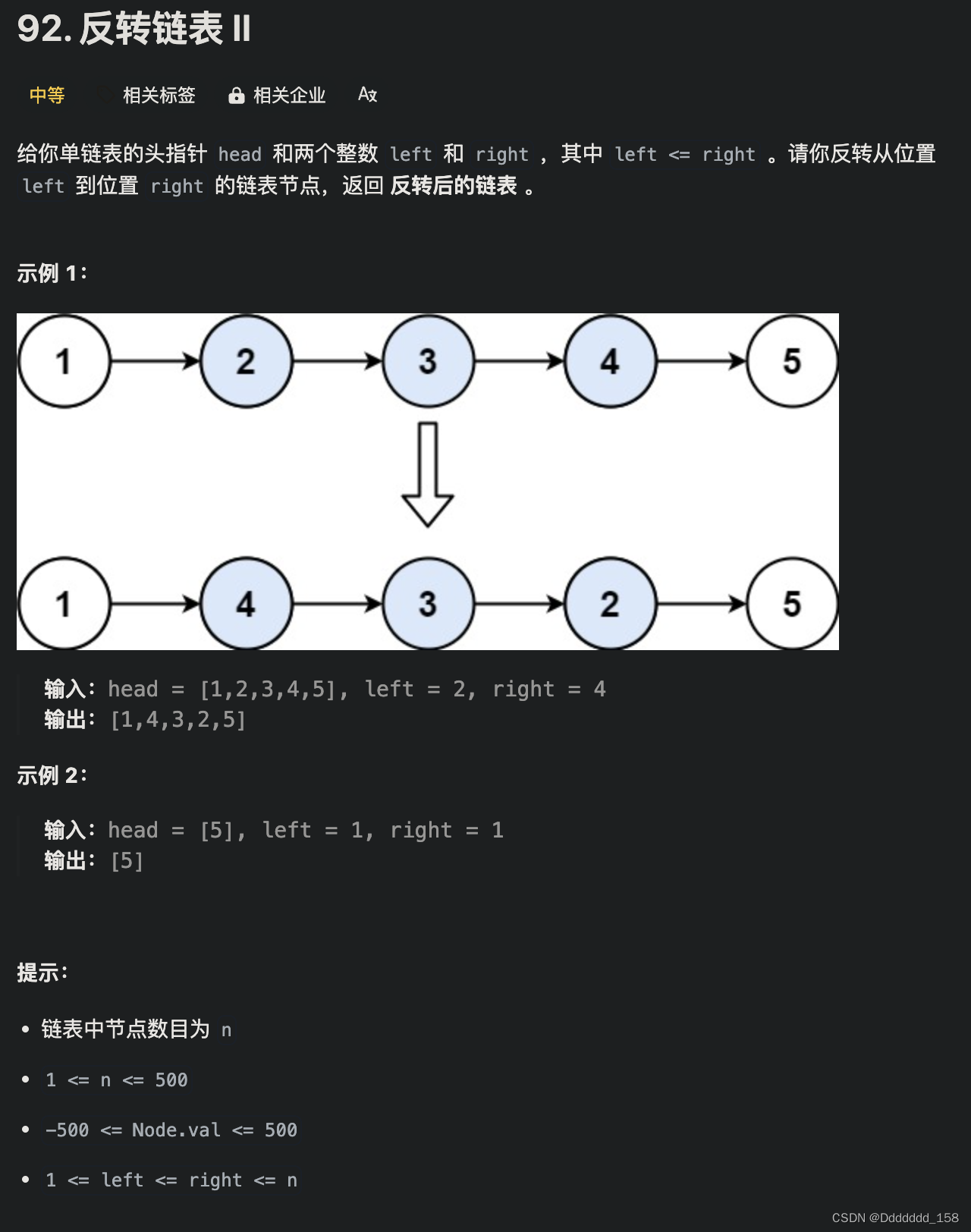
Hi,我是阿佑,前文给大家讲了,如何做一个合法“采蜜”的蜜蜂,有了这么个自保的能力后,阿佑今天就将和大家踏入 —— 异步爬虫 的大门!
