事务
为了确保连续多个操作的原子性,一个成熟的数据库通常都会有事务支持,Redis也不例外。 Redis的事务使用方法非常简单 不同于关系数据库我们无须理解那么多复杂的事务模型就可以直接使用。不过也正是因为这种简单性它的事务模型很不严格这要求我们不能像使用关系数据库的事务一样来使用 Redis 事务。
Redis 事务的基本用法
每个事务的操作指令都有 begin commit rollback, begin 指示事务的开始,commit 指示事务的提交, rollback 指示事务的回滚。它们大致的形式如下。
begin();
try {comrnand1();comrnand2();commit();
)catch(Exception e){rollback();
}
redis 事务在形式上看起来也差不多,指令分别是 multi exec discard, multi 指示事务的开始, exec 指示事务的执行, di card 指示事务的丢弃
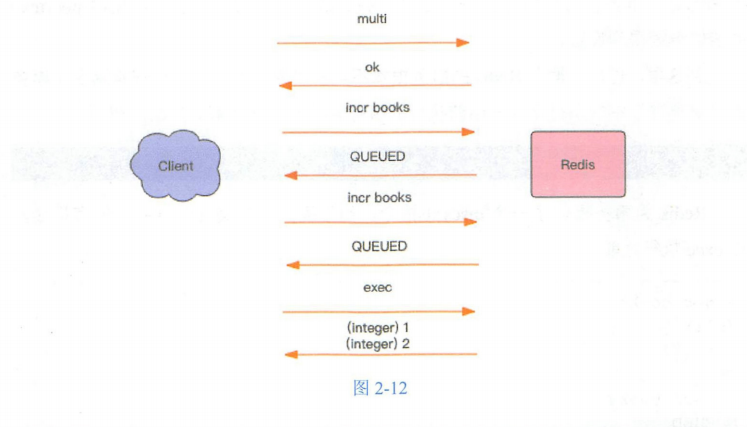
> multi
OK
> incr books
QUEUED
> incr books
QUEUED
> exec
(integer) 1
(integer) 2
上面的指令演示了一个完整的事务过程,所有的指令在 exec 之前不执行,而是缓存在服务器的一个事务队列中,服务器一旦收到exec 指令,才开始执行整个事务队列,执行完毕后一次性返回所有指令的运行结果。因为== Redis 的单线程特性,它不用担心自己在执行队列的时候被其他指令打搅,可以保证他们能得到的原子性==执行。
显示了以上事务过程完整的交互效果 QUEUED是 一个简单字符串,同OK 是一个形式,它表示指令已经被服务器缓存到队列里了。
事务的原子性是指事务要么全部成功 要么全部失败,那么 Redis 事务执行是原子性的吗?
下面我们来看一个特别的例子
> multi
OK
> set books iamastring
QUEUED
> incr books
QUEUED
> set poorman iamdesperate
QUEUED
> exec
1) OK
2) (error) ERR value is not an integer or out of range
3) OK
> get books
"iamastring"
> get poorman
"iamdesperate"
上面的例子是事务执行到中间时遇到失败了,因为我们不能对一个字符串进行数学运算。事务在遇到指令执行失败后,后面的指令还会继续执行,所以 poorman的值能继续得到设置。
到这里,你应该明白 Redis 的事务根本不具备原子性,而仅仅是满足了事务的隔离性中的串行化,当前执行的事务有着不被其他事务打断的权利。
discard(丢弃)
redis 为事务提供了一个 discard 指令,用于丢弃事务缓存队列中的所有指令,在 exec 执行之前。
> get books
(nil)
> multi
OK
> incr books
QUEUED
> incr books
QUEUED
> discard
OK
> get books
(nil)
可以看到,在 discard 之后,队列中的所有指令都没执行,就好像 multi 和 discard 中间的所有指令从未发生过一样。
优化
