CaiT通过LayerScale层来保证深度ViT训练的稳定性,加上将特征学习和分类信息提取隔离的class-attention层达到了很不错的性能,值得看看
来源:晓飞的算法工程笔记 公众号
论文: Going deeper with Image Transformers

- 论文地址:https://arxiv.org/abs/2103.17239
- 论文代码:https://github.com/facebookresearch/deit
Introduction
自ResNet出现以来,残差架构在计算机视觉中非常突出:
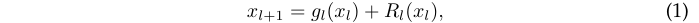
其中函数\(g_l\)和\(R_l\)定义了网络如何更新第l层的输入\(x_l\)。函数\(g_l\)通常是恒等式,而残差分支\(R_l\)则是网络构建的核心模块,许多研究都着力于残差分支\(R_l\)的变体以及如何对\(R_l\)进行初始化。实际上,残差结构突出了训练优化和结构设计之间的相互作用,正如ResNet作者所说的:残差结构没有提供更好的特征表达能力,之所以取得更好的性能,是因为残差结构更容易训练。
目前很火的ViT网络可认为是实现了一种特定形式的残差架构:在将输入图像转换为一组\(x_0\)的向量之后,网络交替进行自注意力层 (SA) 与前馈网络 (FFN) 处理:
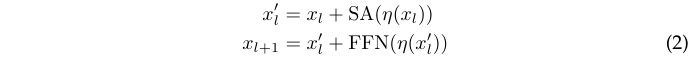