异步爬虫大法
- 1. 引言
- 1.1 爬虫框架的价值:效率与复杂度管理
- 1.2 高级应用:从单一抓取到数据挖掘
- 1.3 小明的数据之旅
- 2. Scrapy框架详解
- 2.1 Scrapy简介
- 2.1.1 架构与组件
- 2.1.2 安装与环境配置
- 2.2 核心概念
- 2.2.1 Spiders:爬虫定义与数据提取
- 2.2.2 Items:数据结构设计
- 2.2.3 Selectors:高效的数据提取工具
- 2.2.4 Middlewares:中间件的使用与自定义
- 2.3 Scrapy实战
- 2.3.1 创建项目与编写第一个Spider
- 2.3.2 数据处理与存储扩展
- 2.3.3 爬虫调度与去重策略
- 3. 高级爬虫技巧与框架
- 3.1 异步爬虫
- 3.1.1 异步IO原理
- 3.1.2 Aiohttp结合异步爬虫实例
- 3.2 分布式爬虫
- 3.2.1 分布式爬虫概念与优势
- 3.2.2 Scrapy-Redis与分布式部署实践
- 3.3 机器学习辅助爬虫
- 3.3.1 数据预处理与特征提取
- 3.3.2 应用案例:内容分类与质量评估
1. 引言
在数据的大海中,有一群特殊的“潜水员”,他们不寻珍珠,不探宝藏,他们的目标是那些散落在网络深处的数字和信息。这些“潜水员”就是我们今天的主角——爬虫。
1.1 爬虫框架的价值:效率与复杂度管理
让我们来认识一下小明,一个对数据充满热情的年轻人。小明是个数据迷,他总是梦想着能够从互联网的海量信息中,挖掘出有价值的数据宝藏。但是,小明很快发现,没有合适的工具,单凭手工操作,他就像是在用勺子挖井,效率极低。
直到有一天,小明遇到了Scrapy——一个强大的爬虫框架。Scrapy就像是给小明的勺子装上了涡轮增压,让他的数据挖掘效率瞬间提升。Scrapy通过提供一套标准化、模块化的工具,让小明能够更加高效地进行数据采集,同时降低了开发和维护的复杂度。
1.2 高级应用:从单一抓取到数据挖掘
随着小明对Scrapy的熟练掌握,他不再满足于仅仅是数据的抓取。他开始探索更高级的应用——数据挖掘。数据挖掘,就像是在找到宝藏后,进一步研究它们的历史、价值和可能的用途。
小明开始尝试使用Scrapy进行更复杂的数据处理和分析。他利用Scrapy的强大功能,不仅能够抓取网页数据,还能对数据进行清洗、分类、甚至预测分析。小明的数据挖掘之旅,就像是从一座小岛出发,逐渐探索到整个数据的海洋。
1.3 小明的数据之旅
小明的故事,其实是每一个数据采集者的缩影。从最初的手工操作,到使用爬虫框架,再到进行高级的数据挖掘,小明的成长之路,也是数据采集技术发展的缩影。
在这个故事中,小明代表了每一个对数据充满热情的人。他的成长,也映射了数据采集技术从简单到复杂,从单一到多元的发展趋势。
通过小明的故事,我们可以看到,无论是个人还是企业,掌握高效的数据采集和分析技术,都是在这个数据驱动的时代中,获得竞争优势的关键。
在接下来的章节中,我们将跟随小明的脚步,深入探索Scrapy框架的奥秘,学习如何构建高效的爬虫系统,以及如何利用高级技术进行数据挖掘。让我们一起,跟随小明,踏上这场充满挑战和机遇的数据之旅吧!

