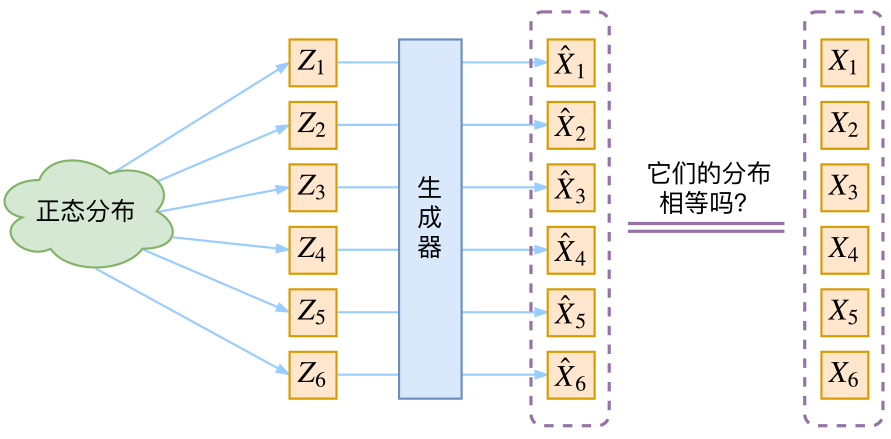
编译过程一般可以分为6步:扫描、语法分析、语义分析、源代码优化、代码生成和目标代码优化。
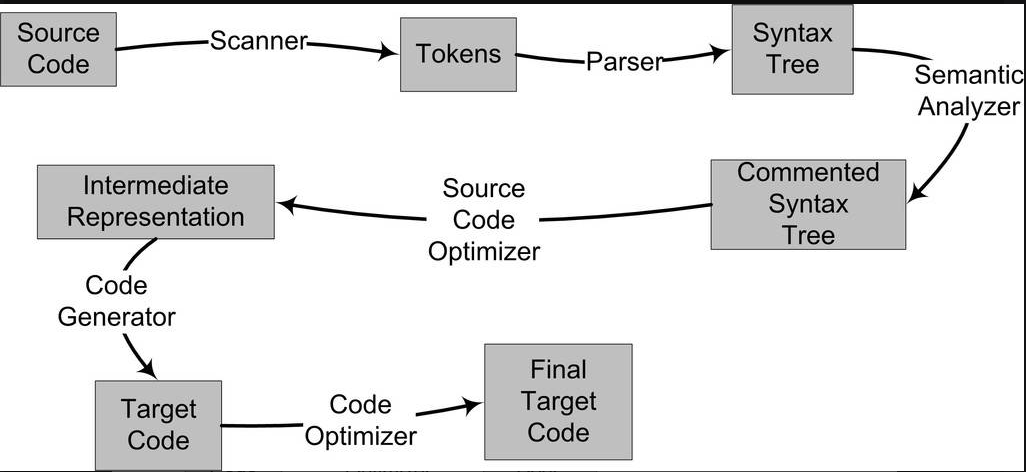
整个过程
- 词法分析:扫描器扫描代码之后,将代码生成一个个token
- 语法分析:语法分析器对token进行语法分析,最后生成一个语法树
对于不同的编程语言,可以共用一个语法分析器,因为只是将token生成一个语法树而已,语法树的每个节点是一个表达式
- 语义分析:通过语义分析器进行静态语义分析,主要做声明和类型的匹配,类型转换这类工作。最终为语法树的每个表达式都标识类型,也就是做了comment
- 中间语言生成:由于在对源码进行优化的时候,直接对语法树进行分析比较困难,所以编译器会先将整个语法树转成一个中间代码(是语法树的一种顺序表示)
中间代码使得编译器可以被分为前端和后端。编译器前端负责产生机器无关的中间代码,编译器后端将中间代码转换成目标机器代码。这样对于一些可以跨平台的编译器而言,它们可以针对不同的平台使用同一个前端和针对不同机器平台的数个后端。
源代码级优化器产生中间代码标志着下面的过程都属于编辑器后端。编译器后端主要包括代码生成器(Code Generator)和目标代码优化器(Target Code Optimizer)
- 目标代码生成与优化:
代码生成器将中间代码转换成目标机器代码,这个过程十分依赖于目标机器,因为不同的机器有着不同的字长、寄存器、整数数据类型和浮点数数据类型等。最后目标代码优化器对上述的目标代码进行优化,比如选择合适的寻址方式、使用位移来代替乘法运算、删除多余的指令等'
最终
经过编译,预处理后的文件(.i),会变成目标文件(.o),每个编译单元会生成一个.o文件,最终多个.o文件经过链接,才能得到最后的可执行文件


![[LeetCode] 134. Gas Station](https://img2024.cnblogs.com/blog/747577/202407/747577-20240707232800466-649701410.png)