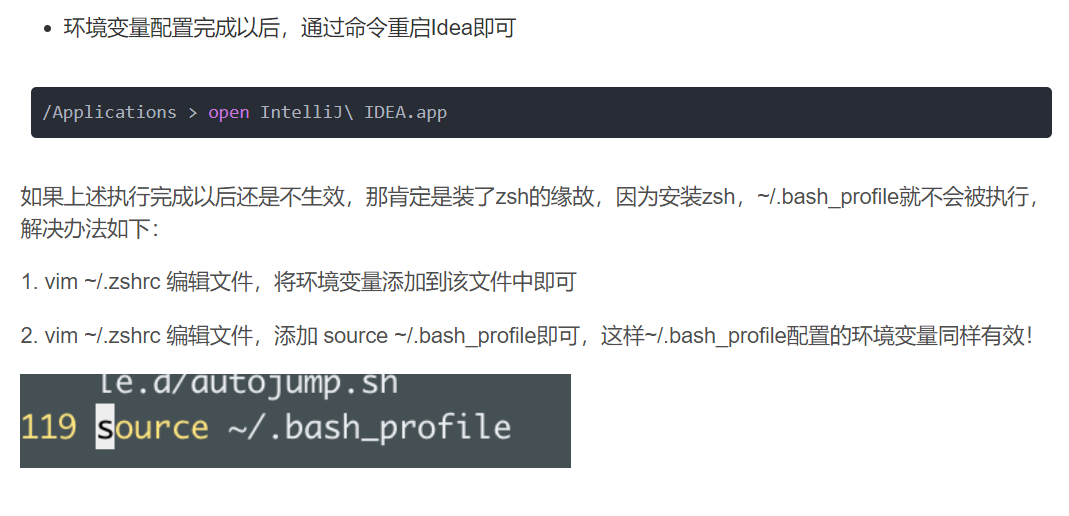
集合进阶
集合容器中只能存放对象,基本数据类型需要使用对应的包装类
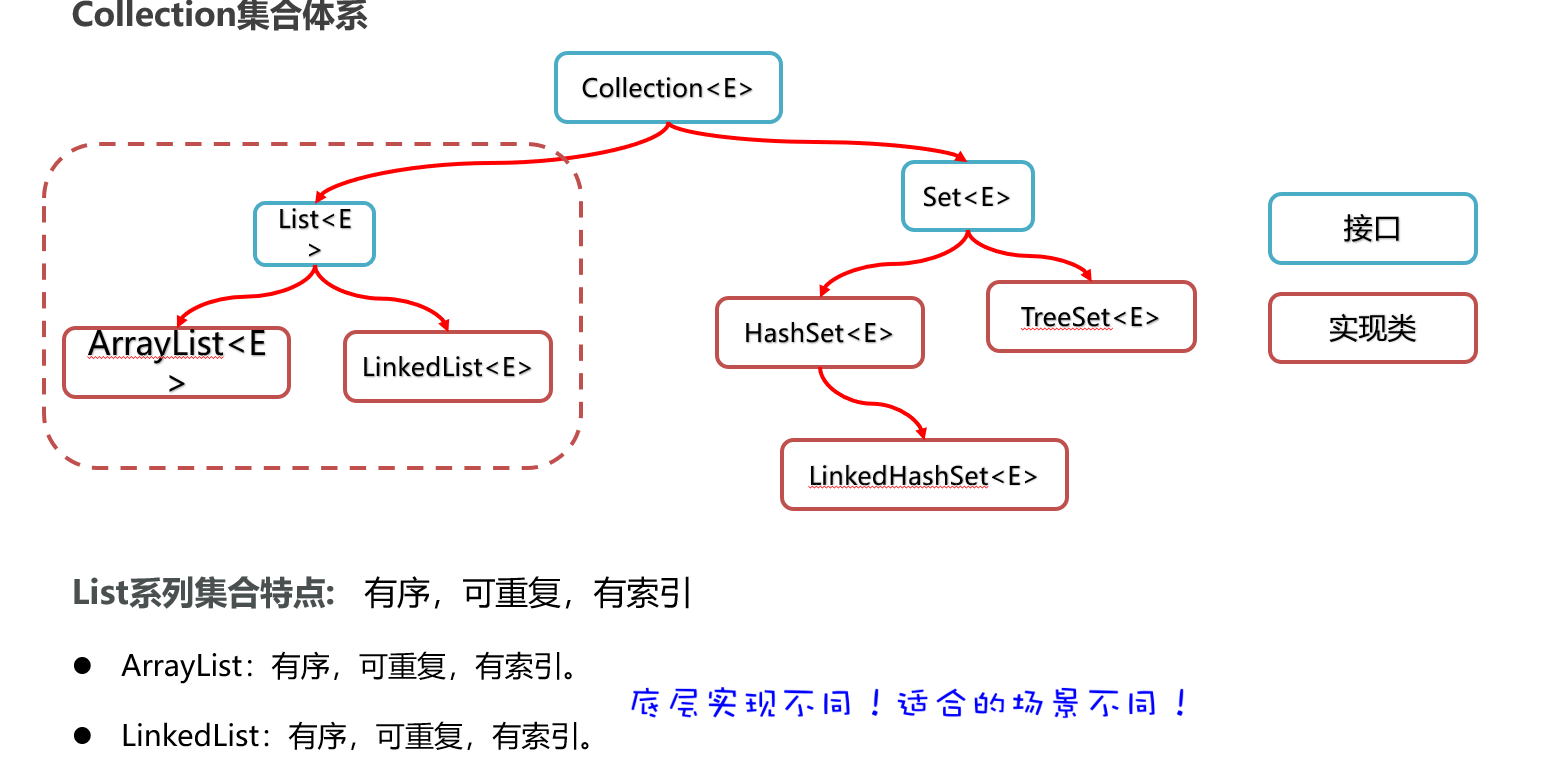
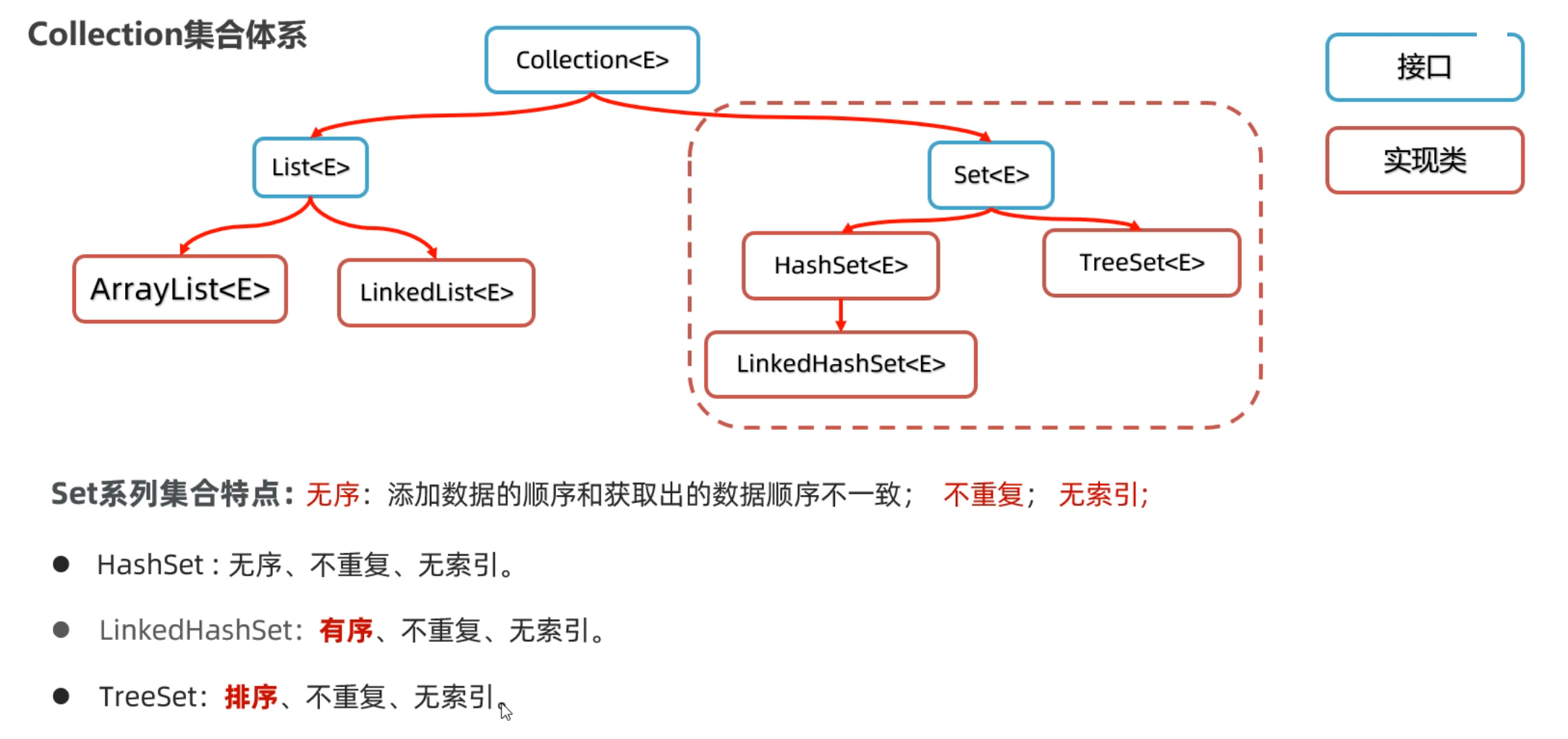
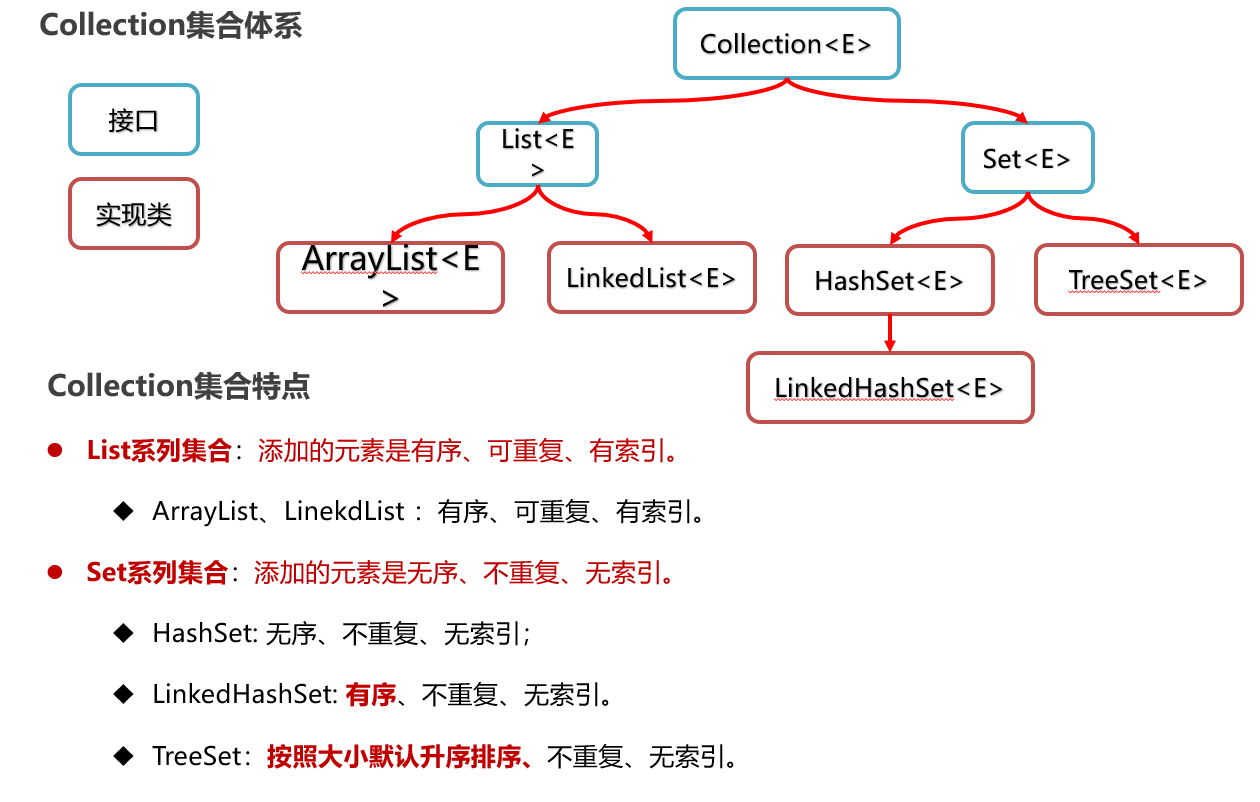
Collection单列集合
collection集合体系 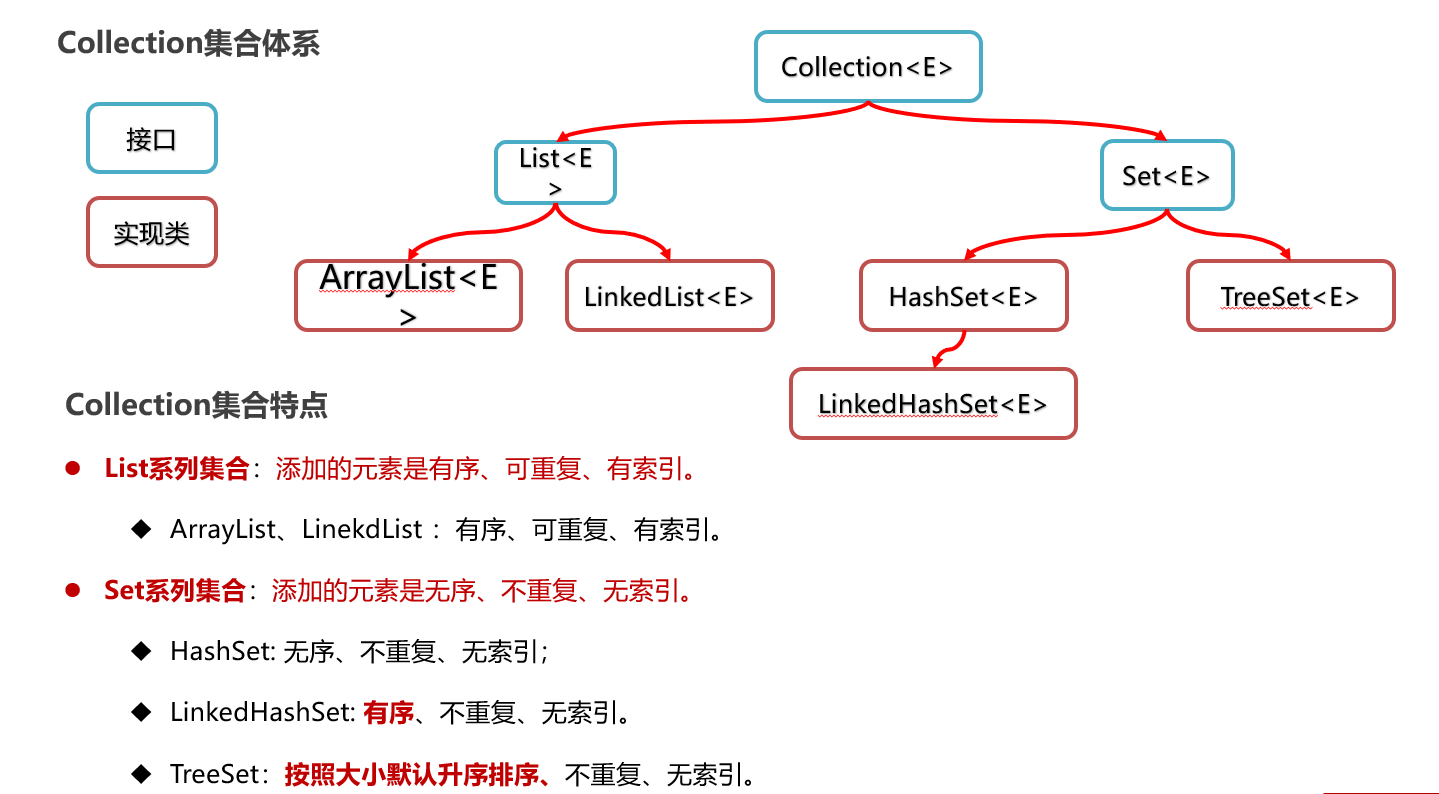
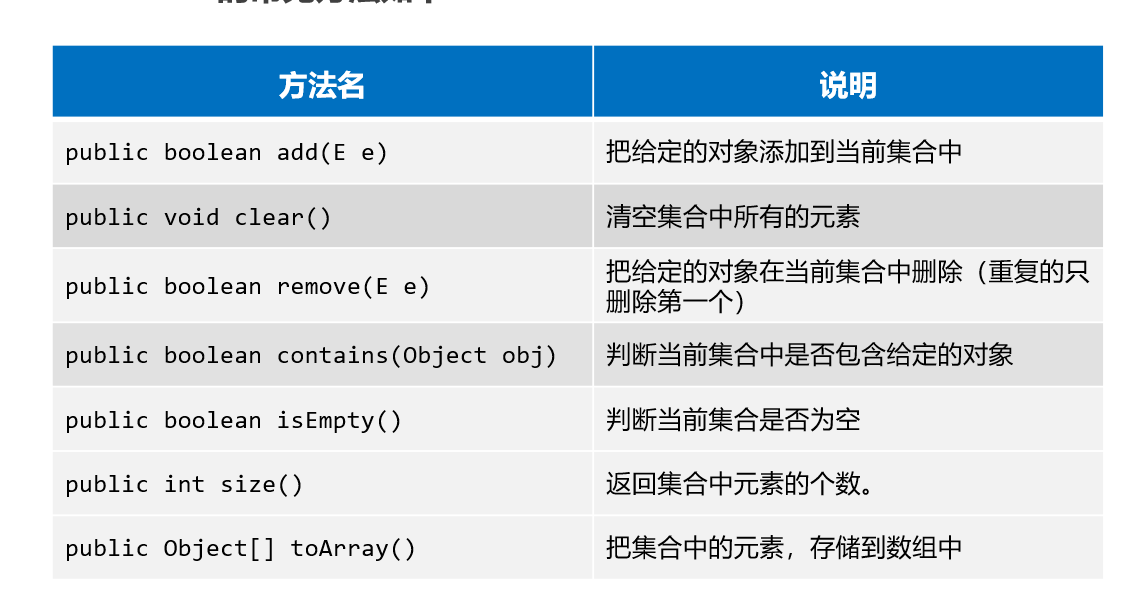
collection常用方法
package com.itheima.d1_collection;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.function.IntFunction;/**目标:掌握Collection集合的常用API.Collection是集合的祖宗类,它的功能是全部集合都可以继承使用的,所以要学习它。Collection API如下:- public boolean add(E e): 把给定的对象添加到当前集合中 。- public void clear() :清空集合中所有的元素。- public boolean remove(E e): 把给定的对象在当前集合中删除。- public boolean contains(Object obj): 判断当前集合中是否包含给定的对象。- public boolean isEmpty(): 判断当前集合是否为空。- public int size(): 返回集合中元素的个数。- public Object[] toArray(): 把集合中的元素,存储到数组中。*/
public class CollectionTest2API {public static void main(String[] args) {Collection<String> c = new ArrayList<>(); // 多态写法// 1.public boolean add(E e):添加元素, 添加成功返回true。c.add("java1");c.add("java1");c.add("java2");c.add("java2");c.add("java3");System.out.println(c);// 2.public void clear():清空集合的元素。//c.clear();//System.out.println(c);// 3.public boolean isEmpty():判断集合是否为空 是空返回true,反之。System.out.println(c.isEmpty()); // false// 4.public int size():获取集合的大小。System.out.println(c.size());// 5.public boolean contains(Object obj):判断集合中是否包含某个元素。System.out.println(c.contains("java1")); // trueSystem.out.println(c.contains("Java1")); // false// 6.public boolean remove(E e):删除某个元素:如果有多个重复元素默认删除前面的第一个!System.out.println(c.remove("java1"));System.out.println(c);// 7.public Object[] toArray():把集合转换成数组Object[] arr = c.toArray();System.out.println(Arrays.toString(arr));String[] arr2 = c.toArray(new String[c.size()]);System.out.println(Arrays.toString(arr2));System.out.println("--------------------------------------------");// 把一个集合的全部数据倒入到另一个集合中去。Collection<String> c1 = new ArrayList<>();c1.add("java1");c1.add("java2");Collection<String> c2 = new ArrayList<>();c2.add("java3");c2.add("java4");c1.addAll(c2); // 就是把c2集合的全部数据倒入到c1集合中去。System.out.println(c1);System.out.println(c2);}
}迭代器遍历集合

接下来学习的迭代器就是一种集合的通用遍历方式。
代码写法如下:
Collection<String> c = new ArrayList<>();
c.add("赵敏");
c.add("小昭");
c.add("素素");
c.add("灭绝");
System.out.println(c); //[赵敏, 小昭, 素素, 灭绝]//第一步:先获取迭代器对象
//解释:Iterator就是迭代器对象,用于遍历集合的工具)
Iterator<String> it = c.iterator();//第二步:用于判断当前位置是否有元素可以获取
//解释:hasNext()方法返回true,说明有元素可以获取;反之没有
while(it.hasNext()){//第三步:获取当前位置的元素,然后自动指向下一个元素.String e = it.next();System.out.println(s);
}
迭代器代码的原理如下:
- 当调用iterator()方法获取迭代器时,当前指向第一个元素
- hasNext()方法则判断这个位置是否有元素,如果有则返回true,进入循环
- 调用next()方法获取元素,然后自动指向下一个位置
- 等下次循环时,则获取下一个元素,依此内推
增强for循环遍历集合
增强for不光可以遍历集合,还可以遍历数组。接下来我们用代码演示一下:
Collection<String> c = new ArrayList<>();
c.add("赵敏");
c.add("小昭");
c.add("素素");
c.add("灭绝");//1.使用增强for遍历集合
for(String s: c){System.out.println(s);
}//2.再尝试使用增强for遍历数组
String[] arr = {"迪丽热巴", "古力娜扎", "稀奇哈哈"};
for(String name: arr){System.out.println(name);
}
lambda表达式遍历集合
集合的foreach方法结合lambda表达式遍历结合
c.forEach(new Consumer<String>() {@Overridepublic void accept(String s) {System.out.println(s);}
由于Consumer是接口,无法实例化对象,所以可以使用匿名内部类,
由于consumer是函数式接口,所以可以使用lambda表达式来简化
package com.itheima.d2_collection_traverse;
import java.util.ArrayList;
import java.util.Collection;/**目标:Collection集合的遍历方式三:JDK8开始新增的Lambda表达式。*/
public class CollectionDemo03 {public static void main(String[] args) {Collection<String> c = new ArrayList<>();c.add("赵敏");c.add("小昭");c.add("殷素素");c.add("周芷若");System.out.println(c);// [赵敏, 小昭, 殷素素, 周芷若]// s// default void forEach(Consumer<? super T> action): 结合Lambda表达式遍历集合:// c.forEach(new Consumer<String>() {// @Override// public void accept(String s) {// System.out.println(s);// }// });//// c.forEach((String s) -> {// System.out.println(s);// });//// c.forEach(s -> {// System.out.println(s);// });//// c.forEach(s -> System.out.println(s) );c.forEach(System.out::println );}
}
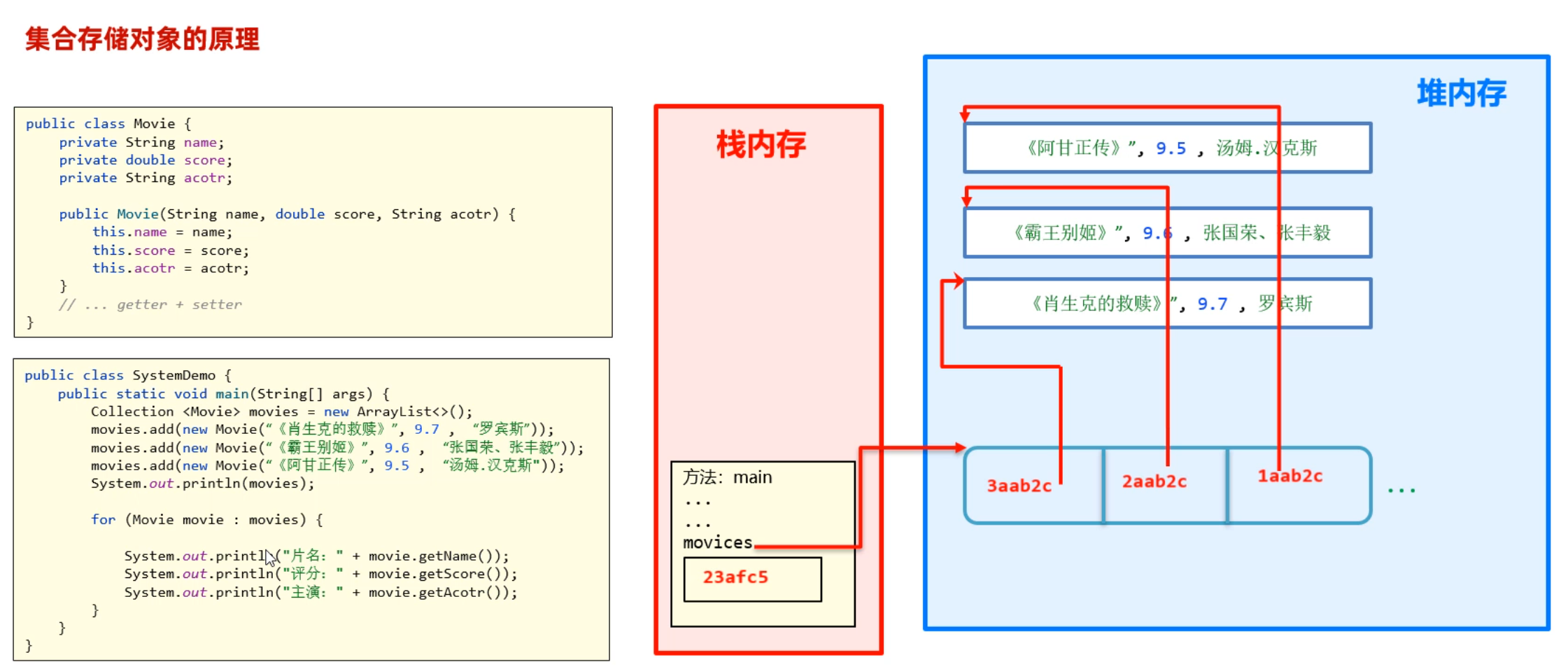
集合在计算机中的存储原理
当往集合中存对象时,实际上存储的是对象的地址值
List集合
List集合的特有方法
//1.创建一个ArrayList集合对象(有序、有索引、可以重复)
List<String> list = new ArrayList<>();
list.add("蜘蛛精");
list.add("至尊宝");
list.add("至尊宝");
list.add("牛夫人");
System.out.println(list); //[蜘蛛精, 至尊宝, 至尊宝, 牛夫人]//2.public void add(int index, E element): 在某个索引位置插入元素
list.add(2, "紫霞仙子");
System.out.println(list); //[蜘蛛精, 至尊宝, 紫霞仙子, 至尊宝, 牛夫人]//3.public E remove(int index): 根据索引删除元素, 返回被删除的元素
System.out.println(list.remove(2)); //紫霞仙子
System.out.println(list);//[蜘蛛精, 至尊宝, 至尊宝, 牛夫人]//4.public E get(int index): 返回集合中指定位置的元素
System.out.println(list.get(3));//5.public E set(int index, E e): 修改索引位置处的元素,修改后,会返回原数据
System.out.println(list.set(3,"牛魔王")); //牛夫人
System.out.println(list); //[蜘蛛精, 至尊宝, 至尊宝, 牛魔王]
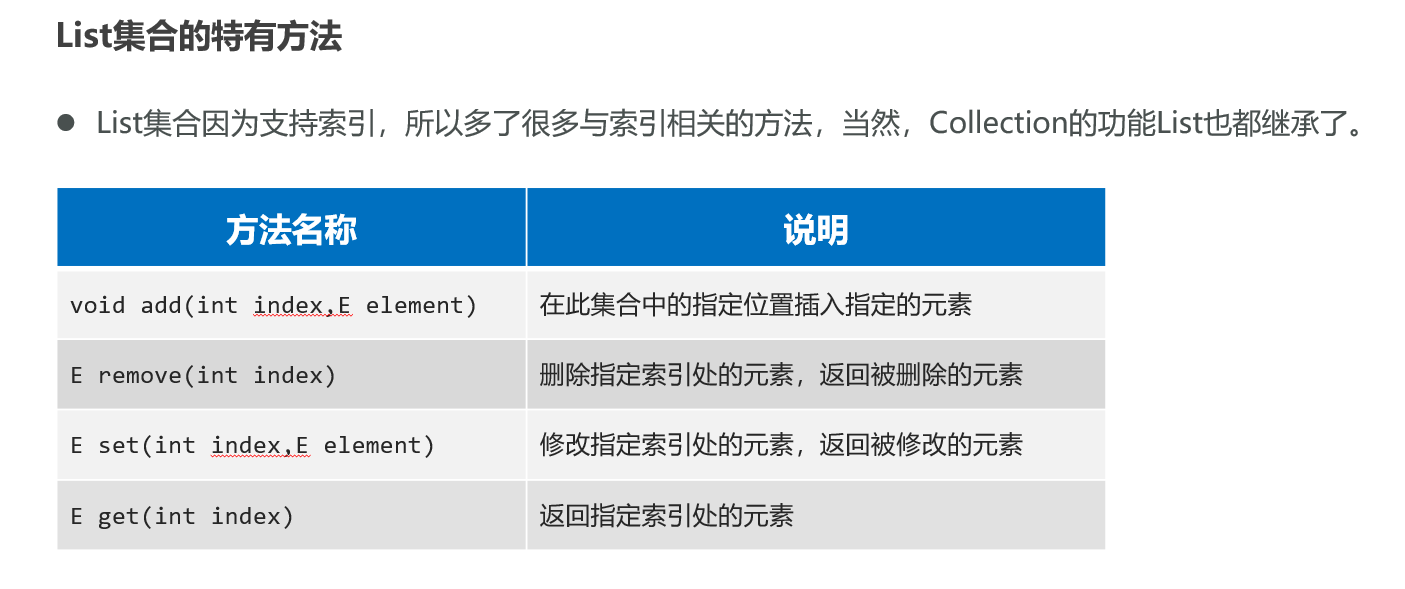
list集合的遍历方式
- 普通for循环(只因为List有索引)
- 迭代器
- 增强for
- Lambda表达式
package com.itheima.d3_collection_list;import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;/**拓展:List系列集合的遍历方式.List遍历方式:(1)for循环。(独有的,因为List有索引)。(2)迭代器。(3)foreach。(4)JDK 1.8新技术。*/
public class ListTest2 {public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("糖宝宝");list.add("蜘蛛精");list.add("至尊宝");//(1)for循环for (int i = 0; i < list.size(); i++) {// i = 0 1 2String s = list.get(i);System.out.println(s);}//(2)迭代器。Iterator<String> it = list.iterator();while (it.hasNext()) {System.out.println(it.next());}//(3)增强for循环(foreach遍历)for (String s : list) {System.out.println(s);}//(4)JDK 1.8开始之后的Lambda表达式list.forEach(s -> {System.out.println(s);});}
}
ArrayList集合
ArrayList集合的底层原理
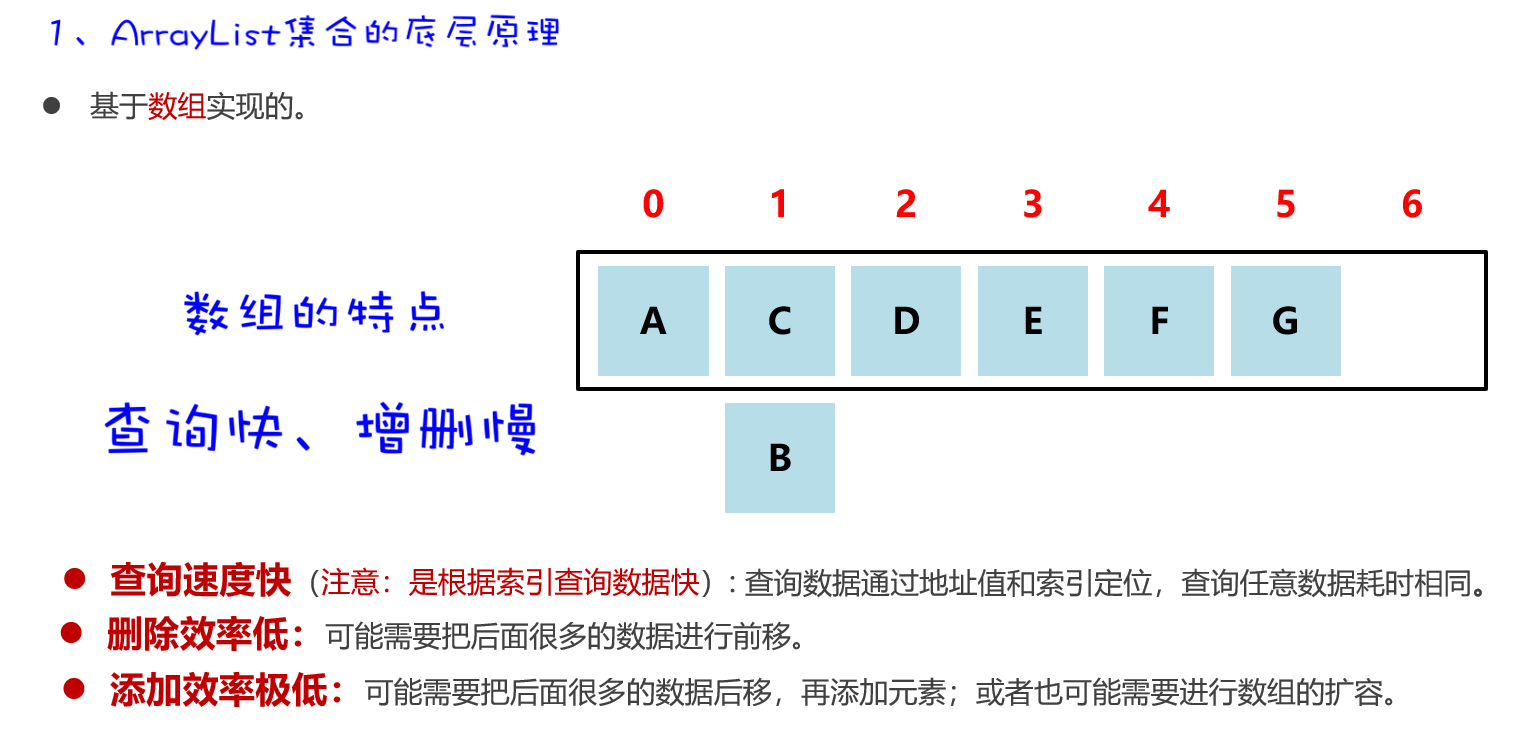
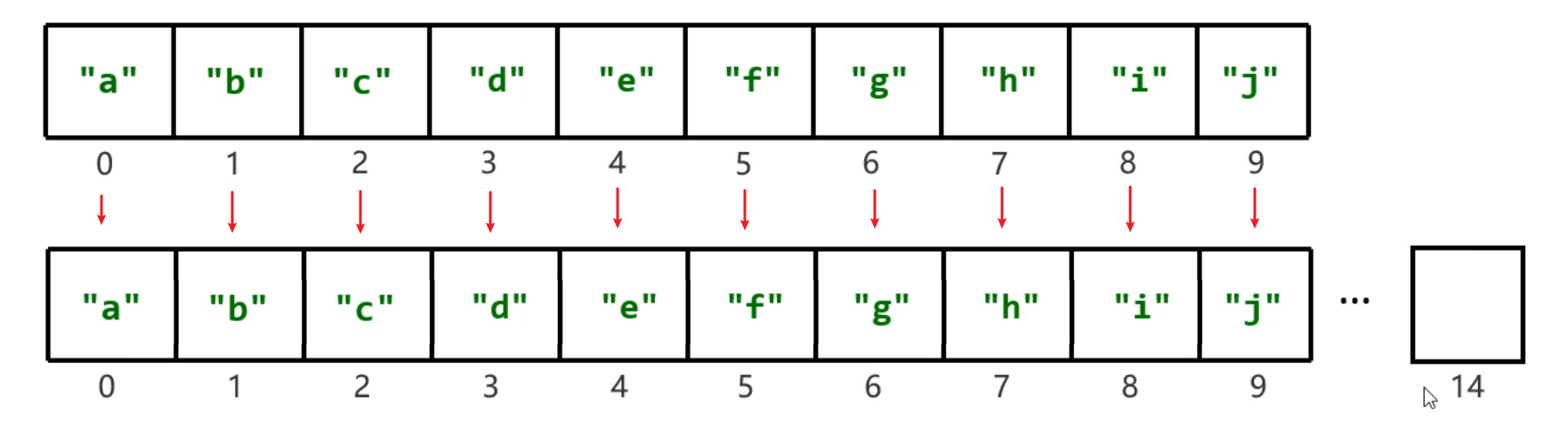
数组的长度是固定的,但是集合的长度是可变的,这是怎么做到的呢?原理如下:

数组扩容,并不是在原数组上扩容(原数组是不可以扩容的),底层是创建一个新数组,然后把原数组中的元素全部复制到新数组中去。
ArrayList的使用场景 
LinkedList集合
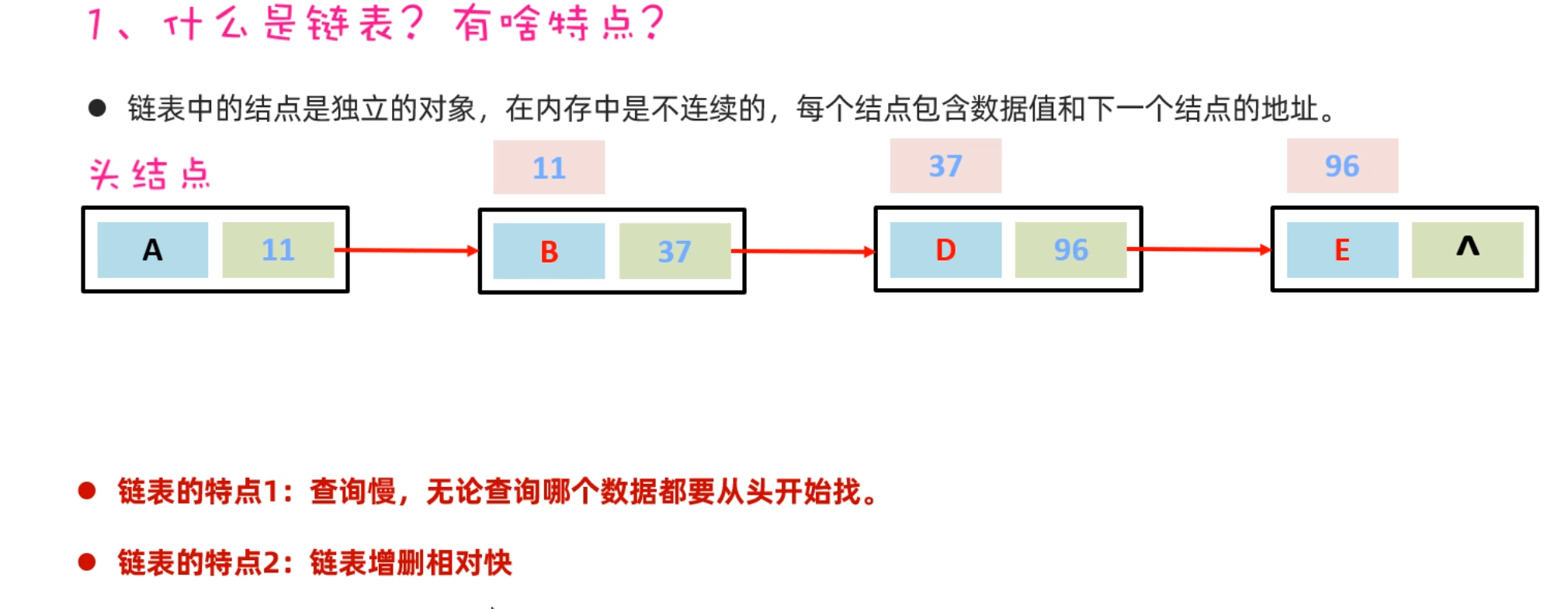
LinkedList集合介绍
LinkedList底层是链表结构,链表结构是由一个一个的节点组成,一个节点由数据值、下一个元素的地址组成。如下图所示
假如,现在要在B节点和D节点中间插入一个元素,只需要把B节点指向D节点的地址断掉,重新指向新的节点地址就可以了。如下图所示:
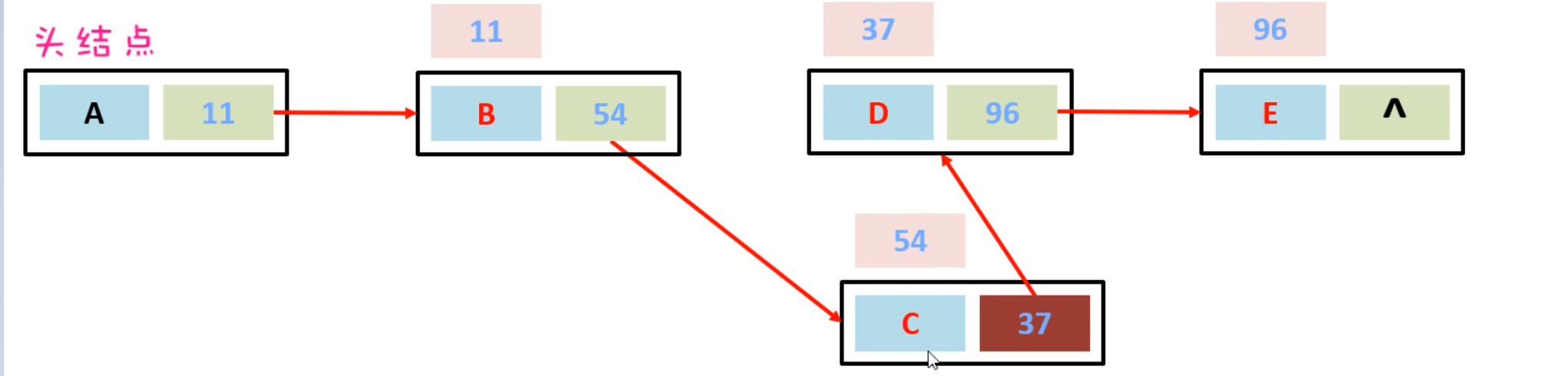
假如,现在想要把D节点删除,只需要让C节点指向E节点的地址,然后把D节点指向E节点的地址断掉。此时D节点就会变成垃圾,会把垃圾回收器清理掉。
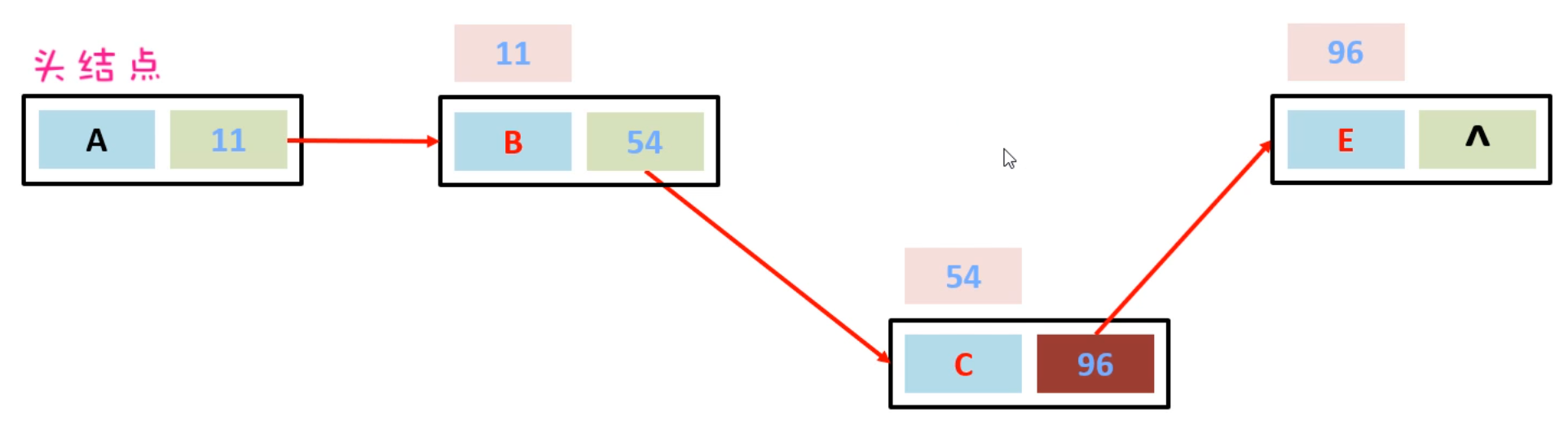
上面的链表是单向链表,它的方向是从头节点指向尾节点的,只能从左往右查找元素,这样查询效率比较慢;还有一种链表叫做双向链表,不光可以从做往右找,还可以从右往左找。如下图所示:
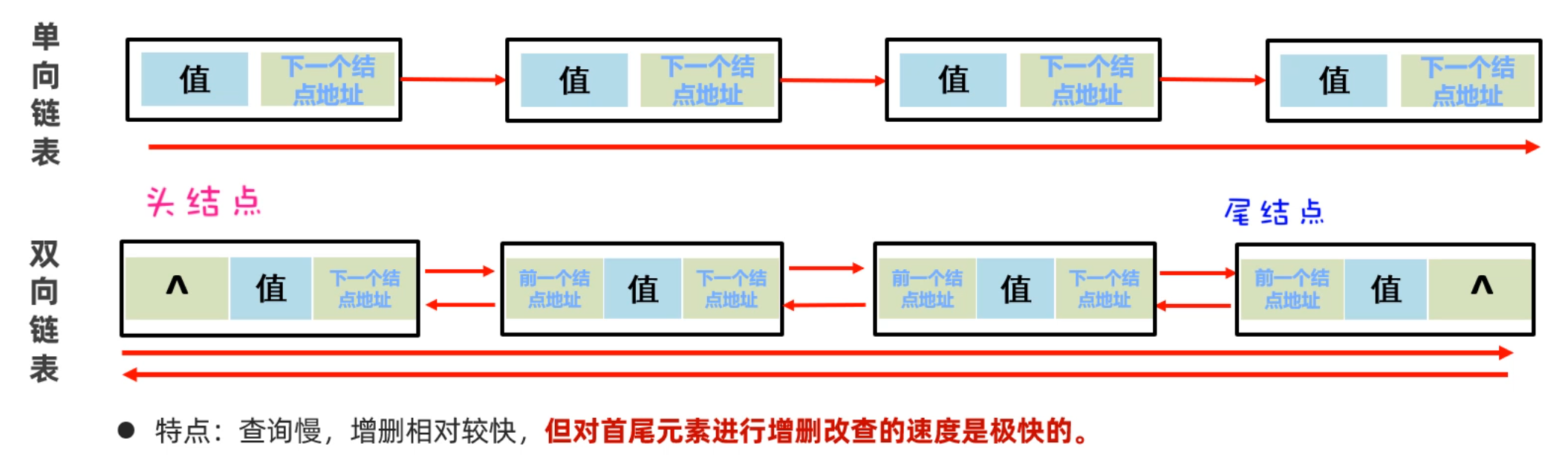
LinkedList集合是基于双向链表实现了,所以相对于ArrayList新增了一些可以针对头尾进行操作的方法,如下图示所示:
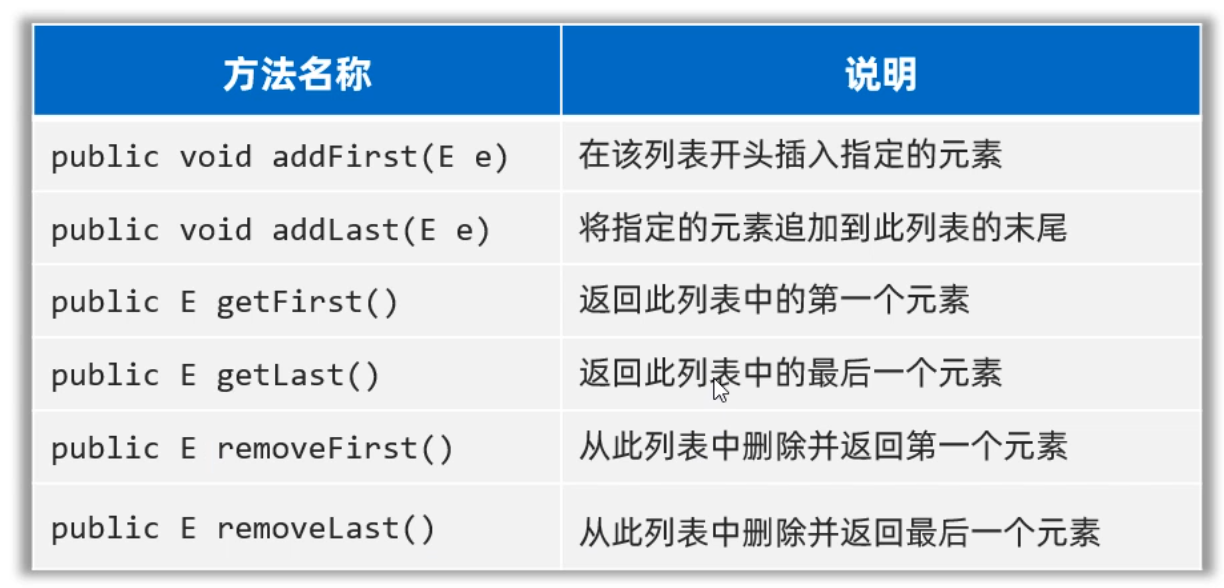
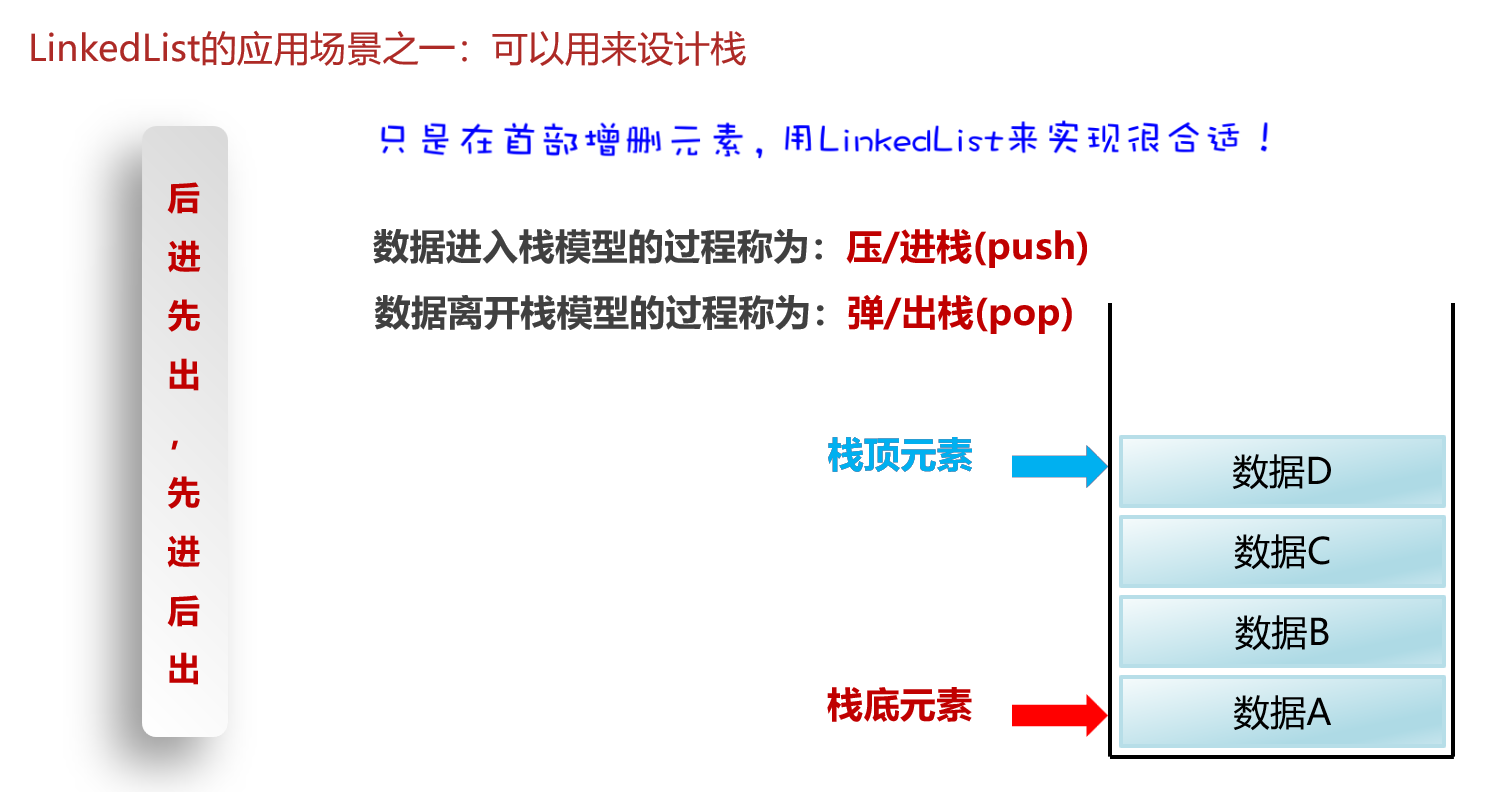
LinkedList集合的使用场景
设计栈和队列
- 队列

-
栈
package com.itheima.d3_collection_list;import java.util.LinkedList;/*** 目标:掌握LinkedList集合的使用。*/
public class ListTest3 {public static void main(String[] args) {// 1、创建一个队列。LinkedList<String> queue = new LinkedList<>();// 入队queue.addLast("第1号人");queue.addLast("第2号人");queue.addLast("第3号人");queue.addLast("第4号人");System.out.println(queue);// 出队System.out.println(queue.removeFirst());System.out.println(queue.removeFirst());System.out.println(queue.removeFirst());System.out.println(queue);System.out.println("--------------------------------------------------");// 2、创建一个栈对象。LinkedList<String> stack = new LinkedList<>();// 压栈(push) 实际调用的就是addFirst方法stack.push("第1颗子弹");stack.push("第2颗子弹");stack.push("第3颗子弹");stack.push("第4颗子弹");System.out.println(stack);// 出栈(pop) 实际调用的就是removeFirst方法System.out.println(stack.pop());System.out.println(stack.pop());System.out.println(stack);}
}
Set集合
//Set<Integer> set = new HashSet<>(); //无序、无索引、不重复 [按照哈希算法计算位置输出的]
//Set<Integer> set = new LinkedHashSet<>(); //有序、无索引、不重复 [666, 555, 777, 888]
Set<Integer> set = new TreeSet<>(); //可排序(升序)、无索引、不重复 [555, 666, 777, 888]
set.add(666);
set.add(555);
set.add(555);
set.add(888);
set.add(888);
set.add(777);
set.add(777);
System.out.println(set); //[555, 666, 777, 888]
HashSet集合
HashSet可以存储null值

哈希值

HashSet集合的底层原理(基于HashMap集合)

HashSet集合底层是基于哈希表实现的,哈希表根据JDK版本的不同,也是有点区别的
- JDK8以前:哈希表 = 数组+链表
- JDK8以后:哈希表 = 数组+链表+红黑树

我们发现往HashSet集合中存储元素时,底层调用了元素的两个方法:一个是hashCode方法获取元素的hashCode值(哈希值);另一个是调用了元素的equals方法,用来比较新添加的元素和集合中已有的元素是否相同。
- 只有新添加元素的hashCode值和集合中以后元素的hashCode值相同、新添加的元素调用equals方法和集合中已有元素比较结果为true, 才认为元素重复。
- 如果hashCode值相同,equals比较不同,则以链表的形式连接在数组的同一个索引为位置(如上图所示)
在JDK8开始后,为了提高性能,当链表的长度超过8时,就会把链表转换为红黑树,如下图所示:


