1. 总结openssh服务安全加固和总结openssh免密认证原理,及免认证实现过程。
1.仅使用SSHv2 协议
2.关闭或者延迟压缩
Compression no
3.限制身份验证最大尝试次数
MaxAuthTries 3
4.禁用root账户登录
PermitRootLogin no
5.显示最后一次登录的日期和时间
PrintLastLog yes #用户可以意识到未经授权的账户登录事件
6.结束空闲的SSH会话
ClientAliveInterval 900 #设置超时间隔(以秒为单位),在此间隔后,如果未从客户端接收到任何数据,sshd服务端将通过加密的通道发送消息请求客户端回应。默认值为0,表示不会执行该操作
ClientAliveCountMax 0 #设置客户端探活消息(上文所述操作)的数量,如果发送客户端探活消息达到此阈值,则sshd服务端将断开客户端连接,从而终止会话。
7.指定白名单用户
AllowUsers user #只允许user用户ssh登录
8.禁用空密码
PermitEmptyPasswords no
9.禁用基于受信主机的无密码登录
IgnoreRhosts yes
10.禁用基于已知主机的访问
IgnoreUserKnownHosts yes
#在身份验证时忽略已知主机
11.禁用X11Forwarding
X11Forwarding no
12.使用非常规端口
Port 9212
13.将服务绑定到指定IP
ListenAddress 10.0.0.5
#默认情况下,SSH会监听本机上配置的所有IP地址,但是你应该指定SSH绑定在特定的IP,最好是在专用VLAN中的地址。
14.保护SSH密钥
ls -l /etc/ssh/*key
chmod 0600 /etc/ssh/*key
15.保护主机公钥
ls -l /etc/ssh/*pub
chmod 0644 /etc/ssh/*pub
16.检查用户特定的配置文件
StrictModes yes
#StrictModes设置ssh在接收登录之前是否检查用户home目录和rhosts文件的权限和所有权,StrictModes为yes必需保证存放公钥的文件夹的拥有者与登陆用户名是相同的。
17.防止特权升级
UsePrivilegeSeparation sandbox
18.使用密钥进行身份验证
PubkeyAuthentication yes
19.禁用不使用的身份验证方法(按需选择)
禁用 GSSAPI 认证
GSSAPIAuthentication no
禁用Kerberos认证
KerberosAuthentication no
禁用口令认证
PasswordAuthentication no
禁用密钥认证
PubkeyAuthentication no
20.使用符合FIPS 140-2标准的密码
Ciphers aes128-ctr,aes192-ctr,aes256-ctr
21.使用符合FIPS 140-2标准的MAC
MACs hmac-sha2-256,hmac-sha2-512
22.配置白名单或主机防火墙过滤传入的SSH连接
使用iptables;Firewalld;UFW过滤SSH连接
2. 总结sudo配置文件格式,总结相关示例。
user host=(runas) command #基本格式
例子:
root ALL=(ALL) AL
user: 运行命令者的身份
host: 通过哪些主机
(runas):以哪个用户的身份
command: 运行哪些命令
用户别名 (User_Alias)
User_Alias ADMINS = a,b
Runas 别名 (Runas_Alias)
#定义用户可以使用 sudo -u 切换到的目标用户别名
Runas_Alias WEBADMINS = www-data, nginx
主机别名 (Host_Alias)#
需要提前在hosts中定义,或者写ip
/etc/hosts
127.0.0.1 localhost
192.168.1.10 web01
192.168.1.11 web02
192.168.1.12 web03
Host_Alias WEBSERVERS = web01, web02, web03
命令别名 (Cmnd_Alias)
Cmnd_Alias SHUTDOWN = /sbin/shutdown, /sbin/reboot
总结:ADMINS WEBSERVERS=(root) SHUTDOWN
#允许ADMINS的用户 通过WEBSERVERS里的主机以root权限的方式允许SHUTDOWN里的命令
