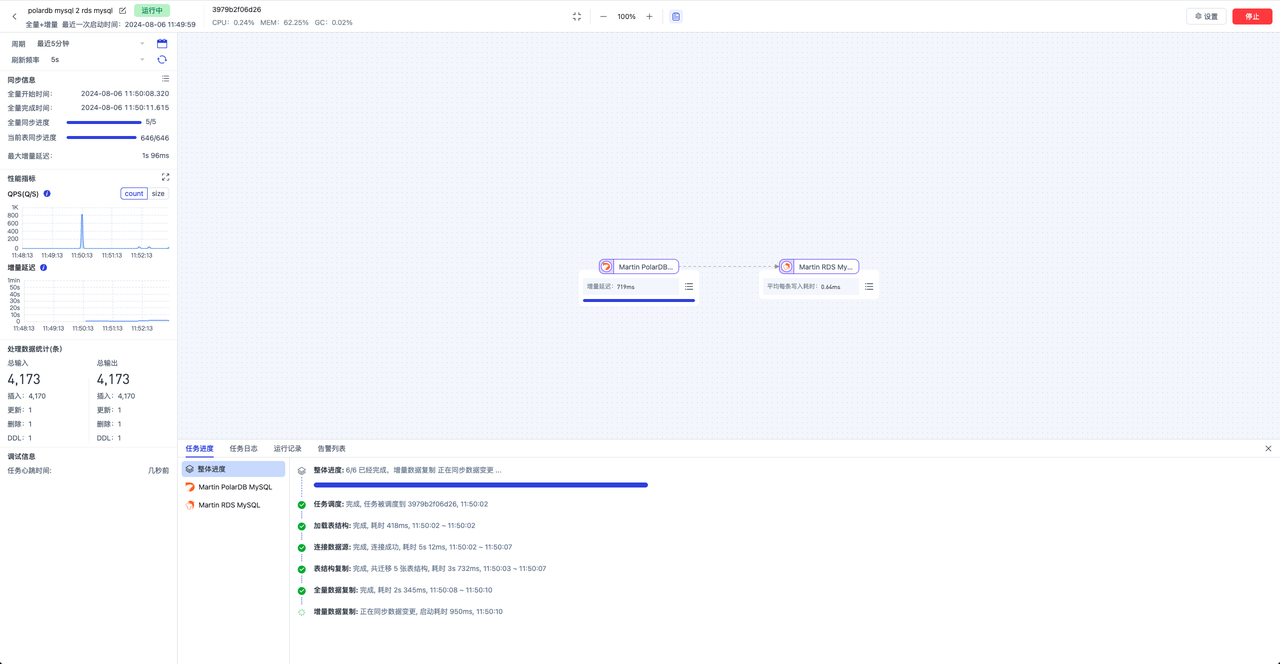
cartographer 代码思想解读(1)- 相关匹配
cartographer在2016年开源后一直在使用,但是一直未仔细阅读并分析其核心代码结构。目前网上可以找到许多博主对其分析和理解。其cartographer的基本思想可参考他人的 博主博客。本博客主要目的根据其框架思想,将其核心算法进行提取,方便后续学习和移植。其google开源的代码量太大,层次太多,大量虚函数,继承关系,功能齐全,并且采用大量的C++11.0新特性等许多原因,导致阅读代码难度加大。因此此次阅读仅对slam核心算法及其思想进行总结。
前端
基本上所有了解slam的人都知道SLAM可分为前端和后端处理,其中前端处理是slam的前提,通常称为帧间匹配,即将新的一帧激光点云和上帧或多帧进行匹配,获取新时刻位置的过程,cartographer也不例外。仔细阅读源码发现,cartographer并非仅一种前端匹配算法,本节仅分析其中一种:采用相关匹配的方法。(注:实际采用的是优化的方法)
帧间匹配主要包括:scan-to-scan、scan-to-map 和优化的方法。
其中cartographer源码中存在一种scan-to-map的相关匹配的算法,其代码目录:cartographer/mapping/internal/2d/scanmathing
栅格地图
Cartographer采用的是当前新的scan激光帧,是否匹配submap并加入。其submap为栅格地图,可以认为submap为一个2维数组,其每个索引下的value值表示概率。为提高运算性能和速度,cartographer将概率表示进行优化,包括概率整数化和对数化。其栅格地图代码目录:cartographer/mapping/2d/grid.h。后续将加入专门代码详解和cartographer的优化。
相关匹配
顶层方法文件目录:cartographer/mapping/internal/2d/scanmathing/real_time_correlative_scan_matcher_2d.cc
调用入口方法为double RealTimeCorrelativeScanMatcher2D::Match
double RealTimeCorrelativeScanMatcher2D::Match(const transform::Rigid2d& initial_pose_estimate,const sensor::PointCloud& point_cloud, const Grid2D& grid,transform::Rigid2d* pose_estimate) const {CHECK(pose_estimate != nullptr);//获取初始位置的角度const Eigen::Rotation2Dd initial_rotation = initial_pose_estimate.rotation();//将当前点云转换为初始角度坐标系下点云const sensor::PointCloud rotated_point_cloud = sensor::TransformPointCloud(point_cloud,transform::Rigid3f::Rotation(Eigen::AngleAxisf(initial_rotation.cast<float>().angle(), Eigen::Vector3f::UnitZ())));// 定义搜索的空间,包括平移的窗口和角度窗口// options_ 为配置参数,由上层调用传入const SearchParameters search_parameters(options_.linear_search_window(), options_.angular_search_window(),rotated_point_cloud, grid.limits().resolution());// 在一定角度搜索空间中(一定窗口内,一定分辨率,如1度分辨率, 搜索范围100度,共100个角度空间),// 对当前点云进行旋转变换,放入vector中const std::vector<sensor::PointCloud> rotated_scans =GenerateRotatedScans(rotated_point_cloud, search_parameters);// 将点云进行坐标转换到世界坐标系坐标,即根据当前估计位置(可以为里程计的位置)进行转换const std::vector<DiscreteScan2D> discrete_scans = DiscretizeScans(grid.limits(), rotated_scans,Eigen::Translation2f(initial_pose_estimate.translation().x(),initial_pose_estimate.translation().y()));// 初始化在xy平移空间内偏移量,即窗口大小和偏移量std::vector<Candidate2D> candidates =GenerateExhaustiveSearchCandidates(search_parameters);// 