文章汇总
存在的问题
在没有归纳偏差的情况下,vit通常在只有少数标记训练数据可用的few-shot学习机制下学习低质量令牌依赖关系,这在很大程度上导致了上述性能下降。
动机
cnn的归纳偏置并不天生就适用于vit,也不能很好地增强和加速vit中的token依赖学习。如果vit可以快速准确地学习令牌依赖关系,因此自然可以从标记较少的训练数据中学习,这与few-shot学习场景是一致的。即引导patch令牌相似或不相似的ViT,从而加速令牌依赖学习。
解决办法
进行了patch级别上的监督学习。并且进一步提出了背景斑块滤波和空间一致性增强两种技术。前者旨在缓解背景patch被错误地分配给语义类和不正确的局部监督的不良情况的影响;后者是在保持生成的特定位置监督的准确性的同时,为数据增强引入足够的多样性。
流程解读
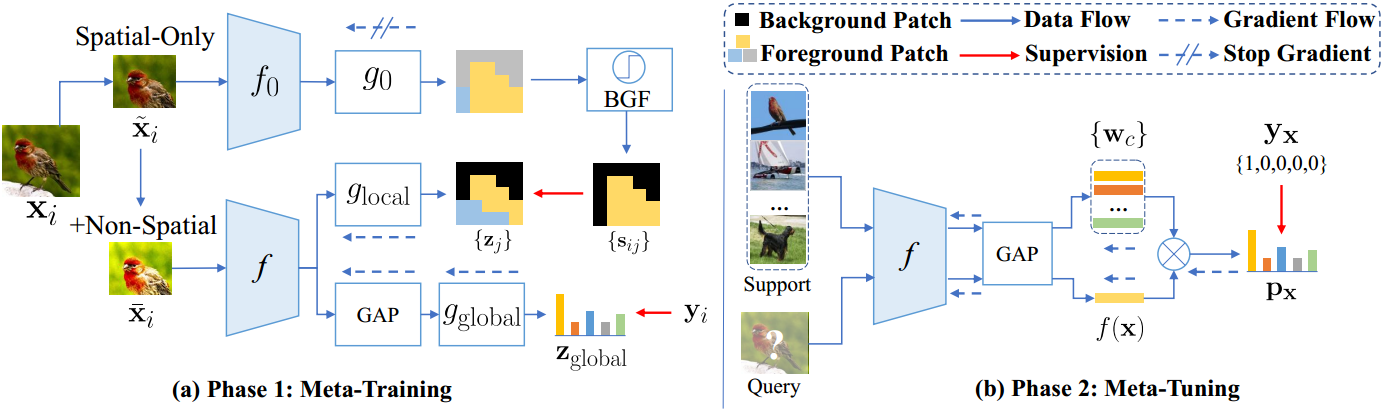
元训练阶段
这里 f , f 0 f,f_0 f,f0都是ViT(实验中作者用了多种ViT模型来比较), g 0 g_0 g0是不看训练的分离器, g g l o b a l , g l o b a l g_{global},g_{lobal} gglobal,global是两个可训练的分类器,分别用于全局语义分类和局部在patch级别上的分类。
对于输入数据,通过空间变换(例如,随机裁剪和调整大小,翻转和旋转)来增强输入图像 x i x_i xi来获得 x ~ i \tilde x_i x~i因此作为 f 0 f_0 f0的输入数据,之后在 x ~ i \tilde x_i x~i上通过非空间变换,例如颜色抖动,获得 x ˉ i \bar x_i xˉi。
me:公式中的 f g ( x ) f_g(x) fg(x)可以理解成 g 0 ( f 0 ( x ) ) g_0(f_0(x)) g0(f0(x))
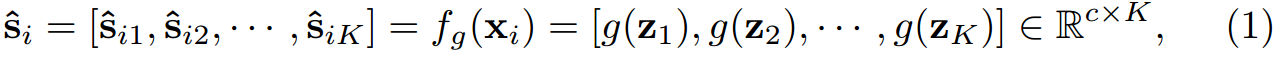
这里的 z z z是通过ViT架构的 f f f获得的 z = f ( x i ) = [ z c l s , z 1 , z 2 , . . . , z k ] z=f(x_i)=[z_{cls},z_1,z_2,...,z_k] z=f(xi)=[zcls,z1,z2,...,zk],最终得到 s ^ i j \hat s_{ij} s^ij来表示样本 x i x_i xi中第 j j j个局部patch x i j x_{ij} xij的伪标签。
损失函数如下:
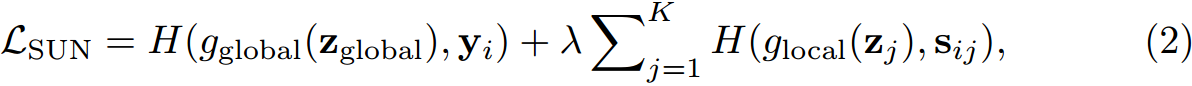
z g l o b a l z_{global} zglobal是所有patch令牌 { z j } j = 1 K \{z_j\}^K_{ j=1} {zj}j=1K的全局平均池化。H为交叉熵损失。 λ \lambda λ为1超参数,作者设置了为0.5。
背景过滤(BGF)技术(me:真正的创新点)
为了解决教师 f 0 f_0 f0总是错误地将背景补丁分配到基础(语义)类(me:标签中的种类)中,而不是背景类中,并提供不准确的特定位置监督。
通过给定一批 m m m个置信度评分为 { s ^ i j } \{\hat s_{ij}\} {s^ij}的patch,我们首先为每个patch选择最大分数,然后对patch的 m m m个分数按升序排序。接下来,我们将分数最低的前p%的patch视为背景patch。同时,我们在基类 C b a s e C_{base} Cbase中添加了一个新的惟一类,即背景类。相应的,我们对生成的伪标签 s ^ i ∈ R c \hat s_{i}\in R^c s^i∈Rc增加一个维度得到 s i j ∈ R c + 1 s_{ij}\in R^{c+1} sij∈Rc+1。
元微调阶段
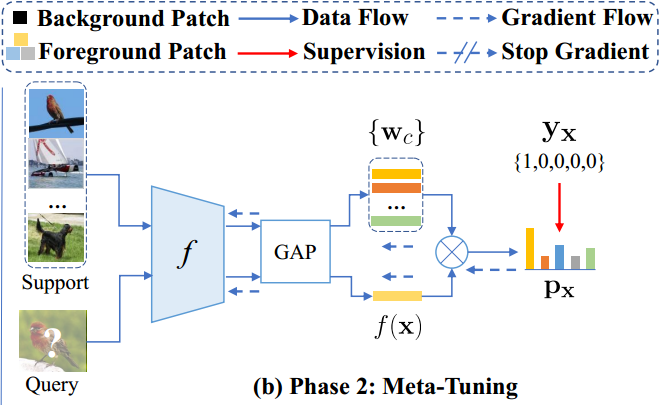
类似于Meta-Baseline
SUN通过 w k = ∑ x ∈ S k G A P ( f ( x ) ) / ∣ S k ∣ w_k=\sum_{x\in S_k}GAP(f(x))/|S_k| wk=∑x∈SkGAP(f(x))/∣Sk∣为第 k k k类的分类原型 w k w_k wk,其中 S k S_k Sk表示来自c类的支持样本,GAP表示全局平均池化操作。
对于每个查询图像 x x x,元学习器 f f f计算第 k k k个类的分类置信度得分:
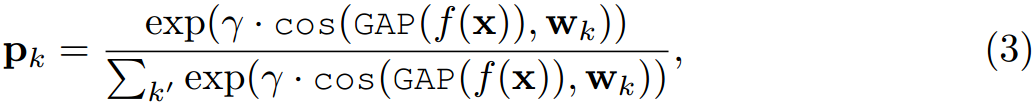
