一、京东小程序是什么
京东小程序平台能够提供开放、安全的产品,成为品牌开发者链接京东内部核心产品的桥梁,致力于服务每一个信任我们的外部开发者,为不同开发能力的品牌商家提供合适的服务和产品,让技术开放成为品牌的新机会。“Once Build, Run Anywhere”,一个小程序可以在多个APP运行,引擎层抹平差异,一套代码,相同页面,云端下发,多端运行。
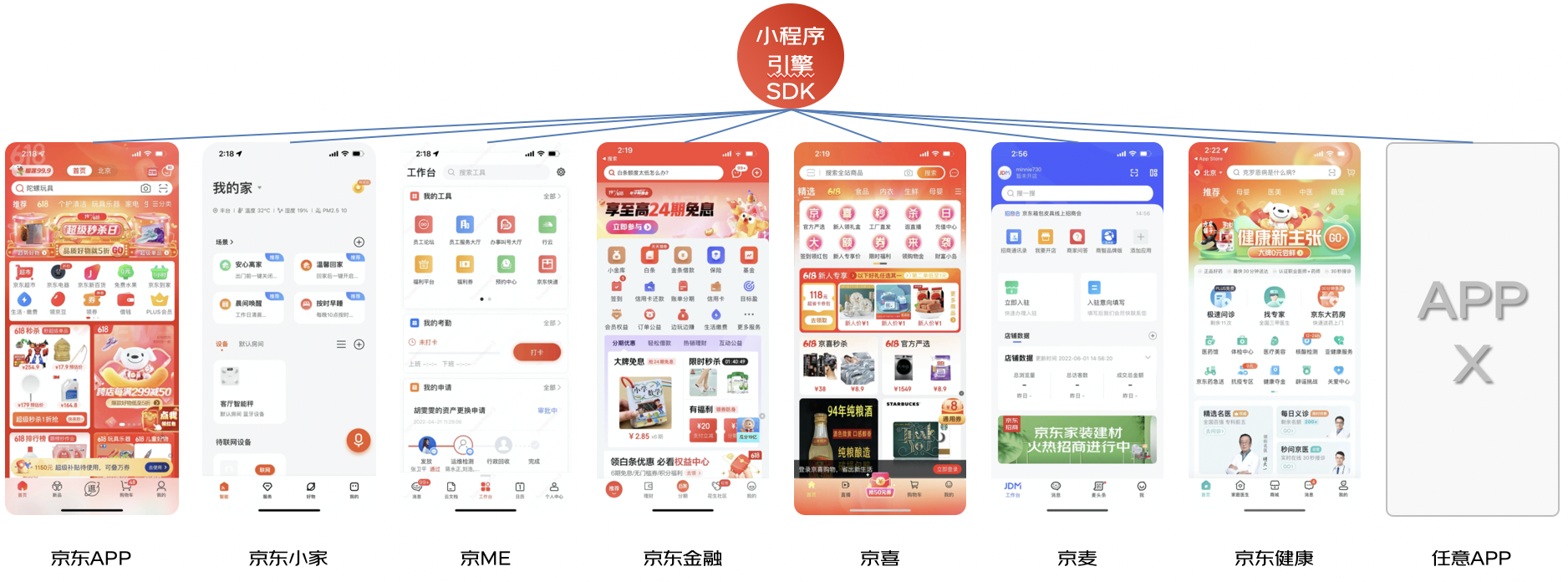
可能大家还不太了解我们的京东小程序,京东小程序到底是什么呢?它和微信小程序有什么区别?首先呢,需要明确的是,京东小程序不是运行在微信端的京东商城购物小程序,而是运行在京东APP的,基于京东小程序引擎的一套京东系的小程序。
它是和支付宝小程序或者微信小程序对标的一类京东化的小程序。
举个例子,大家可以体验一下,比如在主站搜索宝格丽,会通过搜索直达直接跳转到宝格丽小程序上,我们可以在这里购买奢侈品,或者在首页的同城Tab页下,可以浏览到非常多的到家门店类的小程序,总之,京东小程序所覆盖的业务还是极其广泛的!