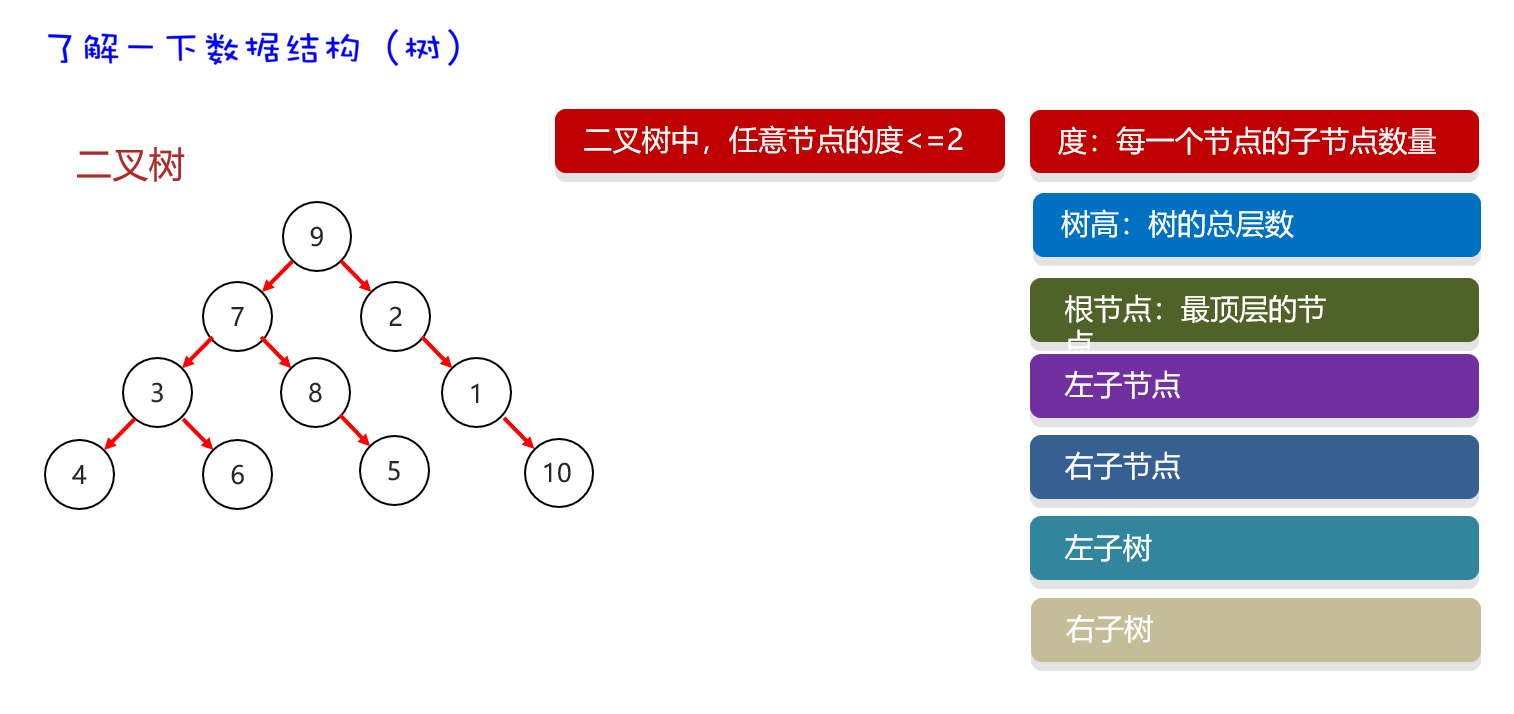
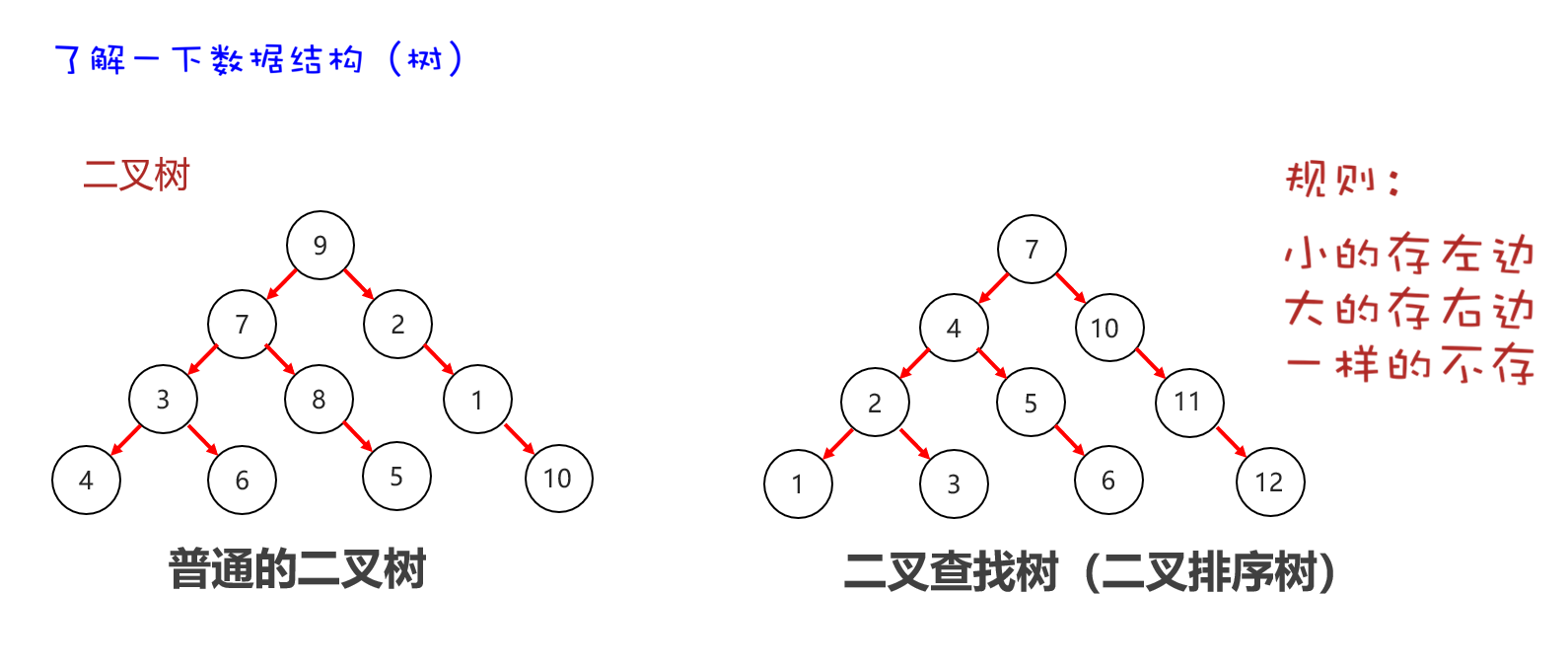
二叉树
二叉排序树
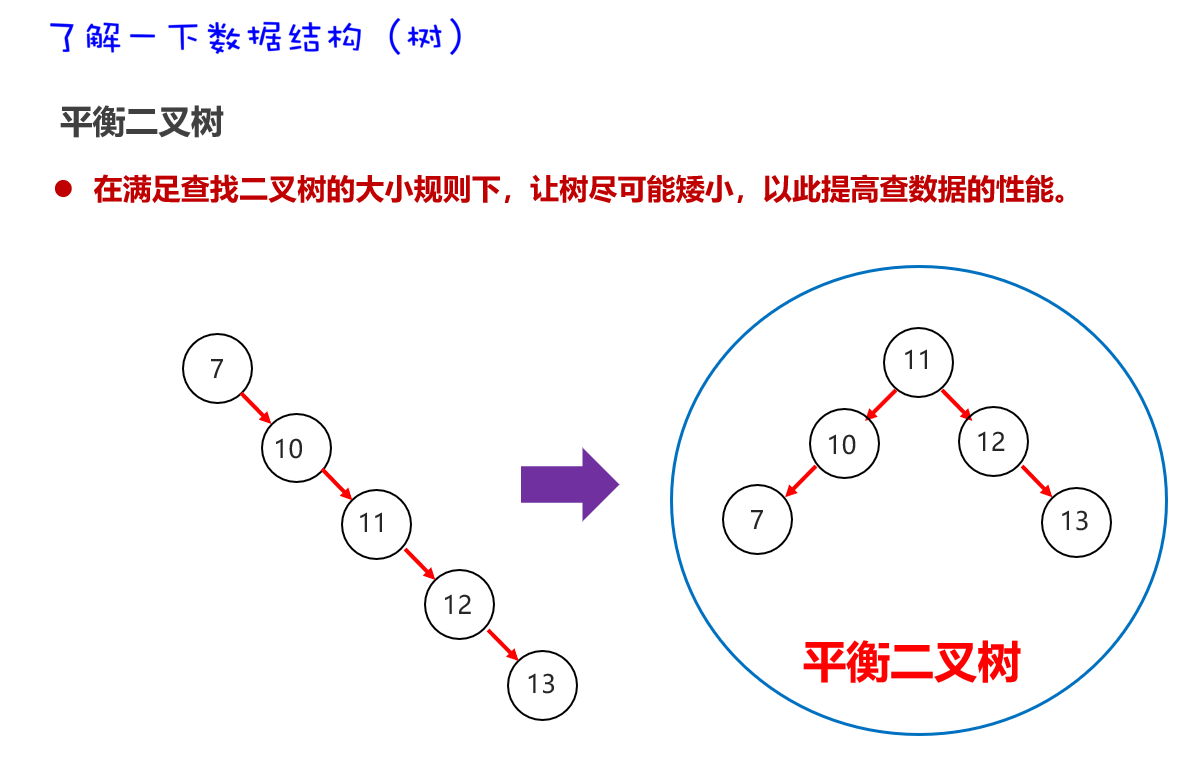
平衡二叉树
红黑树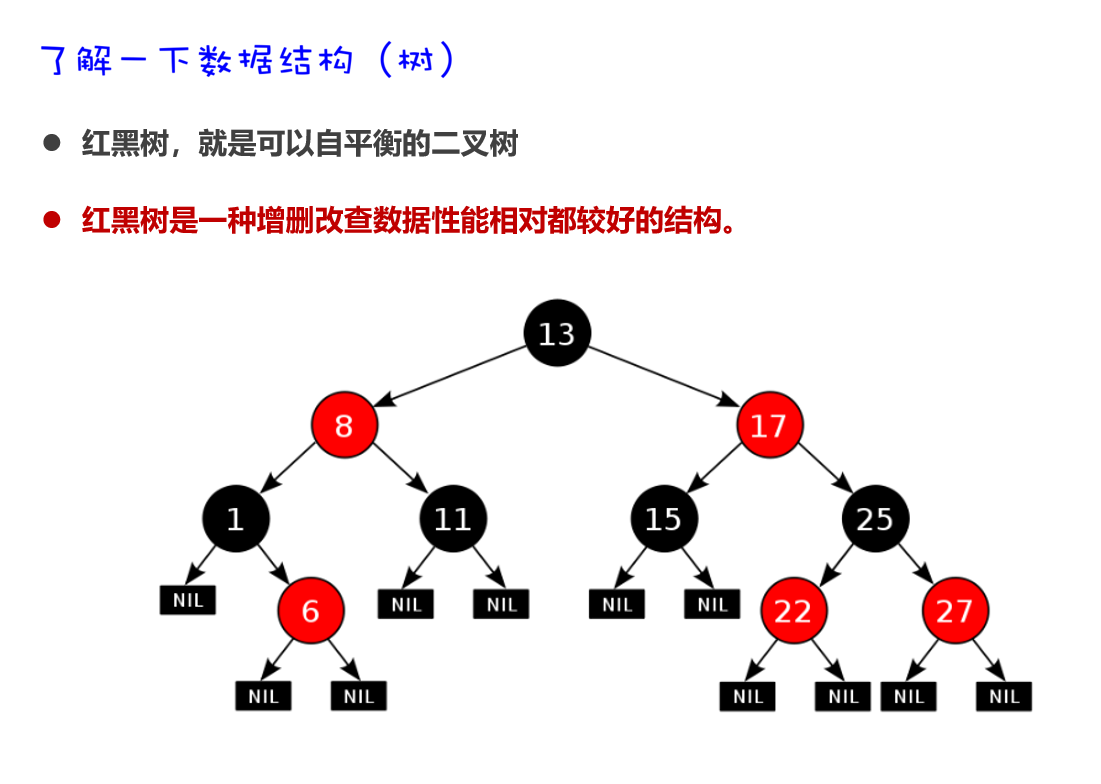
HashSet去重原理
前面我们学习了HashSet存储元素的原理,依赖于两个方法:一个是hashCode方法用来确定在底层数组中存储的位置,另一个是用equals方法判断新添加的元素是否和集合中已有的元素相同。
要想保证在HashSet集合中没有重复元素,我们需要重写元素类的hashCode和equals方法。比如以下面的Student类为例,假设把Student类的对象作为HashSet集合的元素,想要让学生的姓名和年龄相同,就认为元素重复。
public class Student{private String name; //姓名private int age; //年龄private double height; //身高//无参数构造方法public Student(){}//全参数构造方法public Student(String name, int age, double height){this.name=name;this.age=age;this.height=height;}//...get、set、toString()方法自己补上..//按快捷键生成hashCode和equals方法//alt+insert 选择 hashCode and equals@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;if (age != student.age) return false;if (Double.compare(student.height, height) != 0) return false;return name != null ? name.equals(student.name) : student.name == null;}@Overridepublic int hashCode() {int result;long temp;result = name != null ? name.hashCode() : 0;result = 31 * result + age;temp = Double.doubleToLongBits(height);result = 31 * result + (int) (temp ^ (temp >>> 32));return result;}
}
接着,写一个测试类,往HashSet集合中存储Student对象。
public class Test{public static void main(String[] args){Set<Student> students = new HashSet<>();Student s1 = new Student("至尊宝",20, 169.6);Student s2 = new Student("蜘蛛精",23, 169.6);Student s3 = new Student("蜘蛛精",23, 169.6);Student s4 = new Student("牛魔王",48, 169.6);students.add(s1);students.add(s2);students.add(s3);students.add(s4);for(Student s : students){System.out.println(s);}}
}
打印结果如下,我们发现存了两个蜘蛛精,当时实际打印出来只有一个,而且是无序的。
Student{name='牛魔王', age=48, height=169.6}
Student{name='至尊宝', age=20, height=169.6}
Student{name='蜘蛛精', age=23, height=169.6}
LinkedHashSet集合

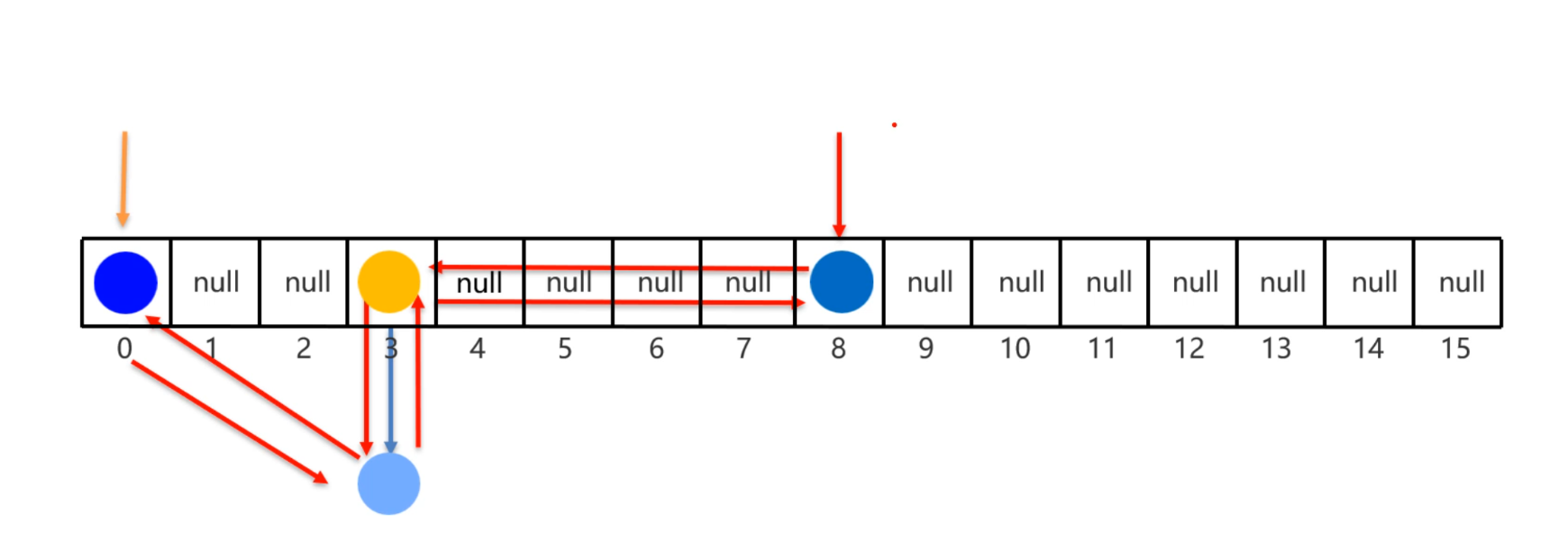
每次添加元素,就和上一个元素用双向链表连接一下。第一个添加的元素是双向链表的头节点,最后一个添加的元素是双向链表的尾节点。
把上个案例中的集合改成LinkedList集合,我们观察效果怎样
public class Test{public static void main(String[] args){Set<Student> students = new LinkedHashSet<>();Student s1 = new Student("至尊宝",20, 169.6);Student s2 = new Student("蜘蛛精",23, 169.6);Student s3 = new Student("蜘蛛精",23, 169.6);Student s4 = new Student("牛魔王",48, 169.6);students.add(s1);students.add(s2);students.add(s3);students.add(s4);for(Student s : students){System.out.println(s);}}
}
打印结果如下
Student{name='至尊宝', age=20, height=169.6}
Student{name='蜘蛛精', age=23, height=169.6}
Student{name='牛魔王', age=48, height=169.6}
TreeSet集合
TreeSet不可以存储null值,会报空指针异常
TreeSet集合底层原理基于HashMap集合实现

TreeSet自定义排序规则
我们想要告诉TreeSet集合按照指定的规则排序,有两种办法:
第一种:让元素的类实现Comparable接口,重写compareTo方法
第二种:在创建TreeSet集合时,通过构造方法传递Compartor比较器对象
- 排序方式1:我们先来演示第一种排序方式
//第一步:先让Student类,实现Comparable接口
//注意:Student类的对象是作为TreeSet集合的元素的
public class Student implements Comparable<Student>{private String name;private int age;private double height;//无参数构造方法public Student(){}//全参数构造方法public Student(String name, int age, double height){this.name=name;this.age=age;this.height=height;}//...get、set、toString()方法自己补上..//第二步:重写compareTo方法//按照年龄进行比较,只需要在方法中让this.age和o.age相减就可以。/*原理:在往TreeSet集合中添加元素时,add方法底层会调用compareTo方法,根据该方法的结果是正数、负数、还是零,决定元素放在后面、前面还是不存。*/@Overridepublic int compareTo(Student o) {//this:表示将要添加进去的Student对象//o: 表示集合中已有的Student对象return this.age-o.age;}
}
此时,再运行测试类,结果如下
Student{name='至尊宝', age=20, height=169.6}
Student{name='紫霞', age=20, height=169.8}
Student{name='蜘蛛精', age=23, height=169.6}
Student{name='牛魔王', age=48, height=169.6}
- 排序方式2:接下来演示第二种排序方式
//创建TreeSet集合时,传递比较器对象排序
/*
原理:当调用add方法时,底层会先用比较器,根据Comparator的compare方是正数、负数、还是零,决定谁在后,谁在前,谁不存。
*/
//下面代码中是按照学生的年龄升序排序
Set<Student> students = new TreeSet<>(new Comparator<Student>{@Overridepublic int compare(Student o1, Student o2){//需求:按照学生的身高排序return Double.compare(o1,o2); }
});//创建4个Student对象
Student s1 = new Student("至尊宝",20, 169.6);
Student s2 = new Student("紫霞",23, 169.8);
Student s3 = new Student("蜘蛛精",23, 169.6);
Student s4 = new Student("牛魔王",48, 169.6);//添加Studnet对象到集合
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
System.out.println(students);

不同集合的使用场景

集合的并发修改异常

package com.itheima.d5_collection_exception;
import java.util.*;/*** 目标:理解集合的并发修改异常问题,并解决。*/
public class CollectionTest1 {public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("王麻子");list.add("小李子");list.add("李爱花");list.add("张全蛋");list.add("晓李");list.add("李玉刚");System.out.println(list);// [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]// 需求:找出集合中全部带“李”的名字,并从集合中删除。
// Iterator<String> it = list.iterator();
// while (it.hasNext()){
// String name = it.next();
// if(name.contains("李")){
// list.remove(name);
// }
// }
// System.out.println(list);// 使用for循环遍历集合并删除集合中带李字的名字// [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]// [王麻子, 李爱花, 张全蛋, 李玉刚]// i
// for (int i = 0; i < list.size(); i++) {
// String name = list.get(i);
// if(name.contains("李")){
// list.remove(name);
// }
// }
// System.out.println(list);System.out.println("---------------------------------------------------------");// 怎么解决呢?// 使用for循环遍历集合并删除集合中带李字的名字// [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]// [王麻子, 张全蛋]// i
// for (int i = 0; i < list.size(); i++) {
// String name = list.get(i);
// if(name.contains("李")){
// list.remove(name);
// i--;
// }
// }
// System.out.println(list);// 倒着去删除也是可以的。// 需求:找出集合中全部带“李”的名字,并从集合中删除。
// Iterator<String> it = list.iterator();
// while (it.hasNext()){
// String name = it.next();
// if(name.contains("李")){
// // list.remove(name); // 并发修改异常的错误。
// it.remove(); // 删除迭代器当前遍历到的数据,每删除一个数据后,相当于也在底层做了i--
// }
// }
// System.out.println(list);// 使用增强for循环遍历集合并删除数据,没有办法解决bug.
// for (String name : list) {
// if(name.contains("李")){
// list.remove(name);
// }
// }
// System.out.println(list);// list.forEach(name -> {
// if(name.contains("李")){
// list.remove(name);
// }
// });
// System.out.println(list);}
}
Collections工具类
常用方法
注意Collections并不是集合,它比Collection多了一个s,一般后缀为s的类很多都是工具类。这里的Collections是用来操作Collection的工具类。它提供了一些好用的静态方法,如下

我们把这些方法用代码来演示一下:
public class CollectionsTest{public static void main(String[] args){//1.public static <T> boolean addAll(Collection<? super T> c, T...e)List<String> names = new ArrayList<>();Collections.addAll(names, "张三","王五","李四", "张麻子");System.out.println(names);//2.public static void shuffle(List<?> list):对集合打乱顺序Collections.shuffle(names);System.out.println(names);//3.public static <T> void short(List<T list): 对List集合排序List<Integer> list = new ArrayList<>();list.add(3);list.add(5);list.add(2);Collections.sort(list);System.out.println(list);}
}
Collections工具类自定义排序方法
上面我们往集合中存储的元素要么是Stirng类型,要么是Integer类型,他们本来就有一种自然顺序所以可以直接排序。但是如果我们往List集合中存储Student对象,这个时候想要对List集合进行排序自定义比较规则的。指定排序规则有两种方式,如下:
排序方式1:让元素实现Comparable接口,重写compareTo方法
比如现在想要往集合中存储Studdent对象,首先需要准备一个Student类,实现Comparable接口。
public class Student implements Comparable<Student>{private String name;private int age;private double height;//排序时:底层会自动调用此方法,this和o表示需要比较的两个对象@Overridepublic int compareTo(Student o){//需求:按照年龄升序排序//如果返回正数:说明左边对象的年龄>右边对象的年龄//如果返回负数:说明左边对象的年龄<右边对象的年龄,//如果返回0:说明左边对象的年龄和右边对象的年龄相同return this.age - o.age;}//...getter、setter、constructor..
}
然后再使用Collections.sort(list集合)对List集合排序,如下:
//3.public static <T> void short(List<T list): 对List集合排序
List<Student> students = new ArrayList<>();
students.add(new Student("蜘蛛精",23,169.7));
students.add(new Student("紫霞",22,169.8));
students.add(new Student("紫霞",22,169.8));
students.add(new Student("至尊宝",26,169.5));/*
原理:sort方法底层会遍历students集合中的每一个元素,采用排序算法,将任意两个元素两两比较;每次比较时,会用一个Student对象调用compareTo方法和另一个Student对象进行比较;根据compareTo方法返回的结果是正数、负数,零来决定谁大,谁小,谁相等,重新排序元素的位置注意:这些都是sort方法底层自动完成的,想要完全理解,必须要懂排序算法才行;
*/
Collections.sort(students);
System.out.println(students);
排序方式2:使用调用sort方法是,传递比较器
/*
原理:sort方法底层会遍历students集合中的每一个元素,采用排序算法,将任意两个元素两两比较;每次比较,会将比较的两个元素传递给Comparator比较器对象的compare方法的两个参数o1和o2,根据compare方法的返回结果是正数,负数,或者0来决定谁大,谁小,谁相等,重新排序元素的位置注意:这些都是sort方法底层自动完成的,不需要我们完全理解,想要理解它必须要懂排序算法才行.
*/
Collections.sort(students, new Comparator<Student>(){@Overridepublic int compare(Student o1, Student o2){return o1.getAge()-o2.getAge();}
});
System.out.println(students);
斗地主案例
我们先分析一下业务需求:
- 总共有54张牌,每一张牌有花色和点数两个属性、为了排序还可以再加一个序号
- 点数可以是:“3”,"4","5","6","7","8","9","10","J","Q","K","A","2"
- 花色可以是:“♣”,"♠","♥","♦"
- 斗地主时:三个玩家每人手里17张牌,剩余3张牌作为底牌
第一步:为了表示每一张牌有哪些属性,首先应该新建一个扑克牌的类
第二步:启动游戏时,就应该提前准备好54张牌
第三步:接着再完全洗牌、发牌、捋牌、看牌的业务逻辑
先来完成第一步,定义一个扑克类Card
public class Card {private String number;private String color;// 每张牌是存在大小的。private int size; // 0 1 2 ....public Card() {}public Card(String number, String color, int size) {this.number = number;this.color = color;this.size = size;}public String getNumber() {return number;}public void setNumber(String number) {this.number = number;}public String getColor() {return color;}public void setColor(String color) {this.color = color;}public int getSize() {return size;}public void setSize(int size) {this.size = size;}@Overridepublic String toString() {return color + number ;}
}
再完成第二步,定义一个房间类,初始化房间时准备好54张牌
public class Room {// 必须有一副牌。private List<Card> allCards = new ArrayList<>();public Room(){// 1、做出54张牌,存入到集合allCards// a、点数:个数确定了,类型确定。String[] numbers = {"3","4","5","6","7","8","9","10","J","Q","K","A","2"};// b、花色:个数确定了,类型确定。String[] colors = {"♠", "♥", "♣", "♦"};int size = 0; // 表示每张牌的大小// c、遍历点数,再遍历花色,组织牌for (String number : numbers) {// number = "3"size++; // 1 2 ....for (String color : colors) {// 得到一张牌Card c = new Card(number, color, size);allCards.add(c); // 存入了牌}}// 单独存入小大王的。Card c1 = new Card("", "🃏" , ++size);Card c2 = new Card("", "👲" , ++size);Collections.addAll(allCards, c1, c2);System.out.println("新牌:" + allCards);}
}
最后完成第三步,定义一个启动游戏的方法,完成洗牌、发牌、捋牌、看牌的业务逻辑
/**
* 游戏启动
*/
public void start() {// 1、洗牌: allCardsCollections.shuffle(allCards);System.out.println("洗牌后:" + allCards);// 2、发牌,首先肯定要定义 三个玩家。 List(ArrayList) Set(TreeSet)List<Card> linHuChong = new ArrayList<>();List<Card> jiuMoZhi = new ArrayList<>();List<Card> renYingYing = new ArrayList<>();// 正式发牌给这三个玩家,依次发出51张牌,剩余3张做为底牌。// allCards = [♥3, ♣10, ♣4, ♥K, ♦Q, ♣2, 🃏, ♣8, ....// 0 1 2 3 4 5 6 ... % 3for (int i = 0; i < allCards.size() - 3; i++) {Card c = allCards.get(i);// 判断牌发给谁if(i % 3 == 0){// 请啊冲接牌linHuChong.add(c);}else if(i % 3 == 1){// 请啊鸠来接牌jiuMoZhi.add(c);}else if(i % 3 == 2){// 请盈盈接牌renYingYing.add(c);}}// 3、对3个玩家的牌进行排序sortCards(linHuChong);sortCards(jiuMoZhi);sortCards(renYingYing);// 4、看牌System.out.println("啊冲:" + linHuChong);System.out.println("啊鸠:" + jiuMoZhi);System.out.println("盈盈:" + renYingYing);List<Card> lastThreeCards = allCards.subList(allCards.size() - 3, allCards.size()); // 51 52 53System.out.println("底牌:" + lastThreeCards);jiuMoZhi.addAll(lastThreeCards);sortCards(jiuMoZhi);System.out.println("啊鸠抢到地主后:" + jiuMoZhi);
}/*** 集中进行排序* @param cards*/
private void sortCards(List<Card> cards) {Collections.sort(cards, new Comparator<Card>() {@Overridepublic int compare(Card o1, Card o2) {// return o1.getSize() - o2.getSize(); // 升序排序return o2.getSize() - o1.getSize(); // 降序排序}});
}
不要忘记了写测试类了,
public class GameDemo {public static void main(String[] args) {// 1、牌类。// 2、房间Room m = new Room();// 3、启动游戏m.start();}
}
Map双列集合
Map集合
Map集合介绍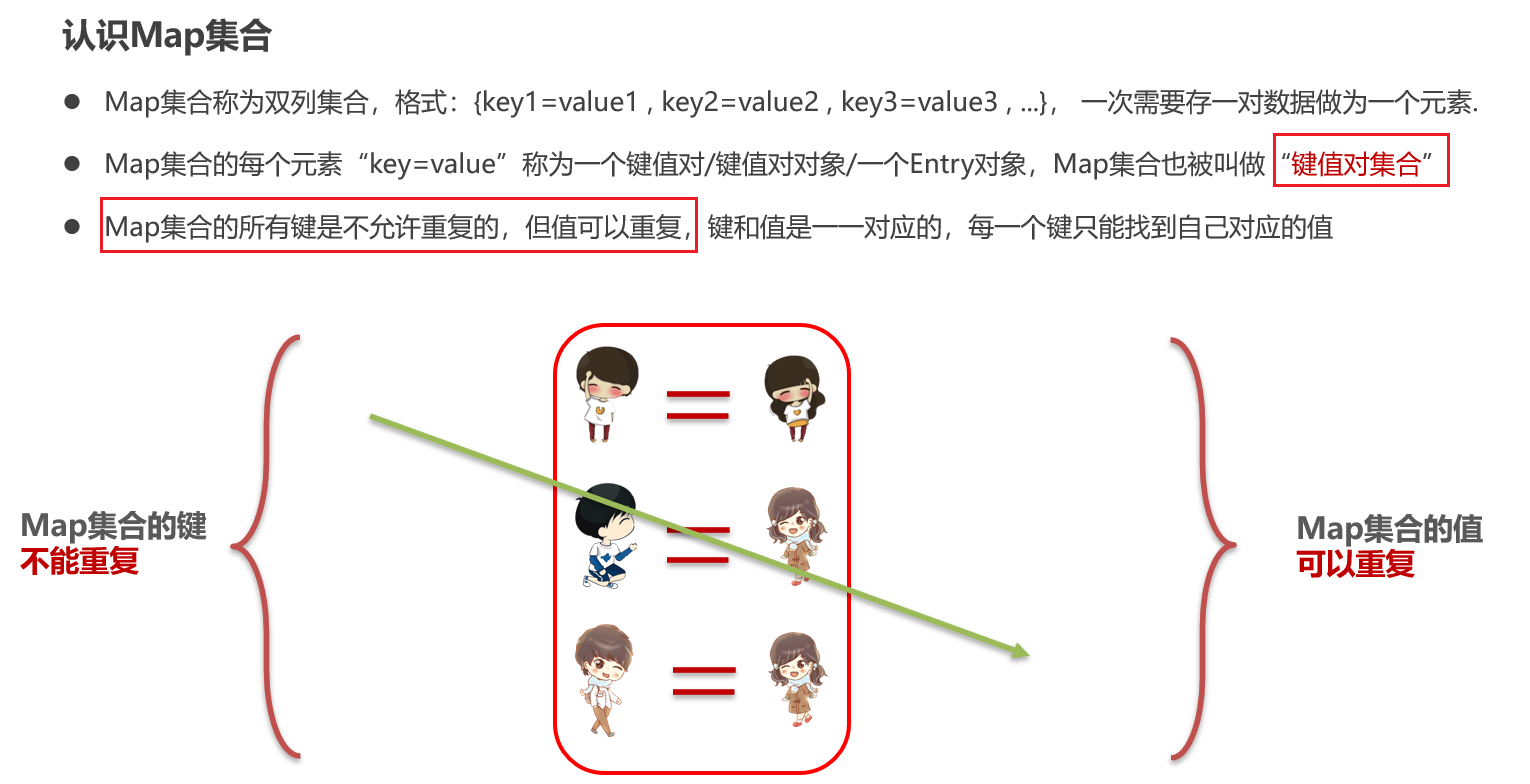
Map集合体系
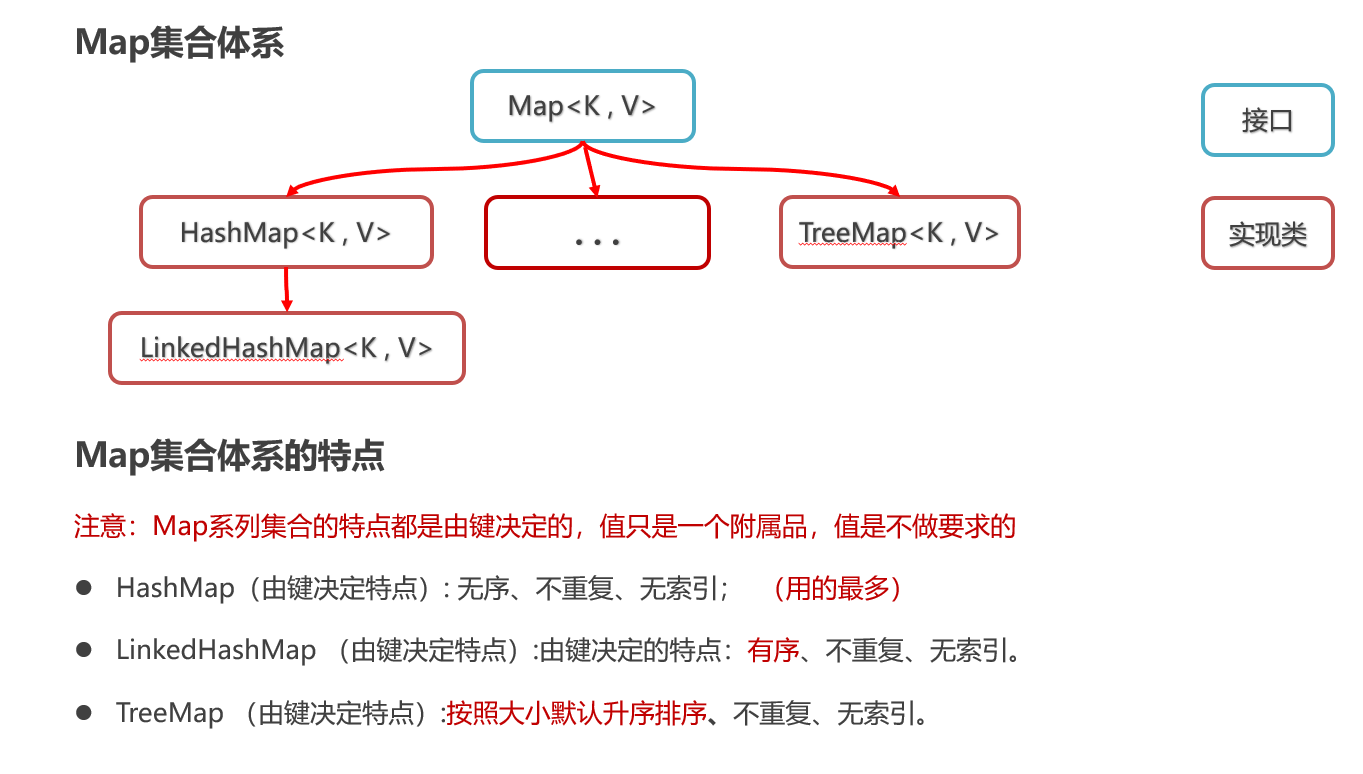
Map集合常用方法
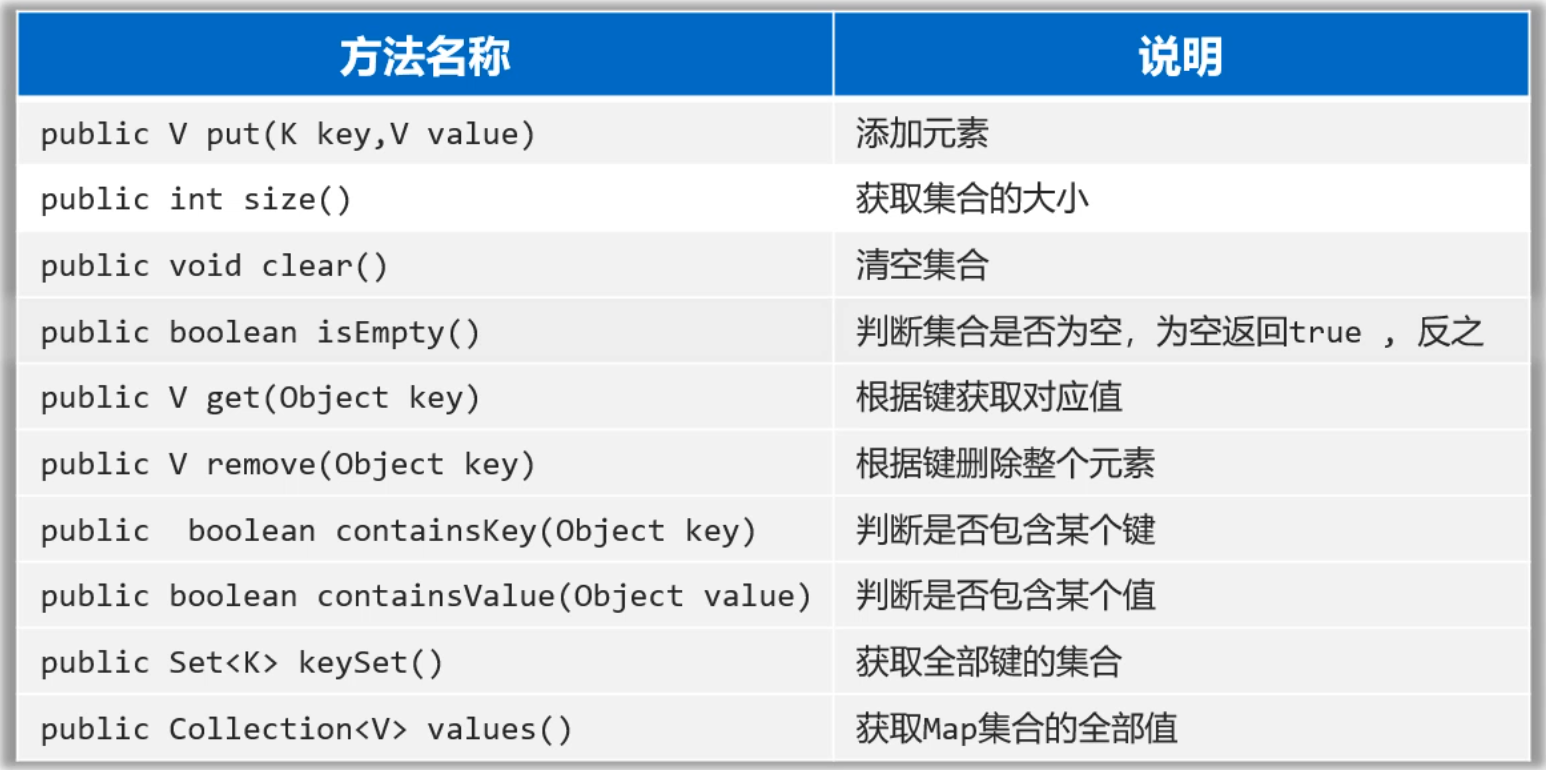
public class MapTest2 {public static void main(String[] args) {// 1.添加元素: 无序,不重复,无索引。Map<String, Integer> map = new HashMap<>();map.put("手表", 100);map.put("手表", 220);map.put("手机", 2);map.put("Java", 2);map.put(null, null);System.out.println(map);// map = {null=null, 手表=220, Java=2, 手机=2}// 2.public int size():获取集合的大小System.out.println(map.size());// 3、public void clear():清空集合//map.clear();//System.out.println(map);// 4.public boolean isEmpty(): 判断集合是否为空,为空返回true ,反之!System.out.println(map.isEmpty());// 5.public V get(Object key):根据键获取对应值int v1 = map.get("手表");System.out.println(v1);System.out.println(map.get("手机")); // 2System.out.println(map.get("张三")); // null// 6. public V remove(Object key):根据键删除整个元素(删除键会返回键的值)System.out.println(map.remove("手表"));System.out.println(map);// 7.public boolean containsKey(Object key): 判断是否包含某个键 ,包含返回true ,反之System.out.println(map.containsKey("手表")); // falseSystem.out.println(map.containsKey("手机")); // trueSystem.out.println(map.containsKey("java")); // falseSystem.out.println(map.containsKey("Java")); // true// 8.public boolean containsValue(Object value): 判断是否包含某个值。System.out.println(map.containsValue(2)); // trueSystem.out.println(map.containsValue("2")); // false// 9.public Set<K> keySet(): 获取Map集合的全部键。Set<String> keys = map.keySet();System.out.println(keys);// 10.public Collection<V> values(); 获取Map集合的全部值。Collection<Integer> values = map.values();System.out.println(values);// 11.把其他Map集合的数据倒入到自己集合中来。(拓展)Map<String, Integer> map1 = new HashMap<>();map1.put("java1", 10);map1.put("java2", 20);Map<String, Integer> map2 = new HashMap<>();map2.put("java3", 10);map2.put("java2", 222);map1.putAll(map2); // putAll:把map2集合中的元素全部倒入一份到map1集合中去。System.out.println(map1);System.out.println(map2);}
}
Map集合的遍历方式

键找值

/*** 目标:掌握Map集合的遍历方式1:键找值*/
public class MapTest1 {public static void main(String[] args) {// 准备一个Map集合。Map<String, Double> map = new HashMap<>();map.put("蜘蛛精", 162.5);map.put("蜘蛛精", 169.8);map.put("紫霞", 165.8);map.put("至尊宝", 169.5);map.put("牛魔王", 183.6);System.out.println(map);// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}// 1、获取Map集合的全部键Set<String> keys = map.keySet();// System.out.println(keys);// [蜘蛛精, 牛魔王, 至尊宝, 紫霞]// key// 2、遍历全部的键,根据键获取其对应的值for (String key : keys) {// 根据键获取对应的值double value = map.get(key);System.out.println(key + "=====>" + value);}}
}
键值对
各位同学,接下来我们学习Map集合的第二种遍历方式,这种遍历方式更加符合面向对象的思维。
前面我们给大家介绍过,Map集合是用来存储键值对的,而每一个键值对实际上是一个Entry对象。
这里Map集合的第二种方式,是直接获取每一个Entry对象,把Entry存储扫Set集合中去,再通过Entry对象获取键和值。
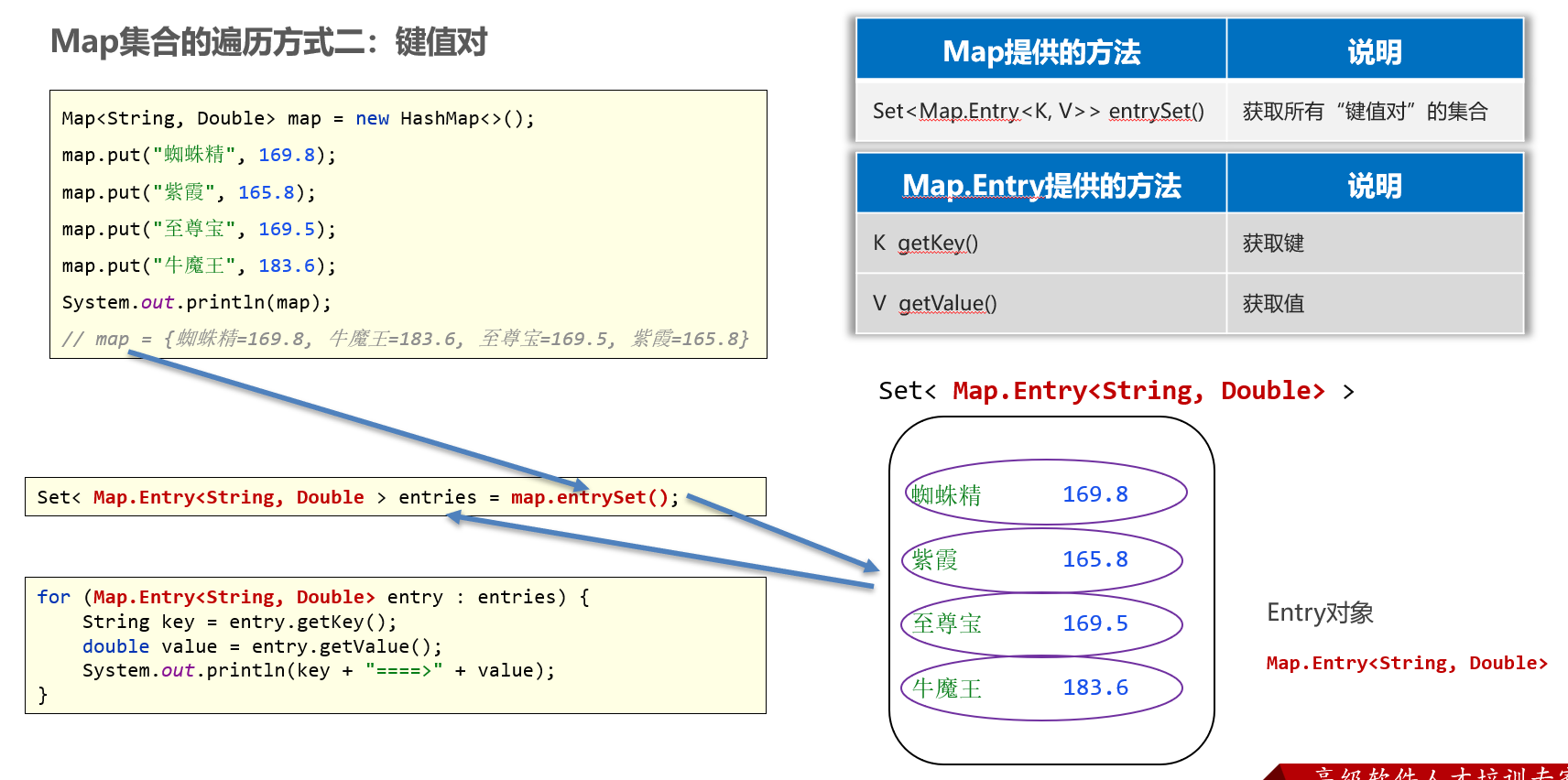
package com.itheima.d5_map_traverse;
import java.util.*;
/*** 目标:掌握Map集合的第二种遍历方式:键值对。*/
public class MapTest2 {public static void main(String[] args) {Map<String, Double> map = new HashMap<>();map.put("蜘蛛精", 169.8);map.put("紫霞", 165.8);map.put("至尊宝", 169.5);map.put("牛魔王", 183.6);System.out.println(map);// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}// entries = [(蜘蛛精=169.8), (牛魔王=183.6), (至尊宝=169.5), (紫霞=165.8)]// entry// 1、调用Map集合提供entrySet方法,把Map集合转换成键值对类型的Set集合Set<Map.Entry<String, Double>> entries = map.entrySet();for (Map.Entry<String, Double> entry : entries) {String key = entry.getKey();double value = entry.getValue();System.out.println(key + "---->" + value);}}
}
lambda
package com.itheima.d5_map_traverse;import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;/*** 目标:掌握Map集合的第二种遍历方式:键值对。*/
public class MapTest3 {public static void main(String[] args) {Map<String, Double> map = new HashMap<>();map.put("蜘蛛精", 169.8);map.put("紫霞", 165.8);map.put("至尊宝", 169.5);map.put("牛魔王", 183.6);System.out.println(map);// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}// map.forEach((k, v) -> {// System.out.println(k + "--->" + v);// });map.forEach(new BiConsumer<String, Double>() {@Overridepublic void accept(String k, Double v) {System.out.println(k + "---->" + v);}});// 上面的BiConsumer是函数式接口,所以可以使用lambda表达式来简化map.forEach(( k, v) -> {System.out.println(k + "---->" + v);});}
}
Map集合的练习案例

先分析需求,再考虑怎么用代码实现
1.首先可以将80个学生选择的景点放到一个集合中去(也就是说,集合中的元素是80个任意的ABCD元素)
2.准备一个Map集合用来存储景点,以及景点被选择的次数
3.遍历80个学生选择景点的集合,得到每一个景点,判断Map集合中是否包含该景点
如果不包含,则存储"景点=1"
如果包含,则存获取该景点原先的值,再存储"景点=原来的值+1"; 此时新值会覆盖旧值
/*** 目标:完成Map集合的案例:统计投票人数。*/
public class MapDemo4 {public static void main(String[] args) {// 1、把80个学生选择的景点数据拿到程序中来。List<String> data = new ArrayList<>();String[] selects = {"A", "B", "C", "D"};Random r = new Random();for (int i = 1; i <= 80; i++) {// 每次模拟一个学生选择一个景点,存入到集合中去。int index = r.nextInt(4); // 0 1 2 3data.add(selects[index]);}System.out.println(data);// 2、开始统计每个景点的投票人数// 准备一个Map集合用于统计最终的结果Map<String, Integer> result = new HashMap<>();// 3、开始遍历80个景点数据for (String s : data) {// 问问Map集合中是否存在该景点if(result.containsKey(s)){// 说明这个景点之前统计过。其值+1. 存入到Map集合中去result.put(s, result.get(s) + 1);}else {// 说明这个景点是第一次统计,存入"景点=1"result.put(s, 1);}}System.out.println(result);}
}
HashMap集合
 HashMap集合的底层原理
HashMap集合的底层原理
首先,我们学习HashMap集合的底层原理。前面我们学习过HashSet的底层原理,实际上HashMap底层原理和HashSet是一样的。为什么这么说呢?因为我们往HashSet集合中添加元素时,实际上是把元素作为添加添加到了HashMap集合中。
下面是Map集合的体系结构,HashMap集合的特点是由键决定的: 它的键是无序、不能重复,而且没有索引的。再各种Map集合中也是用得最多的一种集合。
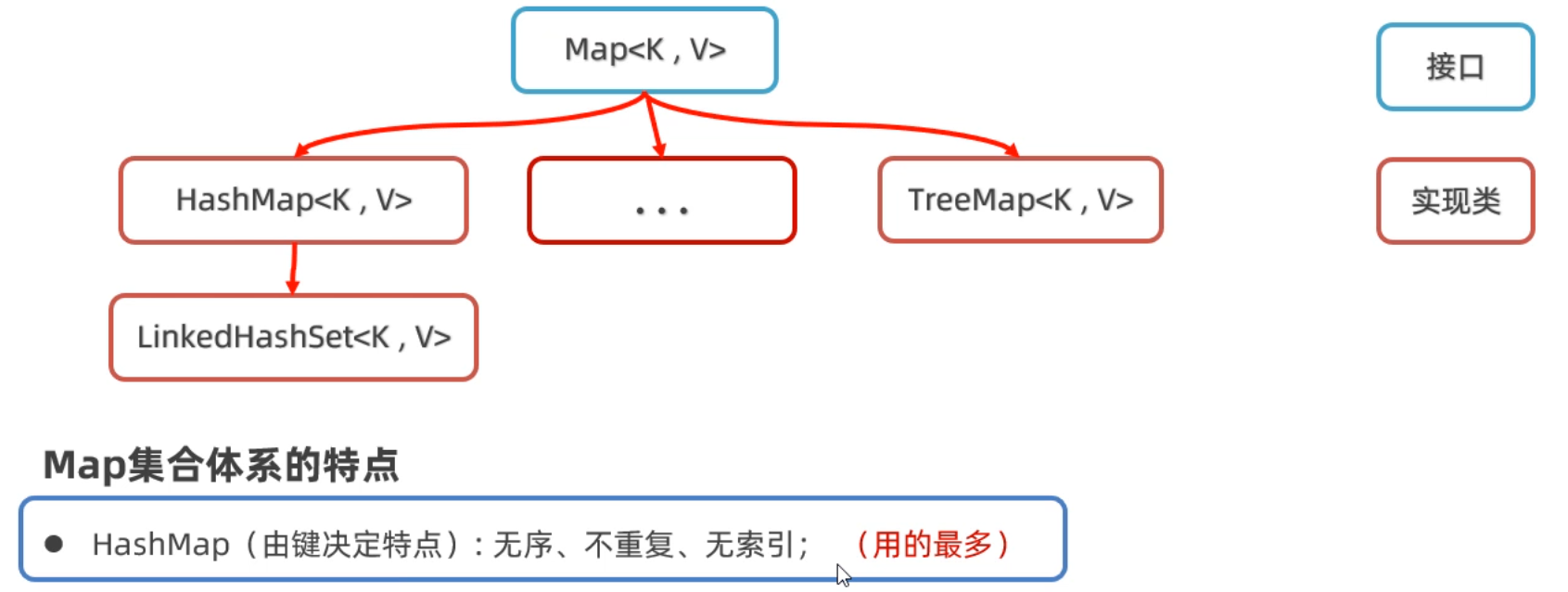
刚才我们说,HashSet底层就是HashMap,我们可以看源码验证这一点,如下图所示,我们可以看到,创建HashSet集合时,底层帮你创建了HashMap集合;往HashSet集合中添加添加元素时,底层却是调用了Map集合的put方法把元素作为了键来存储。所以实际上根本没有什么HashSet集合,把HashMap的集合的值忽略不看就是HashSet集合。

HashSet的原理我们之前已经学过了,所以HashMap是一样的,底层是哈希表结构。
HashMap底层数据结构: 哈希表结构
JDK8之前的哈希表 = 数组+链表
JDK8之后的哈希表 = 数组+链表+红黑树
哈希表是一种增删改查数据,性能相对都较好的数据结构往HashMap集合中键值对数据时,底层步骤如下
第1步:当你第一次往HashMap集合中存储键值对时,底层会创建一个长度为16的数组
第2步:把键然后将键和值封装成一个对象,叫做Entry对象
第3步:再根据Entry对象的键计算hashCode值(和值无关)
第4步:利用hashCode值和数组的长度做一个类似求余数的算法,会得到一个索引位置
第5步:判断这个索引的位置是否为null,如果为null,就直接将这个Entry对象存储到这个索引位置
如果不为null,则还需要进行第6步的判断
第6步:继续调用equals方法判断两个对象键是否相同
如果equals返回false,则以链表的形式往下挂
如果equals方法true,则认为键重复,此时新的键值对会替换就的键值对。HashMap底层需要注意这几点:
1.底层数组默认长度为16,如果数组中有超过12个位置已经存储了元素,则会对数组进行扩容2倍
数组扩容的加载因子是0.75,意思是:16*0.75=12 2.数组的同一个索引位置有多个元素、并且在8个元素以内(包括8),则以链表的形式存储
JDK7版本:链表采用头插法(新元素往链表的头部添加)
JDK8版本:链表采用尾插法(新元素往那个链表的尾部添加)3.数组的同一个索引位置有多个元素、并且超过了8个或者数组长度超过64,则以红黑树形式存储
从HashMap底层存储键值对的过程中我们发现:决定键是否重复依赖与两个方法,一个是hashCode方法、一个是equals方法。有两个键计算得到的hashCode值相同,并且两个键使用equals比较为true,就认为键重复。
所以,往Map集合中存储自定义对象作为键,为了保证键的唯一性,我们应该重写hashCode方法和equals方法。
比如有如下案例:往HashMap集合中存储Student对象作为键,学生的家庭住址当做值。要求,当学生对象的姓名和年龄相同时就认为键重复。比如有如下案例:往HashMap集合中存储Student对象作为键,学生的家庭住址当做值。要求,当学生对象的姓名和年龄相同时就认为键重复。
public class Student implements Comparable<Student> {private String name;private int age;private double height;// this o@Overridepublic int compareTo(Student o) {return this.age - o.age; // 年龄升序排序}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name, age, height);}public Student() {}public Student(String name, int age, double height) {this.name = name;this.age = age;this.height = height;}//...get,set方法自己补全....@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +", height=" + height +'}';}
}
写一个测试类,在测试类中,创建HashMap集合,键是Student类型,值是Stirng类型
/*** 目标:掌握Map集合下的实现类:HashMap集合的底层原理。*/
public class Test1HashMap {public static void main(String[] args) {Map<Student, String> map = new HashMap<>();map.put(new Student("蜘蛛精", 25, 168.5), "盘丝洞");map.put(new Student("蜘蛛精", 25, 168.5), "水帘洞");map.put(new Student("至尊宝", 23, 163.5), "水帘洞");map.put(new Student("牛魔王", 28, 183.5), "牛头山");System.out.println(map);}
}
上面存储的键,有两个蜘蛛精,但是打印出只会有最后一个。

LinkedHashMap集合
 LinkedHashMap集合的底层原理
LinkedHashMap集合的底层原理
LinkedHashMap的底层原理,和LinkedHashSet底层原理是一样的。底层多个一个双向链表来维护键的存储顺序。
取元素时,先取头节点元素,然后再依次取下一个几点,一直到尾结点。所以是有序的。
TreeMap集合
TreeMap集合不能存储null值

TreeMap集合的特点也是由键决定的,默认按照键的升序排列,键不重复,也是无索引的。
TreeMap集合的底层原理
TreeMap集合的底层原理和TreeSet也是一样的,底层都是红黑树实现的。所以可以对键进行排序。比如往TreeMap集合中存储Student对象作为键,排序方法有两种。直接看代码吧
TreeMap集合自定义排序规则
排序方式1:写一个Student类,让Student类实现Comparable接口
//第一步:先让Student类,实现Comparable接口
public class Student implements Comparable<Student>{private String name;private int age;private double height;//无参数构造方法public Student(){}//全参数构造方法public Student(String name, int age, double height){this.name=name;this.age=age;this.height=height;}//...get、set、toString()方法自己补上..//按照年龄进行比较,只需要在方法中让this.age和o.age相减就可以。/*原理:在往TreeSet集合中添加元素时,add方法底层会调用compareTo方法,根据该方法的结果是正数、负数、还是零,决定元素放在后面、前面还是不存。*/@Overridepublic int compareTo(Student o) {//this:表示将要添加进去的Student对象//o: 表示集合中已有的Student对象return this.age-o.age;}
}
排序方式2:在创建TreeMap集合时,直接传递Comparator比较器对象。
/*** 目标:掌握TreeMap集合的使用。*/
public class Test3TreeMap {public static void main(String[] args) {Map<Student, String> map = new TreeMap<>(new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return Double.compare(o1.getHeight(), o2.getHeight());}});// Map<Student, String> map = new TreeMap<>(( o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight()));map.put(new Student("蜘蛛精", 25, 168.5), "盘丝洞");map.put(new Student("蜘蛛精", 25, 168.5), "水帘洞");map.put(new Student("至尊宝", 23, 163.5), "水帘洞");map.put(new Student("牛魔王", 28, 183.5), "牛头山");System.out.println(map);}
}
这种方式都可以对TreeMap集合中的键排序。注意:只有TreeMap的键才能排序,HashMap键不能排序。
集合的嵌套
各位同学,到现在为止我们把Map集合和Collection集合的都已经学习完了。但是在实际开发中可能还会存在一种特殊的用法。就是把一个集合当做元素,存储到另一个集合中去,我们把这种用法称之为集合嵌套。

- 案例分析
1.从需求中我们可以看到,有三个省份,每一个省份有多个城市
我们可以用一个Map集合的键表示省份名称,而值表示省份有哪些城市
2.而又因为一个身份有多个城市,同一个省份的多个城市可以再用一个List集合来存储。
所以Map集合的键是String类型,而指是List集合类型
HashMap<String, List<String>> map = new HashMap<>();
- 代码如下
/*** 目标:理解集合的嵌套。* 江苏省 = "南京市","扬州市","苏州市“,"无锡市","常州市"* 湖北省 = "武汉市","孝感市","十堰市","宜昌市","鄂州市"* 河北省 = "石家庄市","唐山市", "邢台市", "保定市", "张家口市"*/
public class Test {public static void main(String[] args) {// 1、定义一个Map集合存储全部的省份信息,和其对应的城市信息。Map<String, List<String>> map = new HashMap<>();List<String> cities1 = new ArrayList<>();Collections.addAll(cities1, "南京市","扬州市","苏州市" ,"无锡市","常州市");map.put("江苏省", cities1);List<String> cities2 = new ArrayList<>();Collections.addAll(cities2, "武汉市","孝感市","十堰市","宜昌市","鄂州市");map.put("湖北省", cities2);List<String> cities3 = new ArrayList<>();Collections.addAll(cities3, "石家庄市","唐山市", "邢台市", "保定市", "张家口市");map.put("河北省", cities3);System.out.println(map);List<String> cities = map.get("湖北省");for (String city : cities) {System.out.println(city);}map.forEach((p, c) -> {System.out.println(p + "----->" + c);});}
}
文件
File类
File类,它就用来表示当前系统下的文件(也可以是文件夹),通过File类提供的方法可以获取文件大小、判断文件是否存在、创建文件、创建文件夹等。
但是需要我们注意:File对象只能对文件进行操作,不能操作文件中的内容。读写数据使用IO流
IDEA软件相对路径是从当前工程下开始寻找

