CUDA入门必看,如何高效地编写并行程序
进入公司实习已经一个月有余,从编写第一个 kernel 开始到现在分析优化 LLM 程序,我的CUDA学习成果颇丰,项目进展顺利,现将我的学习路径整理分享出来。跟随在GPU芯片架构领域深耕多年的企业家王旭老师,我从一开始对GPU架构领域全无了解,到如今上手LLM开源项目优化项目,在该领域我逐渐从一个的小白成长为资深小白。从一个企业级程序架构师的角度,王旭老师为我整理了一套CUDA学习方案和文档资料。
虽然CUDA架构是基于C++语言所开发的,但它不仅仅只是在GPU调用、线程分配方向上API的延伸拓展,而是遵循着一定的设计思路。CUDA的研发以及在当下的流行,从始至终都在完成提升性能这一件事。从这一套学习方案中,你会时刻感受到性能指标在编写CUDA程序中所占据的考量有多重。因此要编写出更加成熟的kernel程序,可以跟着我梳理出的学习流程一步一步掌握基础知识,侧重于对性能指标的提升,将CUDA最开始的初衷运用到你的代码之中。
要学习它最前沿的知识,就先了解它最初的样貌。
学习CUDA我推荐先从Nvidia CUDA 官方文档开始。我将我的学习路线顺序整理如下,并对每一章节的知识作出归纳和总结,并附上我对初学者所给出的建议,便于你理解每一篇文档的用意,所要达到的目的,帮助你快速高效地攻克在学习CUDA道路上的重重难点,获得知识的同时在理念上的有所感悟。
我将不对代码细节上做过多的讲述,如果你需要的是保姆级教程, 也许这篇文档并不适合你。但是如果你在细节上遇到许多坑,那么这篇文档将为你提供解决问题的思路。
1.Cuda 简介
主题:分配GPU线程 & 调度GPU内存
原文链接: An Even Easier Introduction to CUDA
如果你在耕地,你需要什么?一头壮牛还是1024只鸡?
你只需要在 main 函数中敲入这一行简单的代码,就能体会到调用GPU函数是一件多么自然的事。
kernel<<<grid, block>>>(char* param);
其中kernel是你的函数名,你可以自定义。在初学阶段,你可以将grid设置为 1 ,代表你只用到一个block线程块。block是你的线程块尺寸,代表着一个线程块中线程thread的多少。grid和block可以是一维的,也可以是二维的,甚至是三维的,取决于你要完成的任务。在上图的例子中,你可以将block简单设置为256。你知道它最好是2的幂次(但<=1024),它不仅仅只是程序员的强迫症。
在你的kernel函数实现前加上 __global__,代表它是运行在GPU的函数。并且你的每一个线程中都在调用这个函数。
__global__ kernel(char* param) { ... }
为了能够在不同的线程中处理不同的数据,假设现在有一块内存地址,我需要在线程中拿到这些内存地址,访问它的数据。那么我们这样做,给每个线程分配一个id序号,它们从0 ~ n,n是id数最大的线程,其实在一维线程块中它等于上面的block - 1,即255。我们用这些序号的差异来计算得出每个线程需要访问的地址。
在CUDA语言中,我们一般称GPU为设备Device,称CPU为主机Host。假设我们的Device上有一块内存 d_mem , 我们这样来访问到它的第 0 ~ 255 个数据。
__global__ kernel(int* d_mem) { int id = treadIdx.x;d_mem[id] = 0;}
这个函数在每一个线程中都会被调用。此时想必你已经知道了如何使用线程的序号来控制你想要访问的内存位置。下面的几个API是我简单引用的最基础的API。