最后,最小化交叉熵损失 L f e w − s h o t = H ( p x , y x ) L_{few-shot} = H(p_x,y_x) Lfew−shot=H(px,yx),对各种采样任务 { τ } \{\tau\} {τ}上的元学习器 f f f进行微调,其中 p x = [ p 1 , . . . , p c ] p_x=[p_1,...,p_c] px=[p1,...,pc]为预测, y x y_x yx为 x x x的真实标签。
摘要
vision transformers(ViTs)的少样本学习能力虽然被广泛关注,但很少被研究。在这项工作中,我们通过经验发现,在相同的少样本学习框架(例如MetaBaseline)中,用ViT模型代替广泛使用的CNN特征提取器通常会严重损害少样本分类性能。此外,我们的实证研究表明,在没有归纳偏差的情况下,vit通常在只有少数标记训练数据可用的few-shot学习机制下学习低质量令牌依赖关系,这在很大程度上导致了上述性能下降。为了缓解这一问题,我们首次提出了一个简单而有效的vit训练框架,即自我促进式监督(SUN)。具体来说,SUN除了对全局语义学习进行常规的全局监督外,还在少样本学习数据集上对ViT进行了进一步的预训练,然后使用它来生成单个特定于位置的监督,以指导每个patch令牌。这种特定于位置的监督告诉ViT哪些patch token相似或不同,从而加速token依赖学习。此外,它还对每个patch令牌中的局部语义进行建模,以提高对象基础和识别能力,从而有助于学习可推广的模式。为了提高特定位置监督的质量,我们进一步提出了两种技术:1)背景斑块过滤,过滤出背景斑块并将其分配到一个额外的背景类中;2)空间一致性增强,为数据增强引入足够的多样性,同时保持生成的局部监督的准确性。实验结果表明,使用vit的SUN显著优于其他使用vit的少样本学习框架,是第一个达到比CNN最先进性能更高的学习框架。我们的代码可以在https://github.com/DongSky/few-shot-vit上公开获得。
1介绍
Vision transformer, ViTs在计算机视觉领域取得了巨大的成功,在图像分类[12,48,49,52,32,65]、目标检测[5,13]和分割[66,43]等许多视觉任务上甚至超过了相应的最先进的cnn。vit成功的一个关键因素是其强大的自我注意机制[50],该机制不引入任何归纳偏见并且与cnn中的卷积机制相比,可以更好地捕捉数据中局部特征之间的长期依赖关系。这促使我们研究两个重要的问题。首先,我们想知道ViTs能否在few-shot学习设置下表现良好,该设置旨在仅以少量标记样本作为参考,从新类别中识别物体。第二,如果没有,如何提高vit的短时学习能力?机器智能非常需要少样本学习能力,因为在实践中,由于数据稀缺(例如疾病数据),捕获数据的设备成本高,人工标记成本高(例如像素级标记),许多任务实际上只有很少的标记数据。在这项工作中,我们对few-shot分类特别感兴趣[51,14,42],这是评估方法的few-shot学习能力的基准任务。
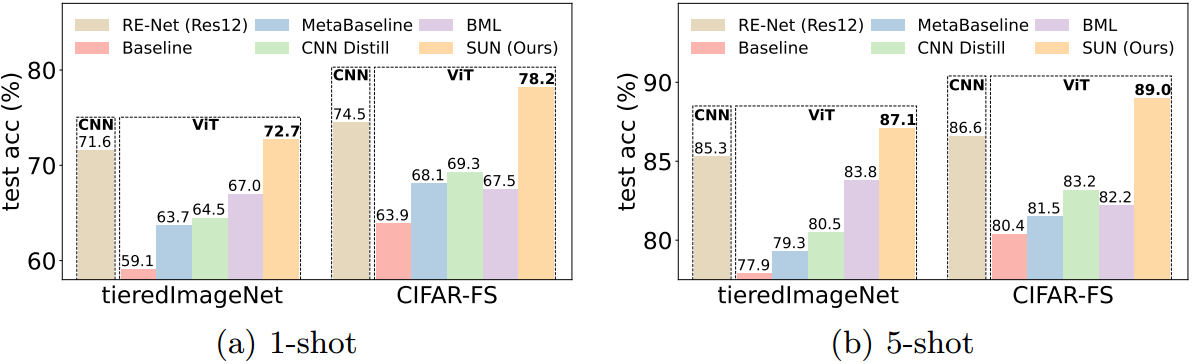
图1所示。不同少样本分类框架的性能比较。除了最先进的RE-Net[21]使用ResNet-12[17]作为特征提取器外,所有方法都使用相同的NesT转换器[65]作为特征提取器。在相同的ViT骨干网下,我们的SUN明显超过了其他基线,甚至比使用CNN骨干网的SoTA基线性能更高。最好以彩色观看。
对于第一个问题,不幸的是,我们通过经验发现,对于具有代表性的few-shot学习框架,例如Meta-Baseline[8],用vit代替CNN特征提取器严重损害了few-shot分类性能。最可能的原因是ViTs缺乏归纳偏倚——在没有任何先验归纳偏倚的情况下,ViTs需要大量的数据来学习局部特征之间的依赖关系,即patch token。我们在第3节中的分析表明,引入类似cnn的归纳偏置可以部分加速vit中的token依赖学习,从而部分缓解这种影响,这也符合[25,64]中在监督学习下的观察结果。例如,在图1中,“Baseline”[7]和“Meta-Baseline”[8]使用的是普通的ViT,而“CNN蒸馏”通过将预训练好的CNN教师网络蒸馏到ViT中,引入了类似CNN的归纳偏置,从而获得了更高的性能。然而,由于vit和cnn具有不同的网络架构,并且cnn中的归纳偏置往往不能很好地捕获远程依赖关系,因此,类似cnn的归纳偏置并不天生就适用于vit,也不能很好地增强和加速vit中的token依赖学习。这自然促使我们思考如何提高vit的少样本学习能力。
