深入掌握Service
Service是Kubernetes实现微服务架构的核心概念,通过创建Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上。
Service定义
Service用于为一组提供服务的Pod抽象一个稳定的网络访问地址,是Kubernetes实现微服务的核心概念。通过Service的定义设置的访问地址是DNS域名格式的服务名称,对于客户端应用来说,网络访问方式并没有改变(DNS域名的作用等价于主机名、互联网域名或IP地址)。
Service还提供了负载均衡器功能,将客户端请求负载分发到后端提供具体服务的各个Pod上。
Service的概念和原理
Service主要用于提供网络服务,通过Service的定义,能够为客户端应用提供稳定的访问地址(域名或IP地址)和负载均衡功能,以及屏蔽后端Endpoint的变化,是Kubernetes实现微服务的核心资源。
Service的概念
Service实现的是微服务架构中的几个核心功能:全自动的服务注册、服务发现、服务负载均衡等。

Service定义中的关键字段是ports和selector。
本例中的ports定义部分指定了Service本身的端口号为8080,targetPort则用来指定后端Pod的容器端口号,selector定义部分设置的是后端Pod所拥有的label:app=webapp。
在提供服务的Pod副本集运行过程中,如果Pod列表发生了变化,则Kubernetes的Service控制器会持续监控后端Pod列表的变化,实时更新Service对应的后端Pod列表。
一个Service对应的“后端”由Pod的IP和容器端口号组成,即一个完整的“IP:Port”访问地址,这在Kubernetes系统中叫作Endpoint。
Service不仅具有标准网络协议的IP地址,还以DNS域名的形式存在。Service的域名表示方法为<servicename>.<namespace>.svc.<clusterdomain>,
servicename为服务的名称,
namespace为其所在namespace的名称,
clusterdomain为Kubernetes集群设置的域名后缀。
Service的负载均衡机制
当一个Service对象在Kubernetes集群中被定义出来时,集群内的客户端应用就可以通过服务IP访问到具体的Pod容器提供的服务了。从服务IP到后端Pod的负载均衡机制,则是由每个Node上的kube-proxy负责实现的。
kube-proxy的代理模式
目前kube-proxy提供了以下代理模式(通过启动参数--proxy-mode设置)。
-
userspace模式:用户空间模式,由kube-proxy完成代理的实现,效率最低,不再推荐使用。
-
iptables模式:kube-proxy通过设置Linux Kernel的iptables规则,实现从Service到后端Endpoint列表的负载分发规则,效率很高。但是,如果某个后端Endpoint在转发时不可用,此次客户端请求就会得到失败的响应,相对于userspace模式来说更不可靠。此时应该通过为Pod设置readinessprobe(服务可用性健康检查)来保证只有达到ready状态的Endpoint才会被设置为Service的后端Endpoint。
-
ipvs模式:在Kubernetes 1.11版本中达到Stable阶段,kube-proxy通过设置Linux Kernel的netlink接口设置IPVS规则,转发效率和支持的吞吐率都是最高的。ipvs模式要求Linux Kernel启用IPVS模块,如果操作系统未启用IPVS内核模块,kube-proxy则会自动切换至iptables模式。同时,ipvs模式支持更多的负载均衡策略,如下所述。
- rr:round-robin,轮询。
- lc:least connection,最小连接数。
- dh:destination hashing,目的地址哈希。
- sh:source hashing,源地址哈希。
