1、什么是深度学习
1.1、机器学习

图1:计算机有效工作的常用方法:程序员编写规则(程序),计算机遵循这些规则将输入数据转换为适当的答案。这一方法被称为符号主义人工智能,适合用来解决定义明确的逻辑问题,比如早期的PC小游戏:五子棋等,但是像图像分类、语音识别或自然语言翻译等更复杂、更模糊的任务,难以给出明确的规则。
图2:机器学习把这个过程反了过来:机器读取输入数据和相应的答案,然后找出应有的规则。机器学习系统是训练出来的,而不是明确的用程序编写出来。举个例子,如果你想为度假照片添加标签,并希望将这项任务自动化,那么你可以将许多人工打好标签的照片输人机器学习系统,系统将学会把特定照片与特定标签联系在一起的统计规则。
定义:机器学习就是在预定义的可能性空间中,利用反馈信号的指引,在输入数据中寻找有用的表示和规则。
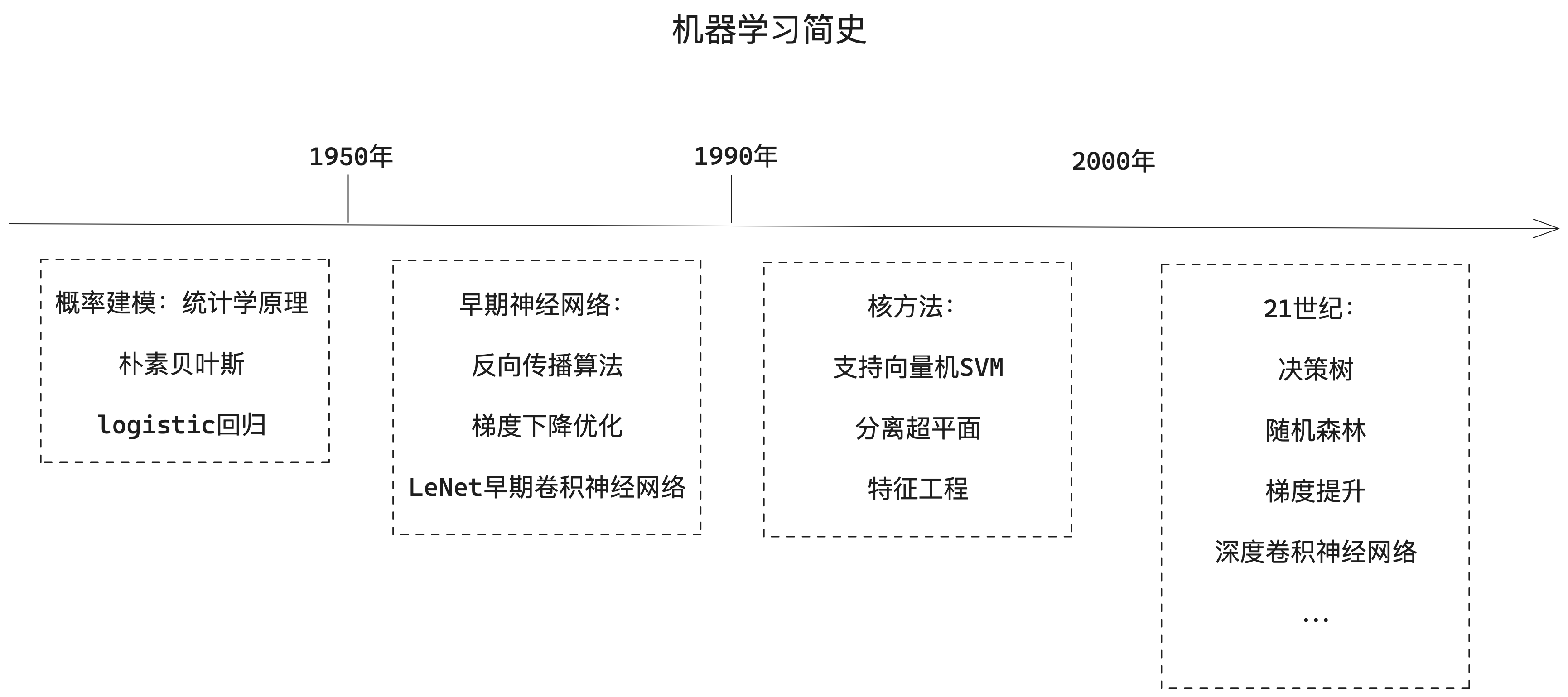
1.2、深度学习
深度学习是机器学习的一个分支领域,强调从一系列连续的表示层中学习。现代的深度学习模型通常包含数十个甚至上百个连续的表示层,它们都是从训练数据中自动学习而来。与之对应,机器学习有时也被称为浅层学习。
在深度学习中,这些分层表示是通过叫作神经网络的模型学习得到的。深度神经网络可以看作多级信息蒸馏过程:信息穿过连续的过滤器,其纯度越来越高。
