监控的背景和意义
在现代前端开发中,接入监控系统是一个很重要的环节,它可以帮助开发者、产品、运营了解应用的性能表现,用户的实际体验以及潜在的错误和问题,从而进一步优化用户体验,帮助产品升级迭代。
背景
意义
监控的类别
从上面可看出,通过监控能够促使我们的系统更加健壮、稳定,体验更好。那我们团队也从去年开始逐步将各个应用接入了监控。到目前为止,我们的监控分为两个部分:
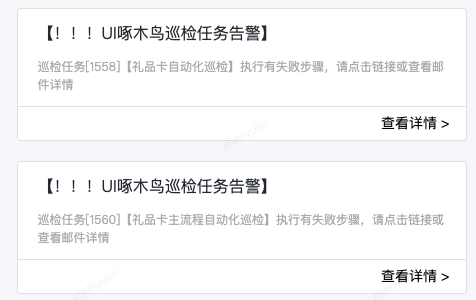
监控整体架构
监控建设实践
实时监控
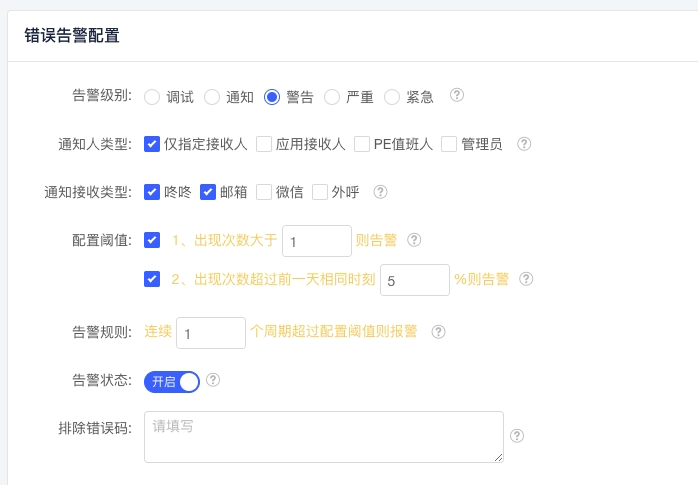
通过整合 SGM 监控平台和告警系统,我们实现了对所有接入应用的实时监控。一旦检测到异常,系统会立即通过多种方式(如咚咚、邮件、电话等)通知相关团队成员,确保问题能够被迅速发现和解决。为了提高告警的有效性,我们精心设计了告警策略,确保只有真正的异常情况才会触发告警。以下是我们在优化告警设置过程中积累的一些关键经验和建议:
这些经验和建议是我们在实践中不断摸索和尝试的结果,希望能够帮助你们更有效地管理和响应系统告警,确保应用的稳定运行。
WEB端
用户体验
用户体验是指用户在使用网站过程中的整体感受、情绪和态度,它包括与产品交互的全程。对于开发者而言,打造出色的用户体验意味着关注网站的加载速度、视觉稳定性、交互响应时间、渲染性能等关键因素。Google 提出了一系列 Web 性能标准指标,这些指标旨在量化用户体验的不同层面。SGM 性能监控平台紧跟这些标准,对几项关键指标进行监控并提供反馈,以确保用户能够获得流畅且愉悦的网站使用体验。

最初,我们遵循了 Google 提出的标准来精确设定我们的告警系统。

配置告警后,我们注意到告警频率较高,主要是因为多数系统的实际网页最大内容绘制(LCP)值普遍超过了预期的 2.5s 标准。然而,这些告警并未实质性影响用户的正常使用体验。为了优化告警机制,我们经过仔细评估后,决定将部分系统的 LCP 阈值暂时调整至 5s,并相应调整了告警级别,以更合理地反映系统性能对用户体验的实际影响。
显然,当前调整的 LCP 阈值 5s 并非我们的最终目标。这一调整是基于应用当前的性能状况所做的临时措施,旨在优化告警的频率和质量。我们计划随着对各个应用性能的持续改进,最终将 LCP 阈值恢复至标准的 2.5s。
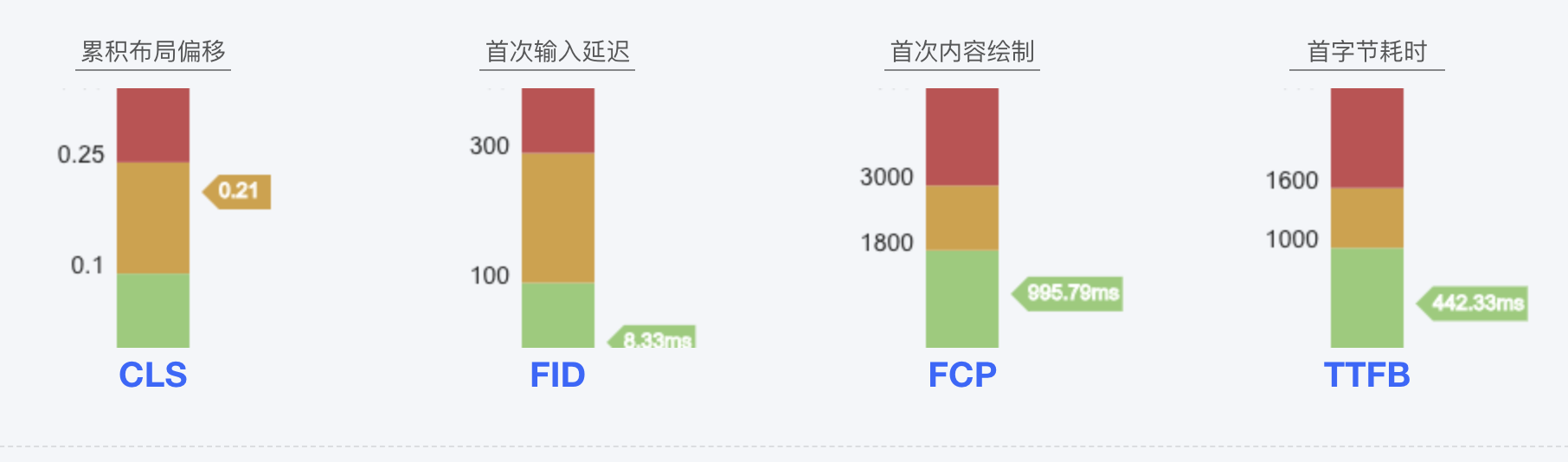
从最初启用告警到目前决定关闭大部分告警,我们的决策基于以下考虑:
基于这些理由,我们目前选择只对 LCP 指标保持告警启用,以确保关注到可能影响用户加载体验的关键性能问题。
| 健康度指标 | 告警开启 | 标准值 | 优化后值 | 告警阀值 | 告警级别 |
|---|---|---|---|---|---|
