- 背景
- 问题分析
- 进一步排查
- 问题原因
- Pod的QoS服务质量等级
- 结论
背景
今天开发团队反馈,测试环境中部分业务功能无法正常使用。经过初步排查,发现某个业务Pod在一天内重启了10次,因此需要进一步调查原因。
问题分析
首先,我查看了Pod的日志,发现JVM并未抛出任何错误,服务却直接重启了。这表明进程是被强制终止的,初步判断可能是Pod达到内存上限后被Kubernetes触发了OOM(Out Of Memory)杀死进程的机制。
接下来,我检查了Pod的事件信息,发现以下关键点:
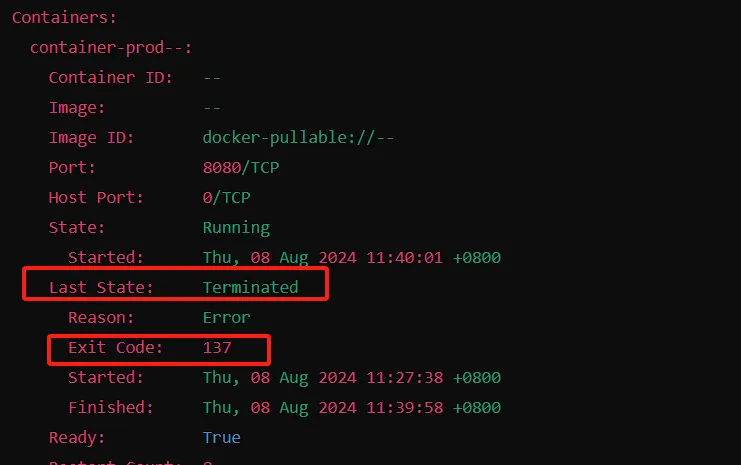
- Last State: Terminated
- Exit Code: 137
Containers:container-prod--:Container ID: --Image: --Image ID: docker-pullable://--Port: 8080/TCPHost Port: 0/TCPState: RunningStarted: Thu, 08 Aug 2024 11:40:01 +0800Last State: TerminatedReason: ErrorExit Code: 137Started: Thu, 08 Aug 2024 11:27:38 +0800Finished: Thu, 08 Aug 2024 11:39:58 +0800Ready: TrueRestart Count: 8Limits:cpu: 8memory: 7GiRequests:cpu: 100mmemory: 512Mi
这个错误码表示Pod的进程被SIGKILL信号强制终止。通常情况下,这是因为Pod达到了内存上限而被Kubernetes杀死。但是,当我查看Pod的内存监控时,发现Pod被杀前的内存使用量仅为3G左右,远未达到设置的7G上限。此时,问题变得更加复杂。
进一步排查
为了找出原因,我查询了Pod所在的节点,并进入该节点查看其内存使用率。结果发现,宿主机的内存使用率已经达到了98%。
问题原因
这就引出了关键问题:为什么Pod的内存未达到上限,却依然被Kubernetes杀死?
经过分析,得出了以下几点结论:
- 内存上限未达,Exit Code 137:
- 如果Pod因内存上限被杀,虽然Exit Code依然是137,但Reason会显示为
OOMKilled,而不是Error。
- 如果Pod因内存上限被杀,虽然Exit Code依然是137,但Reason会显示为
- 宿主机内存耗尽,触发Kubernetes保护机制:
- 宿主机内存耗尽时,Kubernetes会启动保护机制,开始驱逐(evict)一些Pod来释放资源。
- QoS机制的影响:
- 为什么在整个集群中,只有这个Pod反复被驱逐,而其他服务未受影响?原因在于Kubernetes的QoS(Quality of Service)机制。当宿主机资源耗尽时,Kubernetes会按照QoS的优先级,选择驱逐低优先级的Pod来释放资源。
最终,定位到的原因是这个Pod的QoS优先级较低,因此在宿主机资源紧张时,成为了驱逐的首选。
那么问题来了,什么是Pod的QoS?