计算当前帧在角度、x、y三层窗口中每个状态在grid地图中的匹配的评分ScoreCandidates(grid, discrete_scans, search_parameters, &candidates);//采用标准库,迭代获取最大置信度元素const Candidate2D& best_candidate =*std::max_element(candidates.begin(), candidates.end());// 坐标转换为全局坐标*pose_estimate = transform::Rigid2d({initial_pose_estimate.translation().x() + best_candidate.x,initial_pose_estimate.translation().y() + best_candidate.y},initial_rotation * Eigen::Rotation2Dd(best_candidate.orientation));return best_candidate.score;
}
以上为接口代码简单注释。cartographer采用的相关匹配算法基本上可以认为是一种暴力搜索匹配算法,即采用当前的激光帧在已知的栅格地图上进行遍历匹配,获取相关性最高的位置,即置信度最高的位置。其思想几乎与KartoSLAM中的帧间匹配方法一致,但对其进行了一定优化。
3重循环暴力匹配伪代码如下:
for(x)for(y)for(theta)point_new= point_oldbel = sum(point_new)/sum_num
其思想采用了3重循环,在submap中的一定范围内,进行暴力匹配。其步骤如下:
- 将激光点云先转换至估计坐标的世界坐标系下;
- 采用了预先定义x、y、yaw三个窗口大小;
- 将角度进行序列化生成序列,并将点云按照序列后的角度值进行旋转,即可生成N个点云序列。
- 将x,y按照窗口,分辨率进行序列化,即求出应当遍历的所有索引(因为x,y窗口仅需要加减平移)。
- 对以上所有点云在栅格地图中获取最大置信度,仅需查表读取概率值和并归一化;
其相对于KartoSLAM优化点,包括两点:
1.采用空间换取了运算性能,将其遍历的x、y层循环不做实际处理,仅保存其索引队列。同时将角度循环提前遍历并保存所有序列。后续可采用vector迭代和库进行批量处理。
2.减少乘除与sin,cos运算。三层循环最先进行角度旋转,因此sin和cos的运算的次数仅为执行角度量化个数。而后点云转换均为加减运算。
疑问点
1.此相关算法在代码实现上没有看出特别出众之处,可能理解不深。
2.由暴力匹配后得到的置信度,即point在栅格图的概率和并归一化后的结果。而cartographer提供的相关算法,在获取的置信度进行了一次基于与初始位置高斯权重处理作为最终的置信度。
// 此处没看明白????,为什么归一化后的匹配置信度需要加权重,和初始位置距离的高斯分布的概率权重candidate.score *=std::exp(-common::Pow2(std::hypot(candidate.x, candidate.y) *options_.translation_delta_cost_weight() +std::abs(candidate.orientation) *options_.rotation_delta_cost_weight()));
cartographer 代码思想解读(2)- 分支定界快速相关匹配
上节描述cartographer中算法中的相关匹配算法,为前端的scan-match,由于其初始位置有一定确定和分布性,故采用基本的暴力扫描方法。本节描述相关匹配一种快速实现,主要应用于loop-scan。回环检测为后端处理重要步骤,即检测当前位置是否曾经来过,即采用当前scan在历史中搜索是否匹配。故其搜索范围及其位置不确定性较大,故cartographer采用了分枝定界方法进行快速相关匹配。
分支界定基本原理
分支界定是计算机中一种快速求解的方法,其基本方法为将多个约束条件,拆分成多层。而顶层约束条件较少,下层逐渐增加条件,最后一层即支节点为最终结果,我们称之为分支。由于顶层的条件较少,故可得出N多个解,需要对每个解进行评分,并将最大的评分记录此节点,我们称之为上边界,即每层存储结果对应的评分均大于等于下层所有节点评分。我们可以初始一个下边界,即当前最好评分。每个真正评分应为最后一层支节点的评分,如果大于当前的最好评分,则更新,即更新下边界。
分支和边界基本说明,理论上均需要遍历到最后一个支节点才能求出真正解,如此与暴力匹配一致,并没有提高其性能。但由于有了边界后,当某一个节点评分小于当前最好评分,则其节点即以下所有之节点均无需考虑,即为剪枝,如此减少扫描范围。cartographer中在每一层中所有节点的评分也按照从大小排列,如果某节点评分小于当前最后评分(即下边界),则此节点以及此层以后所有节点均可裁剪。
盗一张图。

文字描述较为抽象,可参考他人多个的文档解释。
https://www.jianshu.com/p/9a8089cf7d3f
branch and bound(分支定界)算法
分枝定界图解
源码解读
代码目录:cartographer/mapping/internal/2d/scanmatching/fast_correlative_scan_matcher_2d
