论文:https://arxiv.org/pdf/2405.01434
主页:StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
一、摘要总结
本文提出了一种名为StoryDiffusion的新方法,用于生成一系列内容一致的图像和视频,特别是那些包含主体和复杂细节的图像。StoryDiffusion通过两种新颖的组件来实现这一目标:Consistent Self-Attention(一致性自注意力)和Semantic Motion Predictor(语义运动预测器)。
- Consistent Self-Attention:这是一种新的自注意力计算方式,能够在不需要训练的情况下,通过零样本(zero-shot)的方式显著提升生成图像间的一致性。它通过在自注意力的计算过程中引入参考图像的采样token,增强了图像间的身份和服饰一致性,这对于讲述故事/故事绘本至关重要。
- Semantic Motion Predictor:这是一个新颖的语义空间时间运动预测模块,它被训练用来估计两张给定图像在语义空间中的运动条件。该模块能够将生成的图像序列转换为具有平滑过渡和一致主体的视频,特别是在长视频生成的背景下,相比于仅基于浅特征空间的模块,它提供了更稳定的结果。
二、算法框架
本文提出的StoryDiffusion框架主要分为两个阶段来生成一致性图像和视频:
a.)第一阶段:生成一致性图像
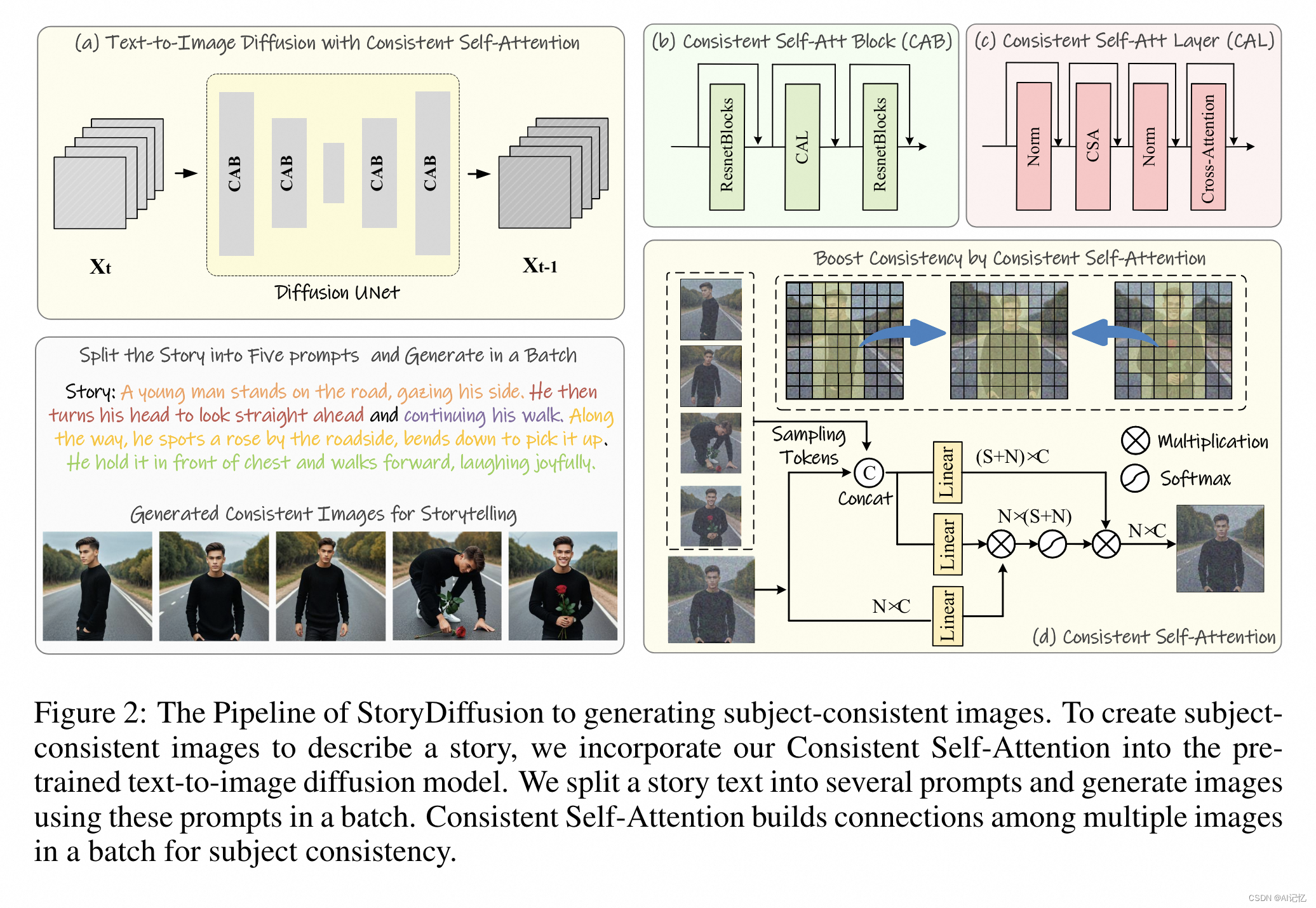
- 文本分割:将一个故事文本分割成多个提示(prompts),每个提示对应一个单独的图像。
- 批量生成:使用分割出的提示批量生成图像。
- Consistent Self-Attention (CAB):将一致性自注意力模块插入到预训练的文本到图像的扩散模型中。这个模块在生成过程中建立图像间的关系,以保持角色的一致性。
- 无需训练的插入:Consistent Self-Attention利用原始的自注意力权重,无需额外训练,即可插入并使用。
b.)第二阶段:生成一致性过渡视频

- 图像序列到视频:将生成的一致性图像序列通过插入帧转换为视频,这里视作已知起始和结束帧的视频生成任务。
- Semantic Motion Predictor:使用语义运动预测器来预测两个给定图像之间的过渡条件。该模块首先将起始帧和结束帧编码到语义空间中,以捕获空间信息。
