- 赛题来源:Datafountain 个贷违约预测 竞赛 - DataFountain
- 参考优秀选手方法单模走天下:公布一个单模型精度达0.9014(B榜第8)的算法 数据科学社区-DataFountain并加入自己理解整理如下:
赛题理解
题目给出了train_internet.csv、train_public.csv、test_public.csv、submit_example.csv。internet数据为网络上搜集来的数据,数据量很大,有标签,不做预处理直接加入到训练集,反而会影响训练效果。train_public为历史数据集,有标签,较重要,test_public为测试集,无标签,预测其is_default是0/1,按照submit_example.csv格式提交。
数据分析
替换标签名称,统一格式
train_inte.rename(columns={'is_default':'isDefault'},inplace=True)
引入ydata包,进行数据探索
# 生成数据探索报告
from ydata_profiling import ProfileReportprofile_train_data = ProfileReport(train_data, title="Profiling Report train_data")
profile_test_public = ProfileReport(test_public, title="Profiling Report test_public")
profile_train_inte = ProfileReport(train_inte, title="Profiling Report train_inte")
profile_train_data.to_file('./train_dara.html')
profile_test_public.to_file('./test_data.html')
profile_train_inte.to_file('./train_inte.html')
自动生成数据分析可视化html页面
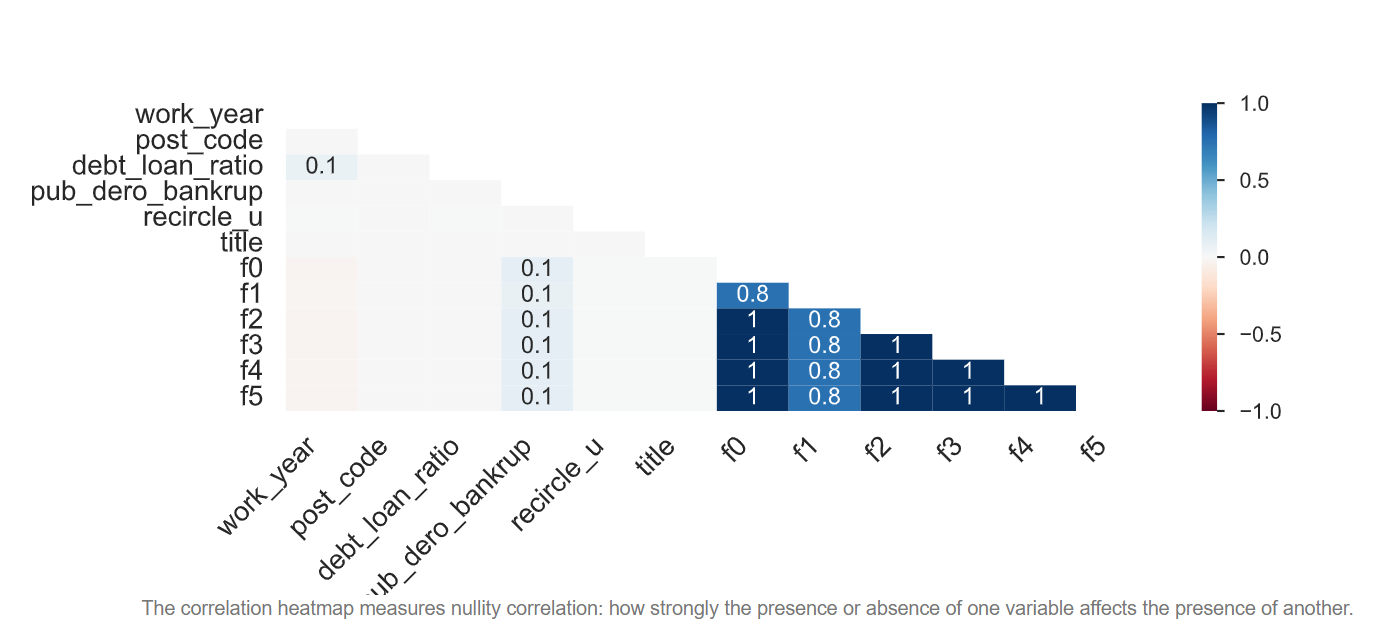
train_inte包含750000个样本,41个个维度特征,1个标签
缺失值热力图如下
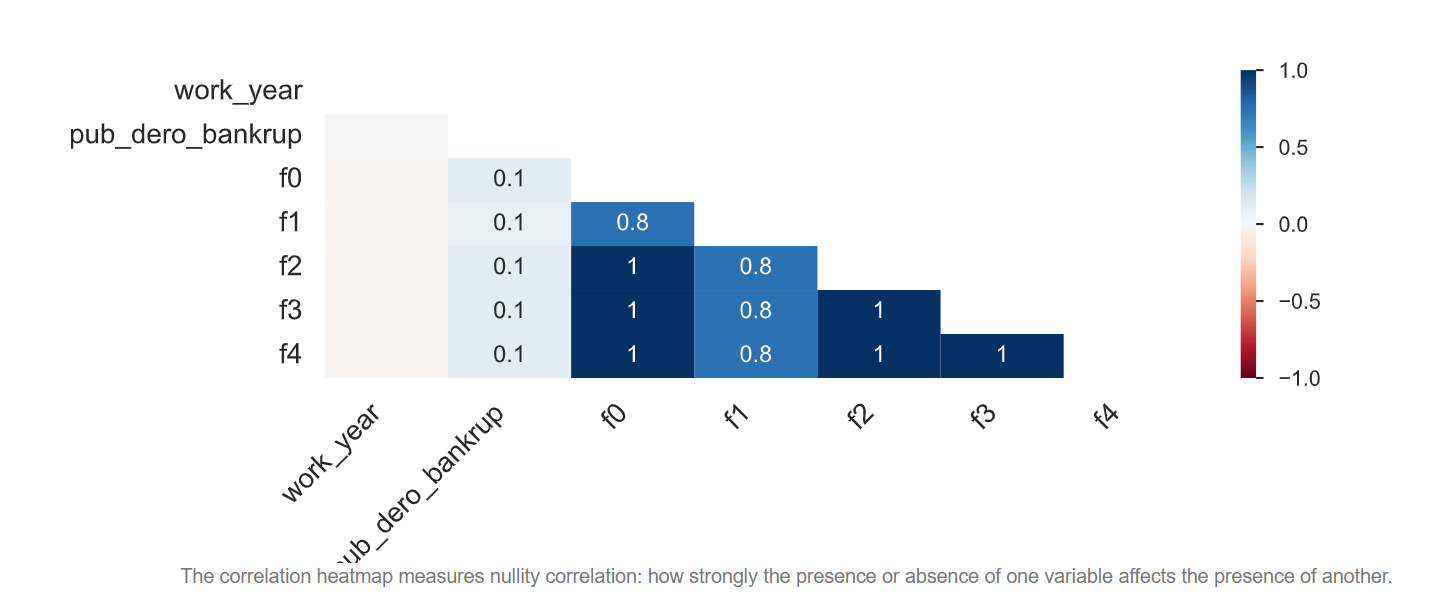
train_public包含10000个样本,38个维度,1个标签
缺失值热力图如下
所有数据中,文本数据包括[work_year,class,work_type,employer_type,industry],date类型包括[earlies_credit_mon,issue_date]
数据预处理
1.对['recircle_u', 'pub_dero_bankrup', 'debt_loan_ratio']和f类数据,均采用均值填充。
由于f类数据的重要性,额外生成5个特征记录f0-f5的均值。至于为什么重要,可以先训练public数据,根据重要性排序得到。
# 缺失值补充
loss_numerical_feas = ['recircle_u', 'pub_dero_bankrup', 'debt_loan_ratio']
f_feas = ['f0', 'f1', 'f2', 'f3', 'f4']train_data[loss_numerical_feas] = train_data[loss_numerical_feas].fillna(train_data[loss_numerical_feas].median())
train_data[f_feas] = train_data[f_feas].fillna(train_data[f_feas].median())
train_data['post_code'] = train_data['post_code'].fillna(train_data['post_code'].mode()[0])
train_data.loc[train_data['debt_loan_ratio'] <= 0, 'debt_loan_ratio'] = 0
for f in f_feas:train_data[f'industry_to_mean_{f}'] = train_data.groupby('industry')[f].transform('mean')test_public[loss_numerical_feas] = test_public[loss_numerical_feas].fillna(test_public[loss_numerical_feas].median())
test_public['post_code'] = test_public['post_code'].fillna(test_public['post_code'].mode()[0])
test_public.loc[test_public['debt_loan_ratio'] <= 0, 'debt_loan_ratio'] = 0
test_public[f_feas] = test_public[f_feas].fillna(test_public[f_feas].median())
for f in f_feas:test_public[f'industry_to_mean_{f}'] = test_public.groupby('industry')[f].transform('mean')train_inte[loss_numerical_feas] = train_inte[loss_numerical_feas].fillna(train_inte[loss_numerical_feas].median())
train_inte['post_code'] = train_inte['post_code'].fillna(train_inte['post_code'].mode()[0])