其中\(\eta\)是LayerNorm算子。
对于卷积神经网络和应用于NLP或语音任务的Transformer,如何对残差架构的残差分支进行归一化、加权或初始化受到了广泛关注。作者也在ViT上对不同初始化、优化和架构设计之间的相互作用进行了分析,并且提出了LayerScale层。LayerScale层包含一个初始权值接近于零的可学习对角矩阵,加在每个残差模块的输出上,可以有效地改进更深层架构的训练。
此外,作者还提出了class-attention层。类似于编码器/解码器架构,显示地将用于token间特征提取的transformer层与将token整合成单一向量进行分类的class-attention层分开,避免了两种目标不同的处理混合的矛盾现象。
通过实验验证,论文的主要贡献如下:
- LayerScale能够显着促进了训练收敛并提高了深度更大的ViT的准确性,仅需在训练时向网络添加了数千个参数(对比总参数量可以忽略不计)。
- 具有class-attention的架构提供了更高效的class embedding的处理。
- 在Imagenet-Real和Imagenet V2 matched frequency上,CaiT无需额外的训练数据就达到了SOTA性能。在ImageNet1k-val上,CaiT与最先进的模型 (86.5%) 相当,但仅需要更少的 FLOPs (329B vs 377B)和更少的参数(356M vs 438M)。
- 在迁移学习方面也取得了相当的结果。
