## 前言
本系列文章是博主在工作中使用SAM模型时的学习笔记,包含三部分:
1. SAM初步理解,简单介绍模型框架,不涉及细节和代码
2. SAM细节理解,对各模块结合代码进一步分析
3. SAM微调实例,原始代码涉及隐私,此部分使用公开的VOC2007数据集,Point和Box作为提示进行mask decoder微调讲解
## 模型总览
SAM论文: https://arxiv.org/abs/2304.02643
SAM Github:https://github.com/facebookresearch/segment-anything
SAM在线demo: https://segment-anything.com/demo
SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zero-shot 和 few-shot能力,结合prompt engineering和fine tuning等技术可以将基座模型应用在各种下游任务中并实现惊人的效果。
SAM就是想构建一个这样的图像分割基座模型,即使是一个未见过的数据集,模型也能自动或半自动(基于prompt)地完成下游的分割任务。为了实现这个目标,SAM定义了一种可提示化的分割任务(promptable segmentation task),这个提示可以是**点、框、掩码、文本**(代码中未实现)等形式,基于这个提示模型就能分割出提示处所在物体的masks。同时这种提示可以是模糊的,比如以下图剪刀握手那的黄色部分点为提示,分割掩码可以是下图最右边三种情况中任意一种,从上到下分别代表**whole, part, subpart**三种层级的分割,这也是SAM兼容的。要达到这种效果就需要足够的高质量分割数据,SAM团队用他们提出的Data Engine策略成功使用人工加模型自动标注的方式制作除了一个有10亿个masks的分割数据集**[SA-1B](https://ai.meta.com/datasets/segment-anything/)**,这也是他们核心的贡献之一,本文尾部会介绍相关流程。模型架构来说相对比较常规,主要是借鉴了ViT和DETR,本身创新不大。
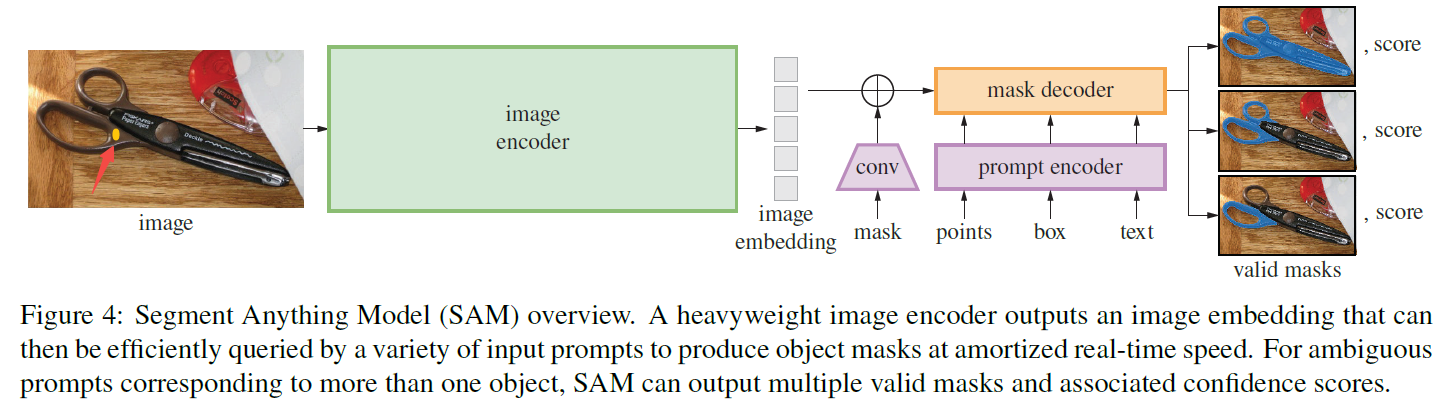
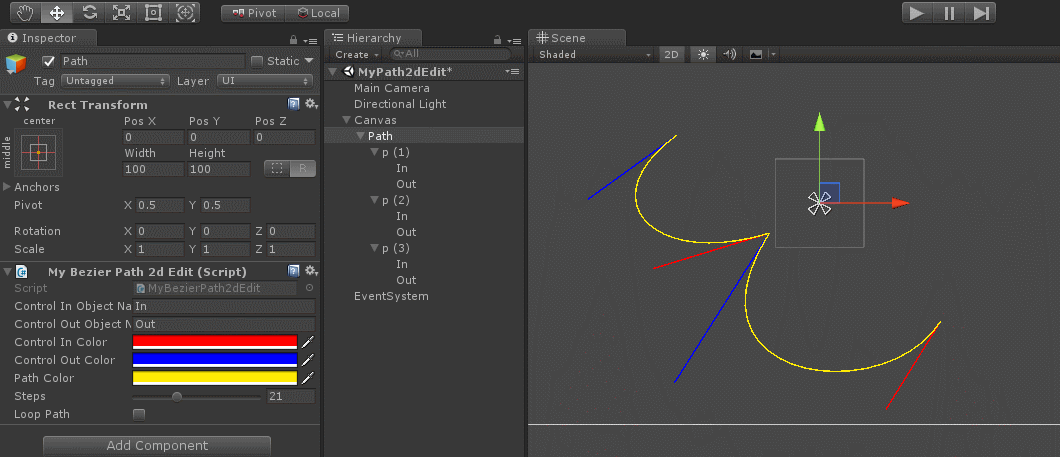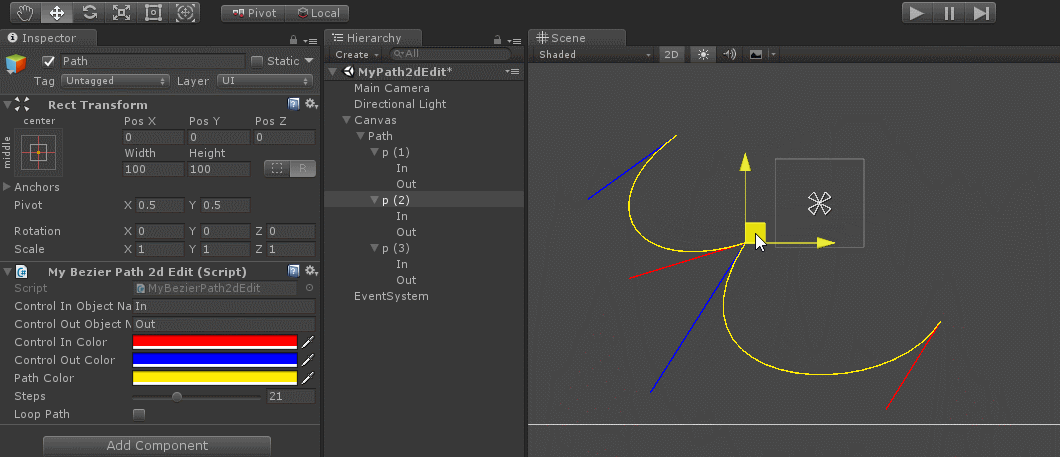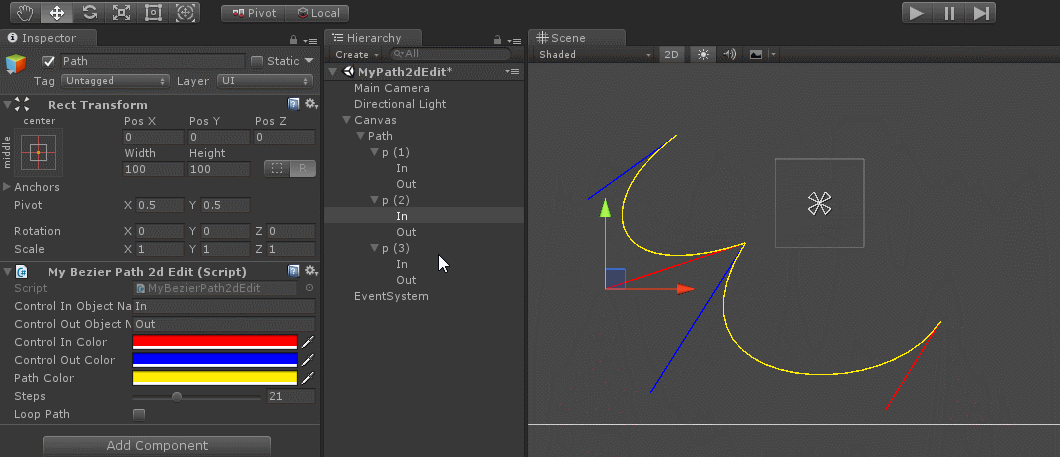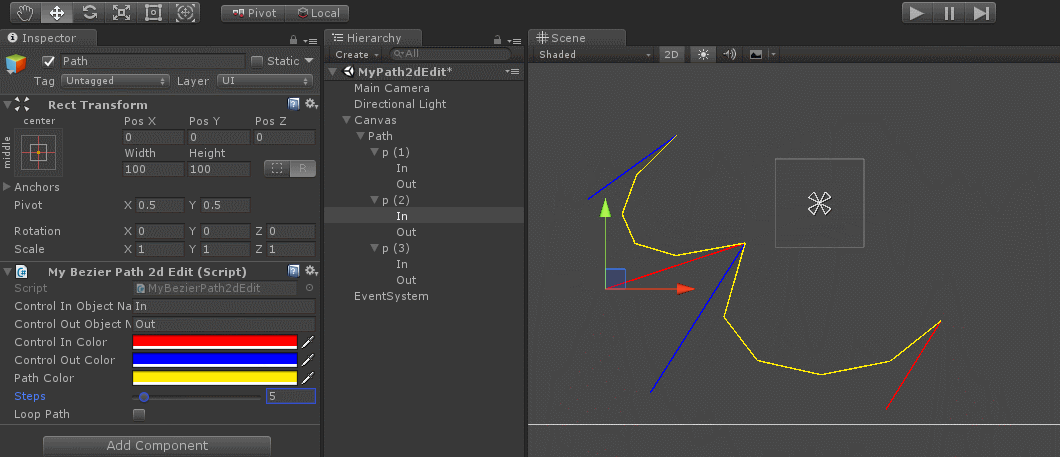
