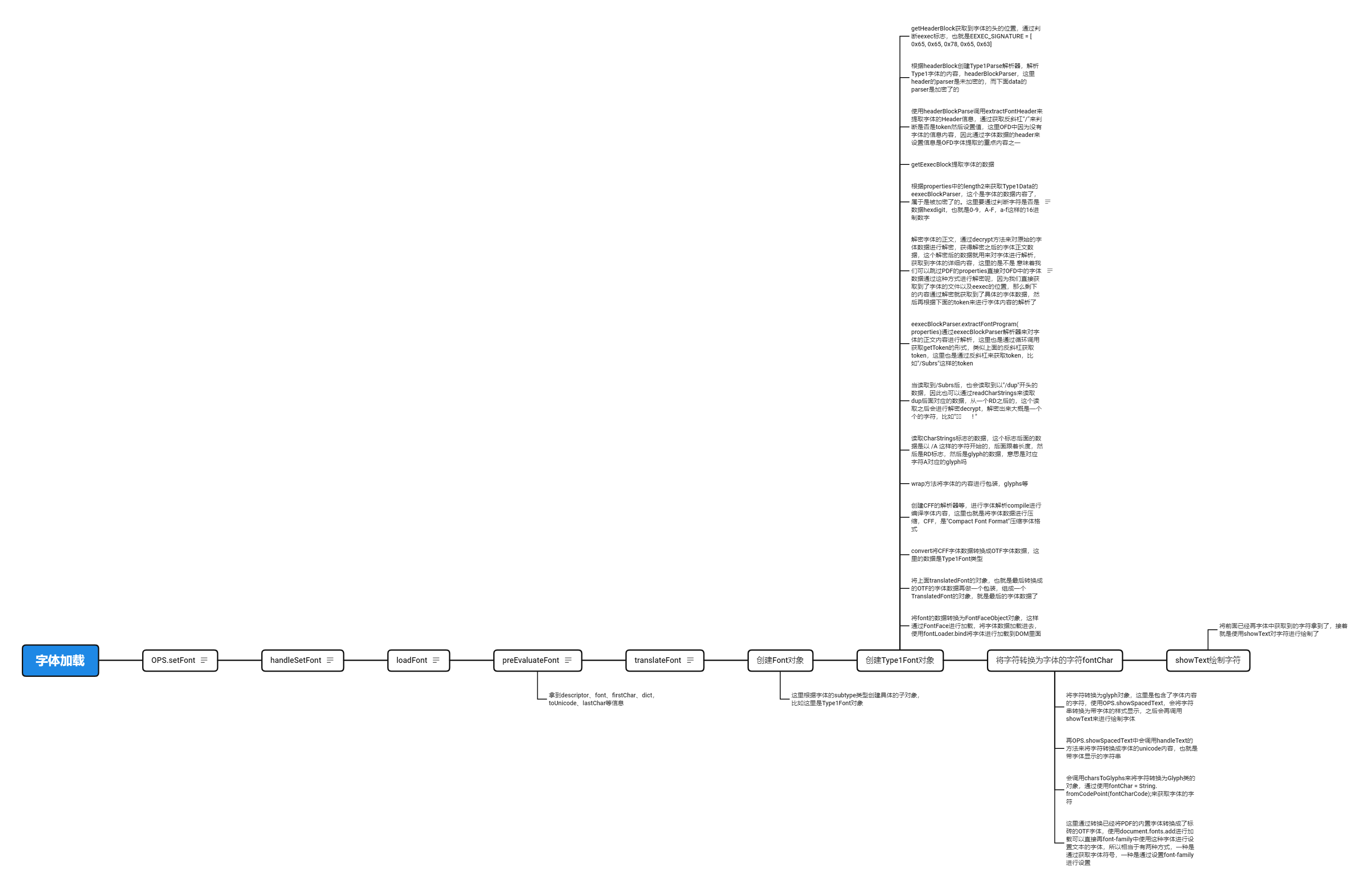
pdf.js中的字体加载流程,下面演示一种Type1的字体的加载流程,会把一些兼容性的内容省去,只记录字体数据的加载过程中涉及到的方法和作用:
- evaluator.js -> handleSetFont:操作符列表中加载字体
- evaluator.js -> loadFont:加载字体的方法
- evaluator.js -> preEvaluateFont:对字体信息进行预处理,对pdf中的字体信息开始整理,类似于将pdf中的字典信息进行整理,拿到pdf中字体的信息
- evaluator.js -> translateFont:通过上一步获取的字体信息,开始对字体进行加载和转换,此时假设字体数据包含有descriptor对象
在translateFont中会创建Font对象,首先是创建字体的properties属性,根据descriptor等获取到fontName等属性值,fontFile拿到字体的数据。
下面是包含descriptor时创建的字体properties属性对象
const properties = {type,name: fontName.name,subtype,file: fontFile,length1,length2,length3,isInternalFont,loadedName: baseDict.loadedName,composite,fixedPitch: false,fontMatrix: dict.getArray("FontMatrix") || FONT_IDENTITY_MATRIX,firstChar,lastChar,toUnicode,bbox: descriptor.getArray("FontBBox") || dict.getArray("FontBBox"),ascent: descriptor.get("Ascent"),descent: descriptor.get("Descent"),xHeight: descriptor.get("XHeight") || 0,capHeight: descriptor.get("CapHeight") || 0,flags: descriptor.get("Flags"),italicAngle: descriptor.get("ItalicAngle") || 0,isType3Font,cssFontInfo,scaleFactors: glyphScaleFactors,systemFontInfo,};
- evaluator.js -> extractDataStructures:有了上面的properties之后,调用extractDataStructures方法来获取字体编码和differences的值,这个方法重要,根据字体数据的编码类型,比如StandardEncoding还是其他等,获取到字体的编码映射等。以及获取toUnicodeMap,这里关于字体的映射和differences限于篇幅,就不做多的赘述,另开文章详写。
- evaluator.js -> extractWidths:提取字体中字符的宽度,每个字符都有一个宽度,所以拿到对应字符之后再进行宽度校正
- evaluator.js -> new Font(fontName.name, fontFile, newProperties):创建Font字体对象
- fonts.js -> fontFile.isEmpty:这个isEmpty会读取字体数据,判断不为空来读取字体的字节数据
- fonts.js -> getFontFileType:获取字体的类型,[type, subtype] = getFontFileType(file, properties);
- fonts.js -> new Type1Font(name, file, properties):根据字体数据和属性properties来创建Type1Font,这里按照Type1类型的字体进行解析字体数据。
- type1_font.js -> new Type1Font(name, file, properties):根据字体数据和属性properties来创建Type1Font,这里按照Type1类型的字体进行解析字体数据。