上面的 redis 事务在发送每个指令到事务缓存队列时都要经过一次网络读写,当一个事务内部的指令较多时,需要的网络 IO 时间也会线性增长 所以通常 redis 的客户端在执行事务时都会结合 pipeline 一起使用,这样可以将多次 IO 操作压缩为单次 IO 操作。比如我们在使用 Python Redis 客户端执行事务时是要强制使用pipeline
pipe = redis.pipeline(transaction=true)
pipe.multi()
pipe.incr("books")
pipe.incr("books")
values=pipe.execute()
Redis 中实现原子操作的 3 种方式
单个命令是原子的
如 HSET key1 field1 value1 field2 value2, 能保证 field1 和 field2 一起设置上
通过事务命令
MULTI
HSET key1 field1 value2 field2 value2
EXPIRE key1 60
EXEC
Redis 服务器缓存 MULTI 后的命令,直到 EXEC 再一起执行。
通过 lua 脚本
local ret = redis.call('hset', KEYS[1], 'field1', ARGV[1], 'field2', ARGV[2]);
redis.call('expire', KEYS[1], ARGV[3]);
return ret;
EVAL <脚本> 1 key1 value1 value2 60
EVAL 是单独的一条命令,自然整个脚本的执行都是原子的。
Transaction 与 Lua 脚本对比
首先,可以看出,简单的操作,transaction 是要比 lua 简洁的。但 lua 能实现更加复杂的逻辑,例如:
local x = redis.call('get', KEYS[1]);
return redis.call('set', KEYS[2], x + 1);
这个操作用 MULTI-EXEC 是实现不了的,因为操作是原子的,在 EXEC 执行之前,前面的命令都无法执行,无法返回结果,自然也就无法计算 x + 1 等于什么。
如果一定要用 transaction, 这个操作可以用 WATCH-MULTI-EXEC 来做,但 optimsitic locking 可能会失败,需要反复重试,这里就是 lua 更简单高效了。
所以,我们可以在简单的命令里用 MULTI-EXEC, 复杂的逻辑用 lua 脚本。当然,用 MULTI-EXEC 时要配合 pipeline 使用,否则每发送一条命令都等待响应的 RTT 会严重影响性能。
关于 Pipeline
只使用 pipeline 不能保证原子性!!!
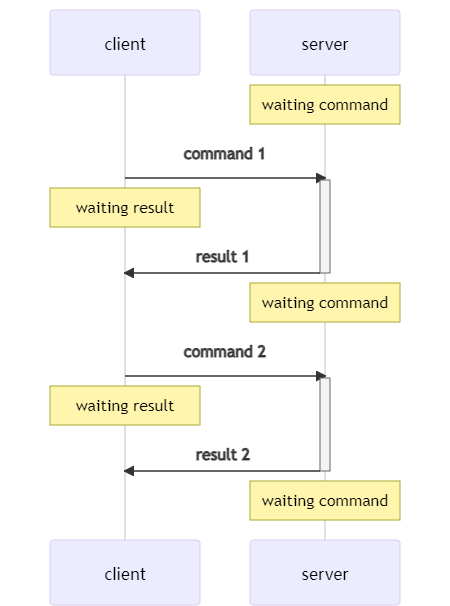
在协议上,pipeline 纯粹就是一个针对 RTT 的优化,可以批量发送命令:
没有 pipeline 时,每个命令都要等待响应
有 pipeline 时,可以发送多个命令后一起等待
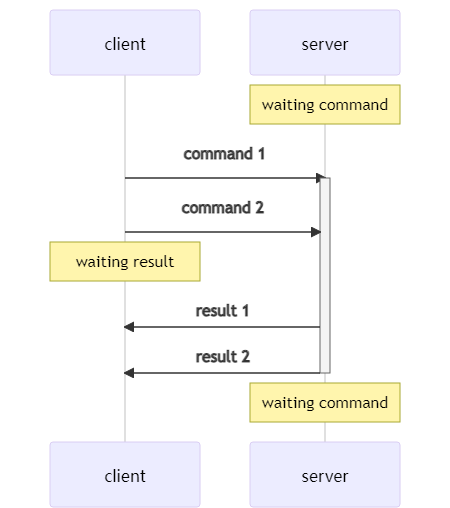
这种方式并不能保证 command 1 和 command 2 是原子的,当有多个 client 同时和 server 通信时,完全可以变成:

这里,对于 client A 来说,它确实使用了 pipeline 操作,连续发送两个命令,然后一起等待响应;但 server 却把两个命令分开处理了。
这种情况在开发的时候可能不容易观察到。如果一个 pipeline 中的数据比较少(比如小于一个 TCP 包的大小),在客户端 redis 库、客户端内核的缓冲下,可能就是这个 pipeline 的命令都在一个 TCP 包中发了出去;server 也一次性地从内核缓冲区把整个 pipeline 请求读出来处理了。这种情况下,看起来就是原子的。