3. 总结PAM架构及工作原理
PAM(模块)
是一个灵活的认证框架,用于在 UNIX 和 Linux 系统中提供可配置的认证机制。PAM 允许系统管理员通过修改配置文件来改变认证过程,而无需修改应用程序本身。
#模块是linux内核中的一部分,程序只需要通过调用模块去使用内核功能
PAM架构:
应用程序、PAM-API、PAM平台、PAM-SPI、PAM模块、PAM配置
工作原理
应用程序通过api使用PAM平台去调用PAM模块程序。
4. 总结PAM配置文件格式,总结相关示例, nologin.so, limits,等模块的使用。
PAM配置格式(#如果程序复杂才需要配置文件)
application type control module-path arguments
application:指服务名,如:telnet、login、ftp等,服务名字“OTHER”代表所有没有在该文件中明确
配置的其它服务
type:指模块类型,即功能
control :PAM库该如何处理与该服务相关的PAM模块的成功或失败情况,一个关健词实现
module-path: 用来指明本模块对应的程序文件的路径名
Arguments: 用来传递给该模块的参数
模块类型
Auth 账号的认证和授权
Account 帐户的有效性,与账号管理相关的非认证类的功能,如:用来限制/允许用户对某个服务
的访问时间,限制用户的位置(例如:root用户只能从控制台登录)
Password 用户修改密码时密码复杂度检查机制等功能
Session 用户会话期间的控制,如:最多打开的文件数,最多的进程数等
-type 表示因为缺失而不能加载的模块将不记录到系统日志,对于那些不总是安装在系统上的模块有
用
control
1.required:模块的成功验证是必需的。如果验证失败,则 PAM 将立即返回失败,并且不会继续执行后续模块。如果验证成功,则继续执行后续模块。
2.sufficient:如果模块成功验证,则 PAM 将立即返回成功,并且不会继续执行后续模块。如果验证失败,则继续执行后续模块。如果所有的 sufficient 模块都失败,则认证失败。
3.requisite:类似于 required,但是如果验证失败,则 PAM 将立即返回失败,并且不会继续执行后续模块。如果验证成功,则继续执行后续模块。
4.optional:模块的成功验证是可选的。即使验证失败,PAM 也会继续执行后续模块。通常与 required 或 sufficient 搭配使用。
5.include:包含另一个 PAM 配置文件中的配置。这允许在配置中重用其他服务的配置。
module-path
模块文件所在绝对路径
**Argument **
debug :该模块应当用syslog( )将调试信息写入到系统日志文件中
no_warn :表明该模块不应把警告信息发送给应用程序
use_first_pass :该模块不能提示用户输入密码,只能从前一个模块得到输入密码
try_first_pass :该模块首先用前一个模块从用户得到密码,如果该密码验证不通过,再提示用户
输入新密码
use_mapped_pass 该模块不能提示用户输入密码,而是使用映射过的密码
expose_account 允许该模块显示用户的帐号名等信息,一般只能在安全的环境下使用,因为泄漏
用户名会对安全造成一定程度的威胁
例子:
pam_securetty.so(限制root用户)
#检查 /etc/securetty 文件中的终端与root终端是否一致
auth required pam_securetty.so
#/etc/pam.d/login
#限制 root 用户只能从指定终端登录
pam_time.so(限制登录时间)
account required pam_time.so
#/etc/pam.d/login
#限制普通用户登录实时间
pam_nologin.so(普通用户登录限制)
启用在pamd下创建nologin即可 普通用户无法远程登录
account required pam_nologin.so
#/etc/pam.d/sshd
#普通用户无法登录。
pan.limits.so(资源限制)
它通过配置文件 /etc/security/limits.conf 和 /etc/security/limits.d/ 目录下的文件,控制用户进程的资源使用,从而帮助管理员防止资源滥用,维护系统稳定性。
配置文件格式