- sed:shortest expected delay,最短期望延时。
- nq:never queue,永不排队。
-
kernelspace模式:Windows Server上的代理模式。
会话保持机制
Service支持通过设置sessionAffinity实现基于客户端IP的会话保持机制,即首次将某个客户端来源IP发起的请求转发到后端的某个Pod上,之后从相同的客户端IP发起的请求都将被转发到相同的后端Pod上,配置参数为service.spec.sessionAffinity
通过Service的负载均衡机制,Kubernetes实现了一种分布式应用的统一入口,免去了客户端应用获知后端服务实例列表和变化的复杂度。
Service的多端口设置
一个容器应用可以提供多个端口的服务,在Service的定义中也可以相应地设置多个端口号。

是同一个端口号使用的协议不同,如TCP和UDP,也需要设置为多个端口号来提供不同的服务
将外部服务定义为Service
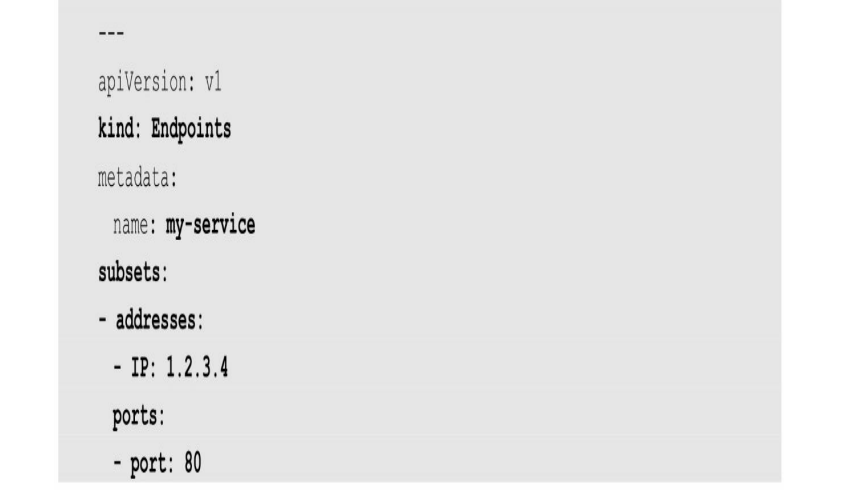
将Service暴露到集群外部
Kubernetes为Service创建的ClusterIP地址是对后端Pod列表的一层抽象,对于集群外部来说并没有意义,但有许多Service是需要对集群外部提供服务的,Kubernetes提供了多种机制将Service暴露出去,供集群外部的客户端访问。这可以通过Service资源对象的类型字段“type”进行设置。
目前Service的类型如下。
- ClusterIP:Kubernetes默认会自动设置Service的虚拟IP地址,仅可被集群内部的客户端应用访问。当然,用户也可手工指定一个ClusterIP地址,不过需要确保该IP在Kubernetes集群设置的ClusterIP地址范围内(通过kube-apiserver服务的启动参数--service-cluster-ip-range设置),并且没有被其他Service使用。
- NodePort:将Service的端口号映射到每个Node的一个端口号上,这样集群中的任意Node都可以作为Service的访问入口地址,即NodeIP:NodePort。
- LoadBalancer:将Service映射到一个已存在的负载均衡器的IP地址上,通常在公有云环境中使用。
- ExternalName:将Service映射为一个外部域名地址,通过externalName字段进行设置。
Kubernetes的服务发现机制
服务发现机制指客户端应用在一个Kubernetes集群中如何获知后端服务的访问地址。Kubernetes提供了两种机制供客户端应用以固定的方式获取后端服务的访问地址:环境变量方式和DNS方式。
Headless Service的概念和应用
在某些应用场景中,客户端应用不需要通过Kubernetes内置Service实现的负载均衡功能,或者需要自行完成对服务后端各实例的服务发现机制,或者需要自行实现负载均衡功能,此时可以通过创建一种特殊的名为“Headless”的服务来实现。
Headless Service的概念是这种服务没有入口访问地址(无ClusterIP地址),kube-proxy不会为其创建负载转发规则,而服务名(DNS域名)的解析机制取决于该Headless Service是否设置了Label Selector。
如果Headless Service设置了Label Selector,Kubernetes则将根据Label Selector查询后端Pod列表,自动创建Endpoint列表,将服务名(DNS域名)的解析机制设置为:当客户端访问该服务名时,得到的是全部Endpoint列表(而不是一个确定的IP地址)。
端点分片与服务拓扑
我们知道,Service的后端是一组Endpoint列表,为客户端应用提供了极大的便利。但是随着集群规模的扩大及Service数量的增加,特别是Service后端Endpoint数量的增加,kube-proxy需要维护的负载分发规则(例如iptables规则或ipvs规则)的数量也会急剧增加,导致后续对Service后端Endpoint的添加、删除等更新操作的成本急剧上升。