技术定义:一种多层的学习数据表示的方法。
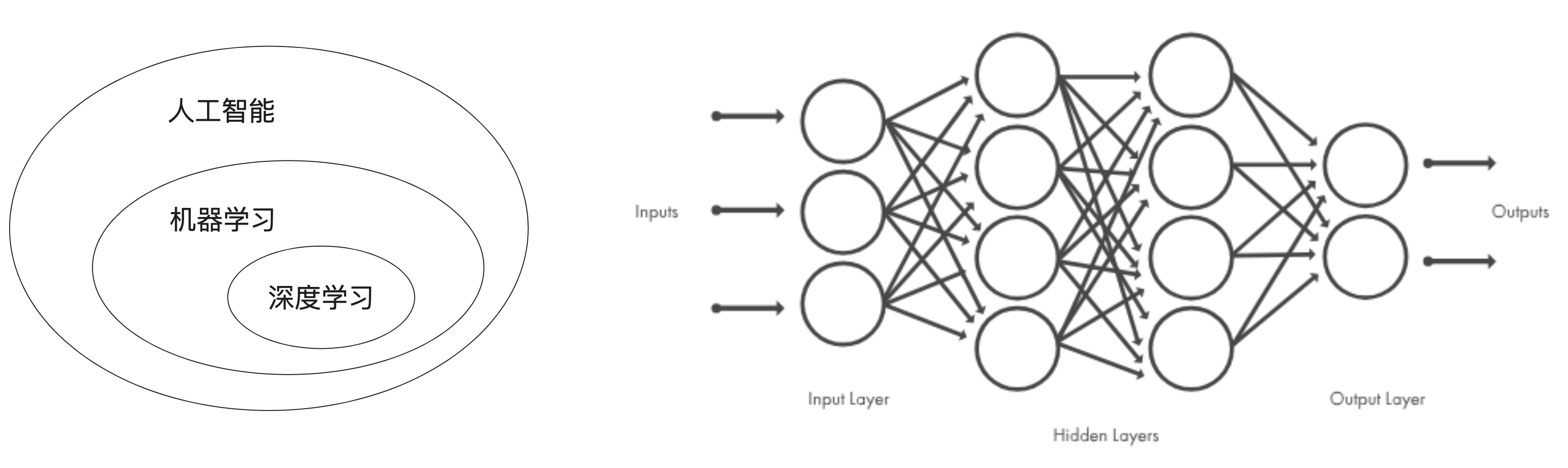
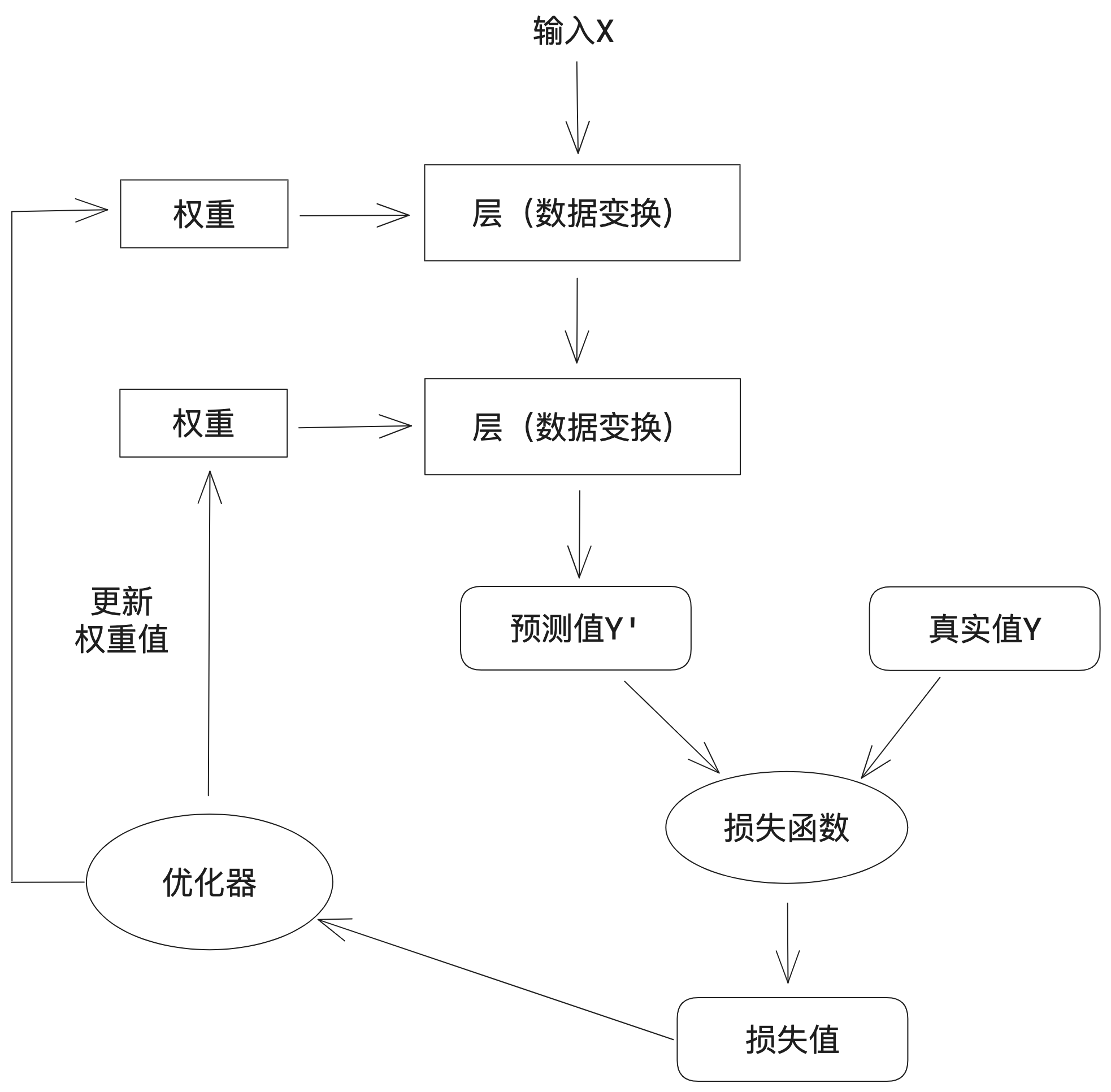
1.3、深度学习工作原理
a. 对神经网络的权重(有时也被称为该层的参数)进行随机赋值
b. 经过一系列随机变换,得到预测值Y'
c. 通过损失函数(有时也被称为目标函数或代价函数),得到预测值Y'与真实值Y之间的损失值
d. 将损失值作为反馈信号,通过优化器来对权重值进行微调,以降低当前示例对应的损失值
e. 循环重复足够做的次数(b-d),得到具有最小损失值的神经网络,就是一个训练好的神经网络
2、神经网络数学基础
2.1、神经网络的数据表示
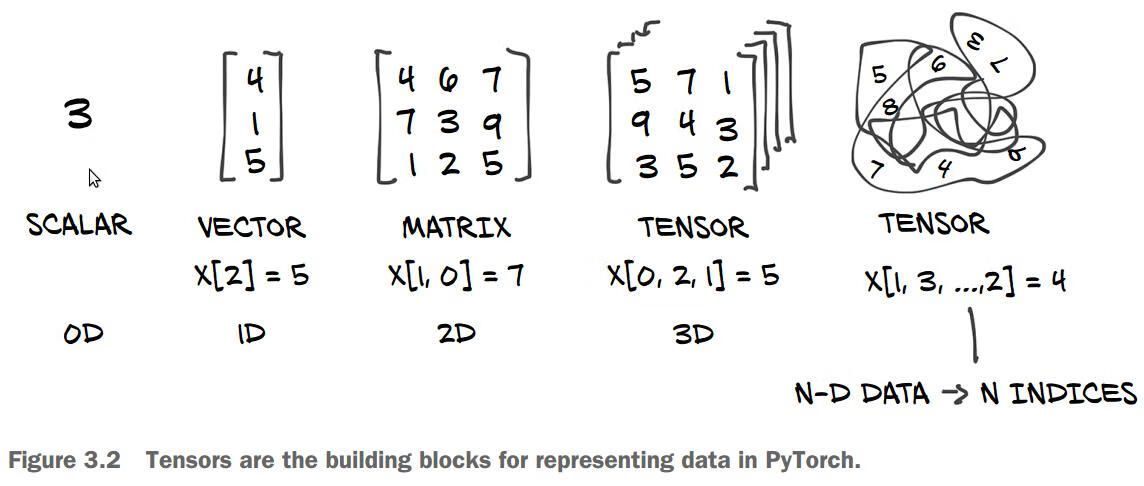
目前所有机器学习系统都使用张量(tensor)作为基本数据结构,张量对这个领域非常重要,TensorFlow就是以它来命名。
张量这一概念的核心在于,它是一个数据容器。它包含的数据通常是数值数据,因此它是一个数字容器。你可能对矩阵很熟悉,它是2阶张量。张量是矩阵向任意维度的推广,张量的维度通常叫做轴。
张量是由以下3个关键属性来定义的。
2.1.1、标量(0阶张量)