但如果一个 pipeline 的数据比较多,大小超过了 TCP 包的大小,那发送出去的多个包 server 就不一定能一次性收到了。可以说在负载比较高的时候,必定会出问题的。
Redis Cluster
在生产环境中一般会使用 redis cluster。 Redis cluster 没有分布式事务,这会对我们能使用的原子操作产生限制。
简单地看一下 redis cluster 是如何实现的:
redis 对 key 做 hash, 把 key 分配到 16384 个 hash slot 中,然后再把 hash slot 和集群节点绑定到一起
hash slot 和节点的绑定关系可以通过通过命令改变,这可以用来从集群中增删节点,平衡数据。改变绑定关系会导致数据迁移。数据迁移不是原子的。
那么 redis cluster 的原子操作要根据 key 的异同分 3 种情况来看:
- 操作中所有的 keys 都相同
- 操作中所有的 keys 都属于同一个 hash slot
- 操作中的 keys 属于多个 hash slot
其中 3 是不用看了,无法支持原子操作。而属于同一个 hash slot 时,要分两种情况:
集群处于稳定状态:这时同一个 hash slot 的 keys 都在同一个节点上,可以实现原子操作
这个 hash slot 正在执行数据迁移:这时操作中的 keys 可能不在同一个节点上,操作可能产生部分失败的结果
迁移过程中,一个 slot 的一部分 keys 在源节点上,另一个部分 keys 在目的节点上。Client 根据 slot 映射,向源节点发送请求;这时如果操作的 key 在目的节点上,server 就会返回 ASK 重定向,操作失败。
这时如果操作的是都是同一个 key, 那么它要么在源节点上,要么在目的节点上,所有操作要么全部成功,要么全部返回重定向。全部返回重定向时,整个事务都没有产生任何效果,这时 atomicity 和 consistency 是可以保证的。
但如果操作的不是同一个 key, 那就要可能部分 keys 操作成功,另一部分返回了重定向。只有一部分命令成功,这时 consistency 就破坏了。
所以,如果要保证 atomicity 和 consistency, redis cluster 的一个事务只能操作一个 key.
总结
单个命令是原子的
MULTI-EXEC 事务命令,和 lua 脚本都是原子的
MULTI-EXEC 要配合 pipeline 使用,否则性能会比 lua 脚本差
WATCH-MULTI-EXEC 不如 lua 脚本
Redis cluster 上,不管用 MULTI-EXEC 还是 lua 脚本,只有操作单个 key 的事务才能保证 consistency. 如果操作了多个 key, 可能会因为数据迁移,产生部分失败的结果
后记: redis 文档里说,lua script 一般比 multi-exec 更快、更简单
A Redis script is transactional by definition, so everything you can do with a Redis transaction, you can also do with a script, and usually the script will be both simpler and faster.