Deeper image transformers with LayerScale
作者的目标是在提高Transformer架构的深度同时,提升图像分类训练优化的稳定性。在ViT和DeiT两项工作中,都没有研究仅在Imagenet上训练时,更大的深度可以带来任何好处:更深的ViT架构性能反而更低,而DeiT则只考虑了12层的架构。
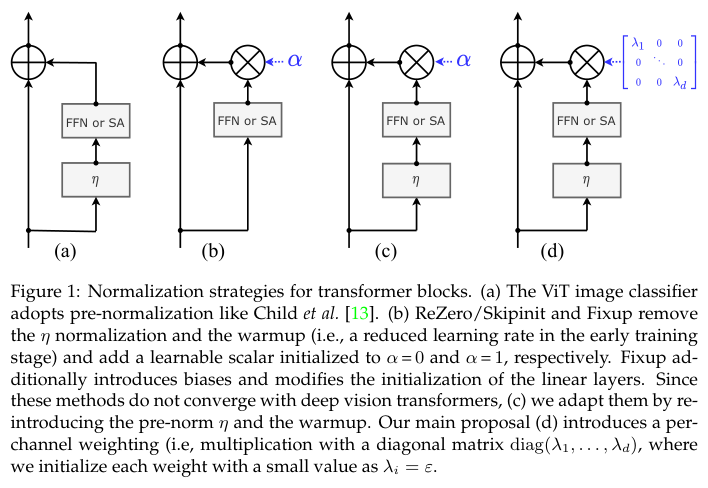
图1展示了可能有助于优化的主要变体,图a是标准的预归一化结构。图b则是Fixup、ReZero和SkipInit这类引入可学习标量\(a_l\)的结构,该类结构会同时去掉预归一化层和学习率warmup:
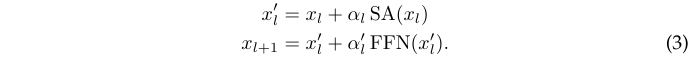
ReZero简单地初始化为\(\alpha = 0\),而Fixup则初始化为\(\alpha = 1\)并进行其他修改:采用不同的权值的初始化策略,添加了几个偏置权值。但在作者的实验中,即使对超参数进行了调整,这些方法也难以收敛。
经过观察,移除warmup和层归一化是导致Fixup和T-Fixup训练不稳定的原因。因此作者重新引入这两部分,使Fixup和T-Fixup在DeiT模型上收敛,如图1c所示。当深度增加时,以较小的值初始化的可学习标量\(a_l\)确实有助于收敛。
-
Our proposal LayerScale