2. Scrapy框架详解
Scrapy,这个名字听起来就像是为网络数据采集而生的。它是一个快速的、高层次的网页爬取和网页抓取框架,用于爬取网站并从页面中提取结构化的数据。Scrapy使用了一些非常复杂的技术,但它提供了一个极其简单的API来处理网页抓取和解析,即使是新手也能快速上手。
2.1 Scrapy简介
2.1.1 架构与组件
Scrapy的架构设计得非常巧妙,它由一系列的组件组成,每个组件都有其独特的职责,但又相互协作,共同完成数据采集的任务。
- 引擎(Engine):是Scrapy的心脏,负责控制数据流和各个组件之间的交互。
- 调度器(Scheduler):负责接收引擎发送的请求并将它们入队,以便之后引擎请求时能够提供。
- 下载器(Downloader):负责获取网页数据,并将网页返回给爬虫进行处理。
- 爬虫(Spiders):负责解析响应并提取数据,将解析出的数据转换为Scrapy的Item对象,同时也负责生成需要进一步处理的新的请求。
- 项目管道(Item Pipeline):负责处理由爬虫提取出来的Item,并执行一系列任务,如清洗、验证和存储数据。
- 下载器中间件(Downloader Middlewares):位于Scrapy的下载器和引擎之间的框架,主要是处理引擎与下载器之间的请求和响应。
- 爬虫中间件(Spider Middlewares):位于Scrapy的爬虫和引擎之间的框架,主要处理爬虫输入的响应和输出的结果及新的请求。
2.1.2 安装与环境配置
安装Scrapy非常简单,你只需要拥有Python和pip(Python的包管理工具),然后在命令行中输入以下命令即可安装Scrapy:
pip install scrapy
安装完成后,你就可以通过以下命令创建一个新的Scrapy项目:
scrapy startproject myproject
创建项目后,你需要配置一些环境变量,比如设置部署分布式爬虫时使用的Redis服务器等。
2.2 核心概念
2.2.1 Spiders:爬虫定义与数据提取
Spider是Scrapy中用于定义爬取目标和解析网页的类。每个Spider都定义了如何跟进链接,以及如何从解析的数据中提取结构化信息。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'# 爬虫的起始网页start_urls = ['http://www.example.com']def parse(self, response):# 解析响应数据的函数self.log('Found', response.url)
2.2.2 Items:数据结构设计
Item是Scrapy中定义数据结构的方式,它允许你为收集的数据定义一个清晰的结构。
import scrapyclass MyItem(scrapy.Item):# define the fields for your item here like:title = scrapy.Field()description = scrapy.Field()# ...
2.2.3 Selectors:高效的数据提取工具
Selectors是Scrapy提供的一种快速提取HTML和XML中数据的方式。它使用 XPath 或 CSS 表达式来选择和提取网页中的元素。
response.xpath('//div[@class="title"]')
response.css('div.title')
2.2.4 Middlewares:中间件的使用与自定义
Middlewares允许你自定义(修改、丢弃、增加)引擎与爬虫之间的请求和响应。
2.3 Scrapy实战
2.3.1 创建项目与编写第一个Spider
让我们开始一个实战项目:用Scrapy来抓取一个新闻网站的新闻标题和链接。首先,创建一个新的Scrapy项目:
scrapy startproject news_scraper
cd news_scraper
然后,生成一个Spider:
scrapy genspider news_spider example.com
现在,编辑 news_spider.py 文件,定义我们的Spider:
import scrapyclass NewsSpider(scrapy.Spider):name = 'news_spider'# 起始网页,这里以http://example.com/news为例start_urls = ['http://example.com/news']# 解析响应的方法def parse(self, response):# 提取新闻标题和链接,并保存到Item中for news in response.css('div.article'):yield {'title': news.css('h2::text').get(),'link': news.css('a::attr(href)').get(),}# 提取下一页的链接,并请求下一页next_page = response.css('a.next::attr(href)').get()if next_page is not None:yield response.follow(next_page, self.parse)
2.3.2 数据处理与存储扩展
接下来,我们将处理抓取的数据,并将其存储到JSON文件中。首先,我们需要定义一个Item:
import scrapyclass NewsItem(scrapy.Item):title = scrapy.Field()link = scrapy.Field()
然后,我们修改Spider,使用Item来保存数据:
# news_spider.py
...def parse(self, response):# 使用Item保存数据for news in response.css('div.article'):item = NewsItem()item['title'] = news.css('h2::text').get()item['link'] = news.css('a::attr(href)').get()yield itemnext_page = response.css('a.next::attr(href)').get()if next_page is not None:yield response.follow(next_page, self.parse)
最后,我们设置Scrapy的输出格式为JSON:
scrapy crawl news_spider -o news.json
2.3.3 爬虫调度与去重策略
为了避免重复抓取同一页面,Scrapy内置了一个去重机制。通过 DUPEFILTER_CLASS 设置,我们可以启用这个机制:
# settings.py
DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter'
此外,Scrapy的调度器会跟踪每个请求的来源,确保不会重复处理相同的页面。
现在,让我们看看一个更完整的实战项目示例,抓取一个虚构的新闻网站,并存储结果到JSON文件:
# news_spider.py
import scrapy
from news_scraper.items import NewsItemclass NewsSpider(scrapy.Spider):name = 'news_spider'start_urls = ['http://example.com/news']def parse(self, response):for news in response.css('div.article'):yield NewsItem(title=news.css('h2::text').get(),link=news.css('a::attr(href)').get())next_page = response.css('a.next::attr(href)').get()if next_page is not None:yield response.follow(next_page, callback=self.parse)# items.py
import scrapyclass NewsItem(scrapy.Item):title = scrapy.Field()link = scrapy.Field()
在项目根目录下运行爬虫:
scrapy crawl news_spider -o output.json
这个命令会启动名为 news_spider 的爬虫,并将结果以JSON格式保存到 output.json 文件中。
通过这个实战项目,我们不仅学会了如何创建Scrapy项目和编写Spider,还了解了如何处理数据和存储结果。更重要的是,我们学会了如何避免重复抓取同一页面,这是构建高效、有道德的爬虫的关键。
记住,无论我们的技术多么高超,都应该尊重数据来源网站的规定,合理合法地进行数据采集。这样,我们的数据之旅才能行稳致远。

3. 高级爬虫技巧与框架
在数据采集的江湖中,Scrapy 框架无疑是一把锋利的宝剑,但高手过招,还需掌握一些独门秘籍。接下来,让我们探索几个高级的爬虫技巧,它们就像是给这把宝剑加持了魔法,让你在数据采集的征途上如虎添翼。
3.1 异步爬虫
在传统的爬虫中,每次下载和处理网页都是同步进行的,这就像是你开着一辆老爷车,每次只能载一个乘客,效率自然上不去。而异步爬虫则像是给你的老爷车装上了涡轮增压,让你能够同时处理多个请求,效率大大提升。
3.1.1 异步IO原理
异步IO(Input/Output)是一种计算模型,它允许程序在等待IO操作(如网络请求)完成时,继续执行其他任务。这就像是你在等公交的时候,不是傻站着,而是可以刷刷手机,看看书,时间利用得更充分。
在Python中,asyncio库为我们提供了异步编程的基础,而aiohttp则是一个支持异步的HTTP客户端/服务器框架,它们俩的结合,可以让你的爬虫飞起来。
3.1.2 Aiohttp结合异步爬虫实例
下面是一个使用aiohttp的异步爬虫示例:
import aiohttp
import asyncioasync def fetch(url):async with aiohttp.ClientSession() as session:async with session.get(url) as response:return await response.text()async def main():urls = ['http://example.com', 'http://anotherexample.com']tasks = [fetch(url) for url in urls]results = await asyncio.gather(*tasks)for result in results:print(result)if __name__ == '__main__':asyncio.run(main())
这段代码会并发地抓取两个网页的内容,而不是一个接一个地抓取,大大提升了效率。
3.2 分布式爬虫
当你的爬虫开始处理大规模的数据采集任务时,单台机器的资源可能就不够用了。这时,分布式爬虫的概念就派上了用场。