File类判断文件类型、获取文件信息
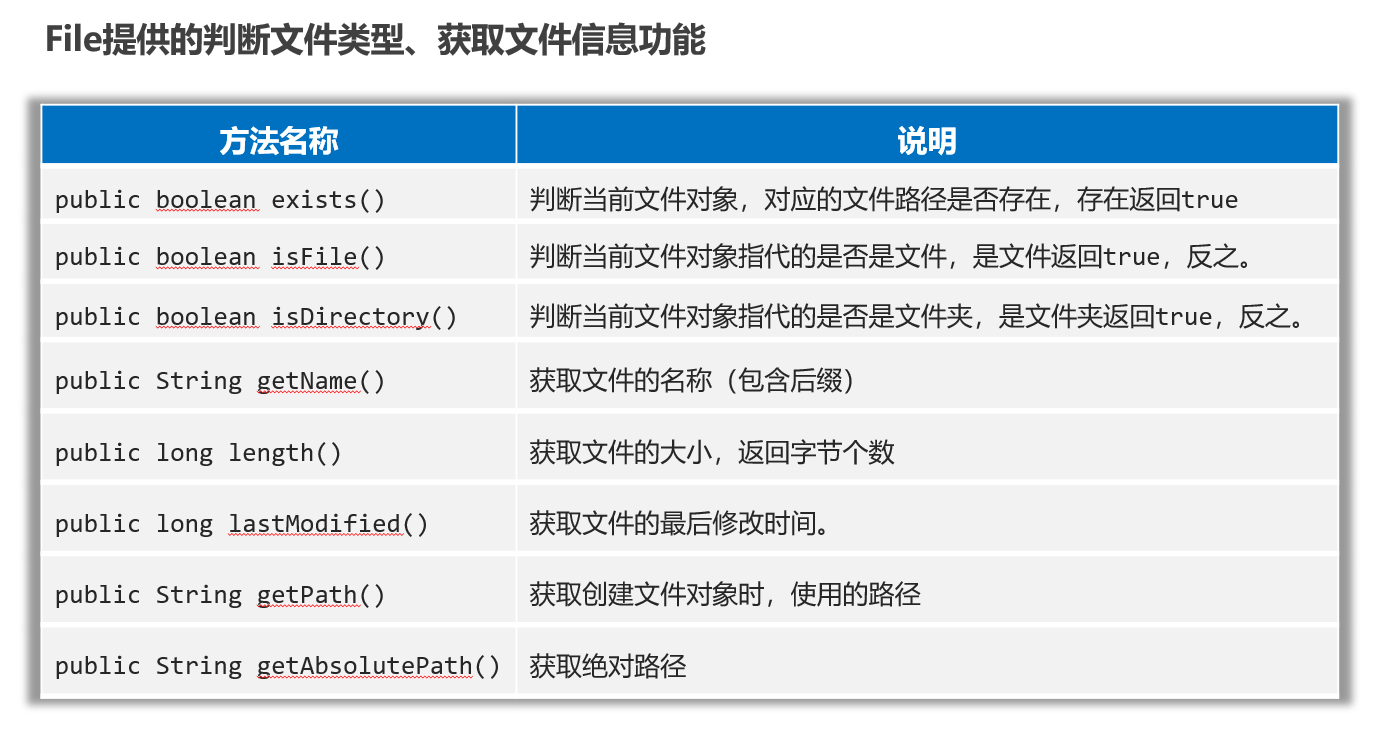
package com.itheima.d1_file;import java.io.File;
import java.io.UnsupportedEncodingException;
import java.text.SimpleDateFormat;/**目标:掌握File提供的判断文件类型、获取文件信息功能*/
public class FileTest2 {public static void main(String[] args) throws UnsupportedEncodingException {// 1.创建文件对象,指代某个文件File f1 = new File("D:/resource/ab.txt");//File f1 = new File("D:/resource/");// 2、public boolean exists():判断当前文件对象,对应的文件路径是否存在,存在返回true.System.out.println(f1.exists());// 3、public boolean isFile() : 判断当前文件对象指代的是否是文件,是文件返回true,反之。System.out.println(f1.isFile());// 4、public boolean isDirectory() : 判断当前文件对象指代的是否是文件夹,是文件夹返回true,反之。System.out.println(f1.isDirectory());// 5.public String getName():获取文件的名称(包含后缀)System.out.println(f1.getName());// 6.public long length():获取文件的大小,返回字节个数System.out.println(f1.length());// 7.public long lastModified():获取文件的最后修改时间。long time = f1.lastModified();SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");System.out.println(sdf.format(time));// 8.public String getPath():获取创建文件对象时,使用的路径File f2 = new File("D:\\resource\\ab.txt");File f3 = new File("file-io-app\\src\\itheima.txt");System.out.println(f2.getPath());System.out.println(f3.getPath());// 9.public String getAbsolutePath():获取绝对路径System.out.println(f2.getAbsolutePath());System.out.println(f3.getAbsolutePath());}
}
File类创建文件、删除文件
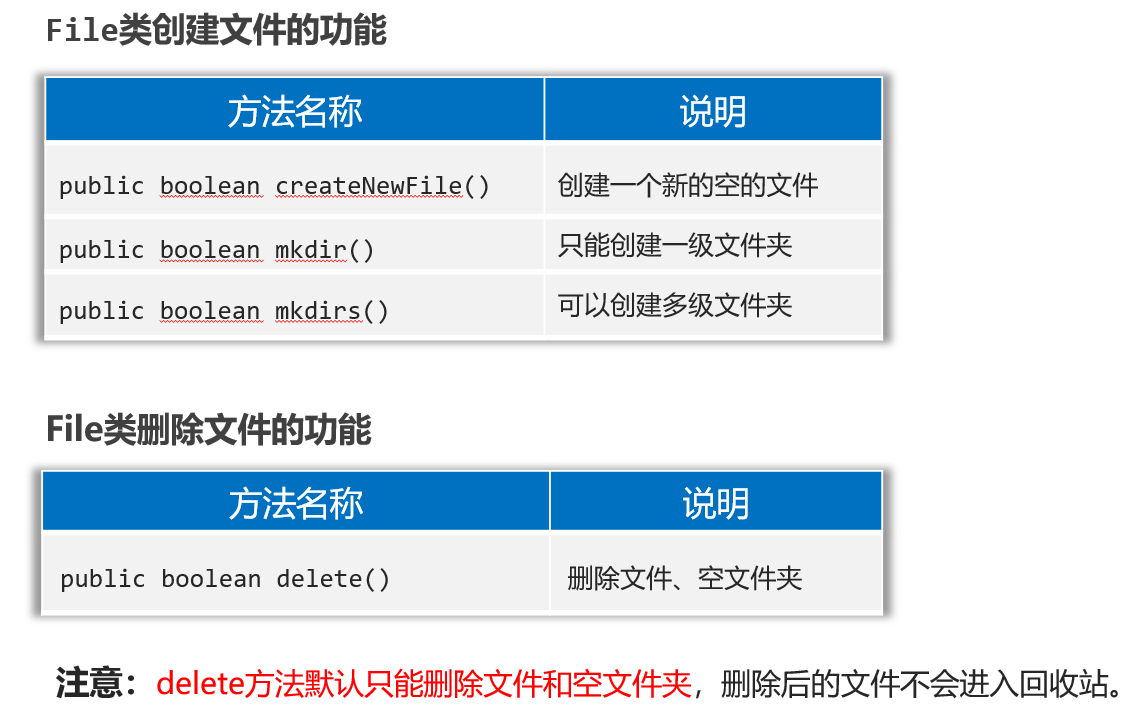
package com.itheima.d1_file;import java.io.File;/*** 目标:掌握File创建和删除文件相关的方法。*/
public class FileTest3 {public static void main(String[] args) throws Exception {// 1、public boolean createNewFile():创建一个新文件(文件内容为空),创建成功返回true,文件存在则会创建失败返回false。File f1 = new File("D:/resource/itheima2.txt");System.out.println(f1.createNewFile());// 2、public boolean mkdir():用于创建文件夹,注意:只能创建一级文件夹File f2 = new File("D:/resource/aaa");System.out.println(f2.mkdir());// 3、public boolean mkdirs():用于创建文件夹,注意:可以创建多级文件夹File f3 = new File("D:/resource/bbb/ccc/ddd/eee/fff/ggg");System.out.println(f3.mkdirs());// 3、public boolean delete():删除文件,或者空文件,注意:不能删除非空文件夹,删除非空文件夹回返回false。System.out.println(f1.delete());System.out.println(f2.delete());File f4 = new File("D:/resource");System.out.println(f4.delete());}
}
File类遍历文件夹

话不多少上代码,演示一下
/*** 目标:掌握File提供的遍历文件夹的方法。*/
public class FileTest4 {public static void main(String[] args) {// 1、public String[] list():获取当前目录下所有的"一级文件名称"到一个字符串数组中去返回。File f1 = new File("D:\\course\\待研发内容");String[] names = f1.list();for (String name : names) {System.out.println(name);}// 2、public File[] listFiles():(重点)获取当前目录下所有的"一级文件对象"到一个文件对象数组中去返回(重点)File[] files = f1.listFiles();for (File file : files) {System.out.println(file.getAbsolutePath());}File f = new File("D:/resource/aaa");File[] files1 = f.listFiles();System.out.println(Arrays.toString(files1));}
}
这里需要注意几个问题
- 当主调是文件时,或者路径不存在时,返回null
- 当主调是空文件夹时,返回一个长度为0的数组
- 当主调是一个有内容的文件夹时,将里面所有一级文件和文件夹路径放在File数组中,并把数组返回
- 当主调是一个文件夹,且里面有隐藏文件时,将里面所有文件和文件夹的路径放在FIle数组中,包含隐藏文件
- 当主调是一个文件夹,但是没有权限访问时,返回null
文件搜索(使用递归)
案例:搜索QQ程序并启动程序
package com.itheima.d2_recursion;import java.io.File;/*** 目标:掌握文件搜索的实现。*/
public class RecursionTest3 {public static void main(String[] args) throws Exception {searchFile(new File("D:/") , "QQ.exe");}/*** 去目录下搜索某个文件* @param dir 目录* @param fileName 要搜索的文件名称*/public static void searchFile(File dir, String fileName) throws Exception {// 1、把非法的情况都拦截住if(dir == null || !dir.exists() || dir.isFile()){return; // 代表无法搜索}// 2、dir不是null,存在,一定是目录对象。// 获取当前目录下的全部一级文件对象。File[] files = dir.listFiles();// 3、判断当前目录下是否存在一级文件对象,以及是否可以拿到一级文件对象。if(files != null && files.length > 0){// 4、遍历全部一级文件对象。for (File f : files) {// 5、判断文件是否是文件,还是文件夹if(f.isFile()){// 是文件,判断这个文件名是否是我们要找的if(f.getName().contains(fileName)){System.out.println("找到了:" + f.getAbsolutePath());// 启动程序Runtime runtime = Runtime.getRuntime();runtime.exec(f.getAbsolutePath());}}else {// 是文件夹,继续重复这个过程(递归)searchFile(f, fileName);}}}}
}
递归删除非空目录
package com.itheima.file;import java.io.File;public class FileDeleteTest {public static void main(String[] args) {File file = new File("day08\\a");deleteDir(file);}/*** 递归删除非空文件夹** @param dir 文件夹*/public static void deleteDir(File dir) {if (dir.exists()) {File[] files = dir.listFiles();if (files != null) {for (File file : files) {if (file.isDirectory()) {deleteDir(file);} else {file.delete();}}}dir.delete();}}}字符集
ASCII和GBK字符集

Unicode字符集

UTF-8字符集



乱码现象
当编码和解码使用的字符集不一致是会出现乱码情况
例如使用GBK存储“a我m”,这是改变文件存储方式为UTF-8会出现“a??m”的情况
a我m
GBK 0xxxxxxx 1xxxxxxx xxxxxxxx 0xxxxxxx (GBK汉字占1个字节,以1开头)
UTF-8 a ? ? m (UTF-8汉字占3个字节,以1110开头)
字符的编码和解码
其实String类类中就提供了相应的方法,可以完成编码和解码的操作。
- 编码:把字符串按照指定的字符集转换为字节数组
- 解码:把字节数组按照指定的字符集转换为字符串
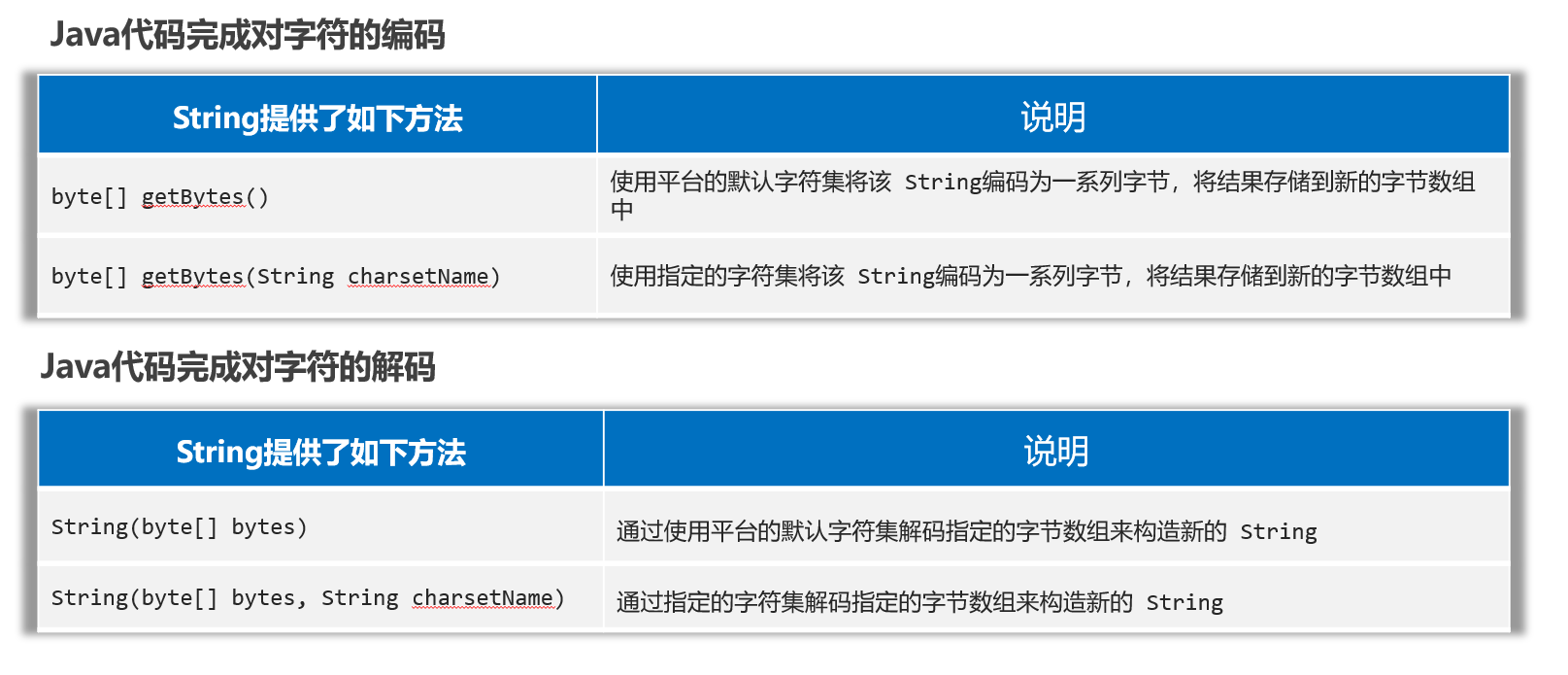
package com.itheima.d3_charset;import java.util.Arrays;/*** 目标:掌握如何使用Java代码完成对字符的编码和解码。*/
public class Test {public static void main(String[] args) throws Exception {// 1、编码String data = "a我b";byte[] bytes = data.getBytes(); // 默认是按照平台字符集(UTF-8)进行编码的。(看你IDEA怎么设置的编码方式)System.out.println(Arrays.toString(bytes));// 按照指定字符集进行编码。byte[] bytes1 = data.getBytes("GBK");System.out.println(Arrays.toString(bytes1));// 2、解码String s1 = new String(bytes); // 默认是按照平台字符集(UTF-8)进行编码的。(看你IDEA怎么设置的编码方式)System.out.println(s1);String s2 = new String(bytes1, "GBK");System.out.println(s2);}
}// 运行结果,输出负数是因为二进制中以1开头表示负数
[97, -26, -120, -111, 98]
[97, -50, -46, 98]
a我b
a我b
IO流
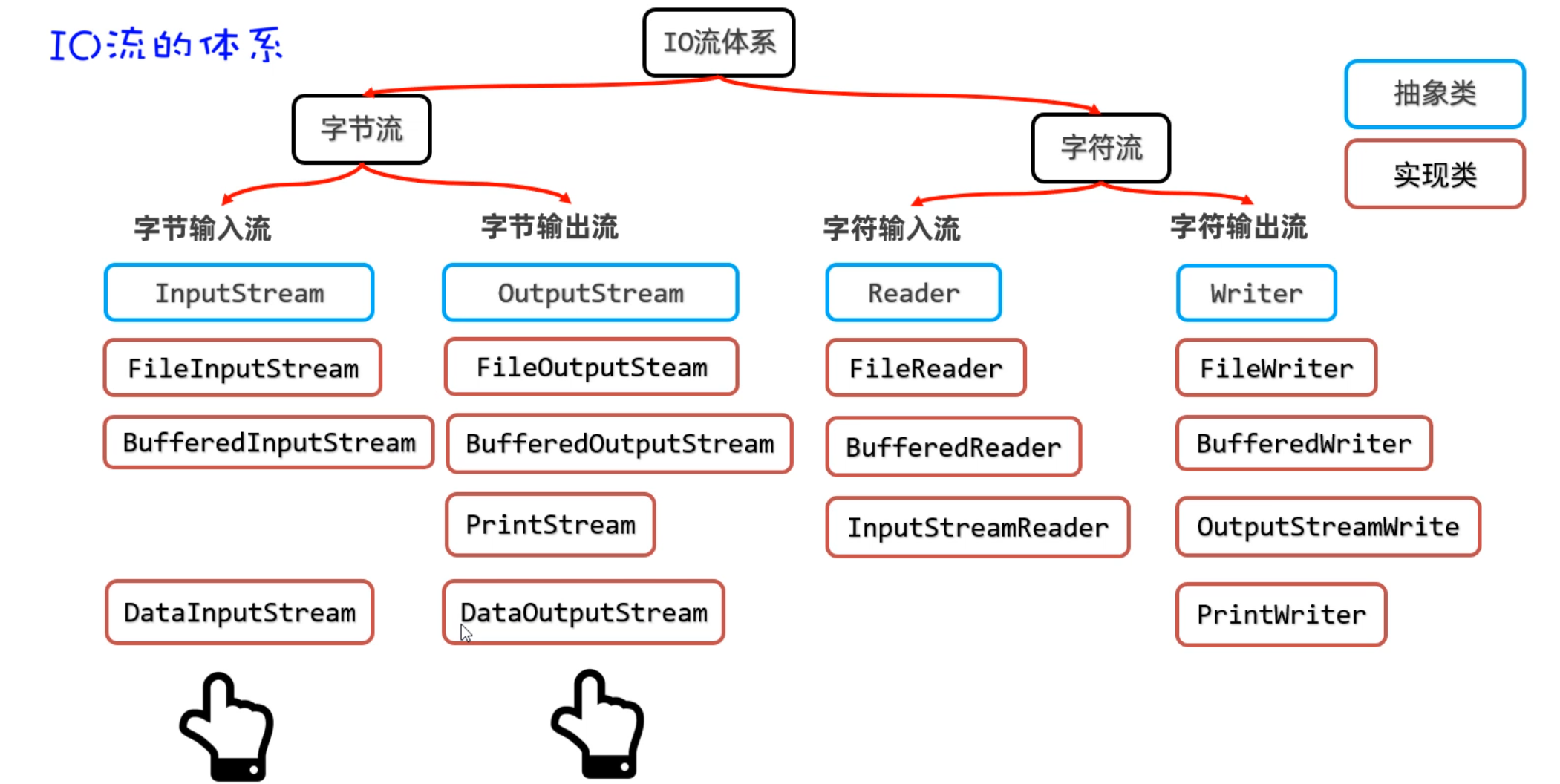
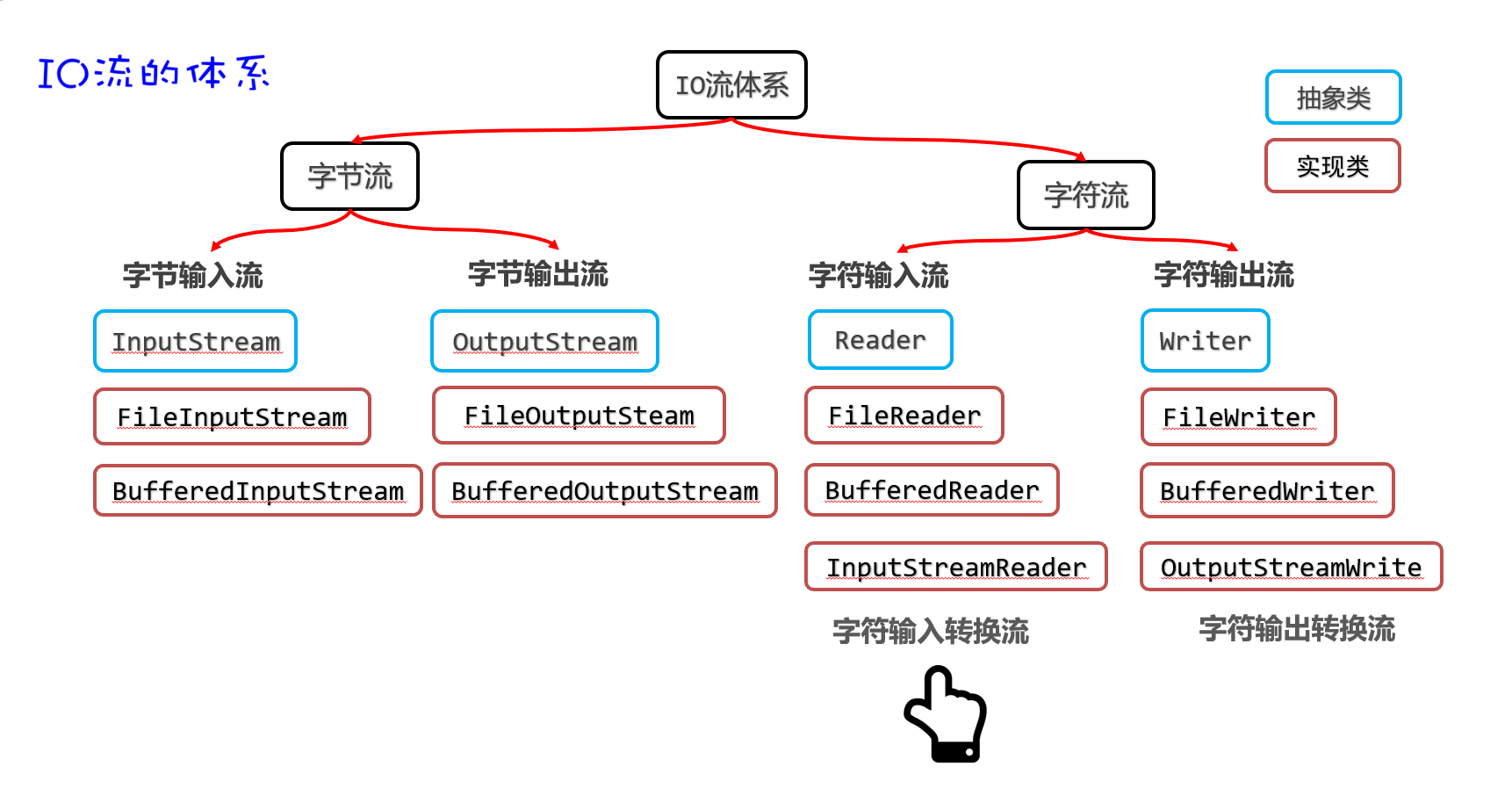
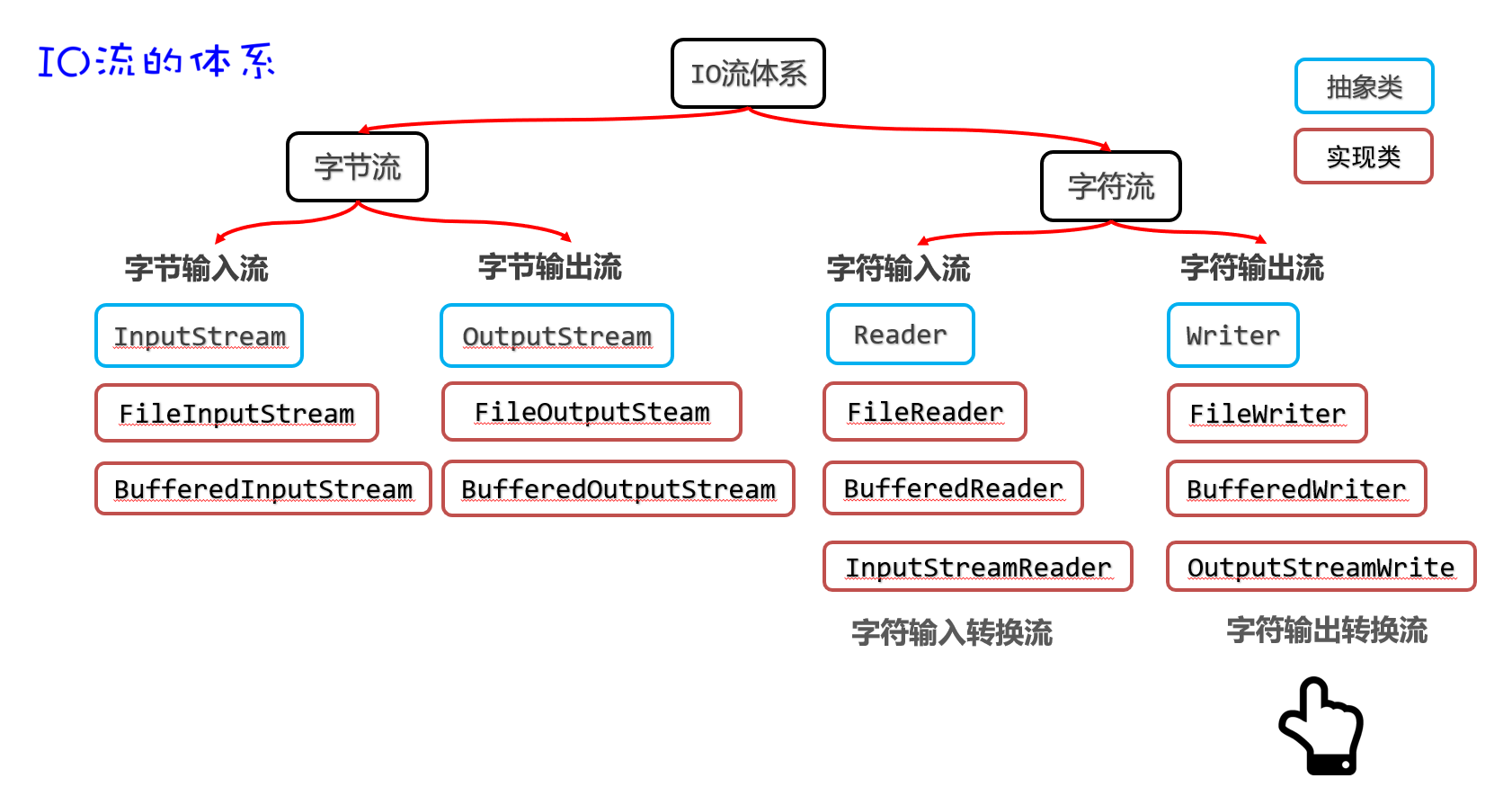
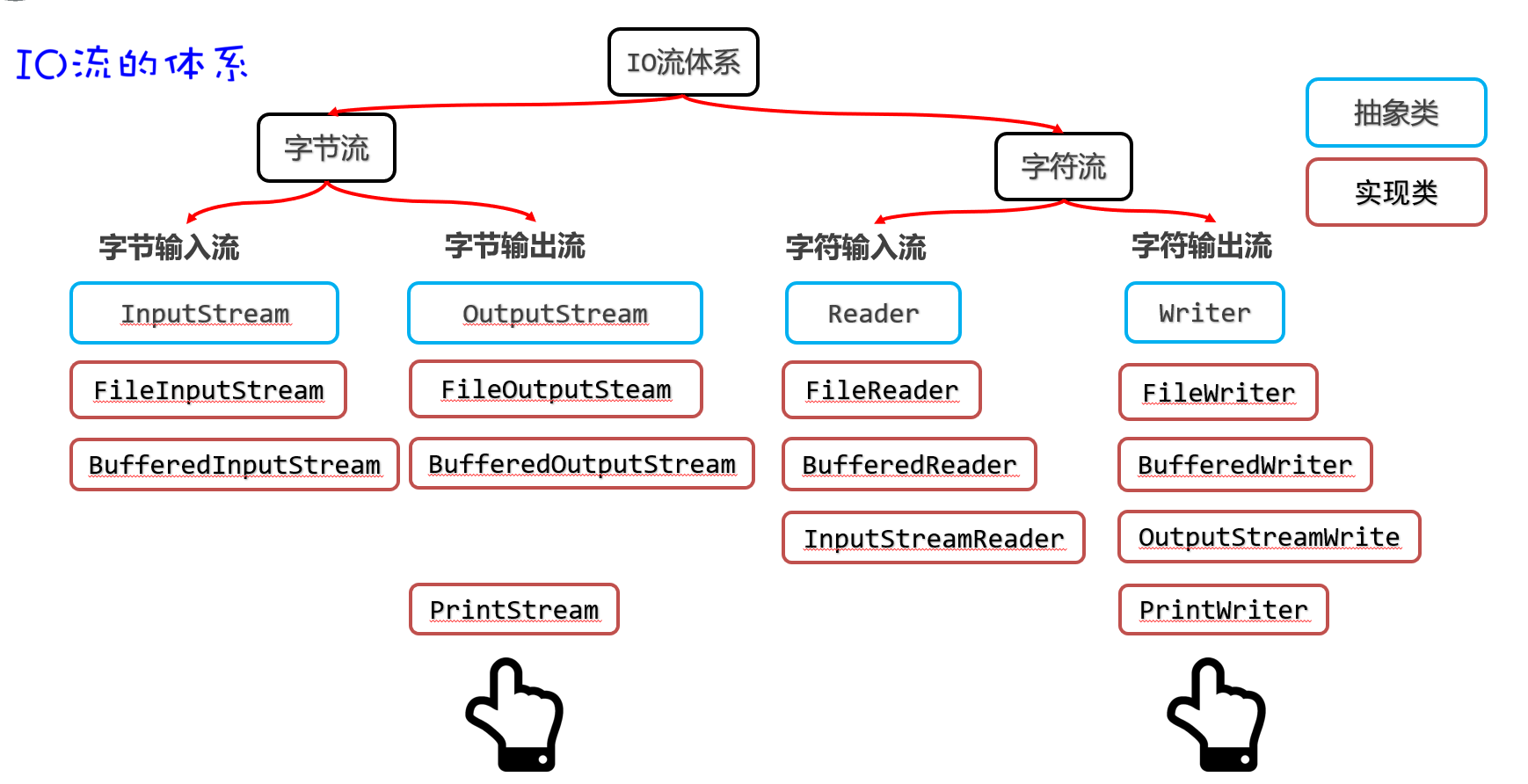
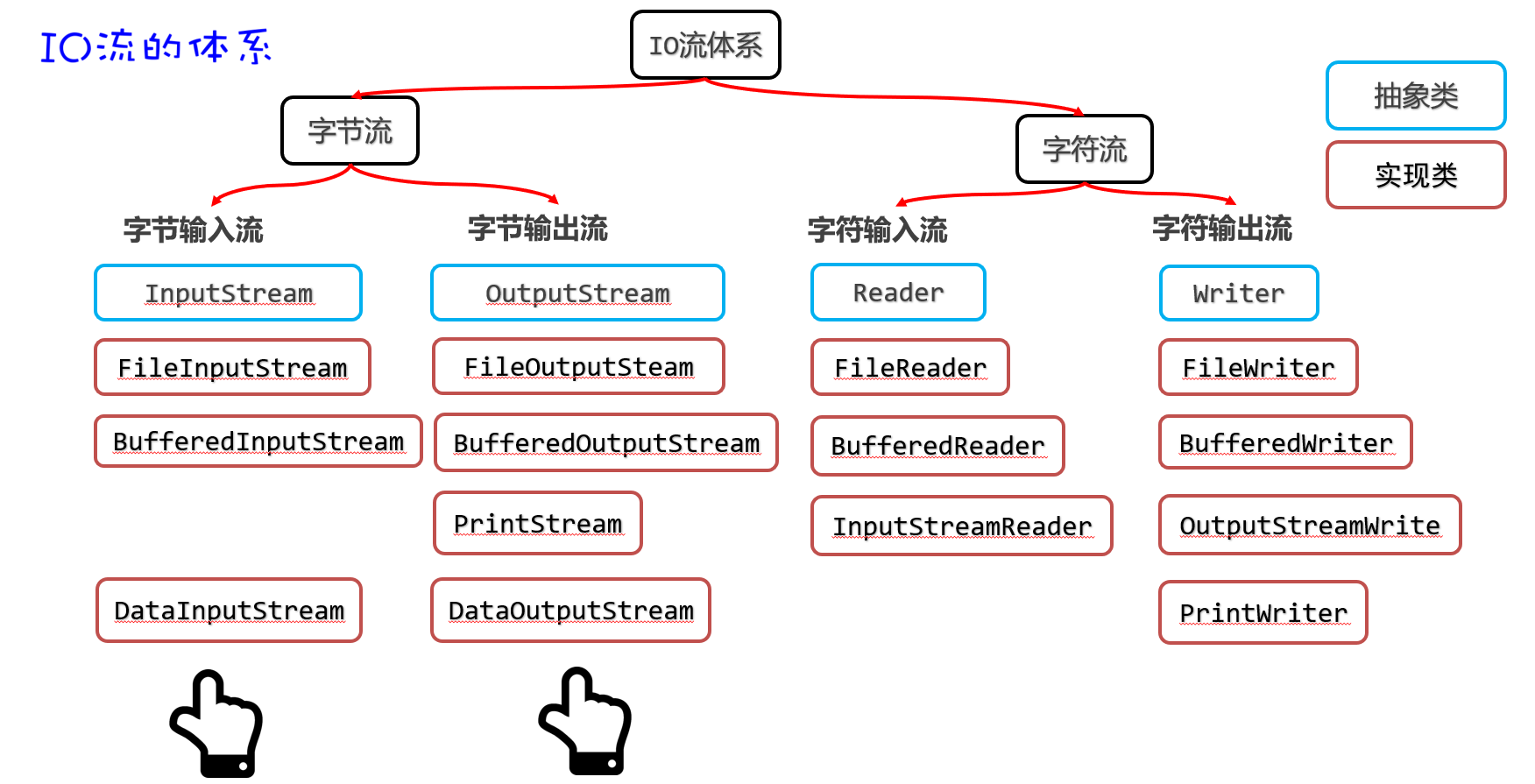
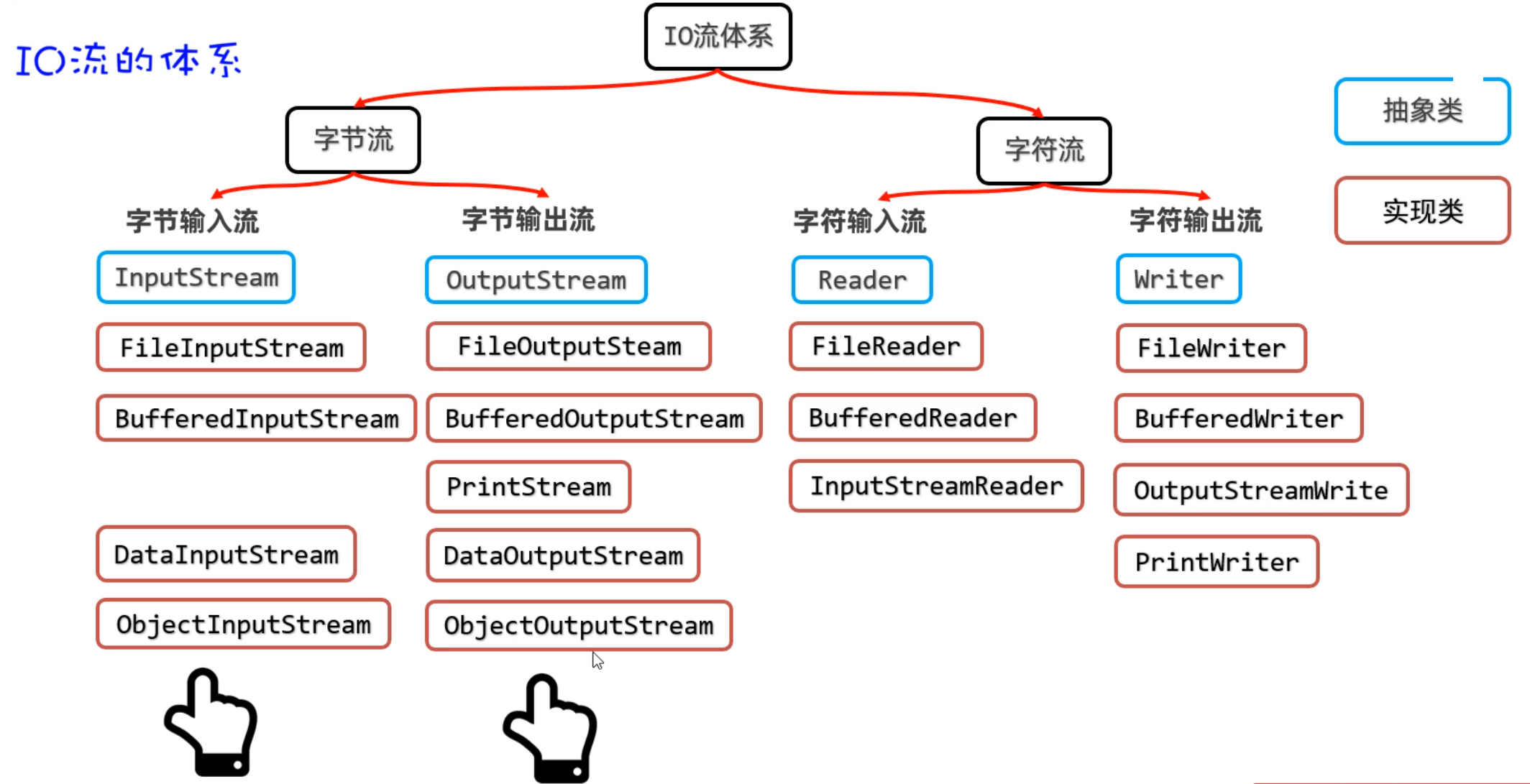
IO流的分类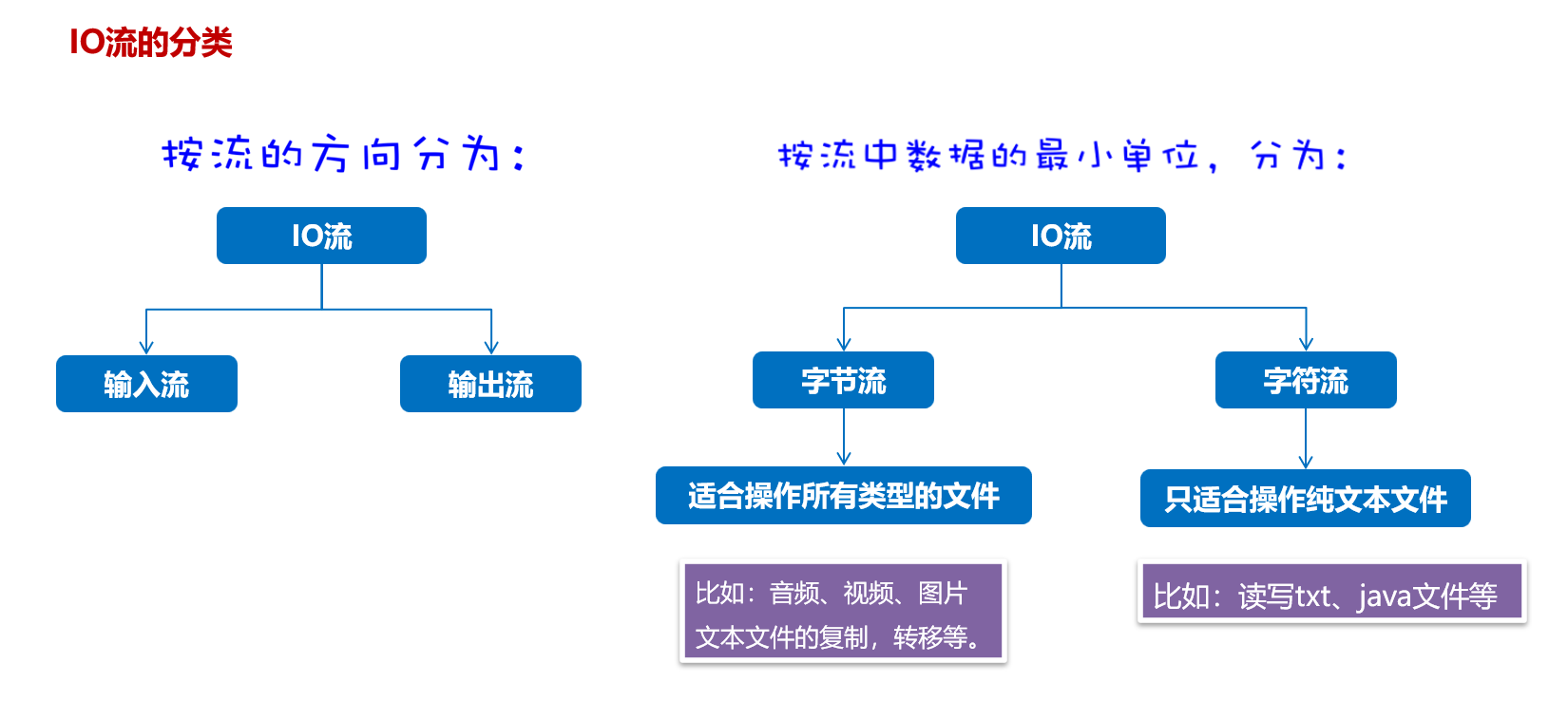


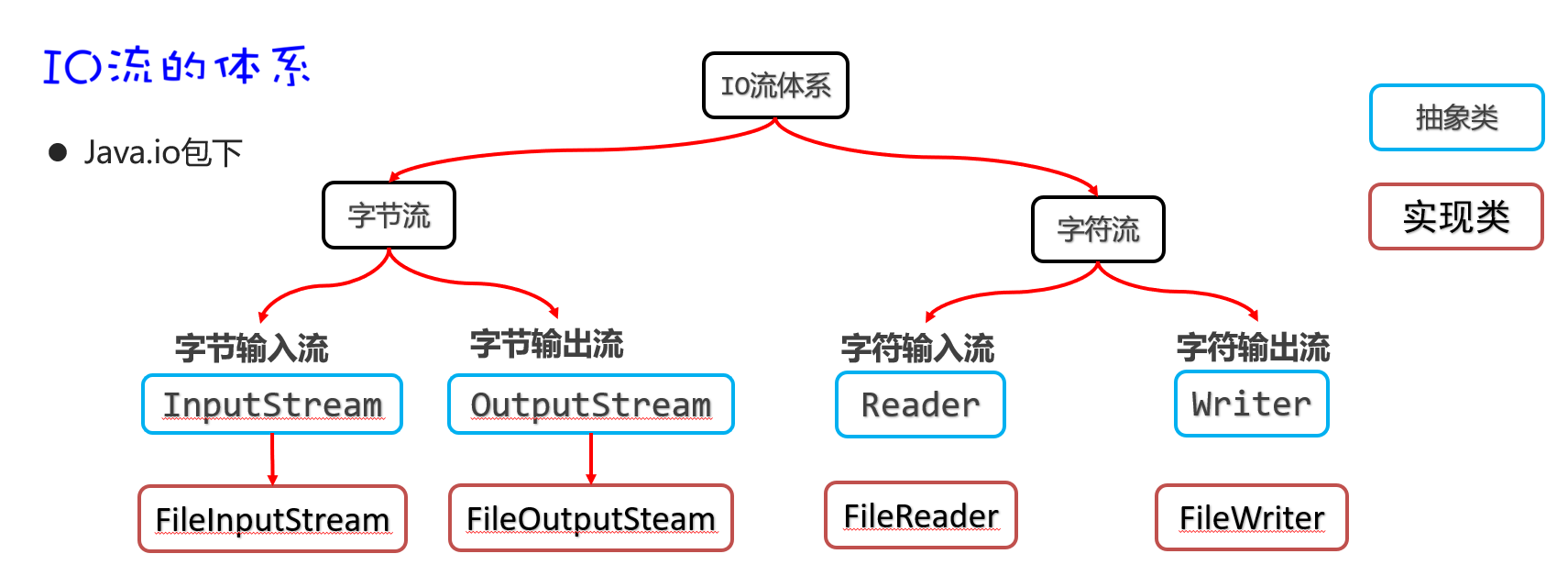
比较全的IO体系
字节字符流
FileInputStream

每次读取一个字节
使用FileInputStream读取文件中的字节数据,步骤如下
第一步:创建FileInputStream文件字节输入流管道,与源文件接通。
第二步:调用read()方法开始读取文件的字节数据。
第三步:调用close()方法释放资源
代码如下:
/*** 目标:掌握文件字节输入流,每次读取一个字节。*/
public class FileInputStreamTest1 {public static void main(String[] args) throws Exception {// 1、创建文件字节输入流管道,与源文件接通。InputStream is = new FileInputStream(("file-io-app\\src\\itheima01.txt"));// 2、开始读取文件的字节数据。// public int read():每次读取一个字节返回,如果没有数据了,返回-1.int b; // 用于记住读取的字节。while ((b = is.read()) != -1){System.out.print((char) b);}//3、流使用完毕之后,必须关闭!释放系统资源!is.close();}
}
这里需要注意一个问题:由于一个中文在UTF-8编码方案中是占3个字节,采用一次读取一个字节的方式,读一个字节就相当于读了1/3个汉字,此时将这个字节转换为字符,是会有乱码的。
每次读取多个字节
各位同学,在上一节我们学习了FileInputStream调用read()方法,可以一次读取一个字节。但是这种读取方式效率太太太太慢了。 为了提高效率,我们可以使用另一个read(byte[] bytes)的重载方法,可以一次读取多个字节,至于一次读多少个字节,就在于你传递的数组有多大。
使用FileInputStream一次读取多个字节的步骤如下
第一步:创建FileInputStream文件字节输入流管道,与源文件接通。
第二步:调用read(byte[] bytes)方法开始读取文件的字节数据。
第三步:调用close()方法释放资源
代码如下:
/*** 目标:掌握使用FileInputStream每次读取多个字节。*/
public class FileInputStreamTest2 {public static void main(String[] args) throws Exception {// 1、创建一个字节输入流对象代表字节输入流管道与源文件接通。InputStream is = new FileInputStream("file-io-app\\src\\itheima02.txt");// 2、开始读取文件中的字节数据:每次读取多个字节。// public int read(byte b[]) throws IOException// 每次读取多个字节到字节数组中去,返回读取的字节数量,读取完毕会返回-1.// 3、使用循环改造。byte[] buffer = new byte[3];int len; // 记住每次读取了多少个字节。 abc 66while ((len = is.read(buffer)) != -1){// 注意:读取多少,倒出多少。String rs = new String(buffer, 0 , len);System.out.print(rs);}// 性能得到了明显的提升!!// 这种方案也不能避免读取汉字输出乱码的问题!!is.close(); // 关闭流}
}
- 需要我们注意的是:read(byte[] bytes)它的返回值,表示当前这一次读取的字节个数。
假设有一个a.txt文件如下:
abcde
每次读取过程如下
也就是说,并不是每次读取的时候都把数组装满,比如数组是 byte[] bytes = new byte[3];
第一次调用read(bytes)读取了3个字节(分别是97,98,99),并且往数组中存,此时返回值就是3
第二次调用read(bytes)读取了2个字节(分别是99,100),并且往数组中存,此时返回值是2
第三次调用read(bytes)文件中后面已经没有数据了,此时返回值为-1
- 还需要注意一个问题:采用一次读取多个字节的方式,也是可能有乱码的。因为也有可能读取到半个汉字的情况。
一次性读取全部字符
同学们,前面我们到的读取方式,不管是一次读取一个字节,还是一次读取多个字节,都有可能有乱码。那么接下来我们介绍一种,不出现乱码的读取方式。
我们可以一次性读取文件中的全部字节,然后把全部字节转换为一个字符串,就不会有乱码了。

// 1、一次性读取完文件的全部字节到一个字节数组中去。
// 创建一个字节输入流管道与源文件接通
InputStream is = new FileInputStream("file-io-app\\src\\itheima03.txt");// 2、准备一个字节数组,大小与文件的大小正好一样大。
File f = new File("file-io-app\\src\\itheima03.txt");
long size = f.length();
byte[] buffer = new byte[(int) size];int len = is.read(buffer);
System.out.println(new String(buffer));//3、关闭流
is.close();

// 1、一次性读取完文件的全部字节到一个字节数组中去。
// 创建一个字节输入流管道与源文件接通
InputStream is = new FileInputStream("file-io-app\\src\\itheima03.txt");//2、调用方法读取所有字节,返回一个存储所有字节的字节数组。
byte[] buffer = is.readAllBytes();
System.out.println(new String(buffer));//3、关闭流
is.close();
最后,还是要注意一个问题:一次读取所有字节虽然可以解决乱码问题,但是文件不能过大,如果文件过大,可能导致内存溢出。
字节流的使用场景

FileOutputSteam

使用FileOutputStream往文件中写数据的步骤如下:
第一步:创建FileOutputStream文件字节输出流管道,与目标文件接通。
第二步:调用wirte()方法往文件中写数据
第三步:调用close()方法释放资源
代码如下:
/*** 目标:掌握文件字节输出流FileOutputStream的使用。*/
public class FileOutputStreamTest4 {public static void main(String[] args) throws Exception {// 1、创建一个字节输出流管道与目标文件接通。// 覆盖管道:覆盖之前的数据
// OutputStream os =
// new FileOutputStream("file-io-app/src/itheima04out.txt");// 追加数据的管道OutputStream os =new FileOutputStream("file-io-app/src/itheima04out.txt", true);// 2、开始写字节数据出去了os.write(97); // 97就是一个字节,代表aos.write('b'); // 'b'也是一个字节// os.write('磊'); // [ooo] 默认只能写出去一个字节byte[] bytes = "我爱你中国abc".getBytes();os.write(bytes);os.write(bytes, 0, 15);// 换行符os.write("\r\n".getBytes());os.close(); // 关闭流}
}
字节流复制文件
可以复制所有格式的文件,原因是文件在计算机的存储方式就是字节

package com.itheima.d4_byte_stream;import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;/*** 目标:使用字节流完成对文件的复制操作。*/
public class CopyTest5 {public static void main(String[] args) throws Exception {// 需求:复制照片。// 1、创建一个字节输入流管道与源文件接通InputStream is = new FileInputStream("file-io-app\\src\\itheima03.txt");// 2、创建一个字节输出流管道与目标文件接通。OutputStream os = new FileOutputStream("file-io-app\\src\\itheima03copy.txt");// 3、创建一个字节数组,负责转移字节数据。byte[] buffer = new byte[1024]; // 1KB.// 4、从字节输入流中读取字节数据,写出去到字节输出流中。读多少写出去多少。int len; // 记住每次读取了多少个字节。while ((len = is.read(buffer)) != -1){os.write(buffer, 0, len);}os.close();is.close();System.out.println("复制完成!!");}
}
这种方式在释放资源的时候可能会存在问题,因为代码中间可能存在会报异常的错误代码,导致代码无法执行下去,最后导致资源得不到释放
复制文件夹
package com.itheima.io;import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;/*** 复制文件夹*/
public class DirCopyTest {public static void main(String[] args) throws Exception {String originPath = "E:\\copy\\projects";String pastePath = "E:\\copy\\paste";dirCopy(originPath, pastePath);}public static void dirCopy(String originPath, String pastePath) throws Exception {File file = new File(originPath);// 文件if (file.isFile() || file.listFiles().length == 0) {return;}// 文件夹File file2 = new File(pastePath + "\\" + file.getName());file2.mkdir();File[] files = file.listFiles();for (File file3 : files) {if (file3.isFile()) {copyFile(file3, file2.getAbsolutePath());} else {dirCopy(file3.getAbsolutePath(), file2.getAbsolutePath());}}}// 复制文件public static void copyFile(File file, String pastePath) throws Exception {try (FileInputStream fis = new FileInputStream(file);FileOutputStream fos = new FileOutputStream(pastePath + "\\" + file.getName())) {byte[] buffer = new byte[1024];int len;while ((len = fis.read(buffer)) != -1) {fos.write(buffer, 0, len);}}}
}IO资源释放
JDK7以前的资源释放
在JDK7版本以前,我们可以使用try...catch...finally语句来处理。格式如下
try{//有可能产生异常的代码
}catch(异常类 e){//处理异常的代码
}finally{//释放资源的代码//finally里面的代码有一个特点,不管异常是否发生,finally里面的代码都会执行。
}
改造上面的字节流复制文件的代码:
public class Test2 {public static void main(String[] args) {InputStream is = null;OutputStream os = null;try {System.out.println(10 / 0);// 1、创建一个字节输入流管道与源文件接通is = new FileInputStream("file-io-app\\src\\itheima03.txt");// 2、创建一个字节输出流管道与目标文件接通。os = new FileOutputStream("file-io-app\\src\\itheima03copy.txt");System.out.println(10 / 0);// 3、创建一个字节数组,负责转移字节数据。byte[] buffer = new byte[1024]; // 1KB.// 4、从字节输入流中读取字节数据,写出去到字节输出流中。读多少写出去多少。int len; // 记住每次读取了多少个字节。while ((len = is.read(buffer)) != -1){os.write(buffer, 0, len);}System.out.println("复制完成!!");} catch (IOException e) {e.printStackTrace();} finally {// 释放资源的操作try {if(os != null) os.close();} catch (IOException e) {e.printStackTrace();}try {if(is != null) is.close();} catch (IOException e) {e.printStackTrace();}}}
}
代码写到这里,有很多同学就已经看不下去了。是的,我也看不下去,本来几行代码就写完了的,加上try...catch...finally之后代码多了十几行,而且阅读性并不高。难受....
JDK7以后的资源释放
try-with-resources
刚才很多同学已经发现了try...catch...finally处理异常,并释放资源代码比较繁琐。Java在JDK7版本为我们提供了一种简化的是否资源的操作,它会自动是否资源。代码写起来也想当简单。
格式如下:
try(资源对象1; 资源对象2;){使用资源的代码
}catch(异常类 e){处理异常的代码
}//注意:注意到没有,这里没有释放资源的代码。它会自动是否资源
代码如下:
package com.itheima.d5_resource;import java.io.*;/*** 目标:掌握释放资源的方式:try-with-resource*/
public class Test3 {public static void main(String[] args) {try (// 1、创建一个字节输入流管道与源文件接通InputStream is = new FileInputStream("file-io-app\\src\\itheima03.txt");// 2、创建一个字节输出流管道与目标文件接通。OutputStream os = new FileOutputStream("file-io-app\\src\\itheima03copy.txt");// 注意:这里只能放置资源对象。(流对象)// int age = 21;// 什么是资源呢?资源都是会实现AutoCloseable接口。资源都会有一个close方法,并且资源放到这里后// 用完之后,会被自动调用其close方法完成资源的释放操作。MyConnection conn = new MyConnection();){// 3、创建一个字节数组,负责转移字节数据。byte[] buffer = new byte[1024]; // 1KB.// 4、从字节输入流中读取字节数据,写出去到字节输出流中。读多少写出去多少。int len; // 记住每次读取了多少个字节。while ((len = is.read(buffer)) != -1){os.write(buffer, 0, len);}System.out.println(conn);System.out.println("复制完成!!");} catch (Exception e) {e.printStackTrace();}}
}
package com.itheima.d5_resource;public class MyConnection implements AutoCloseable{@Overridepublic void close() throws Exception {System.out.println("释放了与某个硬件的链接资源~~~~");}
}
注意:try()括号里面只能放置资源对象。(流对象)
什么是资源呢?资源都是会实现AutoCloseable接口。资源都会有一个close方法,并且资源放到这里后用完之后,会被自动调用其close方法完成资源的释放操作。
FileReader类

/*** 目标:掌握文件字符输入流。*/
public class FileReaderTest1 {public static void main(String[] args) {try (// 1、创建一个文件字符输入流管道与源文件接通Reader fr = new FileReader("io-app2\\src\\itheima01.txt");){// 2、一个字符一个字符的读(性能较差)
// int c; // 记住每次读取的字符编号。
// while ((c = fr.read()) != -1){
// System.out.print((char) c);
// }// 每次读取一个字符的形式,性能肯定是比较差的。// 3、每次读取多个字符。(性能是比较不错的!)char[] buffer = new char[3];int len; // 记住每次读取了多少个字符。while ((len = fr.read(buffer)) != -1){// 读取多少倒出多少System.out.print(new String(buffer, 0, len));}} catch (Exception e) {e.printStackTrace();}}
}
FileWriter类
package com.itheima.d1_char_stream;import java.io.FileWriter;
import java.io.Writer;/*** 目标:掌握文件字符输出流:写字符数据出去*/
public class FileWriterTest2 {public static void main(String[] args) {try (// 0、创建一个文件字符输出流管道与目标文件接通。// 覆盖管道// Writer fw = new FileWriter("io-app2/src/itheima02out.txt");// 追加数据的管道Writer fw = new FileWriter("io-app2/src/itheima02out.txt", true);){// 1、public void write(int c):写一个字符出去fw.write('a');fw.write(97);//fw.write('磊'); // 写一个字符出去fw.write("\r\n"); // 换行// 2、public void write(String c)写一个字符串出去fw.write("我爱你中国abc");fw.write("\r\n");// 3、public void write(String c ,int pos ,int len):写字符串的一部分出去fw.write("我爱你中国abc", 0, 5);fw.write("\r\n");// 4、public void write(char[] buffer):写一个字符数组出去char[] buffer = {'黑', '马', 'a', 'b', 'c'};fw.write(buffer);fw.write("\r\n");// 5、public void write(char[] buffer ,int pos ,int len):写字符数组的一部分出去fw.write(buffer, 0, 2);fw.write("\r\n");} catch (Exception e) {e.printStackTrace();}}
}
FileWriter字符输出流注意事项!!!
FileWriter写完数据之后,必须刷新或者关闭,写出去的数据才能生效。
比如:下面的代码只调用了写数据的方法,没有关流的方法。当你打开目标文件时,是看不到任何数据的。
//1.创建FileWriter对象
Writer fw = new FileWriter("io-app2/src/itheima03out.txt");//2.写字符数据出去
fw.write('a');
fw.write('b');
fw.write('c');
而下面的代码,加上了flush()方法之后,数据就会立即到目标文件中去。
//1.创建FileWriter对象
Writer fw = new FileWriter("io-app2/src/itheima03out.txt");//2.写字符数据出去
fw.write('a');
fw.write('b');
fw.write('c');//3.刷新
fw.flush();
下面的代码,调用了close()方法,数据也会立即到文件中去。因为close()方法在关闭流之前,会将内存中缓存的数据先刷新到文件,再关流。
//1.创建FileWriter对象
Writer fw = new FileWriter("io-app2/src/itheima03out.txt");//2.写字符数据出去
fw.write('a');
fw.write('b');
fw.write('c');//3.关闭流
fw.close(); //会先刷新,再关流
但是需要注意的是,关闭流之后,就不能在对流进行操作了。否则会出异常