作者提出的LayerScale对输出进行通道级别的乘法,而不是单个标量,如图1d所示,将权值更新与特定输出通道关联。公式上,可认为LayerScale是对每个残差分支输出的对角矩阵乘积:
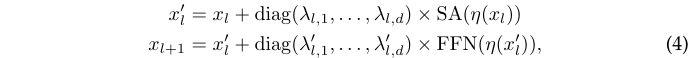
其中参数\(\lambda_{l,i}\)和\(\lambda^{'}_{l,i}\)是可学习权值,初始化为一个固定的小值\(\varepsilon\):
- 深度小于18时,设置为\(\varepsilon=0.1\)。
- 深度小于24时,设置为\(\varepsilon=10^{-5}\)。
- 对于更深的网络,设置为\(\varepsilon=10^{-6}\)。
该公式类似于其他归一化策略,如ActNorm或LayerNorm,但是在残差分支的输出上执行。此外,实际目的也有很大区别:
- ActNorm是数据相关的初始化,使输出具有零均值和单位方差,就像batchnorm操作。而LayerScale用较小的值初始化对角线,使其对残差分支的初始影响很小。因此,LayerScale更接近于ReZero、SkipInit、Fixup和T-Fixup等方法:先训练接近恒等函数的网络,然后在训练过程中让网络逐步集成额外参数。
- LayerScale在优化方面提供了更多的多样性,而不仅仅是通过一个可学习的标量调整,这也是LayerScale优于现有方法的决定性优势。
添加这些参数不会改变架构的特征表达能力,因为也可以集成到SA和FFN层的矩阵参数中,无需更改网络的实现。
