stack和queue的模拟实现
- 容器适配器
- 什么是适配器
- STL标准库中stack和queue的底层结构
- deque的简单介绍
- deque的缺陷
- stack模拟实现
- queue模拟实现
- priority_queue
- priority_queue的使用
- priority_queue的模拟实现
容器适配器
什么是适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
STL标准库中stack和queue的底层结构
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配器,这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认使用deque。


deque的简单介绍
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
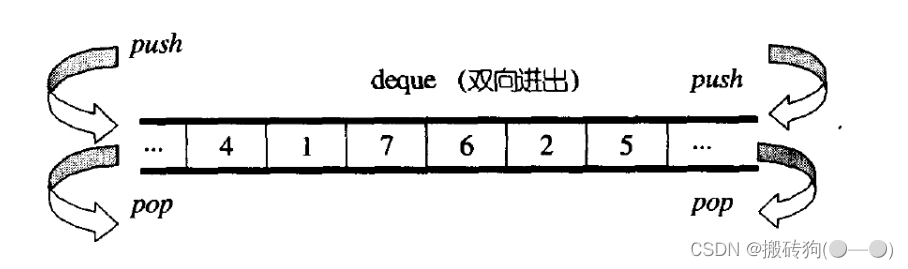
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组。
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂:
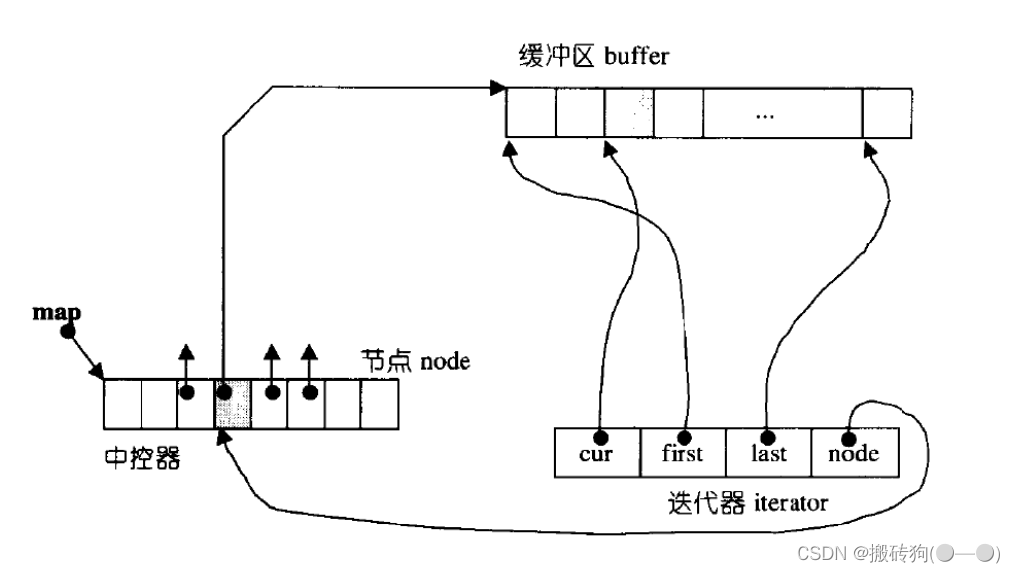
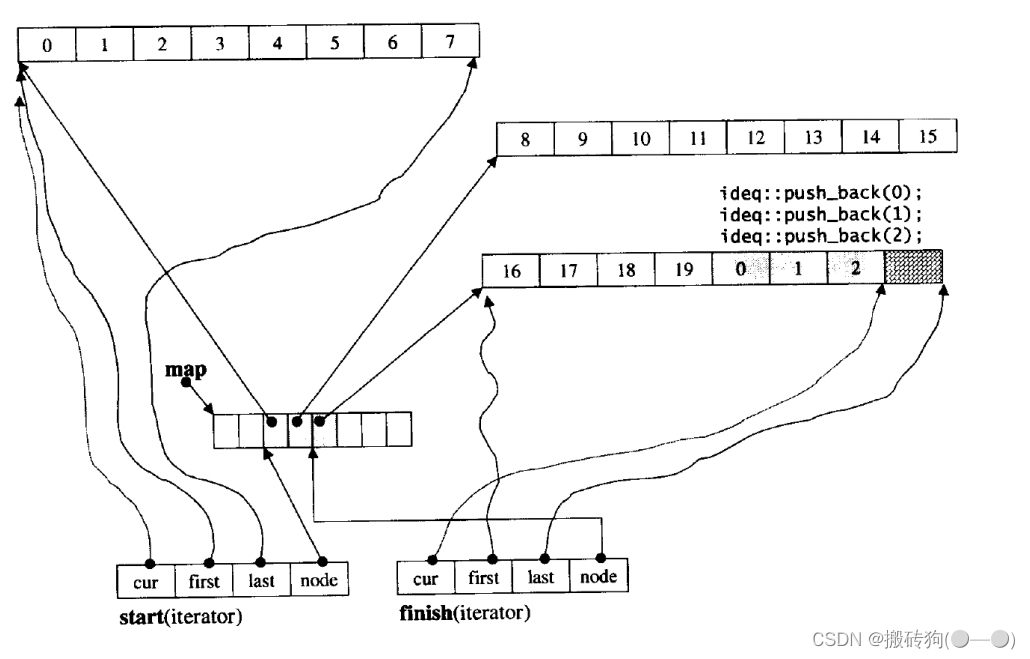
deque的缺陷
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
- stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。
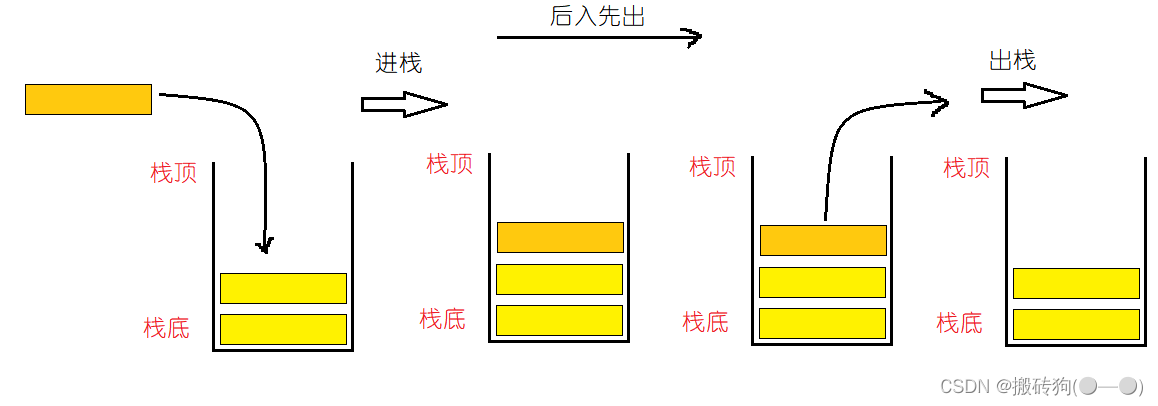
stack模拟实现
stack是一种后入先出的数据结构,有了容器适配器以后,就可以很容易去实现它了:
| 函数说明 | 接口说明 |
|---|---|
| empty() | 检测stack是否为空 |
| size() | 返回stack中元素的个数 |
| top() | 返回栈顶元素的引用 |
| push() | 将元素val压入stack中 |
| pop() | 将stack中尾部的元素弹出 |
| swap() | 交换两个栈中的数据 |
#pragma once
#include<deque>namespace gtt
{template<class T, class Container = deque<T>>class stack{public://插入void push(const T& x){_con.push_back(x);}//删除void pop(){_con.pop_back();}//取栈顶元素T& top(){return _con.back();}const T& top() const{return _con.back();}//判空bool empty() const{return _con.empty();}//求有效元素个数size_t size() const{return _con.size();}//交换两个栈的数据void swap(stack<T, Container>& st){_con.swap(st._con);}private:Container _con;};
}
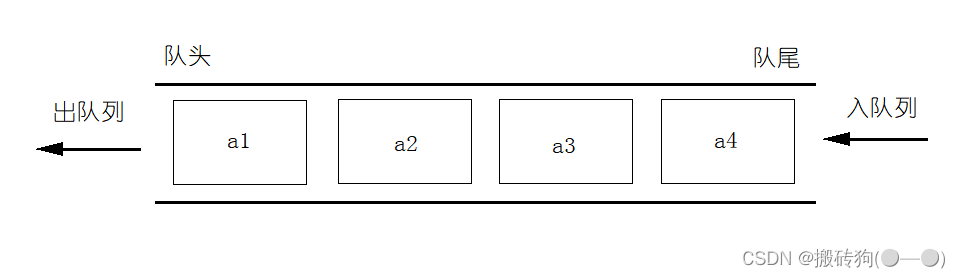
queue模拟实现
队列是队尾入,队头出的数据结构:
| 函数说明 | 接口说明 |
|---|---|
| empty() | 检测队列是否为空,是返回true,否则返回false |
| size() | 返回队列中有效元素的个数 |
| front() | 返回队头元素的引用 |
| back() | 返回队尾元素的引用 |
| push() | 将元素val压入stack中 |
| pop() | 将队头元素出队列 |
| swap() | 交换两个队列中的数据 |
#pragma once
#include<deque>namespace gtt
