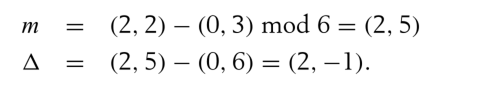第八章:路由基础
路由: 在特定的拓扑上,选择从 source 节点到 destination 节点的路径。
- 一个好的路由算法,即使面对 non-uniform traffic pattern,也能有效地均衡负载,使实际 throughput 更加接近于理想情况。
- 好的路由算法可以使路径长度尽可能短,从而减少跳数和传输的总延迟
1、路由算法示例
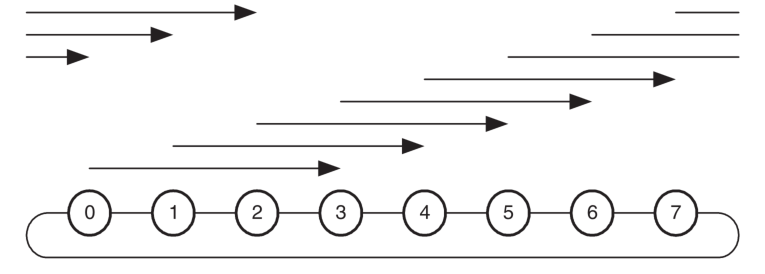
可以逆时针路由,也可以顺时针路由,根据路径长度进行选择
2、路由算法分类
确定性算法(Determinstic):在 x 和 y 之间,总是选择相同的路径进行路由,即使存在着其他可能的路径。确定性算法忽略了路径多样性,因此容易造成负载不均衡。然而这种算法常常被使用,因为它实现简单,且容易实现无死锁性质。
遗忘算法(Oblivious):在确定路由路径时,不会考虑当前网络的实时状态。上面的确定性算法也属于状态无关性算法的范畴。例如,一个随机路由算法即属于状态无关性算法。
自适应算法(Adaptive):在确定路由路径时,会与网络当前状态相适应,使用网络状态信息(Node 状态,link 状态,占用 resources 情况)决定路由。
3、路由关系
一次计算(All-at-once):
当数据包注入进 source 节点时一次性计算完成路由路径。之后在包传输过程中按照计算好的路径路由。
通过在 source 节点计算完整路由路径,能减少用于计算路由路径的时间。但是在后续包传递的过程中,计算好的路由路径需跟数据一起传输。
多次计算(Incremental):
包在到达每一个中转节点时,计算下一跳的路由。一直持续到到达 destination 节点。
不需要随包一起传输路由路径,但在每一个节点都计算路由可能导致包传输的延时加大。相比于 all-at-once,计算路由时可利用的历史信息较少,导致可能无法实现某些 all-at-once 路由算法。
4、确定性路由算法
Destination-Tag Routing in Butterfly Networks

在 Butterfly 网络中,目标地址被直接用作路由选择。地址的每一位被依次用作下一跳路由的决定。这期间,source 节点并没有被考虑。
Dimension-Order Routing in Cube Networks
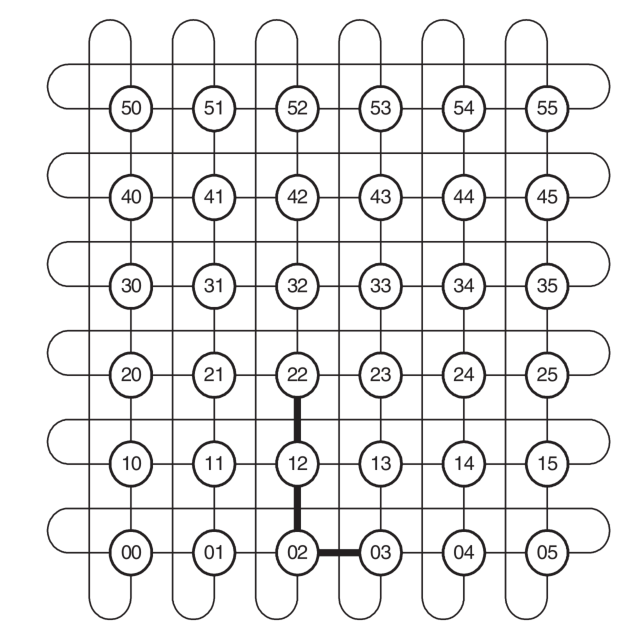
首先计算相对位置
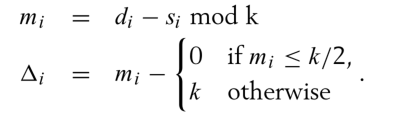
在本拓扑中k为6,因此