当然,京东小程序不仅仅可以运行在京东APP上,只要宿主在运行时依赖了我们的小程序SDK引擎,就可以实现在各类其他宿主APP上的运行,譬如,在京东小家APP上,可以通过小程序去控制智能IOT设备,在京ME的APP上,可以远程操作打印机,实现一键打印。小程序作为一种轻量级的即用即走的工具,用户群体广泛,早已覆盖到了我们生活的方方面面。
京东小程序是链接商家和京东内部核心产品的重要桥梁,也是助力商家实现流量增长、业务发展的一个重要方式。
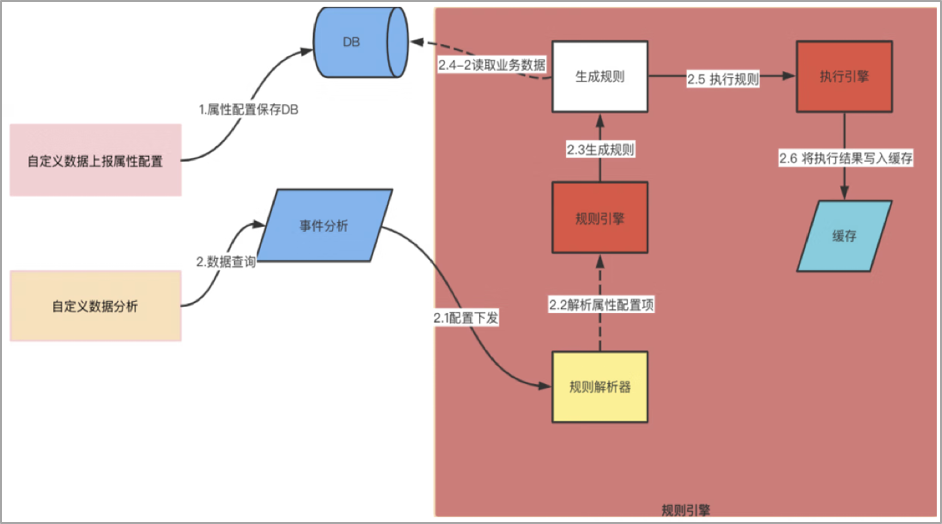
那么,小程序平台是怎么保证商家业务的稳定、健康发展,服务好这些外部商家的呢?这里面非常重要的是我们平台对小程序基本流量的运营与监控。如何不让业务的小程序在线上裸奔?如何帮助业务对自身小程序流量的冲高回落有一种直观的把握和监测?如何基于海量数据指导业务去进行一个精细化的运营?实际上,京东小程序数据中心就扮演了一个这样的小程序数据问题终结者的角色,充分利用各类数据手段,解决这些痛点问题。
二、京东小程序数据中心建设里程碑