train_inte['title'] = train_inte['title'].fillna(train_inte['title'].mode()[0])
train_inte.loc[train_inte['debt_loan_ratio'] <= 0, 'debt_loan_ratio'] = 0
train_inte[f_feas] = train_inte[f_feas].fillna(train_inte[f_feas].median())
for f in f_feas:train_inte[f'industry_to_mean_{f}'] = train_inte.groupby('industry')[f].transform('mean')
2.将文本类特征进行转换,并将时间类数据格式转换,提取年、月、周几作为新的特征添加
class_dict = {'A': 1,'B': 2,'C': 3,'D': 4,'E': 5,'F': 6,'G': 7,
}timeMax = pd.to_datetime('1-Dec-21')
train_data['work_year'] = train_data['work_year'].map(workYearDIc)test_public['work_year'] = test_public['work_year'].map(workYearDIc)train_data['class'] = train_data['class'].map(class_dict)
test_public['class'] = test_public['class'].map(class_dict)train_data['earlies_credit_mon'] = pd.to_datetime(train_data['earlies_credit_mon'].map(findDig))
test_public['earlies_credit_mon'] = pd.to_datetime(test_public['earlies_credit_mon'].map(findDig))train_data.loc[train_data['earlies_credit_mon'] > timeMax, 'earlies_credit_mon'] = train_data.loc[train_data['earlies_credit_mon'] > timeMax, 'earlies_credit_mon'] + pd.offsets.DateOffset(years=-100)
test_public.loc[test_public['earlies_credit_mon'] > timeMax, 'earlies_credit_mon'] = test_public.loc[test_public['earlies_credit_mon'] > timeMax, 'earlies_credit_mon'] + pd.offsets.DateOffset(years=-100)
train_data['issue_date'] = pd.to_datetime(train_data['issue_date'])
test_public['issue_date'] = pd.to_datetime(test_public['issue_date'])# Internet数据处理
train_inte['work_year'] = train_inte['work_year'].map(workYearDIc)
train_inte['class'] = train_inte['class'].map(class_dict)train_inte['earlies_credit_mon'] = pd.to_datetime(train_inte['earlies_credit_mon'])
train_inte['issue_date'] = pd.to_datetime(train_inte['issue_date'])train_data['issue_date_month'] = train_data['issue_date'].dt.month
train_data['issue_date_year'] = train_data['issue_date'].dt.year
test_public['issue_date_month'] = test_public['issue_date'].dt.month
test_public['issue_date_year'] = test_public['issue_date'].dt.year
train_data['issue_date_dayofweek'] = train_data['issue_date'].dt.dayofweek
test_public['issue_date_dayofweek'] = test_public['issue_date'].dt.dayofweektrain_data['earliesCreditMon'] = train_data['earlies_credit_mon'].dt.month
test_public['earliesCreditMon'] = test_public['earlies_credit_mon'].dt.month
train_data['earliesCreditYear'] = train_data['earlies_credit_mon'].dt.year
test_public['earliesCreditYear'] = test_public['earlies_credit_mon'].dt.yeartrain_inte['issue_date_month'] = train_inte['issue_date'].dt.month