因此,我们提出了一种有效的vit学习框架,即自我促进式监督(Self-promoted sUpervisioN,简称SUN)。SUN使ViT模型能够很好地泛化具有少量标记训练数据的未知类别。SUN的核心思想是加强和加速学生之间不同的token的依赖学习,patch tokens,以ViTs为单位。这个想法是直观的,因为如果vit可以快速准确地学习令牌依赖关系,因此自然可以从标记较少的训练数据中学习,这与few-shot学习场景是一致的。特别是,在元训练阶段,SUN为全局特征嵌入提供全局监督,并进一步采用个别特定位置的监督来指导每个patch tokens。在这里,SUN首先在少量学习的训练数据上训练ViT,并使用它来生成patch级伪标签作为特定位置的监督。这就是为什么我们称我们的方法为“自我促进的监督”,因为它使用相同的ViT来产生地方监督。为了提高斑块级监测的质量,我们进一步提出了背景斑块滤波和空间一致性增强两种技术。前者旨在缓解背景补丁被错误地分配给语义类和不正确的局部监督的不良情况的影响;后者是在保持生成的特定位置监督的准确性的同时,为数据增强引入足够的多样性。我们针对特定位置的密集监督从两个方面有利于ViT在少镜头学习任务上的发挥。首先,考虑到所有令牌的特定位置监督是一致的,即相似的局部令牌有相似的伪标签,这种密集的监督告诉ViT哪些补丁令牌相似或不相似,从而可以加速ViT学习高质量的令牌依赖关系。其次,对每个patch令牌中的局部语义进行了很好的建模,以提高ViTs的对象接地和识别能力。实际上,如[68,20]所示,局部令牌中的建模语义可以避免学习偏斜和不可泛化的模式,从而大大提高模型泛化性能,这也是在few-shot学习中非常需要的。这两方面都可以提高vit的短时学习能力。接下来,在元调优阶段,与现有方法类似[8,58],SUN通过在相应的训练数据上微调ViT,使元训练阶段训练的ViT知识适应新的任务。
大量的实验结果表明,在相同的ViT架构下,我们的SUN框架在少样本分类任务上的表现明显优于所有基线框架,如图1所示。此外,据我们所知,具有ViT主干的SUN是第一个将ViT主干应用于少射分类的工作,也是第一个使用类似大小的CNN主干实现比最先进的基线更高性能的ViT方法,如图1所示。这很好地说明了SUN的优越性,因为CNN有很高的归纳偏置,实际上在少样本学习问题上比ViT更适合。此外,我们的SUM也提供了一个简单而坚实的基线,为少样本分类。
2.相关工作
Vision Transformer
与使用卷积捕获图像中的局部信息的cnn不同,ViTs[12]明确地对远程交互进行建模,并且在视觉任务中显示出巨大的潜力。然而,为了达到与在ImageNet上训练的相似模型大小的CNN相当的性能[10],vit需要大规模的数据集来训练[10,44],这大大增加了计算成本。为了缓解这个问题并进一步提高性能,许多工作[48,20,61,56,32,65][54,60,47,26,29,52,57,62]提出有效的解决方案。然而,尽管有了这些先进的技术,vit仍然需要在大规模数据集上进行训练,例如ImageNet[10]或JFT-300M[44],并且经常在小数据集上失败[65,25,64]。最近,一些研究[25,4]也提出了小数据集的vit。例如,Li等[25]从训练良好的CNN初始化ViT,将CNN中的归纳偏置借用到ViT中。同时,Cao等[4]首先使用实例判别损失对ViT进行预训练,然后在目标数据集上对其进行微调。相比之下,我们提出了自我促进的监督,以提供密集的局部监督,增强token依赖学习,缓解数据饥渴问题。此外,我们对少样本学习问题感兴趣,这些问题侧重于使用来自基类的小训练数据初始化vit,并使用少量标记数据泛化新的未见过的类别。
Few-Shot Classification
少样本分类方法大致可分为三类:1)基于优化的方法[14,41,23,69,70],用于快速适应新任务;2)存储重要训练样本的基于记忆方法[39,37,16];3)基于度量的方法[42,8,51,58],学习样本之间的相似性度量。这项工作遵循基于度量的方法的管道,以实现简单和高精度。值得注意的是,最近的一些研究[11,19,58,67,30]也将transformer层与基于度量的方法集成在一起,用于少样本学习。与以往文献[11,19,58,67,30]利用变压器层作为少样本分类器不同,我们的工作重点是提高ViT骨干的少样本分类精度。
3 ViTs在少样本分类中的实证研究
我们研究了各种ViT的少样本学习性能,包括LV-ViT20、LeViT15、Visformer [9] (cnn增强的ViT)、Swin[32]和NesT65。为了公平的比较,我们缩放了这些vit的深度和宽度,使它们的模型尺寸与ResNet12 [17] (~ 12.5M参数)相似,这是最常用的架构,并且在少数样本分类任务上实现了(几乎)最先进的性能。
在这里,我们选择一个简单而有效的Meta-Baseline[8]作为少样本学习框架来测试上述五个vit的性能。具体来说,在元训练阶段,Meta-Baseline执行传统的监督分类;在元调优阶段,给定一个训练任务,它通过对支持集上相同类的样本特征取平均值来计算类原型,然后最小化样本特征与相应类原型之间的余弦距离。对于推理,类似于元调优阶段,给定一个测试任务τ,首先在τ的支持集上计算类原型,并根据测试样本特征与类原型之间的余弦距离为测试样本分配一个类标签。详见4.2节。