| LCP | 开启 | <=2500ms | 针对部分应用 <=5000ms | 1min 内 耗时>=5000ms(持续优化并更新阀值到2500ms) 调用次数:50 连续次数:1次 | 通知 |
| FCP | 关闭 | <=1800ms | - | - | |
| CLS | 关闭 | <=0.1 | - | - | |
| FID | 关闭 | <=100ms | - | - | |
| TTFB | 关闭 | <=1000ms | - | - |
页面性能
网页性能涉及从加载开始到完全可交互的整个过程,包括页面内容的下载、解析和渲染等多个阶段。在 SGM 监控平台上,我们能够追踪到一系列与页面加载性能相关的指标,如页面加载总时长、DNS 解析时长、DOM 加载完成时间、用户的浏览器和地理分布、首次渲染(白屏)时间、用户行为追踪、性能重现和热力图分析等。这些丰富的数据为我们优化页面性能提供了宝贵的参考。特别是首次渲染时间,或称为白屏时间,是我们监控中特别关注的一个关键指标,因为它直接影响用户的首次印象和整体体验。
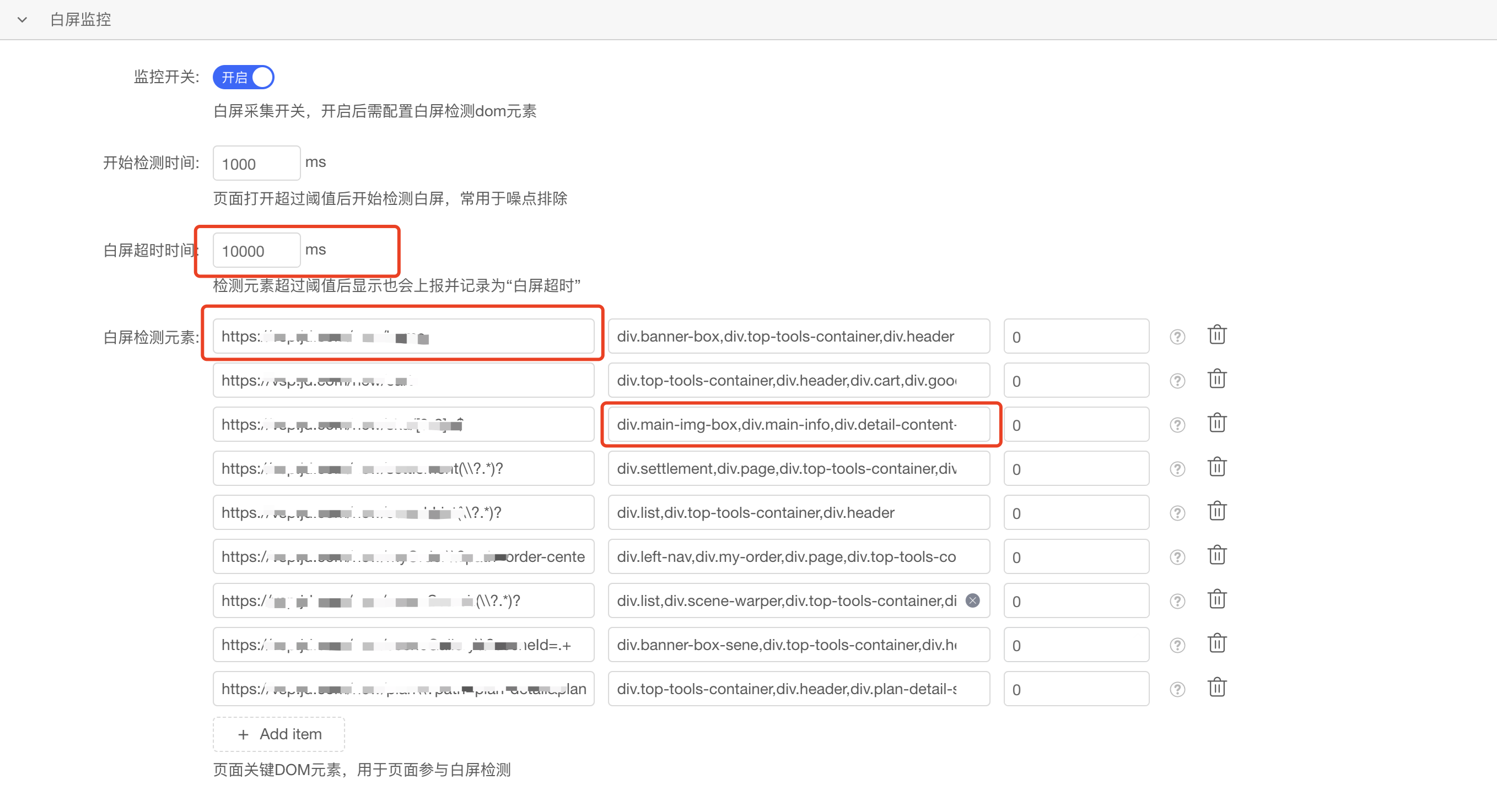
为了监控白屏时间,我们必须在应用的全局配置中的白屏监控项下,指定每个页面的 URL 及其关键元素。同时,我们还需设定监控的起始时间点和超时阈值。值得注意的是,URL 配置支持正则表达式,这为我们提供了灵活性,以匹配和监控一系列相似的页面路径。
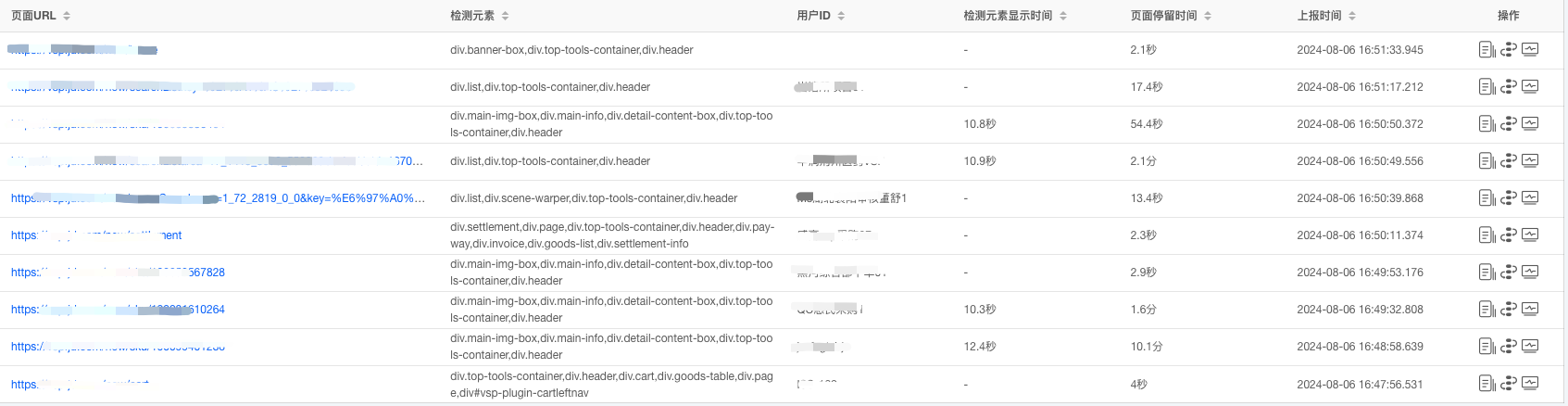
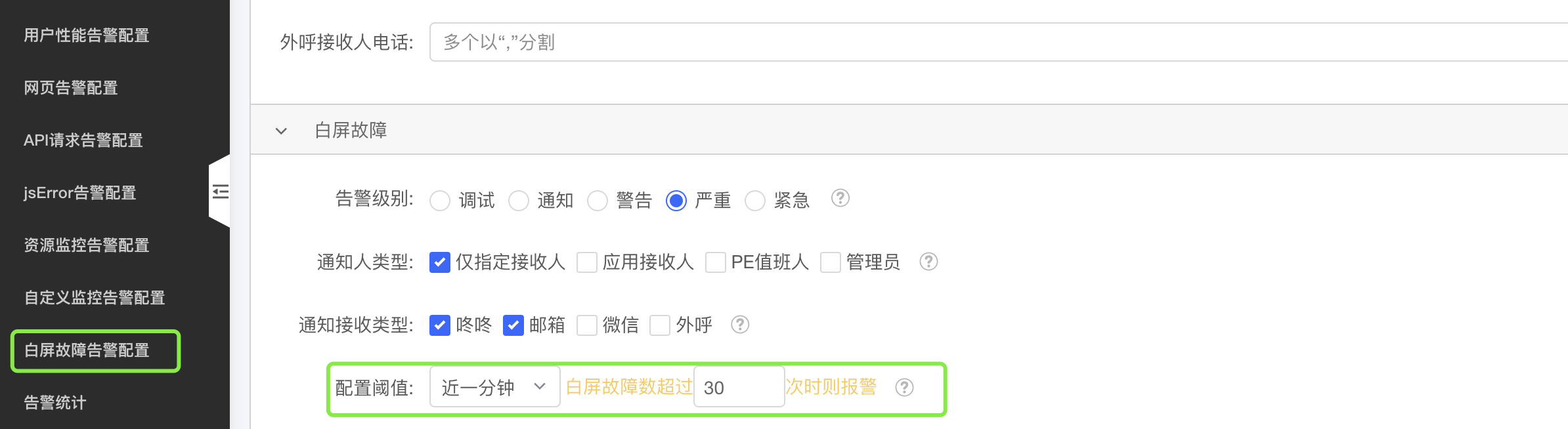
面对当前的局限性,我们采取了双策略应对。一方面,我们利用白屏告警功能直接监控页面的白屏情况;另一方面,我们通过分析页面加载性能指标中的白屏时间来间接监测潜在的白屏问题。在设置平均耗时时间和告警级别时,我们综合考虑了多个因素,包括用户的网络环境、告警的发生频率以及告警的实际适用性,以确保监控方案的有效性和合理性。
| 网页性能 | 告警开启 | 优化前值 | 优化后值 | 告警阀值 | 告警级别 |
|---|---|---|---|---|---|
| 首包时间 | 关闭 | - | - | - | - |
| 页面完全加载时间 | 关闭 | - | - | - | - |
| 白屏时间 | 开启 | <=5000ms | <=10000ms | 1min 内 耗时>=10000ms,后期采用白屏告警替代 调用次数:30 连续次数:5 次 | 紧急 |
JSError监控
我们通过配置错误关键词来匹配控制台的报错信息。报错阈值的设定可以参考各个项目的 QPS,因为在项目实施了恰当的降级策略后,即便控制台出现报错,页面通常仍能正常访问,不会对用户体验造成影响。因此,这个阈值可以适当设置得较高。