<domain> <type> <item> <value>domain:可以是用户名、用户组名(前面加 @),或者 *(表示所有用户)。
type:可以是 soft(软限制)或 hard(硬限制)。
item:要限制的资源类型。
value:限制值。
例子:
# 限制所有用户最大打开文件数为 1024
* - nofile 1024
# 限制用户 zz 的最大进程数为 100
zz - nproc 100
# 限制所有用户的最大虚拟内存大小为 500000 KB
* soft as 500000
5. 实现私有时间服务器
yum install chrony #安装chrony
allow 0.0.0.0/0 #设置谁都可以同步
local stratum 10 #允许没有外网也可以同步
#在自定义主机安装chrony,在/etc/chrony.conf做以上配置
server 192.168.1.130 iburst #在其他机上添加自定义NTP服务器的IP地址
chronyc sources #时间同步
#安装ntp也可,按照安装的时间同步自行调整
6. 总结DNS域名三级结构
域名系统的三级结构是指域名的层次化结构,从根域名(根层)到顶级域名(TLD),再到次级域名(SLD),最后到子域名。
假设有一个完整的域名 www.baidu.com:
根域名:``
顶级域名:com
次级域名:example
主机名(主机名是子域名的一个特例):www
7. 总结DNS服务工作原理,涉及递归和迭代查询原理
DNS查询
主机通过根服务器或本地dns服务器去寻找域名,而每个根服务器地址背后都有多个服务器节点在全球不同地点运行。
递归查询:当一个客户端向 DNS 服务器请求解析一个域名时,如果这个 DNS 服务器没有缓存结果,
它会代表客户端向其他 DNS 服务器进行查询,直到获取到结果或者确定无法解析。在这个过程中,客户端只需要发送一次请求,然后等待最终结果1。
迭代查询:在这种查询中,DNS 服务器不会代替客户端进行查询。相反,如果 DNS 服务器没有缓存结果,
它会告诉客户端下一个可以查询的 DNS 服务器的地址。客户端随后会向这个新的 DNS 服务器发送查询请求。这个过程会重复进行,直到找到答案或者所有路径都已尝试过。
简单来说,递归查询是一种端到端的查询,客户端发出请求后,由 DNS 服务器负责整个查询过程。而迭代查询则需要客户端参与多次查询,每次都是向不同的 DNS 服务器请求信息,直到找到最终结果。在实际应用中,这两种查询方法可能会结合使用。
8. 实现私有DNS, 供本地网络主机作DNS递归查询。
yum install named
#还需要配置named.conf 和配置域名解析
9. 总结DNS服务器类型,解析答案,正反解析域,资源记录定义。
DNS服务器
1.根DNS服务器
位于DNS层级的顶端,保存指向顶级域(TLD)服务器的指针。
共有13组根服务器。
2.顶级域DNS服务器
管理顶级域(如 .com、.org、.net 等)的DNS服务器。
根服务器将请求转发到TLD服务器,TLD服务器再将请求转发到权威DNS服务器
3.权威DNS服务器
保存域名dns记录
当查询到达权威服务器时,它直接返回域名的IP地址或其他资源记录。
4.递归DNS服务器
接收客户端的DNS查询,并负责找到最终的IP地址。
如果自己没有记录,它会依次查询根DNS、TLD DNS和权威DNS服务器
5.缓存DNS服务器
存储主机最近查询过的DNS记录,减少查询时间和网络负载
DNS解析答案
肯定 #直接返回域名的ip和资源记录
否定 #未找到或查询域名不存在
权威 #由权威dns服务器返回
非权威 #由缓存dns服务器返回
正向解析和反向解析域
正向解析域:将域名转换为IP地址
反向解析域:将ip地址转为域名
资源记录定义
A记录:将域名映射到IPv4地址。
AAAA记录:将域名映射到IPv6地址。
CNAME记录:为一个域名设置别名。
MX记录:指定接收电子邮件的邮件服务器。
NS记录:指定管理该域的权威DNS服务器。
PTR记录:用于反向DNS查找,将IP地址映射到域名。
TXT记录:存储任意文本数据,常用于验证和描述性信息。
SRV记录 :定位提供特定服务的服务器。
10. 实现DNS主从同步
/etc/named.rfc1912.zones文件
主dns服务器:
zone "zz.org"{type master;file "zzchongxin.org.zone";
}
副dns服务器:
zone "zz.org"{type slave;masters {192.168.1.130}file "slaves/zzchongxin.org.zone";#不需要将主dns服务器复制到副dns服务器slave里边,会自动cp;从服务器文件放在slaves里
}数据文件zzchongxin.org.zone
$TTL 86400 #保存时间
@ IN SOA dns admin.zz.com. (202405111458 10M 5M 1D 1W)NS dns1NS dns2dns1 A 192.168.1.130dns2 A 192.168.1.128www A 192.168.1.129#注意需要将文件属性修改
chmod 640 zz.org.zone
chgreo named zz.org.zone #更改权限属性让其他人无法访问,只有root修改和named读取
11. 实现DNS子域授权
/etc/named.rfc1912.zones文件
#在原基础上将子域都交给另外一个dns服务器解析;只要用户在主服务器查询,则转发到子域的dns服务器
gx NS gxdns
gxdns A 192,168,10.11
在192.168.10.111上建立dns解析,按需配置,只有上述两行需要在主域添加
12. 基于acl实现智能DNS
#复制两份/etc/named.rfc1912.zones,分别命名pro和test
zone "zz.org"{type master;file "zzchongxin.org.zone.test";
}zone "zz.org"{type master;file "zzchongxin.org.zone.pro";
}
#复制两份数据库分别命名为pro和test$TTL 86400 #保存时间
@ IN SOA dns admin.zz.com. (202405111458 10M 5M 1D 1W)NS dns1dns1 A 192.168.1.130www A 192.168.1.129################################################################$TTL 86400 #保存时间
@ IN SOA dns admin.zz.com. (202405111458 10M 5M 1D 1W)NS dns1dns1 A 192.168.1.130www A 192.168.10.111
acl test_net {10.1.1.0/24192.168.10.0/24}
acl pro_net{11.1.1.0/24196.168.1.0/24
}view tset_view {match-clients {tset_net;};include "/etc/named.rfc1912.zones.test"
}#添加了view 则所有区域要放在view里view pronet_view {match-clients {pro_net;};include "/etc/named.rfc1912.zones.pro"
}
13. 总结防火墙分类
按保护范围划分:
主机防火墙:服务范围为当前一台主机
网络防火墙:服务范围为防火墙一侧的局域网
按实现方式划分:
硬件防火墙:在专用硬件级别实现部分功能的防火墙;另一个部分功能基于软件实现,如:华为,
山石hillstone,天融信,启明星辰,绿盟,深信服, PaloAlto , fortinet飞塔, Cisco, Checkpoint,
NetScreen(2004年被 Juniper 用40亿美元收购)等
软件防火墙:运行于通用硬件平台之上的防火墙的应用软件,Windows 防火墙 ISA --> Forefront
TMG
按网络协议划分:
网络层防火墙:OSI模型下四层,又称为包过滤防火墙
应用层防火墙/代理服务器:proxy 代理网关,OSI模型七层
应用层防火墙
Netfilter(后续linux防火墙都由它延申)
Netfilter 是 Linux 内核中的一个框架,用于操作网络数据包
1.IPTables:
IPTables 是基于 Netfilter 的命令行工具,用于设置、维护和检查 IPv4 和 IPv6 数据包过滤规则。
2.Nftables:
Nftables 是 Netfilter 项目的继任者,旨在取代 IPTables、IP6Tables、ARPTables 和 EBTables。
Nftables 提供一个统一的框架来进行数据包过滤、网络地址转换等。
3.Firewalld:
Firewalld 是一个动态管理防火墙工具。
提供了更为简单和灵活的防火墙管理方式,支持动态更新而无需重新加载防火墙规则。