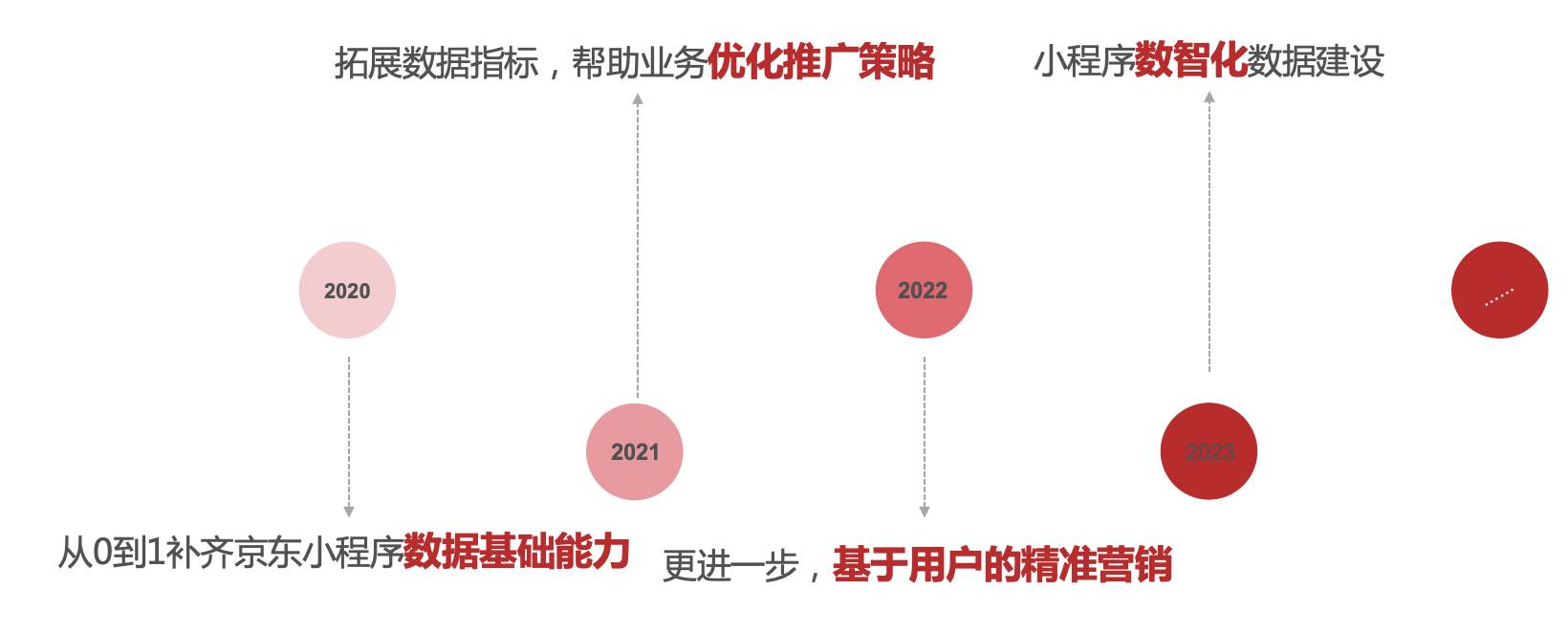
京东小程序数据中心的建设,主要经历了四个阶段,从最开始的由0到1搭建了数据基础能力,到丰富拓展各类数据指标,接着下钻分析到用户,帮助商家实现基于用户的精细化的运营,到目前的小程序数智化建设,在整个小程序的迭代建设的过程中,都从各个维度为小程序的业务发展实现了保驾护航。
三、京东小程序数据中心业务全景图
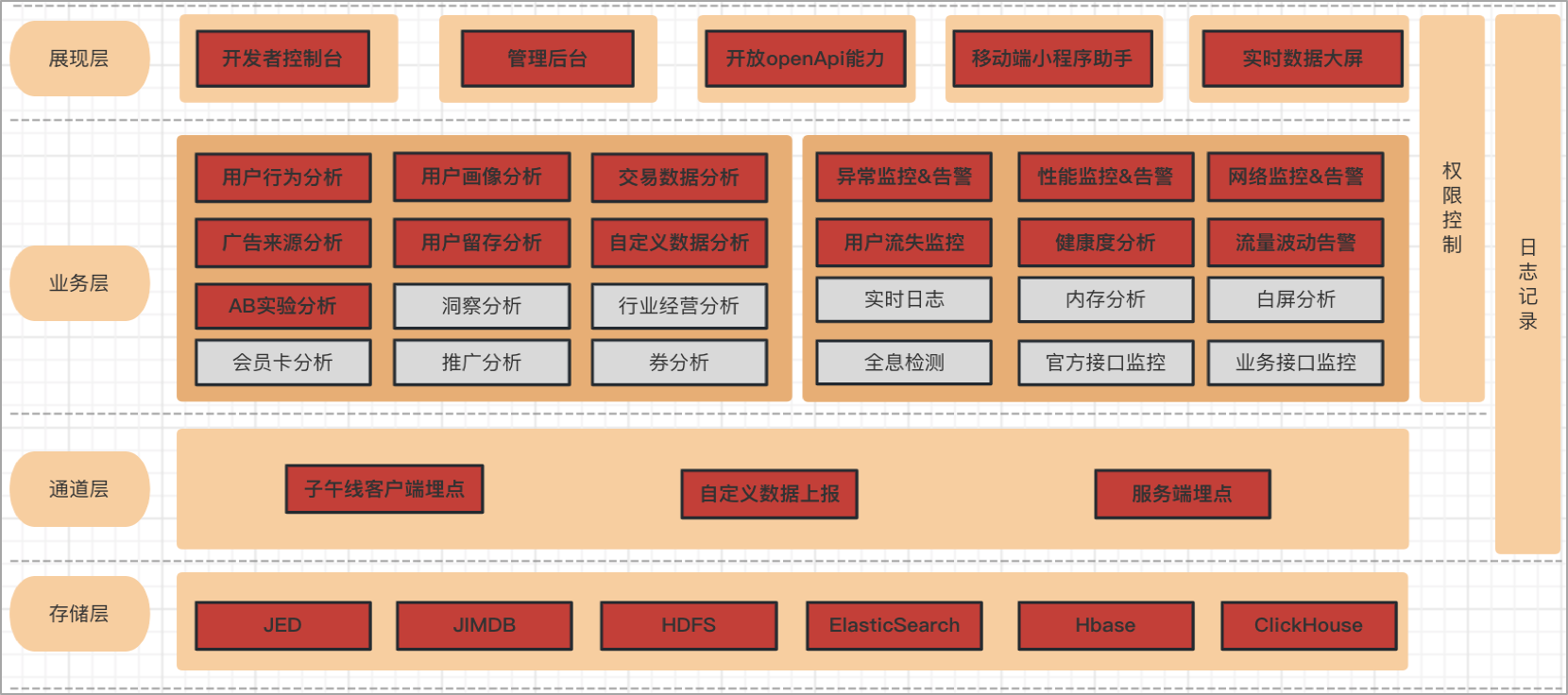
•从功能角度,京东小程序运营数据分析,京东小程序监控数据分析;
•从展现角度,开发者控制台,管理后台,移动端小程序助手,宙斯开放能力;
•从功能领域角度,用户行为分析,交易链路数据分析,用户画像,流失率监控,流量监控等;
•从上报通道角度,子午线,自定义上报,服务端埋点;
•从数据存储角度,JED,JimDB,ES,HBase等;
目前京东小程序数据中心功能范围广泛,我们在根据业务发展的需求,不断完善整个京东小程序数据中心的功能架构。