顶层函数
顶层函数包含两个
// 此匹配为全范围暴力匹配,无初始位置
bool FastCorrelativeScanMatcher2D::MatchFullSubmap(const sensor::PointCloud& point_cloud, float min_score, float* score,transform::Rigid2d* pose_estimate)/*
input:
当前帧估计位置(里程计等提供的初始位置)
当前帧点云(即以激光雷达为坐标系的点云)
最小置信度
(grid在构造函数已经传递)output:
置信度清单
匹配后输出位置*/
bool FastCorrelativeScanMatcher2D::Match(const transform::Rigid2d& initial_pose_estimate,const sensor::PointCloud& point_cloud, const float min_score, float* score,transform::Rigid2d* pose_estimate)
顶层调用函数比较容易理解,但是仔细看会发现无grid地图的传入接口,是因为快速相关匹配算法,并没有直接对grid地图进行处理,而是需要对grid进行了预处理后的分层地图。grid在传入和预处理是在FastCorrelativeScanMatcher2D构建类时传入。
//构造函数
// input: 栅格图, 配置参数
// 栅格地图进行预先处理
FastCorrelativeScanMatcher2D::FastCorrelativeScanMatcher2D(const Grid2D& grid,const proto::FastCorrelativeScanMatcherOptions2D& options): options_(options),limits_(grid.limits()),precomputation_grid_stack_(absl::make_unique<PrecomputationGridStack2D>(grid, options)) {}
分层地图栈 PrecomputationGridStack2D
// 预处理grid地图堆栈构造函数
// 相当于一个堆栈,其堆栈了存储同一个地图但分辨率不同,低分辨率地图value,采用对应高分辨地图中子格中最高分辨率
PrecomputationGridStack2D::PrecomputationGridStack2D(const Grid2D& grid,const proto::FastCorrelativeScanMatcherOptions2D& options) {CHECK_GE(options.branch_and_bound_depth(), 1);// 获取分支边界搜索层参数, 获取grid地图放大的最大宽度const int max_width = 1 << (options.branch_and_bound_depth() - 1);// precomputation_grids_ 根据参数开辟搜索层数
precomputation_grids_.reserve(options.branch_and_bound_depth());std::vector<float> reusable_intermediate_grid;// 赋值原来grid limit参数const CellLimits limits = grid.limits().cell_limits();// 开辟一个vector,其大小为,应该是每层存储的的grid,空间开辟意义不大,每层都会再次resizereusable_intermediate_grid.reserve((limits.num_x_cells + max_width - 1) *limits.num_y_cells);// 构建for (int i = 0; i != options.branch_and_bound_depth(); ++i) {//后续因为需要用来采样的为1,2,4,8,16......//队列中最前的为分辨率最高的地图//队列末尾则为分辨率最低的地图//故需对原图片进行采样,保证第一个采样位置不变,需要对原图进行扩展,而width则扩展和偏移量//层顶采样间隔最小,即为最高分辨率地图const int width = 1 << i;precomputation_grids_.emplace_back(grid, limits, width,&reusable_intermediate_grid);}
}
思想总结:
传入地图为原分辨率地图,即为最高分辨地图。而预处理地图堆栈则保存了n张不同分辨率的栅格地图。其中栈底为原分辨率地图,往上则存储压缩2,4,8,16倍的地图,栈顶则存储最粗分辨率的地图。不同层的地图,其实目的是为了后续相关匹配在不同分辨率地图下匹配,即为分支界定中的层。为保证上边界正确性,即高层中的评分一定高于其底层节点的评分。压缩的地图并非直接从原图固定间隔采样,而是将固定间隔中所有坐标概率值最大值作为低分辨率地图,以此类推完成整个地图栈预处理。其效果图可看下图。