train_inte['issue_date_dayofweek'] = train_inte['issue_date'].dt.dayofweek
train_inte['issue_date_year'] = train_inte['issue_date'].dt.yeartrain_inte['earliesCreditMon'] = train_inte['earlies_credit_mon'].dt.month
train_inte['earliesCreditYear'] = train_inte['earlies_credit_mon'].dt.year
3.对['employer_type', 'industry']数据进行label编码,并舍弃掉第二步已经提取的特征['issue_date', 'earlies_credit_mon']
cat_cols = ['employer_type', 'industry']
from sklearn.preprocessing import LabelEncoder, OneHotEncoderfor col in cat_cols:lbl = LabelEncoder().fit(train_data[col])train_data[col] = lbl.transform(train_data[col])test_public[col] = lbl.transform(test_public[col])train_inte[col] = lbl.transform(train_inte[col])col_to_drop = ['issue_date', 'earlies_credit_mon']
train_data = train_data.drop(col_to_drop, axis=1)
test_public = test_public.drop(col_to_drop, axis=1)
train_inte = train_inte.drop(col_to_drop, axis=1)
4.根据历史经验+查阅相关贷款论文发现,class的再一步细分sub_class,作为一个特征对贷款预测问题有很好的表现,所以对train_inte中class数据进行再一步的细分,目前class有7类分别为ABCDEFG,再将其细分为A1A2A3A4A5....,使用K-means方法。构建好特征后可查看特征重要性,反证明其重要性。K-means聚类方法如下:
def feature_Kmeans(data, label):mms = MinMaxScaler()feats = [f for f in data.columns if f not in ['loan_id', 'user_id', 'isDefault']]data = data[feats]mmsModel = mms.fit_transform(data.loc[data['class'] == label])clf = KMeans(5, random_state=2021)pre = clf.fit(mmsModel)test = pre.labels_final_data = pd.Series(test, index=data.loc[data['class'] == label].index)if label == 1:final_data = final_data.map({0: 'A1', 1: 'A2', 2: 'A3', 3: 'A4', 4: 'A5'})elif label == 2:final_data = final_data.map({0: 'B1', 1: 'B2', 2: 'B3', 3: 'B4', 4: 'B5'})elif label == 3:final_data = final_data.map({0: 'C1', 1: 'C2', 2: 'C3', 3: 'C4', 4: 'C5'})elif label == 4:final_data = final_data.map({0: 'D1', 1: 'D2', 2: 'D3', 3: 'D4', 4: 'D5'})elif label == 5:final_data = final_data.map({0: 'E1', 1: 'E2', 2: 'E3', 3: 'E4', 4: 'E5'})elif label == 6:final_data = final_data.map({0: 'F1', 1: 'F2', 2: 'F3', 3: 'F4', 4: 'F5'})elif label == 7:final_data = final_data.map({0: 'G1', 1: 'G2', 2: 'G3', 3: 'G4', 4: 'G5'})return final_data
聚类后对sub_class进行编码
cat_cols = ['sub_class']
for col in cat_cols:lbl = LabelEncoder().fit(train_data[col])train_data[col] = lbl.transform(train_data[col])test_public[col] = lbl.transform(test_public[col])train_inte[col] = lbl.transform(train_inte[col])
5.通过历史经验和不断尝试,增加新特征并对其进行编码
#######尝试新的特征######################
train_data['post_code_interst_mean'] = train_data.groupby(['post_code'])['interest'].transform('mean')
train_inte['post_code_interst_mean'] = train_inte.groupby(['post_code'])['interest'].transform('mean')