从展现角度看,包括开发者控制台,管理后台,移动端小程序助手,实时数据大屏, 开放openApi能力;
其次是从功能领域角度看,主要包括运营数据分析,监控数据分析。
运营数据分析,包括用户行为分析,比如小程序基础的pv和uv;
来源分析,可以去分析小程序在各个广告投放渠道下的营销转化效果;
用户画像分析,可以分析到浏览过小程序的人群中的哪些是高净值用户群体,以及性别以及年龄等基础的用户画像数据。
监控数据分析,主要是针对线上运行的小程序的奔溃异常,网络请求异常,启动性能数据的分析,用户流失率的实时监测等,可以在小程序出现异常时第一时间通知到开发者。
四、京东小程序数据中心技术架构图
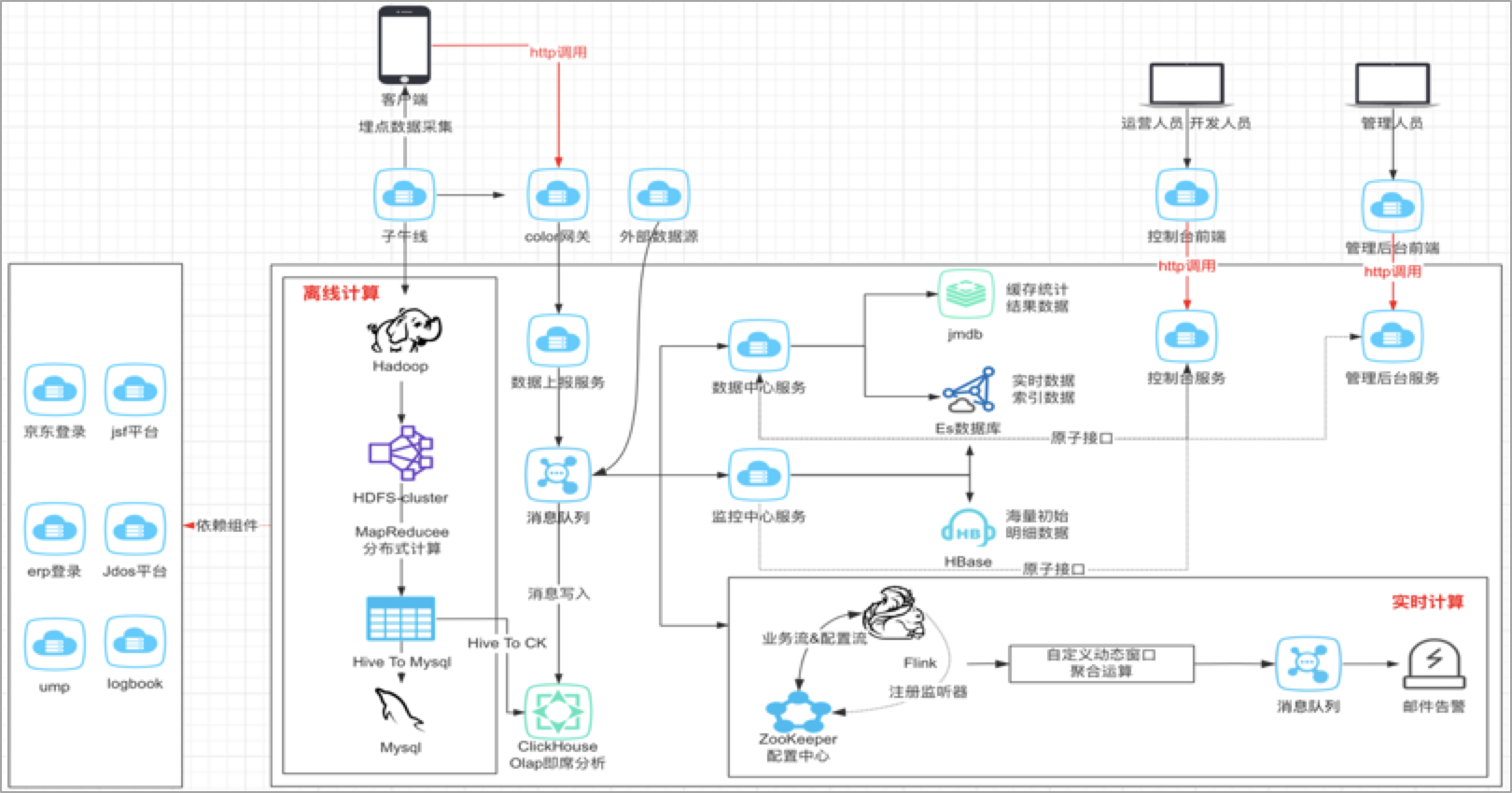
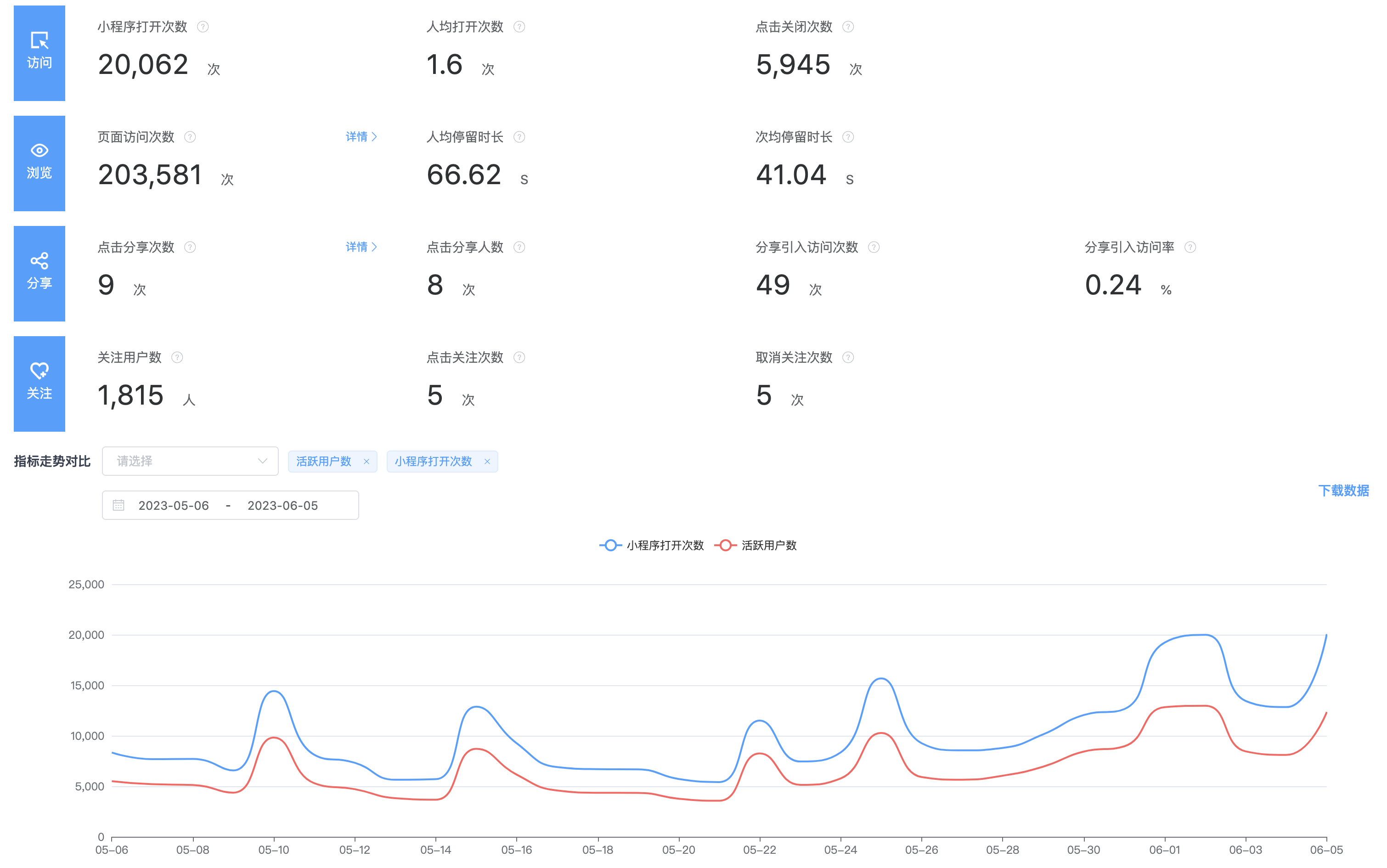
对于整体的架构设计,其实在我看来,数据的分析,主要是解决三个问题,第一个要解决的是数据如何上报的问题,第二个是解决数据如何存储的问题?第三个才是解决数据如何分析的问题?
