什么是 Jenkins Pipeline
Jenkins Pipeline是一种持续集成和持续交付(CI/CD)的功能,它允许开发者将复杂的构建、测试和部署流程编码为一系列称为“管道”的自动化步骤。这些步骤以Groovy脚本的形式编写,并且可以在Jenkins中可视化管理。Pipeline提供了代码化和可重用的构建过程,支持更精细的控制和更高级的自动化。
通过Jenkins Pipeline,可以实现以下目标:
- 代码化: 整个部署流程可以用代码表示,便于版本控制和团队共享。
- 可视化: Jenkins UI提供对Pipeline的可视化展示,包括每个步骤的状态和结果。
- 灵活性: 支持简单的脚本到复杂的多个步骤,适用于不同的应用场景。
- 可重用: 步骤和逻辑可以封装成可重用的代码块,称为“插件”,并在多个项目中复用。
- 工具集成: 能够与各种工具和平台集成,如GitHub、Docker、Kubernetes等。
Jenkins Pipeline通常定义在一个名为Jenkinsfile的文件中,这个文件随着项目代码一起存储在版本控制系统中。这使得构建和部署流程可以跟随项目代码一起演进,实现基础设施即代码(Infrastructure as Code, IaC)。
创建Pipeline任务
新增任务,选择流水线
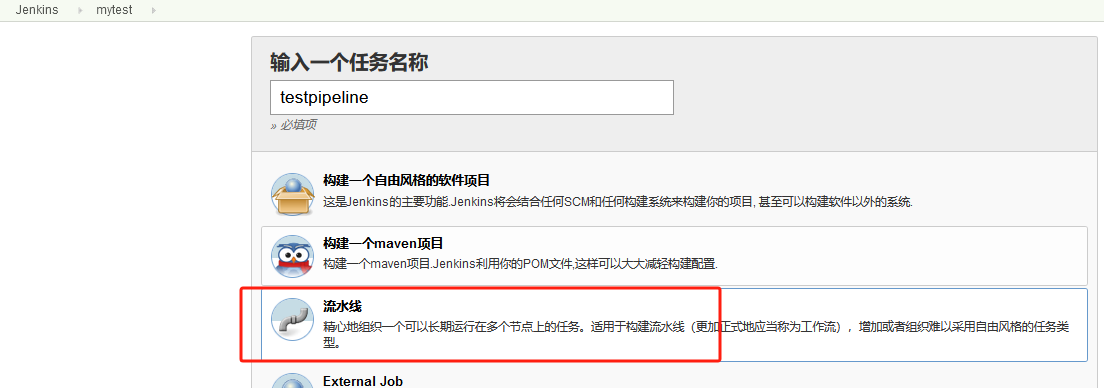
注:如果上图中没有流水线选项的同学那是因为你的Jenkins没有安装pipeline插件,打开 Jenkins 找到 【系统管理】->【插件管理】->【可选插件】 然后在搜索框输入 Pipeline