如此直观可看出,在低分率下的地图匹配其相关性一定较高,如果分辨率继续降低,则极限分辨率为1。(这句话的意思是,随着地图分辨率的不断降低,地图上每个单元格的面积会增大,代表的信息会变得更加粗略。在极端情况下,如果分辨率降低到最低,即整个地图只由一个单元格组成,那么这个单元格包含了所有地图的信息,因此它存在的概率就是100%,或者说概率为1。换句话说,当分辨率降低到极限时,整个地图就只剩下一个单元格,这个单元格必然存在,所以其概率值就是1。这是一种理论上的极端情况,用于说明分辨率降低对概率值的影响。)
真实匹配函数MatchWithSearchParameters
顶层的两个函数实际最终都将调用MatchWithSearchParameters,即真正的匹配流程。
bool FastCorrelativeScanMatcher2D::MatchWithSearchParameters(SearchParameters search_parameters,const transform::Rigid2d& initial_pose_estimate,const sensor::PointCloud& point_cloud, float min_score, float* score,transform::Rigid2d* pose_estimate) const {CHECK(score != nullptr);CHECK(pose_estimate != nullptr);const Eigen::Rotation2Dd initial_rotation = initial_pose_estimate.rotation();// 将点云旋转至初始位置(即估计位置)航向方向上const sensor::PointCloud rotated_point_cloud = sensor::TransformPointCloud(point_cloud,transform::Rigid3f::Rotation(Eigen::AngleAxisf(initial_rotation.cast<float>().angle(), Eigen::Vector3f::UnitZ())));// 根据将角度窗口按照一定分辨率划分,并根据每一个旋转角度将点云旋转,生成N个点云const std::vector<sensor::PointCloud> rotated_scans =GenerateRotatedScans(rotated_point_cloud, search_parameters);// 将所有点云转换到初始位置上const std::vector<DiscreteScan2D> discrete_scans = DiscretizeScans(limits_, rotated_scans,Eigen::Translation2f(initial_pose_estimate.translation().x(),initial_pose_estimate.translation().y()));// 修复下所有点云的大小在空间的大小,即边界
search_parameters.ShrinkToFit(discrete_scans, limits_.cell_limits());//获取低分辨率的量化列表(和标准相关方法对比),并且计算匹配评分结果,并进行了排序const std::vector<Candidate2D> lowest_resolution_candidates =ComputeLowestResolutionCandidates(discrete_scans, search_parameters);// 分支边界搜索最佳匹配const Candidate2D best_candidate = BranchAndBound(discrete_scans, search_parameters, lowest_resolution_candidates,precomputation_grid_stack_->max_depth(), min_score);if (best_candidate.score > min_score) {*score = best_candidate.score;*pose_estimate = transform::Rigid2d({initial_pose_estimate.translation().x() + best_candidate.x,initial_pose_estimate.translation().y() + best_candidate.y},initial_rotation * Eigen::Rotation2Dd(best_candidate.orientation));return true;}return false;
}
其匹配主要思想流程和上一节相关匹配基本一致,只是扫描所有解的方法进行了优化,即采用了分支界定进行快速求解。其流程总结如下:
1.先进行角度搜索空间和间隔进行生成所有可能性角度解,假设N个解,则生成N个cloudpoint;
2.对所有角度解的cloudpoint均转换至地图初始位置下。
3.先对最低分辨率的地图进行相关匹配,即搜索空间也与最低分辨率一致;