举例来说,假设在Kubernetes集群中有10000个Endpoint运行在大约5000个Node上,则对单个Pod的更新将需要总计约5GB的数据传输,这不仅对集群内的网络带宽浪费巨大,而且对Master的冲击非常大,会影响Kubernetes集群的整体性能,在Deployment不断进行滚动升级操作的情况下尤为突出。
Kubernetes从1.16版本开始引入端点分片(Endpoint Slices)机制,包括一个新的EndpointSlice资源对象和一个新的EndpointSlice控制器,在1.17版本时达到Beta阶段。EndpointSlice通过对Endpoint进行分片管理来实现降低Master和各Node之间的网络传输数据量及提高整体性能的目标。对于Deployment的滚动升级,可以实现仅更新部分Node上的Endpoint信息,Master与Node之间的数据传输量可以减少100倍左右,能够大大提高管理效率。EndpointSlice根据Endpoint所在Node的拓扑信息进行分片管理
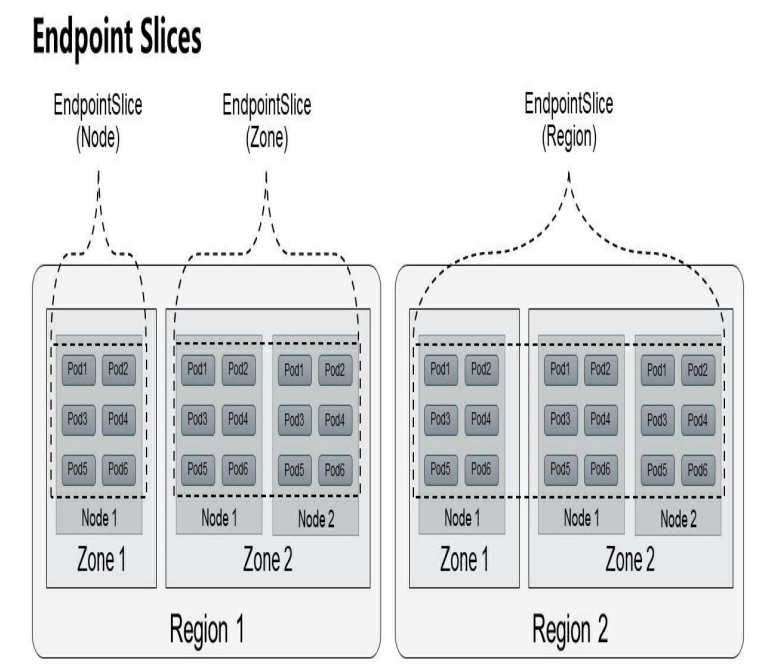
Endpoint Slices要实现的第2个目标是为基于Node拓扑的服务路由提供支持,这需要与服务拓扑(Service Topology)机制共同实现。
默认情况下,在由EndpointSlice控制器创建的EndpointSlice中最多包含100个Endpoint,如需修改,则可以通过kube-controller-manager服务的启动参数--max-endpoints-per-slice设置,但上限不能超过1000。
服务拓扑(Service Topology)
服务拓扑机制从Kubernetes 1.17版本开始引入,目前为Alpha阶段,目标是实现基于Node拓扑的流量路由,例如将发送到某个服务的流量优先路由到与客户端相同Node的Endpoint上,或者路由到与客户端相同Zone的那些Node的Endpoint上。
在默认情况下,发送到一个Service的流量会被均匀转发到每个后端Endpoint,但无法根据更复杂的拓扑信息设置复杂的路由策略。服务拓扑机制的引入就是为了实现基于Node拓扑的服务路由,允许Service创建者根据来源Node和目标Node的标签来定义流量路由策略。
通过对来源(source)Node和目标(destination)Node标签的匹配,用户可以根据业务需求对Node进行分组,设置有意义的指标值来标识“较近”或者“较远”的属性。例如,对于公有云环境来说,通常有区域(Zone或Region)的划分,云平台倾向于把服务流量限制在同一个区域内,这通常是因为跨区域网络流量会收取额外的费用。另一个例子是把流量路由到由DaemonSet管理的当前Node的Pod上。又如希望把流量保持在相同机架内的Node上,以获得更低的网络延时。
服务拓扑机制需要通过设置kube-apiserver和kube-proxy服务的启动参数--feature-gates="ServiceTopology=true,EndpointSlice=true"进行启用(需要同时启用EndpointSlice功能),然后就可以在Service资源对象上通过定义topologyKeys字段来控制到Service的流量路由了。
topologyKeys字段设置的是一组Node标签列表,按顺序匹配Node完成流量的路由转发,流量会被转发到标签匹配成功的Node上。如果按第1个标签找不到匹配的Node,就尝试匹配第2个标签,以此类推。如果全部标签都没有匹配的Node,则请求将被拒绝,就像Service没有后端Endpoint一样。





![[原]代码管理工具WeCode及其数据导出](https://images0.cnblogs.com/blog2015/84698/201506/212224482636126.jpg)