这里需要特别注意 “Script error” 的错误,这种错误给不到任何对我们有用的信息。所以需要采用一定的手段避免出现类似的报错:
<script src="http://xxxdomain.com/home.js" crossorigin></script>Vue.config.errorHandler = (err, vm, info)=> {if (err) {try {console.error(err);window.__sgm__.error(err)} catch (e) {}}
};
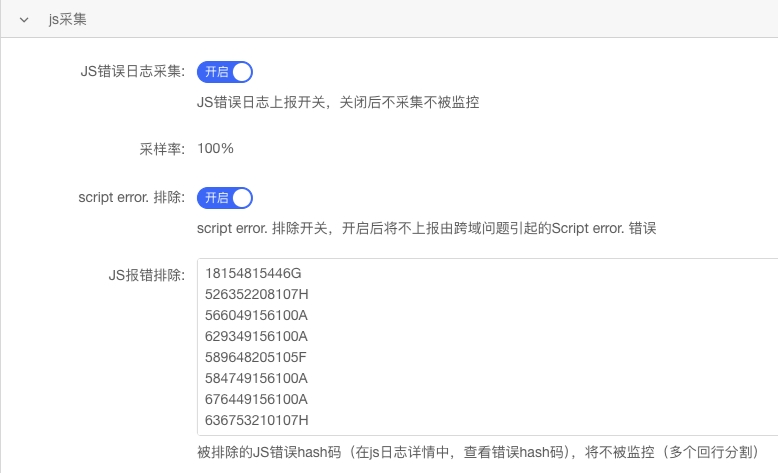
| 关键指标 | 关键字(支持正则匹配) | 触发次数 | 告警级别 |
|---|---|---|---|
| js错误 | null、undefined、error、map、filter、style、length... | 周期:1min ,错误次数:50/100/200(可参考 QPS 值设置),连续次数:1次 | 严重 |
API请求监控
这里我们的告警设置主要关注 HTTP 状态码和业务错误码。这两项指标的异常表明我们的应用可能遇到了问题,需要我们迅速进行检查和处理以确保系统的正常运行。
首先,我们必须在应用的监控配置中设定数据采集参数:
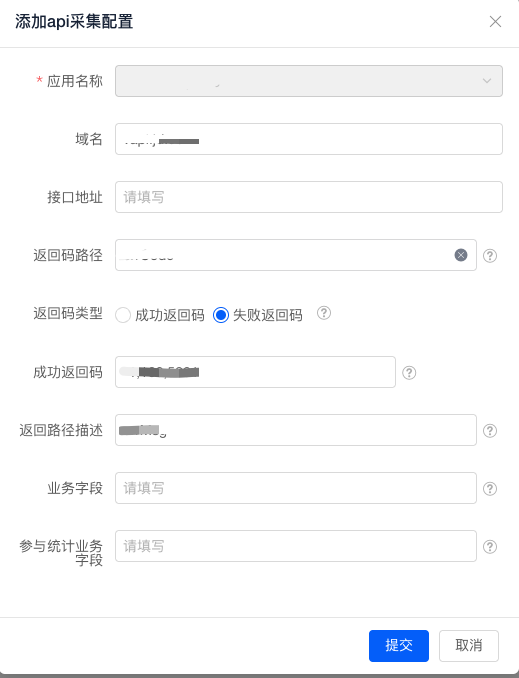
| 关键指标 | 错误码 | 业务域名 | 触发次数 | 告警级别 |
|---|---|---|---|---|
| http错误 | !200(Http响应非200报警) | xx1.jd.com xx2.jd.com | 周期:1min 错误次数:1 总调用次数:50 连续次数:1 | 严重 |
| 业务失败码 | errCode(根据实际业务线设置 -1,-2等) |
针对业务失败码:
| 应用来源 | 标准响应 | 针对性告警 |
|---|---|---|
| 慧采PC 企业购 | { "code":null, "success":true, "msg":"操作成功", "result":{} } | 业务异常码 code ·-1,-2 ·... |
| 锦礼 | { "code": 000, "data": {}, "msg": "操作成功" } | 业务异常码 code ·! (1000 && 3001等 ) |
| color | ·-1 echo ·1 echo | |
| 其他 | ... | .... |
2、对于新增应用,我们实施了后端服务异常码的标准化。因此,在监控方面,我们只需要配置一套统一的标准来进行监控。
{"50000X": "程序异常,内部", "500001": "程序异常,上游","500002": "程序异常,xx","500003": "程序异常,xx",...