{template<class T, class Container = deque<T>>class queue{public://插入void push(const T& x){_con.push_back(x);}//删除void pop(){_con.pop_front();}//取队头元素T& front(){return _con.front();}const T& front() const{return _con.front();}//取队尾元素T& back(){return _con.back();}const T& back()const{return _con.back();}//判空bool empty(){return _con.empty();}//有效元素个数size_t size() const{return _con.size();}//交换两个栈中的数据void swap(queue<T, Container>& q){_con.swap(q._con);}private:Container _con;};
}
priority_queue
priority_queue被称作为优先级队列,类似于我们数据结构阶段所学习的堆:
- 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。
- 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
- 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部。
- 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
- empty():检测容器是否为空
- size():返回容器中有效元素个数
- front():返回容器中第一个元素的引用
- push_back():在容器尾部插入元素
- pop_back():删除容器尾部元素
- 标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指容器类,则使用vector。
- 需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用算法函数make_heap、push_heap和pop_heap来自动完成此操作。
priority_queue的使用
优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用priority_queue。注意:默认情况下priority_queue是大堆。
| 函数声明 | 接口说明 |
|---|---|
| priority_queue() priority_queue(first,last) | 构造一个优先级队列 |
| empty( ) | 检测优先级队列是否为空,是返回true,否则返回false |
| top( ) | 返回优先级队列中最大(最小元素),即堆顶元素 |
| push(x) | 在优先级队列中插入元素x |
| pop() | 删除优先级队列中最大(最小)元素,即堆顶元素 |

#include<iostream>
#include<vector>
#include<functional>
#include<queue>
using namespace std;class Date
{
public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}friend ostream& operator<<(ostream& _cout, const Date& d){_cout << d._year << "-" << d._month << "-" << d._day;return _cout;}
private:int _year;int _month;int _day;
};void priority_queue_test()
{//默认情况下创建的是大堆vector<int> v{ 3,2,7,6,0,4,1,9,8,5 };priority_queue<int> q1;for (auto& e : v){q1.push(e);}while (!q1.empty()){cout << q1.top() << " ";//9 8 7 6 5 4 3 2 1 0q1.pop();}cout << endl;//创建小堆,需要第三个模板参数换出greater比较方式priority_queue<int, vector<int>, greater<int>> heap(v.begin(), v.end());while (!heap.empty()){cout << heap.top() << " ";//0 1 2 3 4 5 6 7 8 9heap.pop();}cout << endl;//如果需要自定义数据,则需要对运算进行重载// 大堆,需要用户在自定义类型中提供<的重载priority_queue<Date> q2;q2.push(Date(2018, 10, 29));q2.push(Date(2018, 10, 28));q2.push(Date(2018, 10, 30));cout << q2.top() << endl;// 如果要创建小堆,需要用户提供>的重载priority_queue<Date, vector<Date>, greater<Date>> q3;q3.push(Date(2018, 10, 29));q3.push(Date(2018, 10, 28));q3.push(Date(2018, 10, 30));cout << q2.top() << endl;