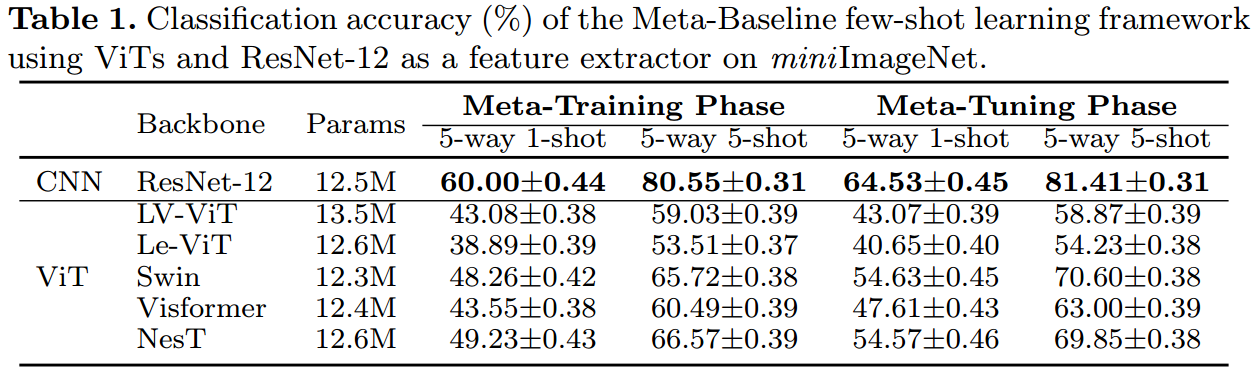
表1总结了miniImageNet上的实验结果[51]。这里的“元训练阶段”是指我们在MetaBaseline中测试元训练阶段之后的vit,而“元调优阶段”是指在元调优阶段之后的vit的测试性能。**令人沮丧的是,人们可以观察到,即使使用相同的MetaBaseline框架,在元训练阶段之后,所有vit的性能都比ResNet-12差得多。**此外,经过元调优阶段后,所有vit的少样本学习性能仍然较差。这些观察结果启发我们去研究vit在元训练期间发生了什么,以及为什么vit的表现比cnn差得多。
分析
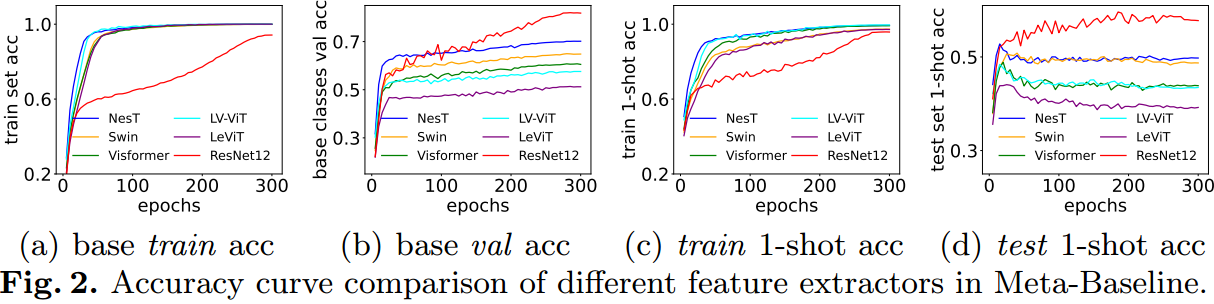
为了分析ViTs在元训练阶段的性能,图2绘制了基本数据集 D b a s e D_{base} Dbase上训练集和验证集的准确率曲线,并报告了新类在训练集和测试集上的5-way 1-shot准确率。从图2(a)和图2(b)中可以看出,所有vit在基本数据集 D b a s e D_{base} Dbase中的训练集和验证集上都有很好的收敛。从图2©可以看出,在整个元训练阶段,ViTs对新类别的训练数据也有很好的收敛,而从图2(d)可以看出,ViTs对新类别的测试数据泛化较差。例如,尽管NesT[65]在前30个元训练时代达到了~ 52%的准确率,但在第30个元训练时代左右,其准确率迅速下降到49.2%。相比之下,ResNet-12在过去100次元训练中保持了近60%的1次准确率。这些观察结果表明,与CNN特征提取器相比,尽管ViTs在数据库上具有良好的泛化能力,但在新类别上往往存在泛化问题。
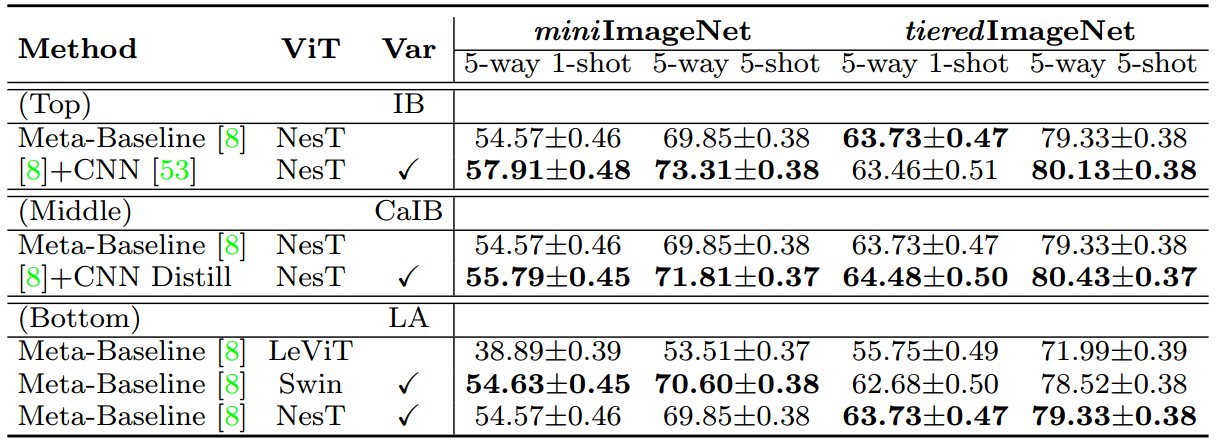
表2。基于两个数据集的ViTs实证分析。(上)显示了感应偏置(IB)对ViTs的少样本精度的影响;(中)研究类似cnn的归纳偏差(CaIB)是否能增强token依赖学习;(下)分析了局部注意(LA)在增强token依赖学习中的作用。
接下来,我们实证分析了为什么ViTs在少样本分类上的表现比cnn差。最可能的解释是缺乏归纳偏置导致性能下降。为了说明这一点,我们介绍归纳偏置(在CNN中)通过三种方式转化为ViT。a)对于每个阶段,我们分别使用一个ViT分支和一个CNN分支独立提取图像特征,并将它们的特征结合起来进行融合。参见附录C.2中的实现细节。这样,该机制继承了CNN分支的归纳偏置。表2(顶部)显示,通过引入这种CNN归纳偏置,新的NesT(即“[8]+CNN”)在很大程度上超过了传统的NesT(“Meta-Baseline[8]”)。b)我们在数据库上训练一个CNN模型,并利用它通过知识蒸馏进行ViT教学[18]。这种方法,即表2(中)中的“[8]+CNN蒸馏”,可以很好地将类似CNN的归纳偏差引入到ViT中以增强依赖学习,并且显著改进了香草的“Meta-Baseline[8]”。为了分析令牌依赖的质量,我们可视化了图4(a)中最后一块香草ViT和cnn蒸馏ViT的注意图。我们可以发现,cnn蒸馏的ViT可以比普通ViT更好地学习令牌依赖,因为前者捕获几乎所有的语义令牌,而后者只捕获少数语义补丁。c)局部关注具有更好的少镜头学习效果。表2(下)显示,在相同的元基线[8]框架下,Swin和NesT的准确率比LeViT高得多,因为Swin和NesT的局部关注引入了(类似cnn的)归纳偏差,并且比LeViT的全局关注可以增强token依赖学习。这些结果表明,归纳偏置有利于少样本分类。
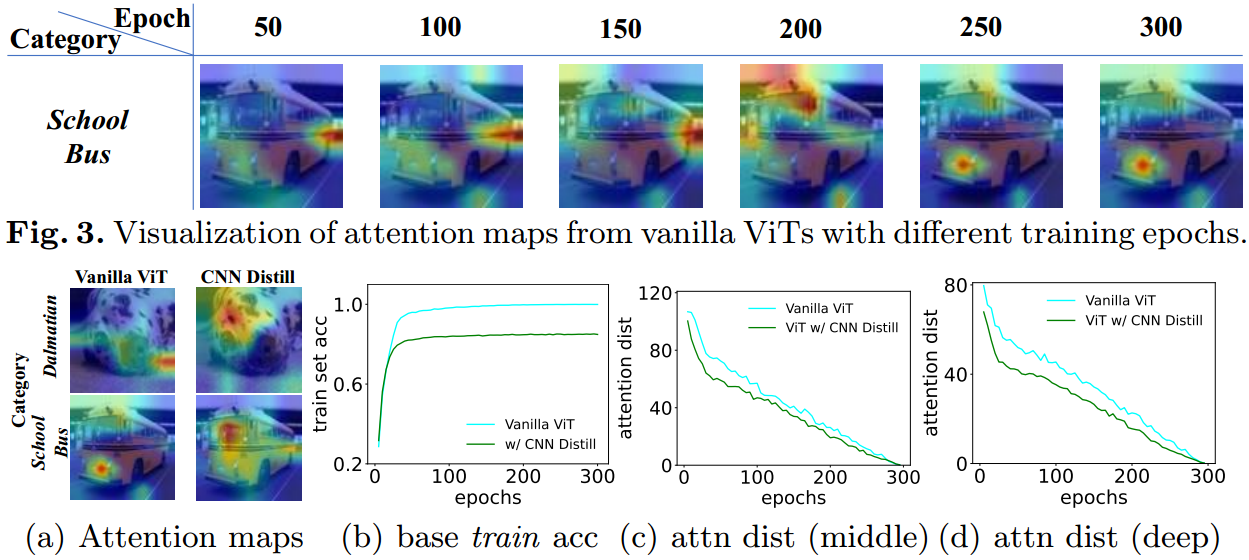
图4所示。(a)香草ViT和cnn蒸馏ViT的注意力图。(b) ViT与cnn -蒸馏ViT之间的训练精度曲线。(c&d) ViT与cnn提炼的ViT在中间层(中)和最后一层(右)的注意得分距离。
4 少样本分类自我推进监督
从第3节的观察和分析中,我们知道1)在现有的few-shot学习框架中,直接用ViT替换CNN特征提取器往往会导致严重的性能下降;2)少样本学习框架增强token依赖学习以弥补归纳偏差的不足,可以提高ViT在少量学习任务上的性能。因此,我们提出了一种自我促进监督(SUN)框架,旨在通过密集的特定位置监督来增强和加速vit中的token依赖学习,从而提高vit的少样本学习能力。与传统的少样本学习框架类似,例如Meta-Baseline,我们的SUN框架也包括两个阶段,即元训练和元调优,如图5所示。下面,我们将介绍这些阶段。
4.1 元训练
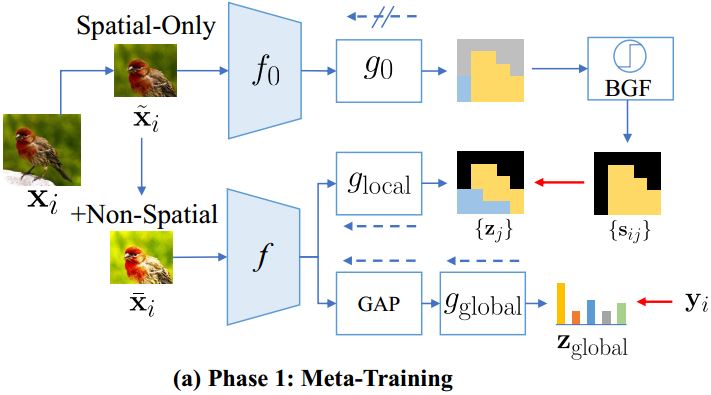