缓冲流
字节缓冲流

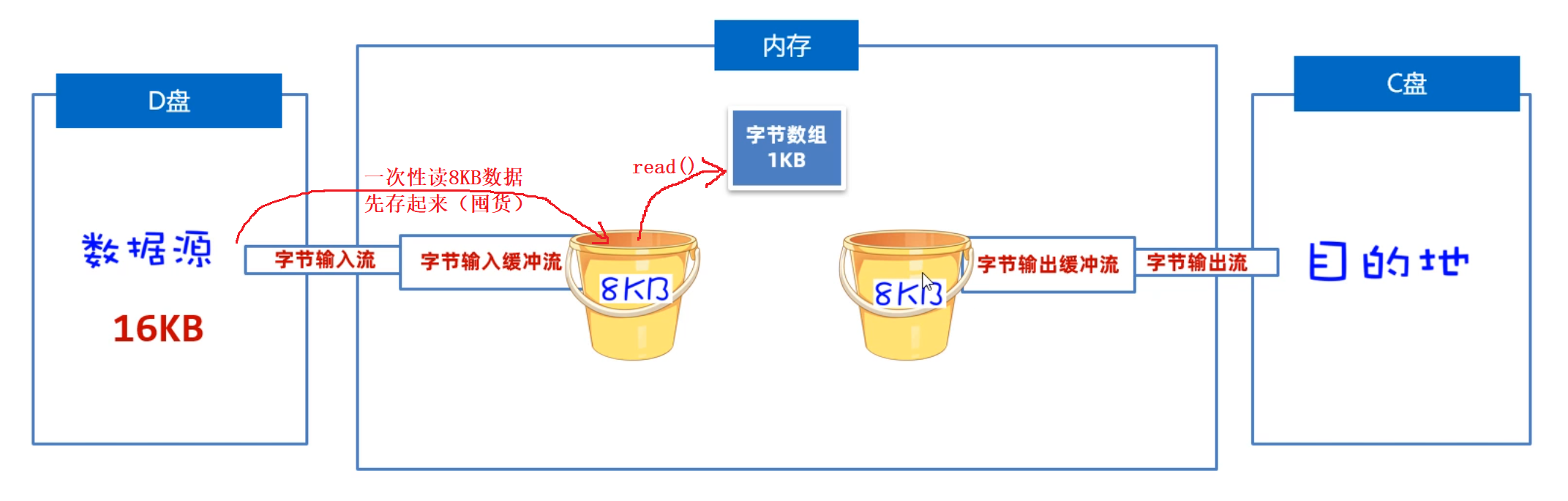
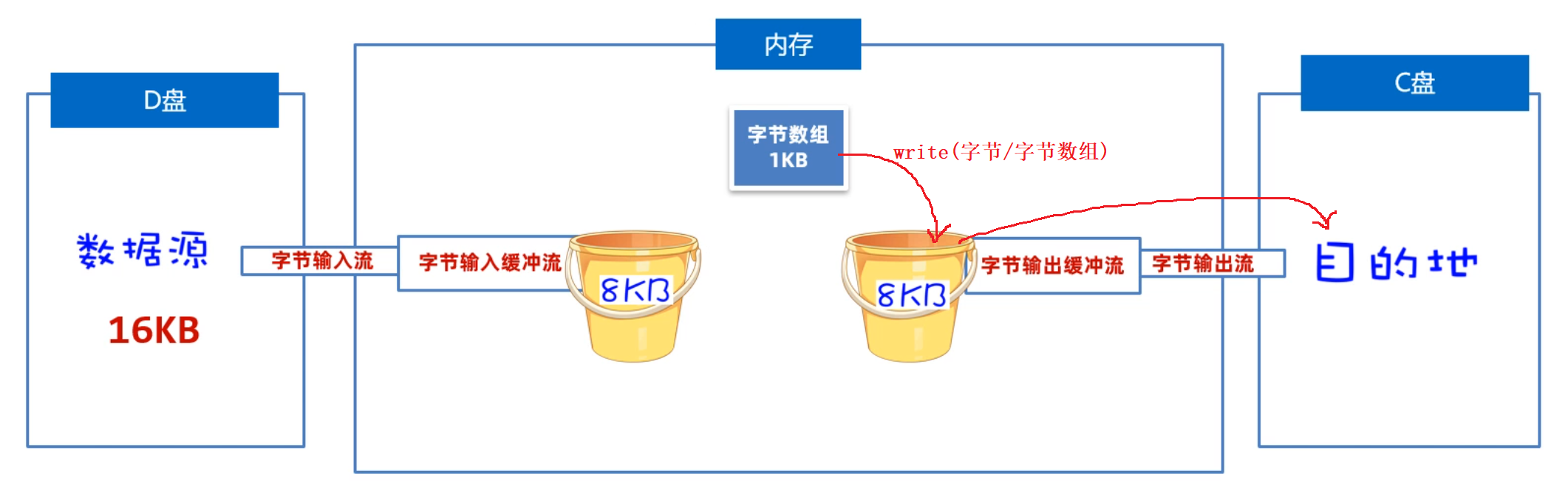
我们先来学习字节缓冲流是如何提高读写数据的性能的,原理如下图所示。是因为在缓冲流的底层自己封装了一个长度为8KB(8192byte)的字节数组,但是缓冲流不能单独使用,它需要依赖于原始流。
- 读数据时:它先用原始字节输入流一次性读取8KB的数据存入缓冲流内部的数组中(ps: 先一次多囤点货),再从8KB的字节数组中读取一个字节或者多个字节(把消耗屯的货)。
- 写数据时: 它是先把数据写到缓冲流内部的8BK的数组中(ps: 先攒一车货),等数组存满了,再通过原始的字节输出流,一次性写到目标文件中去(把囤好的货,一次性运走)。
在创建缓冲字节流对象时,需要封装一个原始流对象进来。构造方法如下

如果我们用缓冲流复制文件,代码写法如下:
public class BufferedInputStreamTest1 {public static void main(String[] args) {try (InputStream is = new FileInputStream("io-app2/src/itheima01.txt");// 1、定义一个字节缓冲输入流包装原始的字节输入流InputStream bis = new BufferedInputStream(is);OutputStream os = new FileOutputStream("io-app2/src/itheima01_bak.txt");// 2、定义一个字节缓冲输出流包装原始的字节输出流OutputStream bos = new BufferedOutputStream(os);){byte[] buffer = new byte[1024];int len;while ((len = bis.read(buffer)) != -1){bos.write(buffer, 0, len);}System.out.println("复制完成!!");} catch (Exception e) {e.printStackTrace();}}
}
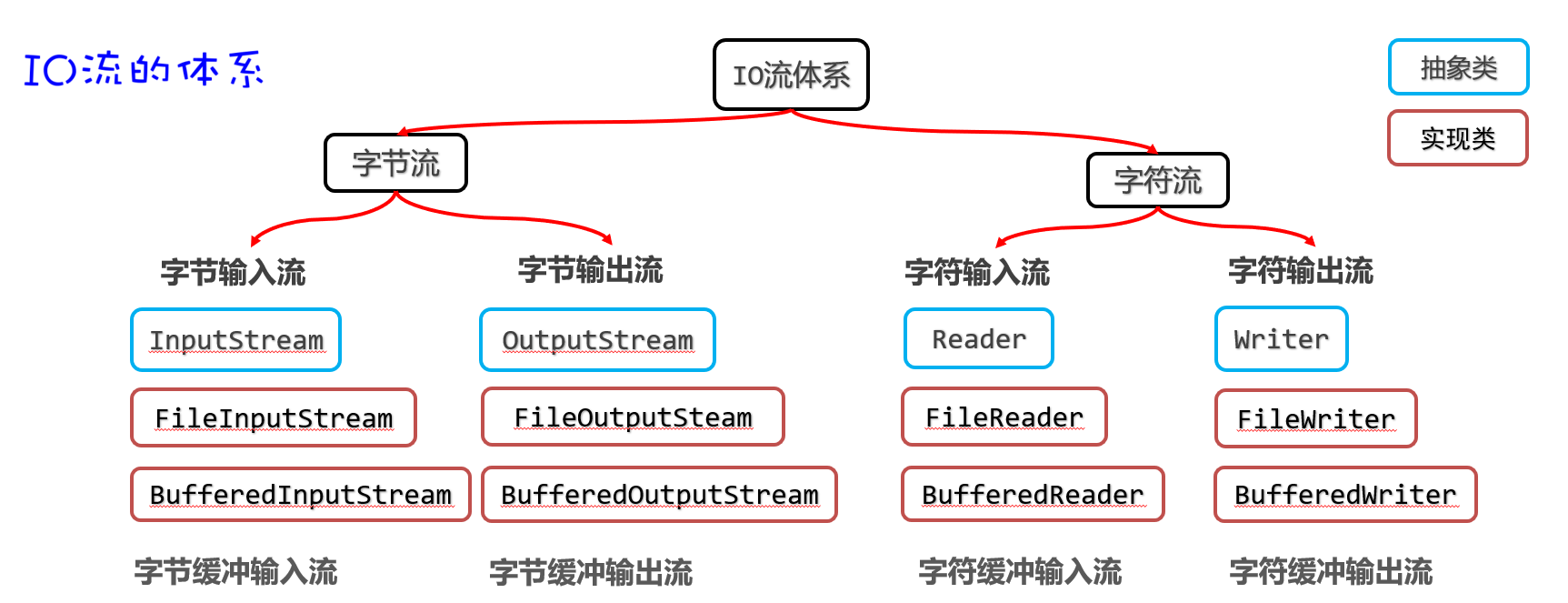
字符缓冲流
字符缓冲输入流
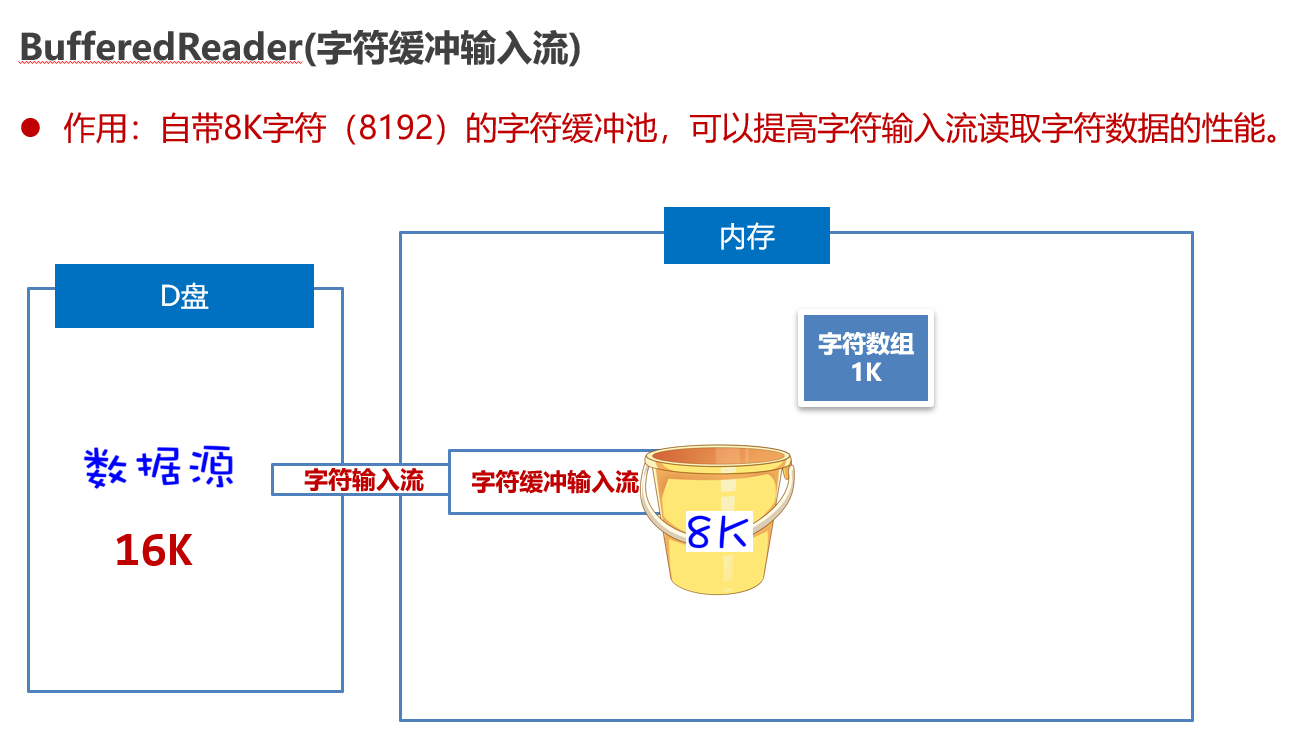

package com.itheima.d2_buffered_stream;import java.io.BufferedReader;
import java.io.FileReader;
import java.io.Reader;/*** 目标:掌握字符缓冲输入流的用法。*/
public class BufferedReaderTest2 {public static void main(String[] args) {try (Reader fr = new FileReader("io-app2\\src\\itheima04.txt");// 创建一个字符缓冲输入流包装原始的字符输入流BufferedReader br = new BufferedReader(fr);){
// char[] buffer = new char[3];
// int len;
// while ((len = br.read(buffer)) != -1){
// System.out.print(new String(buffer, 0, len));
// }
// System.out.println(br.readLine());
// System.out.println(br.readLine());
// System.out.println(br.readLine());
// System.out.println(br.readLine());String line; // 记住每次读取的一行数据while ((line = br.readLine()) != null){System.out.println(line);}} catch (Exception e) {e.printStackTrace();}}
}
字符缓冲输出流
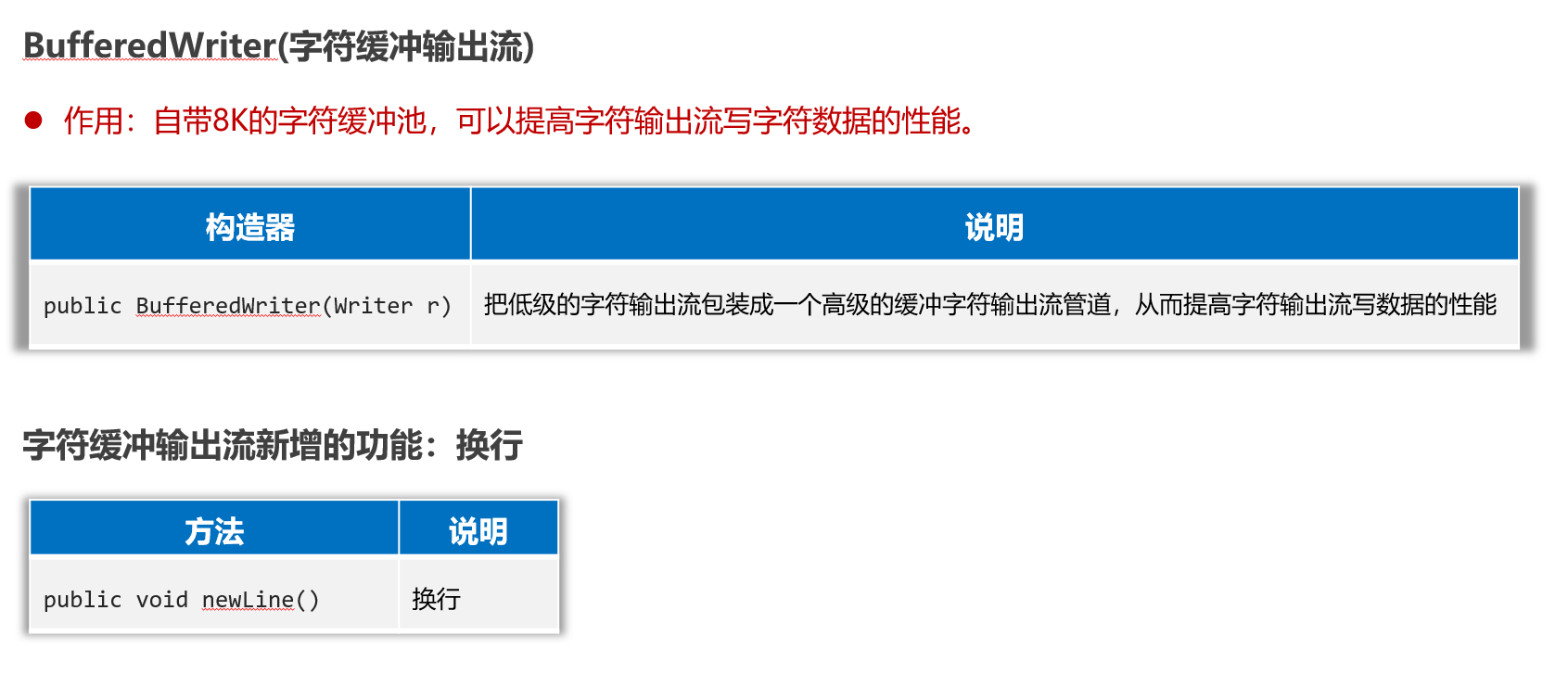
package com.itheima.d2_buffered_stream;import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.Writer;/*** 目标:掌握字符缓冲输出流的用法。*/
public class BufferedWriterTest3 {public static void main(String[] args) {try (Writer fw = new FileWriter("io-app2/src/itheima05out.txt", true);// 创建一个字符缓冲输出流管道包装原始的字符输出流// 不要使用多态写法,否则无法使用新增的特别方法BufferedWriter bw = new BufferedWriter(fw);){bw.write('a');bw.write(97);bw.write('磊');bw.newLine();bw.write("我爱你中国abc");bw.newLine();} catch (Exception e) {e.printStackTrace();}}
}
练习-顺序输出出师表

2.宫中府中,俱为一体,陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理,不宜偏私,使内外异法也。
1.先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。
3.侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下。愚以为宫中之事,事无大小,悉以咨之,然后施行,必能裨补阙漏,有所广益。
5.亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之信之,则汉室之隆,可计日而待也。
4.将军向宠,性行淑均,晓畅军事,试用于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。
9.今当远离,临表涕零,不知所言。
7.先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐托付不效,以伤先帝之明,故五月渡泸,深入不毛。今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。
6.臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。
8.愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。若无兴德之言,则责攸之、祎、允等之慢,以彰其咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏,臣不胜受恩感激。
package Java_project_1;import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;public class BufferedCharTest {public static void main(String[] args) {try(BufferedReader br=new BufferedReader(new FileReader("C:\\Java_Idear_project\\Java_project_1\\src\\csb.txt"));BufferedWriter bw=new BufferedWriter(new FileWriter("C:\\Java_Idear_project\\Java_project_1\\src\\new.txt"));) {List<String>data=new ArrayList<>();String line;while((line=br.readLine())!=null){data.add(line);}System.out.println(data);Collections.sort(data);System.out.println(data);for (String datum:data){bw.write(datum);bw.newLine();}}catch (Exception e){e.printStackTrace();}}
}
三.侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下。愚以为宫中之事,事无大小,悉以咨之,然后施行,必能裨补阙漏,有所广益。
壹.先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。
五.亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之信之,则汉室之隆,可计日而待也。
二.宫中府中,俱为一体,陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理,不宜偏私,使内外异法也。
四.将军向宠,性行淑均,晓畅军事,试用于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。
陆.臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。
九.今当远离,临表涕零,不知所言。
柒.先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐托付不效,以伤先帝之明,故五月渡泸,深入不毛。今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。
八.愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。若无兴德之言,则责攸之、祎、允等之慢,以彰其咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏,臣不胜受恩感激。
package Java_project_1;import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;public class BufferedCharTest {public static void main(String[] args) {try(BufferedReader br=new BufferedReader(new FileReader("C:\\Java_Idear_project\\Java_project_1\\src\\csb.txt"));BufferedWriter bw=new BufferedWriter(new FileWriter("C:\\Java_Idear_project\\Java_project_1\\src\\new.txt"));) {List<String>data=new ArrayList<>();String line;while((line=br.readLine())!=null){data.add(line);}System.out.println(data);//自定义排序规则// "壹","二","三","四","五","陆","柒","八","九" // 升序// "九","八","柒","陆","五","四","三","二","壹" // 降序List<String>sizes=new ArrayList<>();Collections.addAll(sizes,"壹","二","三","四","五","陆","柒","八","九");Collections.sort(data, new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {return sizes.indexOf(o1.substring(0,o1.indexOf(".")))- sizes.indexOf(o2.substring(0,o2.indexOf(".")));}});System.out.println(data);for (String datum:data){bw.write(datum);bw.newLine();}}catch (Exception e){e.printStackTrace();}}
}
缓冲流性能分析
我们说缓冲流内部多了一个数组,可以提高原始流的读写性能。讲到这一定有同学有这么一个疑问,它和我们使用原始流,自己加一个8BK数组不是一样的吗? 缓冲流就一定能提高性能吗?先告诉同学们答案,缓冲流不一定能提高性能。
下面我们用一个比较大文件(889MB)复制,做性能测试,分别使用下面四种方式来完成文件复制,并记录文件复制的时间。
① 使用低级流一个字节一个字节的复制
② 使用低级流按照字节数组的形式复制
③ 使用缓冲流一个字节一个字节的复制
④ 使用缓冲流按照字节数组的形式复制
低级流一个字节复制: 慢得简直让人无法忍受
低级流按照字节数组复制(数组长度1024): 12.117s
缓冲流一个字节复制: 11.058s
缓冲流按照字节数组复制(数组长度1024): 2.163s
【注意:这里的测试只能做一个参考,和电脑性能也有直接关系】
经过上面的测试,我们可以得出一个结论:默认情况下,采用一次复制1024个字节,缓冲流完胜。
但是,缓冲流就一定性能高吗?我们采用一次复制8192个字节试试
低级流按照字节数组复制(数组长度8192): 2.535s
缓冲流按照字节数组复制(数组长度8192): 2.088s
经过上面的测试,我们可以得出一个结论:一次读取8192个字节时,低级流和缓冲流性能相当。相差的那几毫秒可以忽略不计。
继续把数组变大,看一看缓冲流就一定性能高吗?现在采用一次读取1024*32个字节数据试试
低级流按照字节数组复制(数组长度8192): 1.128s
缓冲流按照字节数组复制(数组长度8192): 1.133s
经过上面的测试,我们可以得出一个结论:数组越大性能越高,低级流和缓冲流性能相当。相差的那几秒可以忽略不计。
继续把数组变大,看一看缓冲流就一定性能高吗?现在采用一次读取1024*6个字节数据试试
低级流按照字节数组复制(数组长度8192): 1.039s
缓冲流按照字节数组复制(数组长度8192): 1.151s
此时你会发现,当数组大到一定程度,性能已经提高了多少了,甚至缓冲流的性能还没有低级流高。
最终总结一下:缓冲流的性能不一定比低级流高,其实低级流自己加一个数组,性能其实是不差。只不过缓冲流帮你加了一个相对而言大小比较合理的数组 。
四种方式的测试代码
package com.itheima.d2_buffered_stream;import java.io.*;/**目标:观察原始流和缓冲流的性能。*/
public class TimeTest4 {// 复制的视频路径private static final String SRC_FILE = "D:\\resource\\线程池.avi";// 复制到哪个目的地private static final String DEST_FILE = "D:\\";public static void main(String[] args) {// copy01(); // 低级字节流一个一个字节的赋值,慢的简直让人无法忍受,直接淘汰!copy02();// 低级的字节流流按照一个一个字节数组的形式复制,速度较慢!// copy03(); // 缓冲流按照一个一个字节的形式复制,速度较慢,直接淘汰!copy04(); // 缓冲流按照一个一个字节数组的形式复制,速度极快,推荐使用!}private static void copy01() {long startTime = System.currentTimeMillis();try (InputStream is = new FileInputStream(SRC_FILE);OutputStream os = new FileOutputStream(DEST_FILE + "1.avi");){int b;while ((b = is.read()) != -1){os.write(b);}}catch (Exception e){e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("低级字节流一个一个字节复制耗时:" + (endTime - startTime) / 1000.0 + "s");}private static void copy02() {long startTime = System.currentTimeMillis();try (InputStream is = new FileInputStream(SRC_FILE);OutputStream os = new FileOutputStream(DEST_FILE + "2.avi");){byte[] buffer = new byte[1024*64];int len;while ((len = is.read(buffer)) != -1){os.write(buffer, 0, len);}}catch (Exception e){e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("低级字节流使用字节数组复制耗时:" + (endTime - startTime) / 1000.0 + "s");}private static void copy03() {long startTime = System.currentTimeMillis();try (InputStream is = new FileInputStream(SRC_FILE);BufferedInputStream bis = new BufferedInputStream(is);OutputStream os = new FileOutputStream(DEST_FILE + "3.avi");BufferedOutputStream bos = new BufferedOutputStream(os);){int b;while ((b = bis.read()) != -1){bos.write(b);}}catch (Exception e){e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("缓冲流一个一个字节复制耗时:" + (endTime - startTime) / 1000.0 + "s");}private static void copy04() {long startTime = System.currentTimeMillis();try (InputStream is = new FileInputStream(SRC_FILE);BufferedInputStream bis = new BufferedInputStream(is, 64 * 1024);OutputStream os = new FileOutputStream(DEST_FILE + "4.avi");BufferedOutputStream bos = new BufferedOutputStream(os, 64 * 1024);){byte[] buffer = new byte[1024 * 64]; // 32KBint len;while ((len = bis.read(buffer)) != -1){bos.write(buffer, 0, len);}}catch (Exception e){e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("缓冲流使用字节数组复制耗时:" + (endTime - startTime) / 1000.0 + "s");}
}

转换流
乱码
前面我们学习过FileReader读取文件中的字符,但是同学们注意了,FileReader默认只能读取UTF-8编码格式的文件。如果使用FileReader读取GBK格式的文件,可能存在乱码,因为FileReader它遇到汉字默认是按照3个字节来读取的,而GBK格式的文件一个汉字是占2个字节,这样就会导致乱码。

package com.itheima.d3_transform_stream;import java.io.BufferedReader;
import java.io.FileReader;
import java.io.Reader;/*** 目标:掌握不同编码读取乱码的问题。*/
public class Test1 {public static void main(String[] args) {try (// 1、创建一个文件字符输入流与源文件接通// 代码编码:UTF-8 文件的编码:UTF-8// Reader fr = new FileReader("io-app2/src/itheima04.txt");// 1 床 前 明 月光c// GBK o [oo] [oo] [oo] ...// UTF-8 1 ?????// 代码编码:UTF-8 文件的编码:GBKReader fr = new FileReader("io-app2/src/itheima06.txt");// 2、把文件字符输入流包装成缓冲字符输入流BufferedReader br = new BufferedReader(fr);){String line;while ((line = br.readLine()) != null){System.out.println(line);}} catch (Exception e) {e.printStackTrace();}}
}
InputStreamReader类
前面我们学习过FileReader读取文件中的字符,但是同学们注意了,FileReader默认只能读取UTF-8编码格式的文件。如果使用FileReader读取GBK格式的文件,可能存在乱码,因为FileReader它遇到汉字默认是按照3个字节来读取的,而GBK格式的文件一个汉字是占2个字节,这样就会导致乱码。
Java给我们提供了另外两种流InputStreamReader,OutputStreamWriter,这两个流我们把它叫做转换流。它们可以将字节流转换为字符流,并且可以指定编码方案。
接下来,我们先学习InputStreamReader类,你看这个类名就比较有意思,前面是InputStream表示字节输入流,后面是Reader表示字符输入流,合在一起意思就是表示可以把InputStream转换为Reader,最终InputStreamReader其实也是Reader的子类,所以也算是字符输入流。
InputStreamReader也是不能单独使用的,它内部需要封装一个InputStream的子类对象,再指定一个编码表,如果不指定编码表,默认会按照UTF-8形式进行转换。
需求:我们可以先准备一个GBK格式的文件,然后使用下面的代码进行读取,看是是否有乱码。

public class InputStreamReaderTest2 {public static void main(String[] args) {try (// 1、得到文件的原始字节流(GBK的字节流形式)InputStream is = new FileInputStream("io-app2/src/itheima06.txt");// 2、把原始的字节输入流按照指定的字符集编码转换成字符输入流Reader isr = new InputStreamReader(is, "GBK");// 3、把字符输入流包装成缓冲字符输入流BufferedReader br = new BufferedReader(isr);){String line;while ((line = br.readLine()) != null){System.out.println(line);}} catch (Exception e) {e.printStackTrace();}}
}
执行完之后,你会发现没有乱码。

OutputStreamWriter类
接下来,我们先学习OutputStreamWriter类,你看这个类名也比较有意思,前面是OutputStream表示字节输出流,后面是Writer表示字符输出流,合在一起意思就是表示可以把OutputStream转换为Writer,最终OutputStreamWriter其实也是Writer的子类,所以也算是字符输出流。
OutputStreamReader也是不能单独使用的,它内部需要封装一个OutputStream的子类对象,再指定一个编码表,如果不指定编码表,默认会按照UTF-8形式进行转换。
需求:我们可以先准备一个GBK格式的文件,使用下面代码往文件中写字符数据。
public class OutputStreamWriterTest3 {public static void main(String[] args) {// 指定写出去的字符编码。try (// 1、创建一个文件字节输出流OutputStream os = new FileOutputStream("io-app2/src/itheima07out.txt");// 2、把原始的字节输出流,按照指定的字符集编码转换成字符输出转换流。Writer osw = new OutputStreamWriter(os, "GBK");// 3、把字符输出流包装成缓冲字符输出流BufferedWriter bw = new BufferedWriter(osw);){bw.write("我是中国人abc");bw.write("我爱你中国123");} catch (Exception e) {e.printStackTrace();}}
}

打印流
打印流,这里所说的打印其实就是写数据的意思,它和普通的write方法写数据还不太一样,一般会使用打印流特有的方法叫print(数据)或者println(数据),它打印啥就输出啥。
打印流有两个,一个是字节打印流PrintStream,一个是字符打印流PrintWriter,如下图所示
PrintStream

PrintWriter

package com.itheima.d4_print_stream;import java.io.FileOutputStream;
import java.io.PrintWriter;/*** 目标:掌握打印流:PrintStream/PrintWriter的用法。*/
public class PrintTest1 {public static void main(String[] args) {try (// 1、创建一个打印流管道// PrintStream ps =// new PrintStream("io-app2/src/itheima08.txt", Charset.forName("GBK"));// PrintStream ps =// new PrintStream("io-app2/src/itheima08.txt");PrintWriter ps =new PrintWriter(new FileOutputStream("io-app2/src/itheima08.txt", true));){// println打印任意数据类型ps.println(97);ps.println('a');ps.println("我爱你中国abc");ps.println(true);ps.println(99.5);// ps.write(97); // 'a'} catch (Exception e) {e.printStackTrace();}}
}
PrintStream和PrintWriter的区别

打印流的使用场景
其实我们开学第一课,就给同学们讲过System.out.println()这句话表示打印输出,但是至于为什么能够输出,其实我们一直不清楚。
以前是因为知识储备还不够,无法解释,到现在就可以给同学们揭晓谜底了,因为System里面有一个静态变量叫out,out的数据类型就是PrintStream,它就是一个打印流,而且这个打印流的默认输出目的地是控制台,所以我们调用System.out.pirnln()就可以往控制台打印输出任意类型的数据,而且打印啥就输出啥。
而且System还提供了一个方法,可以修改底层的打印流,这样我们就可以重定向打印语句的输出目的地了。我们玩一下, 直接上代码。
public class PrintTest2 {public static void main(String[] args) {System.out.println("老骥伏枥");System.out.println("志在千里");try ( PrintStream ps = new PrintStream("io-app2/src/itheima09.txt"); ){// 把系统默认的打印流对象改成自己设置的打印流System.setOut(ps);System.out.println("烈士暮年"); System.out.println("壮心不已");} catch (Exception e) {e.printStackTrace();}}
}
此时打印语句,将往文件中打印数据,而不在控制台。
数据流
同学们,接下我们再学习一种流,这种流在开发中偶尔也会用到。比如,我们想把数据和数据的类型一并写到文件中去,读取的时候也将数据和数据类型一并读出来。这就可以用到数据流,有两个DataInputStream和DataOutputStream
DataOutputStream类
我们先学习DataOutputStream类,它也是一种包装流,创建DataOutputStream对象时,底层需要依赖于一个原始的OutputStream流对象。然后调用它的wirteXxx方法,写的是特定类型的数据。

代码如下:往文件中写整数、小数、布尔类型数据、字符串数据
public class DataOutputStreamTest1 {public static void main(String[] args) {try (// 1、创建一个数据输出流包装低级的字节输出流DataOutputStream dos =new DataOutputStream(new FileOutputStream("io-app2/src/itheima10out.txt"));){dos.writeInt(97);dos.writeDouble(99.5);dos.writeBoolean(true);dos.writeUTF("黑马程序员666!");} catch (Exception e) {e.printStackTrace();}}
}
DataInputStream类
学习完DataOutputStream后,再学习DataIntputStream类,它也是一种包装流,创建DataInputStream对象时,底层需要依赖于一个原始的InputStream流对象。然后调用它的readXxx()方法就可以读取特定类型的数据。

代码如下:读取文件中特定类型的数据(整数、小数、字符串等)
public class DataInputStreamTest2 {public static void main(String[] args) {try (DataInputStream dis =new DataInputStream(new FileInputStream("io-app2/src/itheima10out.txt"));){int i = dis.readInt();System.out.println(i);double d = dis.readDouble();System.out.println(d);boolean b = dis.readBoolean();System.out.println(b);String rs = dis.readUTF();System.out.println(rs);} catch (Exception e) {e.printStackTrace();}}
}
序列化流
对象序列化和对象反序列化
简单来讲就是写对象和读对象

各位同学同学,还有最后一个流要学习,叫做序列化流。序列化流是干什么用的呢? 我们知道字节流是以字节为单位来读写数据、字符流是按照字符为单位来读写数据、而对象流是以对象为单位来读写数据。也就是把对象当做一个整体,可以写一个对象到文件,也可以从文件中把对象读取出来。
ObjectOutputStream类
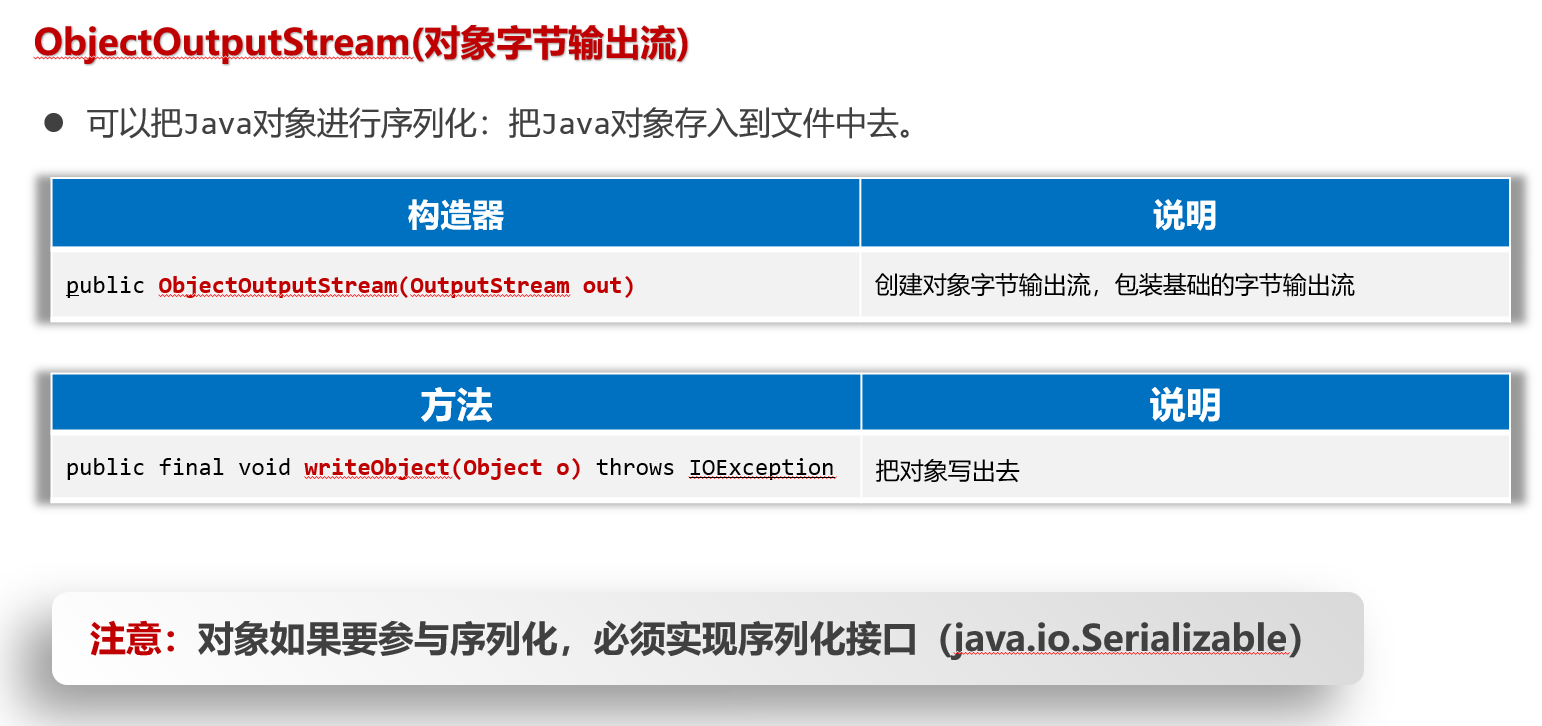
接下来,先学习ObjectOutputStream流,它也是一个包装流,不能单独使用,需要结合原始的字节输出流使用。
代码如下:将一个User对象写到文件中去
- 第一步:先准备一个User类,必须让其实现Serializable接口。
// transient 这个成员变量将不参与序列化(不会将这个成员变量写到文件中)。
private transient String passWord;
// 注意:对象如果需要序列化,必须实现序列化接口。
public class User implements Serializable {private String loginName;private String userName;private int age;// transient 这个成员变量将不参与序列化。private transient String passWord;public User() {}public User(String loginName, String userName, int age, String passWord) {this.loginName = loginName;this.userName = userName;this.age = age;this.passWord = passWord;}@Overridepublic String toString() {return "User{" +"loginName='" + loginName + '\'' +", userName='" + userName + '\'' +", age=" + age +", passWord='" + passWord + '\'' +'}';}
}
- 第二步:再创建ObjectOutputStream流对象,调用writeObject方法对象到文件。
public class Test1ObjectOutputStream {public static void main(String[] args) {try (// 2、创建一个对象字节输出流包装原始的字节 输出流。ObjectOutputStream oos =new ObjectOutputStream(new FileOutputStream("io-app2/src/itheima11out.txt"));){// 1、创建一个Java对象。User u = new User("admin", "张三", 32, "666888xyz");// 3、序列化对象到文件中去oos.writeObject(u);System.out.println("序列化对象成功!!");} catch (Exception e) {e.printStackTrace();}}
}
注意:写到文件中的对象,是不能用记事本打开看的。因为对象本身就不是文本数据,打开是乱码

怎样才能读懂文件中的对象是什么呢?这里必须用反序列化,自己写代码读
ObjectInputStream类
接下来,学习ObjectInputStream流,它也是一个包装流,不能单独使用,需要结合原始的字节输入流使用。

接着前面的案例,文件中已经有一个Student对象,现在要使用ObjectInputStream读取出来。称之为反序列化。
public class Test2ObjectInputStream {public static void main(String[] args) {try (// 1、创建一个对象字节输入流管道,包装 低级的字节输入流与源文件接通ObjectInputStream ois = new ObjectInputStream(new FileInputStream("io-app2/src/itheima11out.txt"));){User u = (User) ois.readObject();System.out.println(u);} catch (Exception e) {e.printStackTrace();}}
}
如何一次序列化多个对象
使用ArrayList集合

package com.itheima.d6_object_stream;import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;public class Demo {public static void main(String[] args) {// 序列化try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("io-app2/src/demoout.txt"));){User user1 = new User("admin1", "张三", 12, "123");User user2 = new User("admin2", "李四", 23, "123");List<User> list = new ArrayList<>();Collections.addAll(list, user1, user2);oos.writeObject(list);} catch (Exception e) {e.printStackTrace();}// 反序列化try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("io-app2/src/demoout.txt"));){List<User> list1 = (List) ois.readObject();for (User user : list1) {System.out.println(user);}} catch (Exception e) {e.printStackTrace();}}
}

transient关键字
在 Serializable 和 Externalizable 接口中,transient 关键字的表现也不同,在 Serializable 中表示该成员变量不参与序列化和反序列化,在 Externalizable 中不起作用,因为 Externalizable 接口需要实现 readExternal 和 writeExternal 方法,需要手动完成序列化和反序列化的过程。
IO框架
什么是框架
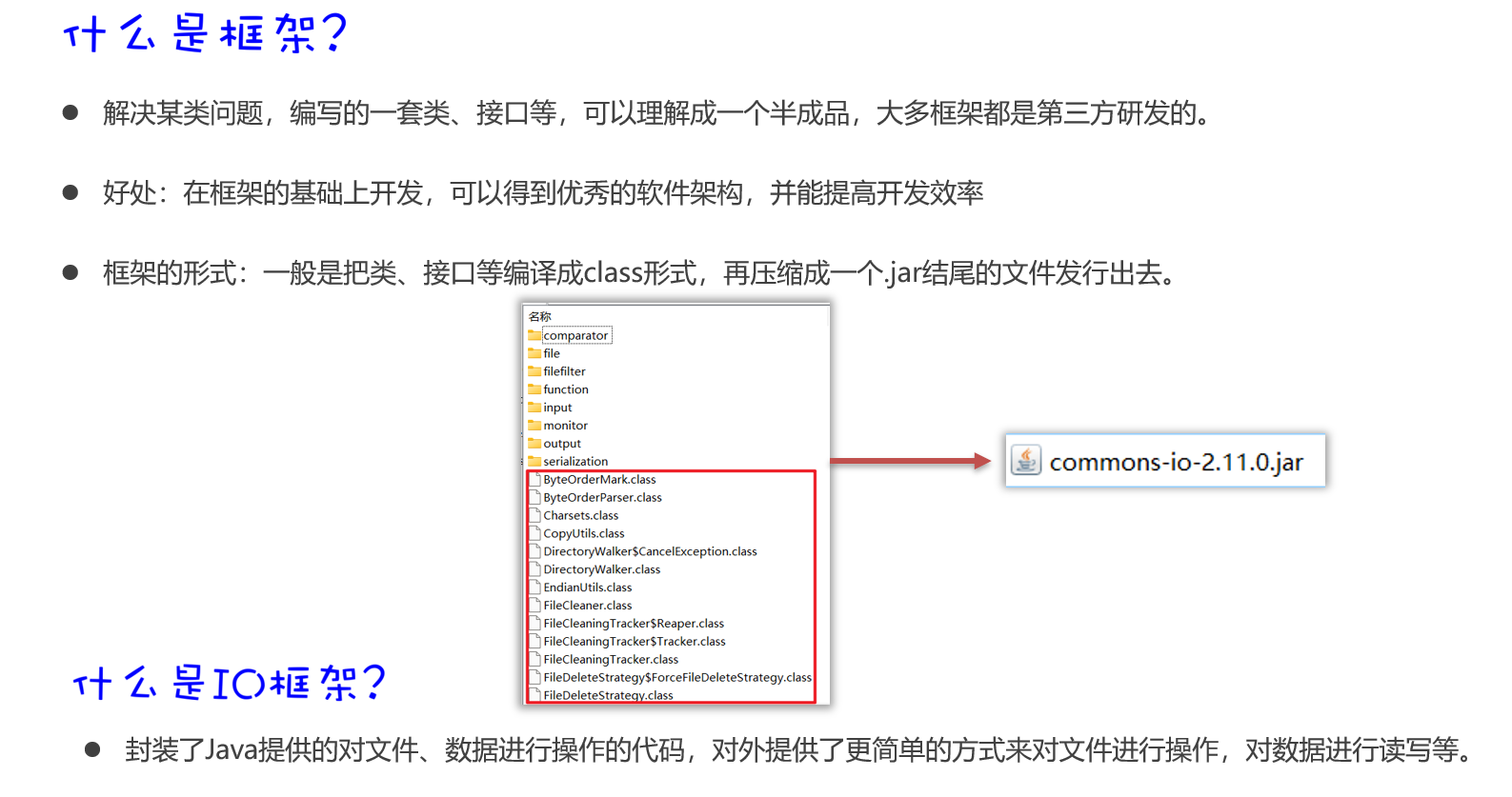
如何在项目中使用框架

Commons-io框架

代码举例
package com.itheima.d7_commons_io;import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.Reader;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.List;/*** 目标:使用CommonsIO框架进行IO相关的操作。*/
public class CommonsIOTest1 {public static void main(String[] args) throws Exception {
// FileUtils.copyFile(new File("io-app2\\src\\itheima01.txt"), new File("io-app2/src/a.txt"));
// FileUtils.copyDirectory(new File("D:\\resource\\私人珍藏"), new File("D:\\resource\\私人珍藏3"));
// FileUtils.deleteDirectory(new File("D:\\resource\\私人珍藏3"));// Java提供的原生的一行代码搞定很多事情// Files.copy(Path.of("io-app2\\src\\itheima01.txt"), Path.of("io-app2\\src\\b.txt"));
// System.out.println(Files.readString(Path.of("io-app2\\src\\itheima01.txt")));// String s = FileUtils.readFileToString(new File("io-app2/src/a.txt"), "UTF-8");
// System.out.println(s);Reader r = new BufferedReader(new FileReader("io-app2/src/a.txt"));List<String> strings = IOUtils.readLines(r);for (String string : strings) {System.out.println(string);}}}
特殊文件
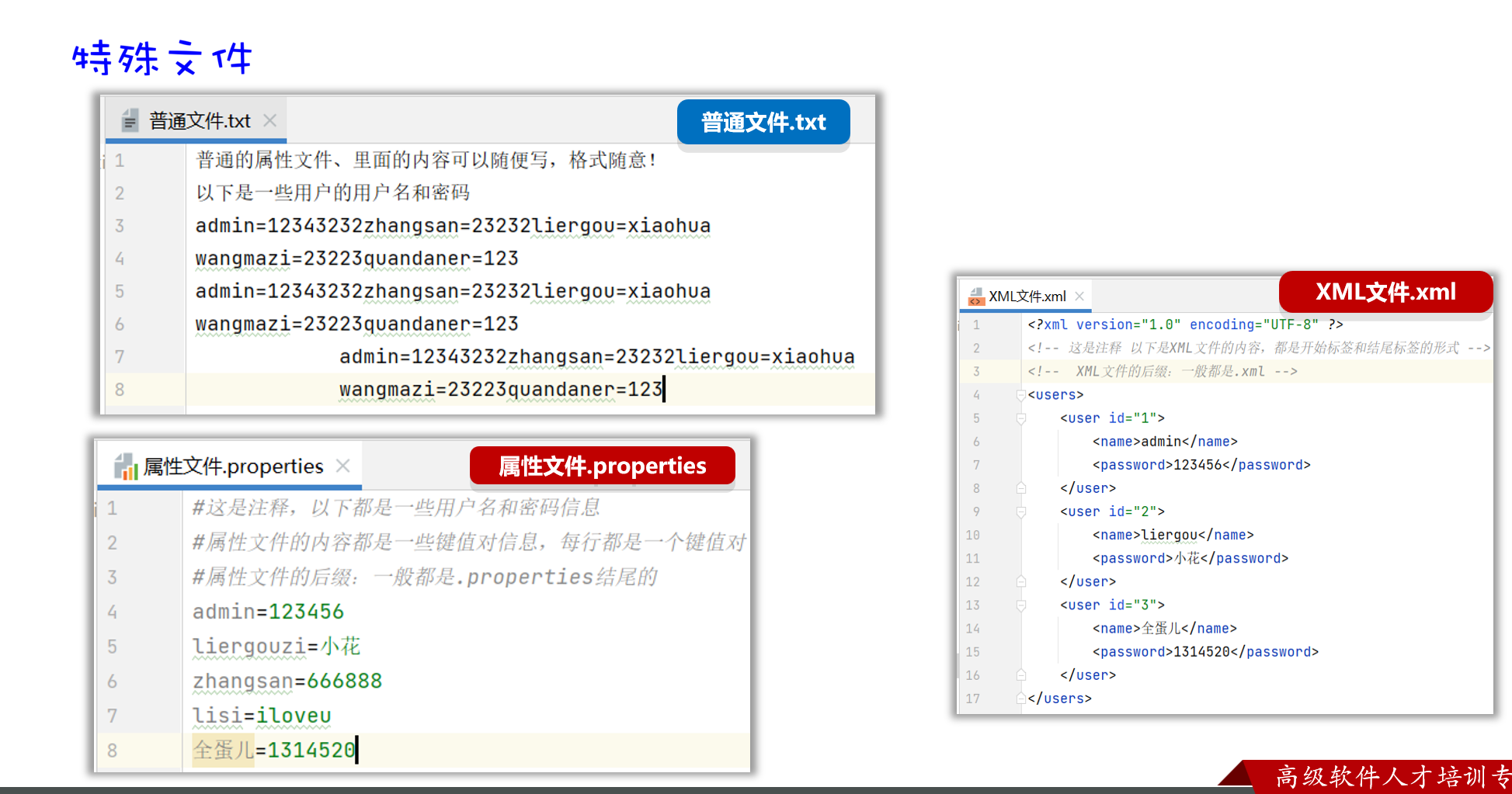
后缀为.properties的文件,称之为属性文件,它可以很方便的存储一些类似于键值对的数据。经常当做软件的配置文件使用。
而xml文件能够表示更加复杂的数据关系,比如要表示多个用户的用户名、密码、家乡、性别等。在后面,也经常当做软件的配置文件使用。
Properties属性文件
Properties是什么
Properties是Map接口下面的一个实现类,所以Properties也是一种双列集合,用来存储键值对。但是一般不会把它当做集合来使用。
Properties核心作用
Properties类的对象,用来表示属性文件,可以用来读取属性文件中的键值对。
Properties属性文件的特点
- 属性文件后缀以
.properties结尾 - 属性文件里面的每一行都是一个键值对,键和值中间用=隔开。比如:
admin=123456 #表示这样是注释信息,是用来解释这一行配置是什么意思。- 每一行末尾不要习惯性加分号,以及空格等字符;不然会把分号,空格会当做值的一部分。
- 键不能重复,值可以重复
Properties读取属性文件的键值对数据