如上图,SAM模型架构主要包括image encoder,prompt encoder和mask decoder三部分:
- image encoder,使用了ViT模型将图像编码得到image embedding
- prompt encoder,将point、box、mask、txt等提示信息进行编码,后续会和image embedding一起用于生成masks
- mask decoder,将上述两个模块得到的embeddings整合,然后结合两个可学习的tokens生成不同层级的masks和对应的置信度值
值得一提的是,**prompt encoder和mask decoder都是非常轻量的**,主要的计算开销都在image encoder上,这点从模型权重上也能看出来,以ViT_B为基础的SAM权重是375M,其中prompt encoder只有32.8k,mask decoder是16.3M(4.35%),剩余则是image encoder,可想而知图像编码这块是非常耗时的。因此在实际推理中,一般单张图的image embedding只计算一次,然后将结果缓存起来,需要的时候直接调用。在image embedding已经计算好的情况下,论文中说给定一个prompt,生成mask时prompt encoder和mask decoder在浏览器中的计算耗时也仅需50ms。下面会具体介绍下各模块的输入输出和流程,均只考虑batch size为1的情况,代码讲解在下一篇。
### Image encoder
**输入:**
默认是1024x1024的图像,如尺寸不一致会将原图按最长边resize
**输出:**
单张图的1x256x64x64的image embedding,即编码后的图像特征
#### 流程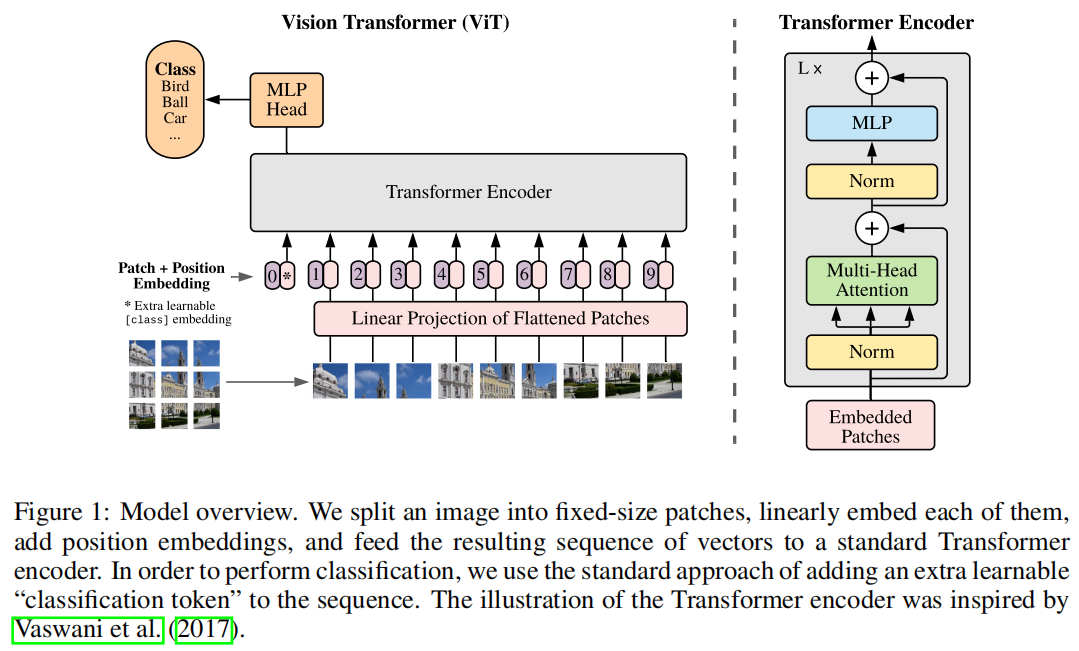
上图是[ViT](https://arxiv.org/abs/2010.11929)ViT论文中的结构图,image encoder整体流程和ViT是一样的,区别在于不需要[class]token做分类,只输出最终的图像编码张量
* 输入1024的图,拆分成64x64的768维patchs
* 经过attention block(window和global的MSA,相对位置编码)和MLP得到同样大小64x64x768embbeding特征
* 再经过neck得到1x256x64x64的图片embedding
这块有一篇文字介绍的更详细,如果想了解更多细节可以看这篇:[Image encoder模块Vision Transformer网络解析](https://blog.csdn.net/yangyu0515/article/details/130200524)
### Prompt encoder
**输入:**
point、box、mask、txt(代码未实现)等prompt,格式一般如下,B为batch size
* point需要包含点的x,y坐标BxNx2和label(0为前景,1位背景)BxNx1
* box包含框的左上和右下两个点,BxNx4,对于某个gt即单个mask,只会有1个box;如果输入的是N个box最终会生成N个masks
* mask一般和SAM最终输出mask的hxw(256x256),Bx1xHxW
* txt在SAM代码中未实现,这块可以参考[Grounded-Segment-Anything](https://github.com/IDEA-Research/Grounded-Segment-Anything)
**输出两个:**
* **sparse_embeddings** 点和框的稀疏嵌入,形状为BxNx(embed_dim),其中**N由输入点和框的数量确定**,如果两者同时有则N的计算方式为(点的个数+2x框的个数)
* point box 全都没有,输出大小:Bx0x256
* 如果只有point,输出大小:Bx(N+1)x256,会补充一个[0,0]空点在最后,label为-1,表示只有点提示;
* 如果只有box,输出大小: (B\*N)x2x256
* piont、box都有,输出大小:BxNx256
* **dense_embeddings** 掩码的密集嵌入,形状为Bx(embed_dim)x(embed_H)x(embed_W),**默认大小为Bx256x64x64**,没有提示时会返回一个网络学习到的no mask默认嵌入
#### 流程
网络已自动学会了针对不通过类型提示的编码信息,输入的point、box、mask等提示加上位置编码后,再加上网络学会的综合编码信息,最终对point、box这种稀疏的提示会返回sparse embedding, 对mask会返回dense embeddings(没有mask提示时是网络学习到的embeddings)。这部分就相当于把各种提示转换为decoder能理解的格式。
### Mask decoder
**输入:**
* image encoder得到的image_embeddings和图像的positional encoding