Specializing layers for class attention
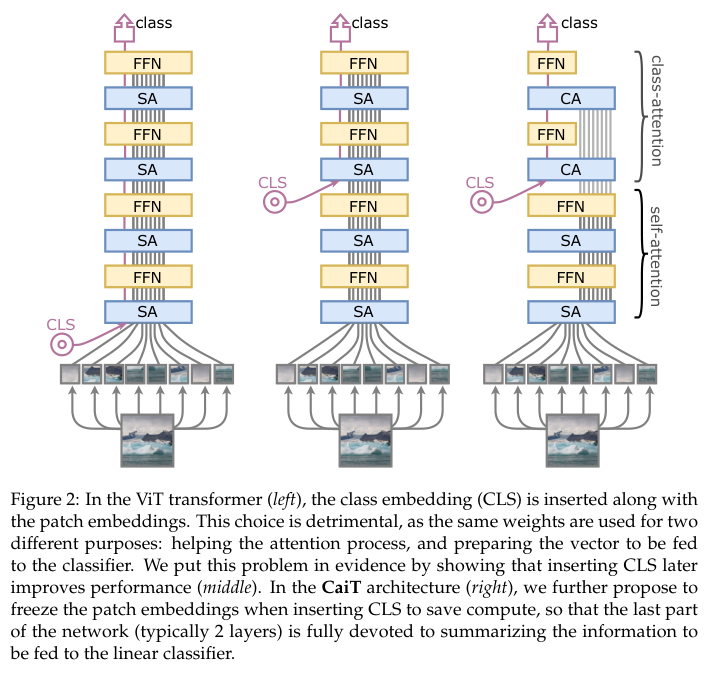
CaiT架构如图2右,设计核心旨在规避ViT架构要求权值训练同时优化两个相互矛盾的目标的问题。两个矛盾的目标分别是:
- 学习token之间的自我注意。
- 总结token间对分类有用的信息。
为此,CaiT的核心就是将上面两个矛盾完全分隔开。
Later class token
作为对比,在网络中间中插入Class token,这样前面的层可以专注于执行自我注意计算。作为不受矛盾目标影响的baseline,作者还考虑了将输出的平均池化用于分类的做法
Architecture
CaiT包含两个不同的处理阶段:
- self-attention阶段与ViT转换器类似,但没有Class token。
- class-attentio阶段是一组层,将token集合成class token,随后将输入到线性分类器中。
class-attention阶段依次交替由多头类注意(CA)和FFN组成的层,在这个阶段只有class token会更新。
Multi-heads class attention
CA的作用是从token中提取信息,与SA 类似,但CA只计算class toekn \(x_{class}\)和\(x_{class}\)与冻结的token \(x_{patches}\)的集合之间的注意力。