仅包含一个数字的张量叫做标量(SCALAR),也叫0阶张量或0维张量。
下面是一个NumPy标量
import numpy as np
x = np.array(3)
x.ndim // 轴:0, 形状:()2.1.2、向量(1阶张量)
数字组成的数组叫做向量(VECTOR),也叫1阶张量或1维张量。
下面是一个NumPy向量
x = np.array([4, 1, 5])
x.ndim // 轴:1, 形状:(3,)这个向量包含3个元素,所以也叫3维向量。不要把3维向量和3维张量混为一谈,3维向量只有一个轴,沿着这个轴有3个维度。
2.1.3、矩阵(2阶张量)
向量组成的数组叫做矩阵(MATRIX),也2阶张量或2维张量。矩阵有2个轴:行和列。
下面是一个NumPy矩阵
x = np.array([[4, 6, 7],[7, 3, 9],[1, 2, 5]
])
x.ndim // 轴:2, 形状:(3, 3)现实世界中的向量实例:
向量数据:形状为(samples, features)的2阶张量,每个样本都是一个数值(特征)向量,向量数据库存储的基本单位。
2.1.4、3阶张量与更高阶的张量
将多个矩阵打包成一个新的数组,就可以得到一个3阶张量(或3维张量)
下面是一个3阶NumPy张量