test_public['post_code_interst_mean'] = test_public.groupby(['post_code'])['interest'].transform('mean')train_data['industry_mean_interest'] = train_data.groupby(['industry'])['interest'].transform('mean')
train_inte['industry_mean_interest'] = train_inte.groupby(['industry'])['interest'].transform('mean')
test_public['industry_mean_interest'] = test_public.groupby(['industry'])['interest'].transform('mean')train_data['recircle_u_b_std'] = train_data.groupby(['recircle_u'])['recircle_b'].transform('std')
test_public['recircle_u_b_std'] = test_public.groupby(['recircle_u'])['recircle_b'].transform('std')
train_inte['recircle_u_b_std'] = train_inte.groupby(['recircle_u'])['recircle_b'].transform('std')
train_data['early_return_amount_early_return'] = train_data['early_return_amount'] / train_data['early_return']
test_public['early_return_amount_early_return'] = test_public['early_return_amount'] / test_public['early_return']
train_inte['early_return_amount_early_return'] = train_inte['early_return_amount'] / train_inte['early_return']
# 可能出现极大值和空值
train_data['early_return_amount_early_return'][np.isinf(train_data['early_return_amount_early_return'])] = 0
test_public['early_return_amount_early_return'][np.isinf(test_public['early_return_amount_early_return'])] = 0
train_inte['early_return_amount_early_return'][np.isinf(train_inte['early_return_amount_early_return'])] = 0
# 还款利息
train_data['total_loan_monthly_payment'] = train_data['monthly_payment'] * train_data['year_of_loan'] * 12 - train_data['total_loan']
test_public['total_loan_monthly_payment'] = test_public['monthly_payment'] * test_public['year_of_loan'] * 12 - \test_public['total_loan']
train_inte['total_loan_monthly_payment'] = train_inte['monthly_payment'] * train_inte['year_of_loan'] * 12 - train_inte['total_loan']#########################################################
# 目标编码
def gen_target_encoding_feats(train, train_inte, test, encode_cols, target_col, n_fold=10):'''生成target encoding特征'''# for training set - cvtg_feats = np.zeros((train.shape[0], len(encode_cols)))kfold = StratifiedKFold(n_splits=n_fold, random_state=1024, shuffle=True)for _, (train_index, val_index) in enumerate(kfold.split(train[encode_cols], train[target_col])):df_train, df_val = train.iloc[train_index], train.iloc[val_index]for idx, col in enumerate(encode_cols):target_mean_dict = df_train.groupby(col)[target_col].mean()df_val[f'{col}_mean_target'] = df_val[col].map(target_mean_dict)tg_feats[val_index, idx] = df_val[f'{col}_mean_target'].valuesfor idx, encode_col in