4.将最低分辨率所有位置及其对应评分放入集合中,同时按照评分从高到低排序。
5.调用分支界定方法求出最佳评分及其对应位置,则为相关匹配最佳值。
分支界定搜索BranchAndBound
根据分支界定的思想可知,第一步应先求取顶层的解及其对应评分(即可能位置和对应匹配置信度)。每层的当前节点的对应的评分均大于等于其所有下层枝叶节点,即上边界。由于不同分辨率地图存储格式,显然满足上边界条件,低分辨地图下的匹配置信度显然高于下层的高分辨地图下的匹配。然后采用迭代方法裁剪枝叶,直到遍历所有叶子节点。
Candidate2D FastCorrelativeScanMatcher2D::BranchAndBound(const std::vector<DiscreteScan2D>& discrete_scans,const SearchParameters& search_parameters,const std::vector<Candidate2D>& candidates, const int candidate_depth,float min_score) const {// 如果没分层,则直接返回评分最高的结果,即到达元分辨率层if (candidate_depth == 0) {// Return the best candidate., 已经拍过序,故第一个则为最佳匹配return *candidates.begin();}Candidate2D best_high_resolution_candidate(0, 0, 0, search_parameters);best_high_resolution_candidate.score = min_score;for (const Candidate2D& candidate : candidates) {// 小于分支下边界,可直接结束,即裁剪此枝叶,因为顶层已经按评分结果从大小排序,后面只能更小if (candidate.score <= min_score) {break;}std::vector<Candidate2D> higher_resolution_candidates;// 由于地图分辨率为2的层数次方, 因此下一层高分辨为2的层数-1 次方// 获取此层下一层的间隔const int half_width = 1 << (candidate_depth - 1);for (int x_offset : {0, half_width}) {// x 到达遍历边界if (candidate.x_index_offset + x_offset >search_parameters.linear_bounds[candidate.scan_index].max_x) {break;}for (int y_offset : {0, half_width}) {// y到达遍历边界if (candidate.y_index_offset + y_offset >search_parameters.linear_bounds[candidate.scan_index].max_y) {break;}// 将此层的下一层更高分辨的坐标列表
higher_resolution_candidates.emplace_back(candidate.scan_index, candidate.x_index_offset + x_offset,candidate.y_index_offset + y_offset, search_parameters);}}// 计算更高层的评分ScoreCandidates(precomputation_grid_stack_->Get(candidate_depth - 1),discrete_scans, search_parameters,&higher_resolution_candidates);// 取最高评分的的pose集合,并且更高评分的结果列表,继续分支,直到子节点,即原分辨率地图best_high_resolution_candidate = std::max(best_high_resolution_candidate,BranchAndBound(discrete_scans, search_parameters,higher_resolution_candidates, candidate_depth - 1,best_high_resolution_candidate.score));}return best_high_resolution_candidate;
}
分支迭代流程总结:
1.当前栈为顶层栈,并且栈中所有的可能性位置(即粗分辨的位置)按照score从大到小排序存储;
2.如果当前栈没有下层,表明为枝叶节点,则直接返回第一个即最大score对应的位置。
3.如果有下一层,将每个节点进行遍历;
4.如果该节点的score小于min-score(即当期最佳匹配score),则将当前节点及其后续所有节点进行裁剪;
4.如果当前节点大于min-score,则将根据下层分配率进行分解所有解,并进行匹配,同样安装score排序;
5.继续调用BranchAndBound进行迭代,即排序后的节点作为BranchAndBound入口,直到枝叶节点。
