一、 Pandas简介
Pandas,python+data+analysis的组合缩写,是python中基于numpy和matplotlib第三方数据分析库,与后者共同构成python数据分析基础工具包,享有数据三剑客之名。正因为pandas是在numpy基础上实现的,其核心数据结构与numpy的ndarray十分相似,但pandas与numpy的关系不是替代,而是互为补充。Pandas就数据处理上比numpy更强大智能,而numpy比pandas更为基础强大。
二、安装Pandas
使用pip install numpy和pip install pandas安装numpy和pandas库


安装完成后会有pandas、numpy、python-deteutil、six这几个三方库
引入pandas
import numpy as num
import pandas as pd
二、pandas读写数据
Pandas支持非常丰富的文件类型,也就是说,他可以读取保存多种类型的数据,比如excel文件、CSV文件,或者json文件、sql文件、html文件等。这对我们获取数据很方便,这里只讲解excel的一些常用用法,其他类型文件大同小异。
1、 read_excel():读取excel
a、 sheet_name:访问指定excel某张工作表。Sheet_name可以是str、int、list、None类型,默认值是0
举例如下:
1、读取一张sheet页
新建一张excel表,表名为test1,sheet页名为test1

import pandas as pd
df=pd.read_excel("test1.xlsx",sheet_name="test1")
print(df)
输出结果如下:

2、读取多张表
添加sheet页2 test2

import pandas as pd
df=pd.read_excel("test1.xlsx",sheet_name=["test1","test2"])
print(df)
输出结果:

3、指定页签读取数据,下标签从0开始
import pandas as pddf2=pd.read_excel("test1.xlsx",sheet_name=[0,1])
print(df2)
输出结果:

这里也可以指定页签读取数据
4、如果想读取所有页签的值,将sheet_name指定成None
import pandas as pddf3=pd.read_excel("test1.xlsx",sheet_name=None)
print(df3)
输出结果:

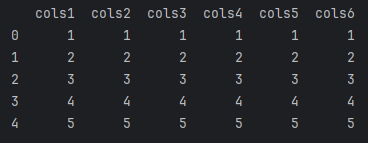
5、不指定sheet_name时,默认读取第一个页签数据
import pandas as pddf4=pd.read_excel("test1.xlsx")
print(df4)
输出结果:





![[笔记]快速傅里叶变换(FFT)](https://img2024.cnblogs.com/blog/3322276/202407/3322276-20240715100606097-912730953.png)