1、京东小程序数据中心的数据上报主要包括三个途径,主要包括客户端埋点,服务端埋点或者其他外部的数据源,客户端埋点主要利用的是子午线,服务端埋点主要是我们服务之间采集数据,服务之间消费和同步。
2、数据存到哪里去,这个需要基于我们业务上对这些数据的实时性要求,判断是实时还是离线,进而采用不同的数据源进行存储,数据指标是要秒级的?分钟级的?还是T+1l类型的,实时性要求不同,那么存储的数据源自然也就不同。
3、数据如何分析,实际上就是我们的业务逻辑,在设计时也需要充分考虑数据模型的复用性和可拓展性。
小程序数据中心对于来自子午线客户端埋点数据,以离线的方式构建小程序自己的业务数仓,一层一层地进行数据的降噪,清洗和计算,将聚合好的维度数据再推送到关系型数据库,方便业务快速接入。对于来自自建通道的实时数据以及外部系统的埋点数据,通过统一上报服务将数据上报到消息队列,进行流量数据的异步处理和消峰,采用专门的消费者服务对上报数据进行消费落库,存储到ES和HBase数据库,便于平台进行多维度的明细或者汇总数据查询;同时,也会基于Flink对消息队列中的数据进行流式实时计算,实现异常波动流量的告警和分析。
五、它山之石可以攻玉,借助集团数据工具打造小程序业务数仓
痛点问题:
1.京东小程序的数据来源多样化,数据量级庞大,如何立足业务数据,发挥数据价值,帮助商家实现精细化的运营?
2.如何复用主站已有的数据模型和能力,让更多的小程序商家参与到京东主站的流量场,让数据驱动商家精准营销?
3.业务指标纷繁复杂,如何沉淀和抽离通用数据模型,减少重复工作?
如何解决:
基于集团BDP平台,自上而下构建京东小程序的业务数仓,借助BDP平台丰富的数据产品工具,多维度地构建小程序的数据能力。离线计算+实时计算相结合,小程序业务数据+集团模型数据相结合。
1.数据分类化,将小程序流量进行主题划分,拆分为点击、浏览、曝光、订单等大维度的主题模型,方便数据定位,增加业务理解;
2.数据分层化,同一个流量主题下,进一步按照ODS->DWD->DWS->ADS的层级结构进行分层,方便追踪数据血缘,减少重复数据模型的开发;
3.数据多元化,下游系统可从小程序数据仓库拉取符合业务需要的领域数据,比如数纺,搜推广等系统,利用下游系统成熟稳定的数据能力,为商家营销充分赋能;
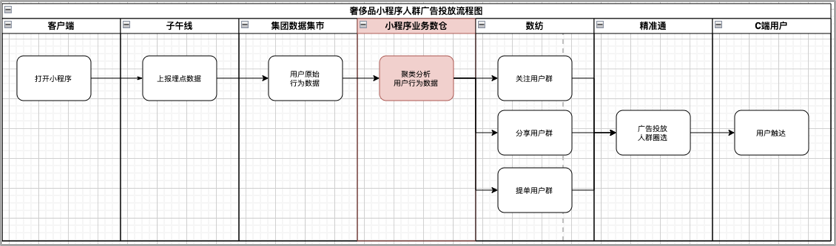
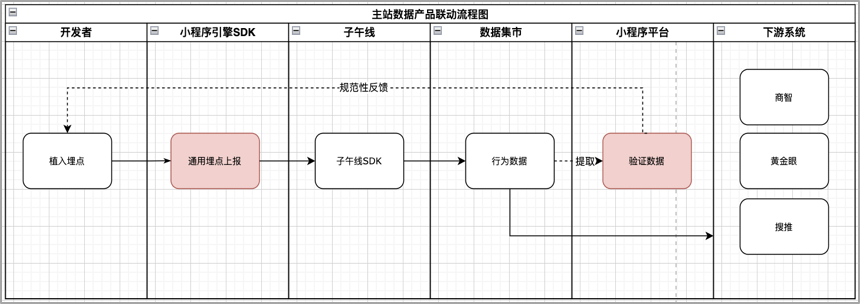
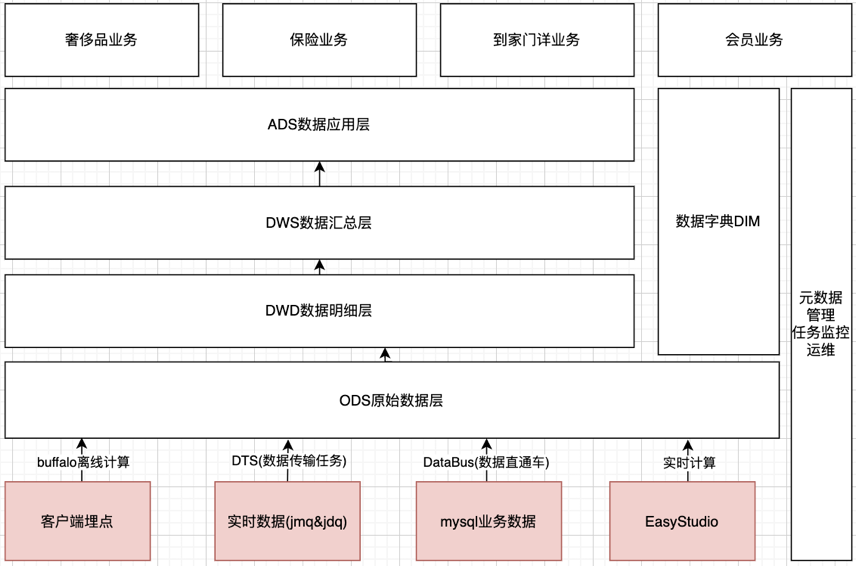
在京东小程序的业务数仓搭建过程中,主要还是应用了集团BDP大数据平台提供的丰富的产品工具和通用能力。
几种典型的使用案例是:
1、离线hive表数据同步到jed等关系型业务库,使用buffalo任务中的出库算子;
2、业务产生的实时MQ数据同步到hive数仓,使用DTS,实时数据传输任务,可以把业务数据同步到数仓;
3、我们需要在数仓中构建业务维表,比如构建小程序基本信息的维表,业务数据需要同步到hive表,可以采用数据直通车DataBus,在表记录的生成上,可以根据业务的需要,采用全量表,增量表,快照表,拉链表或者流水表的不同的记录生成方式。
京东小程序客户端埋点统一上报的子午线,需要从最原始的gdm层底表提取小程序自己的业务数据,原始底表数据量级非常大,不可能每次直接对原始底表查询,这样的话耗费计算资源,效率较低。所以,我们尽量提高底层数据模型的复用度,对数据进行分类化和分层化处理。
所谓分类话,就是将小程序流量进行主题划分,拆分为点击、浏览、曝光、订单等大维度的主题模型,方便数据定位,增加业务理解;
所谓分层化,就是在同一个流量主题下,进一步按照ODS->DWD->DWS->ADS的层级结构进行数据分层,方便追踪数据血缘,减少重复数据模型的开发。
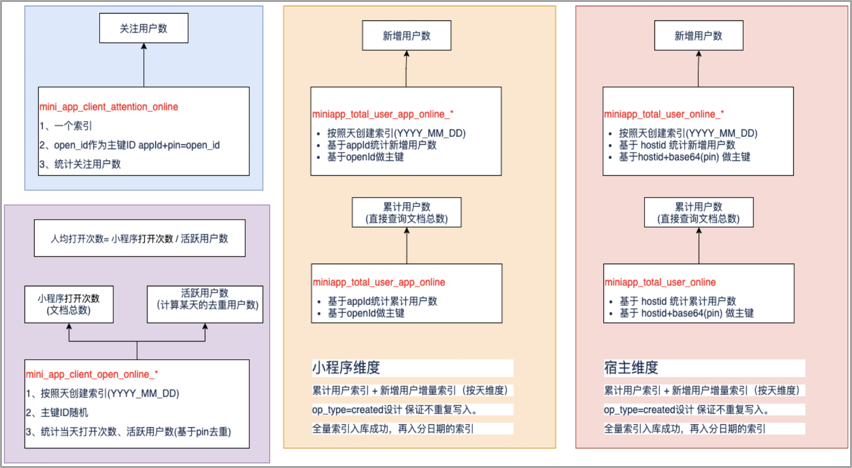
所谓多元化,就是复用度,加工好的这些数据,可以给下游的团队接入使用,比如商智,黄金眼,数纺这些团队。以小程序广告投放为例,在小程序数仓中我们构建了各个类型的用户群体,在数纺注册了用户群体标签,比如关注用户,粉丝用户或者提单用户等,下游的广告精准通系统会基于我们的这些标签进行人群的圈选,进而实现小程序广告的投放。
总之,根据业务特点,充分利用好集团BDP的数据工具,帮助我们实现数仓的搭建。
六、基于FLINK实时计算,落地小程序异常奔溃监控利器
痛点问题:京东小程序在线上运行时,需要实时监测到小程序的业务代码崩溃异常、性能数据波动,网络请求耗时等,在有异常崩溃的情况下,保证可以第一时间通知到商家开发者,帮助业务及时止损。
如何解决:
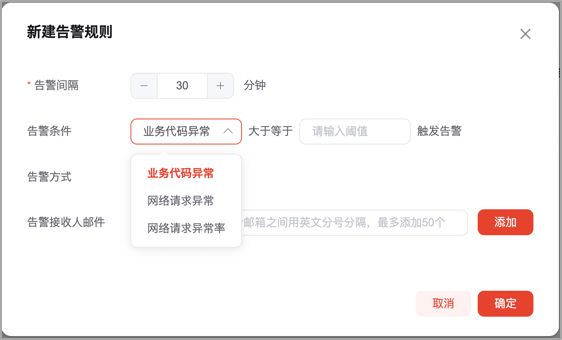
1.报警规则可配置,基于Zookeeper分布式配置中心存储小程序自定义的告警规则,实时监听规则节点变化,当节点数据变化时,实时聚合到业务流;
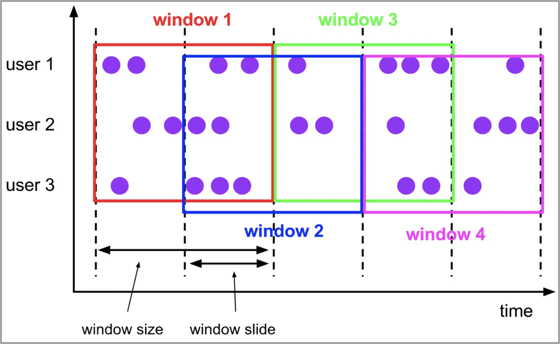
2.自定义滑动窗口,每个小程序的告警窗口大小不一样,拓展实现WindowAssigner,基于用户动态规则确定告警窗口开始时间和截止时间;
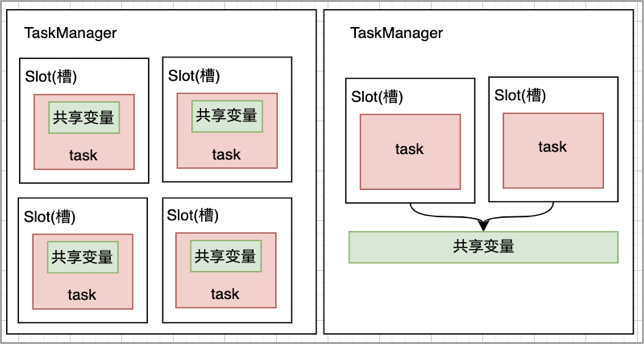
3.广播变量,broadcast机制,将告警配置信息广播到各个Task任务内存,广播变量就是一个公共的共享变量,将一个数据集广播后,不同的Task都可以在节点上获取到,每个节点只存一份,否则,每一个Task都会拷贝一份数据集,会造成内存资源浪费。