- 预测中间帧:在语义空间中,使用基于Transformer的结构预测器来预测中间帧的嵌入。
- 视频扩散模型:将预测的嵌入作为控制信号,使用视频生成模型进行解码,生成最终的过渡视频。
c.)核心流程细节
- Consistent Self-Attention:通过随机采样来自批次中其他图像的特征token,并在自注意力计算中将它们与当前图像的特征合并,以此来增强图像间的一致性。
- Semantic Motion Predictor:利用预训练的CLIP图像编码器将图像映射到语义空间,然后通过Transformer块来预测中间帧的嵌入,最后使用视频扩散模型生成视频。
整个StoryDiffusion框架的设计旨在通过这两个阶段,实现文本故事到一致性图像和视频的高效生成,同时保持对文本提示的高控制性。
三、实验结果
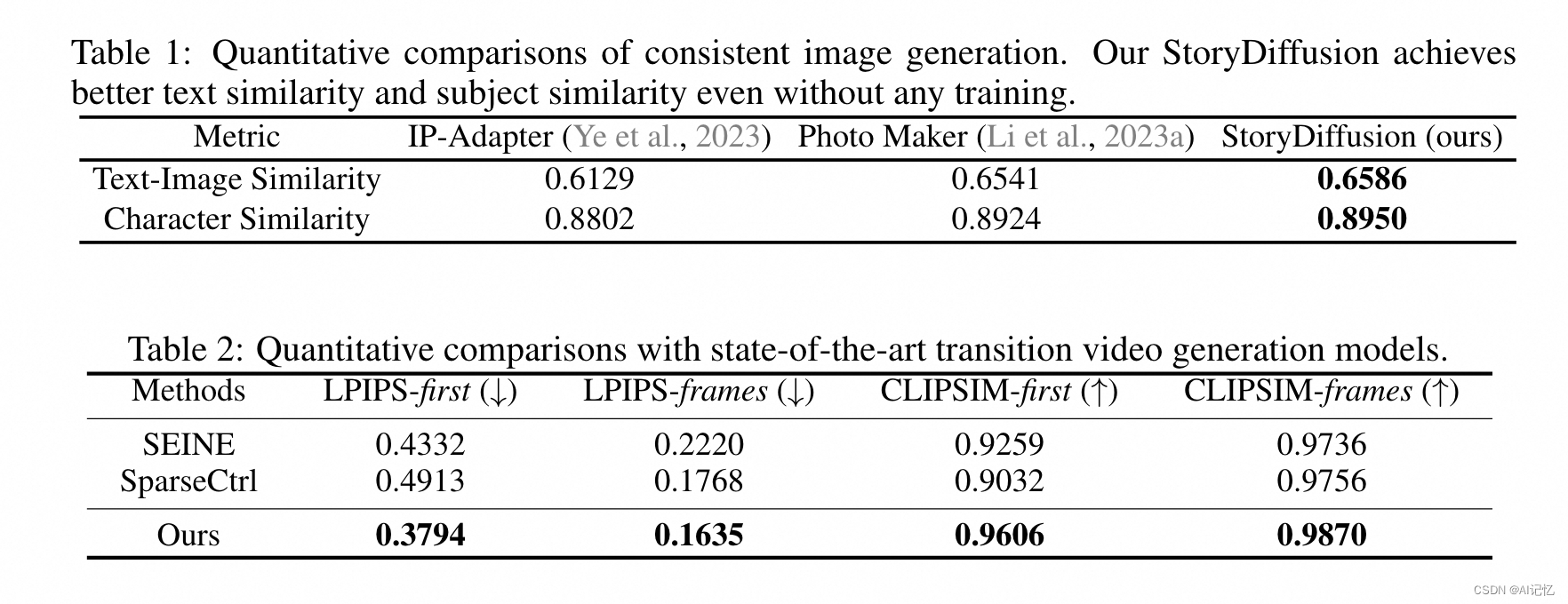
a.)总体指标
- 在与最近的ID保持方法(IP-Adapter和PhotoMaker)进行比较时,StoryDiffusion在文本-图像相似性和角色相似性两个定量指标上均取得了更好的性能。

- 在过渡视频生成方面,与SEINE和SparseCtrl两种最先进的方法相比,StoryDiffusion在所有四个定量指标(LPIPS-first, LPIPS-frames, CLIPSIM-first, CLIPSIM-frames)上均优于其他方法,表明其在生成一致且无缝过渡视频方面的强性能。
b.)Ablation Study
- 用户指定ID生成:StoryDiffusion能够结合PhotoMaker生成与给定控制ID一致的一致性图像,展示了方法的可扩展性和即插即用能力。
- 一致性自注意力的采样率:通过消融研究确定了一致性自注意力的最佳采样率为0.5,既能保持主体一致性,又对扩散过程的影响最小。
四、局限性
- 对于一些细节(如领带)可能存在一致性问题,可能需要更详细的提示来保持图像间的一致性。
- 尽管可以使用滑动窗口方法生成更长的视频,但StoryDiffusion并未专门设计用于长视频生成,因此在生成非常长的视频时可能不完美,这是由于缺乏全局信息交换。未来的工作将进一步探索长视频生成。
![[vue] nvm use时报错 exit status 1:一堆乱码,exit status 5](https://img-blog.csdnimg.cn/direct/c685891de8bd42b0a226106117c4baed.png)