对于图5(a)中的元训练阶段,与meta- baseline类似,我们的目标是学习第3节中提到的元学习器f,使其能够快速适应使用少量训练数据的新类。这里的 f f f实际上是一个特征提取器,在这项工作中是一个ViT模型。SUN的主要思想是一个密集的特定位置监督,旨在增强和加速ViT中的token依赖学习,从而提高有限训练数据上的学习效率。
具体来说,为了在基础数据集 D b a s e D_{base} Dbase上训练元学习者 f f f, SUN使用全局监督,即ground-truth标签,来指导 f f f中所有patch令牌的全局平均令牌,以学习整个图像的全局语义。更重要的是,SUN进一步使用个别的特定位置监督来监督 f f f中的每个patch token。为了生成作为特定位置监督的patch级伪标签,SUN首先进行监督分类预训练,在基础数据集 D b a s e D_{base} Dbase上优化由与 f f f具有相同架构的ViT f 0 f_0 f0和分类器 g 0 g_0 g0组成的教师模型 f g f_g fg。这是合理的,因为教师 f 0 f_0 f0是在 D b a s e D_{base} Dbase上训练的,其预测的patch级伪标签在语义上与整个图像的ground-truth标签一致,即相似的局部和类令牌的相似伪标签。这就是为什么我们的方法被称为自提升的原因,因为 f 0 f_0 f0与 f f f具有相同的架构。从形式上讲,对于基础数据集 D b a s e D_{base} Dbase中的每个训练图像 x i x_i xi, SUN首先计算每个令牌分类置信度分数 s ^ i \hat s_i s^i如下:
式中, z = f ( x i ) = [ z c l s , z 1 , z 2 , . . . , z k ] z=f(x_i)=[z_{cls},z_1,z_2,...,z_k] z=f(xi)=[zcls,z1,z2,...,zk]表示图像 x i x_i xi的类和patch令牌,其中, s ^ i j \hat s_{ij} s^ij表示样本 x i x_i xi中第 j j j个局部patch x i j x_{ij} xij的伪标签。因此,对于每个patch x i j x_{ij} xij,在 s ^ i j \hat s_{ij} s^ij中置信度较高的位置表示该patch包含相应类别的语义。
为了充分发挥局部监督的力量,我们进一步提出了背景过滤(BGF)技术,该技术旨在将背景补丁分类为一个新的独特类别,提高补丁级监督的质量。这种技术是必要的,因为在没有背景类的数据库 D b a s e D_{base} Dbase上进行训练,教师 f 0 f_0 f0总是错误地将背景补丁分配到基础(语义)类(me:标签中的种类)中,而不是背景类中,并提供不准确的特定位置监督。为了解决这个问题,我们将置信度非常低的局部补丁过滤为背景补丁,并将其分类为一个新的唯一类。具体来说,给定一批 m m m个置信度评分为 { s ^ i j } \{\hat s_{ij}\} {s^ij}的patch,我们首先为每个patch选择最大分数,然后对patch的 m m m个分数按升序排序。接下来,我们将分数最低的前p%的patch视为背景patch。同时,我们在基类 C b a s e C_{base} Cbase中添加了一个新的惟一类,即背景类。相应的,我们对生成的伪标签 s ^ i ∈ R c \hat s_{i}\in R^c s^i∈Rc增加一个维度得到 s i j ∈ R c + 1 s_{ij}\in R^{c+1} sij∈Rc+1。对于背景patch,其伪标签 s i j ∈ R c + 1 s_{ij}\in R^{c+1} sij∈Rc+1的最后一个位置为1,其余位置为0。对于非背景补丁,我们只设置他们的伪标签的最后位置为0,而不改变其他值。这样,给定一张带有真值标签 y i y_i yi的图像 x i x_i xi,我们定义它的整体训练损失:
其中 z = f ( x i ) = [ z c l s , z 1 , z 2 , . . . , z k ] z=f(x_i)=[z_{cls},z_1,z_2,...,z_k] z=f(xi)=[zcls,z1,z2,...,zk]表示图像 x i x_i xi的类和patch令牌, z g l o b a l z_{global} zglobal是所有patch令牌 { z j } j = 1 K \{z_j\}^K_{ j=1} {zj}j=1K的全局平均池化。其中H为交叉熵损失, g g l o b a l , g l o b a l g_{global},g_{lobal} gglobal,global是两个可训练的分类器,分别用于全局语义分类和局部补丁分类。对于λ,为了简单起见,我们在所有实验中将其设置为0.5。
