大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
不要轻易使用 For 循环
For 循环,老铁们在编程中经常用到的一个基本结构,特别是在处理列表、字典这类数据结构时。但是,这东西真的是个双刃剑。虽然看起来挺直白,一用就上手,但是,有时候用多了,问题也跟着来了。
性能问题
首先得说说性能问题。铁子们可能都有感觉,当你的数据量一大起来,用 For 循环去跑,这速度简直能让人急死。因为 For 循环处理大数据集时,每次迭代都要进行函数调用,这中间的开销可不小。尤其是在 Python 这样的解释型语言里,每一次循环的效率都非常关键。
可读性问题
再来看看可读性问题。当一个 For 循环嵌套多层,代码就开始变得难以理解。尤其是对于一些初学者或者维护别人代码的铁子们,一大堆的循环层层叠叠,看着就头大。
复杂度问题
最后是复杂度问题。很多时候,复杂的 For 循环逻辑可以通过更简单的方式实现。比如说列表推导式、map() 或者 filter() 这些函数,它们不仅代码更简洁,运行效率也往往比 For 循环高。
所以,老铁们,别看 For 循环简单易用,有时候在处理复杂或者大规模数据时,还是要斟酌一下,看看有没有更合适的工具。接下来,我们将介绍一些这样的替代工具,让你的代码不仅跑得快,而且更加清晰易懂。
1. 列表推导式
说到替代 For 循环的利器,怎能不提列表推导式呢?这货不仅写法简洁,而且执行效率高,是处理列表数据时的一大神器。
基本用法
列表推导式的基本形式是 [表达式 for 变量 in 可迭代对象]。比如说,我们要获取一个列表中所有元素的平方,如果用 For 循环可能要写几行,用列表推导式,一行代码就搞定了:
squares = [x**2 for x in range(10)]
适用场景
列表推导式特别适用于从一个列表生成另一个列表的场景。只要是能通过一行表达式解决的问题,都可以考虑用列表推导式。它不仅能简化代码,还能减少编写错误的机会。
示例代码
来个更实际的例子,假设我们要从一组数字中筛选出所有偶数,并计算它们的三次方。用 For 循环也能做,但用列表推导式,既快又直观:
cubes_of_evens = [x**3 for x in range(20) if x % 2 == 0]
老铁,看到没?这种方式不仅代码量少,而且一眼就能看懂做了啥,是不是比那些嵌套的 For 循环清爽多了?下面,我们来看看更高级一点的工具,也就是生成器表达式,这也是处理数据时的一把利器。
2. 生成器表达式
当谈到处理大数据集或者想要内存使用更加高效时,生成器表达式就跳出来说:“铁子们,看我的!”
基本用法
生成器表达式在形式上与列表推导式很相似,但它是用圆括号包裹起来的,不是方括号。生成器表达式不会一次性生成所有元素,而是生成一个生成器对象,每次迭代时才计算下一个值。这样做的好处是,内存利用率高,特别适合处理大规模数据集。
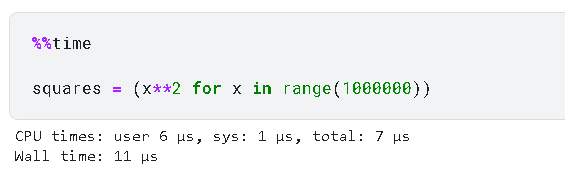
squares = (x**2 for x in range(1000000))
这行代码创建了一个生成器,可以逐个产生一百万个数的平方,但这些平方并不会同时存在内存中。
优势与劣势
生成器表达式的优势显而易见:内存效率高,懒加载,适合大数据处理。但劣势也很明显,它不如列表推导式直观,而且只能迭代一次,用完就没了,需要重新生成。
示例代码
假设我们需要计算大数据集中所有偶数的平方和,用生成器表达式来实现这一功能既节省内存又有效率:
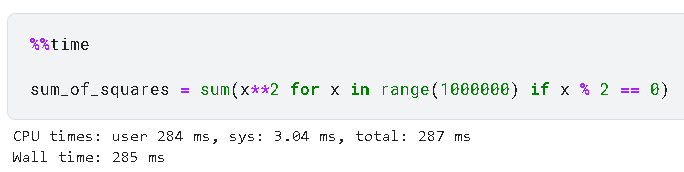
sum_of_squares = sum(x**2 for x in range(1000000) if x % 2 == 0)
是不是感觉生成器表达式像是那种默默无闻的英雄,不占内存的 spotlight,但能大显身手呢?
3. map() 函数
接下来聊聊 map() 函数,这个函数在 Python 里面算是老江湖了,特别擅长批量处理数据。
基本用法
map() 函数的基本思路是将一个函数应用到一个序列的所有元素上。这听起来有点像 For 循环,但实际上 map() 更高效、更直接。基本语法是 map(function, iterable),它返回一个迭代器。
def square(x):return x * x# 使用 map() 应用函数
squares = map(square, range(10))
适用场景
map() 函数非常适合那些需要对数据集中的每个元素都执行同一个操作的场景。它比手写循环快,因为 map() 通常是用 C 语言实现的,执行效率更高。
示例代码
来个实际点的,比如我们要把一系列字符串转换成它们的长度:
lengths = list(map(len, ["apple", "banana", "cherry"]))
看,老铁,只需要简单一行代码,没有复杂的循环,逻辑清晰,效率也棒棒的
4. filter() 函数
紧接着 map(),我们来谈谈 filter() 函数。这个函数就像它的名字那样,专门用来筛选东西,特别适合从一堆数据中过滤出我们需要的那部分。
基本用法
filter() 函数的作用是从一个序列中过滤出符合条件的元素,形成一个新的迭代器。它的基本语法是 filter(function, iterable),其中 function 是一个返回布尔值的函数,用来测试每个元素是否应该包含在新的迭代器中。
def is_even(x):return x % 2 == 0# 使用 filter() 筛选偶数
evens = filter(is_even, range(10))
适用场景
filter() 函数最适合的场景是需要根据某些条件从列表或其他可迭代对象中选择元素的情况。它可以帮助清洁数据,或者准备数据分析阶段。
示例代码
比如说,我们有一列表,想要过滤出里面所有正数的元素:
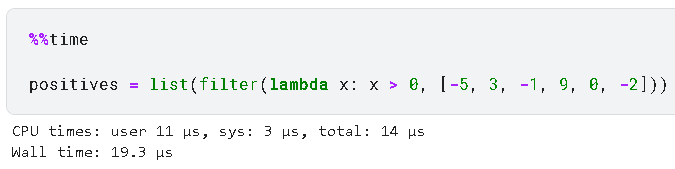
positives = list(filter(lambda x: x > 0, [-5, 3, -1, 9, 0, -2]))
老铁们,是不是感觉 filter() 就像是数据处理的一把锐利的剑,能精准地割掉那些不需要的部分?
5. reduce() 函数
接下来讲讲 reduce() 函数,这个函数可能不像 map() 或 filter() 那样常用,但在需要对列表中的所有元素进行一些累积操作时,reduce() 就能大显身手了。
基本用法
reduce() 函数位于 functools 模块中,它的作用是将一个接受两个参数的函数累积地应用到序列的元素上,从而将序列减少为单一的值。基本语法是 reduce(function, iterable[, initializer])。
from functools import reducedef add(x, y):return x + y# 使用 reduce() 计算元素总和
total = reduce(add, [1, 2, 3, 4, 5])
适用场景
reduce() 特别适合于需要对一系列数据执行累积操作的情况,比如求和、求乘积或者其他需要从一系列值得到单一结果的操作。
示例代码
来个更具体的例子,比如我们要找出一组数中的最大值,可以使用 reduce():
max_value = reduce(lambda x, y: x if x > y else y, [7, 22, 5, 13, 27])
函数——reduce(),虽然它不是 Python 标准库的一部分,但使用起来效果杠杠的,尤其在进行数据累积处理时。
6. itertools 模块
itertools 模块中包含了多种用于构建迭代器的工具,这些工具可以帮助我们高效地处理数据,特别是在需要组合数据、过滤数据或累积数据时。
itertools.starmap
starmap 函数类似于 map(),但它允许函数接受多个参数。所以,当你有一个参数列表的列表(或其他可迭代的序列)时,starmap() 可以非常方便地应用一个多参数函数。
from itertools import starmapdef add(x, y):return x + y# 使用 starmap 来计算多个数对的和
result = list(starmap(add, [(1, 2), (3, 4), (5, 6)]))
这段代码通过 starmap 直接将 add 函数应用于每一对元组,使得代码更加简洁。
itertools.accumulate
accumulate 函数用来计算累积的中间结果,可以非常直观地看到从第一个元素到当前元素的累积结果。默认情况下,它提供累加的功能,但你也可以指定其他的二元函数。
from itertools import accumulate
import operator# 累加
accumulated_sums = list(accumulate([1, 2, 3, 4, 5]))
# 累乘
accumulated_products = list(accumulate([1, 2, 3, 4, 5], operator.mul))
这两个示例展示了如何使用 accumulate 来进行累加和累乘,它们提供了一种非常直观的方式来处理序列的累积计算。
itertools 模块的这些工具在处理复杂的迭代任务时非常有用,它们可以帮助我们写出更高效、更简洁的代码。利用这些工具,你可以优化你的数据处理流程,提高代码的执行效率。
7. NumPy 向量化操作
跳进数据科学的大门,怎能不提 NumPy 的向量化操作?在处理数值数据时,这技能简直是利器。
基本概念
向量化操作指的是直接对数组进行操作,而不是逐个元素进行。这种方法利用了 NumPy 的内部优化,能显著提升计算速度。用 NumPy 来说,就是把那些通常需要在循环中逐个处理的任务,转换为整体操作,让整个数组一次性处理。
