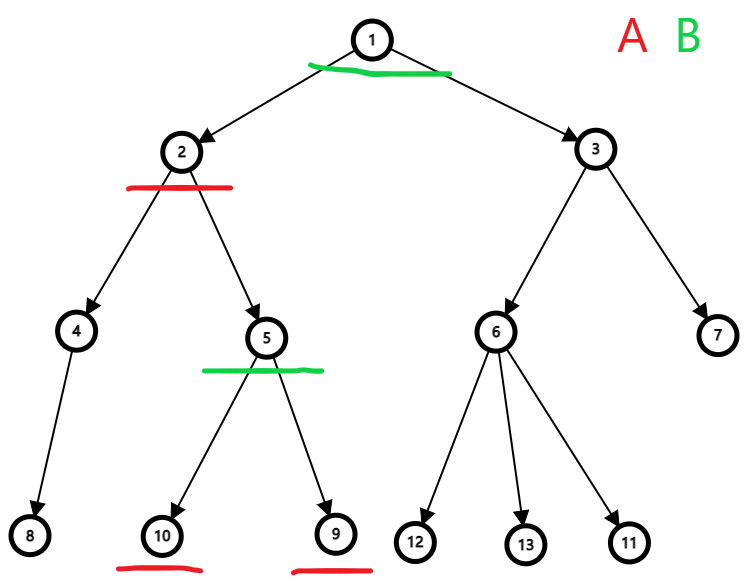
| 应用层 | 应用层的作用是为应用程序提供服务并规定应用程序中通讯相关的细节,也就是为应用提供服务。常见的协议有 HTTP,FTP,TELNET、SMTP 等。 | 是用户与应用程序之间的接口。 | 相当于收件员。当客户(应用)打电话(发起请求)给收件员(应用层)时,收件员可以根据客户的不同需求提供不同的服务(不同协议),比如隔天送达、指定时间送达等等。 |
| 表示层 | 表示层的作用是将应用处理的信息转换为适合网络传输的格式,或者将来自下一层的数据转换为上层能处理的格式。它主要负责数据格式的转换。具体来说,就是将设备固有的数据格式转换为网络标准格式。常见的协议有 ASCII、SSL/TLS 等。 | 主要解决了数据格式的转换。 | 相当于打包员。如果快递(数据)太臃肿,他会在不破坏快递的情况下压扁(压缩)它。如果客户注重安全线,全能的快递公司还能用密码箱( SSL/TLS)打包快递再快送。当然,打包员会确定,目的地快递站的拆包员,能无损地拆开包裹,将快递交给用户。 |
| 会话层 | 会话层作用是负责建立和断开通信连接,以及数据分割等数据传输相关的管理。常见的协议有 ADSP、RPC 等。 | 主要解决了不同主机之间的会话建立和管理。 | 相当于调度员。对快递运输进行调度指挥。例如这次客户要发100吨沙土(数据),到底是空运、陆运还是海运。而运完之后,相关信息(连接)也可以被销毁了,这些都是他的职责。 |
| 传输层 | 传输层起着可靠传输的作用。只在通信双方节点进行处理,而不需在路由器上处理。此层有两个具有代表性的协议:TCP 与 UDP。 | 主要解决了如何保证数据的可靠传输。 | 相当于跟单员。负责任的跟单员(使用 TCP 协议)会保证快递送到客户手上,如果送不到就让公司再发一次。不负责任的跟单员(使用 UDP 协议)只管将快递送到客户指定的地方,不管快递是否送到客户手上。 |
| 网络层 | 网络层负责将数据传输到目标地址。目标地址可以是多个网络通过路由器连接而成的某一个地址。因此这一层主要负责寻址和路由选择。主要由 IP、ICMP 两个协议组成。 | 主要解决了如何将数据包从源地址发送到目的地址。 | 相当于路线规划员。快递公司有很多集散中心(路由器),根据集散中心的情况(是否拥堵),找出一条最合适的路径将货物(数据)沿路运过去。 |
| 数据链路层 | 该层负责物理层面上互连的节点之间的通信传输。例如与1个以太网相连的两个节点间的通讯。常见的协议有 HDLC、PPP、SLIP 等。 | 主要定义了数据帧的格式和传输方式。 | 相当于驾驶员。他们驾驶着汽车,将打包好的快递(数据帧)从一个城市(物理节点)运输到另一个城市 |
| 物理层 | 物理层负责0、1比特流(0、1序列)与电压高低、光的闪灭之间的互换。典型的协议有 RS 232C、RS 449/422/423、V.24 和 X.21、X.21bis 等。 | 解决两个硬件之间如何通信的问题,常见的物理媒介有光纤、电缆、中继器等。 | 相当于交通工具。例如公路、汽车和飞机等,承载货物(数据)的交通运输。 |