现在,我们讨论密集监督(me:即patch级别上的有监督学习)对少样本学习任务的两个好处。首先,所有特定位置的监督都是由教师生成的,因此保证了类似的本地令牌的类似伪标签。这实际上告诉ViT哪些patch令牌相似或不同,从而可以加速令牌依赖学习。其次,相对于对整个图像的全局监督,特定位置监督是在细粒度级别,即patch级别,从而帮助ViTs更容易发现目标物体,提高识别精度。这一点也与之前的一些文献一致。例如,研究[68,20]表明,局部令牌中的建模语义可以避免学习倾斜和不可泛化的模式,从而大大提高模型的泛化性能。因此,这两个方面在少样本学习问题中都是非常需要的,并且可以提高vit的少样本学习能力。
为了在保持足够的数据多样性的同时进一步提高教师0的局部监督的鲁棒性,我们提出了一种“空间一致性增强”(SCA)策略来提高泛化。SCA由纯空间增强和非空间增强组成。在纯空间增强中,我们只引入空间变换(例如,随机裁剪和调整大小,翻转和旋转)来增强输入图像 x i x_i xi并获得 x ~ i \tilde x_i x~i。对于非空间增强,它只利用非空间增强,例如颜色抖动,在 x ~ i \tilde x_i x~i上获得 x ˉ i \bar x_i xˉi。在元训练阶段,我们将 x ~ i \tilde x_i x~i输入到teacher f 0 f_0 f0中以生成用于Eqn的 s i j s_{ij} sij。(2),并将 x ˉ i \bar x_i xˉi输入目标元学习器 f f f。这样,用于训练元学习器 f f f的样本具有高度的多样性,同时仍然享有非常准确的位置特定监督 s i j s_{ij} sij,因为教师 f 0 f_0 f0使用弱增强的 x ~ i \tilde x_i x~i来生成位置特定监督。这也有助于提高ViT的泛化能力。
4.2 元微调
对于图5(b)中的元调优阶段,我们的目标是通过对从基本数据集 D b a s e D_{base} Dbase采样的多个“N-way K-shot”任务 { τ } \{\tau\} {τ}进行训练来调整元学习器 f f f,这样 f f f可以适应包含未见类 C n o v e l C_{novel} Cnovel(即 C n o v e l ∉ D b a s e C_{novel} \notin D_{base} Cnovel∈/Dbase的新任务,只有几个标记的训练样本。为此,在不失一般性的前提下,我们在Meta Baseline中采用了一种简单而有效的元调优方法[8]。此外,我们还在附录D和E中研究了不同的元调优方法,如FEAT[58]和DeepEMD[63]。在相同的FEAT和DeepEMD下,我们的SUN框架仍然显示出优势超过其他少样本学习框架。更多细节见附录D和e。为了完整起见,我们在下面介绍Meta-Baseline中的元调优。具体来说,给定一个支持集为S的任务 τ \tau τ, SUN通过 w k = ∑ x ∈ S k G A P ( f ( x ) ) / ∣ S k ∣ w_k=\sum_{x\in S_k}GAP(f(x))/|S_k| wk=∑x∈SkGAP(f(x))/∣Sk∣为第 k k k类的分类原型 w k w_k wk,其中 S k S_k Sk表示来自c类的支持样本,GAP表示全局平均池化操作。然后,对于每个查询图像 x x x,元学习器 f f f计算第 k k k个类的分类置信度得分:
其中cos表示余弦相似度, γ \gamma γ是温度参数。最后,最小化交叉熵损失 L f e w − s h o t = H ( p x , y x ) L_{few-shot} = H(p_x,y_x) Lfew−shot=H(px,yx),对各种采样任务 { τ } \{\tau\} {τ}上的元学习器 f f f进行微调,其中 p x = [ p 1 , . . . , p c ] p_x=[p_1,...,p_c] px=[p1,...,pc]为预测, y x y_x yx为 x x x的真实标签。此元调整后,给定支持集 S ′ S' S′的新测试任务 τ ′ \tau' τ′,我们按照上述步骤计算其分类原型,然后使用Eqn。(3)预测测试样品的标签。
5 实验
我们首先在5.1节中介绍我们的训练细节。接下来,我们在第5.2节中在四个不同的vit(即LV-ViT, SwinTransformer,Visformer和NesT)上测试我们的SUN。最后,我们选择NesT[65]作为ViT特征提取器,与5.3节中的其他基线进行比较,并在5.5节中进行消融研究。在[7,8,71]之后,我们在三种广泛使用的少样本基准测试(miniImageNet [51], tieredImageNet[40]和CIFAR-FS[3])上使用各种vit对SUN进行了评估,这些基准测试的细节将推迟到附录中。为了公平起见,对于每个基准,我们遵循[7,8,71],并报告在5-way 1-shot和5-way 5-shot分类设置下2000个任务的平均准确率为95%置信区间。