Redis执行lua脚本并不能保证原子性,使用lua脚本只能保证Redis的多个命令原子执行,在这组命令的执行期间,不会有其他客户端的命令干扰,或者可以说,Redis对于原子性的定义与我们所知道的关系型数据库中ACID的原子性定义不同,Redis的原子性是指在执行一组命令期间,只要这组命令没有执行完,就不会去执行客户端发送的其他命令。
为什么推荐用lua脚本而不是redis事务?
那这个lua脚本不是和redis的事务一样吗,都不支持回滚,那为啥还要用lua脚本?
我们来分析一下Redis事务和Redis执行lua脚本的区别就可以知道为什么推荐用lua脚本去执行多个命令了
Redis事务中, 在客户端向Redis请求执行MULTI命令后,后续客户端每一个命令请求都会被redis的服务端记录到一个事务队列里,直到客户端执行EXEC命令时,Redis才会按照先进先出的方式去执行事务队列里的命令,也就是说,在Redis事务中,客户端每一个命令都会与Redis服务端进行交互,需要多次的网络IO操作
相比之下,Redis执行lua脚本,只需要客户端发送一次请求,由Redis服务端去执行自己的脚本文件,这样执行一次网络IO就可以完成操作,显然,lua脚本这种方式比Redis事务会快很多
同时,lua脚本相比于Redis事务这种命令组合的方式,自己可以定义更复杂的业务逻辑,比如可以设置变量进行运算,执行复杂的判断语句等,这些都是Redis事务办不到的,所以这就是为什么推荐使用lua脚本的原因。
我们再来继续深入探讨一下,lua脚本一定能保证Redis执行命令期间不会受到其他客户端请求的打扰吗?
废话,你上面不是说了可以保证吗
诶,此言差矣!我只在单机架构环境下作出保证,集群架构下我可没保证。
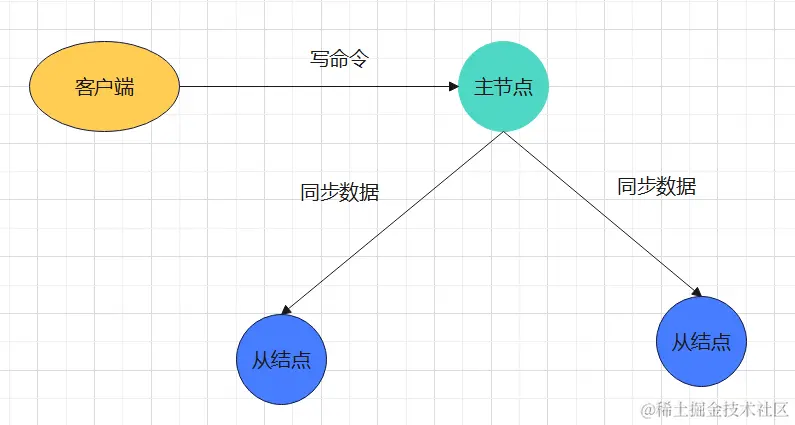
在这种一主多从的架构下,只有一个主节点能执行写命令,所以可以保证lua脚本里面的命令是原子的
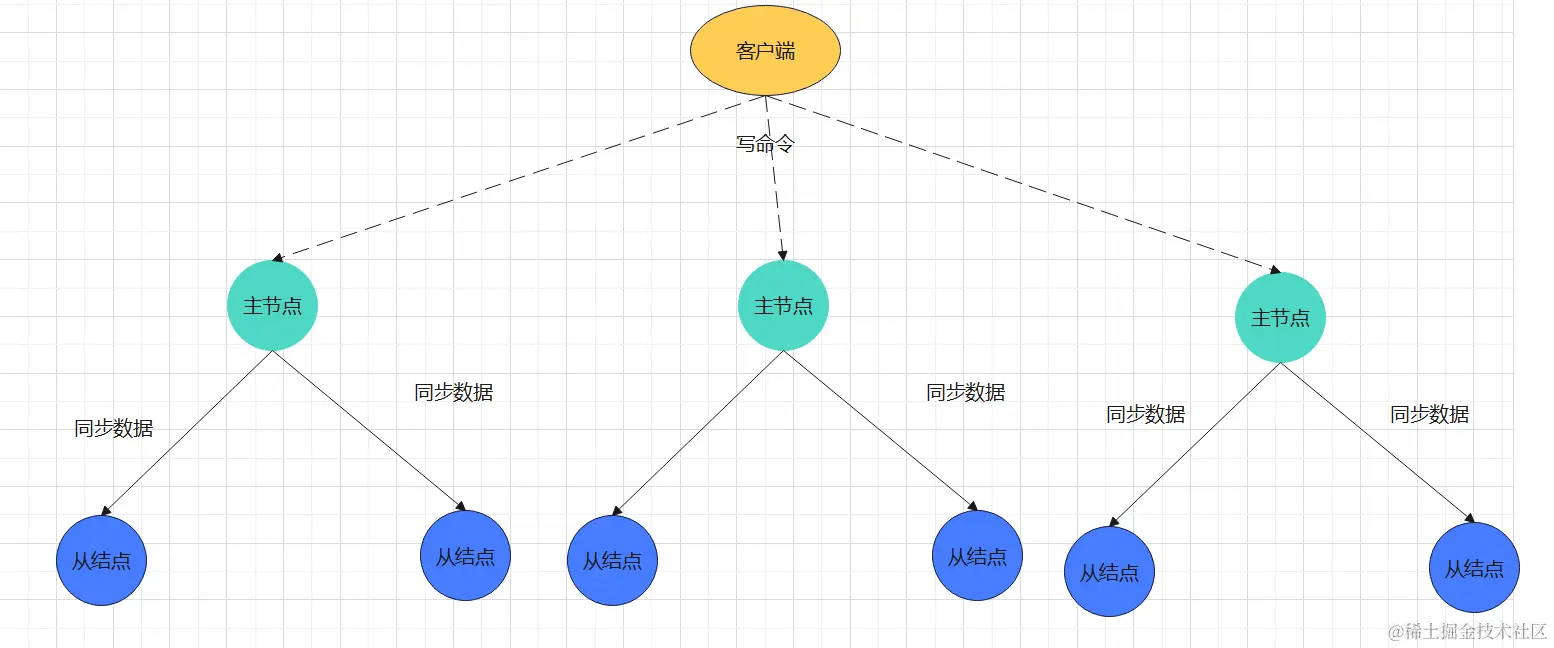
而在这种分片集群的架构下,每个主节点被分配了一部分哈希槽,不同的key映射到不同的哈希槽上,对key的命令可能会执行在不同的主节点上,这样就无法保证lua脚本里的命令是原子的了
总结:redis执行lua脚本里的命令是否是原子操作,要根据不同情况来讨论
redis事务本不具有原子性