1至4层被认为是低层,这些层与数据移动密切相关。5至7层是高层,包含应用程序级的数据。每一层负责一项具体的工作,然后把数据传送到下一层。
从上往下,每经过一层,协议就会在这个包裹上面做点手脚,加点东西,传送到接收端,再层层解套出来,如下示意图:

在实际过程中,七层结构执行了哪些操作呢?
要回答这个问题,我们可以思考一下:用户输入一个网址,计算机执行了什么操作?
1. 所有的数据通信经过封装打包后,经由物理线路传送。

2. 所有的主机名都需要解析为IP地址。

3. 应用层使用HTTP协议,利用传输层面面向连接的TCP协议。

4. WEB应用采用客户机/服务器的工作模式。

5. 数据包通过路由器,根据路由表进行转发。

6.在每个网络内部,都要把IP地址转换成MAC地址。

7.服务器上的WEB服务进程在监听TCP的80端口。
8.服务器按照请求,生成HTML文档发送到客户端。
9.客户端浏览器解释HTML文档,生成页面。
输入URL到显示页面的全过程
基础版本:
- 浏览器根据请求的 URL 交给 DNS 域名解析,找到真实 IP ,向服务器发起请求;
- 服务器交给后台处理完成后返回数据,浏览器接收⽂件( HTML、JS、CSS 、图象等);
- 浏览器对加载到的资源( HTML、JS、CSS 等)进⾏语法解析,建立相应的内部数据结构 (如 HTML 的 DOM);
- 载⼊解析到的资源⽂件,渲染页面,完成。
详细简版:
- 从浏览器接收 url 到开启⽹络请求线程(这⼀部分可以展开浏览器的机制以及进程与线程 之间的关系)
- 开启⽹络线程到发出⼀个完整的 HTTP 请求(这⼀部分涉及到dns查询, TCP/IP 请求,五层因特⽹协议栈等知识)
- 从服务器接收到请求到对应后台接收到请求(这⼀部分可能涉及到负载均衡,安全拦截以及后台内部的处理等等)
- 后台和前台的 HTTP 交互(这⼀部分包括 HTTP 头部、响应码、报⽂结构、 cookie 等知 识,可以提下静态资源的 cookie 优化,以及编码解码,如 gzip 压缩等)
- 单独拎出来的缓存问题, HTTP 的缓存(这部分包括http缓存头部, ETag , catchcontrol 等)
- 浏览器接收到 HTTP 数据包后的解析流程(解析 html、 词法分析然后解析成 dom 树、解析 css ⽣成 css 规则树、合并成 render 树,然后 layout 、 painting 渲染、复合图层的合成、 GPU 绘制、外链资源的处理、 loaded 和 DOMContentLoaded 等)
- CSS 的可视化格式模型(元素的渲染规则,如包含块,控制框, BFC , IFC 等概念)
- JS 引擎解析过程( JS 的解释阶段,预处理阶段,执⾏阶段⽣成执⾏上下⽂, VO ,作 ⽤域链、回收机制等等)
- 其它(可以拓展不同的知识模块,如跨域,web安全, hybrid 模式等等内容)
详细版:
1、在浏览器地址栏输⼊URL
2、浏览器查看缓存,如果请求资源在缓存中并且新鲜,跳转到转码步骤
-
- 如果资源未缓存,发起新请求
- 如果已缓存,检验是否⾜够新鲜,⾜够新鲜直接提供给客户端,否则与服务器进⾏验证。
- 检验新鲜通常有两个HTTP头进⾏控制 Expires 和 Cache-Control:
- HTTP1.0提供 Expires,值为⼀个绝对时间表示缓存新鲜⽇期
- HTTP1.1增加了Cache-Control: max-age=time,值为以秒为单位的最⼤新鲜时间
3、浏览器解析URL获取协议,主机,端⼝,path
4、浏览器组装⼀个HTTP(GET)请求报⽂
5、浏览器获取主机 ip 地址,过程如下:
-
- 浏览器缓存
- 本机缓存
- hosts⽂件
- 路由器缓存
- ISP DNS缓存
- DNS递归查询(可能存在负载均衡导致每次IP不⼀样)
6、打开⼀个socket与⽬标IP地址,端⼝建⽴TCP链接,三次握⼿如下:
-
- 客户端发送⼀个TCP的SYN=1,Seq=X的包到服务器端口
- 服务器发回SYN=1, ACK=X+1, Seq=Y的响应包
- 客户端发送ACK=Y+1, Seq=Z
7、TCP链接建⽴后发送HTTP请求
8、服务器接受请求并解析,将请求转发到服务程序,如虚拟主机使⽤HTTP Host头部判断请求的服务程序
9、服务器检查**HTTP请求头是否包含缓存验证信息**,如果验证缓存新鲜,返回304等对应状态码
10、处理程序读取完整请求并准备HTTP响应,可能需要查询数据库等操作
11、服务器将响应报⽂通过TCP连接发送回浏览器
12、浏览器接收HTTP响应,然后根据情况选择关闭TCP连接或者保留重⽤,关闭TCP连接的四次握⼿如下:
-
- 主动⽅发送Fin=1, Ack=Z, Seq= X报⽂
- 被动⽅发送ACK=X+1, Seq=Z报⽂
- 被动⽅发送Fin=1, ACK=X, Seq=Y报⽂
- 主动⽅发送ACK=Y, Seq=X报⽂
13、浏览器检查响应状态吗:是否为1XX,3XX, 4XX, 5XX,这些情况处理与2XX不同
14、如果资源可缓存,进行缓存
15、对响应进行解码(例如gzip压缩)
16、根据资源类型决定如何处理(假设资源为HTML⽂档)
17、解析HTML⽂档,构件DOM树,下载资源,构造CSSOM树,执⾏js脚本,这些操作没有严 格的先后顺序,以下分别解释:
16、构建DOM树:
Tokenizing:根据HTML规范将字符流解析为标记
Lexing:词法分析将标记转换为对象并定义属性和规则
DOM construction:根据HTML标记关系将对象组成DOM树
17、解析过程中遇到图⽚、样式表、js⽂件,启动下载
18、构建CSSOM树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建CSSOM树
19、根据DOM树和CSSOM树构建渲染树 :
-
- 从DOM树的根节点遍历所有可⻅节点,不可⻅节点包括:
- script , meta 这样本身 不可⻅的标签。
- 被css隐藏的节点,如 display: none
- 对每⼀个可⻅节点,找到恰当的CSSOM规则并应⽤
- 发布可视节点的内容和计算样式
- 从DOM树的根节点遍历所有可⻅节点,不可⻅节点包括:
20、js解析如下:
-
- 浏览器创建Document对象并解析HTML,将解析到的元素和⽂本节点添加到⽂档中,此时**document.readystate为loading**
- HTML解析器遇到没有async和defer的script时,将他们添加到⽂档中,然后执⾏⾏内 或外部脚本。这些脚本会同步执⾏,并且在脚本下载和执⾏时解析器会暂停。这样就可以⽤document.write()把⽂本插⼊到输⼊流中。同步脚本经常简单定义函数和注册事件处理程序,他们可以遍历和操作script和他们之前的⽂档内容
- 当解析器遇到设置了async属性的script时,开始下载脚本并继续解析⽂档。脚本会在它 下载完成后尽快执⾏,但是解析器不会停下来等它下载。异步脚本禁止使⽤ document.write(),它们可以访问⾃⼰script和之前的⽂档元素
- 当⽂档完成解析,document.readState变成interactive
- 所有defer脚本会按照在⽂档出现的顺序执⾏,延迟脚本能访问完整⽂档树,禁止使⽤ document.write()
- 浏览器在Document对象上触发DOMContentLoaded事件
- 此时⽂档完全解析完成,浏览器可能还在等待如图⽚等内容加载,等这些内容完成载⼊ 并且所有异步脚本完成载⼊和执⾏,document.readState变为complete,window触发 load事件
21、显示⻚⾯(HTML解析过程中会逐步显示⻚⾯)
![[WACV2022]Addressing out-of-distribution label noise in webly-labelled data](https://img2023.cnblogs.com/blog/3039442/202408/3039442-20240806194717685-1403539735.png)