请求获取数据
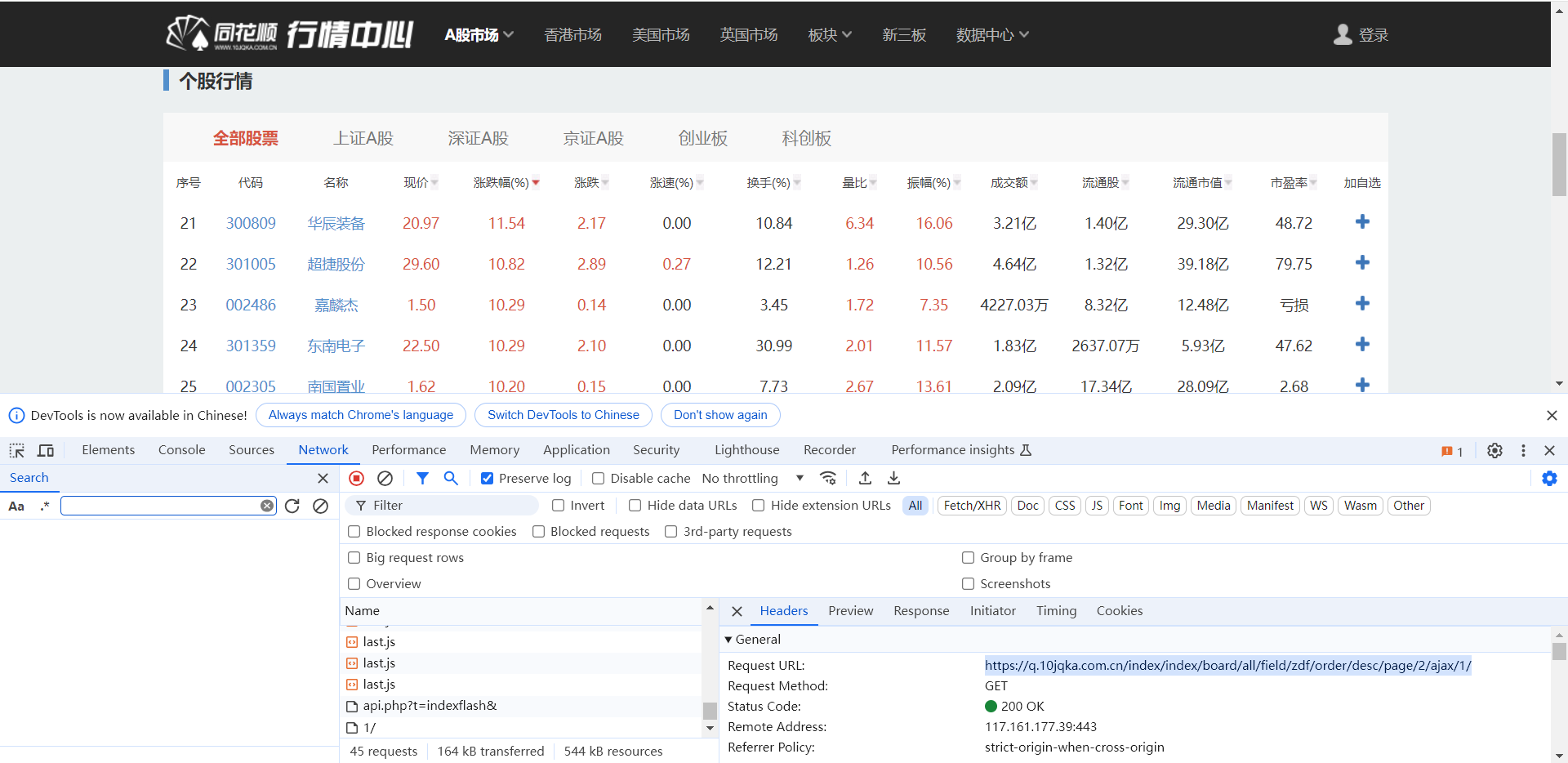
import requestsurl = 'https://q.10jqka.com.cn/index/index/board/all/field/zdf/order/desc/page/2/ajax/1/'headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36' }response = requests.get(url=url, headers=headers) html = response.text print(html)
运行结果:
<html><body><script type="text/javascript" src="//s.thsi.cn/js/chameleon/chameleon.min.1719332.js"></script> <script src="//s.thsi.cn/js/chameleon/chameleon.min.1719332.js" type="text/javascript"></script><script language="javascript" type="text/javascript">window.location.href="//q.10jqka.com.cn/index/index/board/all/field/zdf/order/desc/page/2/ajax/1/";</script></body></html>
结果中并为出现存在所要爬取的数据
思考:可能存在反爬
1、考虑请求头信息
2、存在加密可能
解决方法:1、请求头中添加Cookie、Referer等后再次运行,问题解决
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36','Cookie': 'v=Awcc3GskLeIF9alu7ByNVWQylrDUDNolNeJfetn1IU-9lCmu4dxrPkWw77Xq','Referer': 'https://q.10jqka.com.cn/' }

解析数据:
import parselresponse = requests.get(url=url, headers=headers) html = response.text selector = parsel.Selector(response.text)# 提取所有tr标签 data = selector.css('.m-table tr')[1:] # print(data) for i in data:info = i.css('td::text').getall()numberAndName = i.css('td a::text').getall()# print(numberAndName)# print(info)# 把数据保存到字典里dit = {'序号': info[0],'代码': numberAndName[0],'名称': numberAndName[1],'现价': info[1],'涨跌幅(%)': info[2],'涨跌': info[3],'涨速(%)': info[4],'换手(%)': info[5],'量比': info[6],'振幅(%)' : info[7],'成交额': info[8],'流通股': info[9],'流通市值': info[10],'市盈率': info[11]}print(dit)
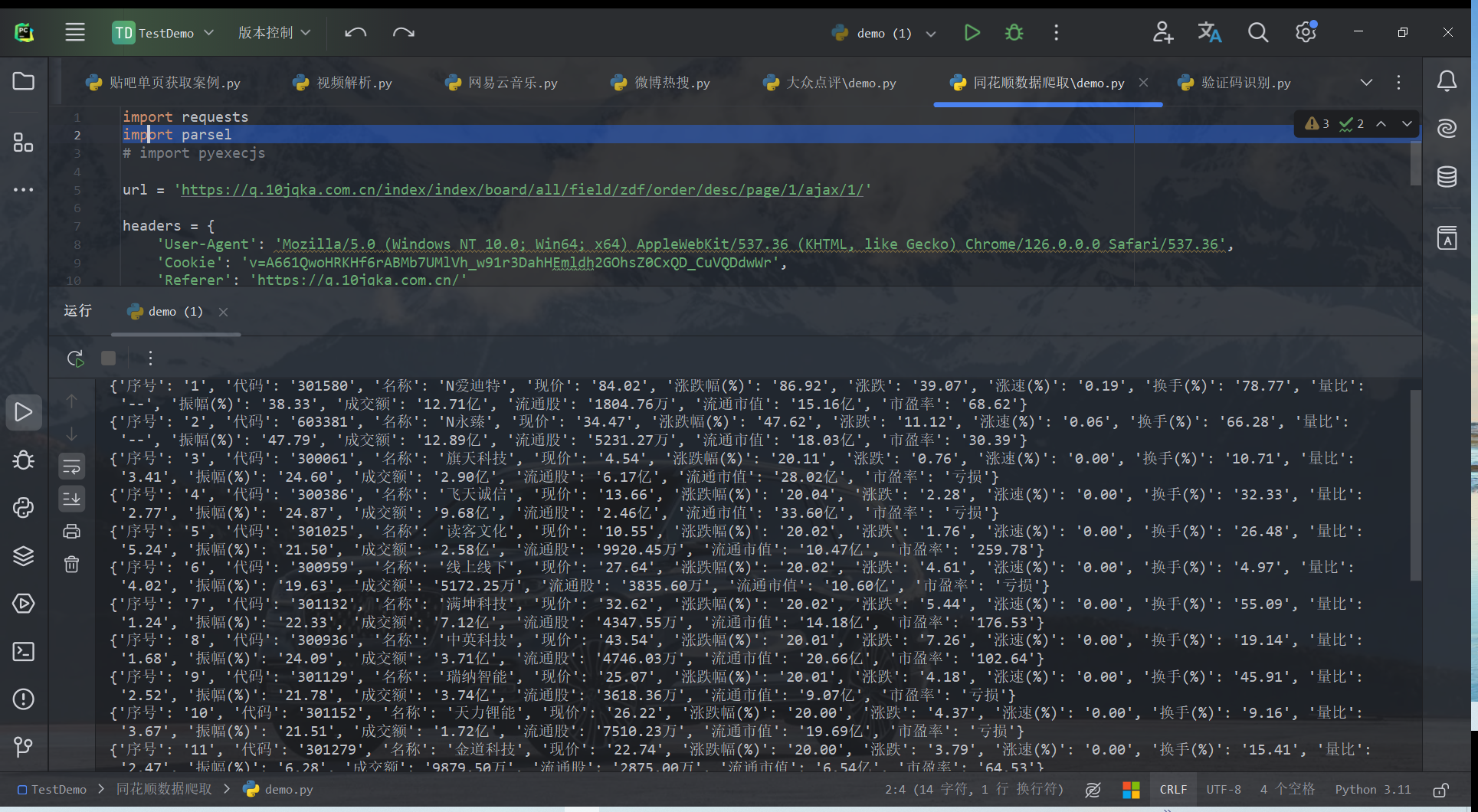
保存数据
股票数据保存为csv
import csv# 创建文件对象 f = open('stockInformation.txt', mode='w', encoding='utf-8', newline='') # 字典写入方法 csv_write = csv.DictWriter(f, fieldnames=['序号','代码','名称','现价','涨跌幅(%)','涨跌','涨速(%)','换手(%)','量比','振幅(%)','成交额','流通股','流通市值','市盈率', ]) # 写入表头 csv_write.writeheader()......for i in data:......# 写入数据 csv_write.writerow(dit) ......
运行结果:

翻页爬取
分析请求连接的变化规律
https://q.10jqka.com.cn/index/index/board/all/field/zdf/order/desc/page/1/ajax/1/https://q.10jqka.com.cn/index/index/board/all/field/zdf/order/desc/page/2/ajax/1/https://q.10jqka.com.cn/index/index/board/all/field/zdf/order/desc/page/3/ajax/1/
添加翻页功能:
for page in range(1, 3):print(f'正在采集第{page}页')url = f'https://q.10jqka.com.cn/index/index/board/all/field/zdf/order/desc/page/{page}/ajax/1/'......print(dit)
运行结果: