ETH Computer Architecture Fall 2023 [1]课程笔记
从 parallelism 到 heterogeneity
Parallelism 加速的本质来自 Admal's Law 和 Polloack's Rule。理想 N 核体系相比单核加速比遵守 \(s = \frac{1}{p+\frac{1-p}{N}}\), 但一味增加并行计算能力不仅边缘递减反而还会 degradation。需要对 Admal's Law 进行进一步修正分析。
Parallel 加速的限制来自于 (1)serial part 无法被并行加速;(2)parallel part 中存在伪并行部分(serail section in parallel part),并行化不完全,并行不完全即由于逻辑或者物理限制,某些执行并不能同时发挥最大并行能力(伪并行)。并行不完全来自于多个并行单元之间的相互约束作用,即各个子单元之间并不是独立的(这是很自然的,毕竟多个单元合作完成一个任务)。从逻辑和物理限制角度有三个原因:
- (逻辑)同步问题(Synchronization),比如某些资源需要共享,为了保证一致性同时只能一个 core 唯一访问;
- (逻辑)任务分配(Load Imbalance),比如任务完成时间的不一导致阻塞等待;
- (物理)共享资源(Resource Sharing),竞争某些物理资源的使用,比如 sharing buffer 访存。
硬件的源头在执行的软件,通过规范并行编程(比如优化同步方式、均匀分配任务)之后仍无法规避的问题,则通过硬件减轻它的影响。加速的底层逻辑很粗暴,直接提高资源(后文是计算能力)加速执行,但难点在怎么只针对加速这一部分,毕竟性能和面积、能耗成本不是线性关系,我们想对重点问题用牛刀,其余部分用菜刀,整体更快但又相对省力。因此引入了硬件上的 heterogeneity。所以 heterogeneity 成立原因是成本和性能非线性关系的 trade-off。
Heterogeneity 异构,通过不一样的底层机制实现某种相同功能,本词不同语境下含义不一(比如介质不同的存储器、计算能力不同的 core、或者专指架构不同的 core,如 AMD Zen5 中大小核架构相同参数不同,在此语境下则是同构。本文语境下指多核体系中不同计算能力的 core。
考虑 Admal's Law 将核做小做多,计算延时、能耗(energy, not power)都是下降,唯一增加的面积开销相比其余二者提升更小,是 延时|能耗 vs 面积 trade-off[2];而 heterogeneity 能耗是会上升的,是 延时 vs 能耗|面积 的 trade-off。本人目前大致感受架构本身设计就是一个 trade-off 的主题,但越深层研究 trade-off 成本越大。
Heterogenetiy 设计案例:Accelerated Critical Section
Parallel section 中又可分为 critical section 和 non-critical section。Critical section 之间互斥,也就是考虑 critical section 和 non-critical 之间俩俩组合搭配的四种可能中,critical-critical 不能同时执行。比如对资源访问的互斥锁(mutex)。
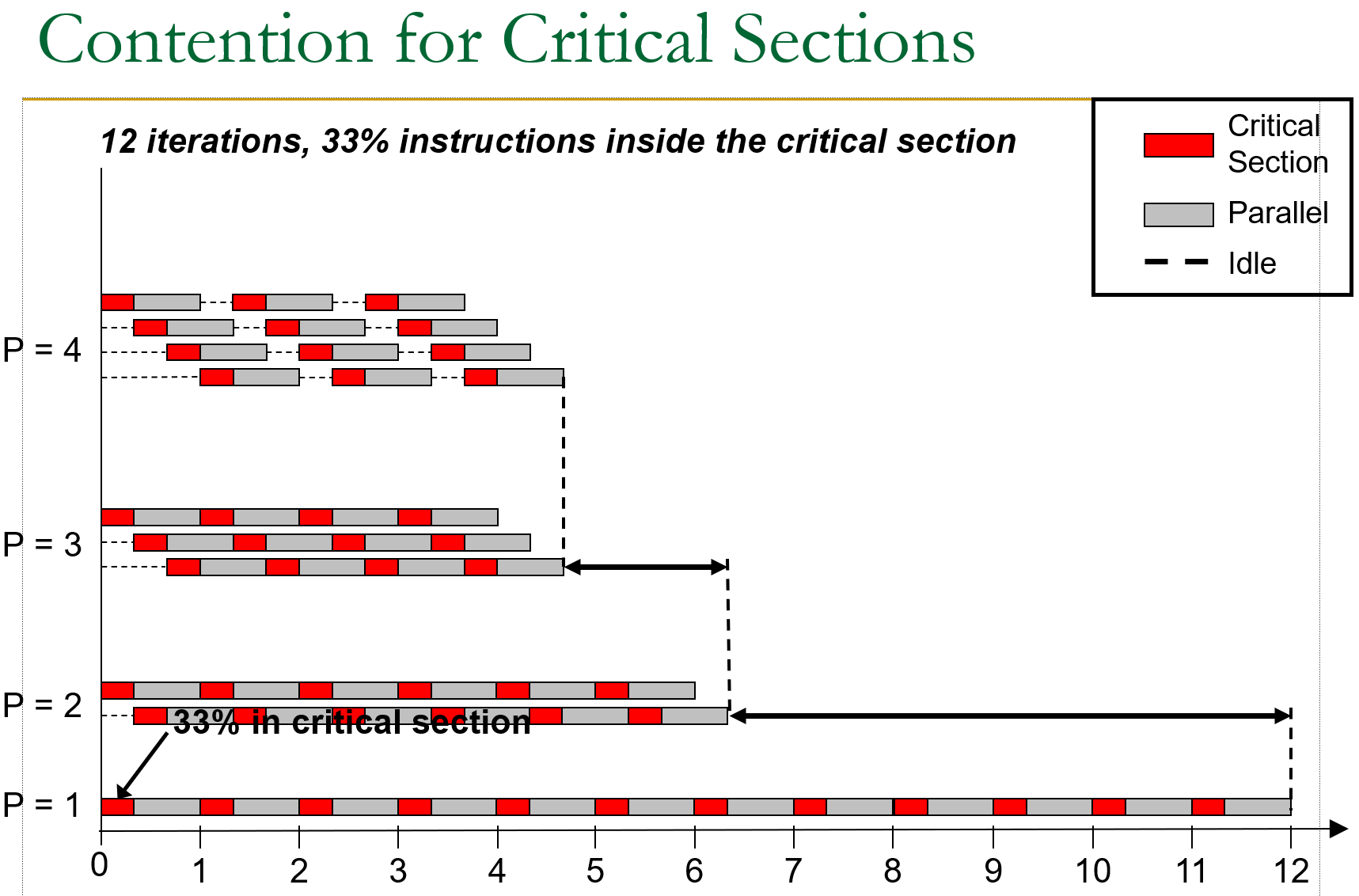
如图,当 P=4 时已经因为 critical 的互斥导致出现 waiting 阻塞。
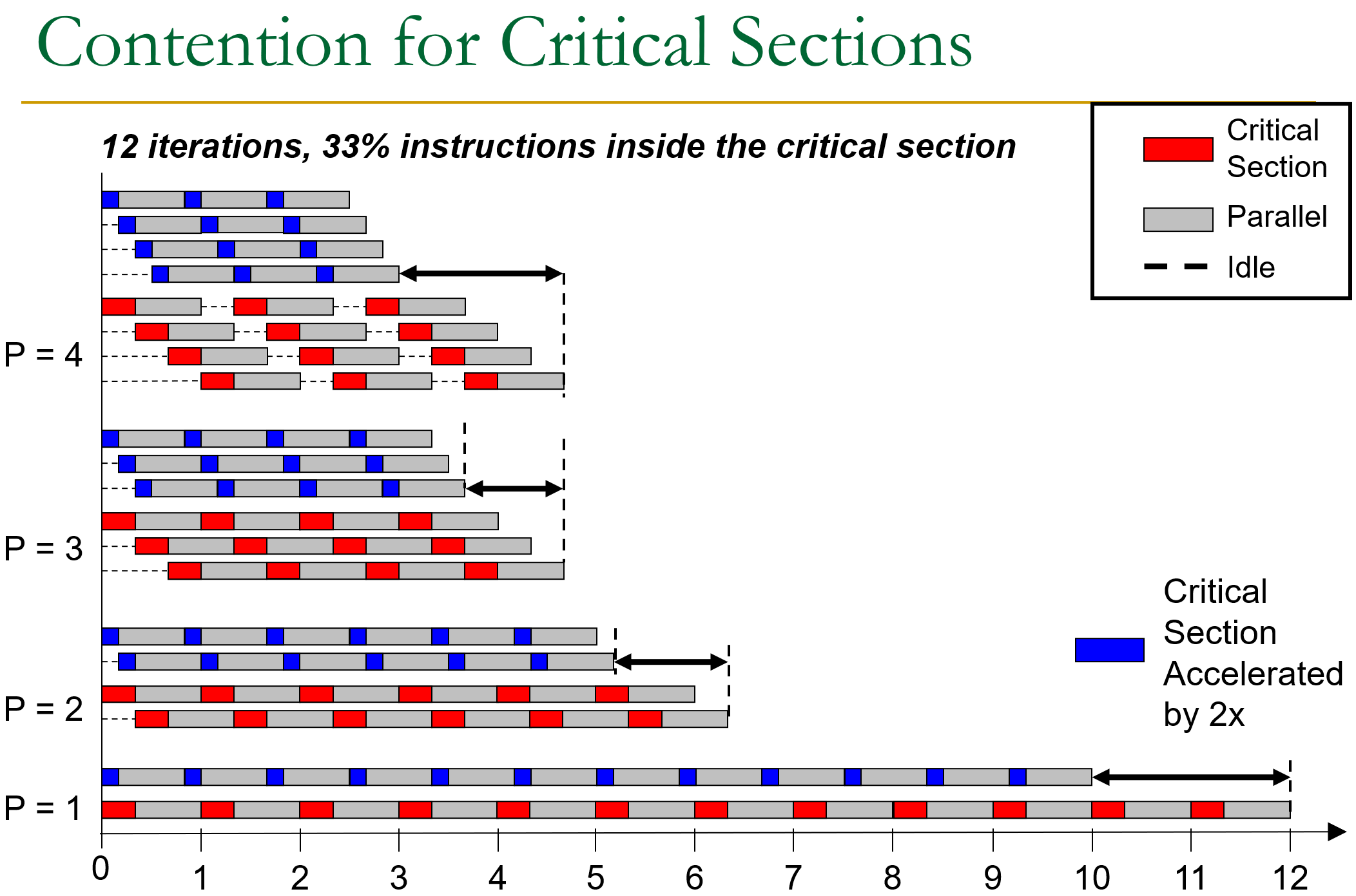
对此解决方案使用 asymmetry 大小核方案,利用大核高算力加速 critial section,同时其余部分保持在小核计算维持总体成本经济。如图,将 critical section 部分加速后不仅加速整体效率也扩展了 scalability。
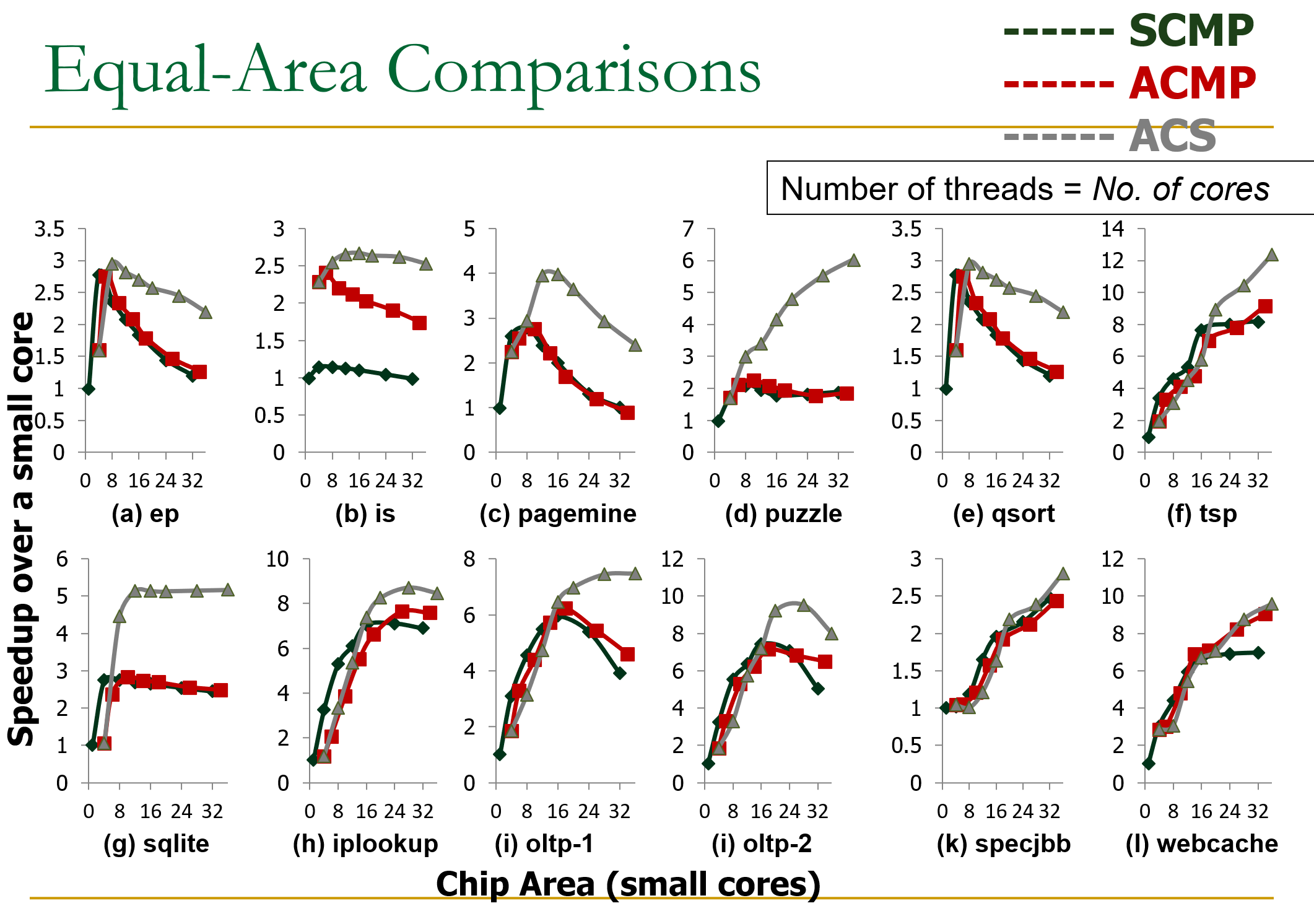
面积相同的情况下不同架构不同任务对比如上。
| 分类 | 结构 | 大核执行 |
|---|---|---|
| SCMP | N同构小核 | - |
| ACMP | 异构(1大核+M小核,M<N) | Serial Part |
| ACS | 异构(1大核+M小核) | Serial Part + Critical Section |
False Serialization
现实情况没有这么简单,一方面 everything with a cost,将 critical section 从小核转移到大核执行增加了通信成本(当然总体延时还是小于小核执行的),另一方面这又人为引入了 resource sharing,多个小核竞争(往往)数量较少的大核。
Critical section 内部又可以根据来源切分为不同种类,并非所有 critical section 都是互斥的,比如对不同资源的访问。此时存在俩种堵塞,同种来源在大核执行堵塞和不同种来源在大核堵塞,对于前者等待大核执行肯定是更高效的(因为小核执行成本高于大核,小核执行等待时间只会更长),但后者执行便存在设计空间,放在小核上执行两者不互斥可以并行,但也有可能在大核上即使阻塞等待总体执行速度也更快,不同来源的 critical section 竞争大核叫做 false serialization。
对于该问题的最优解肯定是准确地计算大小核执行的延时和任务负载,得出最优的调度方案。但综合搜索空间、硬件动态的复杂性,一般在硬件上使用某种动态启发式机制减轻影响。比如使用计数器跟踪 false serilization,如果正确调度 -1(B来源被B来源堵塞),false serialization +1(B被A堵塞),要溢出了则拒绝 false serialization 在大核执行的请求。
Bottleneck Identification and Scheduling
当然大小核并不只用来加速 critical section,但 CAS 例子很好展示了 asymmetry 问题关键:考虑成本,不能所有代码片段放在大核上,并且共享大核调度带来资源竞争,无脑放在大核上性能也不一定提升,问题变为了怎么从代码中拎出 bottleneck,对关键代码针对加速,达到四两拨千斤的效果。
更宽泛地说,bottleneck 可分为三类
- Critial Section:代码执行互斥
- Barrier:代码执行不互斥,但代码开始受其他单元约束
- Pipeline:代码执行不互斥,但代码开始和结束受其他单元约束
针对不同 bottleneck 需要编程时人为进行标识,也就是粒度到代码段。在执行时针对每个 bottleneck 开辟一个空间记录影响(延时时间,threading waiting cycles)[3],根据 TWC 找出影响最大的 bottleneck 放在大核上加速,这个过程叫做 BIS(Bottleneck Identification and Scheduling)。
Conclusion
课程标题是 Parallelism & Heterogeneity,写到这里才豁然明朗:heterogeneity 就暗含 parallelism 的味道啊!Heterogeneity 不同构造单元可以执行相同功能,相同功能的复数则是 parallelism,那么就会存在 mapping 和 scheduling 的空间。若不同单元构造功能都不相同(比如只能执行某种非线性操作的特化硬件单元和加法单元?)说是 heterogeneity 味道好像就不太正了。
https://safari.ethz.ch/architecture/fall2023/doku.php?id=schedule ↩︎
但若考虑单位功耗问题又不一样了,详情见之前博客 https://www.cnblogs.com/devil-sx/p/18299200 ↩︎
实际上代码之间存在耦合依赖关系,等待 bottleneck 2 可能是由于 bottleneck 1 没有执行完,此时延时应记在 bottleneck 1 上,关于依赖部分的追踪详情可见 Bottleneck identification and scheduling in multithreaded applications https://dl.acm.org/doi/10.1145/2150976.2151001。 ↩︎