x = np.array([[[4, 6, 7],[7, 3, 9],[1, 2, 5]],[[5, 7, 1],[9, 4, 3],[3, 5, 2]]
])
x.ndim // 轴:3, 形状:(2, 3, 3)将多个3阶张量打包成一个数组,就可以创建一个4阶张量。
现实世界中的实例:
时间序列数据或序列数据:形状为(samples, timesteps, features)的3阶张量,每个样本都是特征向量组成的序列(序列长度为timesteps)
图像数据:形状为(samples, height, width, channels)的4阶张量,每个样本都是一个二维像素网格,每个像素则由一个“通道”(channel)向量表示。
视频数据:形状为(samples, frames, height, width, channels)的5阶张量,每个样本都是由图像组成的序列(序列长度为frames)。
2.2、神经网络的“齿轮”:张量运算
所有计算机程序最终都可以简化为对二进制输入的一些二进制运算,与此类似,深度神经网络学到的所有变换也都可以简化为对数值数据张量的一些张量运算或张量函数。
2.2.1、逐元素运算
逐元素运算,即该运算分别应用于张量的每个元素。参与运算的张量的形状必须相同。
import numpy as np
z = x + y // 逐元素加法
z = x - y // 逐元素加法
z = x * y // 逐元素乘积
z = x / y // 逐元素除法
z = np.maximum(z, 0.) //逐元素relu,大于0输出等于输入,小于0则输出为0rule运算是一种常用的激活函数,rule(x)就是max(x, 0):如果输入x大于0,则输出等于输入值;如果输入x小于等于0,则输出为0。
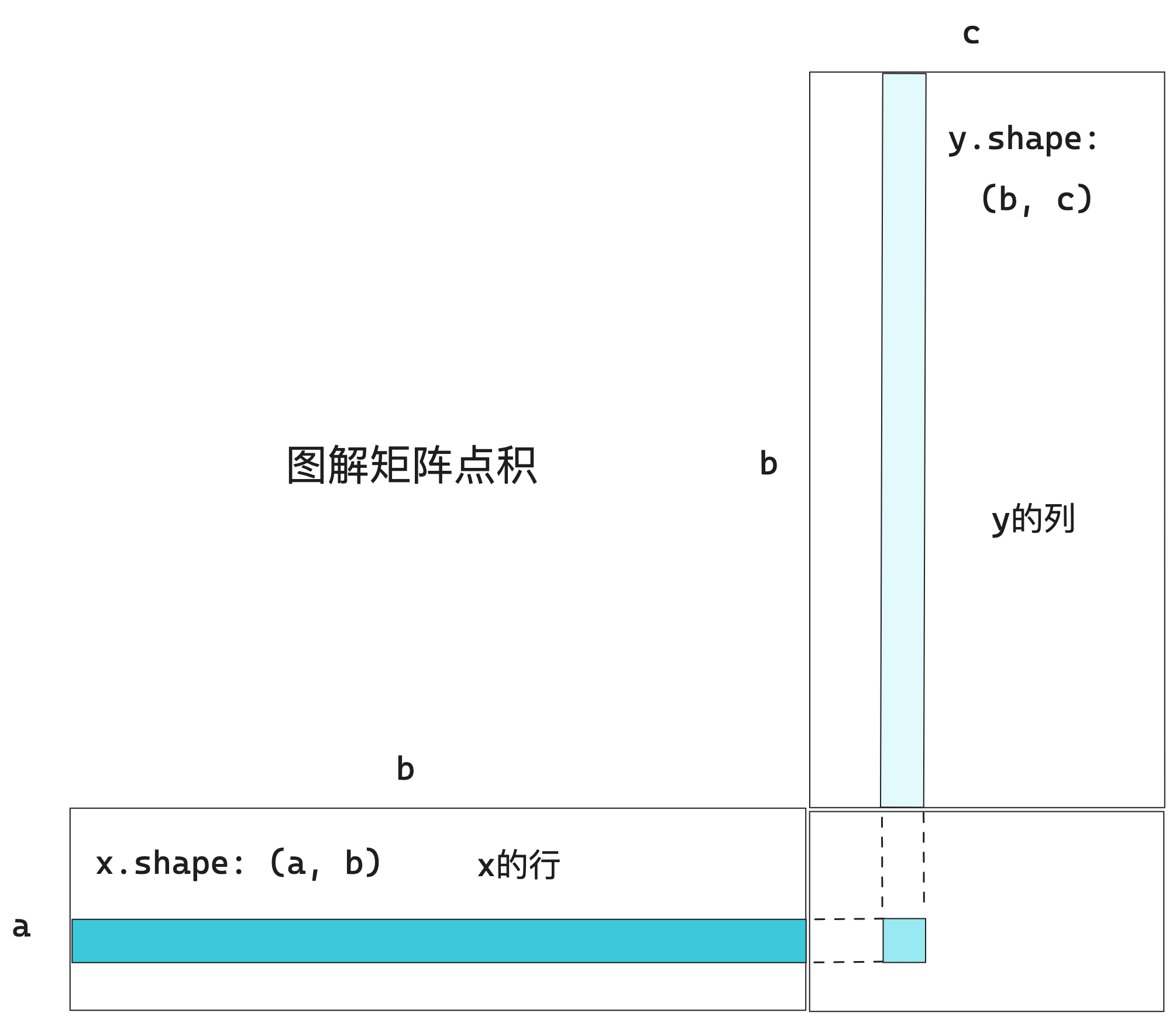
2.2.2、张量积
张量积或点积是最常见且最有用的张量运算之一。注意,不要将其与逐元素乘积弄混。
在NumPy中使用np.dot函数来实现张量积:z = np.dot(x, y)
数学符号中的(·)表示点积运算:z = x · y
2.2.3、张量变形
张量变形是指重新排列张量的行和列,以得到想要的形状。变形后,张量的元素个数与初始张量相同。
import numpy as np
x = np.array([[0, 1],[2, 3][4, 5]])
x.shape //(3, 2)
x = x.reshape((6, 1))
>>> x
array([[0],[1],[2],[3],[4],[5]])
x = x.reshape(2, 3)
>>> x
array([[0, 1, 2],[