5.1 训练详情
对于元训练阶段,我们使用学习率为5e-4的AdamW[34]和余弦学习率调度器[33]分别在miniImageNet、CIFAR-FS和tieredImageNet上训练800、800、300 epoch的元学习器f。对于增强,我们在第4节中使用了空间一致增强。对于每个贴片上的特定位置监督,我们只保留在- sij中置信度最高的top-k(例如,k = 5),以减少标签噪声。为了训练教师fg,我们采用了与[48]相同的增强策略,包括随机裁剪、随机增强、混合等。同时,我们采用与上述参数相同的AdamW[34]训练300个epoch。对于元调优,我们简单地利用Meta Baseline中使用的优化器和超参数,例如,学习率为1e-3的SGD对元学习器进行40个epoch的调优。此外,我们使用相对较大的下降路径率0.5,以避免所有训练的过拟合。这与通常使用0.1的掉落路径率的传统设置有很大不同。在传统的监督设置[56,20,59]的基础上,我们还使用带有残差连接的三层卷积块[17]来计算补丁嵌入。这种传统的主干只有~ 0.2M参数并且比ViT主干小得多。
5.2 不同ViT的比较
我们在四种不同的ViT上评估我们的SUN,即LV-ViT, Swin, Visformer和NesT,涵盖了大多数现有的ViT类型。表3显示,在miniImageNet上,SUN在四个vit上明显超过了Meta-Baseline[8]。具体来说,它比MetaBaseline在5-way 1-shot设置下分别提高了15.9%、10.3%、20.2%和12.0%。这些结果表明,我们的SUN对新类别具有较强的泛化能力,并且与不同类型的vit具有良好的兼容性。此外,在所有vit中,Visformer的性能最好,因为它使用了许多CNN模块,可以更好地处理少镜头的学习任务。在接下来的5.3节和5.5节中,我们使用次优的NesT作为我们的ViT特征提取器,因为NesT不涉及CNN模块,只引入模块来关注局部特征,从而更好地揭示了传统ViT架构的少镜头学习能力。在第5.4节中,我们使用NesT和Visformer与最先进的基于cnn的少镜头分类方法进行比较。
SUN与ViT在依赖学习中的比较。在第3节的分析之后,我们可视化了香草ViT、cnn蒸馏ViT和带有SUN的ViT的注意力图,以比较token依赖学习的质量。对比结果如图6所示。与普通ViT和cnn蒸馏ViT相比,使用SUN的ViT可以在各种类别上捕获更多的语义标记。结果表明,在训练过程中,使用SUN的ViT可以更好地学习token依赖关系

图6所示。注意图的可视化从香草ViT, cnn蒸馏ViT和ViT与SUN。使用SUN的ViT性能更好,因此获得更好的令牌依赖性。
5.3 不同少样本学习框架的比较
在表4中,我们将SUN与相同ViT架构上的其他少量学习框架进行了比较。在表4中,“[8]+CNN-蒸馏”方法对CNN进行预训练,提取ViT;“Semiformer”[53]将CNN模块引入ViT;
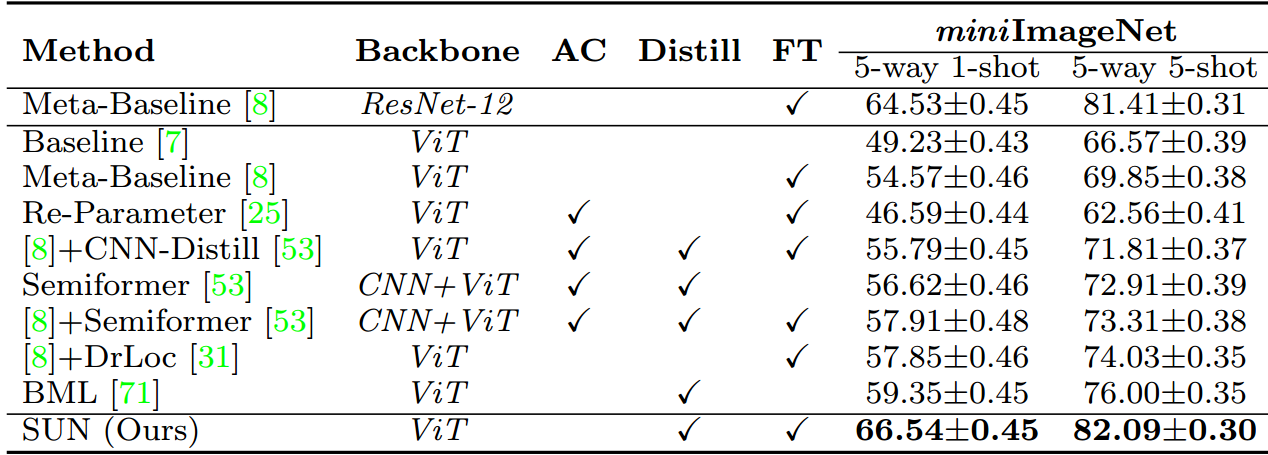
表4。miniImageNet上不同基于ViT的少样本分类框架的比较。“AC”是指在ViT骨干网中引入CNN模块,实现功能融合。“蒸馏”是知识的蒸馏。“FT”使用元调谐来微调元学习器(参见第4.2节)。除[25]外,其他方法均使用NesT作为ViT特征提取器。
“Re-Parameter”[25]通过训练后的CNN初始化ViT;“[8]+DrLoc”预测本地令牌对之间的相对位置;“BML”[71]引入了基于相互学习的少镜头学习框架。所有这些方法都提出了自己的技术,通过引入类似cnn的归纳偏差或构建任务来更好地学习token依赖关系来提高ViT的少射学习性能。除[25]使用其CNN-变压器混合架构外,其他均采用NesT[65]作为ViT特征提取器或使用ResNet-12作为CNN特征提取器。表4显示,就新类别的准确性而言,我们的SUN明显优于所有这些方法。具体来说,我们的SUN在5路1发和5发设置下的表现分别比第二名高出7.19%和6.09%。这些结果表明,即使在相同的ViT上,SUN在新类别上取得了比其他少镜头学习框架更好的少镜头准确率。
5.4 与先进技术的比较