定义具有h个head和p个token的网络,d为token维度,将多头类注意力参数化为投影矩阵\(W_q、W_k、W_v、W_o \in \mathbb{R}^{d\times d}\)和偏置\(b_q, b_k, b_v, b_o \in R_d\)。基于上述定义,CA参数分支的计算可公式化为:
- 先将输入token扩充为\(z=[x_{class}, x_{patches}]\),执行以下映射:
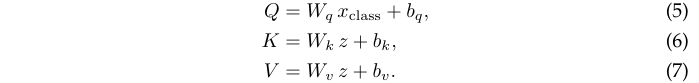
- 计算类注意力权重,其中\(Q\cdot K^T\in\mathbb{R}^{h\times 1\times p}\):
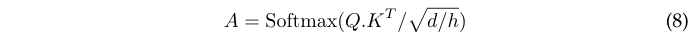
- 将注意力用于加权得到残差分支输出:
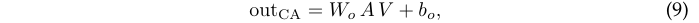
- 将输出叠加到\(x_{class}\)中以进行后续处理。
CA从特征token中提取有用信息整合到class token中。在实验中发现,第一个CA和FFN模块提供了主要的性能提升,叠加第二个模块就足以达到性能提升上限。
Complexity
CA函数在内存和计算方面也比SA更轻量,因为CA只计算class token和token集合之间的注意力:
- 对于CA,\(Q\in\mathbb{R}^d\),\(Q\cdot K^T\in\mathbb{R}^{h\times 1\times p}\)。