6.如果到达枝叶节点的计算获得score,如果大于best_score,则将best_score进行更新。
注意:
1.cartographer 分层采用了很巧妙的方法,实际上每层节点下层仅有4个节点;
2.因为在地图预处理时,其分辨率按照2的层数次方进行压缩的,由于地图有x和y两个方向,因此此层的一个节点,在下层会分为4个节点,即分辨率会放大2倍
为助于理解,可参考如下图示例。

从手绘图可看出,最上一层为函数入口,即低分辨率所有位置在低分辨地图下所有可能的位置,且score分按照从大到小排序。同时假设min_score=0。
然后将此层每个节点的下一层进行同样操作,直到枝叶节点,由于min_score假设为0,则第一个节点及其下层每一个第一个节点都应该遍历,到达枝叶节点时,获取最高评分,如图所示应为0.65。则min_score更新为0.65为下边界。
依次再进行本层的第二个节点,执行同样的操作,假设遍历所有的枝叶节点min_score为0.67。
依次再进行本层第三个节点,发现本层第三个节点的score:0.4<min_score:0.67。即本节点的上边界小于目前min_score,则将本节点及其本层后续节点进行裁剪。
cartographer 代码思想解读(3)- ceres优化库scan-match
前两节分析了cartographer 中的相关匹配思想和相关匹配优化快速实现,但cartographer之所以局部slam即前端匹配的准确度极高,因为最终采用了优化匹配的方法,即比栅格化的地图相关匹配准确度更高。而cartographer将匹配转换成最小二乘思想,并采用自家的ceres库完成优化匹配。
其详细的代码解释可参考他人博客:
基于Ceres库的扫描匹配器
ceres匹配简单总结
//采用ceres库求解
/*
input:
1.估计位置
2.初始位置
3.点云
4.栅格地图
输出:
1.最佳优化值
2.优化信息描述*/
void CeresScanMatcher2D::Match(const Eigen::Vector2d& target_translation,const transform::Rigid2d& initial_pose_estimate,const sensor::PointCloud& point_cloud,const Grid2D& grid,transform::Rigid2d* const pose_estimate,ceres::Solver::Summary* const summary) const {// 估计位置初始值double ceres_pose_estimate[3] = {initial_pose_estimate.translation().x(),initial_pose_estimate.translation().y(),initial_pose_estimate.rotation().angle()};//求解器
ceres::Problem problem;CHECK_GT(options_.occupied_space_weight(), 0.);//两种类型switch (grid.GetGridType()) {// 概率地图case GridType::PROBABILITY_GRID:// 增加匹配的代价函数, 添加误差项
problem.AddResidualBlock(CreateOccupiedSpaceCostFunction2D(options_.occupied_space_weight() /std::sqrt(static_cast<double>(point_cloud.size())),point_cloud, grid),nullptr /* loss function */, ceres_pose_estimate); break;case GridType::TSDF:problem.AddResidualBlock(CreateTSDFMatchCostFunction2D(options_.occupied_space_weight() /std::sqrt(static_cast<double>(point_cloud.size())),point_cloud, static_cast<const TSDF2D&>(grid)),nullptr /* loss function */, ceres_pose_estimate);break;}CHECK_GT(options_.translation_weight(), 0.);// 增加平移权重,代价函数, 平移代价,即优化的位置与target_translation,????不理解,理论上迭代初始值不应该是预测的值吗
problem.AddResidualBlock(TranslationDeltaCostFunctor2D::CreateAutoDiffCostFunction(options_.translation_weight(), target_translation),nullptr /* loss function */, ceres_pose_estimate);CHECK_GT(options_.rotation_weight(), 0.);// 增加旋转权重,代价函数,????,和优化本身比较,有什么意义?????
