转自:https://www.cnblogs.com/miraclepbc/p/14385623.html
图像定位的直观理解
不仅需要我们知道图片中的对象是什么,还要在对象的附近画一个边框,确定该对象所处的位置。
也就是最终输出的是一个四元组,表示边框的位置
图像定位网络架构
可以将图像定位任务看作是一个回归问题!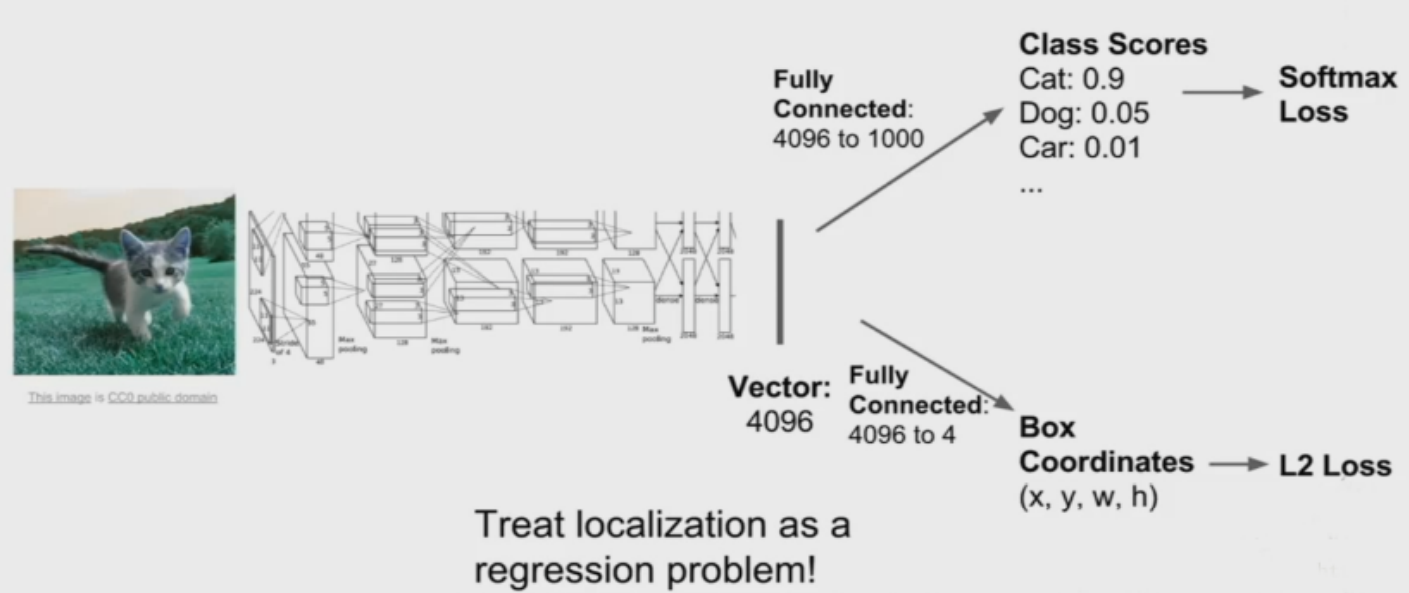
数据集介绍
采用Oxford-IIIT数据集
The Oxford-IIIT Pet Dataset是一个宠物图像数据集,包含37种宠物,每种宠物200张左右宠物图片,该数据集同时包含宠物分类、头部轮廓标注和语义分割信息。
头文件
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import datasets, transforms, models
from torch.utils import data
import os
import shutil
from lxml import etree
from matplotlib.patches import Rectangle
import glob
from PIL import Image
%matplotlib inline
这里介绍几个之前没用过的包:
-
lxml的etree是一个解析HTML文本的工具
-
Rectangle可以在图中画出矩形
数据预处理
获取图片及标签地址
images = glob.glob(r'E:\Oxford-IIIT Pets Dataset\dataset\images\*.jpg')
anno = glob.glob(r'E:\Oxford-IIIT Pets Dataset\dataset\annotations\xmls\*.xml')
这里发现len(images)大于len(anno),因此需要获得有对应xml文件的图像地址
筛选图像地址
这里的思路是:先搞出有xml文件的文件名列表xml_name,然后遍历images,找到文件名在xml_name中的地址
xml_name = [x.split('\\')[-1].split('.')[0] for x in anno]
imgs = [x for x in images if x.split('\\')[-1].split('.')[0] in xml_name]
获取每张图像的边框值
边框值记录在这里:
因此,我们就可以通过解析xml文件,按照路径找到对应的四个值+长和宽
def to_labels(path):xml = open(r'{}'.format(path)).read() # 打开xml文件,注意地址转义的写法selection = etree.HTML(xml) # 用etree解析xml文件width = int(selection.xpath('//size/width/text()')[0]) # 获取数据的方式也值得学习height = int(selection.xpath('//size/height/text()')[0])xmin = int(selection.xpath('//bndbox/xmin/text()')[0])xmax = int(selection.xpath('//bndbox/xmax/text()')[0])ymin = int(selection.xpath('//bndbox/ymin/text()')[0])ymax = int(selection.xpath('//bndbox/ymax/text()')[0])return [xmin / width, ymin / height, xmax / width, ymax / height] # 因为要进行过会儿要进行裁剪,因此我希望获得的是一个比例labels = [to_labels(path) for path in anno]
划分训练集和测试集
数据集定义