}资源错误
这里通常指的是 css、js、图片等资源的加载错误
| 关键指标 | 告警开启 | 告警阀值 | 告警级别 |
|---|---|---|---|
| 资源错误 | 开启 | 周期:1min 错误次数:200(也可参照QPS进行设置) 连续次数:1 | 严重 |
对于图片加载错误,只需在项目中实施适当的降级方案。在应用的监控配置中,我们可以设置为不收集图片错误相关的数据。

再来举个例子:
在企业业务的封闭场景中,例如慧采平台,我们集成了埋点 JavaScript 脚本。然而,由于某些客户的网络环境,导致我们的埋点相关静态资源延迟加载。

治理方案:
自定义上报
每个业务流程的关键节点或核心功能实施了专门的监控措施,以便对任何异常状况进行跟踪、监控并及时上报。
目前,几条业务线已经实施了自定义上报机制,其主要目的包括:
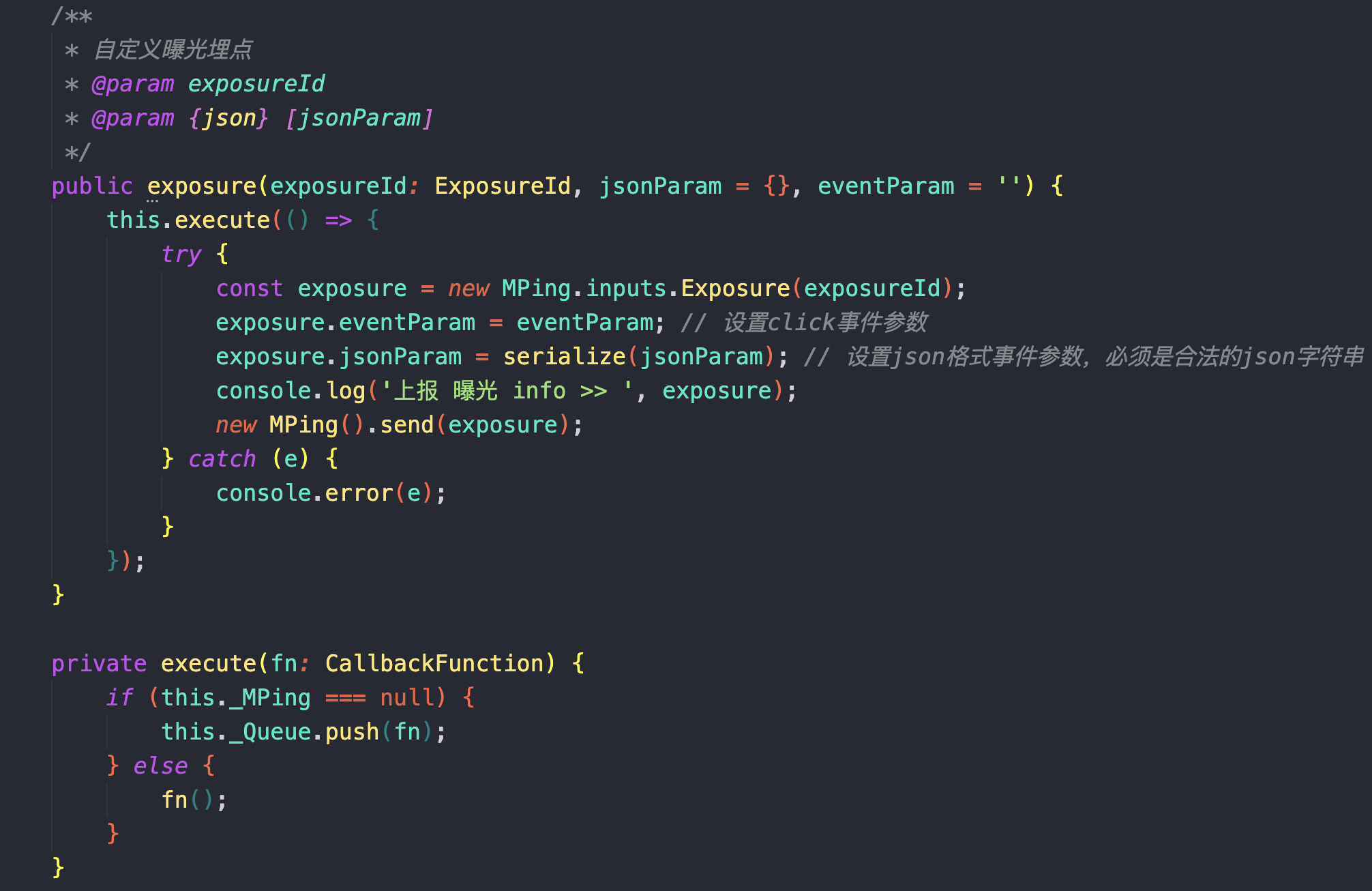
锦礼酷兜:用户在选择地址后,系统未能根据所选地址提供正确的信息,导致页面加载出现异常。
由于这个 H5 页面被嵌入到用户的 App 内,开发者难以直接复现用户遇到的问题。因此,我们利用监控平台的自定义上报功能来收集相关信息,以辅助进行问题排查。


E卡:外部引用资源异常上报(设备指纹,eid 等)
在结算页面提交订单时,系统需要获取设备ID。为此,我们实施了降级方案,并通过自定义上报机制对此过程进行监控,以确保流程的顺利执行。