使用Properties读取属性文件的步骤如下
1、创建一个Properties的对象出来(键值对集合,空容器)
2、调用load(字符输入流/字节输入流)方法,开始加载属性文件中的键值对数据到properties对象中去
3、调用getProperty(键)方法,根据键取值
代码如下:
/*** 目标:掌握使用Properties类读取属性文件中的键值对信息。*/
public class PropertiesTest1 {public static void main(String[] args) throws Exception {// 1、创建一个Properties的对象出来(键值对集合,空容器)Properties properties = new Properties();System.out.println(properties);// 2、开始加载属性文件中的键值对数据到properties对象中去properties.load(new FileReader("properties-xml-log-app\\src\\users.properties"));System.out.println(properties);// 3、根据键取值System.out.println(properties.getProperty("赵敏"));System.out.println(properties.getProperty("张无忌"));// 4、遍历全部的键和值。//获取键的集合Set<String> keys = properties.stringPropertyNames();for (String key : keys) {//再根据键获取值String value = properties.getProperty(key);System.out.println(key + "---->" + value);}properties.forEach((k, v) -> {System.out.println(k + "---->" + v);});}
}
Properties往属性文件中写键值对
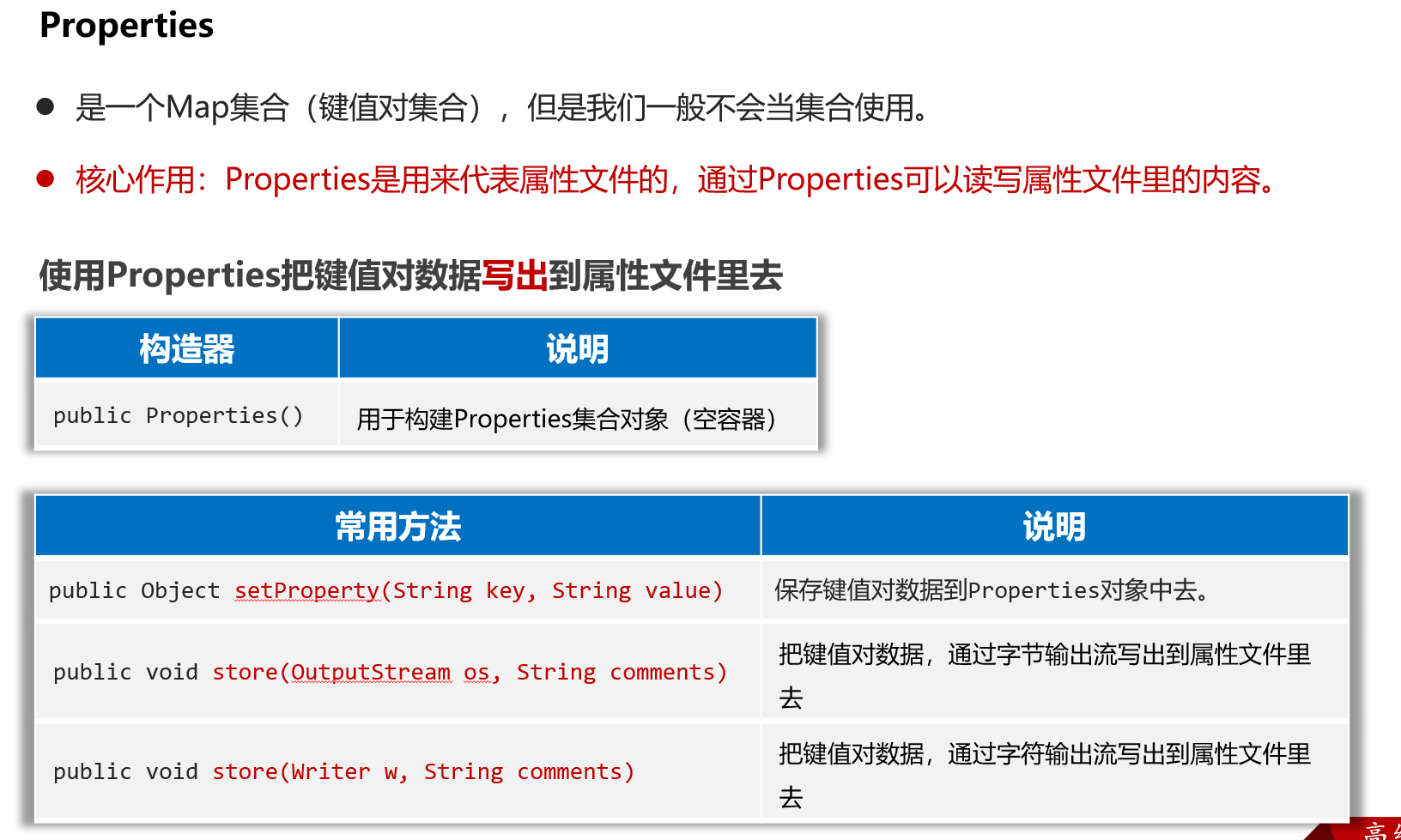
往Properties属性文件中写键值对的步骤如下
1、创建Properties对象出来,
2、调用setProperty存储一些键值对数据
3、调用store(字符输出流/字节输出流, 注释),将Properties集合中的键和值写到文件中注意:第二个参数是注释,必须得加;
public class PropertiesTest2 {public static void main(String[] args) throws Exception {// 1、创建Properties对象出来,先用它存储一些键值对数据Properties properties = new Properties();properties.setProperty("张无忌", "minmin");properties.setProperty("殷素素", "cuishan");properties.setProperty("张翠山", "susu");// 2、把properties对象中的键值对数据存入到属性文件中去properties.store(new FileWriter("properties-xml-log-app/src/users2.properties"), "i saved many users!");}
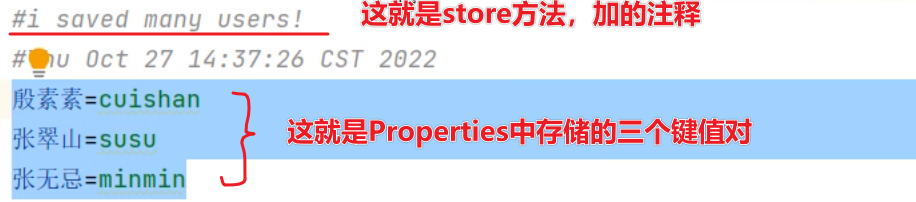
}
运行上面的代码,user2.properties 配置文件打开效果如下图所示。
XML文件
什么是XML
XML是可扩展的标记语言,意思是它是由一些标签组成的,而这些标签是自己定义的。本质上一种数据格式,可以用来表示复杂的数据关系。
XML的特点
XML文件有如下的特点:
- XML中的<标签名> 称为一个标签或者一个元素,一般是成对出现的。
- XML中的标签名可以自己定义(可扩展),但是必须标签必须成对的出现,必须有开始和结束标签
- XML中只能有一个根标签。
- XML标签中可以有属性
- XML必须第一行有文档声明,格式是固定的
- XML文件必须是以.xml为后缀结尾
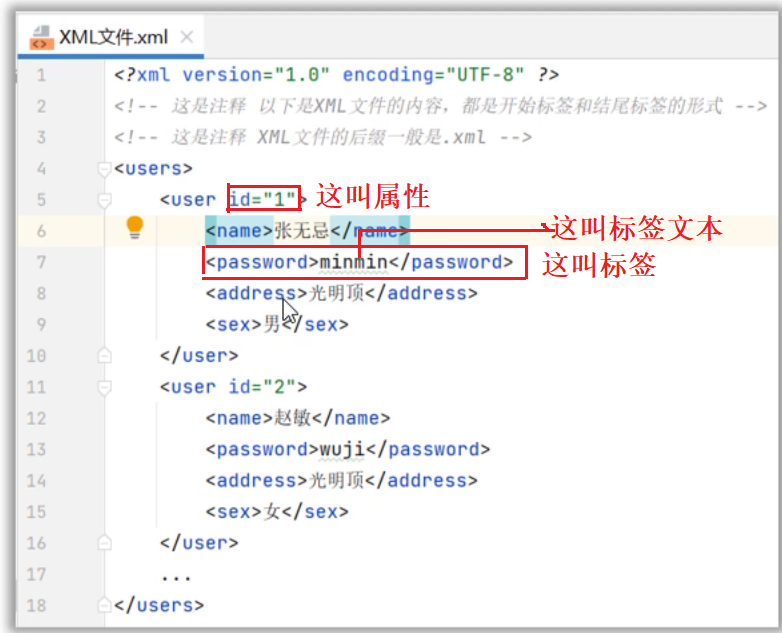
<?xml version="1.0" encoding="UTF-8" ?>
<!-- 注释:以上抬头声明必须放在第一行,必须有 -->
<!-- 根标签只能有一个 -->
<users><user id="1" desc="第一个用户"><name>张无忌</name><sex>男</sex><地址>光明顶</地址><password>minmin</password></user><people>很多人</people><user id="2"><name>敏敏</name><sex>女</sex><地址>光明顶</地址><password>wuji</password></user>
</users>
XML中书写特殊字符
上面XML文件中的数据格式是最为常见的,标签有属性、文本、还有合理的嵌套。XML文件中除了写以上的数据格式之外,还有一些特殊的字符不能直接写。
- 像 <,>,&等这些符号不能出现在标签的文本中,因为标签格式本身就有<>,会和标签格式冲突。如果标签文本中有这些特殊字符,需要用一些占位符代替。
< 表示 <
> 表示 >
& 表示 &
' 表示 '
" 表示 "
表示空格
<data> 3 < 2 && 5 > 4 </data>
<!-- 实际表示<data> 3 < 2 && 5 > 4 </data> -->
- 如果在标签文本中,出现大量的特殊字符,不想使用特殊字符,此时可以用CDATA区,格式如下
<data1><![CDATA[3 < 2 && 5 > 4]]>
</data1>
DOM4J读取xml文件
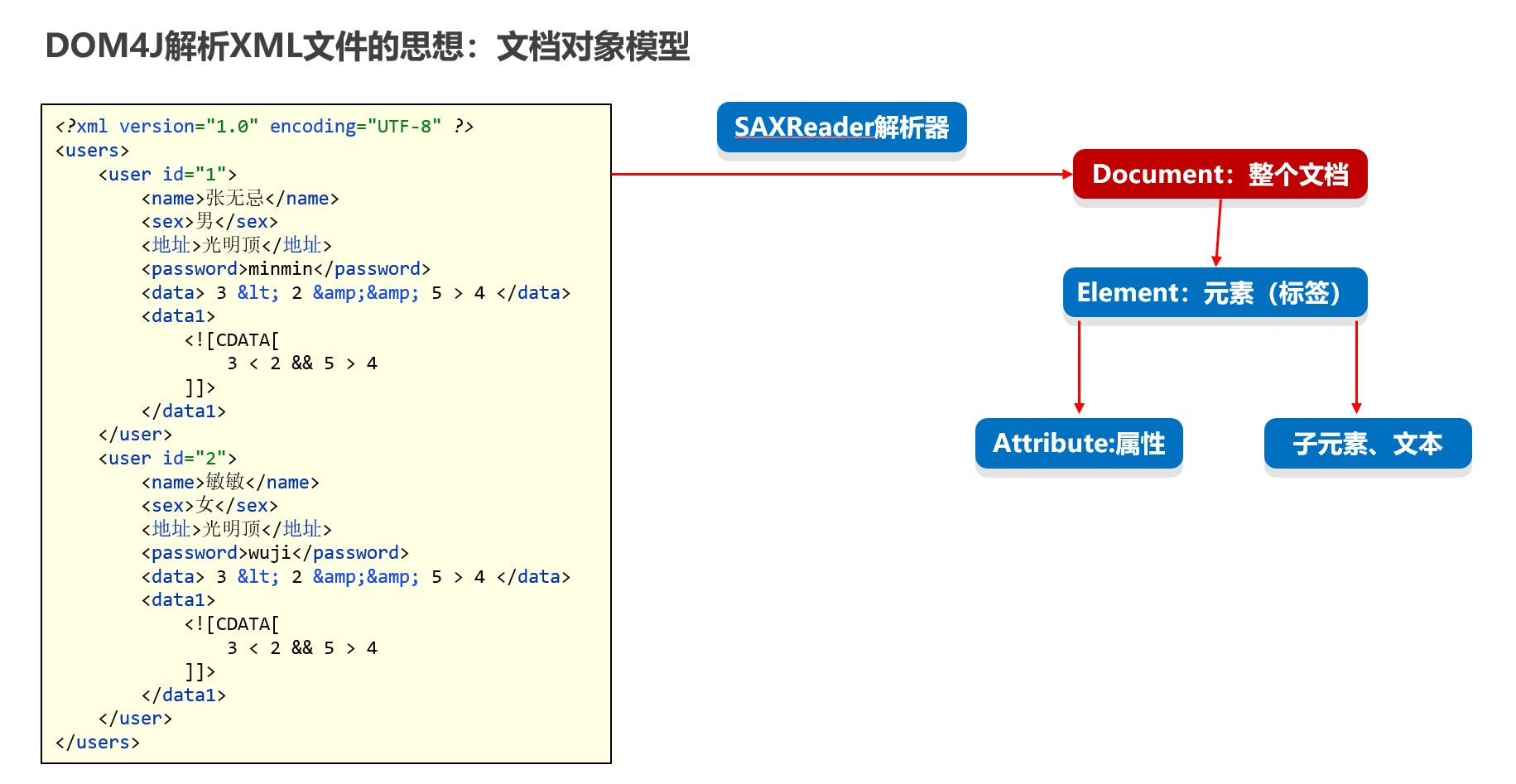
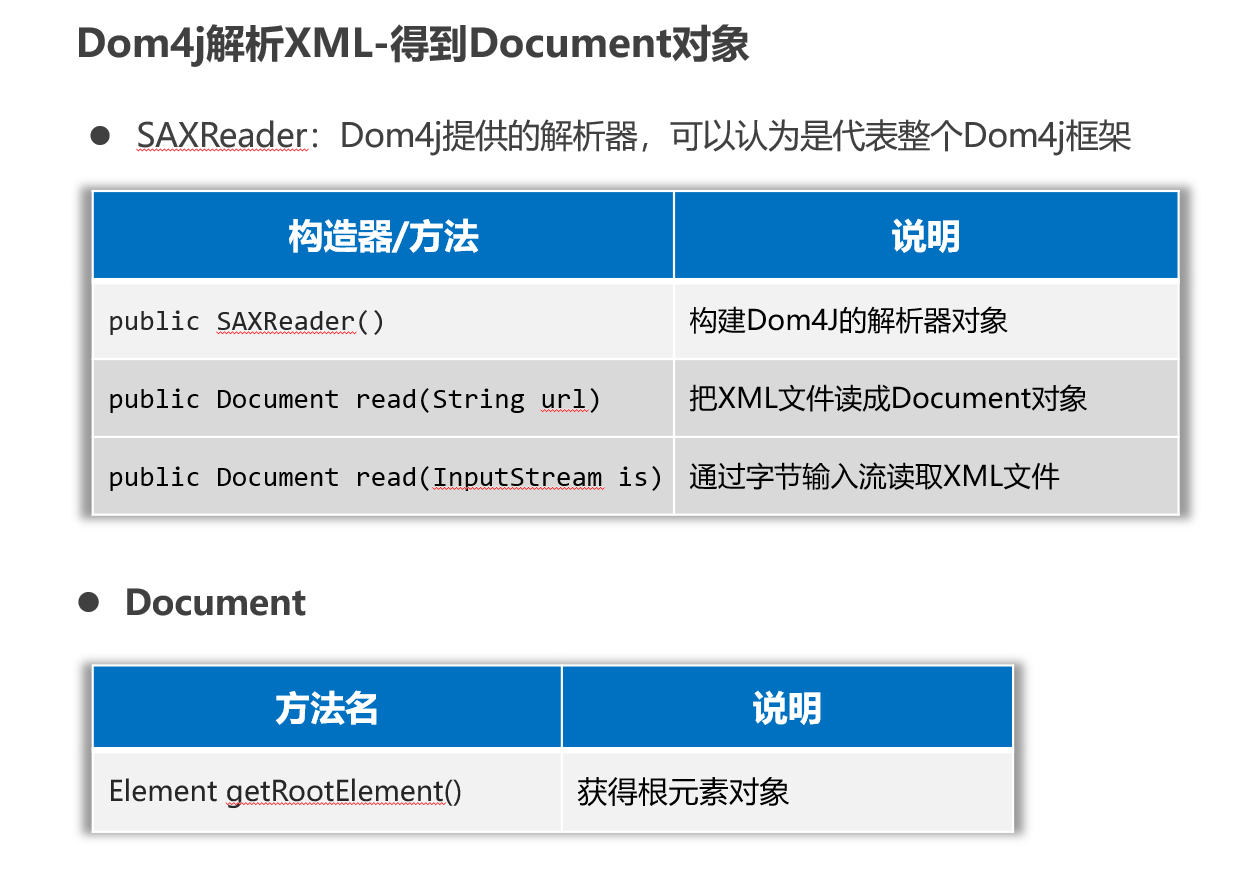
XML解析的过程,是从根元素开始,从外层往里层解析。 我们先把Document对象,和根元素获取出来
public class Dom4JTest1 {public static void main(String[] args) throws Exception {// 1、创建一个Dom4J框架提供的解析器对象SAXReader saxReader = new SAXReader();// 2、使用saxReader对象把需要解析的XML文件读成一个Document对象。Document document =saxReader.read("properties-xml-log-app\\src\\helloworld.xml");// 3、从文档对象中解析XML文件的全部数据了Element root = document.getRootElement();System.out.println(root.getName());}
}
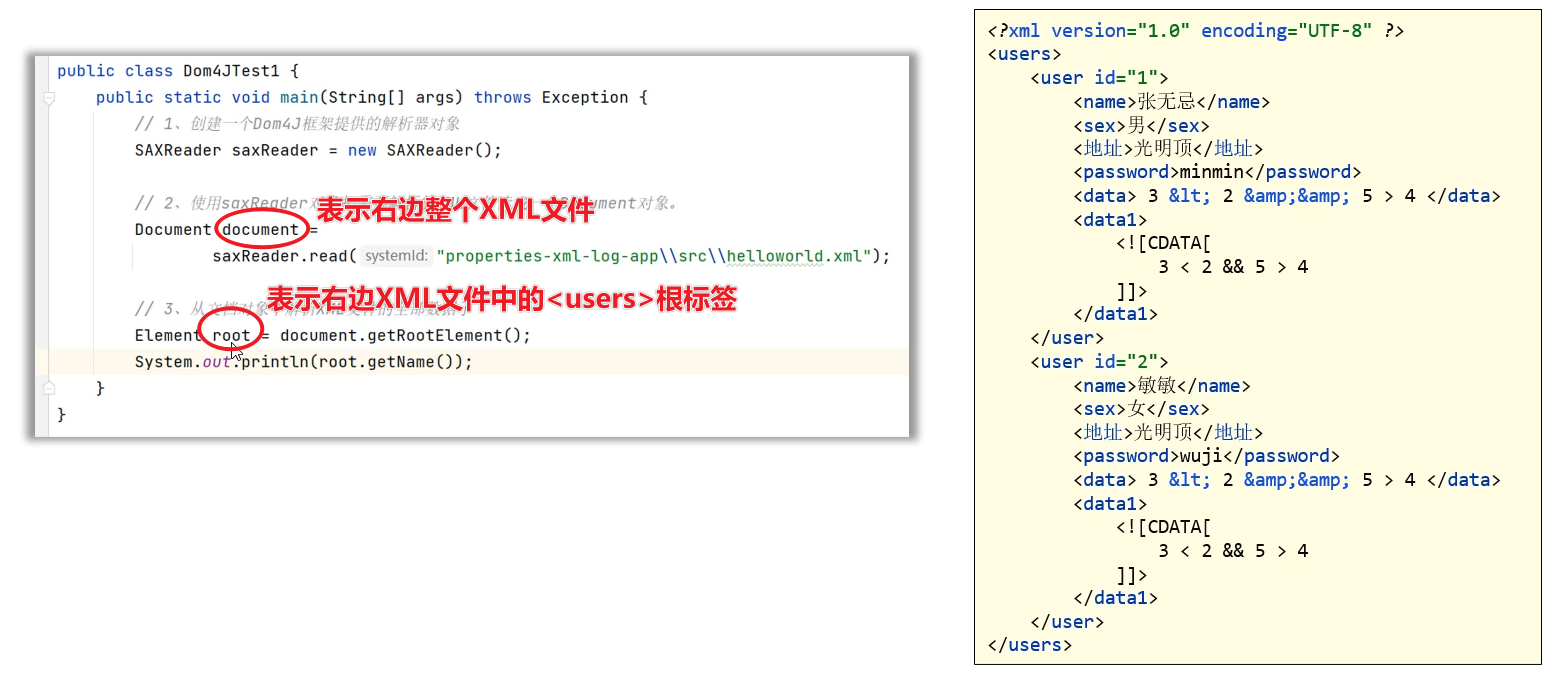
获取到XML文件的根元素之后,接下来,就可以用根元素在获取到它里面的子元素(包括子标签、表属性等)。需要用到的方法如下图所示
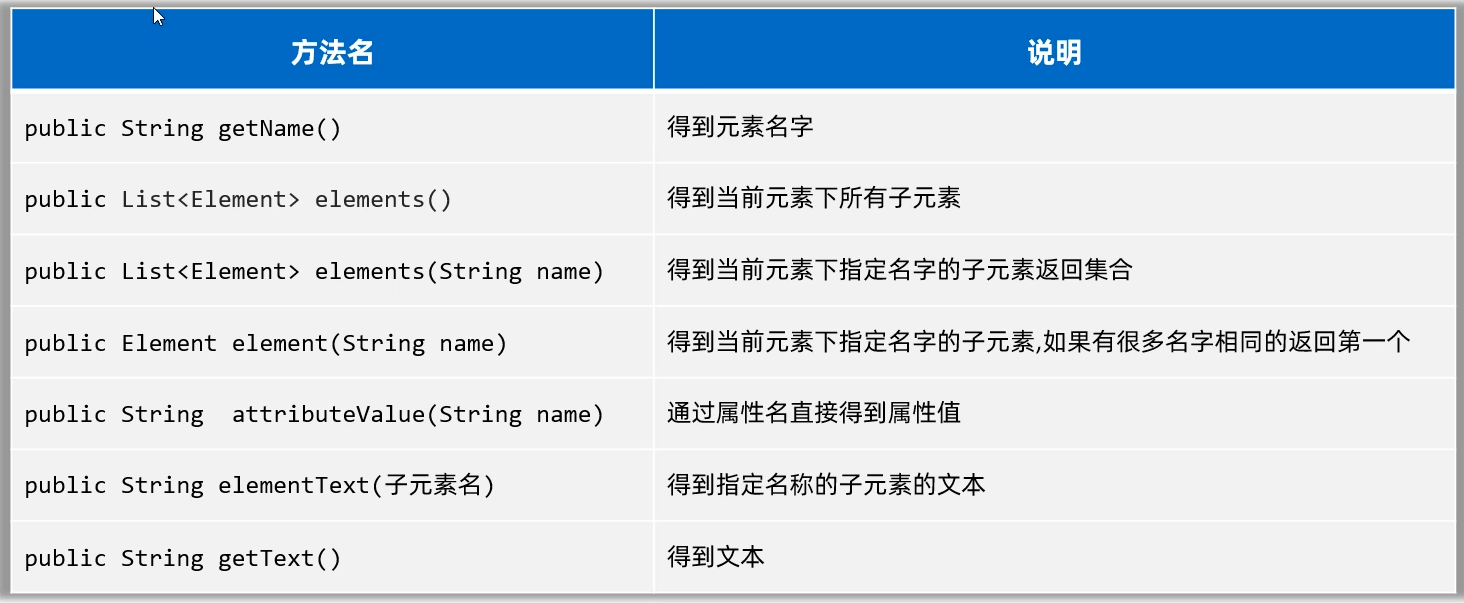
接下来,把上面的方法先一个一个的演示一下。
public class Dom4JTest1 {public static void main(String[] args) throws Exception {// 1、创建一个Dom4J框架提供的解析器对象SAXReader saxReader = new SAXReader();// 2、使用saxReader对象把需要解析的XML文件读成一个Document对象。Document document =saxReader.read("properties-xml-log-app\\src\\helloworld.xml");// 3、从文档对象中解析XML文件的全部数据了Element root = document.getRootElement();System.out.println(root.getName());// 4、获取根元素下的全部一级子元素。// List<Element> elements = root.elements();List<Element> elements = root.elements("user");for (Element element : elements) {System.out.println(element.getName());}// 5、获取当前元素下的某个子元素。Element people = root.element("people");System.out.println(people.getText());// 如果下面有很多子元素user,默认获取第一个。Element user = root.element("user");System.out.println(user.elementText("name"));// 6、获取元素的属性信息呢?System.out.println(user.attributeValue("id"));Attribute id = user.attribute("id");System.out.println(id.getName());System.out.println(id.getValue());List<Attribute> attributes = user.attributes();for (Attribute attribute : attributes) {System.out.println(attribute.getName() + "=" + attribute.getValue());}// 7、如何获取全部的文本内容:获取当前元素下的子元素文本值System.out.println(user.elementText("name"));System.out.println(user.elementText("地址"));System.out.println(user.elementTextTrim("地址")); // 取出文本去除前后空格System.out.println(user.elementText("password"));Element data = user.element("data");System.out.println(data.getText());System.out.println(data.getTextTrim()); // 取出文本去除前后空格}
}
把数据写到xml文件中去(不常用)

package com.itheima.d2_xml;import java.io.BufferedWriter;
import java.io.FileWriter;/*** 目标:如何使用程序把数据写出到 XML文件中去。* <?xml version="1.0" encoding="UTF-8" ?>* <book>* <name>从入门到跑路</name>* <author>dlei</author>* <price>999.9</price>* </book>*/
public class Dom4JTest2 {public static void main(String[] args) {// 1、使用一个StringBuilder对象来拼接XML格式的数据。StringBuilder sb = new StringBuilder();sb.append("<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\r\n");sb.append("<book>\r\n");sb.append("\t<name>").append("从入门到跑路").append("</name>\r\n");sb.append("\t<author>").append("dlei").append("</author>\r\n");sb.append("\t<price>").append(999.99).append("</price>\r\n");sb.append("</book>");try (BufferedWriter bw = new BufferedWriter(new FileWriter("properties-xml-log-app/src/book.xml"));){bw.write(sb.toString());} catch (Exception e) {e.printStackTrace();}}
}
xml约束
XML约束指的是限制XML文件中的标签或者属性,只能按照规定的格式写。
比如我在项目中,想约束一个XML文件中的标签只能写<书>、<书名>、<作者>、<售价>这几个标签,如果写其他标签就报错。
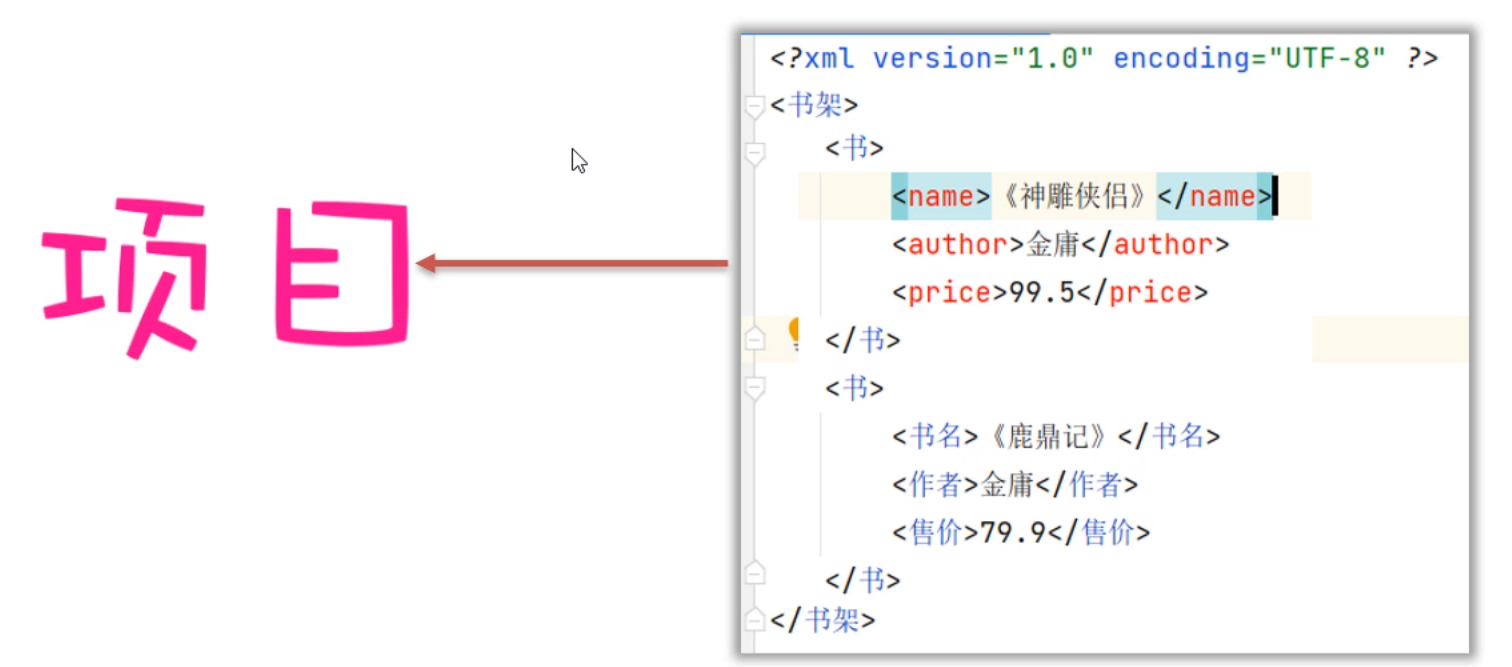
怎么才能达到上面的效果呢?有两种约束技术,一种是DTD约束、一种是Schame约束。
DTD约束
- DTD约束案例如下图所示book.xml中引入了DTD约束文件,book.xml文件中的标签就受到DTD文件的约束
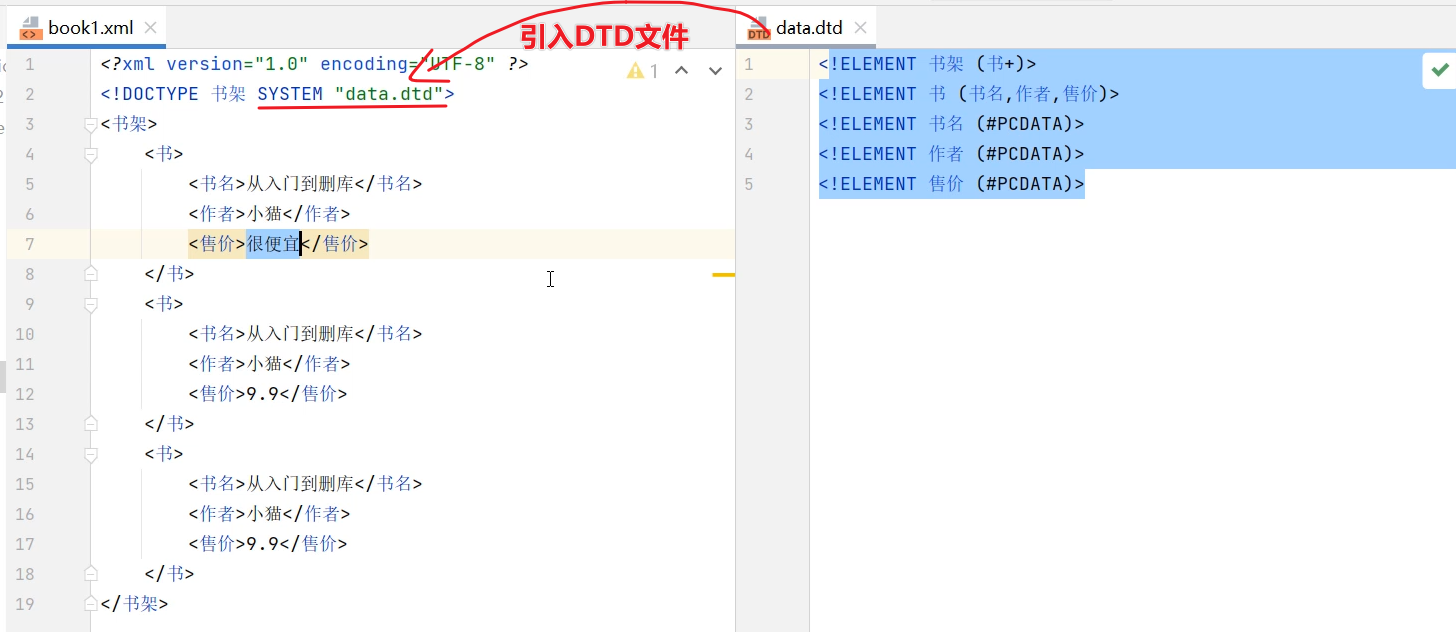
DTD文件解释
<!ELEMENT 书架 (书+)> <!--表示根标签是<书架>,并且书架中有子标签<书>-->
<!ELEMENT 书 (书名,作者,售价)> <!--表示书是一个标签,且书中有子标签<书名>、<作者>、<售价>-->
<!ELEMENT 书名 (#PCDATA)> <!--表示<书名>是一个标签,且<书名>里面是普通文本-->
<!ELEMENT 作者 (#PCDATA)> <!--表示<作者>是一个标签,且<作者>里面是普通文本-->
<!ELEMENT 售价 (#PCDATA)> <!--表示<售价>是一个标签,且<售价>里面是普通文本-->
DTD约束的缺点

比如售价里面写文本也是可以的,但按道理来讲这里应该写的是数字
schema约束 
如下图所示,左边的book2.xml文件就受到右边schema文件(.xsd结尾的文件)的约束。
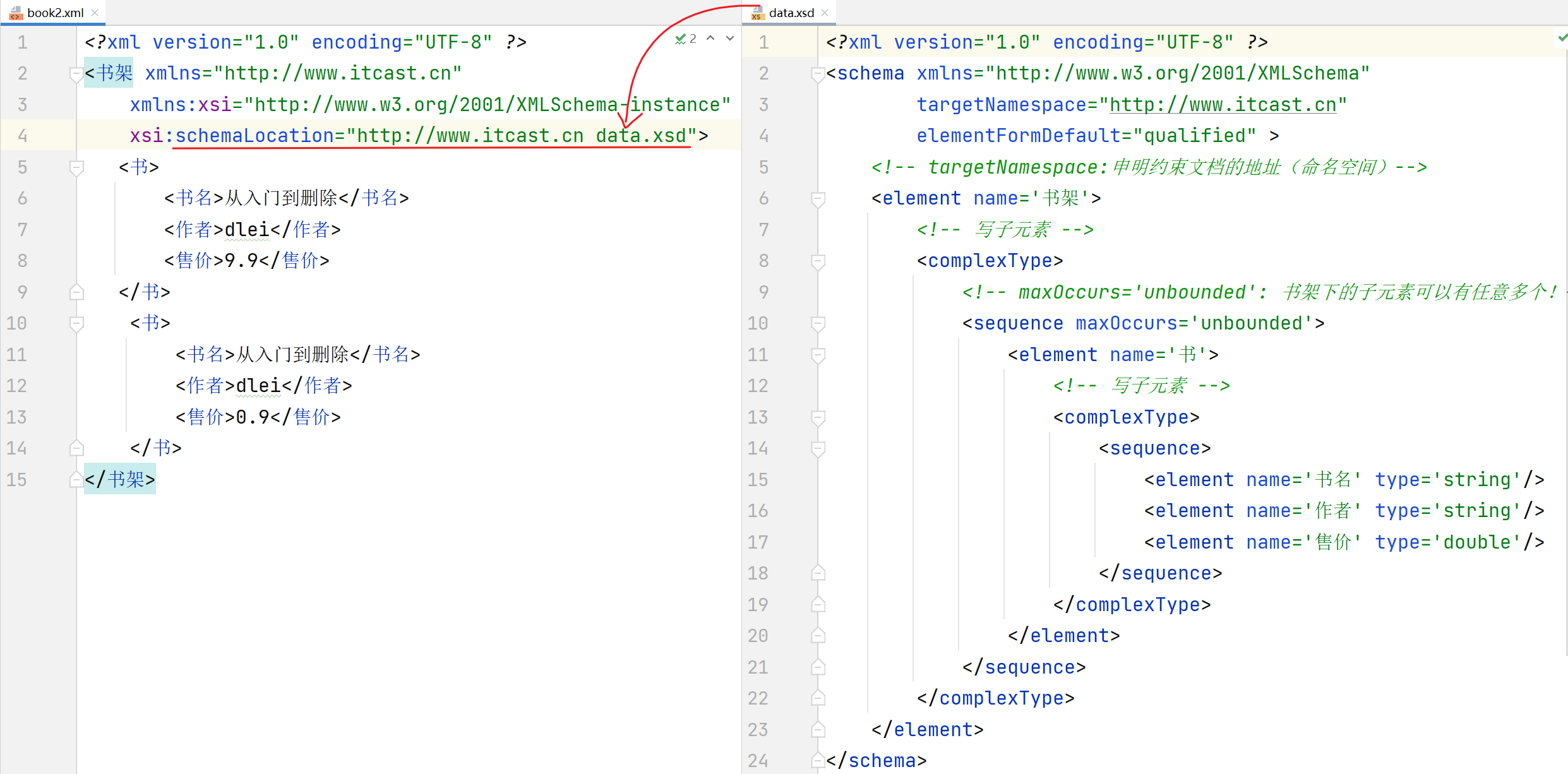
日志技术
日志框架的体系
这里推荐同学们使用Logback日志框架,也在行业中最为广泛使用的。
Logback日志分为哪几个模块

Logback框架
如何使用
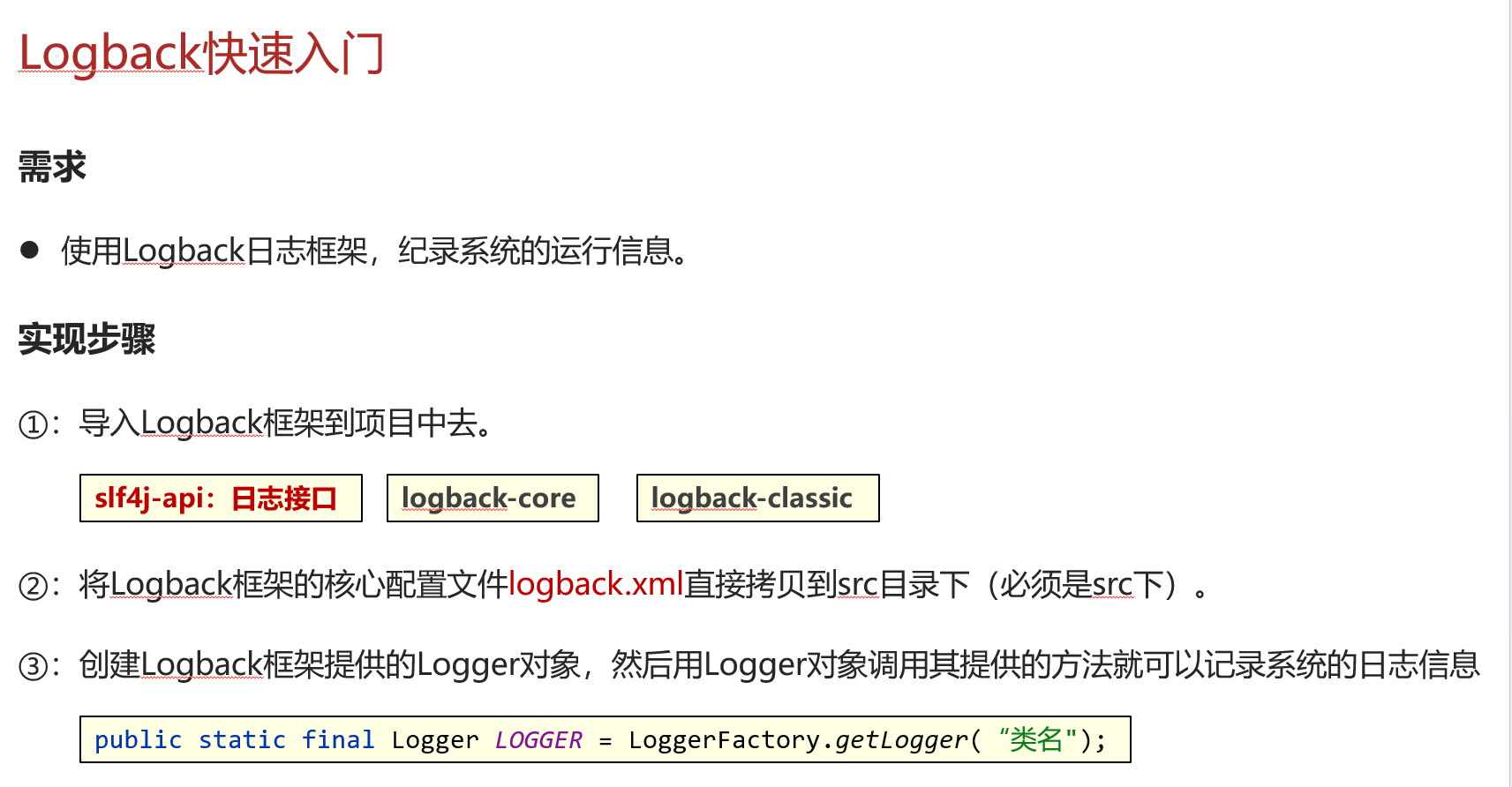
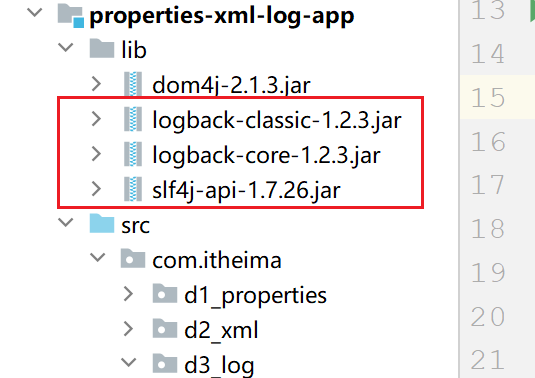
由于Logback是第三方提供的技术,所以首先需要啊将Jar包引入到项目中,具体步骤如下
- 在资料中找到slftj-api.jar、logback-core.jar、logback-classes.jar 这三个jar包,复制一下
- 在当前模块下面新建一个lib文件夹,把刚刚复制的三个jar包都粘贴到此处
- 从资料中找到logback.xml配置文件,将此文件复制粘贴到src目录下(必须是src目录)
- 然后就可以开始写代码了,在代码中创建一个日志记录日对象public static final Logger LOGGER = LoggerFactory.getLogger("当前类名");
- 开始记录日志,代码如下
public class LogBackTest {// 创建一个Logger日志对象public static final Logger LOGGER = LoggerFactory.getLogger("LogBackTest");public static void main(String[] args) {//while (true) {try {LOGGER.info("chu法方法开始执行~~~");chu(10, 0);LOGGER.info("chu法方法执行成功~~~");} catch (Exception e) {LOGGER.error("chu法方法执行失败了,出现了bug~~~");}//}}public static void chu(int a, int b){LOGGER.debug("参数a:" + a);LOGGER.debug("参数b:" + b);int c = a / b;LOGGER.info("结果是:" + c);}
}
当我们运行程序时,就可以看到控制台记录的日志

同时在文件中,也有一份这样的日志信息。文件在哪里内,从配置文件中去找
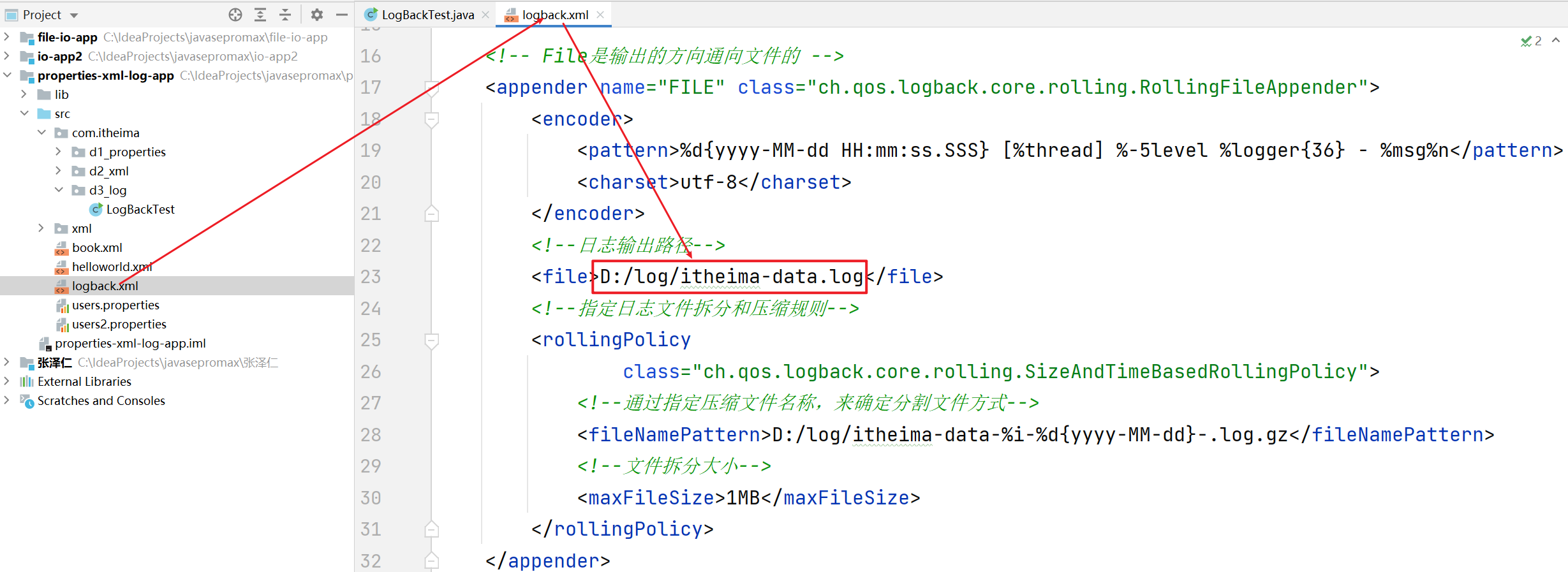
打开D:/log/itheima-data.log看一下文件中是否有记录日志吧!!

核心配置文件logback.xml解析
Logback提供了一个核心配置文件logback.xml,日志框架在记录日志时会读取配置文件中的配置信息,从而记录日志的形式。具体可以做哪些配置呢?
1. 可以配置日志输出的位置是文件、还是控制台
2. 可以配置日志输出的格式
3. 还可以配置日志关闭和开启、以及哪些日志输出哪些日志不输出。
- 如下图所示,控制日志往文件中输出,还是往控制台输出

- 如下图所示,控制打开和关闭日志

- 如下图所示,控制日志的输出的格式
日志格式是由一些特殊的符号组成,可以根据需要删减不想看到的部分。比如不想看到线程名那就不要[%thread]。但是不建议同学们更改这些格式,因为这些都是日志很基本的信息。

Logback设置日志级别

- 在哪里配置日志级别呢?如下图所示(logback.xml)忽略大小写,建议用大写,规范

- Logback只输出大于或者等于核心配置文件配置的日志级别信息。小于配置级别的日志信息,不被记录。
配置的是trace,则trace、debug、info、warn、error级别的日志都被输出
配置的是debug, 则debug、info、warn、error级别的日志被输出
配置的是info,则info、warn、error级别的日志被输出
...
多线程
多线程介绍
什么是线程

什么是多线程
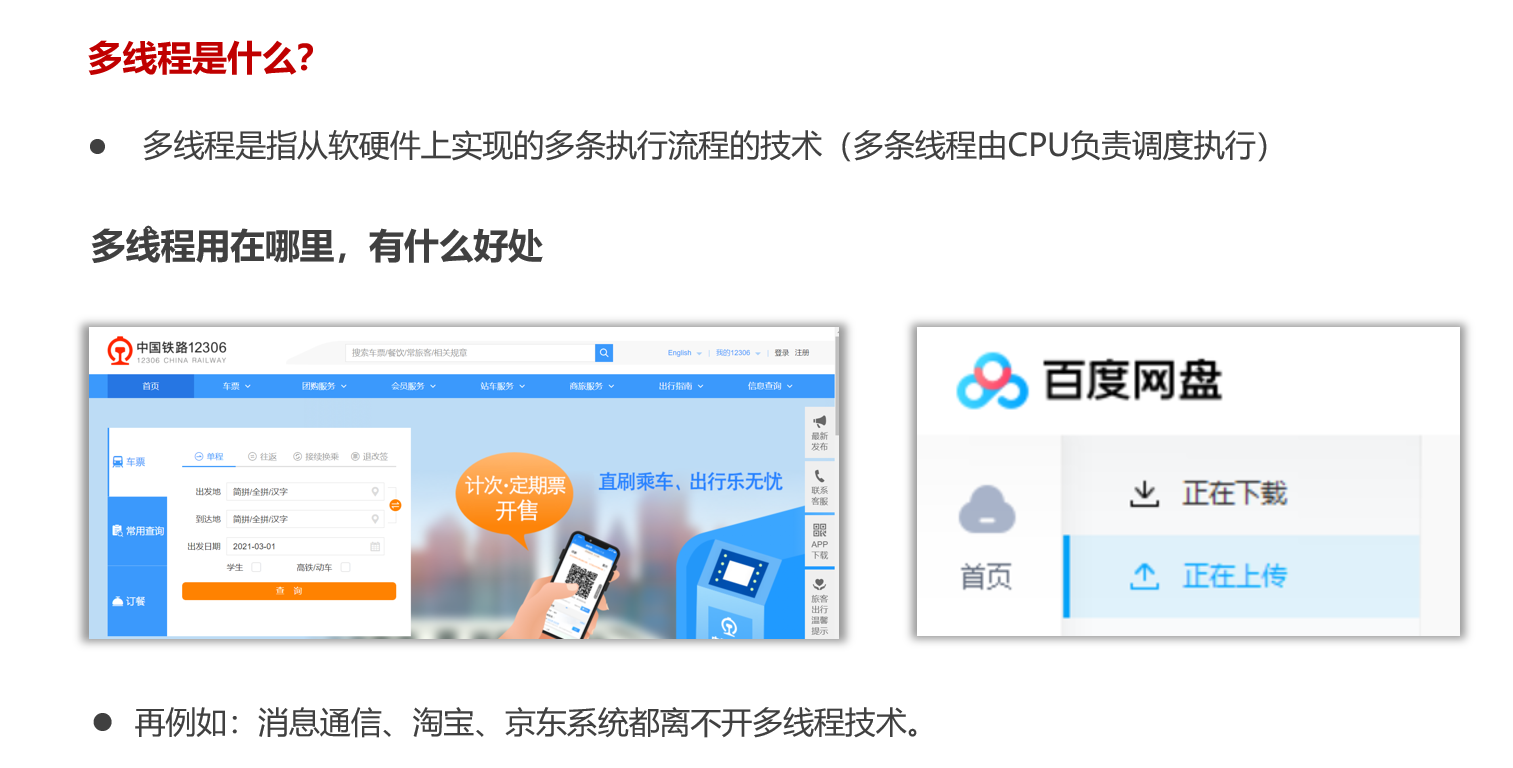
// main方法是由一条默认的主线程负责执行。
创建线程的方式
有三种使用线程的方法:
- 实现 Runnable 接口;
- 实现 Callable 接口;
- 继承 Thread 类。
实现 Runnable 和 Callable 接口的类只能当做一个可以在线程中运行的任务,不是真正意义上的线程,因此最后还需要通过 Thread 来调用。可以说任务是通过线程驱动从而执行的。
方式一(继承Thread类)

package com.itheima.d1_create_thread;/*** 1、让子类继承Thread线程类。*/
public class MyThread extends Thread{// 2、必须重写Thread类的run方法@Overridepublic void run() {// 描述线程的执行任务。for (int i = 1; i <= 5; i++) {System.out.println("子线程MyThread输出:" + i);}}
}
package com.itheima.d1_create_thread;/*** 目标:掌握线程的创建方式一:继承Thread类*/
public class ThreadTest1 {// main方法是由一条默认的主线程负责执行。public static void main(String[] args) {// 3、创建MyThread线程类的对象代表一个线程Thread t = new MyThread();// 4、启动线程(自动执行run方法的)t.start(); // main线程 t线程for (int i = 1; i <= 5; i++) {System.out.println("主线程main输出:" + i);}}
}
方式一继承Thread类的优缺点
多线程的使用注意事项

方式二(实现Runnable接口)
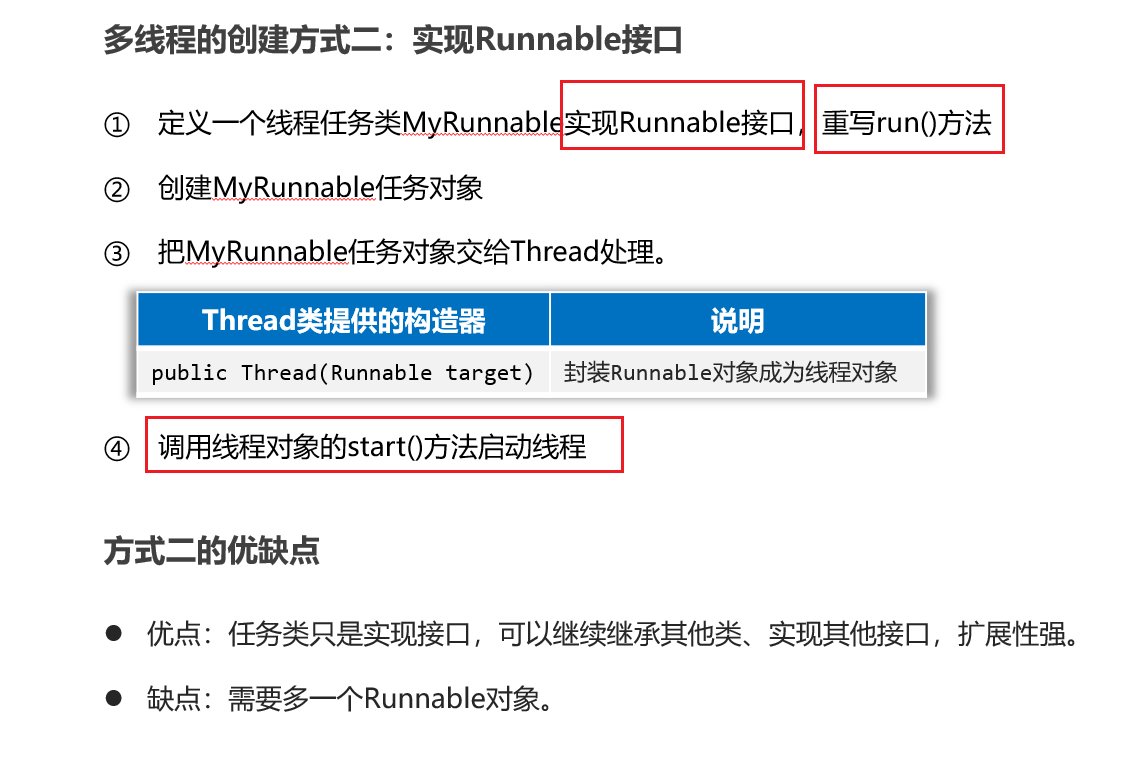
package com.itheima.d1_create_thread;/*** 1、定义一个任务类,实现Runnable接口*/
public class MyRunnable implements Runnable{// 2、重写runnable的run方法@Overridepublic void run() {// 线程要执行的任务。for (int i = 1; i <= 5; i++) {System.out.println("子线程输出 ===》" + i);}}
}
package com.itheima.d1_create_thread;/*** 目标:掌握多线程的创建方式二:实现Runnable接口。*/
public class ThreadTest2 {public static void main(String[] args) {// 3、创建任务对象。Runnable target = new MyRunnable();// 4、把任务对象交给一个线程对象处理。// public Thread(Runnable target)new Thread(target).start();for (int i = 1; i <= 5; i++) {System.out.println("主线程main输出 ===》" + i);}}
}
方式二实现Runnable接口的优缺点

方式二的匿名内部类写法
package com.itheima.d1_create_thread;/*** 目标:掌握多线程创建方式二的匿名内部类写法。*/
public class ThreadTest2_2 {public static void main(String[] args) {// 1、直接创建Runnable接口的匿名内部类形式(任务对象)Runnable target = new Runnable() {@Overridepublic void run() {for (int i = 1; i <= 5; i++) {System.out.println("子线程1输出:" + i);}}};new Thread(target).start();// 简化形式1:new Thread(new Runnable() {@Overridepublic void run() {for (int i = 1; i <= 5; i++) {System.out.println("子线程2输出:" + i);}}}).start();// 简化形式2:new Thread(() -> {for (int i = 1; i <= 5; i++) {System.out.println("子线程3输出:" + i);}}).start();for (int i = 1; i <= 5; i++) {System.out.println("主线程main输出:" + i);}}
}
方式三(实现Callable接口)
方式一集成Thread类和方式二实现Runnable接口创建线程的方式都存在一个问题,就是它们重写的run方法均不能直接返回结果,因为重写的run方法是void,无返回值
 第三种创建线程的方式,步骤如下
第三种创建线程的方式,步骤如下
1.先定义一个Callable接口的实现类,重写call方法
2.创建Callable实现类的对象
3.创建FutureTask类的对象,将Callable对象传递给FutureTask
4.创建Thread对象,将Future对象传递给Thread
5.调用Thread的start()方法启动线程(启动后会自动执行call方法)
等call()方法执行完之后,会自动将返回值结果封装到FutrueTask对象中6.调用FutrueTask对的get()方法获取返回结果
代码如下:先准备一个Callable接口的实现类
package com.itheima.d1_create_thread;import java.util.concurrent.Callable;/*** 1、让这个类实现Callable接口*/
public class MyCallable implements Callable<String> {private int n;public MyCallable(int n) {this.n = n;}// 2、重写call方法@Overridepublic String call() throws Exception {// 描述线程的任务,返回线程执行返回后的结果。// 需求:求1-n的和返回。int sum = 0;for (int i = 1; i <= n; i++) {sum += i;}return "线程求出了1-" + n + "的和是:" + sum;}
}再定义一个测试类,在测试类中创建线程并启动线程,还要获取返回结果
2public class ThreadTest3 {public static void main(String[] args) throws Exception {// 3、创建一个Callable的对象Callable<String> call = new MyCallable(100);// 4、把Callable的对象封装成一个FutureTask对象(任务对象)// 未来任务对象的作用?// 1、是一个任务对象,实现了Runnable对象.// 2、可以在线程执行完毕之后,用未来任务对象调用get方法获取线程执行完毕后的结果。FutureTask<String> f1 = new FutureTask<>(call);// 5、把任务对象交给一个Thread对象new Thread(f1).start();Callable<String> call2 = new MyCallable(200);FutureTask<String> f2 = new FutureTask<>(call2);new Thread(f2).start();// 6、获取线程执行完毕后返回的结果。// 注意:如果执行到这儿,假如上面的线程还没有执行完毕// 这里的代码会暂停,等待上面线程执行完毕后才会获取结果。String rs = f1.get();System.out.println(rs);String rs2 = f2.get();System.out.println(rs2);}
}

三种创建线程方式的优缺点
| 方式 | 优点 | 缺点 |
|---|---|---|
| 继承Thread类 | 编程比较简单,可以直接使用Thread类中的方法 | 扩展性较差,不能再继承其他的类,不能返回线程执行的结果 |
| 实现Runnable接口 | 扩展性强,实现该接口的同时还可以继承其他的类。 | 编程相对复杂,不能返回线程执行的结果 |
| 实现Callable接口 | 扩展性强,实现该接口的同时还可以继承其他的类。可以得到线程执行的结果 | 编程相对复杂 |
线程的常用方法

package com.itheima.d2_thread_api;public class MyThread extends Thread{public MyThread(String name){super(name); // 为当前线程设置名字了}@Overridepublic void run() {// 哪个线程执行它,它就会得到哪个线程对象。Thread t = Thread.currentThread();for (int i = 1; i <= 3; i++) {System.out.println(t.getName() + "输出:" + i);}}
}package com.itheima.d2_thread_api;/*** 目标:掌握Thread的常用方法。*/
public class ThreadTest1 {public static void main(String[] args) {Thread t1 = new MyThread("1号线程");// t1.setName("1号线程");t1.start();System.out.println(t1.getName()); // Thread-0Thread t2 = new MyThread("2号线程");// t2.setName("2号线程");t2.start();System.out.println(t2.getName()); // Thread-1// 主线程对象的名字// 哪个线程执行它,它就会得到哪个线程对象。Thread m = Thread.currentThread();m.setName("最牛的线程");System.out.println(m.getName()); // mainfor (int i = 1; i <= 5; i++) {System.out.println(m.getName() + "线程输出:" + i);}}
}package com.itheima.d2_thread_api;import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;/*** 目标:掌握sleep方法,join方法的作用。*/
public class ThreadTest2 {public static void main(String[] args) throws Exception {System.out.println(Runtime.getRuntime().availableProcessors());for (int i = 1; i <= 5; i++) {System.out.println(i);// 休眠5sif(i == 3){// 会让当前执行的线程暂停5秒,再继续执行// 项目经理让我加上这行代码,如果用户交钱了,我就注释掉!Thread.sleep(5000);}}// join方法作用:让当前调用这个方法的线程先执行完。Thread t1 = new MyThread("1号线程");t1.start();t1.join();Thread t2 = new MyThread("2号线程");t2.start();t2.join();Thread t3 = new MyThread("3号线程");t3.start();t3.join();}
}
线程安全
什么是线程安全问题
线程安全问题指的是,多个线程同时操作同一个共享资源的时候,可能会出现业务安全问题。

线程同步
什么是线程同步

解决线程安全问题
同步最常见的方案就是加锁,意思是每次只允许一个线程加锁,加锁后才能进入访问,访问完毕后自动释放锁,然后其他线程才能再加锁进来。
synchronized
加锁的步骤:
- 多线程同时参与抢锁
- 如果其中一个线程抢到该所,其他线程就不能再占用,抢到锁的线程加锁
- 抢到锁的线程执行完加锁代码后,释放锁
同步锁 -> 线程同步执行
互斥锁 -> 同一把锁只能有一个线程占用
非公平锁 -> 锁释放完之后,线程可以继续抢锁
隐式锁 -> 看不到加锁的过程
线程同步方式一:同步代码块
我们先来学习同步代码块。它的作用就是把访问共享数据的代码锁起来,以此保证线程安全。
//锁对象:必须是一个唯一的对象(同一个地址)
synchronized(锁对象){//...访问共享数据的代码...
}
使用同步代码块,来解决前面代码里面的线程安全问题。我们只需要修改DrawThread类中的代码即可。
// 小明 小红线程同时过来的
public void drawMoney(double money) {// 先搞清楚是谁来取钱?String name = Thread.currentThread().getName();// 1、判断余额是否足够// this正好代表共享资源!synchronized (this) {if(this.money >= money){System.out.println(name + "来取钱" + money + "成功!");this.money -= money;System.out.println(name + "来取钱后,余额剩余:" + this.money);}else {System.out.println(name + "来取钱:余额不足~");}}
}
此时再运行测试类,观察是否会出现不合理的情况。
最后,再给同学们说一下锁对象如何选择的问题
1.建议把共享资源作为锁对象, 不要将随便无关的对象当做锁对象
2.对于实例方法,建议使用this作为锁对象
3.对于静态方法,建议把类的字节码(类名.class)当做锁对象
public static void test(){synchronized (Account.class){}
}// 小明 小红线程同时过来的
public void drawMoney(double money) {// 先搞清楚是谁来取钱?String name = Thread.currentThread().getName();// 1、判断余额是否足够// this正好代表共享资源!synchronized (this) {if(this.money >= money){System.out.println(name + "来取钱" + money + "成功!");this.money -= money;System.out.println(name + "来取钱后,余额剩余:" + this.money);}else {System.out.println(name + "来取钱:余额不足~");}}
}

线程同步方式二:同步方法

// 同步方法public synchronized void drawMoney(double money) {// 先搞清楚是谁来取钱?String name = Thread.currentThread().getName();// 1、判断余额是否足够if(this.money >= money){System.out.println(name + "来取钱" + money + "成功!");this.money -= money;System.out.println(name + "来取钱后,余额剩余:" + this.money);}else {System.out.println(name + "来取钱:余额不足~");}}同步代码块和同步方法的区别
- 不存在哪个好与不好,只是一个锁住的范围大,一个范围小
- 同步方法是将方法中所有的代码锁住
- 同步代码块是将方法中的部分代码锁住
线程同步方式三:Lock锁

Lock锁是JDK5版本专门提供的一种锁对象,通过这个锁对象的方法来达到加锁,和释放锁的目的,使用起来更加灵活。格式如下
1.首先在成员变量位子,需要创建一个Lock接口的实现类对象(这个对象就是锁对象)private final Lock lk = new ReentrantLock();
2.在需要上锁的地方加入下面的代码lk.lock(); // 加锁//...中间是被锁住的代码...lk.unlock(); // 解锁
使用Lock锁改写前面DrawThread中取钱的方法,代码如下
// 创建了一个锁对象
private final Lock lk = new ReentrantLock();public void drawMoney(double money) {// 先搞清楚是谁来取钱?String name = Thread.currentThread().getName();try {lk.lock(); // 加锁// 1、判断余额是否足够if(this.money >= money){System.out.println(name + "来取钱" + money + "成功!");this.money -= money;System.out.println(name + "来取钱后,余额剩余:" + this.money);}else {System.out.println(name + "来取钱:余额不足~");}} catch (Exception e) {e.printStackTrace();} finally {lk.unlock(); // 解锁}}
}
运行程序结果,观察是否有线程安全问题。到此三种解决线程安全问题的办法我们就学习完了。
Lock锁使用的注意事项
- 实例化lock锁对象时,最好将其声明为final,避免别人对锁对象进行修改(因为多个线程访问共享资源时,拿到的锁对象应该是同一个,才能对共享资源进行线程同步的操作)
- 加锁之后最好将执行的核心代码块放进try-catch-finally里面,将解锁操作放进finally代码块里面,这样即使核心代码块出现bug,也能正常解锁,不影响其他线程获取锁
乐观锁和悲观锁
乐观锁:一开始不上锁,认为是没有问题的,所有线程一起跑,等要出现线程安全问题的时候才开始控制,线程安全,性能较好
悲观锁:一上来就上锁,每次只能一个线程进入访问完毕后,再解锁,线程安全,性能较差
互斥同步(阻塞同步)
互斥同步是一种悲观的并发策略,无论数据是否真的会出现竞争,他都要进行加锁。
互斥同步最主要的问题就是线程阻塞和唤醒带来的性能问题,也称阻塞同步。
非阻塞同步
一种乐观并发策略,先进行操作,如果没有其他线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止),这种操作不需要将线程阻塞。
乐观锁需要操作和冲突检测都具备原子性。这里就不能再使用互斥同步来保证了,只能靠硬件来完成。硬件支持的原子性操作最典型的是: 比较并交换(Compare-and-Swap,CAS)。CAS 指令需要有 3 个操作数,分别是内存地址 V、旧的预期值 A 和新值 B。当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。
线程通信
 最经典的就是生产者消费者问题
最经典的就是生产者消费者问题
下面以一个做包子吃包子的类似案例来说明:

接下来,我们先分析一下完成这个案例的思路
1.先确定在这个案例中,什么是共享数据?答:这里案例中桌子是共享数据,因为厨师和顾客都需要对桌子上的包子进行操作。2.再确定有那几条线程?哪个是生产者,哪个是消费者?答:厨师是生产者线程,3条生产者线程; 顾客是消费者线程,2条消费者线程3.什么时候将哪一个线程设置为什么状态生产者线程(厨师)放包子:1)先判断是否有包子2)没有包子时,厨师开始做包子, 做完之后把别人唤醒,然后让自己等待3)有包子时,不做包子了,直接唤醒别人、然后让自己等待消费者线程(顾客)吃包子:1)先判断是否有包子2)有包子时,顾客开始吃包子, 吃完之后把别人唤醒,然后让自己等待3)没有包子时,不吃包子了,直接唤醒别人、然后让自己等待
按照上面分析的思路写代码。先写桌子类,代码如下
public class Desk {private List<String> list = new ArrayList<>();// 放1个包子的方法// 厨师1 厨师2 厨师3public synchronized void put() {try {String name = Thread.currentThread().getName();// 判断是否有包子。if(list.size() == 0){list.add(name + "做的肉包子");System.out.println(name + "做了一个肉包子~~");Thread.sleep(2000);// 唤醒别人, 等待自己// 唤醒一定要放在等待的前面,否则自己已经进入等待,就无法唤醒别人了,相当于自己沉睡了this.notifyAll();this.wait();}else {// 有包子了,不做了。// 唤醒别人, 等待自己this.notifyAll();this.wait();}} catch (Exception e) {e.printStackTrace();}}// 吃货1 吃货2public synchronized void get() {try {String name = Thread.currentThread().getName();if(list.size() == 1){// 有包子,吃了System.out.println(name + "吃了:" + list.get(0));list.clear();Thread.sleep(1000);this.notifyAll();this.wait();}else {// 没有包子this.notifyAll();this.wait();}} catch (Exception e) {e.printStackTrace();}}
}
再写测试类,在测试类中,创建3个厨师线程对象,再创建2个顾客对象,并启动所有线程
public class ThreadTest {public static void main(String[] args) {// 需求:3个生产者线程,负责生产包子,每个线程每次只能生产1个包子放在桌子上// 2个消费者线程负责吃包子,每人每次只能从桌子上拿1个包子吃。Desk desk = new Desk();// 创建3个生产者线程(3个厨师)new Thread(() -> {while (true) {desk.put();}}, "厨师1").start();new Thread(() -> {while (true) {desk.put();}}, "厨师2").start();new Thread(() -> {while (true) {desk.put();}}, "厨师3").start();// 创建2个消费者线程(2个吃货)new Thread(() -> {while (true) {desk.get();}}, "吃货1").start();new Thread(() -> {while (true) {desk.get();}}, "吃货2").start();}
}
执行上面代码,运行结果如下:你会发现多个线程相互协调执行,避免无效的资源挣抢。
厨师1做了一个肉包子~~
吃货2吃了:厨师1做的肉包子
厨师3做了一个肉包子~~
吃货2吃了:厨师3做的肉包子
厨师1做了一个肉包子~~
吃货1吃了:厨师1做的肉包子
厨师2做了一个肉包子~~
吃货2吃了:厨师2做的肉包子
厨师3做了一个肉包子~~
吃货1吃了:厨师3做的肉包子

线程池
什么是线程池

其实,线程池就是一个可以复用线程的技术。
要理解什么是线程复用技术,我们先得看一下不使用线程池会有什么问题,理解了这些问题之后,我们在解释线程复用同学们就好理解了。
假设:用户每次发起一个请求给后台,后台就创建一个新的线程来处理,下次新的任务过来肯定也会创建新的线程,如果用户量非常大,创建的线程也讲越来越多。然而,创建线程是开销很大的,并且请求过多时,会严重影响系统性能。
而使用线程池,就可以解决上面的问题。如下图所示,线程池内部会有一个容器,存储几个核心线程,假设有3个核心线程,这3个核心线程可以处理3个任务。
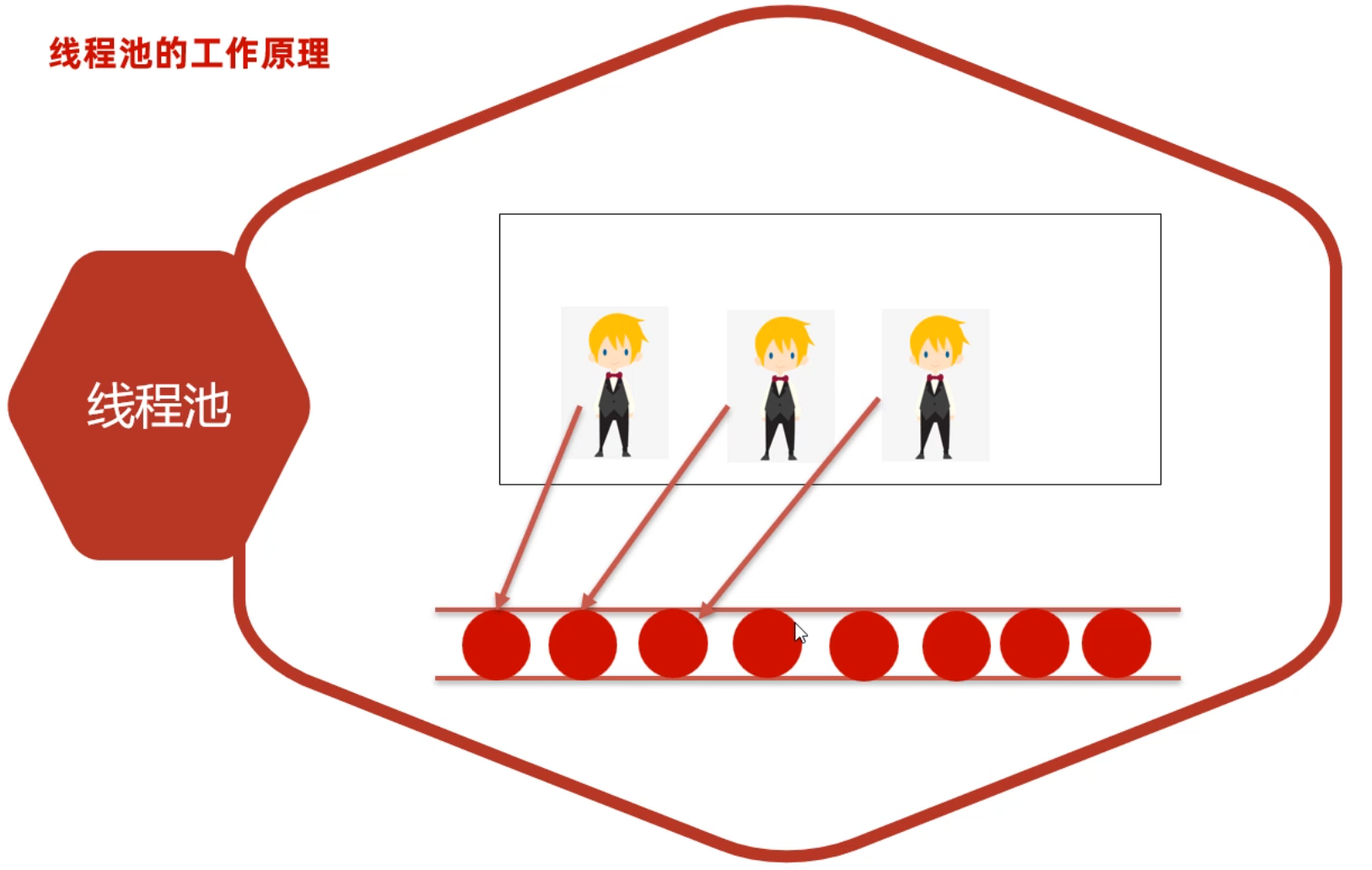
但是任务总有被执行完的时候,假设第1个线程的任务执行完了,那么第1个线程就空闲下来了,有新的任务时,空闲下来的第1个线程可以去执行其他任务。依此内推,这3个线程可以不断的复用,也可以执行很多个任务。
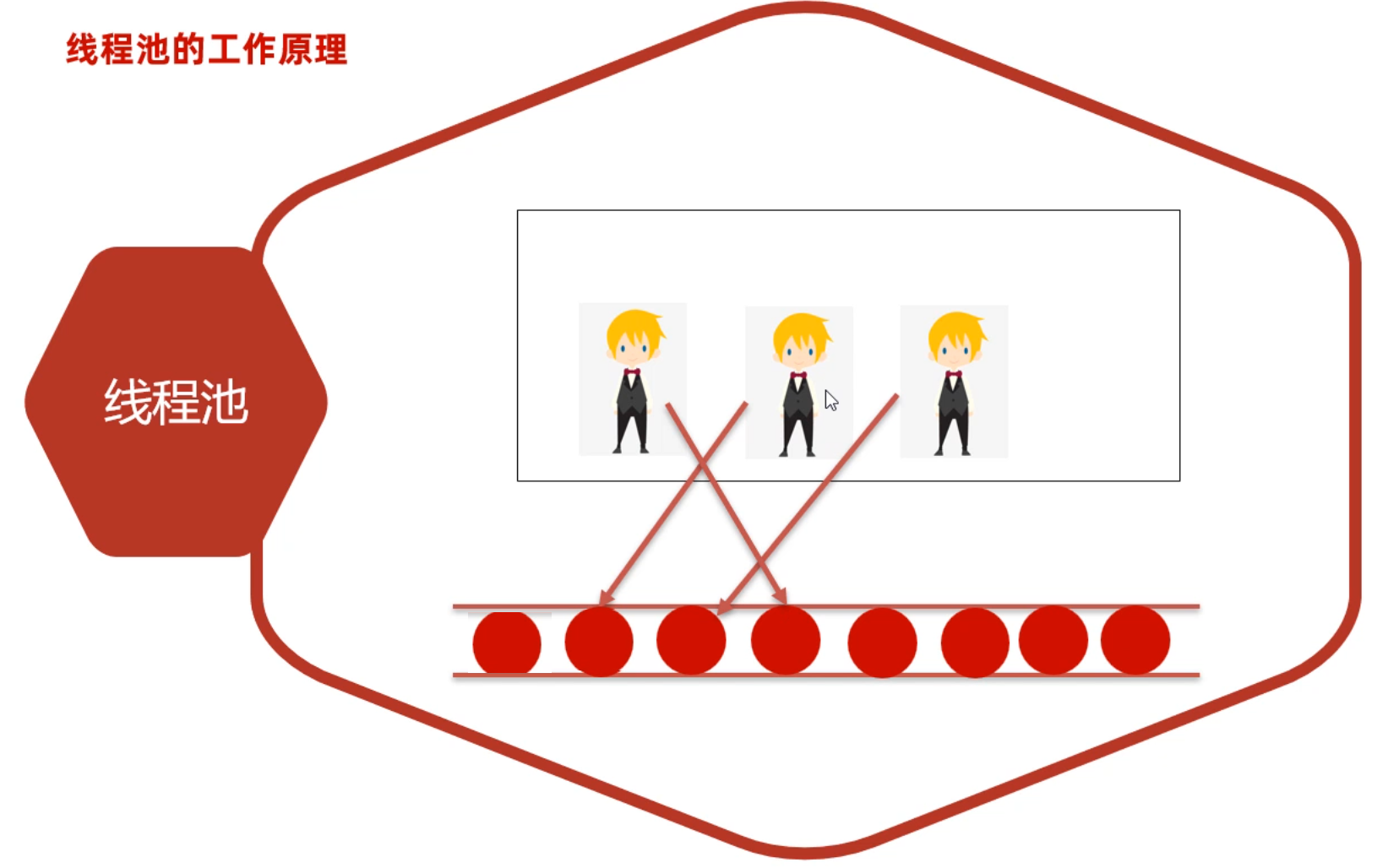
所以,线程池就是一个线程复用技术,它可以提高线程的利用率。
线程池的执行原理
1、当任务到来的时候,直接优先交给核心线程去执行(核心线程数)
2、如果来任务的时候,没有核心线程可用(全部都在执行任务中),那么任务会被丢进任务队列,等待核心线程数执行完来队列中取任务执行
3、如果任务队列满了,再来新任务时,这时候会额外创建临时线程(由线程池的最大线程数来控制的),从而提升队列中任务消费的速度,临时线程无任务执行时,会在临时线程的生存时间到了之后销毁临时线程
4、如果说最大线程数达到最大,任务队列此时也满了,那么来新任务的时候,就由我们设置的拒绝策略来决定新任务是丢弃还是其他功能等
使用线程池的时候如何去设定核心线程数呢?
首先根据理论知识,线程数设置为cpu的核心数*2,然后我们去做压力测试,查看此时服务器的cpu负载情况,保证项目启动,线程数打满的情况下,cpu的消耗在百分之75到80之间
创建线程池

方式一:使用ExecutorService接口的实现类ThreadPoolExecutor类
 接下来,用这7个参数的构造器来创建线程池的对象。代码如下
接下来,用这7个参数的构造器来创建线程池的对象。代码如下
ExecutorService pool = new ThreadPoolExecutor(3, //核心线程数有3个5, //最大线程数有5个。 临时线程数=最大线程数-核心线程数=5-3=28, //临时线程存活的时间8秒。 意思是临时线程8秒没有任务执行,就会被销毁掉。TimeUnit.SECONDS,//时间单位(秒)new ArrayBlockingQueue<>(4), //任务阻塞队列,没有来得及执行的任务在,任务队列中等待Executors.defaultThreadFactory(), //用于创建线程的工厂对象new ThreadPoolExecutor.CallerRunsPolicy() //拒绝策略
);
线程池的注意事项

线程池执行Runnable任务
创建好线程池之后,接下来我们就可以使用线程池执行任务了。线程池执行的任务可以有两种,一种是Runnable任务;一种是callable任务。下面的execute方法可以用来执行Runnable任务。

先准备一个线程任务类
public class MyRunnable implements Runnable{@Overridepublic void run() {// 任务是干啥的?System.out.println(Thread.currentThread().getName() + " ==> 输出666~~");//为了模拟线程一直在执行,这里睡久一点try {Thread.sleep(Integer.MAX_VALUE);} catch (InterruptedException e) {e.printStackTrace();}}
}
下面是执行Runnable任务的代码,注意阅读注释,对照着前面的7个参数理解。
ExecutorService pool = new ThreadPoolExecutor(3, //核心线程数有3个5, //最大线程数有5个。 临时线程数=最大线程数-核心线程数=5-3=28, //临时线程存活的时间8秒。 意思是临时线程8秒没有任务执行,就会被销毁掉。TimeUnit.SECONDS,//时间单位(秒)new ArrayBlockingQueue<>(4), //任务阻塞队列,没有来得及执行的任务在,任务队列中等待Executors.defaultThreadFactory(), //用于创建线程的工厂对象new ThreadPoolExecutor.CallerRunsPolicy() //拒绝策略
);Runnable target = new MyRunnable();
pool.execute(target); // 线程池会自动创建一个新线程,自动处理这个任务,自动执行的!
pool.execute(target); // 线程池会自动创建一个新线程,自动处理这个任务,自动执行的!
pool.execute(target); // 线程池会自动创建一个新线程,自动处理这个任务,自动执行的!
//下面4个任务在任务队列里排队
pool.execute(target);
pool.execute(target);
pool.execute(target);
pool.execute(target);//下面2个任务,会被临时线程的创建时机了
pool.execute(target);
pool.execute(target);
// 到了新任务的拒绝时机了!
pool.execute(target);
执行上面的代码,结果输出如下

新任务拒绝策略

线程池执行Callable任务
接下来,我们学习使用线程池执行Callable任务。callable任务相对于Runnable任务来说,就是多了一个返回值。
执行Callable任务需要用到下面的submit方法

先准备一个Callable线程任务
public class MyCallable implements Callable<String> {private int n;public MyCallable(int n) {this.n = n;}// 2、重写call方法@Overridepublic String call() throws Exception {// 描述线程的任务,返回线程执行返回后的结果。// 需求:求1-n的和返回。int sum = 0;for (int i = 1; i <= n; i++) {sum += i;}return Thread.currentThread().getName() + "求出了1-" + n + "的和是:" + sum;}
}
再准备一个测试类,在测试类中创建线程池,并执行callable任务。
public class ThreadPoolTest2 {public static void main(String[] args) throws Exception {// 1、通过ThreadPoolExecutor创建一个线程池对象。ExecutorService pool = new ThreadPoolExecutor(3,5,8,TimeUnit.SECONDS, new ArrayBlockingQueue<>(4),Executors.defaultThreadFactory(),new ThreadPoolExecutor.CallerRunsPolicy());// 2、使用线程处理Callable任务。Future<String> f1 = pool.submit(new MyCallable(100));Future<String> f2 = pool.submit(new MyCallable(200));Future<String> f3 = pool.submit(new MyCallable(300));Future<String> f4 = pool.submit(new MyCallable(400));// 3、执行完Callable任务后,需要获取返回结果。System.out.println(f1.get());System.out.println(f2.get());System.out.println(f3.get());System.out.println(f4.get());}
}
执行后,结果如下图所示

线程池工具类(Executors)
有同学可能会觉得前面创建线程池的代码参数太多、记不住,有没有快捷的创建线程池的方法呢?有的。Java为开发者提供了一个创建线程池的工具类,叫做Executors,它提供了方法可以创建各种不同特点的线程池。如下图所示

接下来,我们演示一下创建固定线程数量的线程池。这几个方法用得不多,所以这里不做过多演示,同学们了解一下就行了。
public class ThreadPoolTest3 {public static void main(String[] args) throws Exception {// 1、通过Executors创建一个线程池对象。ExecutorService pool = Executors.newFixedThreadPool(17);// 老师:核心线程数量到底配置多少呢???// 计算密集型的任务:核心线程数量 = CPU的核数 + 1// IO密集型的任务:核心线程数量 = CPU核数 * 2// 2、使用线程处理Callable任务。Future<String> f1 = pool.submit(new MyCallable(100));Future<String> f2 = pool.submit(new MyCallable(200));Future<String> f3 = pool.submit(new MyCallable(300));Future<String> f4 = pool.submit(new MyCallable(400));System.out.println(f1.get());System.out.println(f2.get());System.out.println(f3.get());System.out.println(f4.get());}
}
大型并发系统不推荐使用Executors创建线程池
Executors创建线程池这么好用,为什么不推荐同学们使用呢?原因在这里:看下图,这是《阿里巴巴Java开发手册》提供的强制规范要求。


默认线程池
并发和并行
什么是进程、线程?
- 正常运行的程序(软件)就是一个独立的进程
- 线程是属于进程,一个进程中包含多个线程
- 进程中的线程其实并发和并行同时存在
并发和并行
并发:并发是指两个或多个事件在同一时间间隔(同一时间段)发生。
并行:并行是指两个或者多个事件在同一时刻发生。
什么是并发
进程中的线程由CPU负责调度执行,但是CPU同时处理线程的数量是有限的,为了保证全部线程都能执行到,CPU采用轮询机制为系统的每个线程服务,由于CPU切换的速度很快,给我们的感觉这些线程在同时执行,这就是并发。(简单记:并发就是多条线程交替执行)
什么是并行
并行指的是,多个线程同时被CPU调度执行。如下图所示,多个CPU核心在执行多条线程
最后一个问题,多线程到底是并发还是并行呢?
其实多个线程在我们的电脑上执行,并发和并行是同时存在的。
线程的生命周期
接下来就来学习线程的生命周期。在Thread类中有一个嵌套的枚举类叫Thread.Status,这里面定义了线程的6中状态。如下图所示

NEW: 新建状态,线程还没有启动
RUNNABLE: 可以运行状态,线程调用了start()方法后处于这个状态,等待cpu调度
BLOCKED: 锁阻塞状态,线程在执行的时候没有获取到锁处于这个状态
WAITING: 无限等待状态,线程执行时被调用了wait方法处于这个状态另一个线程调用notify或者notifyAll方法才能够唤醒
TIMED_WAITING: 计时等待状态,线程执行时被调用了sleep(毫秒)或者wait(毫秒)方法处于这个状态
TERMINATED: 终止状态, 线程执行完毕或者遇到异常时,处于这个状态。
这几种状态之间切换关系如下图所示
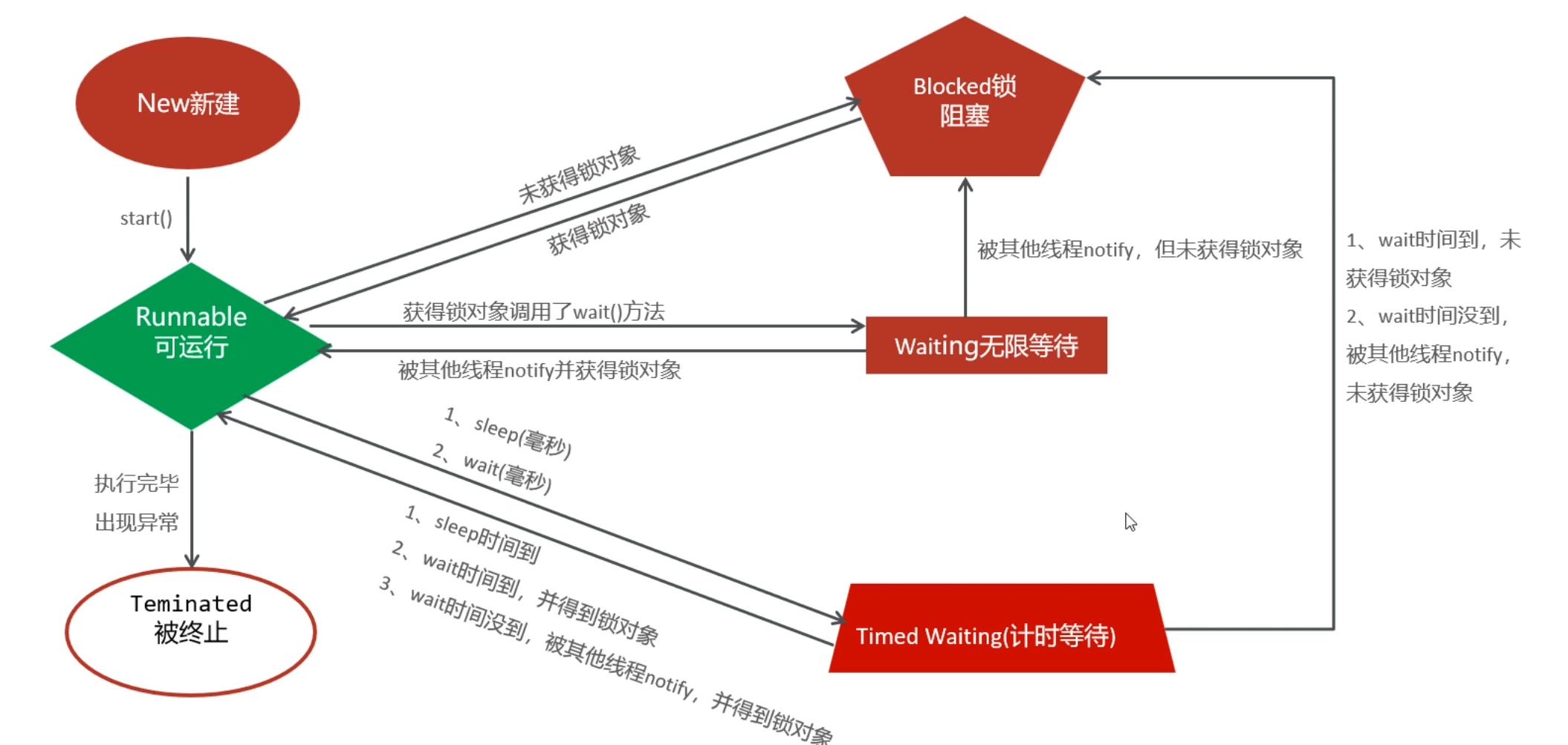
Java的高级技术
单元测试
什么是单元测试
Junit单元测试框架
我们知道单元测试是什么之后,接下来带领同学们使用一下。由于Junit是第三方提供的,所以我们需要把jar包导入到我们的项目中,才能使用,具体步骤如下图所示:

接下来,我们就按照上面的步骤,来使用一下.
先准备一个类,假设写了一个StringUtil工具类,代码如下
public class StringUtil{public static void printNumber(String name){System.out.println("名字长度:"+name.length());}
}
接下来,写一个测试类,测试StringUtil工具类中的方法能否正常使用。
public class StringUtilTest{@Testpublic void testPrintNumber(){StringUtil.printNumber("admin");StringUtil.printNumber(null);}
}
写完代码之后,我们会发现测试方法左边,会有一个绿色的三角形按钮。点击这个按钮,就可以运行测试方法。
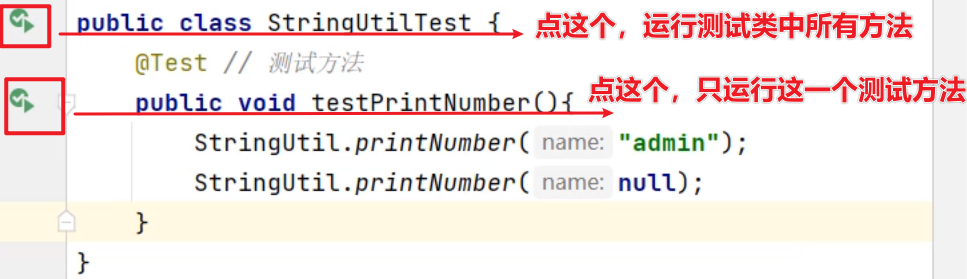
断言机制
所谓断言:意思是程序员可以预测程序的运行结果,检查程序的运行结果是否与预期一致。
我们在StringUtil类中新增一个测试方法
public static int getMaxIndex(String data){if(data == null){return -1;}return data.length();}
接下来,我们在StringUtilTest类中写一个测试方法
public class StringUtilTest{@Testpublic void testGetMaxIndex(){int index1 = StringUtil.getMaxIndex(null);System.out.println(index1);int index2 = StringUtil.getMaxIndex("admin");System.out.println(index2);//断言机制:预测index2的结果Assert.assertEquals("方法内部有Bug",4,index2);}
}
运行测试方法,结果如下图所示,表示我们预期值与实际值不一致
Junit的常见注解
Junit 4.xxxx版本

接下来,我们演示一下其他注解的使用。我们在StringUtilTest测试类中,再新增几个测试方法。代码如下
public class StringUtilTest{@Beforepublic void test1(){System.out.println("--> test1 Before 执行了");}@BeforeClasspublic static void test11(){System.out.println("--> test11 BeforeClass 执行了");}@Afterpublic void test2(){System.out.println("--> test2 After 执行了");}@AfterCalsspublic static void test22(){System.out.println("--> test22 AfterCalss 执行了");}
}
执行上面的测试类,结果如下图所示,观察执行结果特点如下
1.被@BeforeClass标记的方法,执行在所有方法之前
2.被@AfterCalss标记的方法,执行在所有方法之后
3.被@Before标记的方法,执行在每一个@Test方法之前
4.被@After标记的方法,执行在每一个@Test方法之后
我们现在已经知道每一个注解的作用了,那他们有什么用呢?应用场景在哪里?
我们来看一个例子,假设我想在每个测试方法中使用Socket对象,并且用完之后,需要把Socket关闭。代码就可以按照下面的结构来设计
public class StringUtilTest{private static Socket socket;@Beforepublic void test1(){System.out.println("--> test1 Before 执行了");}@BeforeClasspublic static void test11(){System.out.println("--> test11 BeforeClass 执行了");//初始化Socket对象socket = new Socket();}@Afterpublic void test2(){System.out.println("--> test2 After 执行了");}@AfterCalsspublic static void test22(){System.out.println("--> test22 AfterCalss 执行了");//关闭Socketsocket.close();}
}
Junit 5.xxxx版本
和Junit 4.xxxx版本类似,只是注解的叫法不一样了

反射
类的加载时机
1.new对象
2.new子类对象(new子类对象先初始化父类)
3.执行main方法
4.调用静态成员
5.反射,创建Class对象

类加载器
类加载器咱们基于jdk8讲解
1.概述:在jvm中,负责将本地上的class文件加载到内存的对象_ClassLoader
2.分类:BootStrapClassLoader:根类加载器->C语言写的,我们是获取不到的也称之为引导类加载器,负责Java的核心类加载的比如:System,String等jre/lib/rt.jar下的类都是核心类ExtClassLoader(PlatformClassLoader类):扩展类加载器负责jre的扩展目录中的jar包的加载在jdk中jre的lib目录下的ext目录AppClassLoader:系统类加载器负责在jvm启动时加载来自java命令的class文件(自定义类),以及classPath环境变量所指定的jar包(第三方jar包)不同的类加载器负责加载不同的类3.三者的关系(从类加载机制层面):AppClassLoader的父类加载器是ExtClassLoaderExtClassLoader的父类加载器是BootStrapClassLoader但是:他们从代码级别上来看,没有子父类继承关系->他们都有一个共同的父类->ClassLoader4.获取类加载器对象:getClassLoader()是Class对象中的方法类名.class.getClassLoader()5.获取类加载器对象对应的父类加载器ClassLoader类中的方法:ClassLoader getParent()->没啥用6.双亲委派(全盘负责委托机制)a.Person类中有一个StringPerson本身是AppClassLoader加载String是BootStrapClassLoader加载b.加载顺序:Person本身是App加载,按道理来说String也是App加载但是App加载String的时候,先问一问Ext,说:Ext你加载这个String吗?Ext说:我不加载,我负责加载的是扩展类,但是app你别着急,我问问我爹去->bootExt说:boot,你加载String吗?boot说:正好我加载核心类,行吧,我加载吧!7.类加载器的cache(缓存)机制(扩展):一个类加载到内存之后,缓存中也会保存一份儿,后面如果再使用此类,如果缓存中保存了这个类,就直接返回他,如果没有才加载这个类.下一次如果有其他类在使用的时候就不会重新加载了,直接去缓存中拿,保证了类在内存中的唯一性8.所以:类加载器的双亲委派和缓存机制共同造就了加载类的特点:保证了类在内存中的唯一性,防止自定义了与jdk内全限定名一样的类
public class Demo01ClassLoader {public static void main(String[] args) {app();//ext();//boot();}/*** 负责加载核心类* rt.jar包中的类** BootStrapClassLoader是C语言编写,我们获取不到*/private static void boot() {ClassLoader classLoader = String.class.getClassLoader();System.out.println("classLoader = " + classLoader);}/*** 负责加载扩展类*/private static void ext() {ClassLoader classLoader = DNSNameService.class.getClassLoader();System.out.println("classLoader = " + classLoader);}/*** 负责加载自定义类以及第三方jar中的类*/private static void app() {ClassLoader classLoader = Demo01ClassLoader.class.getClassLoader();System.out.println("classLoader = " + classLoader);ClassLoader classLoader1 = FileUtils.class.getClassLoader();System.out.println("classLoader1 = " + classLoader1);ClassLoader parent = classLoader1.getParent();System.out.println("parent = " + parent);//ClassLoader parent1 = parent.getParent();//System.out.println("parent1 = " + parent1);}
}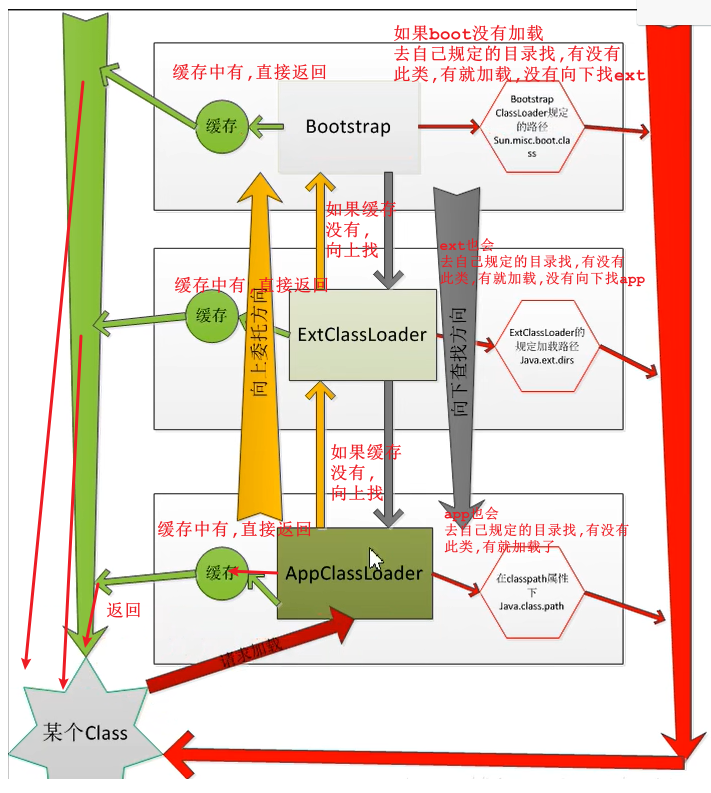
什么是反射
反射就是根据字节码文件, 获得类的信息,字段信息,方法信息等内容, 创建实例,调用方法的技术。
接下来,我们就需要带着同学们认识一下什么是反射。其实API文档中对反射有详细的说明,我们去了解一下。在java.lang.reflect包中对反射的解释如下图所示

翻译成人话就是:反射技术,指的是加载类的字节码到内存,并以编程的方法解刨出类中的各个成分(成员变量、方法、构造器等)。
反射有啥用呢?其实反射是用来写框架用的,但是现阶段同学们对框架还没有太多感觉。为了方便理解,我给同学们看一个我们见过的例子:平时我们用IDEA开发程序时,用对象调用方法,IDEA会有代码提示,idea会将这个对象能调用的方法都给你列举出来,供你选择,如果下图所示
问题是IDEA怎么知道这个对象有这些方法可以调用呢? 原因是对象能调用的方法全都来自于类,IDEA通过反射技术就可以获取到类中有哪些方法,并且把方法的名称以提示框的形式显示出来,所以你能看到这些提示了。
那记事本写代码为什么没有提示呢? 因为技术本软件没有利用反射技术开发这种代码提示的功能,哈哈!!
好了,认识了反射是什么之后,接下来我还想给同学们介绍一下反射具体学什么?
因为反射获取的是类的信息,那么反射的第一步首先获取到类才行。由于Java的设计原则是万物皆对象,获取到的类其实也是以对象的形式体现的,叫字节码对象,用Class类来表示。获取到字节码对象之后,再通过字节码对象就可以获取到类的组成成分了,这些组成成分其实也是对象,其中每一个成员变量用Field类的对象来表示、每一个成员方法用Method类的对象来表示,每一个构造器用Constructor类的对象来表示。
如下图所示:

1、反射获取类的字节码对象
反射的第一步:是将字节码加载到内存,我们需要获取到的字节码对象。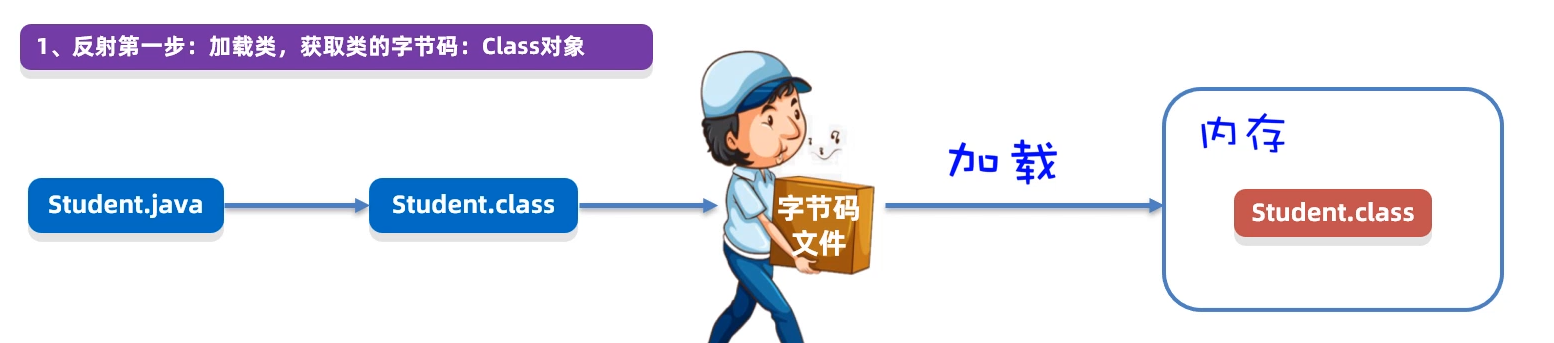
比如有一个Student类,获取Student类的字节码代码有三种写法。不管用哪一种方式,获取到的字节码对象其实是同一个。

public class Test1Class{public static void main(String[] args){Class c1 = Student.class;System.out.println(c1.getName()); //获取全类名System.out.println(c1.getSimpleName()); //获取简单类名Class c2 = Class.forName("com.itheima.d2_reflect.Student");System.out.println(c1 == c2); //trueStudent s = new Student();Class c3 = s.getClass();System.out.println(c2 == c3); //true}
}
2、反射获取类的构造器对象
通过字节码对象获取构造器,并使用构造器创建对象。
获取构造器,需要用到Class类提供的几个方法,如下图所示: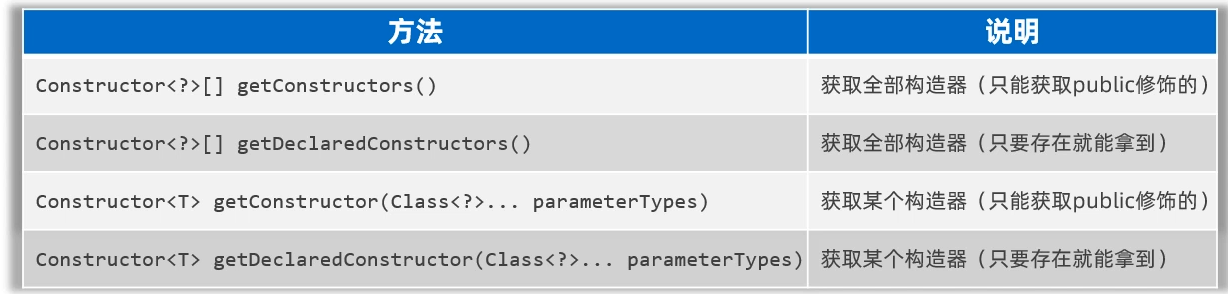
想要快速记住这个方法的区别,给同学们说一下这些方法的命名规律,按照规律来记就很方便了。
get:获取
Declared: 有这个单词表示可以获取任意一个,没有这个单词表示只能获取一个public修饰的
Constructor: 构造方法的意思
后缀s: 表示可以获取多个,没有后缀s只能获取一个
话不多少,上代码。假设现在有一个Cat类,里面有几个构造方法,代码如下
public class Cat{private String name;private int age;public Cat(){}private Cat(String name, int age){}
}
接下来,我们写一个测试方法,来测试获取类中所有的构造器
public class Test2Constructor(){@Testpublic void testGetConstructors(){//1、反射第一步:必须先得到这个类的Class对象Class c = Cat.class;//2、获取类的全部构造器Constructor[] constructors = c.getDeclaredConstructors();//3、遍历数组中的每一个构造器对象。for(Constructor constructor: constructors){System.out.println(constructor.getName()+"---> 参数个数:"+constructor.getParameterCount());}}
}
运行测试方法打印结果如下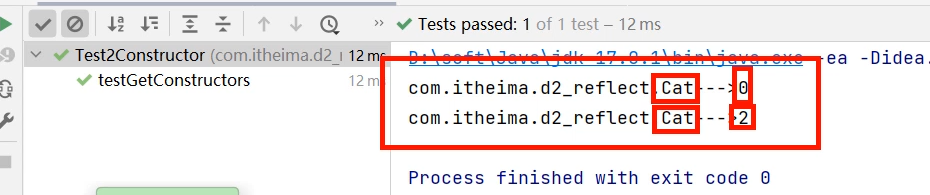
刚才演示的是获取Cat类中所有的构造器,接下来,我们演示单个构造器试一试
public class Test2Constructor(){@Testpublic void testGetConstructor(){//1、反射第一步:必须先得到这个类的Class对象Class c = Cat.class;//2、获取类public修饰的空参数构造器Constructor constructor1 = c.getConstructor();System.out.println(constructor1.getName()+"---> 参数个数:"+constructor1.getParameterCount());//3、获取private修饰的有两个参数的构造器,第一个参数String类型,第二个参数int类型Constructor constructor2 = c.getDeclaredConstructor(String.class,int.class);System.out.println(constructor2.getName()+"---> 参数个数:"+constructor1.getParameterCount());}
}
打印结果如下

反射获取类的构造器的作用
获取到构造器后,有什么作用呢?
其实构造器的作用:初始化对象并返回。
这里我们需要用到如下的两个方法,注意:这两个方法时属于Constructor的,需要用Constructor对象来调用。

如下图所示,constructor1和constructor2分别表示Cat类中的两个构造器。现在我要把这两个构造器执行起来
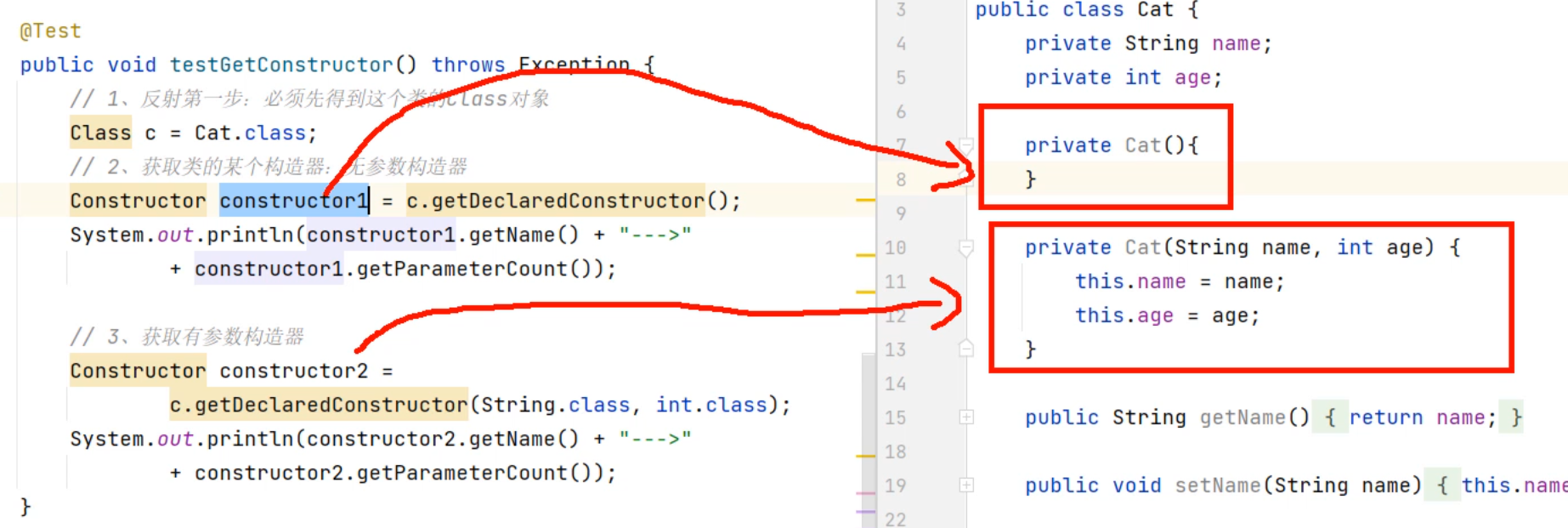
由于构造器是private修饰的,先需要调用setAccessible(true) 表示禁止检查访问控制,然后再调用newInstance(实参列表) 就可以执行构造器,完成对象的初始化了。
代码如下:为了看到构造器真的执行, 故意在两个构造器中分别加了两个打印语句
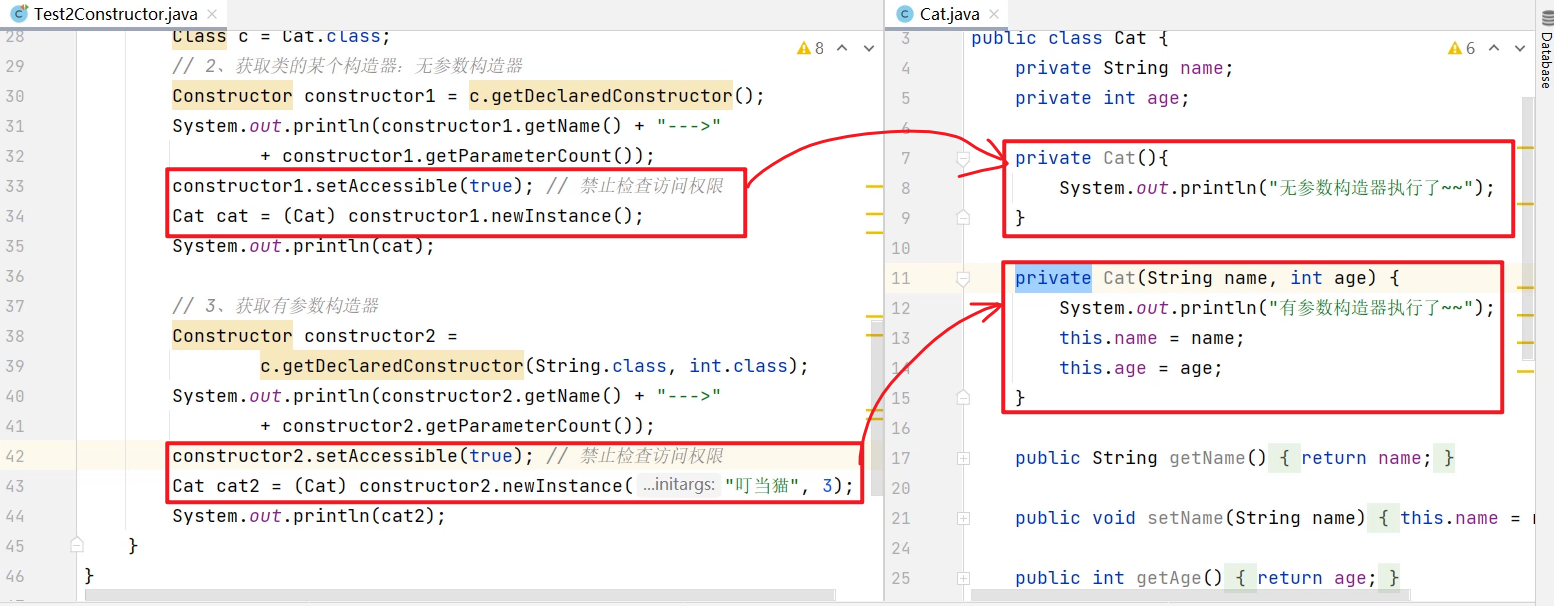
代码的执行结果如下图所示:
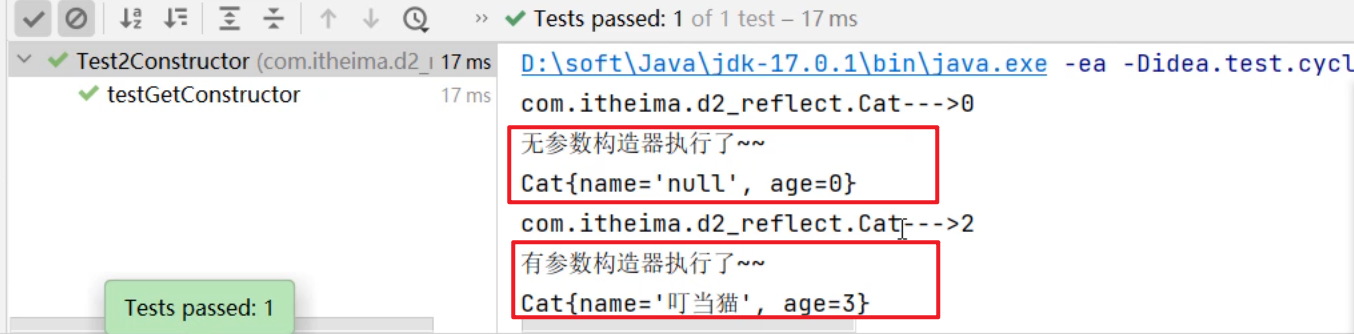
@Testpublic void testGetConstructor() throws Exception {// 1、反射第一步:必须先得到这个类的Class对象Class c = Cat.class;// 2、获取类的某个构造器:无参数构造器Constructor constructor1 = c.getDeclaredConstructor();System.out.println(constructor1.getName() + "--->"+ constructor1.getParameterCount());constructor1.setAccessible(true); // 禁止检查访问权限Cat cat = (Cat) constructor1.newInstance();System.out.println(cat);AtomicInteger a;// 3、获取有参数构造器Constructor constructor2 =c.getDeclaredConstructor(String.class, int.class);System.out.println(constructor2.getName() + "--->"+ constructor2.getParameterCount());constructor2.setAccessible(true); // 禁止检查访问权限Cat cat2 = (Cat) constructor2.newInstance("叮当猫", 3);System.out.println(cat2);}
3、反射获取成员变量&使用
获取类的成员变量,并使用。
其实套路是一样的,在Class类中提供了获取成员变量的方法,如下图所示。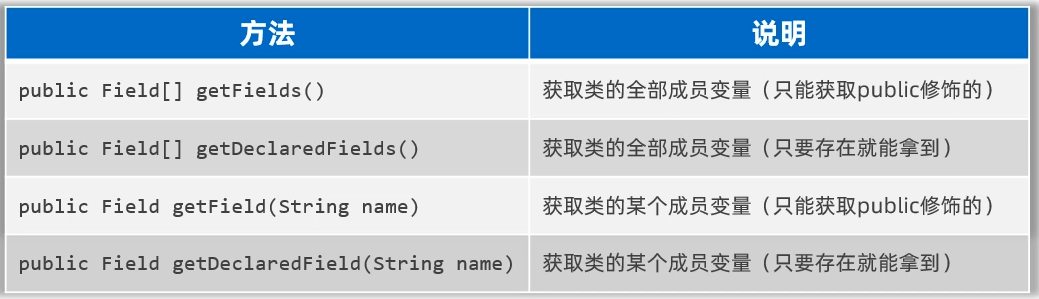
这些方法的记忆规则,如下
get:获取
Declared: 有这个单词表示可以获取任意一个,没有这个单词表示只能获取一个public修饰的
Field: 成员变量的意思
后缀s: 表示可以获取多个,没有后缀s只能获取一个
- 假设有一个Cat类它有若干个成员变量,用Class类提供 的方法将成员变量的对象获取出来。
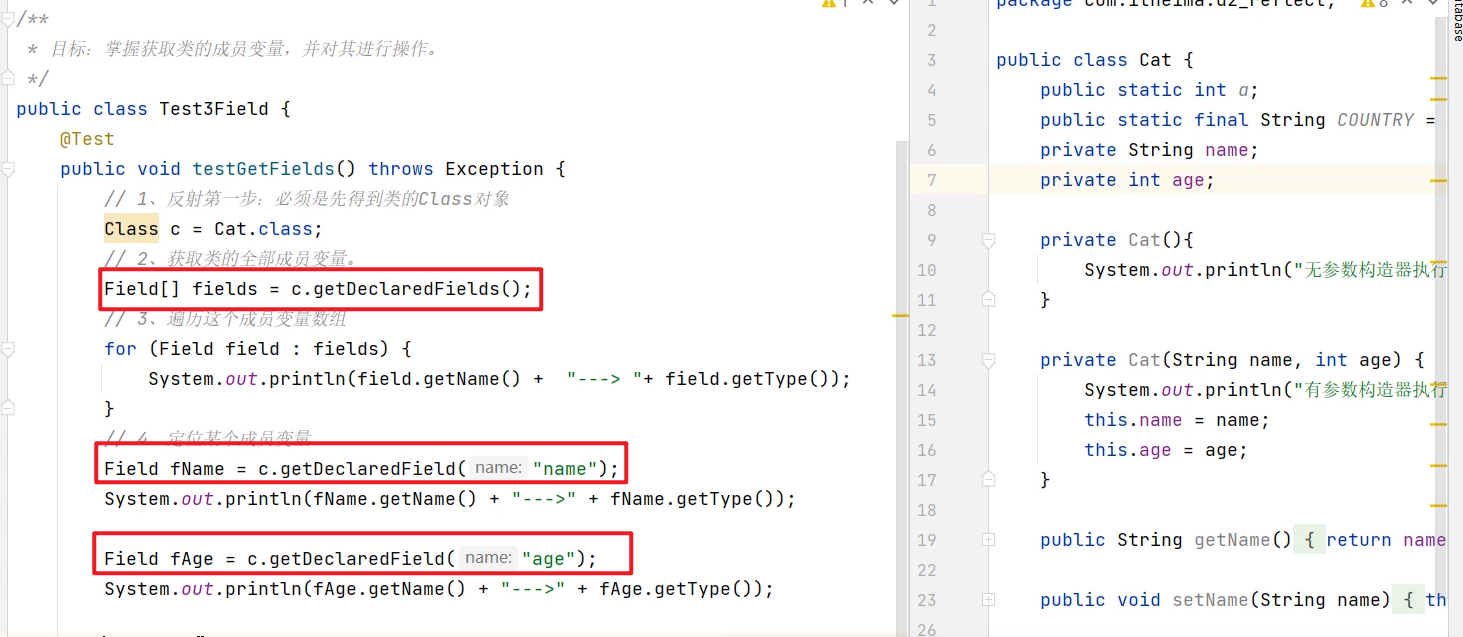
执行完上面的代码之后,我们可以看到控制台上打印输出了,每一个成员变量的名称和它的类型。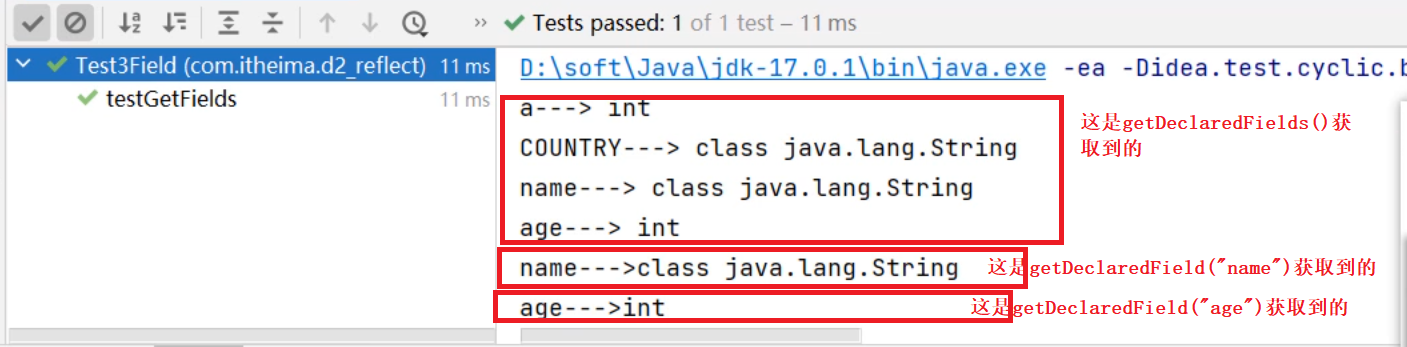
- 获取到成员变量的对象之后该如何使用呢?
在Filed类中提供给给成员变量赋值和获取值的方法,如下图所示。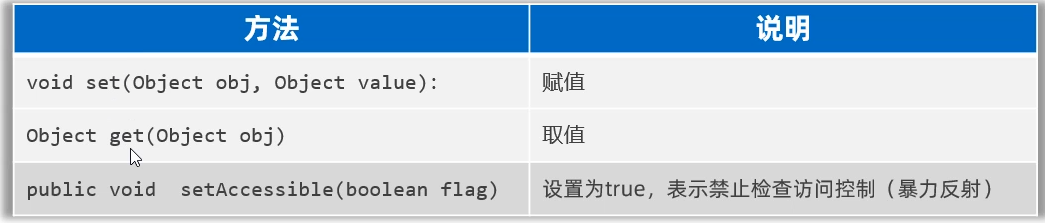
再次强调一下设置值、获取值的方法时Filed类的需要用Filed类的对象来调用,而且不管是设置值、还是获取值,都需要依赖于该变量所属的对象。代码如下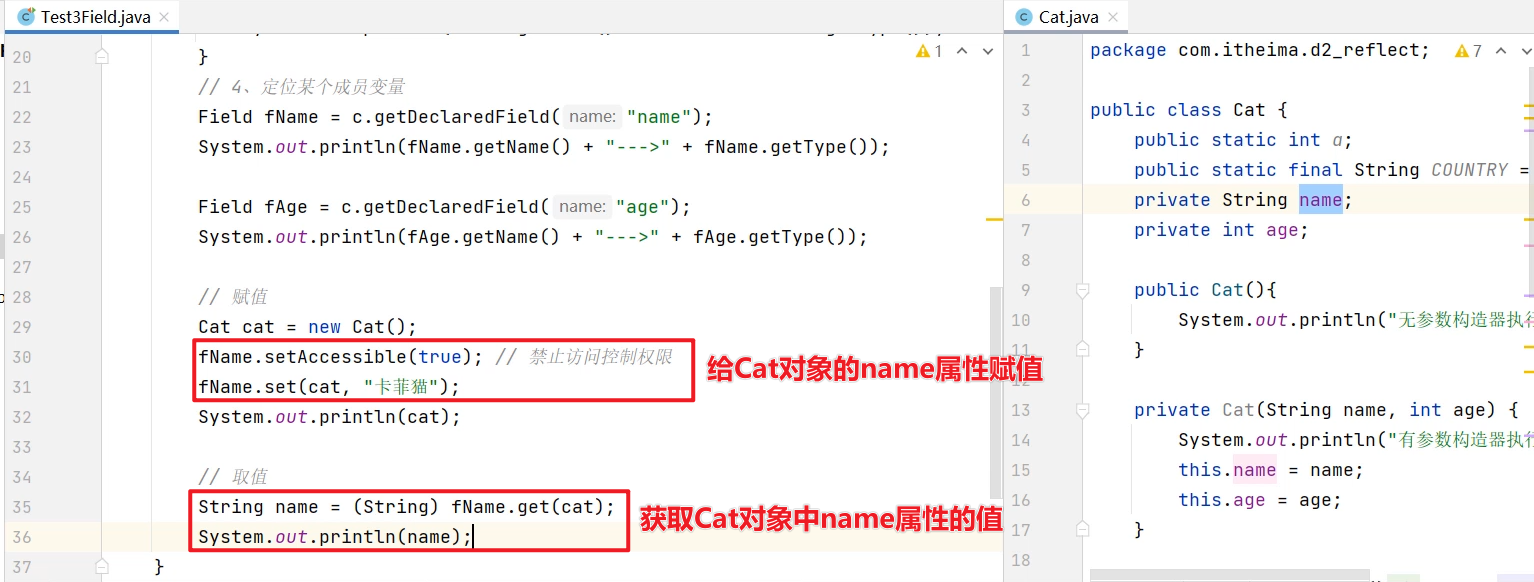
执行代码,控制台会有如下的打印
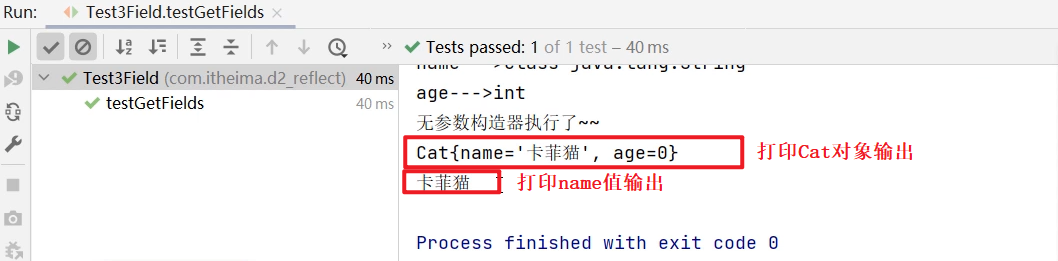
package com.itheima.d2_reflect;import org.junit.Test;import java.lang.reflect.Field;/*** 目标:掌握获取类的成员变量,并对其进行操作。*/
public class Test3Field {@Testpublic void testGetFields() throws Exception {// 1、反射第一步:必须是先得到类的Class对象Class c = Cat.class;// 2、获取类的全部成员变量。Field[] fields = c.getDeclaredFields();// 3、遍历这个成员变量数组for (Field field : fields) {System.out.println(field.getName() + "---> "+ field.getType());}// 4、定位某个成员变量Field fName = c.getDeclaredField("name");System.out.println(fName.getName() + "--->" + fName.getType());Field fAge = c.getDeclaredField("age");System.out.println(fAge.getName() + "--->" + fAge.getType());// 赋值Cat cat = new Cat();fName.setAccessible(true); // 禁止访问控制权限fName.set(cat, "卡菲猫");System.out.println(cat);// 取值String name = (String) fName.get(cat);System.out.println(name);Field a = c.getDeclaredField("a");System.out.println(a.getName() + "--->" + a.getType());}
}4、反射获取成员方法
反射获取成员方法并使用了。
在Java中反射包中,每一个成员方法用Method对象来表示,通过Class类提供的方法可以获取类中的成员方法对象。如下下图所示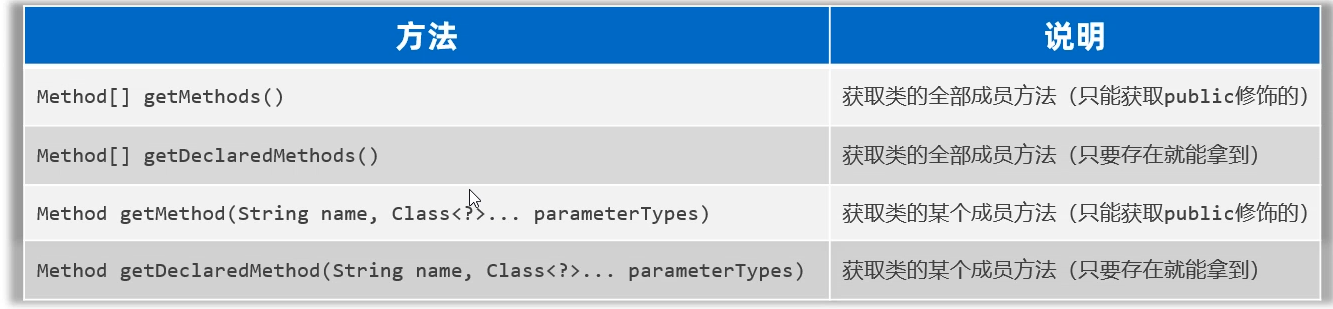
接下来我们还是用代码演示一下:假设有一个Cat类,在Cat类中红有若干个成员方法
public class Cat{private String name;private int age;public Cat(){System.out.println("空参数构造方法执行了");}private Cat(String name, int age){System.out.println("有参数构造方法执行了");this.name=name;this.age=age;}private void run(){System.out.println("(>^ω^<)喵跑得贼快~~");}public void eat(){System.out.println("(>^ω^<)喵爱吃猫粮~");}private String eat(String name){return "(>^ω^<)喵爱吃:"+name;}public void setName(String name){this.name=name;}public String getName(){return name;}public void setAge(int age){this.age=age;}public int getAge(){return age;}
}
接下来,通过反射获取Cat类中所有的成员方法,每一个成员方法都是一个Method对象
public class Test3Method{public static void main(String[] args){//1、反射第一步:先获取到Class对象Class c = Cat.class;//2、获取类中的全部成员方法Method[] methods = c.getDecalaredMethods();//3、遍历这个数组中的每一个方法对象for(Method method : methods){System.out.println(method.getName()+"-->"+method.getParameterCount()+"-->"+method.getReturnType());}}
}
执行上面的代码,运行结果如下图所示:打印输出每一个成员方法的名称、参数格式、返回值类型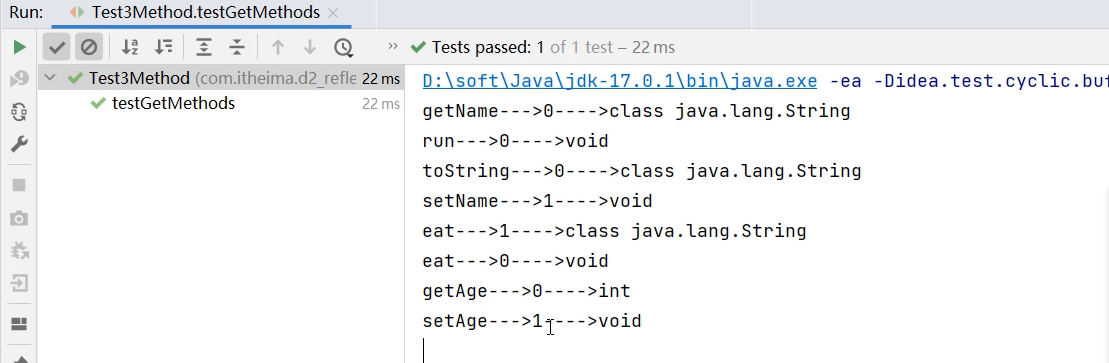
也能获取单个指定的成员方法,如下图所示
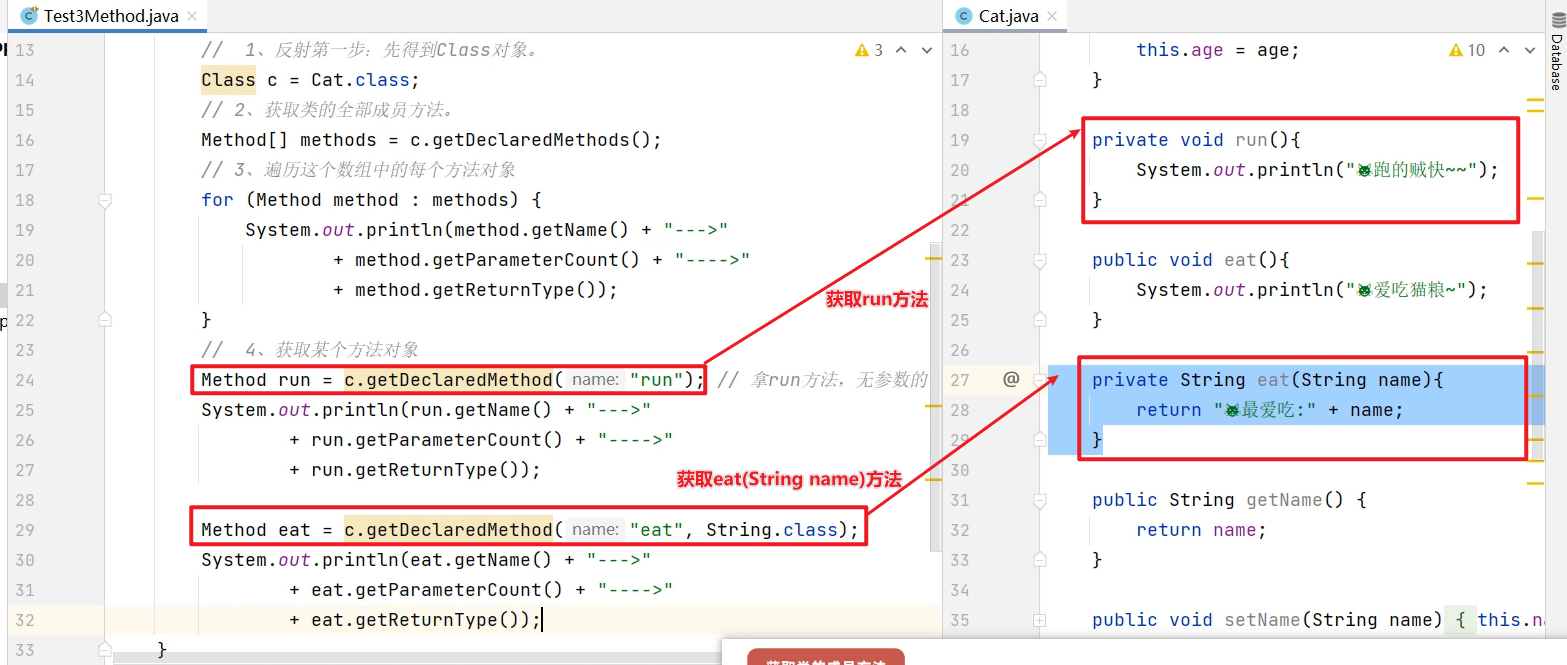
获取到成员方法之后,有什么作用呢?
在Method类中提供了方法,可以将方法自己执行起来。
下面我们演示一下,把run()方法和eat(String name)方法执行起来。看分割线之下的代码
package com.itheima.d2_reflect;import org.junit.Test;import java.lang.reflect.Method;/*** 目标:掌握获取类的成员方法,并对其进行操作。*/
public class Test4Method {@Testpublic void testGetMethods() throws Exception {// 1、反射第一步:先得到Class对象。Class c = Cat.class;// 2、获取类的全部成员方法。Method[] methods = c.getDeclaredMethods();// 3、遍历这个数组中的每个方法对象for (Method method : methods) {System.out.println(method.getName() + "--->"+ method.getParameterCount() + "---->"+ method.getReturnType());}// 4、获取某个方法对象Method run = c.getDeclaredMethod("run"); // 拿run方法,无参数的System.out.println(run.getName() + "--->"+ run.getParameterCount() + "---->"+ run.getReturnType());Method eat = c.getDeclaredMethod("eat", String.class);System.out.println(eat.getName() + "--->"+ eat.getParameterCount() + "---->"+ eat.getReturnType());Cat cat = new Cat();run.setAccessible(true); // 禁止检查访问权限Object rs = run.invoke(cat); // 调用无参数的run方法,用cat对象触发调用的。System.out.println(rs);eat.setAccessible(true); // 禁止检查访问权限String rs2 = (String) eat.invoke(cat, "鱼儿");System.out.println(rs2);}
}
打印结果如下图所示:run()方法执行后打印猫跑得贼快~~,返回null; eat()方法执行完,直接返回猫最爱吃:鱼儿
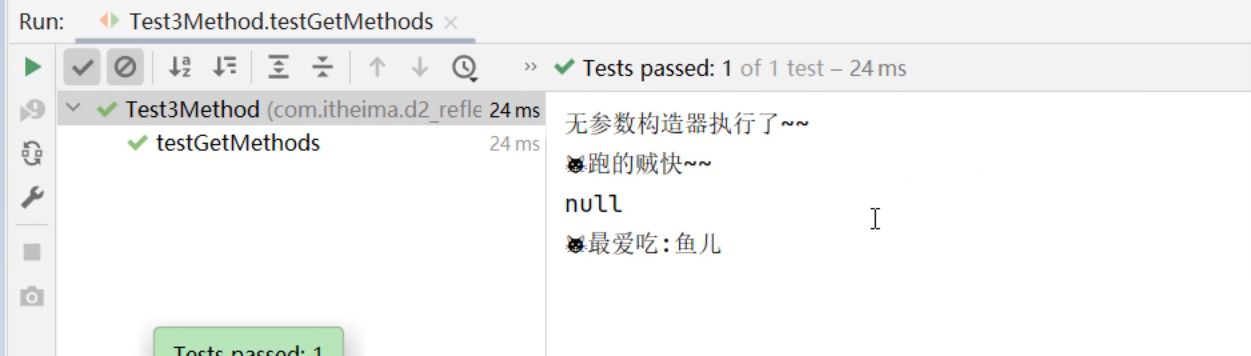 反射的作用和使用场景
反射的作用和使用场景