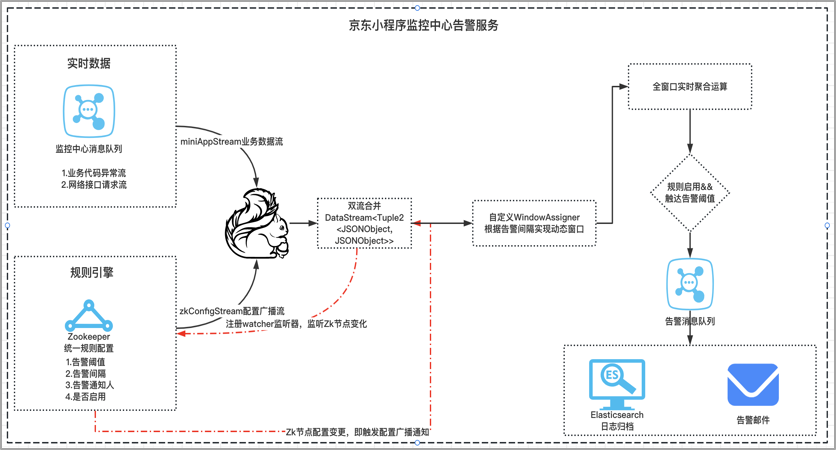
对于小程序的实时监控能力,我们采用flink作为实时计算的框架,小程序在线上运行时,需要实时监测到小程序的业务代码崩溃异常、这种异常很可能会导致小程序白屏或者闪退,需要在探测到有异常崩溃的情况下,保证第一时间通知到商家开发者,帮助业务及时止损。
这里的难点在于告警的规则是支持用户自定义的,比如配置观测多长时间窗口内的异常数据,当达到多少的异常阈值,应该去触发告警,应该判定为异常,这里是需要把告警规则配置的的主动权交给用户的,在这样的背景下,
1、 我们采用的是将告警规则放到分布式的统一配置中心,实时监听节点规则的变化,将业务流和规则流进行connet双流合并;
2、 然后根据告警规则,实现windowAssigner生成自定义的动态计算窗口,从而实现窗口动态化;
3、 最后,采用广播变量的broadcast机制,当告警规则变更时,可以高效地将告警配置广播刷新到各个Task任务内存,提高资源利用率,保证计算时效性。
七、探索OLAP领域的黑马,基于ClickHouse搭建自定义数据分析引擎
痛点问题:小程序内部的数据波动如何自由埋点分析?京东内部业务直接基于子午线埋点上报,业务团队内部自行分析;外部的开发者需要依赖神策,GA等外部的分析系统,无法将数据回流京东,且复用京东现有流量工具进行精细化运营。
如何解决:
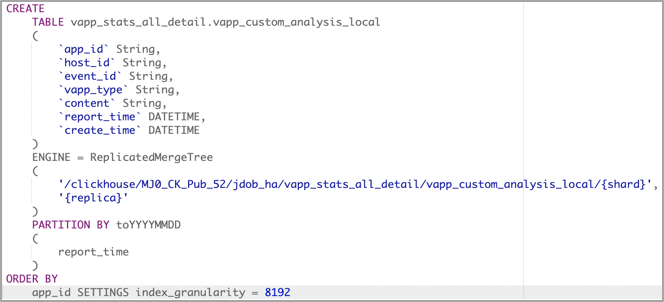
1.选择合适的表存储引擎:采用多副本的ReplicatedMergeTree,保证查询性能和数据存储的高可用;
2.按天分区存储数据: PARTITION BY:分区键,PARTITION BY toYYYYMMDD(EventDate),不同分区下的数据会分开存储,合理建立分区可以加快查询的速度;
3.统一上报协议:生成全局唯一事件ID,事件ID绑定业务数据;
4.动态数据解析:基于visitParamExtract函数解析json动态业务数据;
5.查询脚本下推:Sql引擎生成查询Sql,下沉至ClickHouse完成查询;
小程序内部的数据波动如何自由埋点分析?京东内部业务是可以直接基于子午线埋点上报,业务团队内部自行分析,但是子午线这种产品本身不对外开放,外部的开发者如果想分析小程序自身的内部数据,需要依赖神策,GA等外部的数据分析系统,这样的话,小程序的数据无法回流京东,那么也就无法复用京东现有流量工具进行小程序的精细化运营。
在这样的背景下,我们落地了小程序的自定义分析引擎,底层采用了clickhouse这种适合做即席查询的olap引擎,用来存储小程序上报数据.