}int main()
{priority_queue_test();return 0;
}
priority_queue的模拟实现
在这儿我们需要了解仿函数的概念:
仿函数(Functor)又称为函数对象(Function Object)是一个能行使函数功能的类。仿函数的语法几乎和我们普通的函数调用一样,不过作为仿函数的类,都必须重载 operator() 运算符。因为调用仿函数,实际上就是通过类对象调用重载后的 operator() 运算符。
通过下面这段代码我们就可以很好的认识我们的仿函数:
namespace gtt
{template<class T>class less{public:bool operator()(const T& l, const T& r) const{return l < r;}};template<class T>class greater{public:bool operator()(const T& l, const T& r) const{return l > r;}};
}int main()
{gtt::less<int> lsFunc1;cout << lsFunc1(1, 2) << endl;gtt::greater<int> lsFunc2;cout << lsFunc2(1, 2) << endl;return 0;
}
我们可以将优先级队列就理解为一个堆结构,他的实现也就是一个建堆的过程,就像我们实现堆一样,需要用到向上,向下调整算法,下面就是priority_queue的模拟实现:
namespace gtt
{//Compare时进行比较的仿函数,less->大堆, greater->小堆template<class T, class Container = vector<T>, class Compare = std::less<T>>class priority_queue{public://构造函数priority_queue(){}template<class InputIterator>priority_queue(InputIterator first, InputIterator last){while (first != last){_con.push_back(*first);first++;}//建堆for (int i = (_con.size() - 1 - 1) / 2; i >= 0; i--){adjust_down(i);}}//向上调整算法void adjust_up(size_t child){Compare com;size_t parent = (child - 1) / 2;while (child > 0){//建大堆if (com(_con[parent], _con[child])){std::swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}}//堆的插入void push(const T& x){_con.push_back(x);adjust_up(_con.size() - 1);}//向下调整算法void adjust_down(size_t parent){Compare com;size_t child = parent * 2 + 1;while (child < _con.size()){if (child + 1 < _con.size() && com(_con[child], _con[child + 1])){child++;}if (com(_con[parent], _con[child])){std::swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}}//堆的删除void pop(){std::swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);}//取堆顶元素const T& top(){return _con[0];}//判断堆是否为空bool empty(){return _con.empty();}//堆有效元素个数size_t size(){return _con.size();}private:Container _con;};
}