4.UFW
UFW 是 Ubuntu 发行版中默认的防火墙工具,设计简洁易用。
主要用于简化 IPTables 规则的管理
14. 总结iptable 5表5链, 基本使用,扩展模块。
五表:
filter:过滤规则表,根据预定义的规则过滤符合条件的数据包,默认表
nat:network address translation 地址转换规则表
mangle:修改数据标记位规则表
raw:关闭启用的连接跟踪机制,加快封包穿越防火墙速度
security:用于强制访问控制(MAC)网络规则,由Linux安全模块(如SELinux)实现
五链:
INPUT链:处理进入本机的数据包。
OUTPUT链:处理从本机发出的数据包。
FORWARD链:处理需要本机转发的数据包(即本机作为路由器时)。
PREROUTING链:在进行路由选择之前修改数据包,如DNAT(Destination NAT,目的网络地址转换)。
POSTROUTING链:在进行路由选择之后修改数据包,如SNAT(Source NAT,源网络地址转换)。
例子:
iptables -A INPUT -s 10.0.0.1 -j REJECT #拒绝来自10.0.0.1的包
扩展模块
隐式扩展(不需要写模块而是选项)
tcp 协议的扩展选项
[!] --source-port, --sport port[:port]:匹配报文源端口,可为端口连续范围
[!] --destination-port,--dport port[:port]:匹配报文目标端口,可为连续范围
[!] --tcp-flags mask comp
mask 需检查的标志位列表,用,分隔 , 例如 SYN,ACK,FIN,RST
comp 在mask列表中必须为1的标志位列表,无指定则必须为0,用,分隔tcp协议的扩展选项
例子:
--tcp-flags SYN,ACK,FIN,RST SYN #表示要检查的标志位为SYN,ACK,FIN,RST四个,其中
SYN必须为1,余下的必须为0,第一次握手
--tcp-flags SYN,ACK,FIN,RST SYN,ACK #第二次握手
udp 协议的扩展选项
[!] --source-port, --sport port[:port]:匹配报文的源端口或端口范围
[!] --destination-port,--dport port[:port]:匹配报文的目标端口或端口范围
**icmp扩展 **
[!] --icmp-type {type[/code]|typename}
type/code
0/0 echo-reply icmp应答
8/0 echo-request icmp请求
显示扩展
multiport扩展
多端口号
例子:
iptables -R INPUT 1 -p tcp -m multiport --dports 22,80 -j ACCEPT
iprange扩展
ip范围
例子:
iptables -A INPUT -m iprange --src-range 10.0.0.6-10.0.0.10 -j ACCEPT
mac扩展
mac地址(不需要目标地址,因为目标不是自己则抛弃)
例子:
iptables -A INPUT -s 172.16.0.100 -m mac --mac-source 00:50:56:12:34:56 -j ACCEPT
string扩展
字符串匹配
--algo {bm|kmp} 字符串匹配检测算法
bm:Boyer-Moore
kmp:Knuth-Pratt-Morris
--from offset 开始偏移
--to offset 结束偏移
[!] --string pattern 要检测的字符串模式
[!] --hex-string pattern 要检测字符串模式,16进制格式
例子:
iptables -A OUTPUT -p tcp --sport 80 -m string --algo kmp --from 62 --string "google" -j REJECT #出去带有google拒绝
time扩展
--datestart YYYY[-MM[-DD[Thh[:mm[:ss]]]]] 日期
--datestop YYYY[-MM[-DD[Thh[:mm[:ss]]]]]
--timestart hh:mm[:ss] 时间
--timestop hh:mm[:ss]
[!] --monthdays day[,day...] 每个月的几号
