二叉树的递归套路
二叉树结构
二叉树是一个将数据组织成头尾相连的特殊链表,每一个数据单元与链表一样有一个指向其的指针,但与链表不同的是其可以有两个指向其他单元的指针,分别是其左孩子与右孩子。采用该这种结构,最终数据的呈现形式会与“链”不一样,而呈现出了一种树的结构。

对于这种树型结构,每一棵完整的子树都有头节点、左孩子与右孩子。头节点可以从左右孩子分别收集信息并向上传递,给自己的头节点。这就是二叉树递归套路的基本准则,采用这种方式去写递归算法,就可以简单地遍历所有的二叉树节点并收集信息,在整个二叉树地头节点进行汇集。
二叉树的递归套路步骤
以最低祖先点阐述递归套路的具体执行。最低祖先点:给定一颗二叉树中的两个节点,求二者向根节点溯源路径中第一个相同的节点。
步骤1:构建信息类Info
对于一个我们想要解决的实际问题,当前的处理思想是子节点一直向上提交信息,那么这个信息一定就要能推断问题或者解决问题。所以第一个步骤为:假设头节点可以获取左右孩子的所有信息,构建需要解决这个问题的方法类。
问题分析:想要找到二者的最先祖先点,则该点下路径搜索中必须要能找到这两个节点,而由于是最低的公共祖先节点,所以要返回第一个可以在孩子中搜索到二者的节点,那么信息中一定要包含这个返回节点以及是否能找到两个节点的信息,因此有如下定义:
public static class Info {public boolean findA;//是否这条路径有节点Apublic boolean findB;//是否这条路径有节点Bpublic Node ans;//最找在此节点下路径发现节点A,B的节点public Info(boolean fA, boolean fB, Node an) {findA = fA;findB = fB;ans = an;}
}
步骤2:构建自身的信息体
确定好信息类后,我们的递归函数的返回类型就是信息类,因为我们想要左右孩子直接向头节点返回信息类,然后头节点处理这些信息,并结合自己的信息,生成自己的信息体。因此第二个步骤为:头节点从左右孩子获取左右信息体,结合自身信息处理得到本节点的信息体。
Info leftInfo = process(x.left, a, b);
Info rightInfo = process(x.right, a, b);
boolean findA = (x == a) || leftInfo.findA || rightInfo.findA;//此节点的findA为:左孩子下可以找到||右孩子下可以找到A||自己就是A
boolean findB = (x == b) || leftInfo.findB || rightInfo.findB;//此节点的findB为:左孩子下可以找到||右孩子下可以找到B||自己就是B
Node ans = null;
if (leftInfo.ans != null) {ans = leftInfo.ans;
} else if (rightInfo.ans != null) {ans = rightInfo.ans;
} //如果左右孩子中的返回信息中已经设置好了答案节点那么就直接设置为本信息体的答案,否则就在本节点进行一次信息处理,看看本节点是否有答案。
else {if (findA && findB) {ans = x;}
return new Info(findA, findB, ans);//返回本节点的信息体
必须注意本节点收到左右孩子的信息,结合自身信息进行加工处理时必须要考虑所有的情况。
步骤3:边界条件的处理
这是对头节点下探到自己孩子,返回为空的处理,程序的入口是头节点,会一直下探,探到底部的节点,底部的节点此时也会调用:
Info leftInfo = process(x.left, a, b);
Info rightInfo = process(x.right, a, b);
并得到底部节点的空的孩子的返回信息,这时要合理设置底部的返回信息避免其会对后续的信息处理产生干扰,在本例中,信息体以是否找到节点的boolean类型为核心,所以,为了不干扰结果,当本节点为空时,应该立刻返回一个不干扰的信息体:
return new Info(false,false,null);
代码汇总
经历所有的步骤就有了总的代码:
//1.信息体的设置
public static class Info {public boolean findA;public boolean findB;public Node ans;public Info(boolean fA, boolean fB, Node an) {findA = fA;findB = fB;ans = an;}
}
//递归函数,返回类型是信息体类
