在朴素RAG中通常会对文档、文本进行分块后进行文档嵌入,对所有文件、文本都没有经过采用Chunk方法可能有时候效果不是和好,尽管有着各种分块策略有针对大文件的、针对小文件的策略,但都难免可能会造成上下文语义丢失。
分块通常有两个非常重要的参数chunk_size、chunk_overlap,分别代表块大小与块与块之间的重叠量,并不好确定这两个值的具体数字,只能通过不断实验确定该值。
基本原理
在分块效果不好时或许可以试试多表示索引(Multi-representation indexing),在多表示索引中并不会对整个文档分块后进行文档嵌入。而是通过为每个文档都生成一个文档摘要,为每个文档摘要与文档生成一个唯一ID,将摘要与ID关联嵌入到Vectorstore中,将ID与文档关联存储到独立文档存储中。
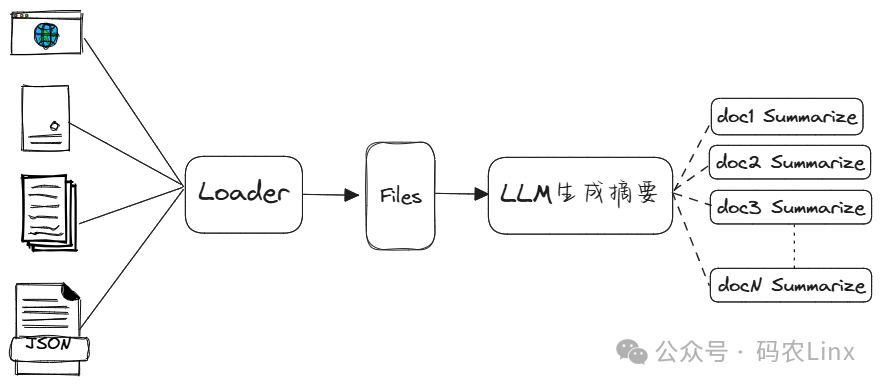
在用户提问时会先根据提出的问题先在多向量检索器中检索相似度最高的文档摘要,获取的文档摘要后也得到了所关联的id,再拿文档id到文档存储中获取所对应的完整文档。
此文档作为用户提问问题的上下文,同时将问题与文档上下文提交到LLM。
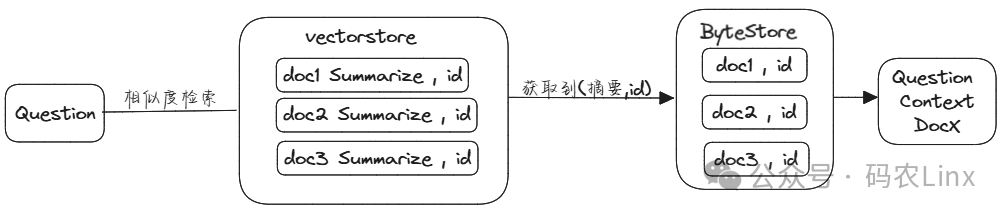
经过多表示索引的使用嵌入空间大小下降很多,相似度搜索性能也会提升,使用完整文档用作上下文LLM响应的准确性也会有所提高。

适用于小文档结构,当文档太大时会超出LLM上下文长度,超大文档并不适用多表示索引。
代码示例
def loadDocs():loader = WebBaseLoader("https://www.hinews.cn/news/system/2024/07/04/033173743.shtml")docs = loader.load()loader = WebBaseLoader("https://www.hinews.cn/news/system/2024/07/04/033173745.shtml")docs.extend(loader.load())return docsdef processSummaries():chain = ({"doc": lambda x: x.page_content}| ChatPromptTemplate.from_template("请总结以下文档:\n\n{doc}")| llm| StrOutputParser())docs=loadDocs()summaries = chain.batch(docs, {"max_concurrency": 5})return summaries,docsdef get_retriever():summaries, docs= processSummaries()docstore = init_docstore() vectorstore = Chroma(collection_name="summaries", embedding_function=initEmbedding())#创建用于映射概要与文档的id数组doc_ids = [str(uuid.uuid4()) for _ in docs]#创建概要文档并关联ID summary_docs = [Document(page_content=s, metadata={"doc_id": doc_id}) for s, doc_id in zip(summaries, doc_ids)]#创建多向量检索器retriever = MultiVectorRetriever(vectorstore=vectorstore,byte_store=docstore,id_key="doc_id",search_kwargs={'k': 1})#将概要文档添加到向量存储retriever.vectorstore.add_documents(summary_docs)#文档与id关联lists = list(zip(doc_ids, docs))#文档添加到检索器的文档存储中retriever.docstore.mset(lists)return retriever创建好多向量检索器后即可使用该检索器,或配合RetrievalQA使用:
query="机场在哪里"
retriever= get_retriever()
retriever.invoke(query)#问答链
qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever, chain_type_kwargs={"prompt": PROMPT})
resp =qa_chain.invoke(query)
从多向量检索器的实现源码可看到,其先从vectorstore中查询到相似度最高的N个概要文档,然后获取概要文档ID,根据ID去查询完整文档。
sub_docs = await self.vectorstore.asimilarity_search(query, **self.search_kwargs)
ids = []
for d in sub_docs:if self.id_key in d.metadata and d.metadata[self.id_key] not in ids:ids.append(d.metadata[self.id_key])
docs = await self.docstore.amget(ids)