class OxfordDataset(data.Dataset):def __init__(self, img_paths, labels, transform):self.imgs = img_pathsself.labels = labelsself.transforms = transformdef __getitem__(self, index):img = self.imgs[index]l1, l2, l3, l4 = self.labels[index]pil_img = Image.open(img)pil_img = pil_img.convert('RGB')data = self.transforms(pil_img)return data, l1, l2, l3, l4def __len__(self):return len(self.imgs)transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor()
])
数据集切分
index = np.random.permutation(len(imgs))
all_imgs_path = np.array(imgs)[index]
all_labels = np.array(labels)[index].astype(np.float32)
s = int(len(all_imgs_path) * 0.8)train_ds = OxfordDataset(all_imgs_path[:s], all_labels[:s], transform)
test_ds = OxfordDataset(all_imgs_path[s:], all_labels[s:], transform)
train_dl = data.DataLoader(train_ds, batch_size = 8, shuffle = True)
test_dl = data.DataLoader(test_ds, batch_size = 8)
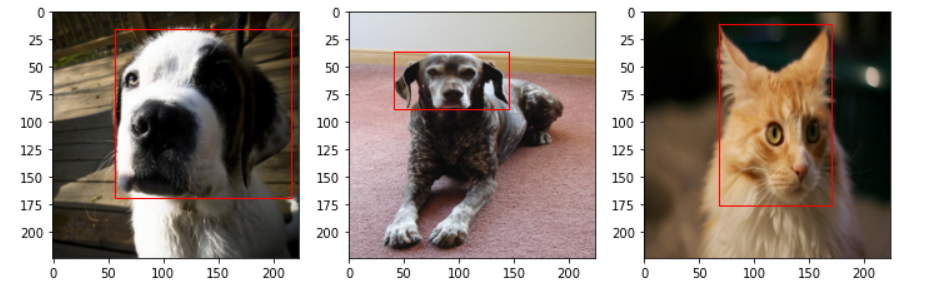
将一个批次的数据绘图
img_batch, out1_b, out2_b, out3_b, out4_b = next(iter(train_dl))plt.figure(figsize = (12, 8))
for i, (img, l1, l2, l3, l4) in enumerate(zip(img_batch[:3], out1_b[:3], out2_b[:3], out3_b[:3], out4_b[:3])):img = img.permute(1, 2, 0).numpy() # 将channel放在最后一维plt.subplot(1, 3, i + 1)plt.imshow(img)xmin, ymin, xmax, ymax = l1 * 224, l2 * 224, l3 * 224, l4 * 224 # 裁剪后的位置,即之前得到的比例乘以图像的长度/宽度rect = Rectangle((xmin, ymin), xmax - xmin, ymax - ymin, fill = False, color = 'red') # fill指的是矩形内部需不需要填充ax = plt.gca()ax.axes.add_patch(rect) # 将元素添加到图像中
定义模型
根据文章一开始给出的网络架构,可以看出组成部分为:卷积基+全连接层
获取卷积基
resnet = models.resnet101(pretrained = True)
conv_base = nn.Sequential(*list(resnet.children())[: -1]) # list(resnet.children())获取网络的各层信息,*表示将列表中的元素解耦
模型定义
模型的组成有1个卷积基+4个全连接层组成,每个全连接层输出一个值
class Net(nn.Module):def __init__(self):super().__init__()self.conv_base = nn.Sequential(*list(resnet.children())[: -1])self.fc1 = nn.Linear(in_size, 1)self.fc2 = nn.Linear(in_size, 1)self.fc3 = nn.Linear(in_size, 1)self.fc4 = nn.Linear(in_size, 1)def forward(self, x):x = self.conv_base(x)x = x.view(x.size(0), -1) # 注意,进入全连接层之前要进行扁平化x1 = self.fc1(x)x2 = self.fc2(x)x3 = self.fc3(x)x4 = self.fc4(x)return x1, x2, x3, x4