反射写框架举例
我们一直说反射使用来写框架的,接下来,我们就写一个简易的框架,简单窥探一下反射的应用。反射其实是非常强大的,这个案例也仅仅值小试牛刀。
需求是让我们写一个框架,能够将任意一个对象的属性名和属性值写到文件中去。不管这个对象有多少个属性,也不管这个对象的属性名是否相同。
分析一下该怎么做
1.先写好两个类,一个Student类和Teacher类
2.写一个ObjectFrame类代表框本架在ObjectFrame类中定义一个saveObject(Object obj)方法,用于将任意对象存到文件中去参数:Object obj: 就表示要存入文件中的对象3.编写方法内部的代码,往文件中存储对象的属性名和属性值1)参数obj对象中有哪些属性,属性名是什么实现值是什么,中有对象自己最清楚。2)接着就通过反射获取类的成员变量信息了(变量名、变量值)3)把变量名和变量值写到文件中去
写一个ObjectFrame表示自己设计的框架,代码如下图所示
package com.itheima.d2_reflect;import java.io.FileOutputStream;
import java.io.PrintStream;
import java.lang.reflect.Field;public class ObjectFrame {// 目标:保存任意对象的字段和其数据到文件中去public static void saveObject(Object obj) throws Exception {PrintStream ps = new PrintStream(new FileOutputStream("src\\data.txt", true));// obj是任意对象,到底有多少个字段要保存。Class c = obj.getClass();String cName = c.getSimpleName();ps.println("---------------" + cName + "------------------------");// 2、从这个类中提取它的全部成员变量Field[] fields = c.getDeclaredFields();// 3、遍历每个成员变量。for (Field field : fields) {// 4、拿到成员变量的名字String name = field.getName();// 5、拿到这个成员变量在对象中的数据。field.setAccessible(true); // 禁止检查访问控制String value = field.get(obj) + "";ps.println(name + "=" + value);}ps.close();}
}使用自己设计的框架,往文件中写入Student对象的信息和Teacher对象的信息。
先准备好Student类和Teacher类
public class Student{private String name;private int age;private char sex;private double height;private String hobby;
}
public class Teacher{private String name;private double salary;
}
创建一个测试类,在测试中类创建一个Student对象,创建一个Teacher对象,用ObjectFrame的方法把这两个对象所有的属性名和属性值写到文件中去。
public class Test5Frame{@Testpublic void save() throws Exception{Student s1 = new Student("黑马吴彦祖",45, '男', 185.3, "篮球,冰球,阅读");Teacher s2 = new Teacher("播妞",999.9);ObjectFrame.save(s1);ObjectFrame.save(s2);}
}
打开data.txt文件,内容如下图所示,就说明我们这个框架的功能已经实现了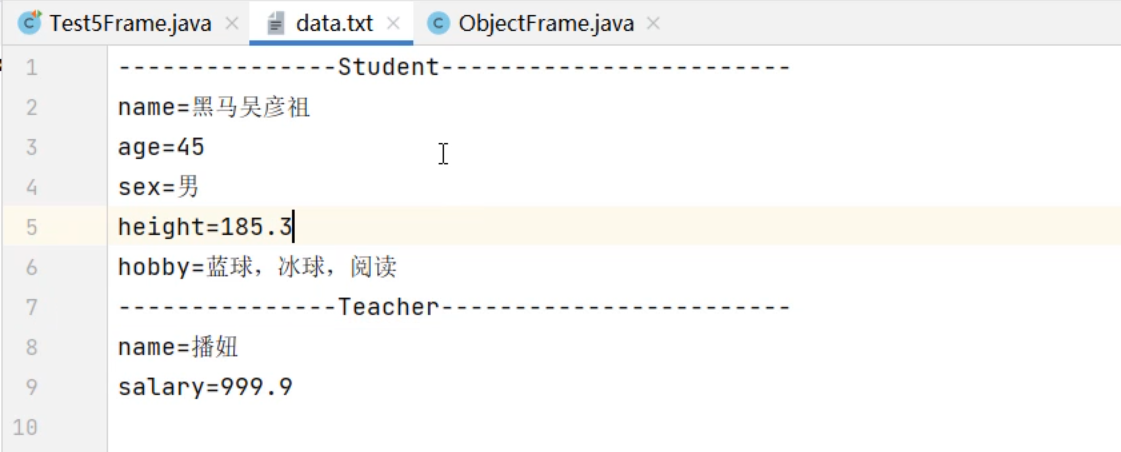
好了,同学们,恭喜大家!学习到这里,反射技术已经学习完毕了。
注解
什么是注解
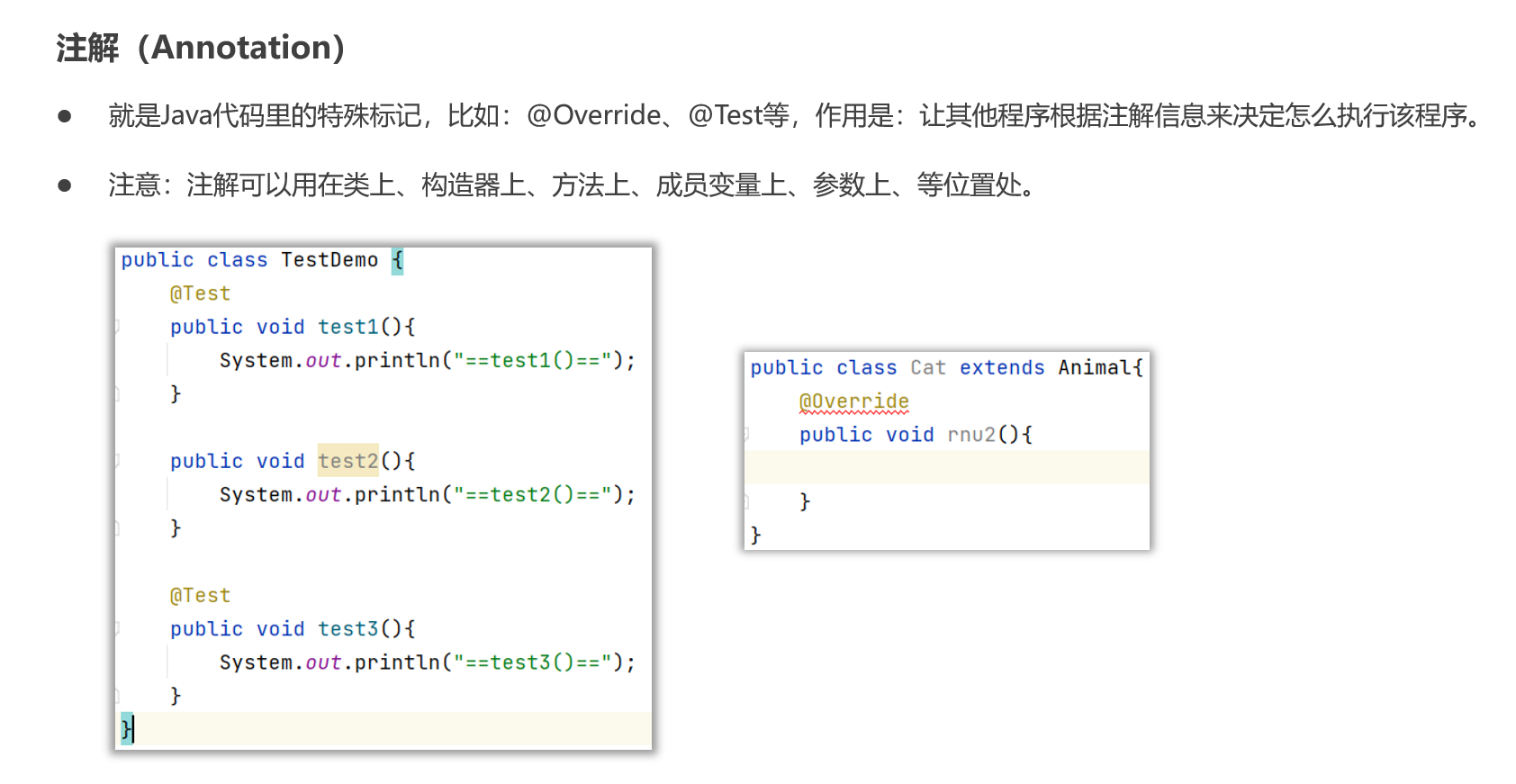 自定义注解
自定义注解

比如:现在我们自定义一个MyTest注解
public @interface MyTest1{String aaa();boolean bbb() default true; //default true 表示默认值为true,使用时可以不赋值。String[] ccc();
}
定义好MyTest注解之后,我们可以使用MyTest注解在类上、方法上等位置做标记。注意使用注解时需要加@符号,如下
@MyTest1(aaa="牛魔王",ccc={"HTML","Java"})
public class AnnotationTest1{@MyTest(aaa="铁扇公主",bbb=false, ccc={"Python","前端","Java"})public void test1(){}
}
注意:注解的属性名如果是value的话,并且只有value没有默认值,使用注解时value名称可以省略。比如现在重新定义一个MyTest2注解
public @interface MyTest2{String value(); //特殊属性int age() default 10;
}
定义好MyTest2注解后,再将@MyTest2标记在类上,此时value属性名可以省略,代码如下
@MyTest2("孙悟空") //等价于 @MyTest2(value="孙悟空")
@MyTest1(aaa="牛魔王",ccc={"HTML","Java"})
public class AnnotationTest1{@MyTest(aaa="铁扇公主",bbb=false, ccc={"Python","前端","Java"})public void test1(){}
}
到这里关于定义注解的格式、以及使用注解的格式就学习完了。
注解的本质
想要搞清楚注解本质是什么东西,我们可以把注解的字节码进行反编译,使用XJad工具进行反编译。经过对MyTest1注解字节码反编译我们会发现:

- MyTest1注解本质上是接口,每一个注解接口都继承子Annotation接口
- MyTest1注解中的属性本质上是抽象方法
- @MyTest1实际上是作为MyTest1接口的实现类对象
- @MyTest1(aaa="孙悟空",bbb=false,ccc={"Python","前端","Java"})里面的属性值,可以通过调用aaa()、bbb()、ccc()方法获取到。 【别着急,继续往下看,再解析注解时会用到】
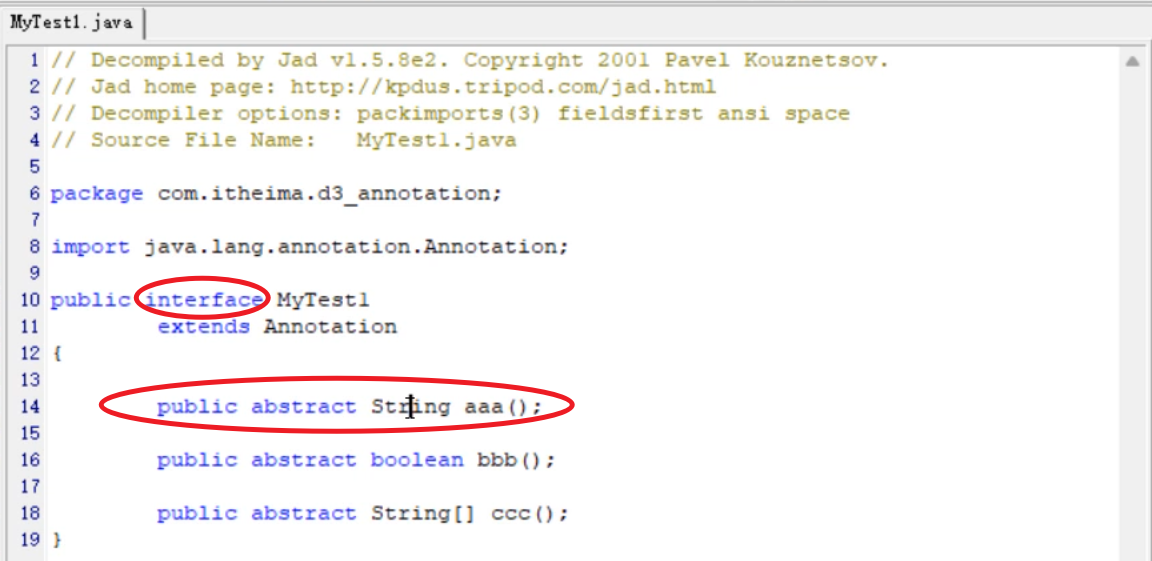
元注解


接下来分别看一下@Target注解和@Retention注解有什么作用,如下图所示
@Target是用来声明注解只能用在那些位置,比如:类上、方法上、成员变量上等
@Retention是用来声明注解保留周期,比如:源代码时期、字节码时期、运行时期
@Target元注解
- @Target元注解的使用:比如定义一个MyTest3注解,并添加@Target注解用来声明MyTest3的使用位置
@Target(ElementType.TYPE) //声明@MyTest3注解只能用在类上
public @interface MyTest3{}
接下来,我们把@MyTest3用来类上观察是否有错,再把@MyTest3用在方法上、变量上再观察是否有错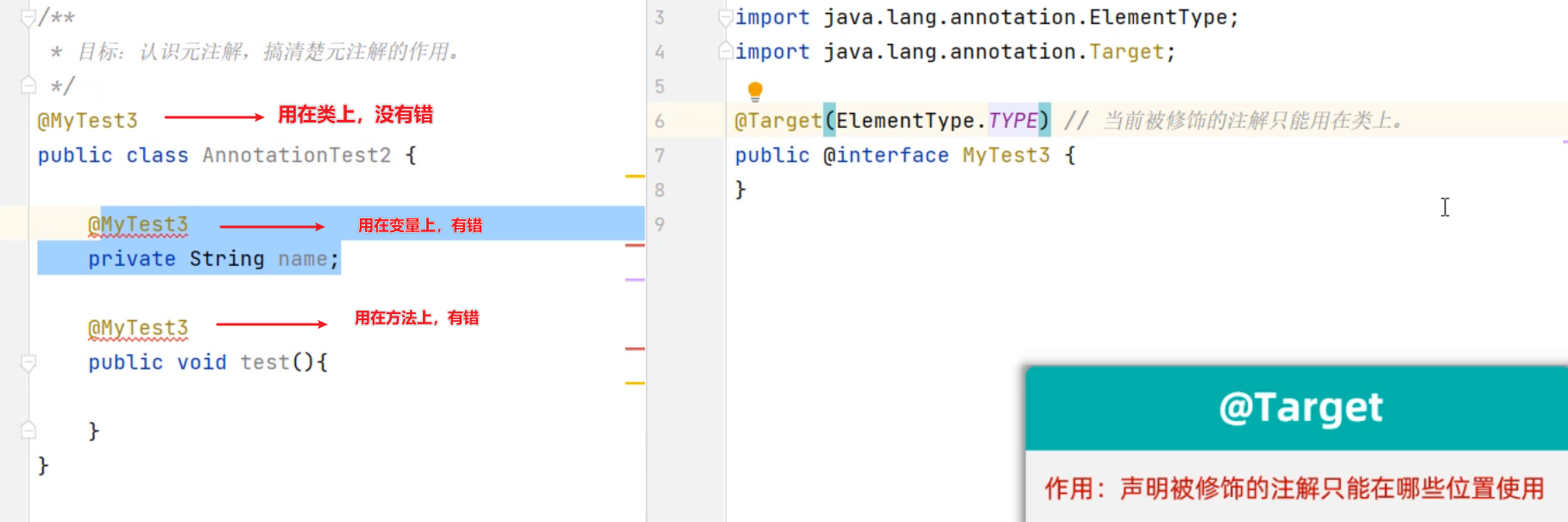
如果我们定义MyTest3注解时,使用@Target注解属性值写成下面样子
//声明@MyTest3注解只能用在类上和方法上
@Target({ElementType.TYPE,ElementType.METHOD})
public @interface MyTest3{}
此时再观察,@MyTest用在类上、方法上、变量上是否有错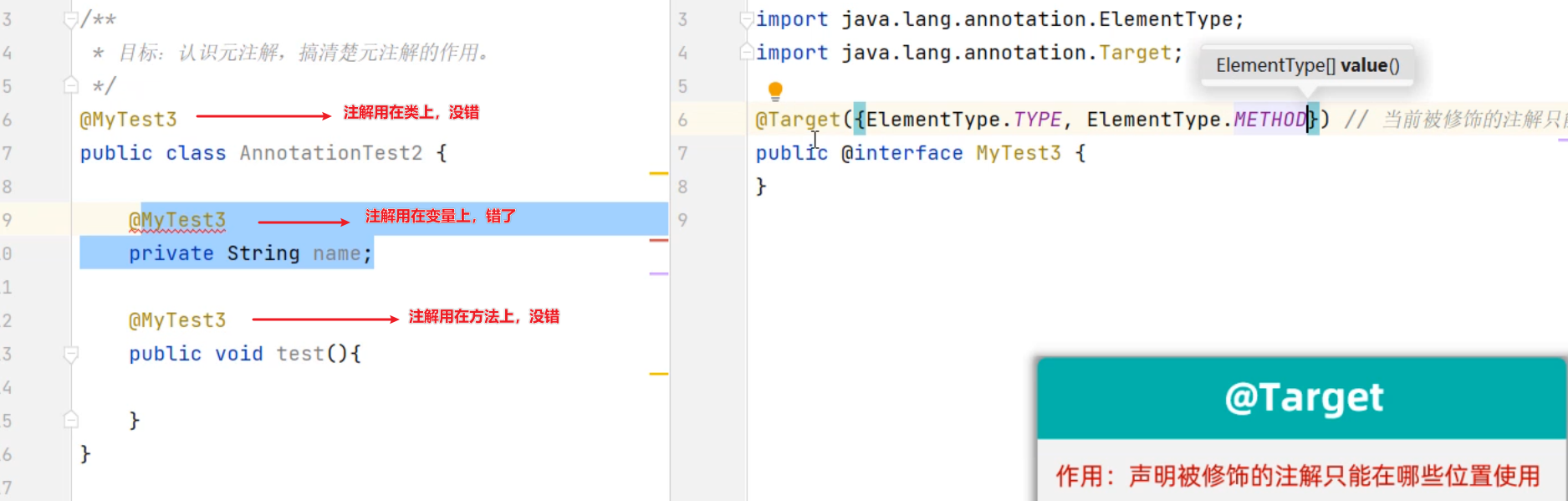
到这里@Target元注解的使用就演示完毕了。
@Retetion元注解
- @Retetion元注解的使用:定义MyTest3注解时,给MyTest3注解添加@Retetion注解来声明MyTest3注解保留的时期
@Retetion是用来声明注解保留周期,比如:源代码时期、字节码时期、运行时期
@Retetion(RetetionPloicy.SOURCE): 注解保留到源代码时期、字节码中就没有了
@Retetion(RetetionPloicy.CLASS): 注解保留到字节码中、运行时注解就没有了
@Retetion(RetetionPloicy.RUNTIME):注解保留到运行时期
【自己写代码时,比较常用的是保留到运行时期】
//声明@MyTest3注解只能用在类上和方法上
@Target({ElementType.TYPE,ElementType.METHOD})
//控制使用了@MyTest3注解的代码中,@MyTest3保留到运行时期
@Retetion(RetetionPloicy.RUNTIME)
public @interface MyTest3{}
@Documented元注解
Documented注解的作用是:描述在使用 javadoc 工具为类生成帮助文档时是否要保留其注解信息。
以下代码在使用Javadoc工具可以生成@TestDocAnnotation注解信息。
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Target;@Documented
@Target({ElementType.TYPE,ElementType.METHOD})
public @interface TestDocAnnotation {public String value() default "default";
}
@TestDocAnnotation("myMethodDoc")
public void testDoc() {}
@Inherited元注解
Inherited注解的作用:被它修饰的Annotation将具有继承性。如果某个类使用了被@Inherited修饰的Annotation,则其子类将自动具有该注解。
我们来测试下这个注解:
- 定义
@Inherited注解:
@Inherited
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE,ElementType.METHOD})
public @interface TestInheritedAnnotation {String [] values();int number();
}
- 使用这个注解
@TestInheritedAnnotation(values = {"value"}, number = 10)
public class Person {
}class Student extends Person{@Testpublic void test(){Class clazz = Student.class;Annotation[] annotations = clazz.getAnnotations();for (Annotation annotation : annotations) {System.out.println(annotation.toString());}}
}
- 输出
xxxxxxx.TestInheritedAnnotation(values=[value], number=10)
即使Student类没有显示地被注解@TestInheritedAnnotation,但是它的父类Person被注解,而且@TestInheritedAnnotation被@Inherited注解,因此Student类自动有了该注解。
@Repeatable (Java8)元注解
Jdk8重复注解
我们再来看看java 8里面的做法:
@Repeatable(Authorities.class)
public @interface Authority {String role();
}public @interface Authorities {Authority[] value();
}public class RepeatAnnotationUseNewVersion {@Authority(role="Admin")@Authority(role="Manager")public void doSomeThing(){ }
}
不同的地方是,创建重复注解Authority时,加上@Repeatable,指向存储注解Authorities,在使用时候,直接可以重复使用Authority注解。从上面例子看出,java 8里面做法更适合常规的思维,可读性强一点
@Native (Java8)元注解
使用 @Native 注解修饰成员变量,则表示这个变量可以被本地代码引用,常常被代码生成工具使用。对于 @Native 注解不常使用,了解即可
注解的解析
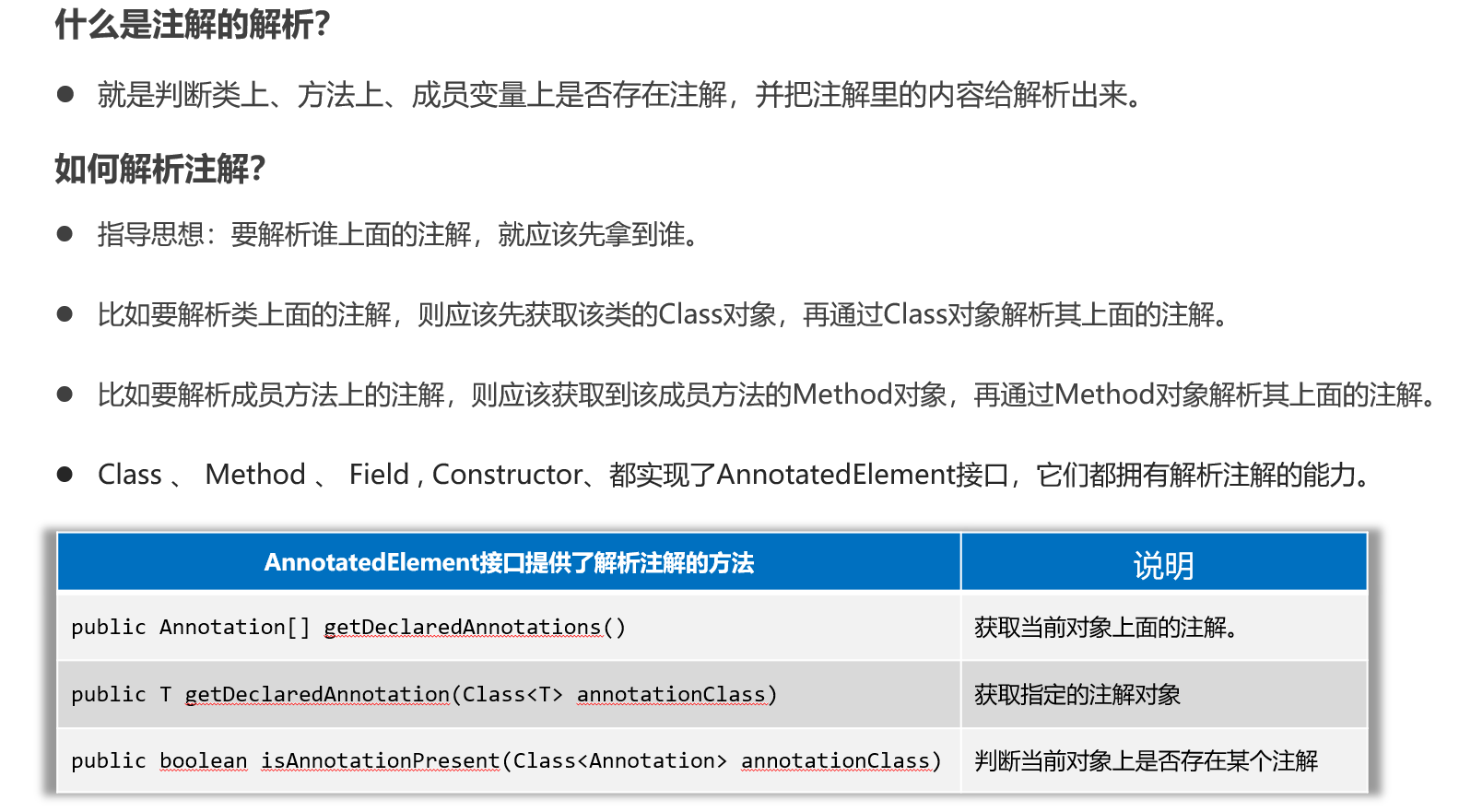
解析注解套路如下
1.如果注解在类上,先获取类的字节码对象,再获取类上的注解
2.如果注解在方法上,先获取方法对象,再获取方法上的注解
3.如果注解在成员变量上,先获取成员变量对象,再获取变量上的注解
总之:注解在谁身上,就先获取谁,再用谁获取谁身上的注解
注解解析案例
解析来看一个案例,来演示解析注解的代码编写
按照需求要求一步一步完成
① 先定义一个MyTest4注解
//声明@MyTest4注解只能用在类上和方法上
@Target({ElementType.TYPE,ElementType.METHOD})
//控制使用了@MyTest4注解的代码中,@MyTest4保留到运行时期
@Retetion(RetetionPloicy.RUNTIME)
public @interface MyTest4{String value();double aaa() default 100;String[] bbb();
}
② 定义有一个类Demo
@MyTest4(value="蜘蛛侠",aaa=99.9, bbb={"至尊宝","黑马"})
public class Demo{@MyTest4(value="孙悟空",aaa=199.9, bbb={"紫霞","牛夫人"})public void test1(){}
}
③ 写一个测试类AnnotationTest3解析Demo类上的MyTest4注解
public class AnnotationTest3{@Testpublic void parseClass(){//1.先获取Class对象Class c = Demo.class;//2.解析Demo类上的注解if(c.isAnnotationPresent(MyTest4.class)){//获取类上的MyTest4注解MyTest4 myTest4 = (MyTest4)c.getDeclaredAnnotation(MyTest4.class);//获取MyTests4注解的属性值System.out.println(myTest4.value());System.out.println(myTest4.aaa());System.out.println(myTest4.bbb());}}@Testpublic void parseMethods(){//1.先获取Class对象Class c = Demo.class;//2.解析Demo类中test1方法上的注解MyTest4注解Method m = c.getDeclaredMethod("test1");if(m.isAnnotationPresent(MyTest4.class)){//获取方法上的MyTest4注解MyTest4 myTest4 = (MyTest4)m.getDeclaredAnnotation(MyTest4.class);//获取MyTests4注解的属性值System.out.println(myTest4.value());System.out.println(myTest4.aaa());System.out.println(myTest4.bbb());}}
}
注解的使用场景
接下来,我们再学习一下注解的应用场景,注解是用来写框架的,比如现在我们要模拟Junit写一个测试框架,要求有@MyTest注解的方法可以被框架执行,没有@MyTest注解的方法不能被框架执行。
第一步:先定义一个MyTest注解
@Target(ElementType.METHOD)
@Retetion(RetetionPloicy.RUNTIME)
public @interface MyTest{}
第二步:写一个测试类AnnotationTest4,在类中定义几个被@MyTest注解标记的方法
public class AnnotationTest4{@MyTestpublic void test1(){System.out.println("=====test1====");}@MyTestpublic void test2(){System.out.println("=====test2====");}public void test3(){System.out.println("=====test2====");}public static void main(String[] args){AnnotationTest4 a = new AnnotationTest4();//1.先获取Class对象Class c = AnnotationTest4.class;//2.解析AnnotationTest4类中所有的方法对象Method[] methods = c.getDeclaredMethods();for(Method m: methods){//3.判断方法上是否有MyTest注解,有就执行该方法if(m.isAnnotationPresent(MyTest.class)){m.invoke(a);}}}
}
动态代理
什么是代理
各位同学,这节课我们学习一个Java的高级技术叫做动态代理。首先我们认识一下代理长什么样?我们以大明星“杨超越”例。
假设现在有一个大明星叫杨超越,它有唱歌和跳舞的本领,作为大明星是要用唱歌和跳舞来赚钱的,但是每次做节目,唱歌的时候要准备话筒、收钱,再唱歌;跳舞的时候也要准备场地、收钱、再唱歌。杨超越越觉得我擅长的做的事情是唱歌,和跳舞,但是每次唱歌和跳舞之前或者之后都要做一些繁琐的事情,有点烦。于是杨超越就找个一个经济公司,请了一个代理人,代理杨超越处理这些事情,如果有人想请杨超越演出,直接找代理人就可以了。如下图所示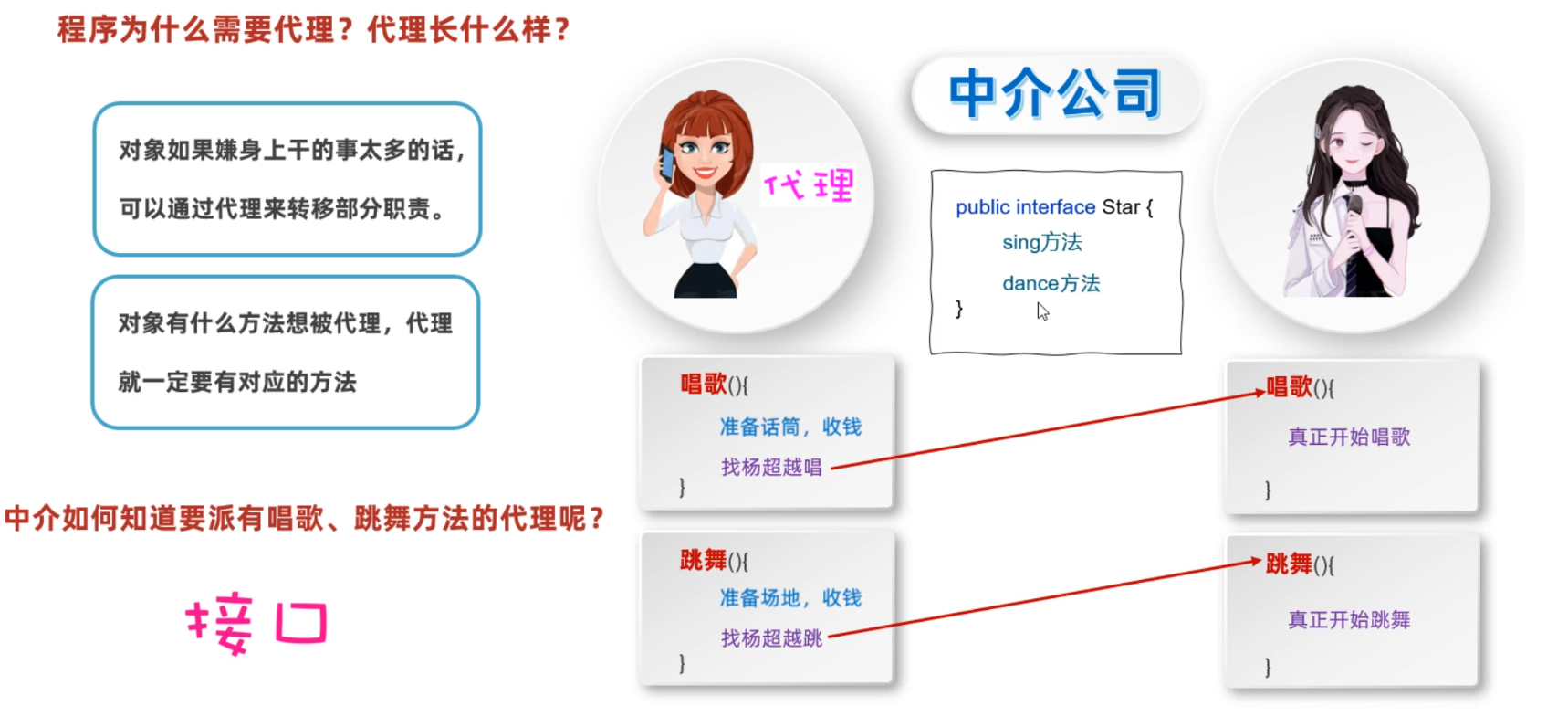
我们说杨超越的代理是中介公司派的,那中介公司怎么知道,要派一个有唱歌和跳舞功能的代理呢?
解决这个问题,Java使用的是接口,杨超越想找代理,在Java中需要杨超越实现了一个接口,接口中规定要唱歌和跳舞的方法。Java就可以通过这个接口为杨超越生成一个代理对象,只要接口中有的方法代理对象也会有。
接下来我们就先把有唱歌和跳舞功能的接口,和实现接口的大明星类定义出来。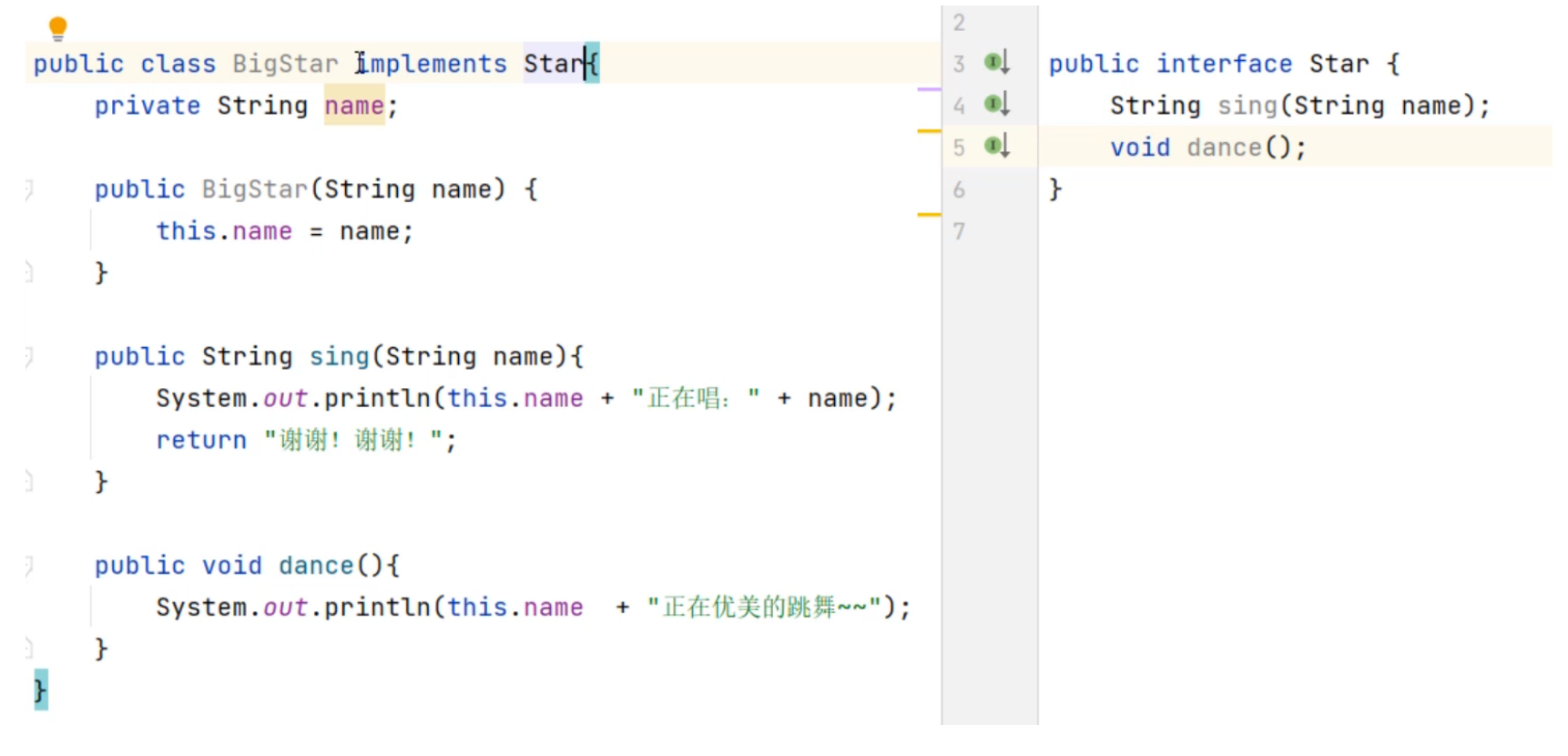
生成动态代理对象
下面我们写一个为BigStar生成动态代理对象的工具类。这里需要用Java为开发者提供的一个生成代理对象的类叫Proxy类。
通过Proxy类的newInstance(...)方法可以为实现了同一接口的类生成代理对象。 调用方法时需要传递三个参数,该方法的参数解释可以查阅API文档,如下。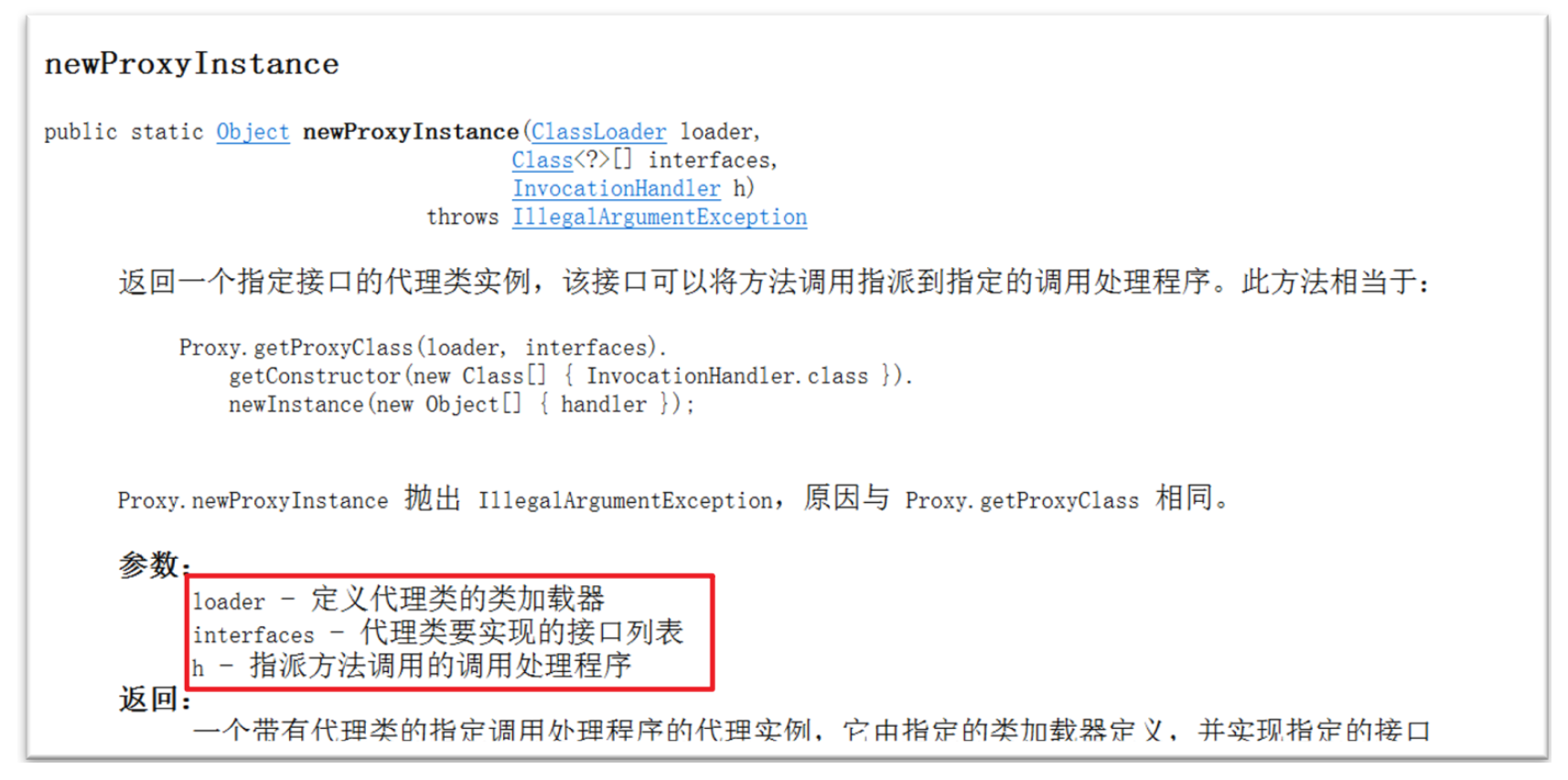
public class ProxyUtil {public static Star createProxy(BigStar bigStar){/* newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h)参数1:用于指定一个类加载器参数2:指定生成的代理长什么样子,也就是有哪些方法参数3:用来指定生成的代理对象要干什么事情*/// Star starProxy = ProxyUtil.createProxy(s);// starProxy.sing("好日子") starProxy.dance()Star starProxy = (Star) Proxy.newProxyInstance(ProxyUtil.class.getClassLoader(),new Class[]{Star.class}, new InvocationHandler() {@Override // 回调方法public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {// 代理对象要做的事情,会在这里写代码if(method.getName().equals("sing")){System.out.println("准备话筒,收钱20万");}else if(method.getName().equals("dance")){System.out.println("准备场地,收钱1000万");}return method.invoke(bigStar, args);}});return starProxy;}
}
调用我们写好的ProxyUtil工具类,为BigStar对象生成代理对象
public class Test {public static void main(String[] args) {BigStar s = new BigStar("杨超越");Star starProxy = ProxyUtil.createProxy(s);String rs = starProxy.sing("好日子");System.out.println(rs);starProxy.dance();}
}
运行测试类,结果如下图所示
恭喜同学们,当你把上面的案例写出来,并且理解,那么动态代理的基本使用就学会了。
动态代理应用
学习完动态代理的基本使用之后,接下来我们再做一个应用案例。
现有如下代码
/*** 用户业务接口*/
public interface UserService {// 登录功能void login(String loginName,String passWord) throws Exception;// 删除用户void deleteUsers() throws Exception;// 查询用户,返回数组的形式。String[] selectUsers() throws Exception;
}
下面有一个UserService接口的实现类,下面每一个方法中都有计算方法运行时间的代码。
/*** 用户业务实现类(面向接口编程)*/
public class UserServiceImpl implements UserService{@Overridepublic void login(String loginName, String passWord) throws Exception {long time1 = System.currentTimeMillis();if("admin".equals(loginName) && "123456".equals(passWord)){System.out.println("您登录成功,欢迎光临本系统~");}else {System.out.println("您登录失败,用户名或密码错误~");}Thread.sleep(1000);long time2 = System.currentTimeMillis();System.out.println("login方法耗时:"+(time2-time1));}@Overridepublic void deleteUsers() throws Exception{long time1 = System.currentTimeMillis();System.out.println("成功删除了1万个用户~");Thread.sleep(1500);long time2 = System.currentTimeMillis();System.out.println("deleteUsers方法耗时:"+(time2-time1));}@Overridepublic String[] selectUsers() throws Exception{long time1 = System.currentTimeMillis();System.out.println("查询出了3个用户");String[] names = {"张全蛋", "李二狗", "牛爱花"};Thread.sleep(500);long time2 = System.currentTimeMillis();System.out.println("selectUsers方法耗时:"+(time2-time1));return names;}
}
观察上面代码发现有什么问题吗?
我们会发现每一个方法中计算耗时的代码都是重复的,我们可是学习了动态代理的高级程序员,怎么能忍受在每个方法中写重复代码呢!况且这些重复的代码并不属于UserSerivce的主要业务代码。
所以接下来我们打算,把计算每一个方法的耗时操作,交给代理对象来做。
先在UserService类中把计算耗时的代码删除,代码如下
/*** 用户业务实现类(面向接口编程)*/
public class UserServiceImpl implements UserService{@Overridepublic void login(String loginName, String passWord) throws Exception {if("admin".equals(loginName) && "123456".equals(passWord)){System.out.println("您登录成功,欢迎光临本系统~");}else {System.out.println("您登录失败,用户名或密码错误~");}Thread.sleep(1000);}@Overridepublic void deleteUsers() throws Exception{System.out.println("成功删除了1万个用户~");Thread.sleep(1500);}@Overridepublic String[] selectUsers() throws Exception{System.out.println("查询出了3个用户");String[] names = {"张全蛋", "李二狗", "牛爱花"};Thread.sleep(500);return names;}
}
然后为UserService生成一个动态代理对象,在动态代理中调用目标方法,在调用目标方法之前和之后记录毫秒值,并计算方法运行的时间。代码如下
package com.itheima.d5_proxy2;import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;public class ProxyUtil {public static UserService createProxy(UserService userService) {UserService userServiceProxy = (UserService) Proxy.newProxyInstance(ProxyUtil.class.getClassLoader(), new Class[]{UserService.class}, new InvocationHandler() {@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {if (method.getName().equals("login") || method.getName().equals("deleteUsers") || method.getName().equals("selectUsers")) {long startTime = System.currentTimeMillis();Object rs = method.invoke(userService, args);long endTime = System.currentTimeMillis();System.out.println(method.getName() + "方法执行耗时:" + (endTime - startTime) / 1000.0 + "s");return rs;} else {Object rs = method.invoke(userService, args);return rs;}}});return userServiceProxy;}
}在测试类中为UserService创建代理对象
/*** 目标:使用动态代理解决实际问题,并掌握使用代理的好处。*/
public class Test {public static void main(String[] args) throws Exception{// 1、创建用户业务对象。UserService userService = ProxyUtil.createProxy(new UserServiceImpl());// 2、调用用户业务的功能。userService.login("admin", "123456");System.out.println("----------------------------------");userService.deleteUsers();System.out.println("----------------------------------");String[] names = userService.selectUsers();System.out.println("查询到的用户是:" + Arrays.toString(names));System.out.println("----------------------------------");}
}
执行结果如下图所示
动态代理对象的执行流程如下图所示,每次用代理对象调用方法时,都会执行InvocationHandler中的invoke方法。
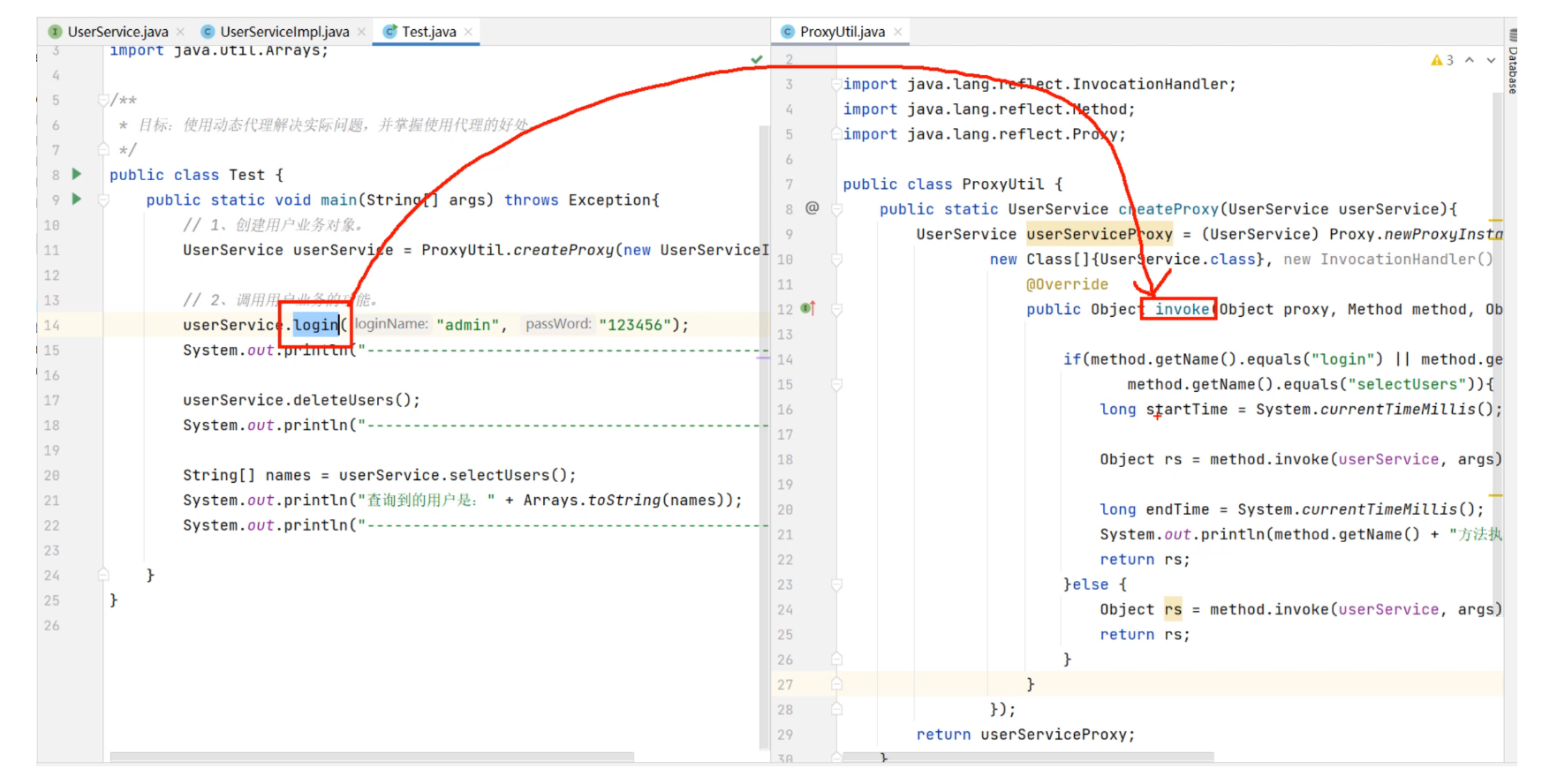
网络编程
一、网络编程概述
同学们,今天我们学习的课程内容叫网络编程。意思就是编写的应用程序可以与网络上其他设备中的应用程序进行数据交互。
网络编程有什么用呢?这个就不言而喻了,比如我们经常用的微信收发消息就需要用到网络通信的技术、在比如我们打开浏览器可以浏览各种网络、视频等也需要用到网络编程的技术。
我们知道什么是网络编程、也知道网络编程能干什么后了,那Java给我们提供了哪些网络编程的解决方案呢?
Java提供的网络编程的解决方案都是在java.net包下。在正式学习Java网络编程技术之前,我们还需要学习一些网络通信的前置知识理论知识,只有这些前置知识做基础,我们学习网络编程代码编写才起来才能继续下去。
首先和同学们聊聊网络通信的基本架构。通信的基本架构主要有两种形式:一种是CS架构(Client 客户端/Server服务端)、一种是BS架构(Brower 浏览器/Server服务端)。
- CS架构的特点:CS架构需要用户在自己的电脑或者手机上安装客户端软件,然后由客户端软件通过网络连接服务器程序,由服务器把数据发给客户端,客户端就可以在页面上看到各种数据了。
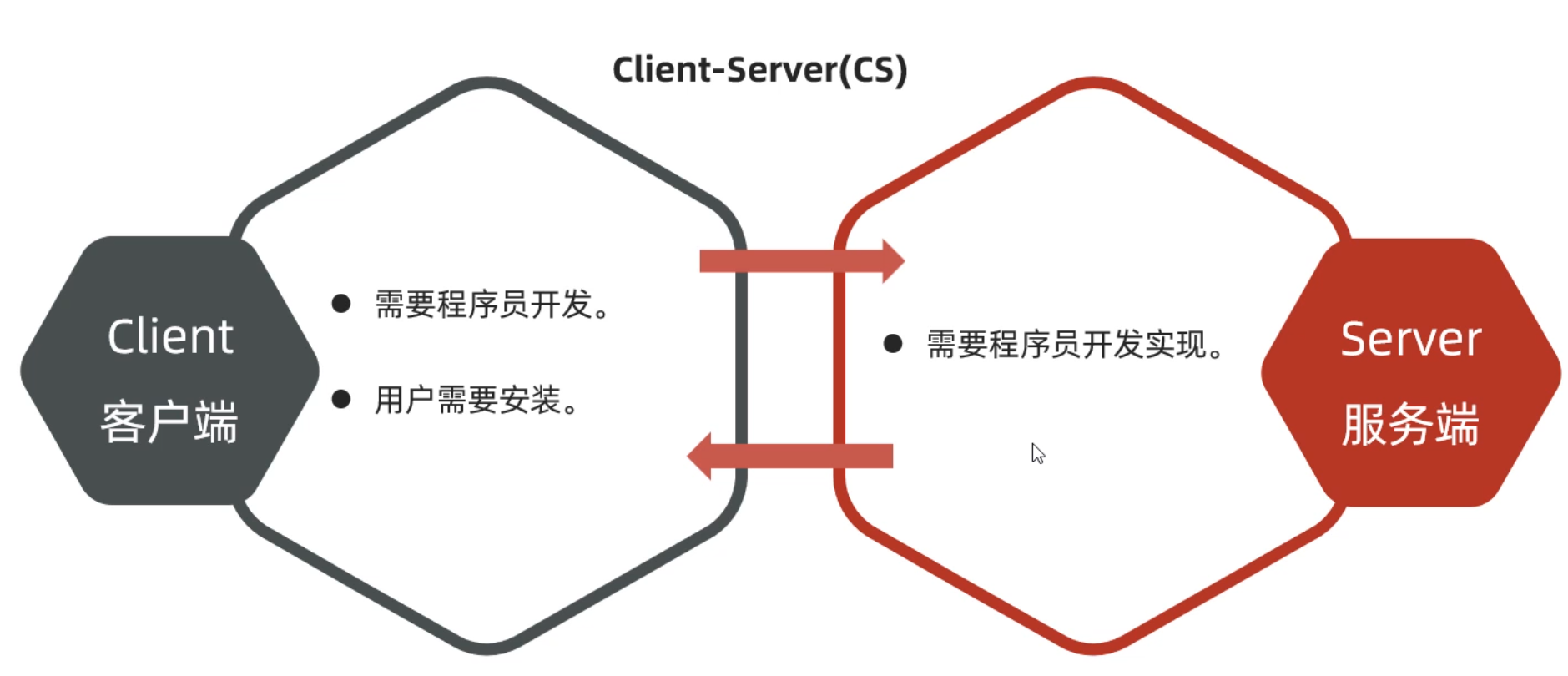
-
BS架构的特点:BS架构不需要开发客户端软件,用户只需要通过浏览器输入网址就可以直接从服务器获取数据,并由服务器将数据返回给浏览器,用户在页面上就可以看到各种数据了。
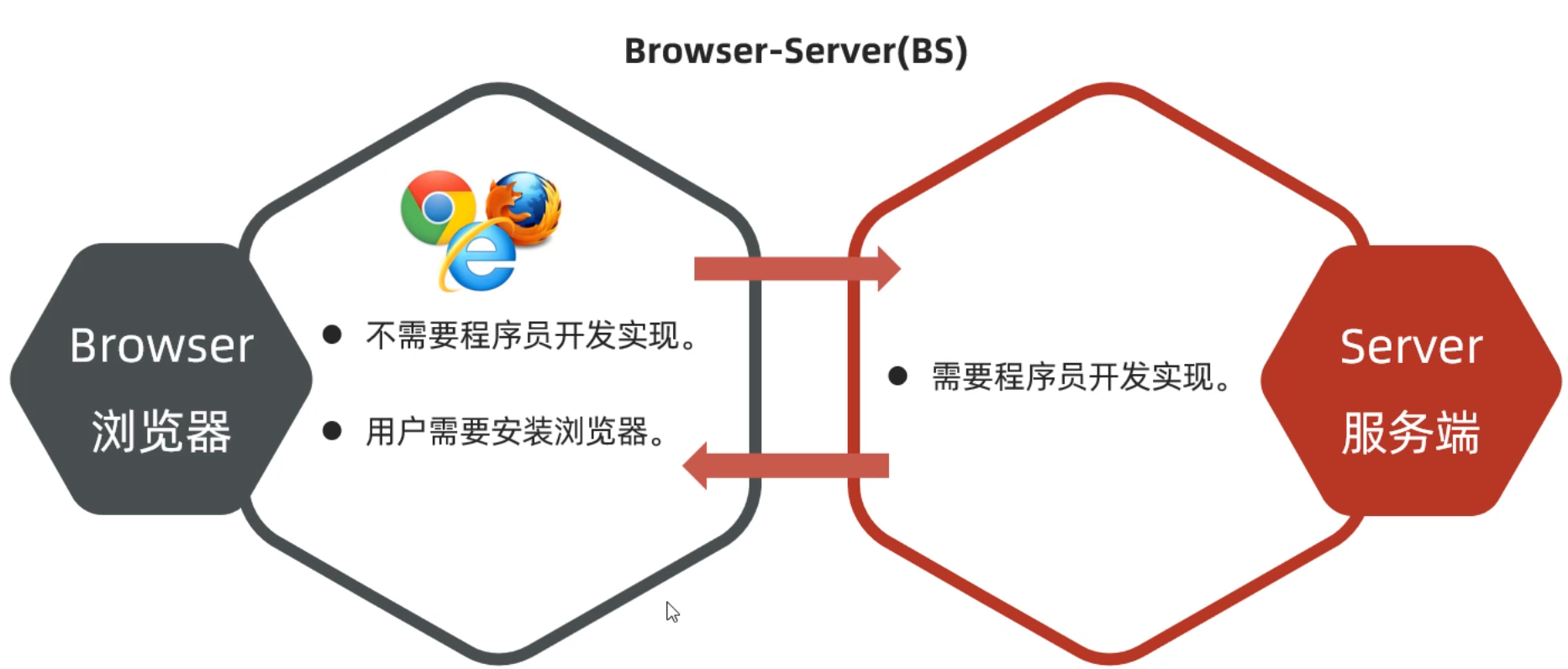
这两种结构不管是CS、还是BS都是需要用到网络编程的相关技术。我们学习Java的程序员,以后从事的工作方向主要还是BS架构的。
二、网络编程三要素
各位小伙伴,我们前面已经知道什么是网络编程了。接下来我们还需要学习一些网络编程的基本概念,才能去编写网络编程的应用程序。
有哪三要素呢?分别是IP地址、端口号、通信协议

