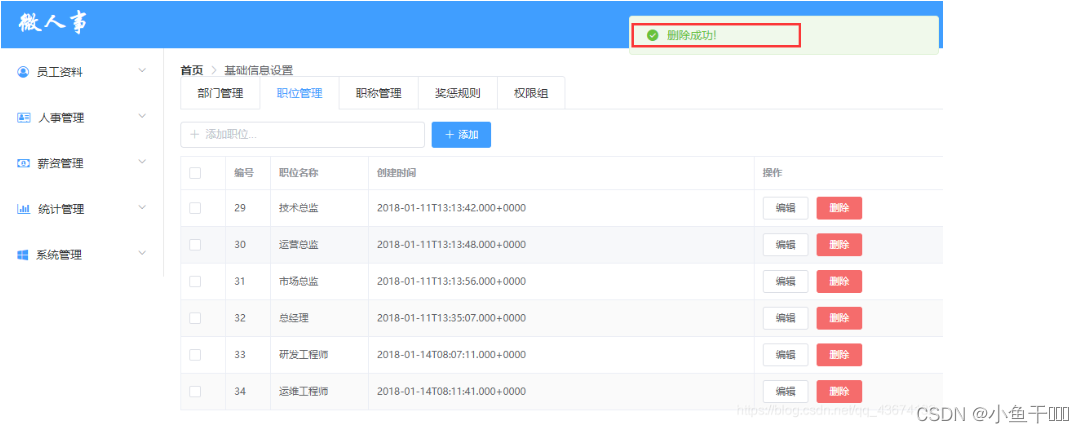
直接看代码。
(一)手动实现
import torch
import torch.nn as nn
import numpy as np
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt#下载MNIST手写数据集
mnist_train = torchvision.datasets.MNIST(root='./MNIST', train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./MNIST', train=False,download=True, transform=transforms.ToTensor()) #读取数据
batch_size = 256
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True,num_workers=0)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False,num_workers=0) #初始化参数
num_inputs,num_hiddens,num_outputs =784, 256,10num_epochs=30lr = 0.001def init_param():W1 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens,num_inputs)), dtype=torch.float32) b1 = torch.zeros(1, dtype=torch.float32) W2 = torch.tensor(np.random.normal(0, 0.01, (num_outputs,num_hiddens)), dtype=torch.float32) b2 = torch.zeros(1, dtype=torch.float32) params =[W1,b1,W2,b2]for param in params: param.requires_grad_(requires_grad=True) return W1,b1,W2,b2def dropout(X, drop_prob):X = X.float()assert 0 <= drop_prob <= 1keep_prob = 1 - drop_probif keep_prob == 0:return torch.zeros_like(X)mask = (torch.rand(X.shape) < keep_prob).float()print(mask)return mask * X / keep_probdef net(X, is_training=True):X = X.view(-1, num_inputs)H1 = (torch.matmul(X, W1.t()) + b1).relu()if is_training:H1 = dropout(H1, drop_prob)return (torch.matmul(H1,W2.t()) + b2).relu()def train(net,train_iter,test_iter,loss,num_epochs,batch_size,lr=None,optimizer=None):train_ls, test_ls = [], []for epoch in range(num_epochs):ls, count = 0, 0for X,y in train_iter:l=loss(net(X),y)optimizer.zero_grad()l.backward()optimizer.step()ls += l.item()count += y.shape[0]train_ls.append(ls)ls, count = 0, 0for X,y in test_iter:l=loss(net(X,is_training=False),y)ls += l.item()count += y.shape[0]test_ls.append(ls)if(epoch+1)%10==0:print('epoch: %d, train loss: %f, test loss: %f'%(epoch+1,train_ls[-1],test_ls[-1]))return train_ls,test_lsdrop_probs = np.arange(0,1.1,0.1)Train_ls, Test_ls = [], []for drop_prob in drop_probs:W1,b1,W2,b2 = init_param()loss = nn.CrossEntropyLoss()optimizer = torch.optim.SGD([W1,b1,W2,b2],lr = 0.001)train_ls, test_ls = train(net,train_iter,test_iter,loss,num_epochs,batch_size,lr,optimizer) Train_ls.append(train_ls)Test_ls.append(test_ls)x = np.linspace(0,len(train_ls),len(train_ls))plt.figure(figsize=(10,8))for i in range(0,len(drop_probs)):plt.plot(x,Train_ls[i],label= 'drop_prob=%.1f'%(drop_probs[i]),linewidth=1.5)plt.xlabel('epoch')plt.ylabel('loss')# plt.legend()
plt.legend(loc=2, bbox_to_anchor=(1.05,1.0),borderaxespad = 0.)