为什么采用clickhouse? clickhouse是基于列式来存储数据,查询性能非常高,在亿级数据的体量下,可以做到秒级的响应,适合做在线的OLAP。
同时,ck支持水平的拓展,适合大数据量的存储,支持按天进行数据的分区存储,在建表时,根据记录的创建时间划分partition,在查询数据时,可以只查某些partition分区的数据,也可以加快查询的效率。
包括本地表和分布式表,本地表运行在各个具体的数据节点,分布式表负责数据的转发和路由。写入数据只写本地表,50-200M/S ,对于大量的数据更新非常实用。
在小程序自定义分析引擎中,规范了数据上报协议,首先由用户配置需要上报的事件ID和业务指标,按照协议约定调用前端jsAPI上报业务数据。在自助查询区域,当用户触发查询时,先基于规则引擎利用自定义事件ID生成查询规则SQL脚本,将规则下推至服务端执行引擎,执行引擎从CK获取业务数据,完成业务数据的一次自定义查询。
八、巧用Elasticsearch特性,让用户行为分析不再困难
痛点问题:需要实时分析小程序的pv、uv、新增用户数、累计用户数以及关注用户数等用户行为类指标,帮助小程序商家掌握自身小程序的用户波动情况。
如何解决:
1.实时性,从小程序的用户行为埋点数据上报到可访问,支持秒级响应;
2.全文检索,基于倒排索引,支持灵活的搜索分析,支持按照小程序不同业务维度进行聚合分析,满足不同的业务需要;
3.易于运维,小程序的日均DAU在300W+,可以基于天、月等维度创建索引,方便进行冷热数据分析;
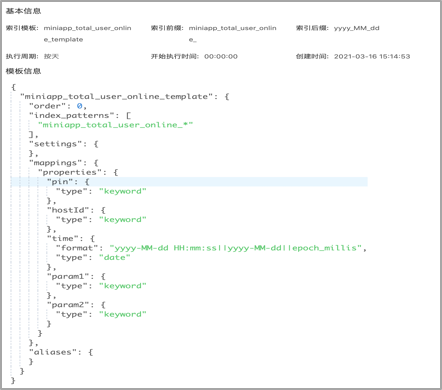
创建ES模板: 周期性按天创建ES索引:

利用索引主键碰撞实现新增&累计用户统计:
语法:
index语法: PUT miniapps/_doc/1
create语法: PUT miniapps/_create/1
语义:
index自动生成id,多次创建,会生成多个document;
index多次索引同一个id,会删除重建,版本号一直++,上个版本删除,保留最新版本;
create自动生成id,多次创建,会生成多个document;
create的重复创建指定文档id的内容,第二次执行创建会报错(主键碰撞),而不是版本号++;
我们是如何做小程序的实时用户行为分析的呢?行为分析需要实时计算小程序的pv、uv、新增用户数、累计用户数以及关注用户数等用户行为类指标,帮助小程序商家掌握自身小程序的用户波动情况。我们将这些数据统一放在ES中进行查询,主要考虑到ES支持灵活的搜索分析,支持按照不同维度进行聚合分析,保证了数据查询的灵活性和实时性的需要。
在创建索引时,不是将数据都堆放到一个索引,而是将按天去创建,基于索引模板,周期性地创建ES索引,保证索引查询效率。
在构建小程序的新增用户的指标时,利用了ES索引碰撞的原理,设置操作类型operateType为create,create的语义是重复创建指定文档id的内容,第二次执行创建会报错(出现主键碰撞),这样的话,保证新增用户的记录在ES索引中只出现一次。
九、不足和展望
1、沉淀小程序行业数据解决方案
沉淀比如车企、保险、3C家电等行业类数据,形成统一的京东小程序行业数据解决方案
2、技术沉淀复用
后续可以把成型的京东小程序数据分析技术方案推广到其他技术栈,比如RN等平台系统
3、智能化建设
考虑如何基于机器学习、人工智能、ChatGPT等技术手段,加强京东小程序数据的智能化建设,如何结合机器学习、深度学习、人工智能AI等技术手段,继续实现京东小程序数据中心的智能化建设。
小程序的智能告警,基于时间序列预测算法,比如Facebook Prophet算法等,做一些告警预判,提升告警的智能性和准确率;
在小程序的预下载场景,可以基于协同过滤算法,做小程序偏好人群的判断,实现预下载的千人千面,从而减少网络带宽,节省资源成本等;
如何将ChatGpt这种AI智能模型,可以分析和理解大量的数据,自动提取和归类数据,使得小程序数据运维更加高效、准确;







![[rCore学习笔记 023]任务切换](https://img2024.cnblogs.com/blog/3071041/202408/3071041-20240808120408027-1741591752.png)