* prompt encoder得到的prompt embeddings(sparse和dense两种)
**输出:**
* masks,如果指定了"multimask_output"参数则会输出3个层级的mask(whole, part, and subpart),否则只输出1个mask
* IoU scores,可以理解为每个mask的置信度,由网络中的iou token得到
#### 流程
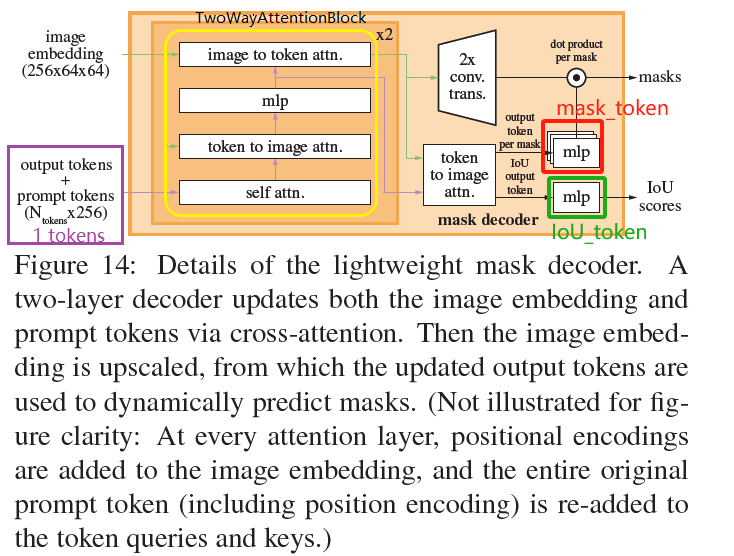
* 首先会image_embeddings会混入dense embeddings的信息(两者直接相加),sparse embeddings则会与mask token和IoU token拼在一起成为一个新的token,mask token后续会用于生成mask,IoU token用于衡量每个mask的好坏
* 然后这个新的token和image_embeddings经过一个TwoWayTransformer模块(下图黄色框部分),先做token的self attention,然后做token(作为key)到图像的cross attention,经过MLP更新token,最后再图像(作为key)到token的attention,目的是不断更新图像和token中的信息,会重复两次
* 更新后token再做一次token(作为key)到图像的cross attention后,又拆出来之前的两个部分mask token和IoU token,后者就代表每个mask的置信度;
而图像信息经过转置卷积还原到原图大小后,会和mask token做矩阵乘法生成最终的masks,类似 [YOLACT](https://mp.weixin.qq.com/s/-kQ4uwvW9OQ0MmU03F8jDw)中的"prototype masks"和"mask coefficients"矩阵乘法
### 整图分割推理(segment everything)

#### 流程
在图片上生成32x32的网格,得到1024个采样点,每个采样点都当做1个前景的prompt进入prompt encoder然后和image encoder结果一起生成mask,每次会处理一个batch(默认64)的采样点;每个batch得到的mask都会进行以下几个过滤:
* predicted IoU过滤,mask decoder除了返回masks还会预测对应mask iou值,过滤低置信度(默认阈值0.88)的mask