problem.AddResidualBlock(RotationDeltaCostFunctor2D::CreateAutoDiffCostFunction(options_.rotation_weight(), ceres_pose_estimate[2]),nullptr /* loss function */, ceres_pose_estimate);// 优化器求解ceres::Solve(ceres_solver_options_, &problem, summary);*pose_estimate = transform::Rigid2d({ceres_pose_estimate[0], ceres_pose_estimate[1]}, ceres_pose_estimate[2]);
}
由于采用了ceres库进行优化求解,其流程较为简单,仅简单描述下其模型。将匹配转换成最小二乘的问题,即需建立最小二乘等式。scan-match包含3个代价函数,可配置其相关权重。
- 点云在栅格地图的匹配程度,期望:匹配度越高;
- 优化的pose与估计的target_pose偏移程度,期望:偏移量越小;
- 优化的angle与init_pose的angle偏移程度,期望:偏移量越小;
其中2和3较为简单,可自行看源码,注意:第一节中的一个疑问,相关匹配后的结果也会考虑其与初始位置偏差进行权重化, 说明cartographer认为其匹配后的值应该与初始估计值相差不大。而点云在栅格地图的匹配为主要代价函数。
扫描匹配OccupiedSpaceCostFunction2D
点云在栅格地图的匹配程度如相关匹配方法一致,即将点云转换至地图坐标后,统计所有点云在栅格grid图中的概率值,越大表明匹配程度越高。由于为代价函数,因此期望匹配越高,则代价越低,故采用grid中的CorrespondenceCost替代probability值(CorrespondenceCost = 1-probability )。
由于栅格地图中坐标是根据默认0.05m的分辨率进行采样得到,即地图坐标相对来说较为稀疏,之所以其优化精度高于相关匹配,Cartographer将grid进行了双三次插值,即可认为更高分辨率的栅格地图。采用了ceres自带的双三插值器,十分方便,其代码注释如下。
// 输入:权重, 点云, 栅格地图OccupiedSpaceCostFunction2D(const double scaling_factor,const sensor::PointCloud& point_cloud,const Grid2D& grid): scaling_factor_(scaling_factor),point_cloud_(point_cloud),grid_(grid) {}// 类型模板template <typename T>// pose为输入待优化量, residual为参差bool operator()(const T* const pose, T* residual) const {// 平移矩阵Eigen::Matrix<T, 2, 1> translation(pose[0], pose[1]);// 旋转向量Eigen::Rotation2D<T> rotation(pose[2]);// 旋转矩阵Eigen::Matrix<T, 2, 2> rotation_matrix = rotation.toRotationMatrix();// 2维转移矩阵, 即当前位置在世界坐标系下的转移矩阵Eigen::Matrix<T, 3, 3> transform;transform << rotation_matrix, translation, T(0.), T(0.), T(1.);// 重新定义gridconst GridArrayAdapter adapter(grid_);// 这里将构造时传入的概率栅格图(local submap)加载到一个双三次插值器中// Grid2D还可以利用BiCubicInterpolator实现双三次插值,它相对于双线性插值的优点是能实现自动求导ceres::BiCubicInterpolator<GridArrayAdapter> interpolator(adapter);const MapLimits& limits = grid_.limits();for (size_t i = 0; i < point_cloud_.size(); ++i) {// Note that this is a 2D point. The third component is a scaling factor.const Eigen::Matrix<T, 3, 1> point((T(point_cloud_[i].position.x())),(T(point_cloud_[i].position.y())),T(1.));// 将点云转换为世界坐标const Eigen::Matrix<T, 3, 1> world = transform * point;// 迭代评价函数// 将坐标转换为栅格坐标,双三次插值器自动计算中对应坐标的value
interpolator.Evaluate((limits.max().x() - world[0]) / limits.resolution() - 0.5 +static_cast<double>(kPadding),(limits.max().y() - world[1]) / limits.resolution() - 0.5 +static_cast<double>(kPadding),&residual[i]);// 所有参差加入同一权重residual[i] = scaling_factor_ * residual[i];}return true;}
总结
采用ceres优化匹配为cartographer 算法中前端核心匹配算法,而相关匹配和快速相关匹配则可作为第一步的预测匹配,可为优化匹配提供一个较好的初始值。其中真正前端中相关匹配方法可以进行配置不使能。