降级方案:如果获取不到,后端会生成 uuid 给到前端。
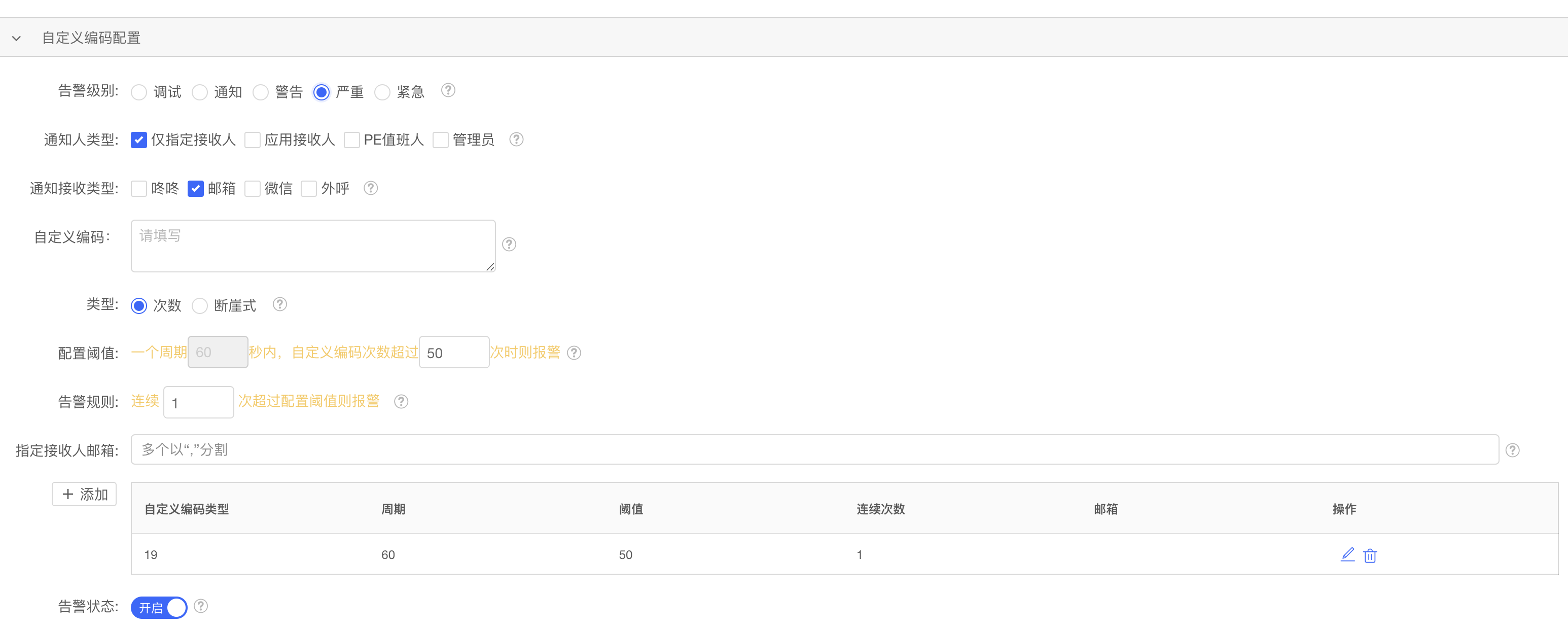
企业购注销pc:我们需要集成科技 SDK,以便在页面上完成用户注销后自动跳转到指定的 URL。上线后,收到客户反馈指出在完成注销流程后页面未能正确跳转。
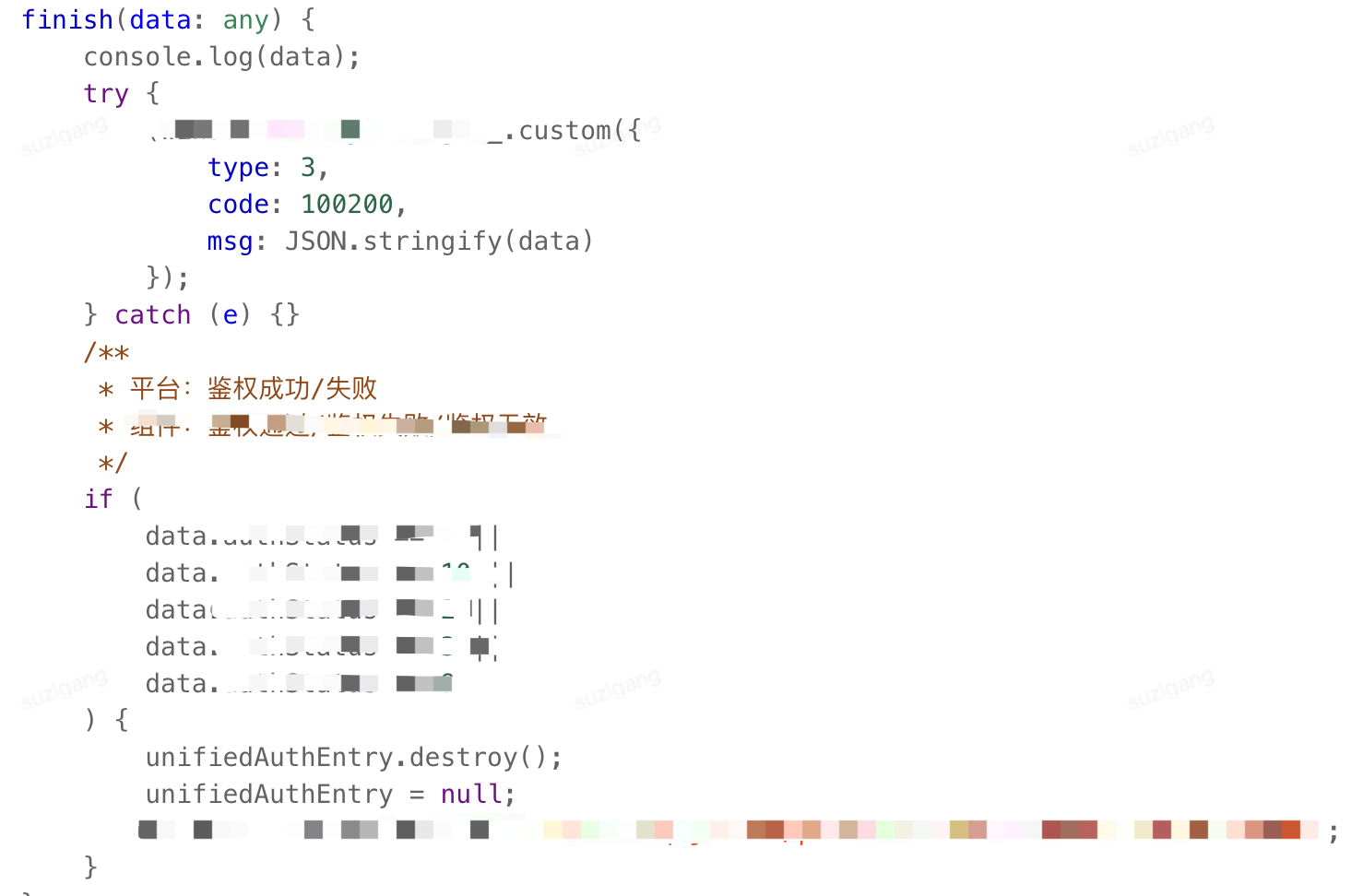
接口异常:在接口异常中,添加自定义监控,查看入参和出参信息。
尽管我们已经在应用中引入了自定义监控以便更好地观察和定位问题,但我们仍需进一步细化和规范化这些监控措施。目前,我们正积极对各业务线的功能点进行梳理,以实现更深入的细化监控。我们的目标是为每个业务线、每个应用的关键链路和功能点定制针对各种异常情况的精细化自定义监控(例如,某页面按钮的显示或点击异常)。
| 自定义告警 | 告警开启 | 告警阀值 | 告警级别 |
|---|---|---|---|
| 自定义编码 | 开启 | 1min内 调用次数:50 连续次数:1次 | 警告 |
小程序端
与 Web 端相比,小程序的监控存在一些差异,主要是缺少了如 LCP(最大内容绘制)等特定性能指标。然而,性能问题、JavaScript错误、资源加载错误等其他监控指标仍然可以被捕获。此外,小程序官方和开发者工具都提供了性能检测工具,这些工具便于开发者查看和优化小程序应用的性能。本文将不深入介绍 Web 端的监控指标,而是专注于介绍小程序中独有的监控和分析工具。