public static Info process(Node x, Node a, Node b) {//边缘的返回if (x == null) {return new Info(false, false, null);}//得到左右孩子的信息,并结合自身信息,加工出自己的信息体,并向上返回。Info leftInfo = process(x.left, a, b);Info rightInfo = process(x.right, a, b);boolean findA = (x == a) || leftInfo.findA || rightInfo.findA;boolean findB = (x == b) || leftInfo.findB || rightInfo.findB;Node ans = null;if (leftInfo.ans != null) {ans = leftInfo.ans;} else if (rightInfo.ans != null) {ans = rightInfo.ans;} else {if (findA && findB) {ans = x;}}return new Info(findA, findB, ans);
}
对于递归套路的理解
整个递归函数的关键是假设头节点可以从左右孩子获得所有想要的信息,这一步是通过:
Info leftInfo = process(x.left, a, b);
Info rightInfo = process(x.right, a, b);
来实现的,那么在实际的程序运转中,会怎样去进行这个递归方法呢,首先我们知道JAVA实现递归函数是依靠方法栈,Java运行一个程序时,会首先向栈中压入其main函数,然后每当main函数中调用了其他函数则继续在栈中压入其他函数,其他函数产生了调用亦然。对于本方法亦然,所以执行到本方法时,会将该方法以栈帧的形式压入方法栈中。
以程序执行到本函数为起点:
栈中压入本方法f(root),开始执行本程序中传入了二叉树的根节点,首先会经过一个空指针判断,如果为空则直接返回,不为空,则会向本程序中传入根节点的左孩子;再次执行以root.left为当前节点的程序,栈中压入本方法f(root.left),再次经历一个空指针判断,然后继续向本程序中传入当前节点的左孩子;再次执行以root.left.left为当前节点的策划功能,栈中压入方法f(root.left.left)……
这个过程会一直重复,直到f(root.left........leftn)进入程序后在判断环节发现其是空,那么就会直接返回,这样该方法结束,方法栈中弹出该方法,执行f(root.left...leftn-1)方法,此时, Info leftInfo = process(x.left, a, b);已经有了返回值,为new Info(false, false, null),该程序就会进入下一条代码的执行:Info rightInfo = process(x.right, a, b);,由于其也为空,则也会返回new Info(false, false, null),这样底部节点就收到了左右信息,就可以开始处理自身信息并加工自己的信息体返回。
那么当底部节点完成其信息体后,这个节点其实也是其他节点的左节点,它的返回信息会被上层代码接收即f(root.left...leftn-2)中的Info leftInfo = process(x.left, a, b);这样,f(root.left...leftn-2)就可以去执行下一行,去接收其右节点信息,这个过程与刚刚的左节点信息上交也是类似的。
总的来说,程序会按照一个递归序的顺序去遍历所有的节点,然后逐级上交信息, 最终在根节点汇总信息后,返回整棵树的信息。
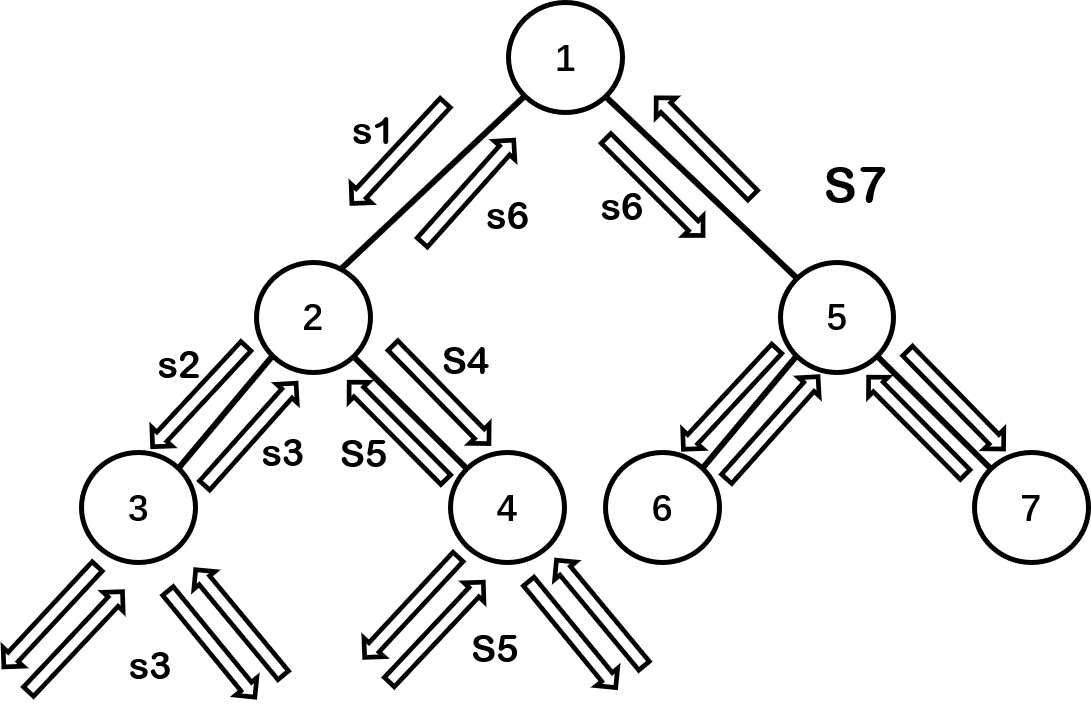
-
f(1)压入栈中,收集左信息,f(2)压入栈中
-
f(2)收集左信息,f(3)压入栈中
-
f(3)将f(3.left)压入栈中,直接返回,将f(3.right)压入栈中,也直接返回,f(3)处理完自身信息,程序结束,方法栈中弹出f(2)。
-
执行f(2)的收集右信息,将f(4)压入栈中
-
f(4)会执行一个跟步骤三一样的过程。并返回作为f(2)的右信息。
-
f(2)已经搜集到了左右信息,处理完信息后,返回信息给f(1)中的收集左信息环节,进入f(1)的收集右信息环节。
-
首先以f(5)为f(1)右信息的返回,压入f(5)。f(5)以f(6)为其左信息。f(6)执行结束,压入f(7)作为f(5)右信息的返回,f(7执行结束,处理f(5)信息,f(1)中得到右信息,最终返回f(1)信息,得到整棵树的信息。
![[rCore学习笔记 023]任务切换](https://img2024.cnblogs.com/blog/3071041/202408/3071041-20240808120408027-1741591752.png)