本文介绍了SQL Server中Upsert的三种常见写法以及他们的性能比较。
SQL Server并不支持原生的Upsert语句,通常使用组合语句实现upsert功能。
假设有表table_A,各字段如下所示:
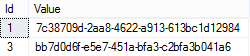
int型Id为主键。
方法1:先查询,根据查询结果判断使用insert或者update
IF EXISTS (SELECT 1 FROM table_A WHERE Id = @Id)BEGINUPDATE dbo.table_ASET Value = @ValueWHERE Id = @Id;END ELSEBEGININSERT INTO dbo.table_A (Id, Value)VALUES(@Id, @Value)END
方法2:先更新,根据更新结果影响的条目数判断是否需要插入
UPDATE dbo.table_A SET Value = @Value WHERE Id = @Id;IF(@@ROWCOUNT = 0) BEGININSERT INTO dbo.table_A (Id, Value)VALUES(@Id, @Value) END
方法3:使用MERGE语句,将待upsert的数据作为source,merge到目标表
MERGE INTO table_A as T USING (SELECT @Id AS id, @Value AS value ) AS S ON T.Id = S.id WHEN MATCHED THENUPDATE SET T.Value = S.value WHEN NOT MATCHED THENINSERT(Id, Value) VALUES(S.id, S.value);
性能比较
在50万行数据项中随机upsert10万次
场景一:upsert数据项100%命中update

场景二:upsert数据项100%命中insert
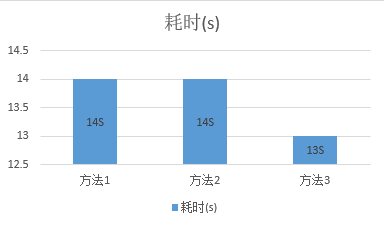
场景三:upsert数据项Id为随机数,~50%insert,~50%update
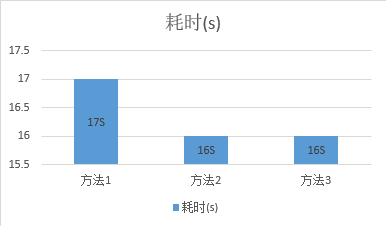
从图中可以看出实验数据存在部分偏差,大体上这三种方法在性能上的差别非常小。对于绝大多数upsert并非关键路径的程序,方法2在可读性和执行性能上综合来讲是较优的方案。
在对性能苛求的场景,可以选用MERGE语句,以下是MERGE语句的优点:”
Faster performance. The Engine needs to parse, compile, and execute only one query instead of three (and no temporary variable to hold the key).
Neater and simpler T-SQL code (after you get proficient in MERGE).
No need for explicit BEGIN TRANSACTION/COMMIT. MERGE is a single statement and is executed in one implicit transaction.
Greater functionality. MERGE can delete rows that are not matched by source (SRC table above). For example, we can delete row 1 from A_Table because its Data column does not match Search_Col in the SRC table. There is also a way to return inserted/deleted values using the OUTPUT clause.“
关于SQL Server的Merge介绍可以查看这里
原文链接
![[考试记录] 2024.7.15 csp-s模拟赛4](https://img2024.cnblogs.com/blog/3358223/202407/3358223-20240715205350281-1423616402.png)