enumerate(encode_cols):train[f'{encode_col}_mean_target'] = tg_feats[:, idx]# for train_inte set - cvtg_feats = np.zeros((train_inte.shape[0], len(encode_cols)))kfold = StratifiedKFold(n_splits=n_fold, random_state=1024, shuffle=True)for _, (train_index, val_index) in enumerate(kfold.split(train_inte[encode_cols], train_inte[target_col])):df_train, df_val = train_inte.iloc[train_index], train_inte.iloc[val_index]for idx, col in enumerate(encode_cols):target_mean_dict = df_train.groupby(col)[target_col].mean()df_val[f'{col}_mean_target'] = df_val[col].map(target_mean_dict)tg_feats[val_index, idx] = df_val[f'{col}_mean_target'].valuesfor idx, encode_col in enumerate(encode_cols):train_inte[f'{encode_col}_mean_target'] = tg_feats[:, idx]# for testing setfor col in encode_cols:target_mean_dict = train.groupby(col)[target_col].mean()test[f'{col}_mean_target'] = test[col].map(target_mean_dict)return train, train_inte, testfeatures = ['house_exist', 'debt_loan_ratio', 'industry', 'title']
train_data, train_inte, test_public = gen_target_encoding_feats(train_data, train_inte, test_public, features,'isDefault', n_fold=10)
6.尝试将train_inte中比较稳的样本,拿到训练样本中。以public为训练集、internet表作为测试集,对internet表进行预测。如果预测为0的阈值小于0.05,则认为该数据比较稳,作为训练数据。这个阈值可以根据实际情况调整,希望在阈值尽量低的情况下筛选出尽量多的数据。
对internet表进行预测可以选择LGB/catBoost模型,其可以有效解决数据不平衡时的过拟合问题,适合本数据集的特点。
########################样本扩充
def fiterDataModel(data_, test_, y_, folds_):oof_preds = np.zeros(data_.shape[0])sub_preds = np.zeros(test_.shape[0])feats = [f for f in data_.columns if f not in ['loan_id', 'user_id', 'isDefault']]for n_fold, (trn_idx, val_idx) in enumerate(folds_.split(data_)):trn_x, trn_y = data_[feats].iloc[trn_idx], y_.iloc[trn_idx]val_x, val_y = data_[feats].iloc[val_idx], y_.iloc[val_idx]clf = LGBMClassifier(n_estimators=4000,# learning_rate=0.08,learning_rate=0.06,num_leaves=2 ** 5,colsample_bytree=.65,subsample=.9,max_depth=5,reg_alpha=.3,reg_lambda=.3,min_split_gain=.01,min_child_weight=2,silent=-1,verbose=-1,)clf.fit(trn_x, trn_y,eval_set=[(trn_x, trn_y.astype(int)), (val_x, val_y.astype(int))],eval_metric='auc', verbose=100, early_stopping_rounds=100 # 40)oof_preds[val_idx] = clf.predict_proba(val_x, num_iteration=clf.best_iteration_)[:, 1]sub_preds += clf.predict_proba(test_[feats], num_iteration=clf.best_iteration_)[:, 1] / folds_.n_splitsprint('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(val_y, oof_preds[val_idx])))del clf, trn_x, trn_y, val_x, val_ygc.collect()print('Full AUC score %.6f' % roc_auc_score(y_, oof_preds))test_['isDefault'] = sub_predsreturn test_[['loan_id', 'isDefault']]tr_cols = set(train_data.columns)