关于原子性的定义有两层含义,一方面是指,一组操作要么全部完成,要么全都不进行,不能出现只完成其中一部分操作,例如在银行转账操作中,我们要从原账户转出,也要转入目标账户,这两个操作必须全部完成,要么都不完成,不能出现从原账户转出,但是没有转入目标账户。另一方面始终,这几个操作不能被打断,例如,银行转账操作中,不能在从原账户转出后打断操作,这样其他事务就会看到原账户少了钱,但是目标账户还没有增加钱的中间状态。
利用lua可以实现原子性,这是因为,redis对所有的lua脚本使用同一个虚拟的客户端进行操作,这样就实现了Lua脚本之间的串行性。
在 Redis中执行 Lua的原子性是指:整个 Lua脚本在执行期间,会被当作一个整体,不会被其他客户端的命令打断。
ACID的原子性是指:事务中的命令要么全执行,要么全部不执行;
Redis中执行 Lua脚本原子性是指:Lua脚本会作为一个整体执行且不被其他客户端打断,至于 Lua脚本里面的命令是否必须全部成功,或者全部失败,并不要求。关于这一点,在接下来的内容也会详细解释;
WATCH
WATCH 命令用于监听一个或多个 Key,如果在执行事务期间这些 Key中任何一个Key的 value被其他事务修改,当前整个事务将会被中止。(需要注意:低于 6.0.9 的 Redis 版本,Key过期不会中止事务)
如下示例:事务1 watch key1 key2,事务2在事务1执行期间修改 key2 = 10,当事务1执行 exec命令时,因为 watch监听到 key2被其他事务(事务2)修改了(value=10) , 因此事务1被取消,事务队列中的所有命令被清除,即 set key1 value1 和 incrby key 2两条命令都不执行,key2的 value还是10;
事务中的错误
事务中主要会出现两种类型的错误:
-
事务命令进入事务队列之前出错。例如,命令语法错误(参数错误、命令名称错误等),或者可能存在一些关键情况,比如内存不足。如下示例,命令incr key2 1/0 在进入事务队列之前报错,所以,当前事务被中止,执行 EXEC命令会报错:
-
调用 EXEC 命令后,事务队列中的命令执行失败。例如,对字符串值进行加1操作。如下示例,key的 value是字符串,当对 key 执行incr key 操作时报错,因此,该条命令执行失败:
事务回滚
Redis的事务不支持回滚。 官方说明如下:
Redis 不支持事务回滚,因为支持回滚会对 Redis 的简单性和性能产生重大影响。
官方说明简明扼要,其实,多加思考也能理解:"Redis" 是 "REmote DIctionary Server" 的缩写,翻译为“远程字典服务”,设计的初衷是用于缓存,追求快速高效。而了解过 ACID事务的小伙伴应该能明白事务回滚的复杂度,因此,Redis不支持事务回滚似乎也合情合理。
到此,我们也对 Redis事务做个小结:Redis的事务由 MULTI/EXEC 两个命令完成,WATCH/DISCARD 两个命令的加持,给 Redis事务提供了 CAS 乐观锁机制。Redis 事务不支持回滚,它和关系型数据库(比如 MySQL)的事务(ACID)是不一样的。
Redis 如何执行 Lua?
分析完原子性和 Redis事务这些理论知识后,我们就得动手实操,看看 Redis是如何执行 Lua的。
一般情况下,Redis执行 Lua常用的方法有 2种:
原生命令,比如 EVAL/EVALSHA命令等;
编程工具,比如编程语言中提供的三方工具包或类库;
在编写 Lua脚本时,需要注意区分 redis.call() 和 redis.pcall() 两个命令的使用。
EVAL
EVAL script numkeys [key [key ...]] [arg [arg ...]]
EVAL语法很简单,EVAL script numkeys 是必填项,[key [key ...]] [arg [arg ...]]是选填项。
redis.call()
redis.call() 用于执行 Redis的命令。当命令执行出错时,会阻断整个脚本执行,并将错误信息返回给客户端。
如下示例:当执行INCRBY key2 1/0 失败时,会抛异常,后续流程被阻断,即SET key3 value3没有被执行。
Redis原生命令执行示例如下:
EVAL "redis.call('SET', 'key1', 'value1'); redis.call('INCRBY', 'key2', 1/0); redis.call('SET', 'key3', 'value3')" 0
redis.pcall()
redis.pcall() 也用于执行 Redis的命令。当命令执行出错时,不会阻断脚本的执行,而是内部捕获错误,并继续执行后续的命令。