* stability score过滤,stability score是mask在两个阈值下二值化后的IoU值,可以理解为改变过滤阈值后还能得到同样mask的能力,过滤低于0.95的mask
* mask threshold过滤,直接过滤mask logits值低于mask_threshold(默认0.0)的mask
* boundary过滤,每个mask生成外界矩形,过滤超过图像边界的mask
所有batch过滤后的的masks结果再进行nms过滤(mask对应外接矩形的nms,阈值0.7)就得到最终的分割结果
#### 最终结果
git上也有官方demo可以参考:[全图分割的官方demo](https://github.com/facebookresearch/segment-anything/blob/main/notebooks/automatic_mask_generator_example.ipynb)
## 数据引擎(data engine)
SAM除了模型外,还公开了一份有10亿个masks的1100万张图的分割数据集**[SA-1B](https://ai.meta.com/datasets/segment-anything/)**,基于他们提出的data engine方案得到,这块的贡献也是非常显著,也体现了Data-centric AI的惊人能力,[这块知乎上"一堆废纸"博主介绍的比较好](如何评价Meta/FAIR 最新工作Segment Anything? - 一堆废纸的回答 - 知乎
https://www.zhihu.com/question/593888697/answer/2972047807)。从论文里总结就是辅助人工标注、半自动标注、全自动标注三步,具体如下:
* 第一步以人工标注为主。初始模型在公开数据集训练后辅助生成masks,再人工精修调整,再用标好的新数据迭代模型。如此重复6次,从12万张图得到430万masks
* 第二步是模型半自动标注高置信度masks,然后人工标注补充剩余未标出的masks。mask的置信度判断是用一个模型对mask进行目标检测,如果能检测出物体则是置信度较高mask无需再人工标注,这个目标检测模型是基于第一步得到的数据训练的。如此迭代5次,从18万张图新增了590万masks
* 第三部是模型全自动标注。基于此前两步的数据得到模型,已有较好的分割能力且能适配模糊提示分割(局部mask或者整体mask),对一张图撒32x32的网格点进行segment everything,后处理会挑选搞IoU和搞稳定性的masks并做NMS得到全图最终的masks。针对所有图片自动分割,最终得到了SA-1B数据集