- 对于SA,\(Q\in\mathbb{R}^{p\times d}\),\(Q\cdot K^T\in\mathbb{R}^{h\times p\times p}\)。
这意味着,与token数量成二次方的计算复杂度在CaiT层中变为线性计算负责度。
Experiments
Preliminary analysis with deeper architectures
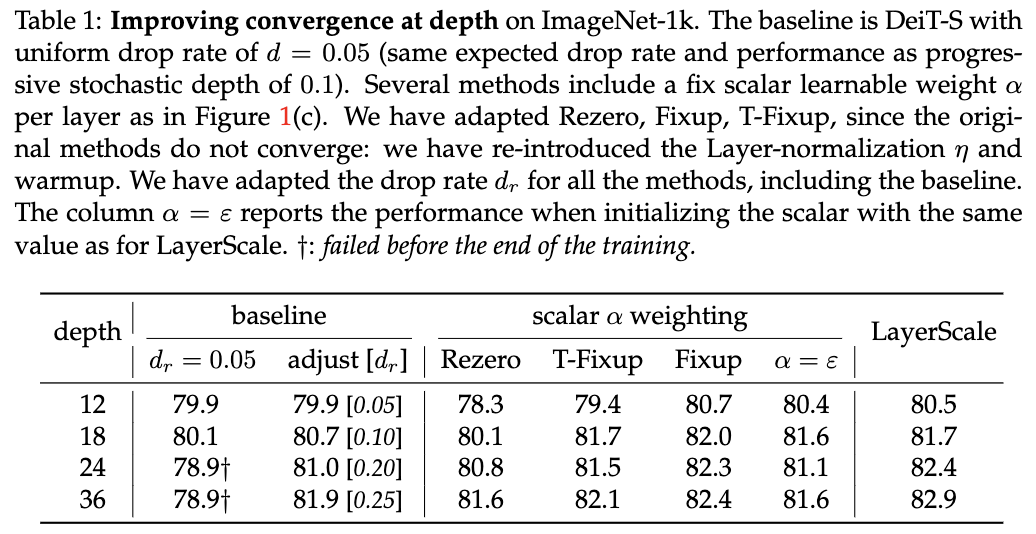
直接扩展网络深度,对不同训练超参数进行分析。
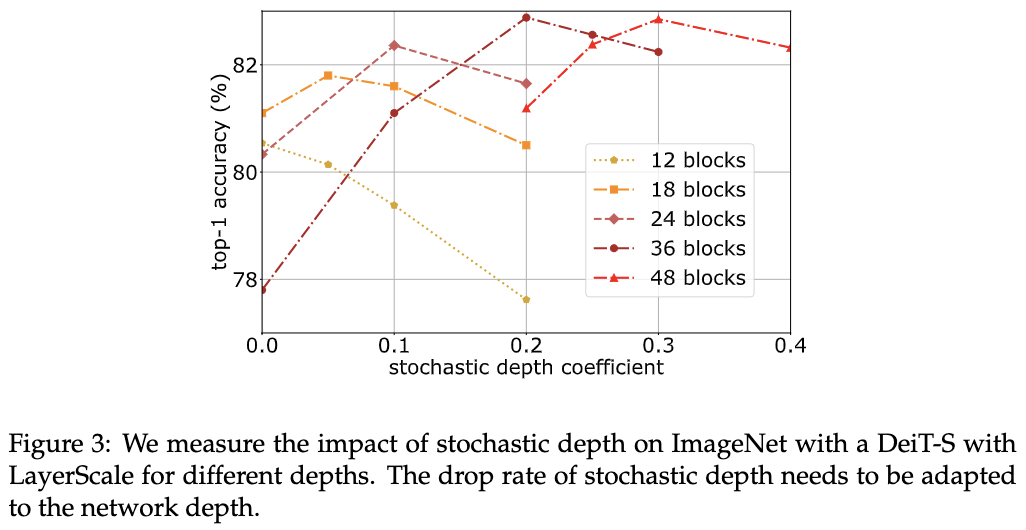
对比不同随机深度丢弃比例以及不同归一化策略的性能。
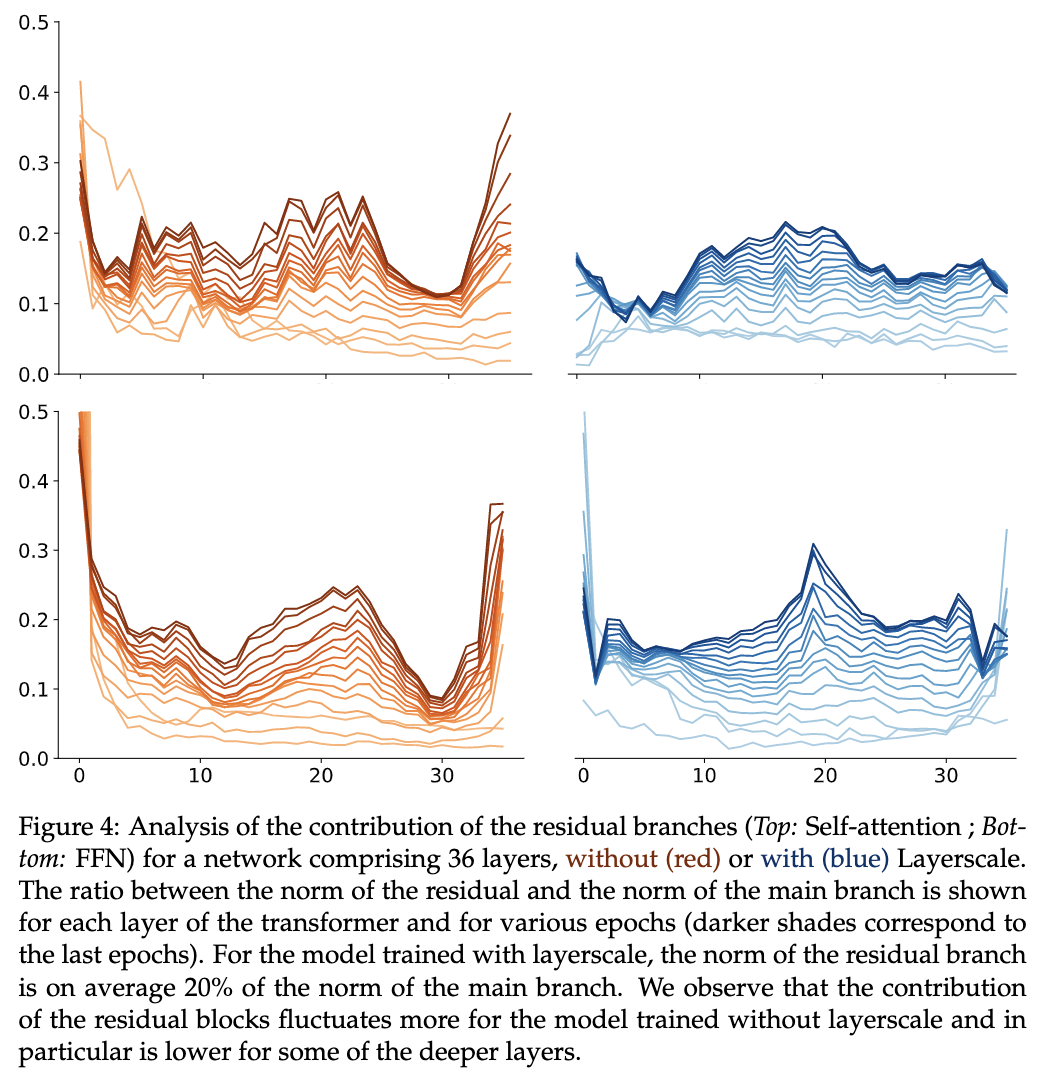
不同层的残差分支的权重可视化,使用LayerScale的权重会比较平稳。
Class-attention layers
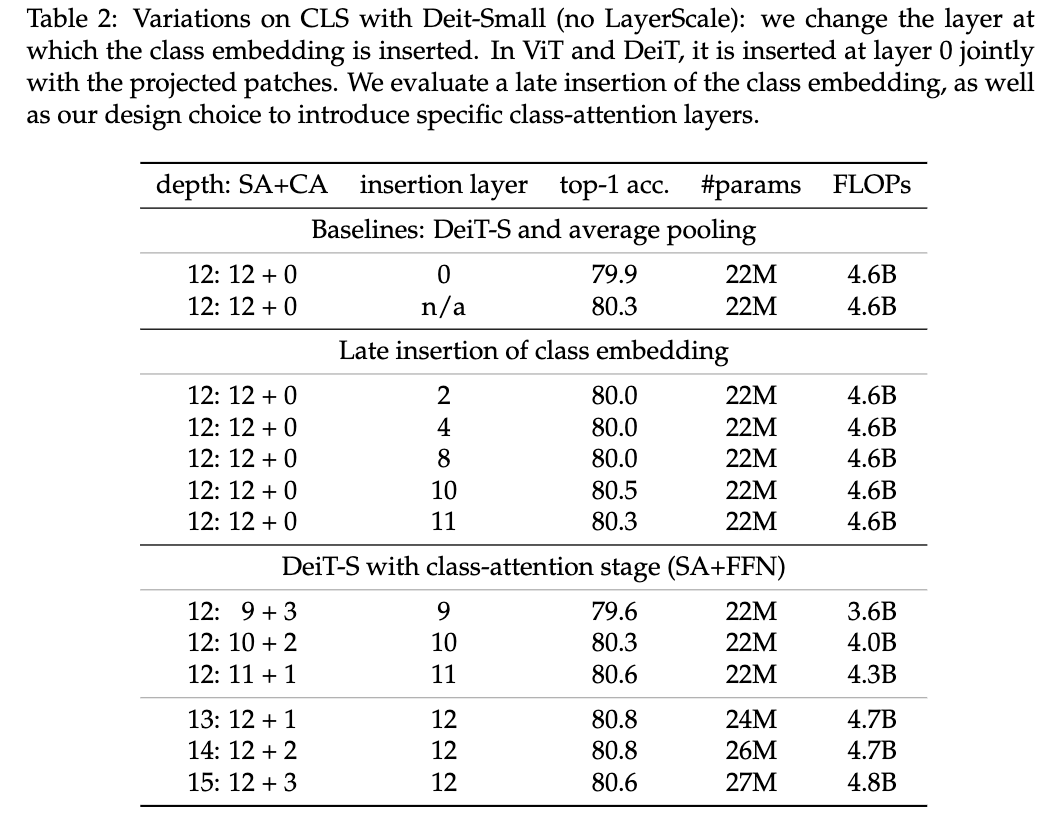
对图2的三种架构进行对比分析,最后是对比不同的SA和CA组合比例。
Our CaiT models
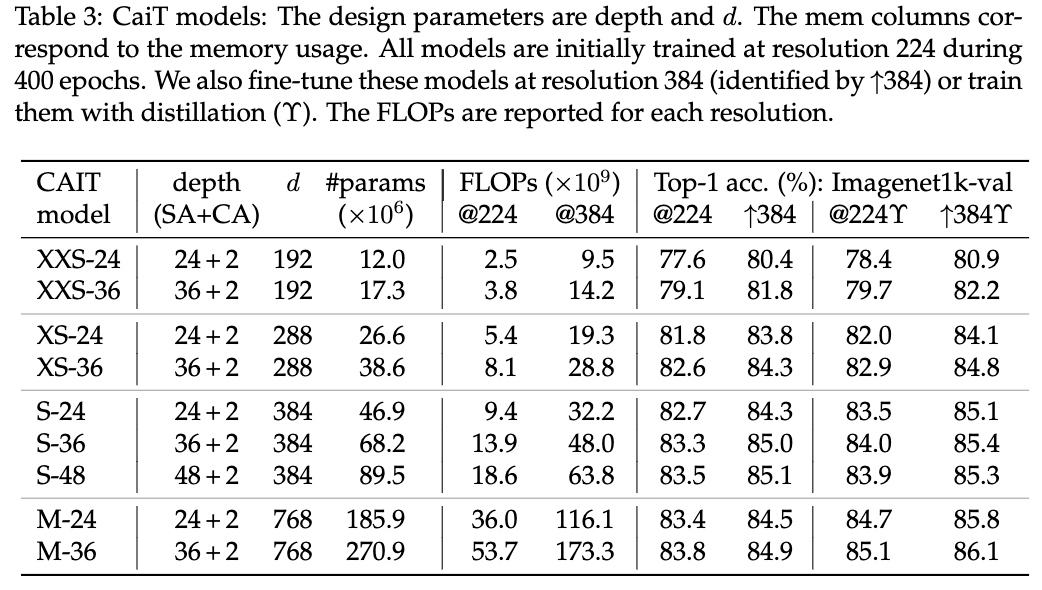

不同大小的CaiT模型性能对比以及对应的超参。
Results
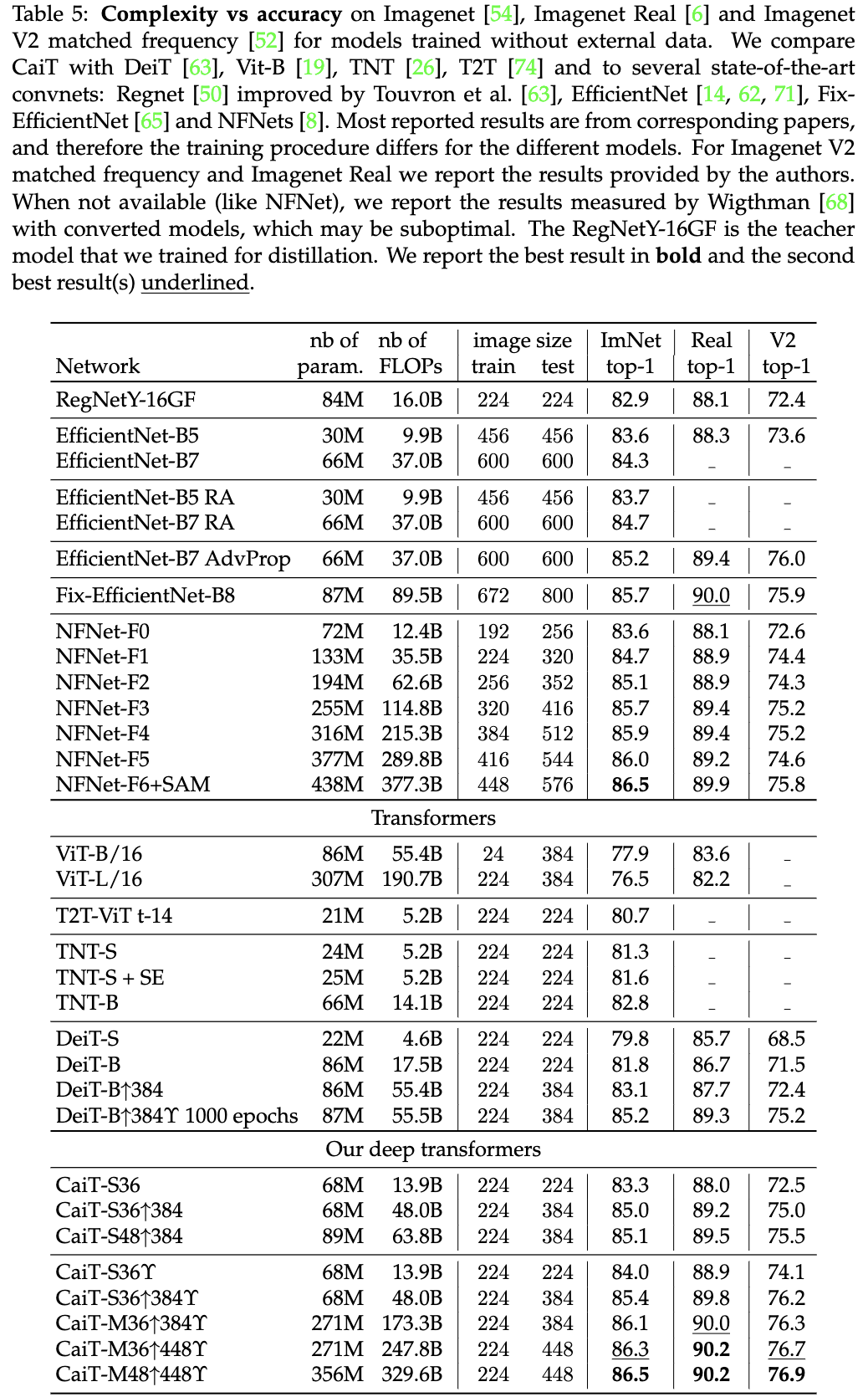