Pod的QoS服务质量等级
QoS,指的是Quality of Service,也就是k8s用来标记各个pod对于资源使用情况的质量,QoS会直接影响当节点资源耗尽的时候k8s对pod进行evict的决策
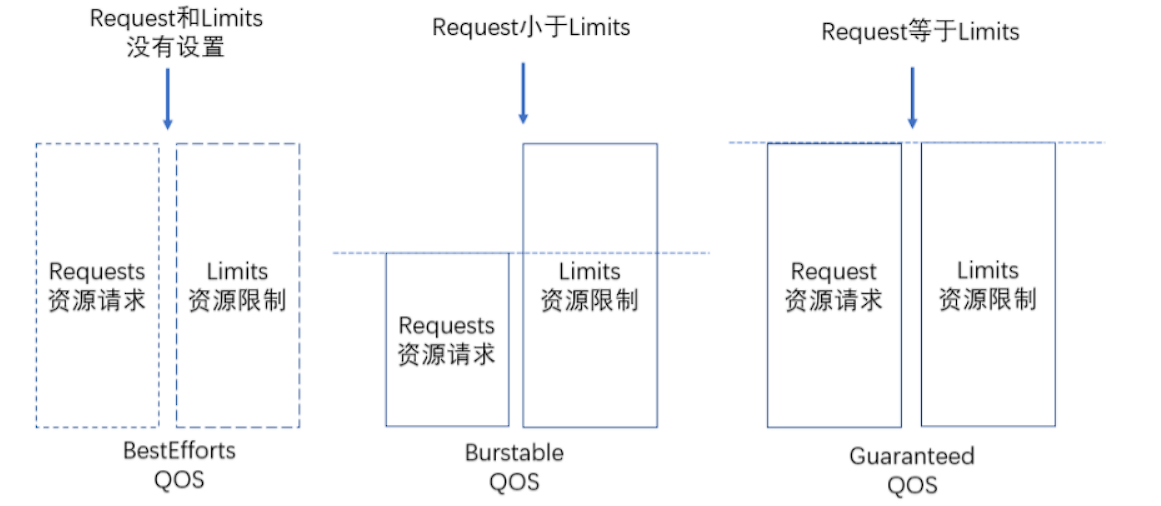
QoS(Quality of Service),可译为 "服务质量等级",或者译作 "服务质量保证",是作用在 Pod 上的一个配置,当 Kubernetes 创建一个 Pod 时,它就会给这个 Pod 分配一个 QoS 等级。
k8s会以pod的描述文件里的资源限制,对pod进行分级:
Guaranteed (该策略下,设置的requests 等于 limits)
- pod.spec.containers[].resources中会存在cpu或memory的request和limit。顾名思义是该容器对资源的最低要求和最高使用量限制。如果我们配置了limit,没有配置request,默认会以limit的值来定义request。
BestEffort(该策略下,没有设置requests 、 limits)
- 当pod的描述文档中没有resource.limit、resource.request相关的配置时,意味着这个容器想跑多少资源就跑多少资源,其资源使用上限实际上即所在node的capacity。
Burstable(该策略下,设置的requests 小于 limits)
- 当resource.limit和resource.request以上述两种方式以外的形式配置的时候,就会采用本模式。 QoS目前只用cpu和memory来描述,其中cpu可压缩资源,当一个容器的cpu使用率超过limit时会被进行流控,而当内存超过limit时则会被oom_kill。这里kubelet是通过自己计算容器的oom_score,确认相应的linux进程的oom_adj,oom_adj最高的进程最先被oom_kill。 Guaranteed模式的容器oom_score最小:-998,对应的oom_adj为0或1,BestEffort模式则是1000,Burstable模式的oom_score随着其内存使用状况浮动,但会处在2-1000之间。
当节点资源耗尽的时候,k8s会按照BestEffort->Burstable(该策略的pods如有多个,也是按照内存使用率来由高到低地终止)->Guaranteed这样的优先级去选择杀死pod去释放资源。
结论
通过这次排查,我们确认了Pod被频繁重启的原因是宿主机内存不足,而非Pod本身的问题。要解决这个问题,可以考虑以下优化措施:
- 调整Pod的资源请求和限制,以提高其QoS优先级。
- 监控和优化集群资源的分配,防止节点内存耗尽的情况发生。
- 在必要时,增加集群的资源,以应对更高的负载需求。
通过这些措施,可以减少类似问题的发生,确保服务的稳定运行。





![[Java并发]ThreadLocal补充](https://img2024.cnblogs.com/blog/1533409/202408/1533409-20240809205617995-2032380131.png)