小程序官方后台
可以分析接口数据、js 分析等。
利用 SGM 的监控功能结合小程序官方的分析工具,对我们的小程序进行综合优化,是一个有效的策略。
原生应用
基础监控:mPaas、烛龙、SGM
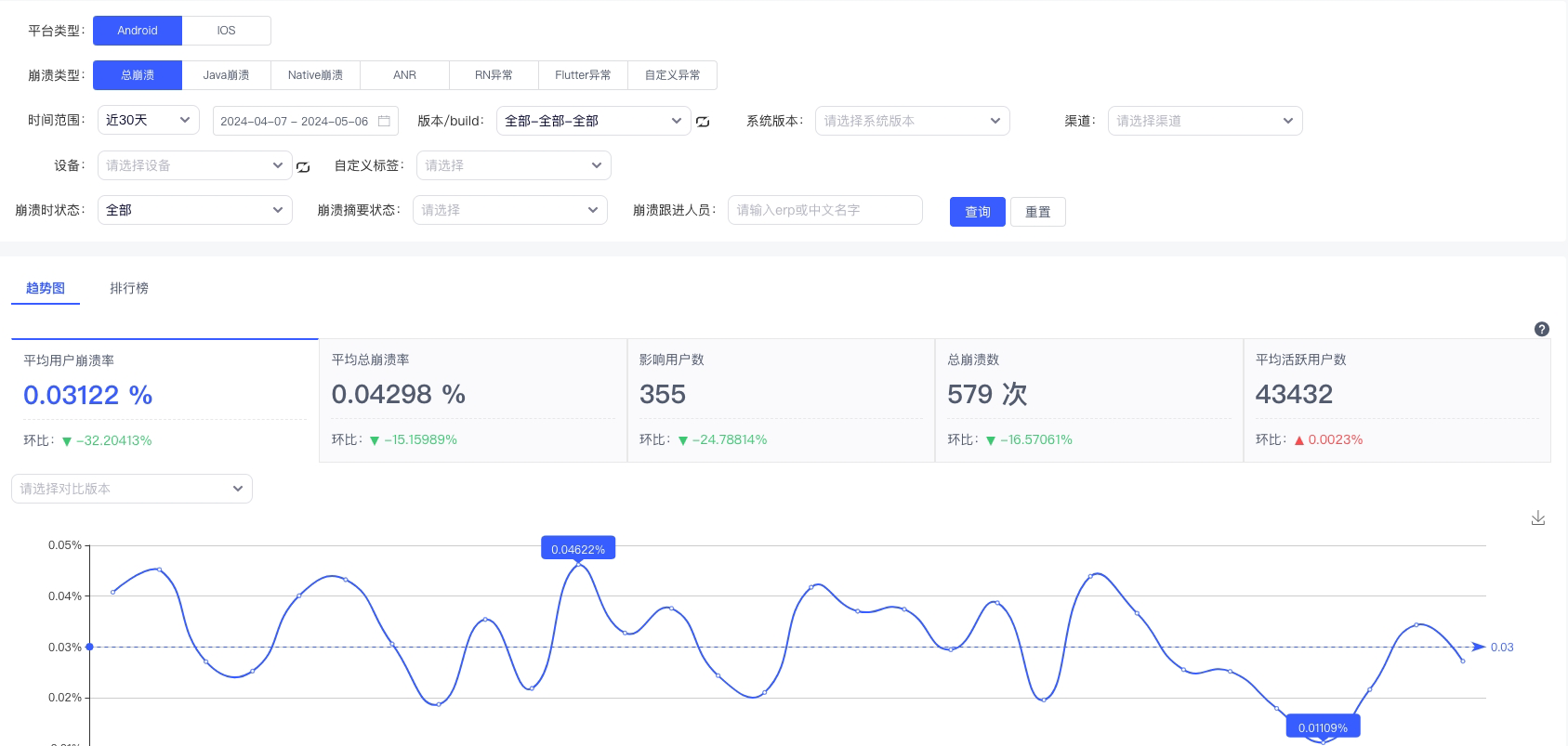
mPaaS:崩溃监控。应用崩溃对用户体验有显著影响,是移动端监控中的一个关键指标。通过不断的监控和优化,京东慧采移动端的崩溃率已经降至较低水平,目前的平均用户崩溃率大约为0.03122%。
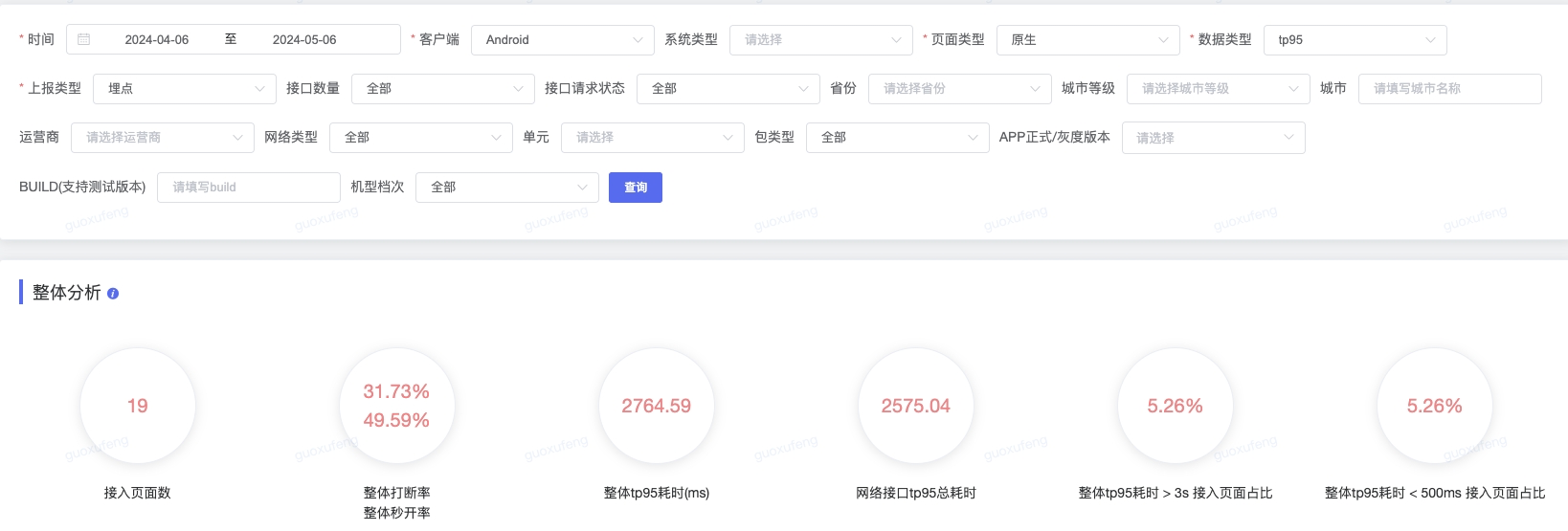
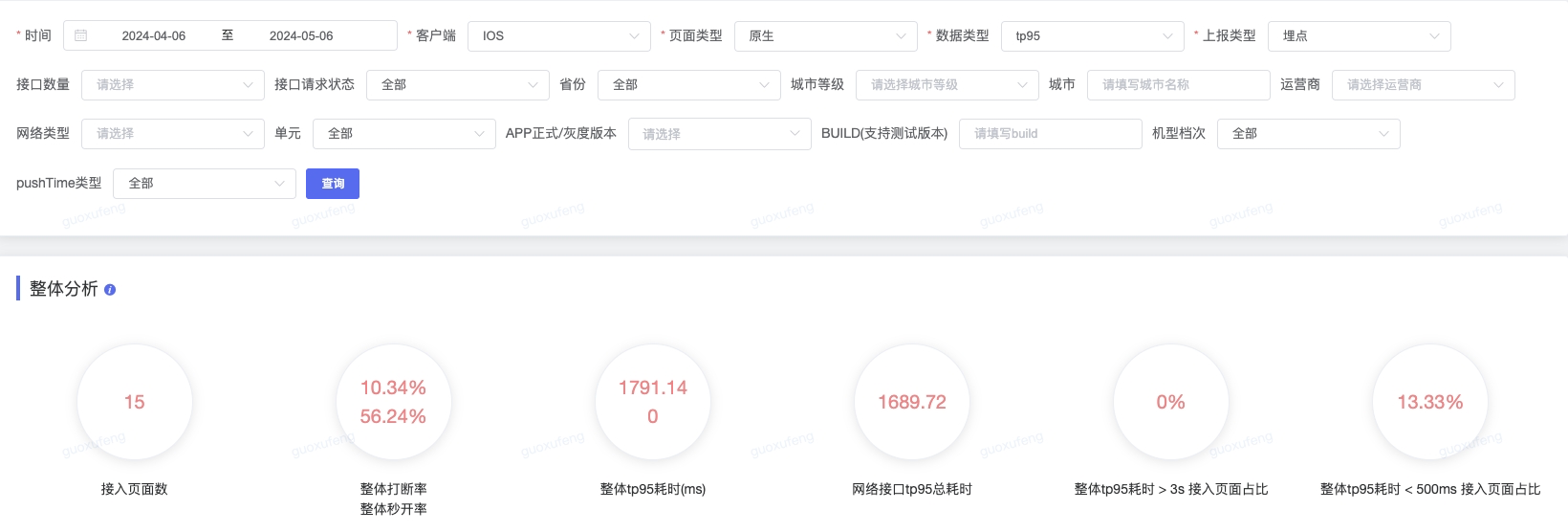
烛龙:启动耗时、首屏耗时、启动且首焦耗时、卡顿。为了改善首屏加载时间,京东慧采采用了烛龙监控平台并实施了相应的优化措施。优化后,应用的整体性能显著提升,其中 Android 平台的tp95耗时大约为 2764ms,iOS 平台的tp95耗时大约为1791ms,均达到了较低的水平。
SGM:网络、WebView、原生页面等指标。
业务监控
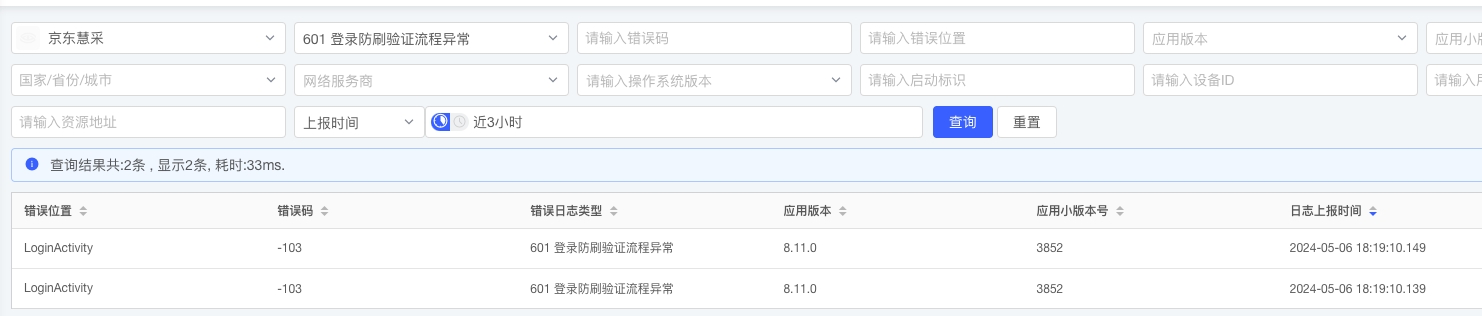
京东慧采在多个业务模块中,其中登录、商详、订单详情 3 个模块接入了业务监控。
登录:登录接入 SGM 监控平台,自定义了整个流程错误码,并配置了告警规则
(1)600:登录正常流程(必要是可白名单开启)