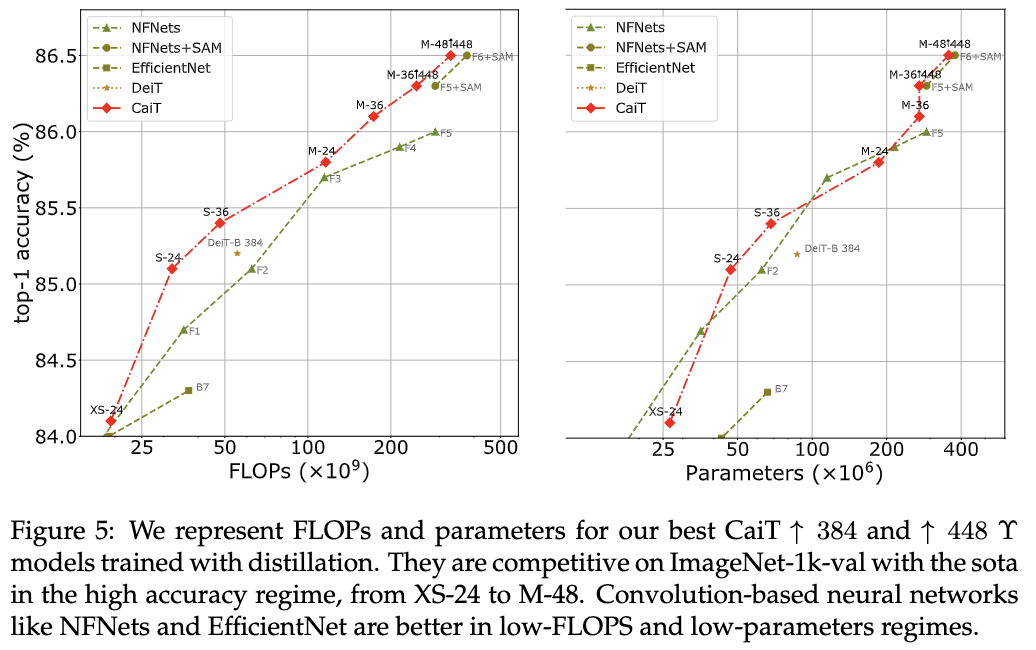
与SOTA模型对比,\(\uparrow\)代表使用高像素finetune,\(\gamma\)代表使用Deit的蒸馏训练。
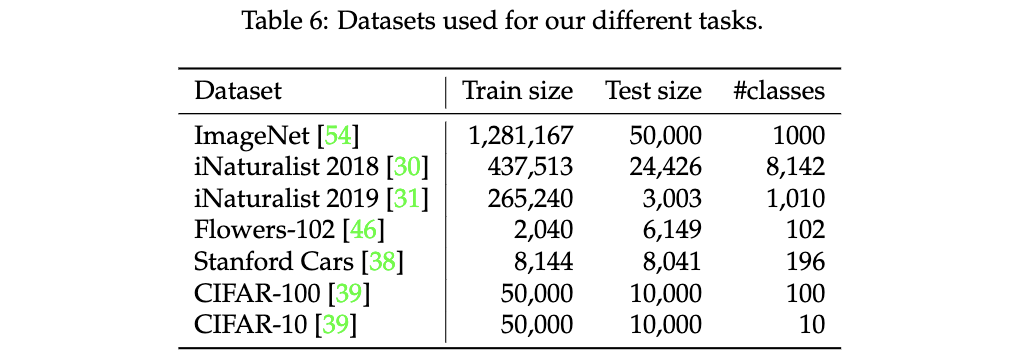
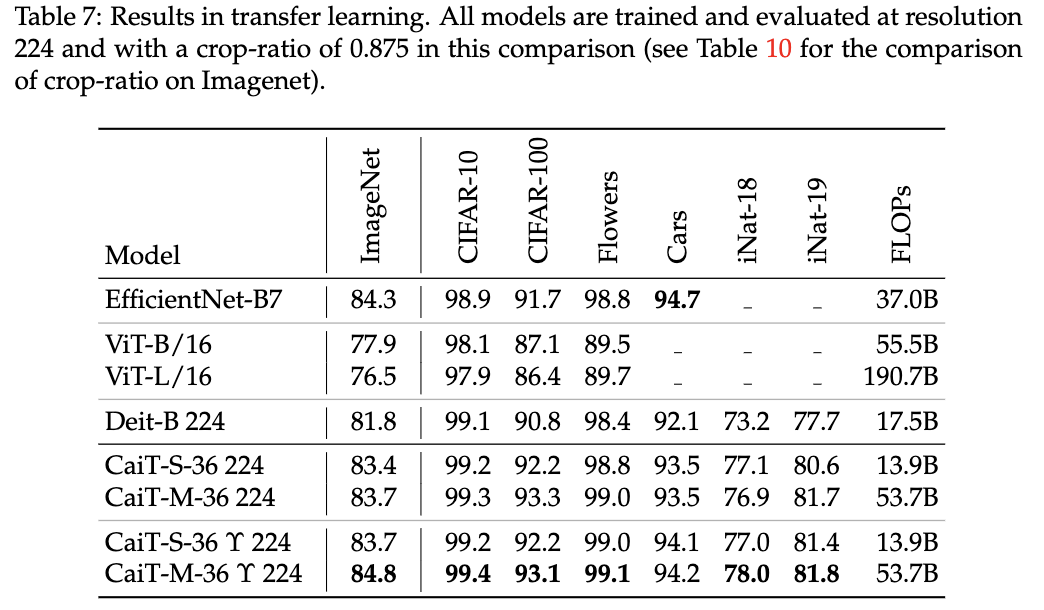
从ImageNet预训练迁移到其它分类数据集的性能对比。
Ablation
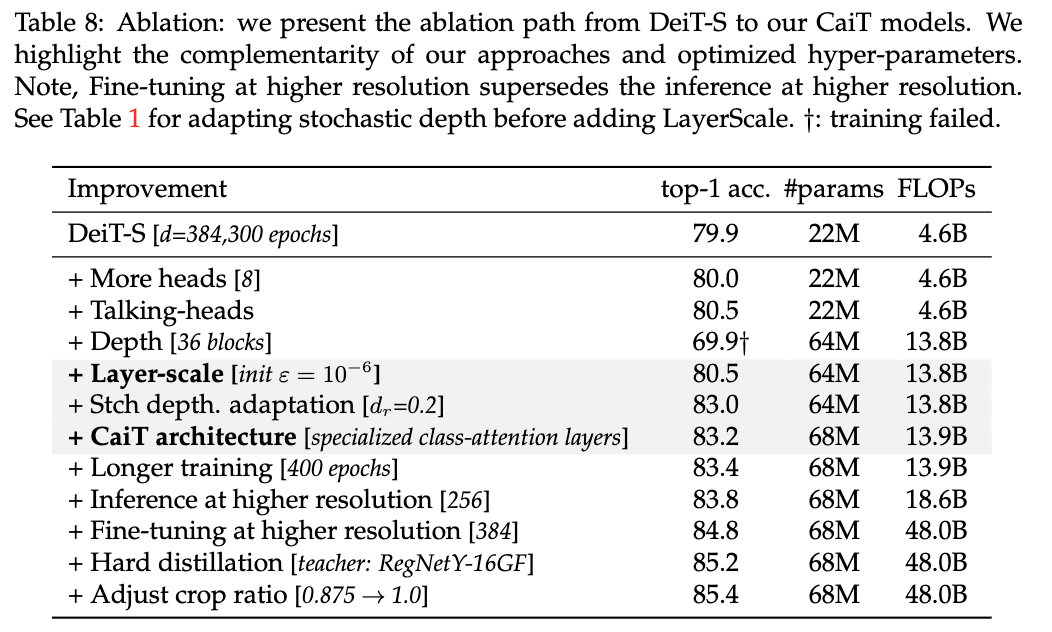
从DeiT过渡到CaiT的性能对比。
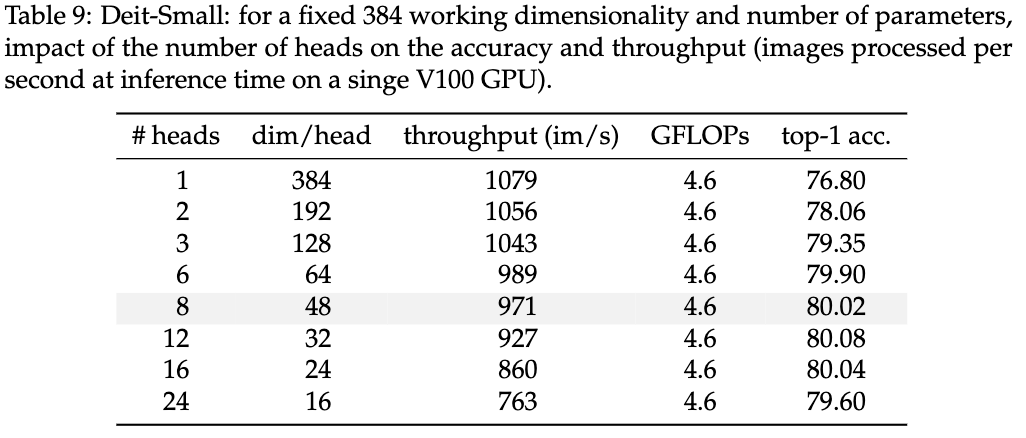
Head数量对性能的影响。
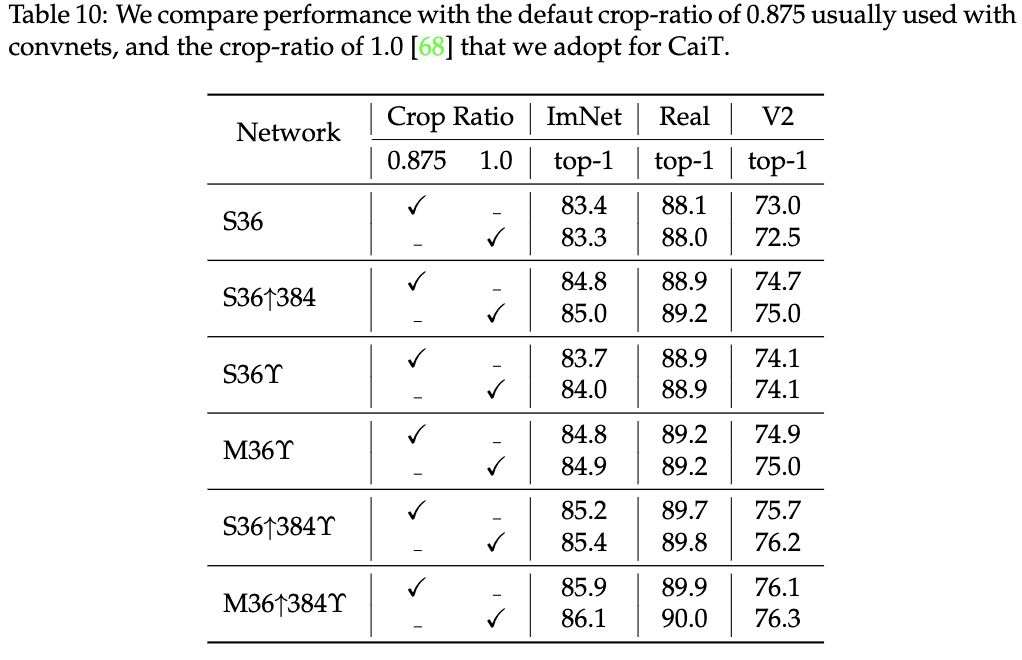
数据增强Crop Ratio对性能的影响。
Conclusion
CaiT通过LayerScale层来保证深度ViT训练的稳定性,加上将特征学习和分类信息提取隔离的class-attention层达到了很不错的性能,值得看看。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】



![[SUCTF 2018]GetShell 1](https://img2024.cnblogs.com/blog/3335050/202407/3335050-20240715134528451-1789385396.png)