[!] --weekdays day[,day...] 星期几,1 – 7 分别表示星期一到星期日
--kerneltz:内核时区(当地时间),不建议使用,CentOS 7版本以上系统默认为 UTC
注意: centos6 不支持kerneltz ,--localtz指定本地时区(默认)
connlimit扩展
连接数
--connlimit-upto N #连接的数量小于等于N时匹配
--connlimit-above N #连接的数量大于N时匹配
例子:
iptables -A INPUT -p tcp --dport 80 -m connlimit --connlimit-above 2 -j REJECT
limit扩展
报文控制(比如限制能接收多少个包)
例子:
iptables -I INPUT -d 172.16.100.10 -p icmp --icmp-type 8 -m limit --limit 10/minute --limit-burst 5 -j ACCEPT
state扩展
/proc/net/nf_conntrack
根据状态匹配
NEW:新发出请求;连接追踪信息库中不存在此连接的相关信息条目,因此,将其识别为第一次发
出的请求
ESTABLISHED:NEW状态之后,连接追踪信息库中为其建立的条目失效之前期间内所进行的通信
状态
RELATED:新发起的但与已有连接相关联的连接,如:ftp协议中的数据连接与命令连接之间的关
系
INVALID:无效的连接,如flag标记不正确
UNTRACKED:未进行追踪的连接,如:raw表中关闭追踪
例子:
jiptables -A INPUT -m state --state ESTABLISHED -J ACCEPT
iptables -A INPUT -m state --state NEW -J REJECT
#先将所以用户都可以进入,然后拒绝新用户
15. 总结iptables规则优化实践,规则保存和恢复。
优化:
1.优先放行已建立连接
#在规则链的开头,放行所有状态为 ESTABLISHED 的入站和出站连接,提高效率。
2.谨慎放行新入站请求
3.限制特殊目的的访问
#在放行规则之前,添加拒绝规则以限制特定访问
4.特定规则放在前面
#同类规则中,匹配范围小的规则(如特定 IP)放在前面。
5.不同类规则中匹配范围大的放前面
#对不同类规则,匹配范围大的规则放在前面。
6.合并相似规则
#将多个可以用一条规则描述的规则合并,减少规则数量。
7.设置默认策略为白名单方式
#通过在规则链最后设置默认策略为白名单方式,仅放行特定连接。
规则保存
sudo iptables-save > /etc/iptables/ruules_1
规则恢复
cento6
规则覆盖保存至/etc/sysconfig/iptables文件中
cento7及以上
iptables-restore < /etc/iptables/ruules_1
16. 总结NAT转换原理, DNAT/SDNAT原理,并自行设计架构实现DNAT/SNAT。
NAT转换原理:
简单的说同过DNAT和SNAT的应用去转换公网和内网的访问,不然它们之间连接,而是通过NAT防火墙去转发。公网访问只能访问NAT防火墙无法得知确切的内网地址,而内网需要再NAT防火墙通过NAT防火墙的ip地址去访问公网。
DNAT/SNAT
根据匹配规则来修改数据包的ip地址
DNAT:公网经过NAT防火墙,如果数据包匹配 DNAT 规则,防火墙或路由器将数据包的目标地址修改为内部服务器的私有 IP 地址。
SNAT:内网访问外网经过NAT防火墙,如果数据包匹配 SNAT 规则,防火墙或路由器将数据包的源地址修改为公共 IP 地址。
#注意: 需要开启 ip_forward
框架
NAT防火墙:
192.168.1.130(内网)
192.168.10.111(外网)
vim /etc/sysctl.conf
net.ipv4.ip_forward = 1 #开启转发内核参数
sysctl -p
/etc/sysconfig/network-scripts/ifcfg-xxxx
eth0DEVICE=eht0BOOTPROTO=dhcpOMBOOT=yes #虚拟机的网络设为192.168.1.0/24eth1NAME=eth1DEVICE=eht1BOOTPROTO=staticIPADDR=192.168.10.111PREFIX=24OMBOOT=yes nmcli connection reload #更新ip配置