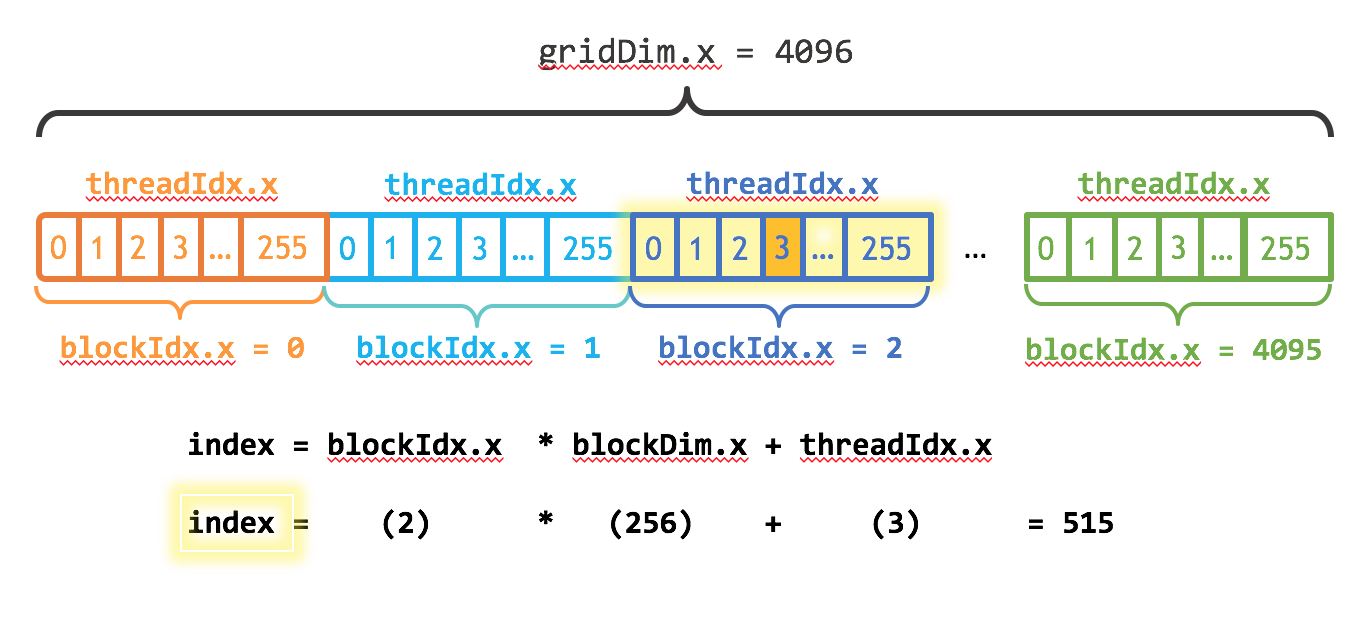
blockIdx.x //此线程的block序号
blockDim.x //block在x维上的长度,在一维block中代表着一个线程块中的thread数目
gridDim.x //grid在x维上的长度,在一维grid中代表着一个grid中的block数目
经过学习,你会从一维的block/grid逐步接触到二维、三维的block/grid,但现在还不必要。请认真思考这些变量的含义,并把它们抽象成图格的形式,这样你会更加理解其中的含义。
上图中的index的含义是什么?以后你将经常用到这样的形式去处理更多的数据。index = blockIdx.x * blockDim.x + threadIdx.x。这里我需要做一点提醒,上图中的gridDim.x是线程块block的长度,也就是说有 4096 个 0~255 那么长的block。曾经我误以为这是 thread的数目。
2.GPU-CPU共用内存:统一内存
主题:统一内存调度 & 内存创建销毁、拷贝
原文链接: Unified Memory for CUDA Beginners
程序员在某种意义上也属于
搬运工。
当你需要使用线程处理数据的时候,一定离不开内存空间的创建。在普通的C语言程序中,我们只需要调用动态分配内存的函数 malloc 就能在内存中开辟一块指定大小的内存空间。但是 malloc 所创建的内存空间是 Host 端的,你的 Decive 一般来说是无法访问的。 CUDA 中提供了一个创建统一内存的API, 这个API的使用和 malloc 类似,但是创建的内存可以被 device 端调用。也就是说,你的__global__函数可以访问这块内存。
float* x;
float* y;cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
作为初学者你可以先使用它,而不去思考这块内存究竟被放置在哪个位置。 你可以通过文档继续了解它的实现原理,简单来说,尽管这个函数在 Host 和 device 上都创建了内存,但是只有当你需要在 device 上使用时,它才会自动将 Host 上的内存拷贝到 device 上。

以下是三个创建内存的API。
malloc() //原生C语言的动态内存创建函数
cudamalloc() //特别的,只在 Device 端创建内存
cudamallocHost() //特别的,只在 Host 端创建内存
创建好内存,你需要对你的数据进行初始化, memset() 函数很有帮助。 想起曾经大一课堂上老师为我们介绍这类函数的用法,他以过来人告诉我们这类函数在实际编程经常使用到。 作为大一的愣头青,心是向着算法的,自然没把搬运内存和拷贝内存的事放在心上。死去的记忆开始攻击我(ー`´ー),如今每天都在开辟内存、初始化内存、拷贝内存、再把内存拷贝回来。以下是几个内存拷贝的函数,memcpy()想必你已经不陌生, cudamemcpy()函数是cuda的内存拷贝API,其中第四个参数决定了内存从哪拷贝到哪。
memcpy(*dest, *src, byteSize) //从src地址拷贝byteSize字节大小的内存给dest的地址
cudamemcpy(*dest, *src, byteSize, cudamemcpyHostToDevice); //从Host拷贝给Device