如下示例:当执行INCRBY key2 1/0 失败时,不会抛异常,后续流程继续执行,即SET key3 value3 也被执行。
Redis原生命令执行示例:
EVAL "redis.pcall('SET', 'key1', 'value1'); redis.pcall('INCRBY', 'key2', 1/0); redis.pcall('SET', 'key3', 'value3')" 0
原子性保证
首先,可以肯定的是:Redis执行 Lua脚本可以保证原子性,不过这和 Redis Server的部署方式密不可分。
Redis 通常有 3种不同的部署方式,部署方式不同,原子性的保证也不一样。
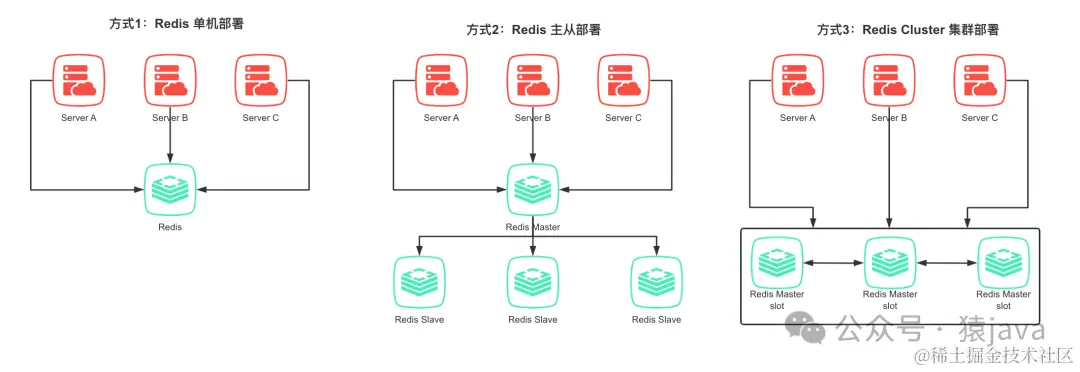
单机部署
不管 Lua脚本中操作的 key是不是同一个,都能保证原子性;
主从部署
Redis 主从复制是用于将主节点的数据同步到从节点,以保持数据的一致性。而Redis的所有写操作都在主节点上,所以,不管 Lua脚本中操作的 key是不是同一个,都能保证原子性;
需要注意:当主节点执行写命令时,从节点会异步地复制这些写操作。在这个复制的过程中,从节点的数据可能与主节点存在一定的延迟。因此,如果在 Lua 脚本中包含读操作,并且该脚本在主节点上执行,可能会读到最新的数据,但如果在从节点上执行,可能会读到稍有延迟的数据。
Cluster集群部署
如果 Lua脚本操作的 key是同一个,能保证原子性;
如果操作的 Key不相同,可能被 hash 到不同的 slot,也可能 hash 到相同的 slot,所以不一定能保证原子性;
因此,在 Cluster集群部署的环境下使用 Lua脚本时一定要注意:Lua脚本中操作的是同一个 Key;
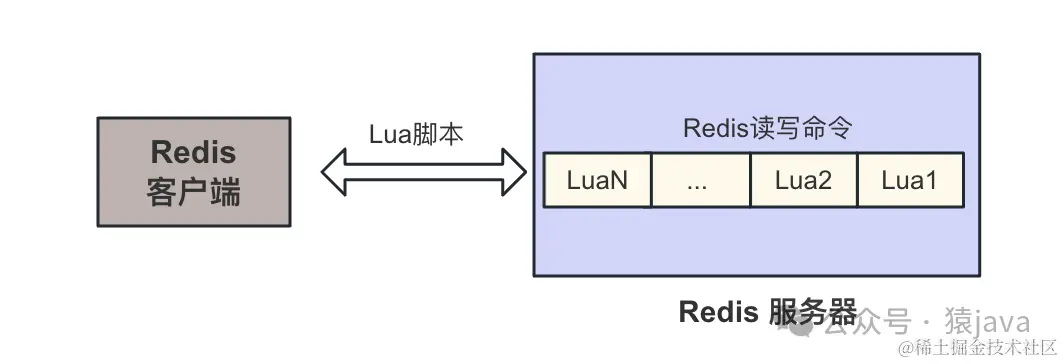
这里以 Redis单机部署为例:当客户端向服务器发送一个带有 Lua脚本的请求时,Redis会把该脚本当作一个整体,然后加载到一个脚本缓存中,因为 Redis读写命令是单线程操作(关于 Redis的单线程模型和多路复用线程模型会在其他的文章中讲解),最终,Lua脚本的读写在 Redis服务器上可以简单地抽象成下图,所有的 Lua脚本会按照进入顺序放入队列中,然后串行进行读写,这样就保证每个 Lua不会被其他的客户端打断,从而保证了原子性:
在面试中,Redis 执行 Lua脚本时,能否保证原子性?这个问题如何作答?
