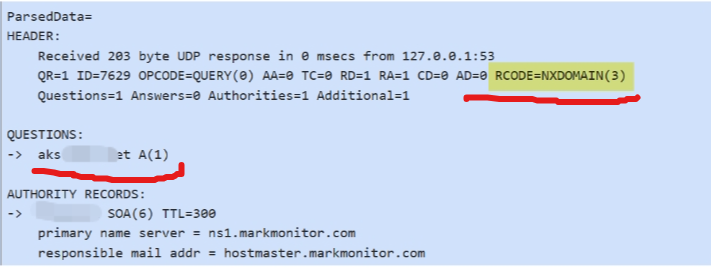
Q-learning是一种基于值迭代的强化学习(Reinforcement Learning, RL)算法,主要用于在给定环境中学习一个策略,使得智能体(agent)能够在与环境交互的过程中获得最大累计奖励。它通过学习一个状态-动作值函数(Q函数)来指导智能体的行为选择,适用于各种离散状态和动作的任务环境。Q-learning在各种应用领域中都有显著表现,包括机器人控制、游戏AI、交通系统优化以及金融市场分析等。通过不断改进和扩展,Q-learning在未来将有望在更多复杂的实际任务中发挥重要作用,特别是在结合其他机器学习技术和多智能体系统的研究中。

一、Q-learning算法
强化学习是做出最佳决策的科学。它可以帮助我们制定活的物种所表现出的奖励动机行为。比方说,你想让一个孩子坐下来学习考试。要做到这一点非常困难,但是如果每次完成一章/主题时都给他一块巧克力,他就会明白,如果他继续学习,他会得到更多的巧克力棒。所以他会有一些学习考试的动机。这里孩子代表着Agent代理。奖励制度和考试代表了Environment环境。今天的题目是类似于强化学习的States状态。所以,孩子必须决定哪些话题更重要(即计算每种行为的价值)。这将是我们的工作的 Value-Function价值方程,每次他从一个国家(States)到另一个国家(States)旅行时,他都会得到Reward奖励,他用来在时间内完成主题的方法就是我们的Policy决策。
1.1 Q-learning计算步骤
Q-learning的核心思想是通过不断地更新状态-动作值(\(Q\)值)来逼近最优Q函数(\(Q^*\)),从而得到最优策略。我们可以构建一个矩阵 \(Q\), 它用来表示 agent 已经从经验中学到的知识。矩阵 \(Q\) 与 \(R\) 是同阶的, 其行表示状态,列表示行为,\(R(s,a)\)表示在状态\(s\)是采取行为\(a\)获得的奖励。由于刚开始时 agent 对外界环境一无所知, 因此矩阵 \(Q\) 应初始化为零矩阵,对于状态数目未知的情形, 我们可以让 \(Q\) 从一个元素出发, 每次发现一个新的状态时就可以在 \(Q\) 中增加相应的行列。
Q-learning 算法的转移规则比较简单, 如下式所示:
其中 \(s, a\) 表示当前的状态和行为, \(\widetilde{s}, \widetilde{a}\) 表示 \(s\) 的下一个状态及行为, 学习参数 \(\gamma\) 为满足 \(0 \leq \gamma<1\) 的常数。式 (1) 中的 \(\gamma\) 满足 \(0 \leq \gamma<1\),如果\(\gamma=0\),对立即的奖励更有效;如果接近1,整个系统会更考虑将来的奖励。
在没有老师的情况下, 我们的 agent 将通过经验进行学习 (也称为无监督学习)。它不断从一个状态转至另一状态进行探索, 直到到达目标。我们将 agent 的每一次探索称为一个 episode。在每一个 episode 中, agent 从任意初始状态到达目标状态。当 agent 达到目标状态后, 一个 episode 即结束, 接着进入另一个 episode。下面给出整个 \(Q\)-learning 算法的计算步骤:
Step 1 给定参数 \(\gamma\) 和 reward 矩阵 \(R\);
Step 2 今 \(Q:=0\);
Step 3 For each episode:
3.1 随机选择一个初始的状态 \(s\);
3.2 若未达到目标状态, 则执行以下几步
(1) 在当前状态 \(s\) 的所有可能行为中选取一个行为 \(a\);
(2) 利用选定的行为 \(a\), 得到下一个状态 \(\widetilde{s}\);
(3) 按照公式(1),计算 \(Q(s, a)\);
(4) 令 \(s:=\widetilde{s}\).
Agent 利用上述算法从经验中进行学习。每一个 episode 相当于一个 training session.在一个 traiming session 中, agent 探索外界环境, 并接收外界环境的 reward, 直到达到目标状态. 训练的目的是要强化 agent 的 “大脑” (用 \(Q\) 表示)。训练得越多, 则 \(Q\) 被优化得更好,当矩阵 \(Q\) 被训练强化后, agent 便很容易找到达到目标状态的最快路径了。利用训练好的矩阵 \(Q\), 我们可以很容易地找出一条从任意状态 \(s_0\) 出发达到目标状态的行为路径, 具体步骤如下:
令当前状态 \(s:=s_0\);
确定 \(a\), 它满足 \(Q(s, a)=\max _{\tilde{a}}\{Q(s, \widetilde{a})\}\);
令当前状态 \(s:=\widetilde{s}(\widetilde{s}\) 表示 \(a\) 对应的下一个状态 \()\);
重复执行步 2 和步 3 直到 \(s\) 成为目标状态.
通过不断迭代更新 $Q(s, a) $ 的值,Q-Learning算法可以学习到最优策略 \(\pi^*\) 下的状态-动作对的价值函数$ Q^*(s, a)$。这个过程不需要环境的动态模型,因此Q-Learning是一种无模型的强化学习算法。
1.2 Q-Learning解的推导
Q-Learning算法的目标是找到一个策略\(\pi^*\),使得\(Q(s,a)\) 最大化,即:
Q-Learning的更新规则如下:
其中:
- $ Q_t(s_t, a_t)$是时间 \(t\)下状态\(s_t\) 和动作 $ a_t$ 的\(Q\)值
- $ R_{t+1} $ 是在 $(s_t, a_t) $下的即时奖励
- \(\alpha\)是学习率,$0 \leq \alpha < 1 $
- $ \gamma$ 是折扣因子
假设我们有一个策略 $\pi $,其对应的Q值函数为 $ Q^{\pi}$。根据贝尔曼动态规划方程,我们有:
由于 $$V^{\pi}(s') = \max_{a'} Q^{\pi}(s', a')$$,我们可以将 $ V^{\pi}(s')$替换为 $ \max_{a'} Q^{\pi}(s', a')$:
如果我们取 $ \pi $为最优策略 $ \pi^*$,那么我们得到:
这个方程表明,最优\(Q\)值 $ Q^*(s, a)$ 可以通过对未来状态的最优Q值的加权和来计算。这就是Q-Learning算法的马尔科夫解。
二、Q-learning算例
一只小白鼠在迷宫里面,目的是找到出口,如果他走出了正确的步子,就会给它正反馈(糖),否则给出负反馈(点击),那么,当它走完所有的道路后。无论比把它放到哪儿,它都能通过以往的学习找到通往出口最正确的道路。假设迷宫有5间房,如图1所示,这5间房有些房间是想通的,我们分别用0-4进行了标注,其中5代表了是是出口。
| 图1 迷宫 | 图2 状态转移收益 |
|---|---|
 |
 |
在这个游戏里,我们的目标是能够走出房间,就是到达5的位置,为了能更好的达到这个目标,我们为每一个门设置一个奖励。比如如果能立即到达5,那么我们给予100的奖励,其它没法到5的我们不给予奖励,权重是0了;5因为也可以到它自己,所以也是给100的奖励,其它方向到5的也都是100的奖励。 在Q-learning中,目标是权重值累加的最大化,所以一旦达到5,它将会一直保持在这儿,如图3所示。
| 图3 权重图 | 图4 收益矩阵 |
|---|---|
 |
 |
2.1 \(Q\)和\(R\)矩阵