训练模型
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)loss_func = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001)
epochs = 10
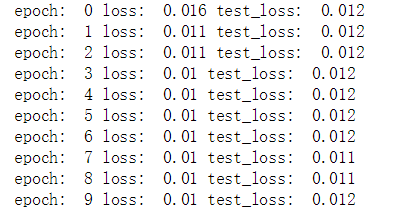
exp_lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size = 7, gamma = 0.1)def fit(epoch, model, trainloader, testloader):running_loss = 0model.train()for x, y1, y2, y3, y4 in trainloader:x, y1, y2, y3, y4 = x.to(device), y1.to(device), y2.to(device), y3.to(device), y4.to(device)y_pred1, y_pred2, y_pred3, y_pred4 = model(x)loss1 = loss_func(y_pred1, y1)loss2 = loss_func(y_pred2, y2)loss3 = loss_func(y_pred3, y3)loss4 = loss_func(y_pred4, y4)loss = loss1 + loss2 + loss3 + loss4optimizer.zero_grad()loss.backward()optimizer.step()with torch.no_grad():running_loss += loss.item()exp_lr_scheduler.step()epoch_loss = running_loss / len(trainloader.dataset)test_running_loss = 0model.eval()with torch.no_grad():for x, y1, y2, y3, y4 in testloader:x, y1, y2, y3, y4 = x.to(device), y1.to(device), y2.to(device), y3.to(device), y4.to(device)y_pred1, y_pred2, y_pred3, y_pred4 = model(x)loss1 = loss_func(y_pred1, y1)loss2 = loss_func(y_pred2, y2)loss3 = loss_func(y_pred3, y3)loss4 = loss_func(y_pred4, y4)loss = loss1 + loss2 + loss3 + loss4test_running_loss += loss.item()epoch_test_loss = test_running_loss / len(testloader.dataset)print('epoch: ', epoch, 'loss: ', round(epoch_loss, 3),'test_loss: ', round(epoch_test_loss, 3))return epoch_loss, epoch_test_losstrain_loss = []
test_loss = []
for epoch in range(epochs):epoch_loss, epoch_test_loss = fit(epoch, model, train_dl, test_dl)train_loss.append(epoch_loss)test_loss.append(epoch_test_loss)
注意,回归问题不用计算准确率
结果