(2)601:登录防刷验证流程异常监控
(3)602:登录魔方验证流程异常监控
(4)603:登录流程异常监控

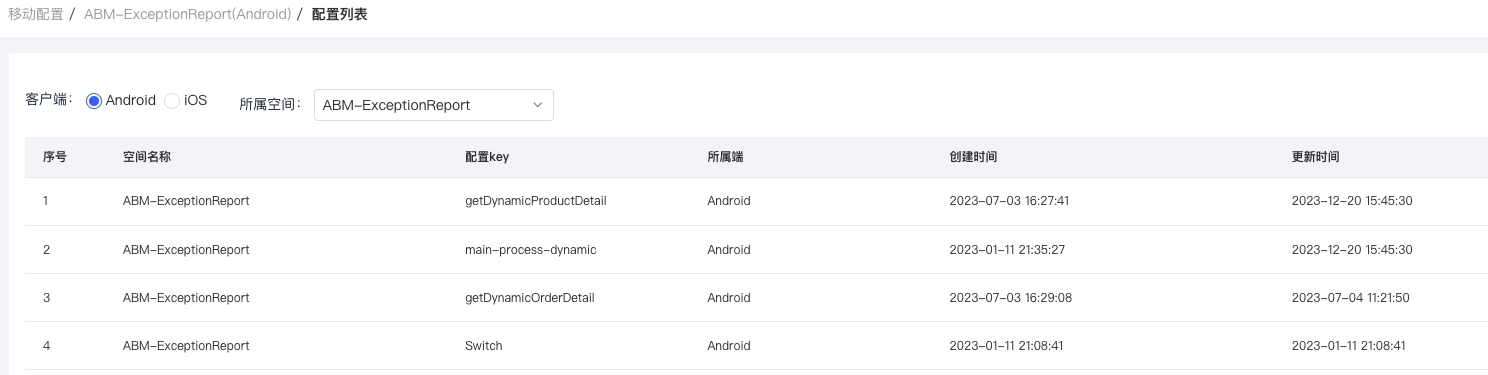
商详、订单详情:在商品详情和订单详情页面,我们集成了业务监控 SDK。通过移动配置平台,我们下发了监控规则,以便在接口返回的数据不符合预期时,能够上报错误信息。目前,这些监控信息被上报到崩溃分析平台的自定义异常模块中,以便进行进一步的分析和优化。
(1)接口请求是否成功。
(2)banner 楼层:是否为空、楼层类型是否正常(1 原生)、数据/大小图地址是否为空。
(3)商品信息楼层:是否为空、楼层类型是否正常(2 动态)、数据/商品名称/价格是否为空。
(4)服务楼层:是否为空、楼层类型是否正常(1 原生)、数据/服务信息是否为空。
(5)spu 和物流楼层:是否为空、楼层类型是否正常(1 原生)、数据/sup信息是否为空。
(6)其他:其他/按钮数据/按钮名称是否为空、按钮类型是否正常(排除1/2/3/4/5/6/20000)。
订单详情监控信息:
(1)接口请求是否成功。
(2)基础信息楼层:是否为空、楼层类型是否正常(2 动态)、数据/地址信息是否为空。
(3)商品信息楼层:是否为空、楼层类型是否正常(2 动态)、数据/商品列表是否为空。
(4)支付信息楼层:是否为空、楼层类型是否正常(2 动态)、数据是否为空。
(5)价格楼层:是否为空、楼层类型是否正常(2 动态)、数据是否为空。