3.2.1 分布式爬虫概念与优势
分布式爬虫将爬取任务分散到多台机器上执行,每台机器负责一部分任务。这就像是你组织了一支庞大的探险队,每个队员都有自己的任务,大家一起协作,效率自然比单打独斗要高。
分布式爬虫的优势在于:
- 高吞吐量:多台机器并行工作,可以处理更多的请求。
- 高可用性:即使某台机器宕机,其他机器仍然可以继续工作。
- 易于扩展:需要更多资源时,只需增加机器即可。
3.2.2 Scrapy-Redis与分布式部署实践
Scrapy-Redis是一个将Scrapy与Redis结合的库,它使用Redis作为消息队列,协调各个爬虫节点的工作。
部署Scrapy-Redis的大致步骤如下:
-
安装Scrapy-Redis:
pip install scrapy-redis -
在项目的
settings.py文件中启用Scrapy-Redis:# settings.py ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 300, } DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' SCHEDULER = 'scrapy_redis.scheduler.Scheduler' -
运行Redis服务器,并在爬虫节点上配置Redis服务器的地址。
-
启动爬虫节点,它们会从Redis队列中获取任务,并将自己的结果存回Redis。
通过这种方式,你可以轻松地将爬虫部署到多台机器上,构建起一个强大的分布式爬虫系统。
3.3 机器学习辅助爬虫
在数据采集的江湖中,机器学习就像是一剂神奇的药水,能够让我们的爬虫变得更加智能,更加强大。下面,让我们一起探索如何将机器学习融入到爬虫中,让我们的爬虫变得更加聪明。
3.3.1 数据预处理与特征提取
在机器学习的世界里,数据就是一切。在开始机器学习之前,我们需要对数据进行预处理,提取出有用的特征。
数据预处理就像是在烹饪一道大餐前,需要先准备好食材。我们可能需要清洗数据,去除噪声,提取出有用的信息。然后,我们使用特征提取技术,从预处理后的数据中提取出有用的特征,供机器学习模型使用。
这个过程就像是在挑选食材,只有最新鲜、最优质的食材,才能烹饪出最美味的大餐。
3.3.2 应用案例:内容分类与质量评估
一旦我们准备好了数据,就可以开始训练机器学习模型了。一个典型的应用案例是内容分类和质量评估。通过训练一个机器学习模型,我们可以自动识别网页内容的主题,或者评估内容的质量。
例如,使用TensorFlow和Keras构建一个简单的文本分类模型:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences# 假设我们有一些文本数据和对应的标签
texts = ["这是一个好的例子", "这是一个坏的例子"]
labels = [0, 1]# 定义Tokenizer
tokenizer = Tokenizer(num_words=100, oov_token="<OOV>")
tokenizer.fit_on_texts(texts)# 转换文本为序列
sequences = tokenizer.texts_to_sequences(texts)
padded = pad_sequences(sequences, maxlen=10)# 构建一个简单的模型
model = keras.Sequential([keras.layers.Embedding(100, 16, input_length=10),keras.layers.GlobalAveragePooling1D(),keras.layers.Dense(24, activation="relu"),keras.layers.Dense(1, activation="sigmoid"),
])# 编译模型
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])# 训练模型
model.fit(padded, labels, epochs=10)
训练完成后,这个模型就可以用于预测新网页内容的分类了。
通过机器学习,我们的爬虫不仅仅是一个简单的数据采集工具,它还可以变得更加智能,能够理解网页内容的含义,从而做出更加精准的决策。
掌握了这些高级技巧,你就像是拥有了一本秘籍的武林高手,可以在数据采集的江湖中游刃有余。但记住,真正的高手,不仅要有强大的技巧,还要有正确的价值观和责任感。在使用爬虫技术时,一定要遵守法律法规,尊重数据来源网站的规定,做一个有道德的“数据侠”。

通过训练好的模型,我们可以预测新新闻的主题,或者评估新闻的质量。这就像是给我们的爬虫装上了一个智能大脑,让它能够理解数据的含义,做出更加精准的决策。
当然,机器学习的应用远不止于此。我们还可以使用机器学习来识别验证码,模拟复杂的用户行为,甚至是预测网站的结构变化。
掌握了机器学习辅助爬虫的技巧,你就像是拥有了一件强大的武器,在数据采集的江湖中,你将所向披靡。
但记住,无论我们的技术多么高超,都应该尊重数据来源网站的规定,合理合法地进行数据采集。这样,我们的数据之旅才能行稳致远。
通过机器学习,我们的爬虫不仅仅是一个简单的数据采集工具,它还可以变得更加智能,更加强大。在未来,随着技术的不断进步,爬虫将变得更加智能化,自动化,它将能够更好地理解和处理数据,为我们的决策提供更加有力的支持。
让我们一起,继续在数据的海洋中乘风破浪,勇往直前,探索更多的可能!
我是阿佑,一个专磕 python 的中二青年,欢迎持续关注,未完待续!