-
IP地址:表示设备在网络中的地址,是网络中设备的唯一标识
-
端口号:应用程序在设备中唯一的标识
-
协议:连接和数据在网络中传输的规则。
如下图所示:假设现在要从一台电脑中的微信上,发一句“你愁啥?”到其他电脑的微信上,流程如下
1.先通过ip地址找到对方的电脑
2.再通过端口号找到对方的电脑上的应用程序
3.按照双方约定好的规则发送、接收数据
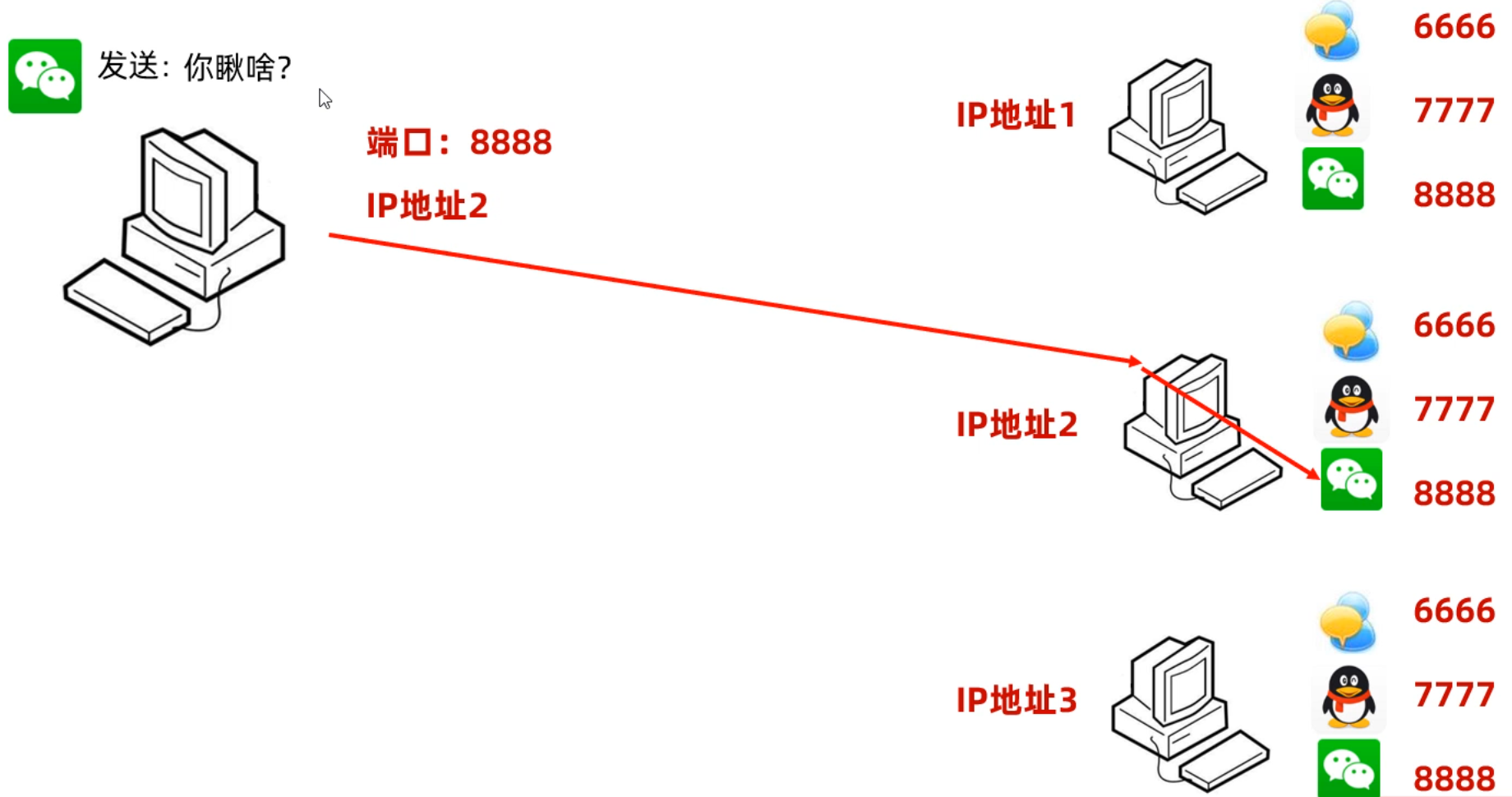
2.1 IP地址
接下来,我们详细介绍一下IP地址。IP(Ineternet Protocol)全称互联网协议地址,是分配给网络设备的唯一表示。IP地址分为:IPV4地址、IPV6地址
IPV4地址由32个比特位(4个字节)组成,如果下图所示,但是由于采用二进制太不容易阅读了,于是就将每8位看成一组,把每一组用十进制表示(叫做点分十进制表示法)。所以就有了我们经常看到的IP地址形式,如:192.168.1.66
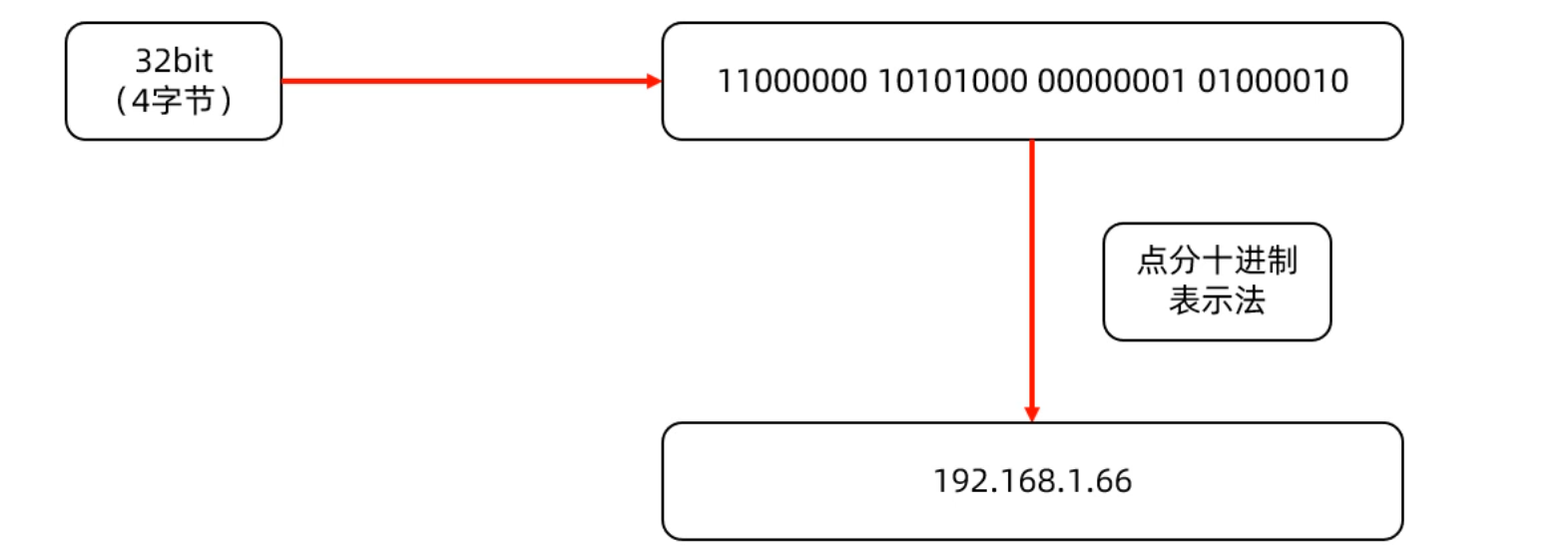
如果想查看本机的IP地址,可以在命令行窗口,输入ipconfig命令查看,如下图所示
经过不断的发展,现在越来越多的设备需要联网,IPV4地址已经不够用了,所以扩展出来了IPV6地址。
IPV6采用128位二进制数据来表示(16个字节),号称可以为地球上的每一粒沙子编一个IP地址,
IPV6比较长,为了方便阅读,每16位编成一组,每组采用十六进制数据表示,然后用冒号隔开(称为冒分十六进制表示法),如下图所示
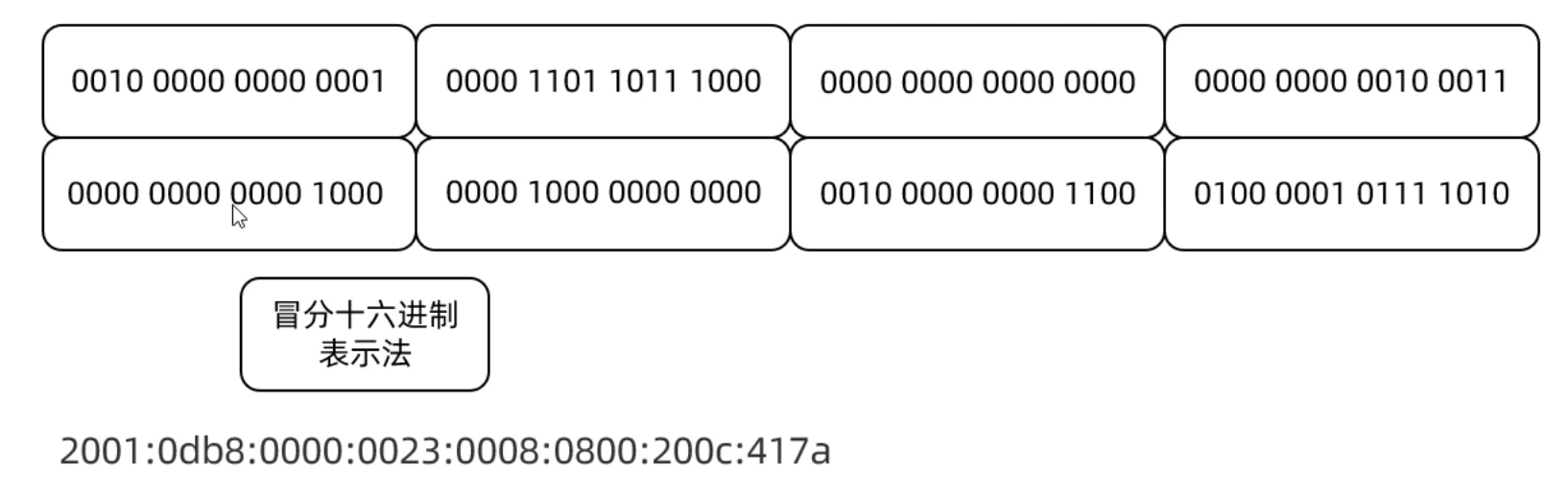
我们在命令行窗口输入ipconfig命令,同样可以看到ipv6地址,如下图所示
现在的网络设备,一般IPV4和IPV6地址都是支持的。
聊完什么是IP地址和IP地址分类之后,接下来再给大家介绍一下和IP地址相关的一个东西,叫做域名。
我们在浏览器上访问某一个网站是,就需要在浏览器的地址栏输入网址,这个网址的专业说法叫做域名。比如:传智播客的域名是http://www.itcast.cn。
域名和IP其实是一一对应的,由运营商来管理域名和IP的对应关系。我们在浏览器上敲一个域名时,首先由运营商的域名解析服务,把域名转换为ip地址,再通过IP地址去访问对应的服务器设备。

关于IP地址,还有一个特殊的地址需要我们记住一下。就是我们在学习阶段进行测试时,经常会自己给自己消息,需要用到一个本地回送地址:127.0.0.1
最后给同学们介绍,两个和IP地址相关的命令
ipconfig: 查看本机的ip地址
ping 域名/ip 检测当前电脑与指定的ip是否连通
ping命令出现以下的提示,说明网络是通过的
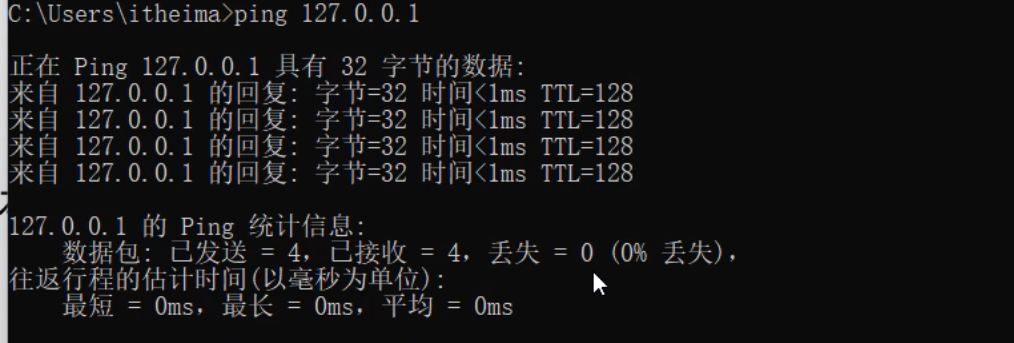
2.2 InetAddress类
各位小伙伴,在上一节课我们学习了网络编程的三要素之一,IP地址。按照面向对象的设计思想,Java中也有一个类用来表IP地址,这个类是InetAddress类。我们在开发网络通信程序的时候,可能有时候会获取本机的IP地址,以及测试与其他地址是否连通,这个时候就可以使用InetAddress类来完成。下面学习几个InetAddress的方法。

演示上面几个方法的效果
public class InetAddressTest {public static void main(String[] args) throws Exception {// 1、获取本机IP地址对象的InetAddress ip1 = InetAddress.getLocalHost();System.out.println(ip1.getHostName());System.out.println(ip1.getHostAddress());// 2、获取指定IP或者域名的IP地址对象。InetAddress ip2 = InetAddress.getByName("www.baidu.com");System.out.println(ip2.getHostName());System.out.println(ip2.getHostAddress());// ping www.baidu.comSystem.out.println(ip2.isReachable(6000));}
}
2.3 端口号
端口号:指的是计算机设备上运行的应用程序的标识,被规定为一个16位的二进制数据,范围(0~65535)
端口号分为一下几类(了解一下)
- 周知端口:0~1023,被预先定义的知名应用程序占用(如:HTTP占用80,FTP占用21)
- 注册端口:1024~49151,分配给用户经常或者某些应用程序
- 动态端口:49152~65536,之所以称为动态端口,是因为它一般不固定分配给某进程,而是动态分配的。
需要我们注意的是,同一个计算机设备中,不能出现两个应用程序,用同一个端口号

2.4 协议
各位同学,前面我们已经学习了IP地址和端口号,但是想要完成数据通信还需要有通信协议。
网络上通信的设备,事先规定的连接规则,以及传输数据的规则被称为网络通信协议。

为了让世界上各种上网设备能够互联互通,肯定需要有一个组织出来,指定一个规则,大家都遵守这个规则,才能进行数据通信。
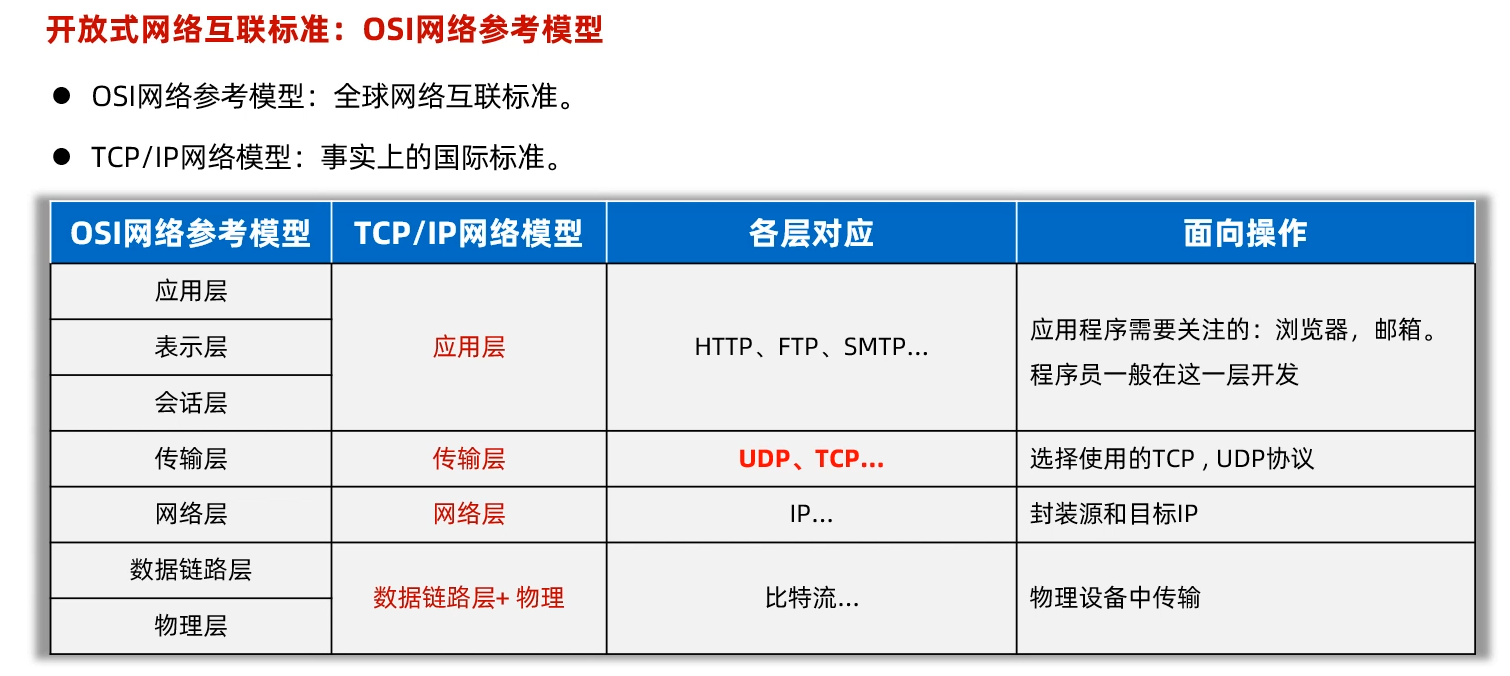
只要按照OSI网络参考模型制造的设备,就可以在国际互联网上互联互通。其中传输层有两个协议,是我们今天会接触到的(UDP协议、TCP协议)
- UDP协议特点

- TPC协议特点

三次握手如下图所示:目的是确认通信双方,手法消息都是正常没问题的

四次挥手如下图所示:目的是确保双方数据的收发已经完成,没有数据丢失

三、UDP通信代码(入门案例)
有了网络编程的三要素基础知识之后,我们就可以开始学习编写网络通信的程序了。首先学习基于UDP协议通信的代码编写。
UDP是面向无连接的、不需要确认双方是否存在,所以它是不可靠的协议。Java提供了一个类叫DatagramSocket来完成基于UDP协议的收发数据。使用DatagramSocket收发数据时,数据要以数据包的形式体现,一个数据包限制在64KB以内
具体流程如下图所示:假设我们把DatagramSocket看做是街道两天的人,现在左边的人要扔一盘韭菜到右边,这里的韭菜就是数据,但是数据需要用一个盘子装起来,这里的盘子就是DatagramPacket数据包的意思。通信双方都需要有DatagramSocket(扔、接韭菜人),还需要有DatagramPacket(装韭菜的盘子)
下面我们看一个案例,需要有两个程序,一个表示客户端程序,一个表示服务端程序。
需求:客户端程序发一个字符串数据给服务端,服务端程序接收数据并打印。
3.1 客户端程序
/*** 目标:完成UDP通信快速入门:实现1发1收。*/
public class Client {public static void main(String[] args) throws Exception {// 1、创建客户端对象(发韭菜出去的人)DatagramSocket socket = new DatagramSocket(7777);// 2、创建数据包对象封装要发出去的数据(创建一个韭菜盘子)/* public DatagramPacket(byte buf[], int length,InetAddress address, int port)参数一:封装要发出去的数据。参数二:发送出去的数据大小(字节个数)参数三:服务端的IP地址(找到服务端主机)参数四:服务端程序的端口。*/byte[] bytes = "我是快乐的客户端,我爱你abc".getBytes();DatagramPacket packet = new DatagramPacket(bytes, bytes.length, InetAddress.getLocalHost(), 6666);// 3、开始正式发送这个数据包的数据出去了socket.send(packet);System.out.println("客户端数据发送完毕~~~");socket.close(); // 释放资源!}
}
3.2 服务端程序
public class Server {public static void main(String[] args) throws Exception {System.out.println("----服务端启动----");// 1、创建一个服务端对象(创建一个接韭菜的人) 注册端口DatagramSocket socket = new DatagramSocket(6666);// 2、创建一个数据包对象,用于接收数据的(创建一个韭菜盘子)byte[] buffer = new byte[1024 * 64]; // 64KB.DatagramPacket packet = new DatagramPacket(buffer, buffer.length);// 3、开始正式使用数据包来接收客户端发来的数据socket.receive(packet);// 4、从字节数组中,把接收到的数据直接打印出来// 接收多少就倒出多少// 获取本次数据包接收了多少数据。int len = packet.getLength();String rs = new String(buffer, 0 , len);System.out.println(rs);System.out.println(packet.getAddress().getHostAddress());System.out.println(packet.getPort());socket.close(); // 释放资源}
}
四、UDP通信代码(多发多收)
刚才的案例,我们只能客户端发一次,服务端接收一次就结束了。下面我们想把这个代码改进一下,
需求:实现客户端不断的发数据,而服务端能不断的接收数据,客户端发送exit时客户端程序退出。
4.1 客户端程序
/*** 目标:完成UDP通信快速入门:实现客户端反复的发。*/
public class Client {public static void main(String[] args) throws Exception {// 1、创建客户端对象(发韭菜出去的人)DatagramSocket socket = new DatagramSocket();// 2、创建数据包对象封装要发出去的数据(创建一个韭菜盘子)/* public DatagramPacket(byte buf[], int length,InetAddress address, int port)参数一:封装要发出去的数据。参数二:发送出去的数据大小(字节个数)参数三:服务端的IP地址(找到服务端主机)参数四:服务端程序的端口。*/Scanner sc = new Scanner(System.in);while (true) {System.out.println("请说:");String msg = sc.nextLine();// 一旦发现用户输入的exit命令,就退出客户端if("exit".equals(msg)){System.out.println("欢迎下次光临!退出成功!");socket.close(); // 释放资源break; // 跳出死循环}byte[] bytes = msg.getBytes();DatagramPacket packet = new DatagramPacket(bytes, bytes.length, InetAddress.getLocalHost(), 6666);// 3、开始正式发送这个数据包的数据出去了socket.send(packet);}}
}
4.2 服务端程序
/*** 目标:完成UDP通信快速入门-服务端反复的收*/
public class Server {public static void main(String[] args) throws Exception {System.out.println("----服务端启动----");// 1、创建一个服务端对象(创建一个接韭菜的人) 注册端口DatagramSocket socket = new DatagramSocket(6666);// 2、创建一个数据包对象,用于接收数据的(创建一个韭菜盘子)byte[] buffer = new byte[1024 * 64]; // 64KB.DatagramPacket packet = new DatagramPacket(buffer, buffer.length);while (true) {// 3、开始正式使用数据包来接收客户端发来的数据socket.receive(packet);// 4、从字节数组中,把接收到的数据直接打印出来// 接收多少就倒出多少// 获取本次数据包接收了多少数据。int len = packet.getLength();String rs = new String(buffer, 0 , len);System.out.println(rs);System.out.println(packet.getAddress().getHostAddress());System.out.println(packet.getPort());System.out.println("--------------------------------------");}}
}
五、TCP通信(一发一收)
学习完UDP通信的代码编写之后,接下来我们学习TCP通信的代码如何编写。Java提供了一个java.net.Socket类来完成TCP通信。
我们先讲一下Socket完成TCP通信的流程,再讲代码怎么编写就很好理解了。如下图所示
- 当创建Socket对象时,就会在客户端和服务端创建一个数据通信的管道,在客户端和服务端两边都会有一个Socket对象来访问这个通信管道。
- 现在假设客户端要发送一个“在一起”给服务端,客户端这边先需要通过Socket对象获取到一个字节输出流,通过字节输出流写数据到服务端
- 然后服务端这边通过Socket对象可以获取字节输入流,通过字节输入流就可以读取客户端写过来的数据,并对数据进行处理。
- 服务端处理完数据之后,假设需要把“没感觉”发给客户端端,那么服务端这边再通过Socket获取到一个字节输出流,将数据写给客户端
- 客户端这边再获取输入流,通过字节输入流来读取服务端写过来的数据。

5.1 TCP客户端
下面我们写一个客户端,用来往服务端发数据。由于原始的字节流不是很好用,这里根据我的经验,我原始的OutputStream包装为DataOutputStream是比较好用的。
/*** 目标:完成TCP通信快速入门-客户端开发:实现1发1收。*/
public class Client {public static void main(String[] args) throws Exception {// 1、创建Socket对象,并同时请求与服务端程序的连接。Socket socket = new Socket("127.0.0.1", 8888);// 2、从socket通信管道中得到一个字节输出流,用来发数据给服务端程序。OutputStream os = socket.getOutputStream();// 3、把低级的字节输出流包装成数据输出流DataOutputStream dos = new DataOutputStream(os);// 4、开始写数据出去了dos.writeUTF("在一起,好吗?");dos.close();socket.close(); // 释放连接资源}
}
5.2 TCP服务端
上面我们只是写了TCP客户端,还没有服务端,接下来我们把服务端写一下。这里的服务端用来接收客户端发过来的数据。
/*** 目标:完成TCP通信快速入门-服务端开发:实现1发1收。*/
public class Server {public static void main(String[] args) throws Exception {System.out.println("-----服务端启动成功-------");// 1、创建ServerSocket的对象,同时为服务端注册端口。ServerSocket serverSocket = new ServerSocket(8888);// 2、使用serverSocket对象,调用一个accept方法,等待客户端的连接请求Socket socket = serverSocket.accept();// 3、从socket通信管道中得到一个字节输入流。InputStream is = socket.getInputStream();// 4、把原始的字节输入流包装成数据输入流DataInputStream dis = new DataInputStream(is);// 5、使用数据输入流读取客户端发送过来的消息String rs = dis.readUTF();System.out.println(rs);// 其实我们也可以获取客户端的IP地址System.out.println(socket.getRemoteSocketAddress());dis.close();socket.close();}
}
六、TCP通信(多发多收)
到目前为止,我们已经完成了客户端发送消息、服务端接收消息,但是客户端只能发一次,服务端只能接收一次。现在我想要客户端能过一直发消息,服务端能够一直接收消息。
下面我们把客户端代码改写一下,采用键盘录入的方式发消息,为了让客户端能够一直发,我们只需要将发送消息的代码套一层循环就可以了,当用户输入exit时,客户端退出循环并结束客户端。
6.1 TCP客户端
/*** 目标:完成TCP通信快速入门-客户端开发:实现客户端可以反复的发消息出去*/
public class Client {public static void main(String[] args) throws Exception {// 1、创建Socket对象,并同时请求与服务端程序的连接。Socket socket = new Socket("127.0.0.1", 8888);// 2、从socket通信管道中得到一个字节输出流,用来发数据给服务端程序。OutputStream os = socket.getOutputStream();// 3、把低级的字节输出流包装成数据输出流DataOutputStream dos = new DataOutputStream(os);Scanner sc = new Scanner(System.in);while (true) {System.out.println("请说:");String msg = sc.nextLine();// 一旦用户输入了exit,就退出客户端程序if("exit".equals(msg)){System.out.println("欢迎您下次光临!退出成功!");dos.close();socket.close();break;}// 4、开始写数据出去了dos.writeUTF(msg);dos.flush();}}
}
6.2 TCP服务端
为了让服务端能够一直接收客户端发过来的消息,服务端代码也得改写一下。我们只需要将读取数据的代码加一个循环就可以了。
但是需要我们注意的时,如果客户端Socket退出之后,就表示连接客户端与服务端的数据通道被关闭了,这时服务端就会出现异常。服务端可以通过出异常来判断客户端下线了,所以可以用try...catch把读取客户端数据的代码套一起来,catch捕获到异常后,打印客户端下线。
/*** 目标:完成TCP通信快速入门-服务端开发:实现服务端反复发消息*/
public class Server {public static void main(String[] args) throws Exception {System.out.println("-----服务端启动成功-------");// 1、创建ServerSocket的对象,同时为服务端注册端口。ServerSocket serverSocket = new ServerSocket(8888);// 2、使用serverSocket对象,调用一个accept方法,等待客户端的连接请求Socket socket = serverSocket.accept();// 3、从socket通信管道中得到一个字节输入流。InputStream is = socket.getInputStream();// 4、把原始的字节输入流包装成数据输入流DataInputStream dis = new DataInputStream(is);while (true) {try {// 5、使用数据输入流读取客户端发送过来的消息String rs = dis.readUTF();System.out.println(rs);} catch (Exception e) {System.out.println(socket.getRemoteSocketAddress() + "离线了!");dis.close();socket.close();break;}}}
}
七、TCP通信(多线程改进)
上一个案例中我们写的服务端程序只能和一个客户端通信,如果有多个客户端连接服务端,此时服务端是不支持的。
为了让服务端能够支持多个客户端通信,就需要用到多线程技术。具体的实现思路如下图所示:每当有一个客户端连接服务端,在服务端这边就为Socket开启一条线程取执行读取数据的操作,来多少个客户端,就有多少条线程。按照这样的设计,服务端就可以支持多个客户端连接了。
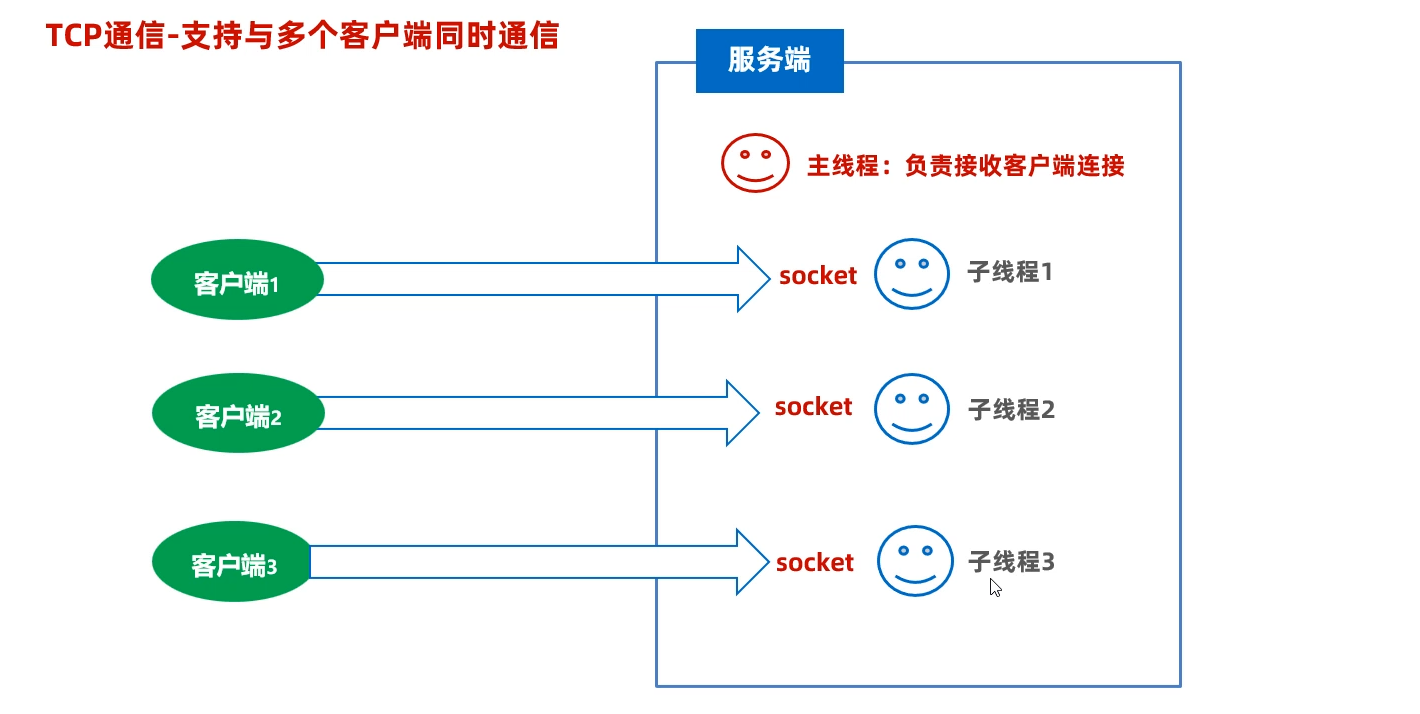
按照上面的思路,改写服务端代码。
7.1 多线程改进
首先,我们需要写一个服务端的读取数据的线程类,代码如下
public class ServerReaderThread extends Thread{private Socket socket;public ServerReaderThread(Socket socket){this.socket = socket;}@Overridepublic void run() {try {InputStream is = socket.getInputStream();DataInputStream dis = new DataInputStream(is);while (true){try {String msg = dis.readUTF();System.out.println(msg);} catch (Exception e) {System.out.println("有人下线了:" + socket.getRemoteSocketAddress());dis.close();socket.close();break;}}} catch (Exception e) {e.printStackTrace();}}
}
接下来,再改写服务端的主程序代码,如下:
/*** 目标:完成TCP通信快速入门-服务端开发:要求实现与多个客户端同时通信。*/
public class Server {public static void main(String[] args) throws Exception {System.out.println("-----服务端启动成功-------");// 1、创建ServerSocket的对象,同时为服务端注册端口。ServerSocket serverSocket = new ServerSocket(8888);while (true) {// 2、使用serverSocket对象,调用一个accept方法,等待客户端的连接请求Socket socket = serverSocket.accept();System.out.println("有人上线了:" + socket.getRemoteSocketAddress());// 3、把这个客户端对应的socket通信管道,交给一个独立的线程负责处理。new ServerReaderThread(socket).start();}}
}
7.2 案例拓展(群聊)
接着前面的案例,下面我们案例再次拓展一下,这个并不需要同学们必须掌握,主要是为了锻炼同学们的编程能力、和编程思维。
我们想把刚才的案例,改进成全能够实现群聊的效果,就是一个客户端发的消息,其他的每一个客户端都可以收到。
刚才我们写的多个客户端可以往服务端发现消息,但是客户端和客户端是不能直接通信的。想要试下全群聊的效果,我们还是必须要有服务端在中间做中转。 具体实现方案如下图所示:
我们可以在服务端创建一个存储Socket的集合,每当一个客户端连接服务端,就可以把客户端Socket存储起来;当一个客户端给服务端发消息时,再遍历集合通过每个Socket将消息再转发给其他客户端。
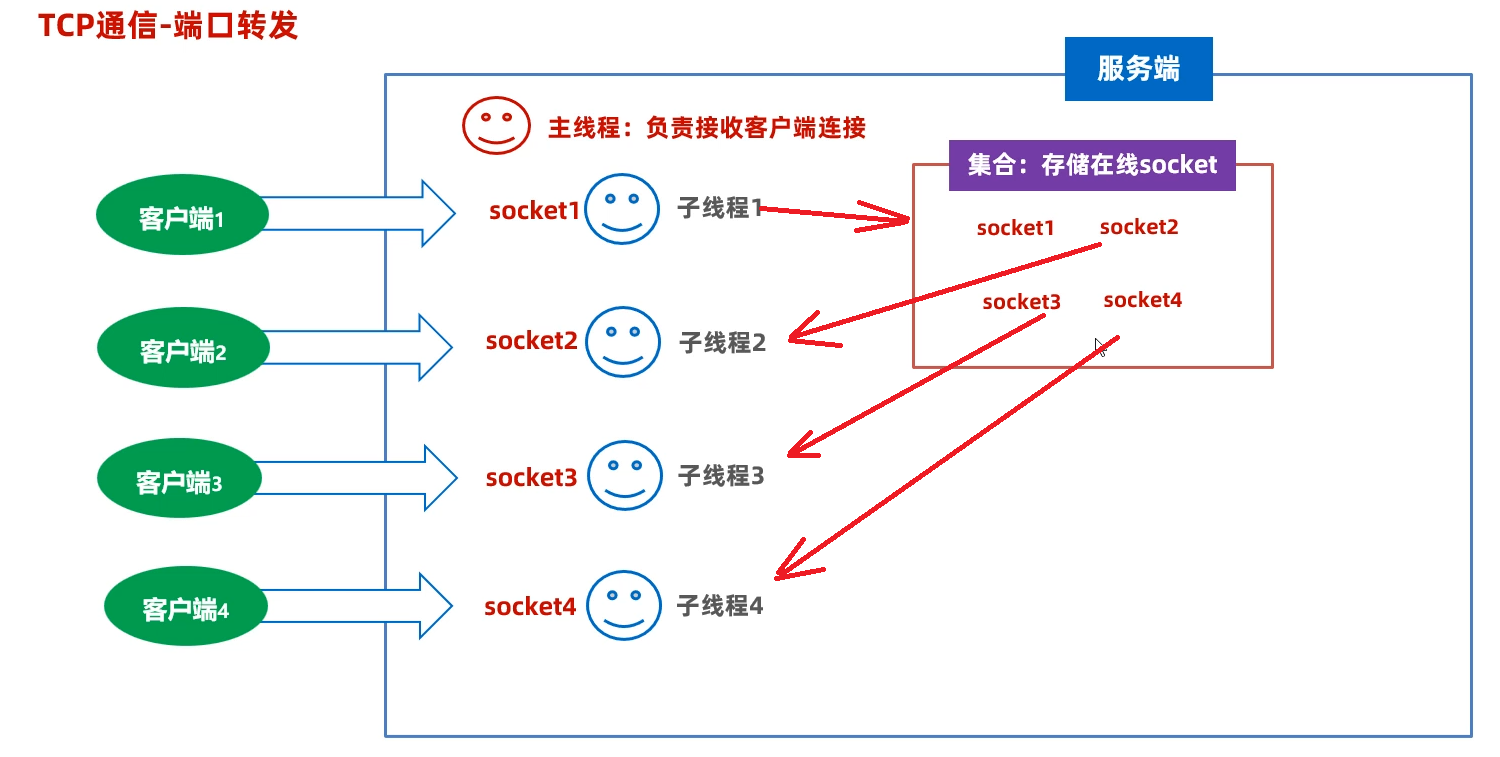
下面我们改造服务端代码,由于服务端读取数据是在线程类中完成的,所以我们改SerReaderThread类就可以了。服务端的主程序不用改。
public class ServerReaderThread extends Thread{private Socket socket;public ServerReaderThread(Socket socket){this.socket = socket;}@Overridepublic void run() {try {InputStream is = socket.getInputStream();DataInputStream dis = new DataInputStream(is);while (true){try {String msg = dis.readUTF();System.out.println(msg);// 把这个消息分发给全部客户端进行接收。sendMsgToAll(msg);} catch (Exception e) {System.out.println("有人下线了:" + socket.getRemoteSocketAddress());Server.onLineSockets.remove(socket);dis.close();socket.close();break;}}} catch (Exception e) {e.printStackTrace();}}private void sendMsgToAll(String msg) throws IOException {// 发送给全部在线的socket管道接收。for (Socket onLineSocket : Server.onLineSockets) {OutputStream os = onLineSocket.getOutputStream();DataOutputStream dos = new DataOutputStream(os);dos.writeUTF(msg);dos.flush();}}
}
八、BS架构程序(简易版)
前面我们所写的代码都是基于CS架构的。我们说网络编程还可以编写BS架构的程序,为了让同学们体验一下BS架构通信,这里我们写一个简易版的程序。仅仅只是体验下一,后期我们会详细学习BS架构的程序如何编写。
BS架构程序的实现原理,如下图所示:不需要开发客户端程序,此时浏览器就相当于是客户端,此时我们只需要写服务端程序就可以了。
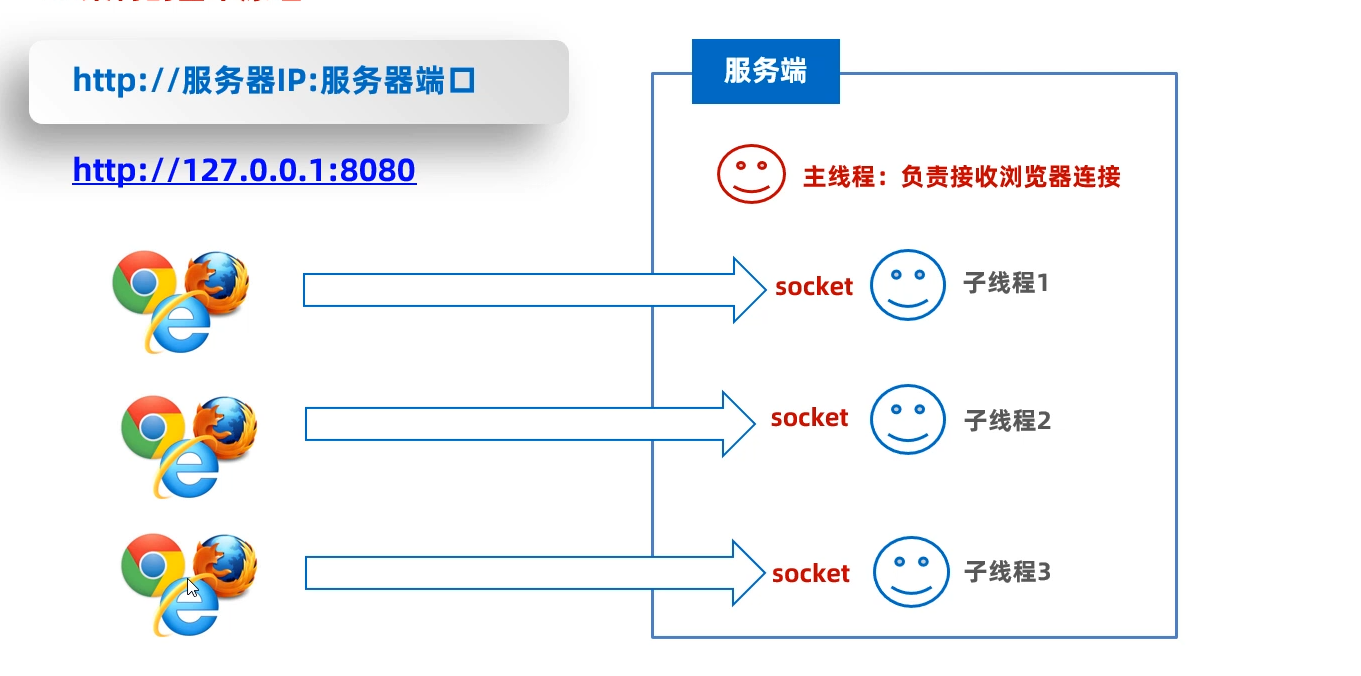
在BS结构的程序中,浏览器和服务器通信是基于HTTP协议来完成的,浏览器给客户端发送数据需要按照HTTP协议规定好的数据格式发给服务端,服务端返回数据时也需要按照HTTP协议规定好的数据给是发给浏览器,只有这两双方才能完成一次数据交互。
客户端程序不需要我们编写(浏览器就是),所以我们只需要写服务端就可以了。
服务端给客户端响应数据的数据格式(HTTP协议规定数据格式)如下图所示:左图是数据格式,右图是示例。

接下来,我们写一个服务端程序按照右图示例的样子,给浏览器返回数据。注意:数据是由多行组成的,必须按照规定的格式来写。
8.1 服务端程序
先写一个线程类,用于按照HTTP协议的格式返回数据
public class ServerReaderThread extends Thread{private Socket socket;public ServerReaderThread(Socket socket){this.socket = socket;}@Overridepublic void run() {// 立即响应一个网页内容:“黑马程序员”给浏览器展示。try {OutputStream os = socket.getOutputStream();PrintStream ps = new PrintStream(os);ps.println("HTTP/1.1 200 OK");ps.println("Content-Type:text/html;charset=UTF-8");ps.println(); // 必须换行ps.println("<div style='color:red;font-size:120px;text-align:center'>黑马程序员666<div>");ps.close();socket.close();} catch (Exception e) {e.printStackTrace();}}
}
再写服务端的主程序
/*** 目标:完成TCP通信快速入门-服务端开发:要求实现与多个客户端同时通信。*/
public class Server {public static void main(String[] args) throws Exception {System.out.println("-----服务端启动成功-------");// 1、创建ServerSocket的对象,同时为服务端注册端口。ServerSocket serverSocket = new ServerSocket(8080);while (true) {// 2、使用serverSocket对象,调用一个accept方法,等待客户端的连接请求Socket socket = serverSocket.accept();System.out.println("有人上线了:" + socket.getRemoteSocketAddress());// 3、把这个客户端对应的socket通信管道,交给一个独立的线程负责处理。new ServerReaderThread(socket).start();}}
}
8.2 服务端主程序用线程池改进
为了避免服务端创建太多的线程,可以把服务端用线程池改进,提高服务端的性能。
先写一个给浏览器响应数据的线程任务
public class ServerReaderRunnable implements Runnable{private Socket socket;public ServerReaderRunnable(Socket socket){this.socket = socket;}@Overridepublic void run() {// 立即响应一个网页内容:“黑马程序员”给浏览器展示。try {OutputStream os = socket.getOutputStream();PrintStream ps = new PrintStream(os);ps.println("HTTP/1.1 200 OK");ps.println("Content-Type:text/html;charset=UTF-8");ps.println(); // 必须换行ps.println("<div style='color:red;font-size:120px;text-align:center'>黑马程序员666<div>");ps.close();socket.close();} catch (Exception e) {e.printStackTrace();}}
}
再改写服务端的主程序,使用ThreadPoolExecutor创建一个线程池,每次接收到一个Socket就往线程池中提交任务就行。
public class Server {public static void main(String[] args) throws Exception {System.out.println("-----服务端启动成功-------");// 1、创建ServerSocket的对象,同时为服务端注册端口。ServerSocket serverSocket = new ServerSocket(8080);// 创建出一个线程池,负责处理通信管道的任务。ThreadPoolExecutor pool = new ThreadPoolExecutor(16 * 2, 16 * 2, 0, TimeUnit.SECONDS,new ArrayBlockingQueue<>(8) , Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());while (true) {// 2、使用serverSocket对象,调用一个accept方法,等待客户端的连接请求Socket socket = serverSocket.accept();// 3、把这个客户端对应的socket通信管道,交给一个独立的线程负责处理。pool.execute(new ServerReaderRunnable(socket));}}
}
语法糖
复杂的操作隐藏起来,使用看得见的简单操作
- 构造器(代码未提供的情况下,编译器自动提供)
- 增强for循环(数组:fori 集合:迭代器)
- try-with-resources(自动关闭流)