same_col = list(tr_cols.intersection(set(train_inte.columns)))
train_inteSame = train_inte[same_col].copy()
Inte_add_cos = list(tr_cols.difference(set(same_col)))
for col in Inte_add_cos:train_inteSame[col] = np.nan
y = train_data['isDefault']
folds = KFold(n_splits=5, shuffle=True, random_state=546789)
IntePre = fiterDataModel(train_data, train_inteSame, y, folds)
IntePre['isDef'] = train_inte['isDefault']
print(roc_auc_score(IntePre['isDef'], IntePre.isDefault))
## 选择阈值0.05,从internet表中提取预测小于该概率的样本,并对不同来源的样本赋予来源值
InteId = IntePre.loc[IntePre.isDefault < 0.05, 'loan_id'].tolist()
train_inteSame['isDefault'] = train_inte['isDefault']
use_te = train_inteSame[train_inteSame.loan_id.isin(InteId)].copy()
data = pd.concat([train_data, test_public, use_te]).reset_index(drop=True)
模型训练
最终将train_public和部分train_internet数据作为训练集,test_public作为测试集,采用LGB模型进行训练,并保存至csv文件。
def LGBModel(data_, test_, y_, folds_):oof_preds = np.zeros(data_.shape[0])sub_preds = np.zeros(test_.shape[0])feats = [f for f in data_.columns if f not in ['loan_id', 'user_id', 'isDefault']]for n_fold, (trn_idx, val_idx) in enumerate(folds_.split(data_)):trn_x, trn_y = data_[feats].iloc[trn_idx], y_.iloc[trn_idx]val_x, val_y = data_[feats].iloc[val_idx], y_.iloc[val_idx]clf = LGBMClassifier(n_estimators=4000,# learning_rate=0.08,learning_rate=0.06,num_leaves=2 ** 5,colsample_bytree=.65,subsample=.9,max_depth=5,reg_alpha=.3,reg_lambda=.3,min_split_gain=.01,min_child_weight=2,silent=-1,verbose=-1,# n_jobs=1,)clf.fit(trn_x, trn_y,eval_set=[(trn_x, trn_y.astype(int)), (val_x, val_y.astype(int))],eval_metric='auc', verbose=100, early_stopping_rounds=100, # 40)oof_preds[val_idx] = clf.predict_proba(val_x, num_iteration=clf.best_iteration_)[:, 1]sub_preds += clf.predict_proba(test_[feats], num_iteration=clf.best_iteration_)[:, 1] / folds_.n_splitsprint('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(val_y, oof_preds[val_idx])))del clf, trn_x, trn_y, val_x, val_ygc.collect()print('Full AUC score %.6f' % roc_auc_score(y_, oof_preds))test_['isDefault'] = sub_predsreturn test_[['loan_id', 'isDefault']]train = data[data['isDefault'].notna()]
test = data[data['isDefault'].isna()]
y = train['isDefault']
folds = KFold(n_splits=5, shuffle=True, random_state=546789)
test_preds = LGBModel(train, test, y, folds)
test_preds.rename({'loan_id': 'id'}, axis=1)[['id', 'isDefault']].to_csv('optimize.csv', index=None)
最终得分
最终得分为0.89,再通过网格搜索等优化方法可以进一步提高准确率,本文略。



![[转载]SVN系列之—-SVN版本回滚的办法](https://images2018.cnblogs.com/blog/682223/201807/682223-20180724152202179-1064512451.png)