第一步,需要解释这里的原子性是什么?它和关系数据事务 ACID中的一致性的差异是什么?消除原子性在具体载体(RDBMS/NoSQL)上概念的差异;
第二步,需要解释 Redis的事务,说明 RDBMS/NoSQL 在事务上的差异点;
第三步,需要解释 Redis在不同部署方式下原子性能否保证。Redis部署方式有3种:单机部署,主从部署,Cluster集群部署,需要说明在哪些部署方式下能保证原子性,哪些不能保证原子性;
第四步,解释 Redis 执行 Lua脚本是如何保证原子性;
第五步,分析下 Redis的单线程模型 和 IO多路复用模型(加分项),这步是可选项;
Why Lua?
既然 Redis事务能保证原子性,为什么还需要 Lua脚本呢?
Lua 是一种嵌入式语言,是 Redis官方推荐的脚本语言;
Lua 脚本一般比 MULTI/EXEC 更快、更简单;
Redis 事务中,事务队列中的所有命令都必须在 EXEC命令执行才会被执行,对于多个命令之间存在依赖关系,比如后面的命令需要依赖上一个命令结果的场景,Redis事务无法满足,因此 Lua 脚本更适合复杂的场景;
Redis 事务能做的 Lua能做,Redis事务做不到的 Lua也能做;
Lua注意事项
Redis执行 Lua脚本时,Lua的编写需要注意以下几个点:
不要在 Lua脚本中使用阻塞命令(如BLPOP、BRPOP等)。因此这些命令可能会导致 Redis服务器在执行脚本期间被阻塞,无法处理其他请求;
不要编写过长的 Lua脚本。因为 Redis读写命令是单线程,过长的脚本,加载,解析,运行会比较耗时,导致其他命令的延迟延迟增加;
不要在 Lua脚本中进行复杂耗时的逻辑;因为 Redis读写命令是单线程的,长时间运行脚本可能导致其他命令的延迟增加;
Lua脚本中,需要注意区分 redis.call() 和 redis.pcall() 命令;
Lua 索引表从索引 1 开始,而不是 0;
总结
原子性需要区分具体使用的载体,在关系型数据库(比如 MySQL))和 No SQL(比如Redis)中,原子性的概念是不相同的;
Redis的事务(MULTI/ESXEC)和关系型数据库(比如 MySQL)的事务(ACID)也是不相同的;
ACID的原子性指:命令要么全部执行,要么全部不执行;
Redis执行 Lua脚本的原子性指:Lua脚本会当作一个整体被执行且不被其他事务打断,但是 Lua 脚本里面的命令无法保证“要么全部执行,要么全部不执行”;
Lua脚本使用 redis.pcall() 执行命令出错时会被catch,后续命令会正常执行;
Lua脚本使用 redis.call() 执行命令出错时会抛给客户端,后续命令会被阻断;
Lua 脚本一般比 MULTI/EXEC 更快、更简单;
Redis的部署方式决定了 Redis执行 Lua脚本是否能保证原子性,编写 Lua脚本时,特别需要注意在一个事务中是否要求操作同一个 key;
![[米联客-安路飞龙DR1-FPSOC] FPGA基础篇连载-01 软件工具环境搭建](https://img2023.cnblogs.com/blog/2504661/202407/2504661-20240728184626933-752860148.jpg)