import numpy as np# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])# 计算每个元素的平方
squares = arr ** 2
性能优势
NumPy 的向量化操作由底层的 C 语言支持,执行速度远快于 Python 的循环。这不仅减少了执行时间,还能在处理大型数据集时节省大量资源。
示例代码
比如说,我们需要计算两个数组的点积,直接用 NumPy 的向量化方式就可以简洁高效地完成:
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])# 计算点积
dot_product = np.dot(a, b)
看到没有老铁?这操作简直快如闪电。而且代码整洁到不行,看着都是一种享受。

8. Pandas 向量化操作
继 NumPy 之后,Pandas 在数据处理界也是个大腕儿。它的向量化操作专门针对表格数据,效率和功能都一流。
基本概念
Pandas 向量化操作主要是指对 DataFrame 或 Series 对象进行的操作,这些操作不需要显式的循环。就像 NumPy,Pandas 的操作也是建立在底层的 C 语言优化之上,所以速度很快,特别是在处理大型数据集时。
import pandas as pd# 创建一个 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})# 计算每个元素的平方
df_squared = df ** 2
性能优势
使用 Pandas 的向量化操作,可以显著提高数据处理速度,并减少代码的复杂度。当处理成千上万条记录时,这种优势尤为明显。
示例代码
来看一个实用的例子,比如我们要根据一列的条件快速过滤数据:
# 创建一个较大的 DataFrame
large_df = pd.DataFrame({'Age': [22, 45, 18, 25, 30],'Salary': [35000, 80000, 27000, 32000, 40000]
})# 过滤出年龄大于 24 岁的记录
filtered_df = large_df[large_df['Age'] > 24]
老铁们,Pandas 的向量化操作让数据筛选、转换这些任务变得简单又快速。处理表格数据时,它简直是得力助手。
9. 并行处理
在处理大规模数据或需要高性能计算时,单纯依靠向量化操作有时还不够,这时并行处理就闪亮登场了。并行处理能让我们把任务分散到多个处理器上,实现真正的同时执行,大幅提升效率。
基本概念
并行处理意味着同时运行多个计算任务。这通常通过多线程或多进程实现,每个线程或进程处理数据的一个部分。Python 中有多种方式来实现并行处理,包括使用 threading 和 multiprocessing 库。
from multiprocessing import Pooldef square(number):return number * number# 创建一个进程池
with Pool(4) as p:results = p.map(square, range(10))
使用方法
并行处理适用于计算密集型任务,或者当任务可以被自然地分解成多个独立部分时。正确使用并行处理可以显著减少程序的运行时间。
示例代码
比如,我们需要处理一个大数据集,每个数据点需要进行复杂计算,可以将数据分批处理:
import numpy as np
from multiprocessing import Pool# 大数据集
data = np.random.rand(10000)# 复杂计算的函数
def complex_calculation(x):return np.sin(x) ** 2 + np.cos(x) ** 2# 使用进程池
with Pool(8) as p:results = p.map(complex_calculation, data)
通过并行处理,我们可以更高效地利用计算资源,处理那些让单核 CPU 望而却步的重任务。这就是现代编程的一种趋势,特别是在数据科学和机器学习领域,有效地利用并行处理技术可以大大加速数据处理和模型训练过程。
[ 抱个拳,总个结 ]
在编程中,替换 For 循环的方法有很多,每种方法都有其适用的场景。选择合适的方法不仅能提升代码的执行效率,还能增强代码的可读性和可维护性。
根据具体需求选择
老铁们,选择替代方法的时候,首先得考虑你的具体需求。比如,如果处理的是大数据集,并且对性能要求极高,可能向量化操作或并行处理会更合适。如果是简单的数据转换,列表推导式或 map() 函数可能就足够了。
考虑代码的可读性
代码的可读性是软件开发中的关键。选择那些能让其他开发者一看就懂的方法,可以减少未来维护的难度。比如,列表推导式因其简洁性通常比传统的 For 循环更易读,但如果推导式变得过于复杂,可能就得考虑回到更基本的循环结构,或者使用函数来提高清晰度。
性能优化的注意事项
在进行性能优化时,别忘了测试和验证你的选择是否真的提升了性能。有时候,一些看似高效的方法(如并行处理)可能因为引入的额外开销而未必带来预期的性能提升。使用像 Python 的 timeit 模块这样的工具来量化不同方法的性能,可以帮助你做出更明智的选择。
老铁们,选对工具,事半功倍。希望这些建议能帮你们在实际工作中做出更好的技术选择,写出更优雅、更高效的代码。如果还有其他想了解的,尽管问!
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
应对不确定,最确定的方法是做好确定的事
确定的,比如,基础很重要;
确定的,比如,人是会挂的;
大侠,你说还是什么是确定的且是需要被特别关照的呢?
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