想象一下小白鼠(或虚拟的机器人),它对环境一无所知,但它需要通过自我学习知道怎么样到外面,就是到达5的位置。好啦,现在可以引出Q-learning的概念了,“状态”以及“动作”,我们可以将每个房间看成一个state,从一个房间到另外一个房间的动作叫做action,state是一个节点,而action是用一个剪头表示。现在假设我们在状态2,从状态2可以到状态3,而无法到状态0、1、4、5,因为2没法直接到0、1、4;从状态3,可以到1、4或者2,而无法到达0、5;而4可以到0、3、5,而无法到达1、2;其它依次类推。所以我们能够把这些用一个矩阵来表示,这个矩阵就是这里的\(Q\)矩阵了,这个矩阵的列表表示的是当前状态,而行标表示的则是下一个状态。如\(Q\)矩阵的第三行的行标是2,如果取第四列,列标为3,就表示从状态2转移到状态3。
鉴于状态2可以转移到状态3,这时记这个转移收益为0(不奖不罚);如果从状态2转移不到状态4,就记2->4的转移收益是-1(负激励,尽量不这样走),如果从某个状态转移到了目标状态5(达成目标,正激励),其收益就记为100,就构造了收益矩阵\(R\)。
Q矩阵初始化的时候全为0,因为它的状态我们已经全部知道了,这里总的状态是6,因为后面要求最大值,所以初始化都为0。如果我们并不知道有多少个状态,那么请从1个状态开始,一旦发现新的状态,那么为这个矩阵添加上新的行和列,如图4所示。
我们的小白鼠(或虚拟机器人)将通过环境来学习,机器人会从一个状态跳转到另一个状态,直到我们到达最终目标状态。我们把从开始状态开始一直达到最终目标状态的这个过程称之为一个场景,小白鼠会从一个随机的开始场景出发,直到到达最终状态完成一个场景,然后立即重新初始化到一个开始状态,从而进入下一个场景。
2.2 计算episode
为进一步理解上一节中介绍的 Q-learning 算法是如何工作的, 下面我们一步一步地迭代几个 episode。
首先取学习参数 \(\gamma=0.8\),初始状态为房间 1,并将 \(Q\) 初始化为一个零矩阵。观察矩阵 \(R\) 的第二行 (对应房间 1 或状态 1 ), 它包含两个非负值, 即当前状态 1 的下一步行为有两种可能: 转至状态 3 或转至状态 5。 随机地, 我们选取转至状态 5。
| 初始\(Q\)矩阵 | 收益矩阵 |
|---|---|
 |
 |
想象一下, 当我们的 agent 位于状态 5 以后, 会发生什么事情呢? 观察矩阵 \(R\) 的第 6 行 (对应状态 5 ), 它对应三个可能的行为: 转至状态 1,4 或 5 ,根据公式 (1), 我们有
现在状态 5 变成了当前状态。因为状态 5 即为目标状态, 故一次 episode 便完成了, 至此, 小白鼠的 “大脑” 中的 \(Q\) 矩阵刷新为
| 一次 episode 后的 \(Q\) 矩阵 | 一次 episode 后的 \(Q\) 矩阵 |
|---|---|
 |
 |
接下来, 进行下一次 episode 的迭代, 首先随机地选取一个初始状态, 这次我们选取状态 3 作为初始状态。
观察矩阵 \(R\) 的第四行 (对应状态 3 ), 它对应三个可能的行为: 转至状态 1,2 或 4。 随机地, 我们选取转至状态 1 ,因此观察矩阵 \(R\) 的第二行 (对应状态 1 ), 它对应两个可能的行为: 转至状态 3 或 5,根据公式 (1),我们有
若我们执行更多的episode 迭代,最终将得到一个收敛矩阵(理论上可以证明这个矩阵一定存在),见下图所示。
| 状态转移图 | \(Q\)收敛矩阵 |
|---|---|
 |
 |
| 规范化处理\(Q\)矩阵(用矩阵元素最大值除所有元素) | 转移的最优行为 |
|---|---|
 |
 |
最终策略:在状态 0 下,选择动作 4 作为最优策略;在状态 1 下,选择动作 5 作为最优策略;在状态 2 下,选择动作 3 作为最优策略;在状态 3 下,选择动作 4 作为最优策略;在状态 4 下,选择动作 5 作为最优策略;在状态 5 下,选择动作 5 作为最优策略。所以从状态2出发的最优路径序列为2-3-4-5。
三、算法Python程序
import numpy as np# 定义参数
gamma = 0.8 # 折扣因子
alpha = 0.1 # 学习率
epsilon = 0.1 # 探索概率
episodes = 10000 # 学习的总回合数# 定义收益矩阵
R = np.array([[-1, -1, -1, -1, 0, -1],[-1, -1, -1, 0, -1, 100],[-1, -1, -1, 0, -1, -1],[-1, 0, 0, -1, 0, -1],[0, -1, -1, 0, -1, 100],[-1, 0, -1, -1, 0, 100]
])# 初始化Q值矩阵
Q = np.zeros_like(R, dtype=float)# Q-learning算法
for episode in range(episodes):# 随机选择初始状态state = np.random.randint(0, R.shape[0])while True:# 选择动作:采用ε-贪婪策略if np.random.rand() < epsilon:action = np.random.randint(0, R.shape[1])else:action = np.argmax(Q[state])# 执行动作,获取即时奖励和下一个状态next_state = actionreward = R[state, action]# 只在奖励不为 -1 时进行 Q 值更新if reward != -1:# Q值更新Q[state, action] = Q[state, action] + alpha * (reward + gamma * np.max(Q[next_state]) - Q[state, action])# 状态转移state = next_state# 如果达到了终止状态,结束本回合if reward == 100:break# 对 Q 矩阵进行规范化,使最大值为100
max_value = np.max(Q)
if max_value > 0:Q = (Q / max_value) * 100# 保留两位小数
Q = np.round(Q, 2)# 输出最终的Q值矩阵
print("最终的Q值矩阵(规范化后):")
print(Q)# 输出最终策略
policy = np.argmax(Q, axis=1)
print("最终策略:")
print(policy)# 解释最终策略
for state in range(len(policy)):print(f"在状态 {state} 下,选择动作 {policy[state]} 作为最优策略。")
总结
Q-learning是一种基于价值迭代的强化学习算法,其主要特点是不需要知道环境的动态模型。智能体通过与环境的直接交互来学习策略,适用于各种不确定和复杂的环境。Q-learning采用离线更新方法,在每次交互后立即更新Q值,使得算法在训练过程中不断优化。Q-learning的基本思想是通过更新状态-动作值函数(Q值),来评估每个动作在每个状态下的价值。具体而言,智能体在每个状态选择一个动作,接收到环境的反馈(奖励)和转移到的新状态,然后使用Bellman方程更新Q值。该过程持续进行,直到Q值函数收敛,最终得到最优策略。
Q-learning在许多领域取得了显著成功,如游戏、机器人控制和自动化。然而,它也存在一些挑战和局限性。首先,在处理高维状态空间和连续动作空间时,Q-learning的表现不佳。其次,在大型复杂环境中,Q-learning的学习效率较低,需要大量时间和计算资源来收敛。为克服这些挑战,未来研究方向包括:结合深度学习的方法,例如深度Q网络(DQN),以处理高维和复杂任务;多智能体系统中的Q-learning算法,研究智能体之间的协作和竞争;迁移学习,将一个任务中学到的知识迁移到另一个相关任务,提高学习效率和泛化能力;确保Q-learning算法在无人驾驶、医疗等高风险领域的安全性和鲁棒性。
参考资料
- A Painless Q-learning Tutorial (一个 Q-learning 算法的简明教程)
- 《深入浅出机器学习》之强化学习
- 强化学习:Q-learning由浅入深:简介1
- 强化学习之Q-learning简介