plt.title('train loss with dropout')
plt.show()运行结果:
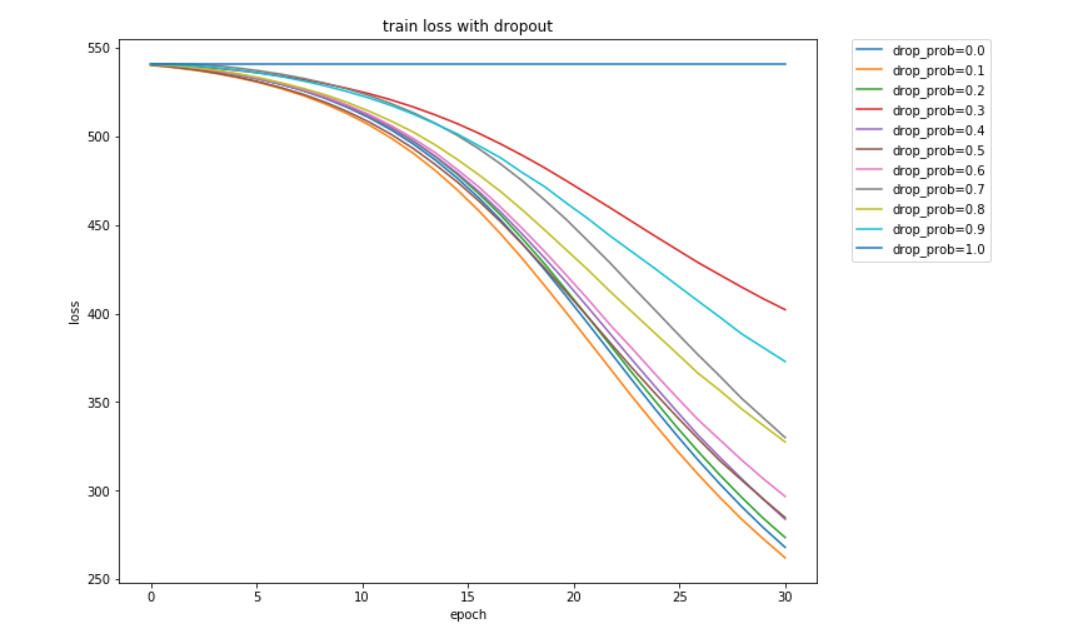
(二)torch.nn实现
import torch
import torch.nn as nn
import numpy as np
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as pltmnist_train = torchvision.datasets.MNIST(root='./MNIST', train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./MNIST', train=False,download=True, transform=transforms.ToTensor())
batch_size = 256
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True,num_workers=0)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False,num_workers=0) class LinearNet(nn.Module):def __init__(self,num_inputs, num_outputs, num_hiddens1, num_hiddens2, drop_prob1,drop_prob2):super(LinearNet,self).__init__()self.linear1 = nn.Linear(num_inputs,num_hiddens1)self.relu = nn.ReLU()self.drop1 = nn.Dropout(drop_prob1)self.linear2 = nn.Linear(num_hiddens1,num_hiddens2)self.drop2 = nn.Dropout(drop_prob2)self.linear3 = nn.Linear(num_hiddens2,num_outputs)self.flatten = nn.Flatten()def forward(self,x):x = self.flatten(x)x = self.linear1(x)x = self.relu(x)x = self.drop1(x)x = self.linear2(x)x = self.relu(x)x = self.drop2(x)x = self.linear3(x)y = self.relu(x)return ydef train(net,train_iter,test_iter,loss,num_epochs,batch_size,params=None,lr=None,optimizer=None):train_ls, test_ls = [], []for epoch in range(num_epochs):ls, count = 0, 0for X,y in train_iter:l=loss(net(X),y)optimizer.zero_grad()l.backward()optimizer.step()ls += l.item()count += y.shape[0]train_ls.append(ls)ls, count = 0, 0for X,y in test_iter:l=loss(net(X),y)ls += l.item()count += y.shape[0]test_ls.append(ls)if(epoch+1)%5==0:print('epoch: %d, train loss: %f, test loss: %f'%(epoch+1,train_ls[-1],test_ls[-1]))return train_ls,test_ls num_inputs,num_hiddens1,num_hiddens2,num_outputs =784, 256,256,10
num_epochs=20
lr = 0.001
drop_probs = np.arange(0,1.1,0.1)
Train_ls, Test_ls = [], []for drop_prob in drop_probs:net = LinearNet(num_inputs, num_outputs, num_hiddens1, num_hiddens2, drop_prob,drop_prob)for param in net.parameters():nn.init.normal_(param,mean=0, std= 0.01)loss = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(net.parameters(),lr)train_ls, test_ls = train(net,train_iter,test_iter,loss,num_epochs,batch_size,net.parameters,lr,optimizer)Train_ls.append(train_ls)Test_ls.append(test_ls)x = np.linspace(0,len(train_ls),len(train_ls))
plt.figure(figsize=(10,8))
for i in range(0,len(drop_probs)):plt.plot(x,Train_ls[i],label= 'drop_prob=%.1f'%(drop_probs[i]),linewidth=1.5)plt.xlabel('epoch')plt.ylabel('loss')
plt.legend(loc=2, bbox_to_anchor=(1.05,1.0),borderaxespad = 0.)
plt.title('train loss with dropout')
plt.show()input = torch.randn(2, 5, 5)
m = nn.Sequential(
nn.Flatten()
)
output = m(input)
output.size()
运行结果:
关于dropout的原理,网上资料很多,一般都是用一个正态分布的矩阵,比较矩阵元素和(1-dropout),大于(1-dropout)的矩阵元素值的修正为1,小于(1-dropout)的改为1,将输入的值乘以修改后的矩阵,再除以(1-dropout)。
疑问:
- 数值经过正态分布矩阵的筛选后,还要除以 (1-dropout),这样做的原因是什么?
- Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。