cudamemcpy(*dest, *src, byteSize, cudamemcpyDeviceToHost); //从Device拷贝回Host
如果你使用完刚才开辟的内存后顺手把它释放了,那么你是一个好程序员。
Free(*mem); //释放由 malloc 创建的内存
cudaFree(*mem); //释放由 cudamalloc() cudamallocHost() 创建的内存
你已经是一个成熟的程序员了,现在你要完成组织交给你的任务ヾ(≧▽≦*)o。以下是一段完整的CUDA代码,其中的saxpy是运行在GPU上的kernel函数,它可以将 x, y 矩阵的对应的元素做一次乘加操作。 将这段代码复制到你的.cu文件里,通过编译运行它来直接感受kernel函数是如何被调用的,并了解我们是怎么在 Host 和 device 端进行数据传输的,我想这会对你有帮助。
#include <stdio.h>__global__ void saxpy(int n, float a, float *x, float *y)
{int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < n)y[i] = a * x[i] + y[i];
}int main(void)
{int N = 20 * (1 << 20);float *x, *y, *d_x, *d_y;x = (float *)malloc(N * sizeof(float));y = (float *)malloc(N * sizeof(float));cudaMalloc(&d_x, N * sizeof(float));cudaMalloc(&d_y, N * sizeof(float));for (int i = 0; i < N; i++){x[i] = 1.0f;y[i] = 2.0f;}cudaMemcpy(d_x, x, N * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_y, y, N * sizeof(float), cudaMemcpyHostToDevice);saxpy<<<(N + 511) / 512, 512>>>(N, 2.0f, d_x, d_y);cudaMemcpy(y, d_y, N * sizeof(float), cudaMemcpyDeviceToHost);float maxError = 0.0f;for (int i = 0; i < N; i++){maxError = max(maxError, abs(y[i] - 4.0f));}printf("Max error: %fn\n", maxError);}CUDA程序必须在nvcc的环境下编译运行,并且你需要把.cpp后缀名改为.cu。 建立nvcc的环境需要 Nvidia 的 GPU 。 你可以使用这两行代码再命令行中进行编译和运行。
nvcc test.cu -o test.out //编译
./test.out //运行
上面的代码我直接抄自借鉴 Nvidia 的官方文档,并对其中目前学习未涉及的调用做了删改,以便你能专注于这一种计算方法。在这两章,我们学习了 CUDA 的线程分配、内存调度等基础知识,帮助你编写了第一个kernel程序,当然,我们并不会止步于此,我们的CUDA学习之旅才刚刚开始。
我将从CUDA的运行性能、查询设备参数、处理报错、数据传输、流控制等多个方面继续为你介绍CUDA的入门知识,多方面地带你感受CUDA的 编程之美 。