在这里,我们比较了SUN和最先进的(SoTAs),包括基于CNN的方法和基于ViT的方法,miniImageNet [51], tieredImageNet[40]和CIFAR-FS[3]。表5报告了评估结果。在不引入像[55,21]这样极其复杂的少镜头学习方法的情况下,我们的SUN在miniImageNet[51]上实现了与SoTA相当的性能,并在tieredImageNet[40]和CIFAR-FS[3]上设置了新的SoTA。具体来说,在tieredImageNet的5-way 1-shot和5-shot设置下,我们的SUN (Visformer)分别获得了72.99%和86.74%,比SoTA TPMN分别提高了0.8%和0.2%[55]。在CIFAR-FS数据集上,我们的SUN (NesT)在1次射击精度和5次射击精度方面分别获得78.17%和88.98%,在1次射击精度方面显著优于所有最先进的方法至少2.5%。同时,我们的SUN (Visformer)在miniImageNet测试集上也获得了67.80%的单镜头准确率,比基于SoTA cnn的少镜头分类方法高出约1.2%。这些结果很好地证明了vit与我们的SUN在少量学习中的有效性。
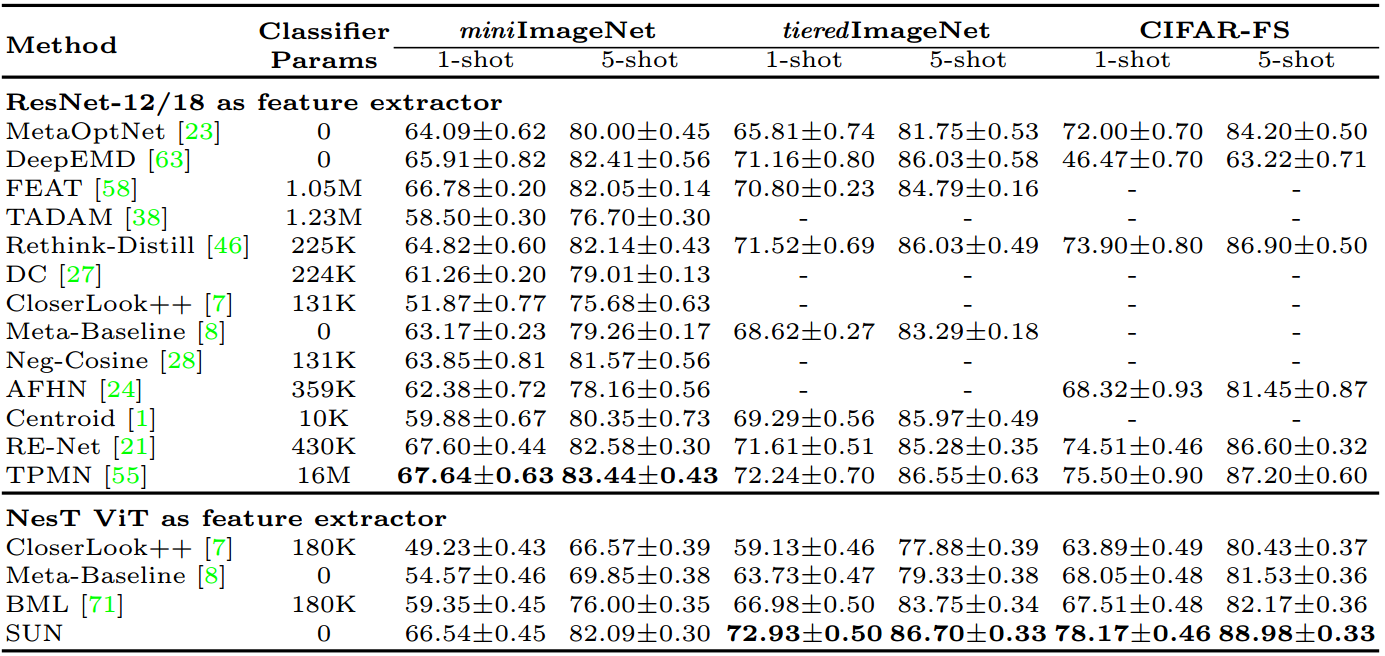
表5所示。5-way 少样本分类设置下与SoTA少样本学习方法的比较。最好的两种方法的结果用粗体表示。
5.5 消融研究
SUN中每个阶段的效果
我们研究了SUN中每个训练阶段的效果。为了公平起见,我们总是使用相同的ViT特征提取器[65]作为元学习器f进行少镜头分类。表6显示,在miniImageNet数据集上,与基线(表6中以“Base”表示)相比,元训练阶段的教师ViT fg在1次射击和5次射击准确率方面显著优于基线13.2%和12.9%。通过引入特定位置的监督,类型(b)的单次射击精度提高了约0.7%。然后,在引入SCA和BGF后,(d)型可以进一步提高~ 1.8%的1次射击精度和~ 1.0%的5次射击精度。一个可能的原因是SCA提高了预训练变压器的特定位置监督质量,同时在元训练阶段保持了对目标变压器的强增强能力。同时,BGF消除了背景patch标注错误带来的负面影响,提高了特征表示质量。这两种技术显著提高了ViT特征提取器的位置特异性监督和泛化能力。
为了进一步分析我们的元训练阶段,我们绘制了[7]中元训练方法的精度曲线,并绘制了图7(a) ~ 7(d)中的元训练阶段。
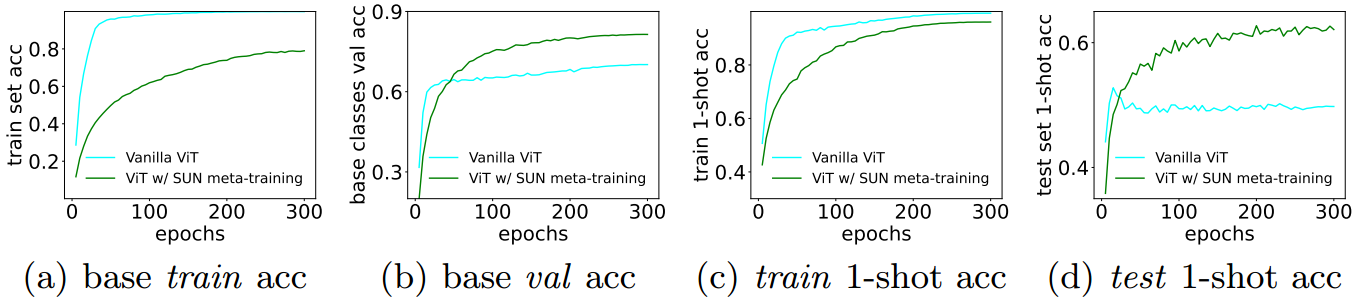
图7所示。miniImageNet上ViTs(无或无SUN元训练阶段)的精度。使用SUN元训练的vit在基础类别和新类别上都能更好地泛化。
如图7©和7(d)所示,使用SUN的ViT对新类的分类精度更高。此外,如图7(b)所示,SUN在基类上也比元训练方法提高了约11%[7]。这一观察结果启发我们重新思考vit的小样本分类训练范式,使vit既能很好地泛化基本类别,也能很好地泛化新类别。
我们还研究了元调优阶段。如表6 (e)所示,经过元训练阶段的元学习者可以很自然地采用现有的少量学习方法,并得到进一步的改进。具体来说,我们的SUN(用(e)表示)在元训练阶段之后,在1-shot和5-shot的准确率方面也比f高出1.7%和1.1%。
微调方法
我们还使用不同的元调优方法来评估我们的SUN。为了对我们的太阳进行实证分析,我们将Visformer[9]固定为ViT主干,并选择Meta-Baseline[8]、FEAT[58]和密集预测方法DeepEMD[63]。如表8所示,所有SUN-M/F/D都提高了精度,性能优于相应的基于cnn的基线。此外,SUN-D达到了69.56%的5way1-shot精度,甚至略高于SoTA COSOC[35]。

表8所示。元调谐的消融,其中“SUN-*”表示我们和其他人是sota。
跌落路径率分析
如第5.1节所述,我们还展示了跌落路径率pdpr的影响。本文采用元培训阶段的教师ViT模型进行研究。表7显示,相对较大的下降路径率(例如, p d p r p_{dpr} pdpr = 0.5)给出了最高的准确性,因为它可以很好地缓解过拟合,并且适用于训练样本有限的少样本学习问题。

表7所示。miniImageNet上教师ViT模型中路径下降率的影响。
6 结论
在这项工作中,我们首先通过经验证明,将CNN特征提取器替换为ViT模型会导致在少样本学习任务上的严重性能下降,而在有限训练数据上缓慢的token依赖学习在很大程度上导致了这种性能下降。为了解决这一问题,我们首次提出了一种简单而有效的vit培训框架,即自我促进式监督(SUN)。SUN首先在few-shot学习数据集上对ViT进行预训练,利用它来生成个别的位置特定监督,1)引导patch令牌相似或不相似的ViT,从而加速令牌依赖学习;2)提高对物体的接地和识别能力。在小样本分类任务上的实验结果表明,SUN在精度上优于目前最先进的分类方法。
参考资料
论文下载(ECCV2022)
https://arxiv.org/abs/2203.07057
代码地址
https://github.com/DongSky/few-shot-vit