- type1_font.js -> checkEExecFlag,getHeaderBlock,extractFontHeader来获取Type1字体的头数据
- type1_parser.js -> extractFontProgram:提取字体数据中的
/CharStrings等token数据,这里时字体的规格数据 - type1_parser.js -> this.wrap(name,type2Charstrings,this.charstrings,subrs,properties):将字体数据进行包装,按照CFF格式进行组装拼接,这里是对字体格式进行,里面涉及的关于字体的内容比较多,这里不做过多赘述。CFF是紧凑型字体,这里还不会直接使用,通过CFF字体之后会再次convert为OTF字体
- type1_parser.js -> adjustWidths(properties):对字体宽度进行重新矫正,使用fontMatrix进行校正
- fonts.js -> convert(name, cff, properties):最后是将CFF的字体数据传入之后再进行组装成OTF字体数据,并且转换成unit8array的二进制数组,这个就是最后使用的字体数据了,进行loadFont的数据
- evaluator.js -> new TranslatedFont({loadedName: font.loadedName,font: translatedFont,dict: font,evaluatorOptions: this.options}):将OTF的字体再次进行转换,构造一个TranslatedFont对象,主要是包含了OTF的字体数据font值,以及用来发送字体加载完成的消息,也就是send方法,并且对Type3字体做处理,这里具体Type3字体的处理暂不赘述。
- evaluator.js -> handleSetFont:这里进入到let translated = await this.loadFont,将上面所生成的translatedFont对象作为字体数据,并且translatedFont调用send方法表示当前字体加载完成,将当前的消息发送到api.js中,此时调用的是
commonobj,然后对象是Font类型 - api.js -> messageHandler.on("commonobj"):处理加载完字体发送过来的数据,const font = new FontFaceObject(exportedData, ...),这里将translatedFont中的font的data数据进行转换成FontFaceObject对象,这个FontFaceObject是pdf.js封装的用来进行处理FontFace字体对象的类,这样在使用FontFace的时候就是使用pdf.js中包装的FontFaceObject来将OTF中的字体数据和浏览器的FontFace对象之间进行关联
- api.js -> this.fontLoader.bind(font):使用fontLoader对上一步中的FontFaceObject字体进行加载,会调用FontFaceObject中的createNativeFontFace,也就是将pdf.js中的字体转换为FontFace这样的对象,这样创建浏览器的本地FontFace对象,这个FontFace加载的名字也就是后面要在设置字体的时候使用的font-family的名字,再通过document.fonts.add(fontFace)即完成字体到本地浏览器的加载
以上便是pdf.js对于Type1字体加载的整个流程,其中并没有进行详细叙述,但是也大概包含了完整的从数据流到字体的流程,其中还包含几个重要步骤没有详细描述,比如FlateStream的加载和解析,相当于对flate编码的流数据进行解密。以及具体的CFF和OTF字体之间的转换,关键有一个是对于字体中header的一个描述使用。还有toUnicodeMap这样进行字体映射的内容的具体描述。
下图是一个加载的具体流程,从左到右,从上到下的顺序








![[Java]“不同族”基本数据类型间只能“强转”吗?](https://img-blog.csdnimg.cn/direct/da8d7ec093fc485a91a74208c34de93a.png)