定时巡检
定时巡检可以通过两种方法实现:
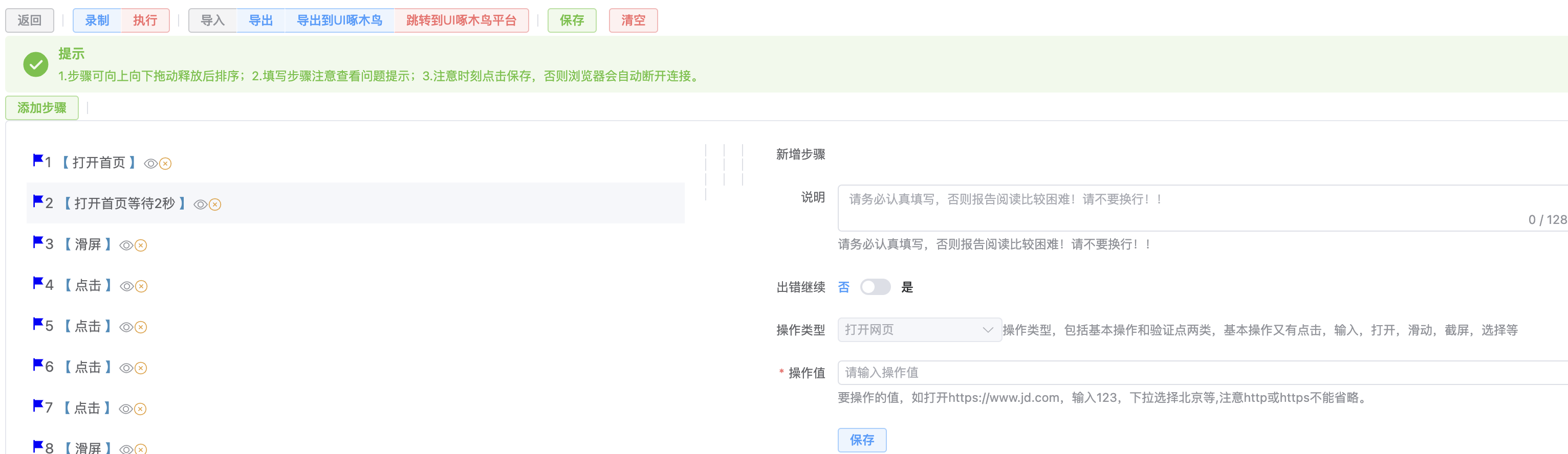
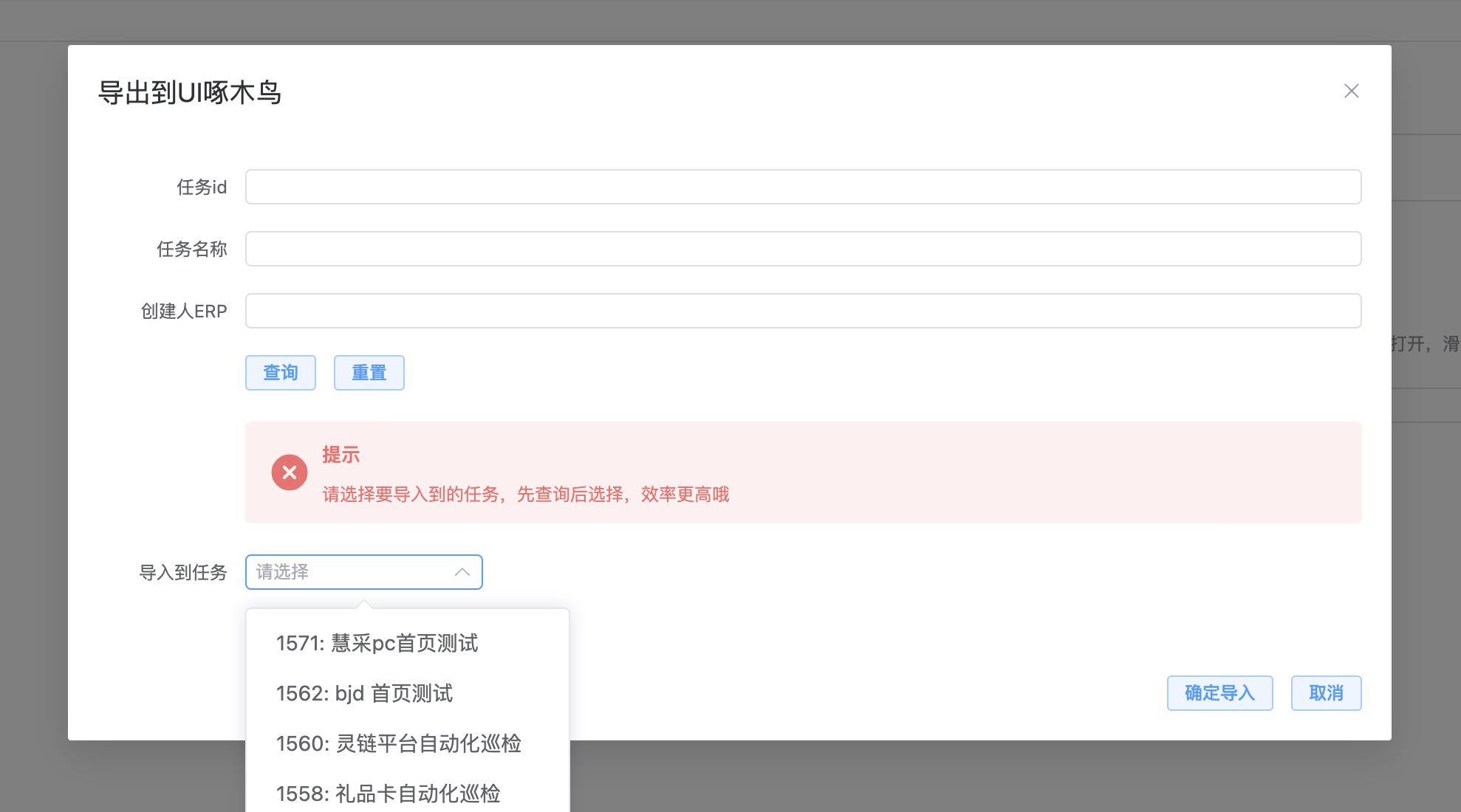
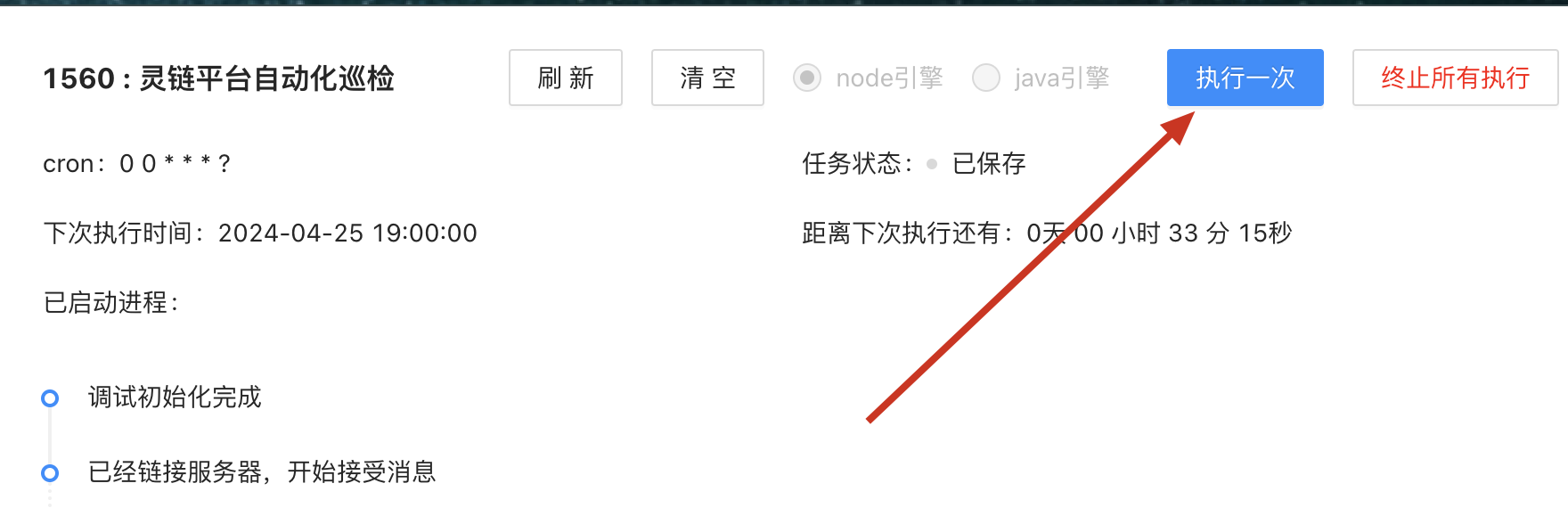
UI 啄木鸟
定时巡检的主要目的是确保每个项目的核心流程在每次迭代中保持稳定。通过配置定时任务,我们能够及时发现并解决线上问题,从而维护系统的稳定性。
什么是 UI 啄木鸟
UI啄木鸟平台,由京东集团-京东科技开发,是一个自动化巡检工具,其主要功能包括:
在使用Chrome插件过程中,我们遇到了一些问题。与京东科技团队沟通后,我们获得了共同开发和升级插件的机会。目前,我们已经添加了新功能并修复了一些已知问题。
使用chrome扩展程序进行安装即可。
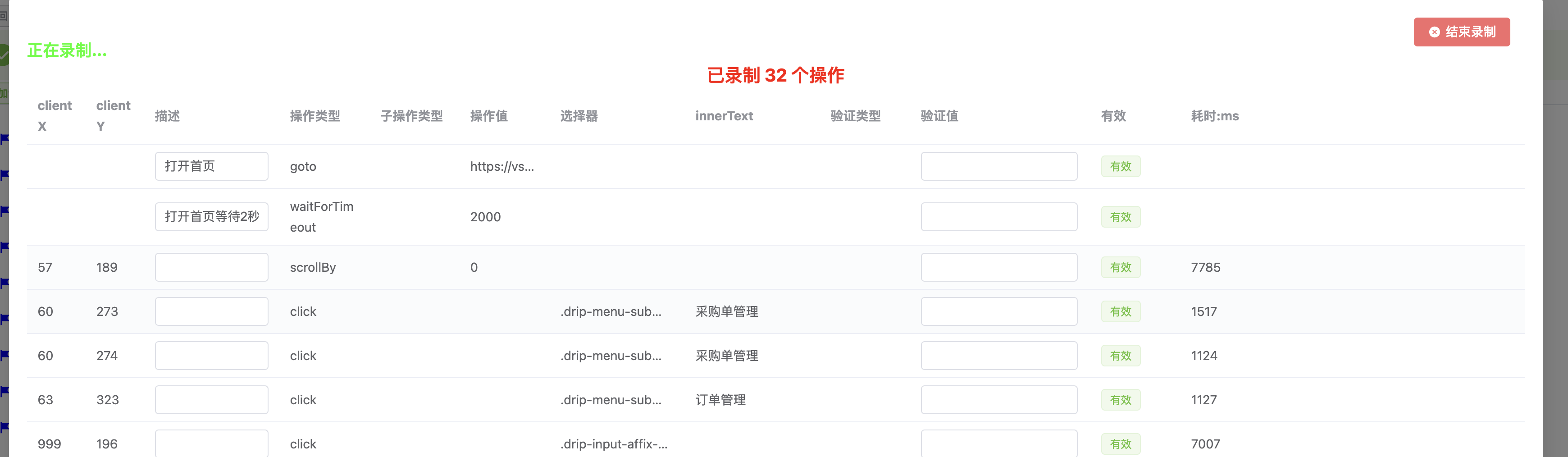
怎么使用

自启动巡检工具
自动化巡检工具能够检测页面上的多种元素和链接,包括 a 标签的外链、接口返回的链接、鼠标悬停元素、点击元素,以及跳转后 URL 的有效性。该工具尤其适合用于频道页,这些页面通常通过投放广告和配置通天塔链接来生成。在大型促销活动期间,我们可以运行脚本来验证广告和通天塔链接的有效性。目前,工具的功能还相对有限,并且对于广告组等特定接口的支持不够通用,这也是我们计划逐步改进和优化的方向。
功能检测