sudo nmcli connection up eth0 #如果上述无法成功则使用这个
nmcli connection show #查看现有连接
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 ! -d 192.168.1.0/24 -j SNAT --to-source 192.168.10.111 #设置SNAT转发 除了内网其他都转发
iptables -t nat -A PREROUTING -d 192.168.10.111 -p tcp --dport 80 -j DNAT --to-destination 192.168.1.128:80 #蛇者DNAT,将内网ip映射到NAT端口
ip addr show eth0 #验证
ip route show #验证
外网机
192.168.10.100/24
#设为仅主机
etc/netplan(ubnutuu)network:ethernets:addresses:- 192.168.10.100/24ens33:#dhcp4: trueversion: 2
内网机
192.168.1.131 1机
192.168.1.128 2机
eth0DEVICE=eht0BOOTPROTO=dhcpGETWAY=192.168.1.130OMBOOT=yes #虚拟机的网络设为192.168.1.0/24
结果:
SNAT
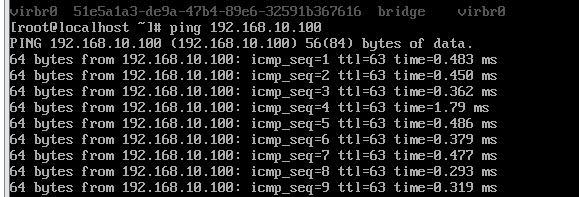
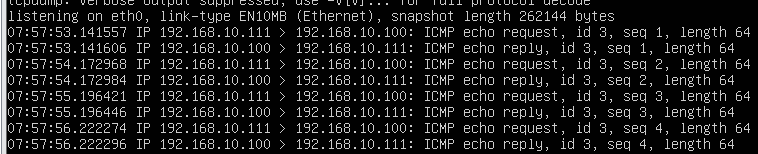
DNAT

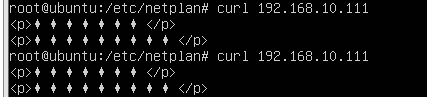
17. 使用REDIRECT将90端口重定向80,并可以访问到80端口的服务
iptables -t nat -A PREROUTING -p tcp --dport 90 -j REDIRECT --to-port 80
18. firewalld常见区域总结。
firewalld 默认有 9 个 zone,默认的 zone 为 public,zone 可以理解为 firewalld 的单位、规则集。
drop(丢弃)
所有传入的网络数据包都被丢弃,不会回应任何请求。
只有出站连接被允许。block(限制)
类似于 drop 区域,但会向传入请求发送拒绝消息。
适用于不希望与网络通信,但希望对方知道请求被拒绝的情况。public(公共)
允许有限的传入连接(例如,SSH),大多数服务被拒绝。external(外部)
适用于在防火墙后使用路由(如 NAT)的外部网络。
允许有限的传入连接,适合用作网关的外部接口。dmz(非军事区)
允许对特定服务的访问,例如 Web 服务器。work(工作区)
拒绝除和传出流量相关的,以及ssh,ipp-client,dhcpv6-client预定义服务之外的其它所有传入流量home(家庭)
默认信任较多,允许大多数服务,适用于设备较多的家庭网络。internal(内部)
适用于受信任的内部网络。trusted(信任)
所有网络连接都被信任,允许所有流量进出。
19. 通过ntftable来实现暴露本机80/443/ssh服务端口给指定网络访问
nft add table inet filter #建表nft add chain inet filter input { type filter hook input priority 0 \; policy drop \; }#在 inet 表中创建一个 filter 链,挂钩在输入位置,优先级为 0,默认策略为 drop规则:nft add rule inet filter input iif lo accept#允许本地流量nft add rule inet filter input ct state established,related accept#允许已经建立的连接
nft add rule inet filter input ip saddr 192.168.1.0/24 tcp dport { 80, 443, 22 } accept
#允许来自特定网络的 HTTP (80), HTTPS (443) 和 SSH (22) 流量
nft list table inet filter #查看inet表规则





![[原]代码管理工具WeCode及其数据导出](https://images0.cnblogs.com/blog2015/84698/201506/212224482636126.jpg)