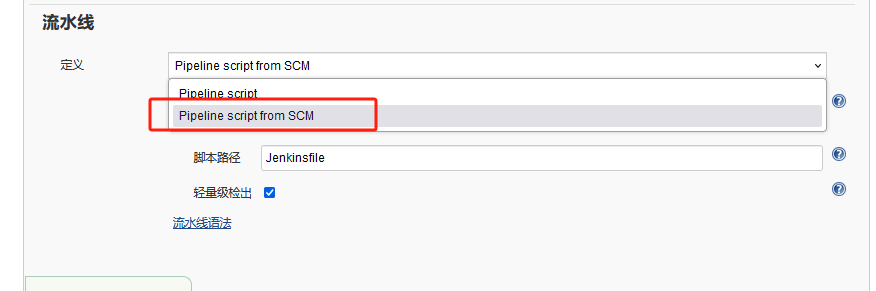
Pipeline定义有两种方式:
- 一种是Pipeline Script ,是直接把脚本内容写到脚本对话框中;
- 另一种是 Pipeline script from SCM (Source Control Management–源代码控制管理,即从gitlab/github/git上获得pipeline脚本–JenkisFile)
例如我们公司就选择第二种方式,把该项目的所有前后端服务配置成Jenkinsfile文件,统一存放到gitlab的ops项目下面,方便运维统一管理。
进入之前创建好的项目点击配置,选择流水线配置:
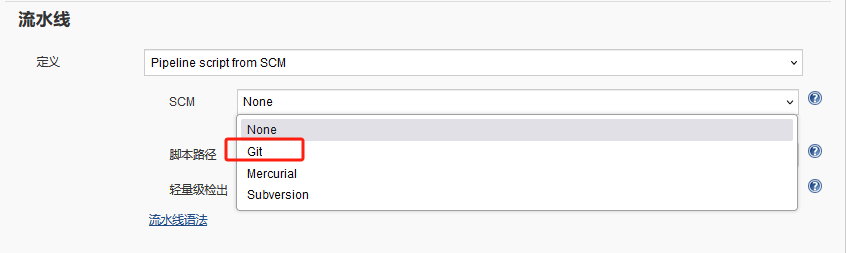
选择SCM
选择git,这里就是填写Jenkinsfile的git地址
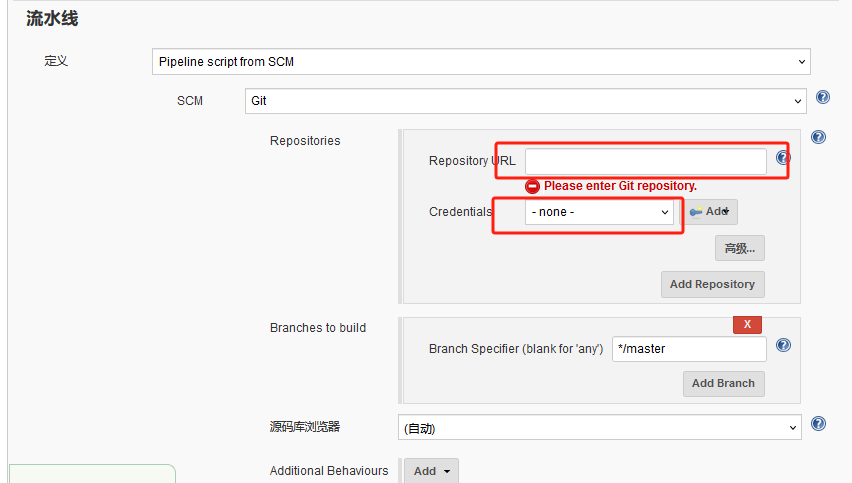
这里申明具体服务jenkinsfile在gitlab项目中的位置,实例为ops/testpipeline的Jenkinsfile文件(ops是gitlab上的项目项目存放的是所有服务的Jenkinsfile)
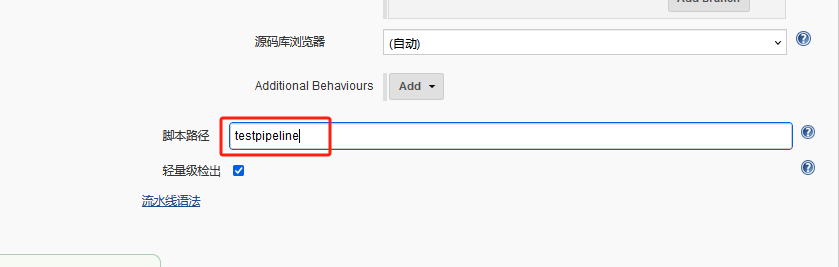
jenkins pipeline语法
Jenkins Pipeline 语法主要涉及定义项目的构建、测试、部署等流程,通过Groovy语言编写,分为声明式和脚本式两种语法。以下是Jenkins Pipeline语法的主要组成部分及其用途:
- agent:指定流水线的执行节点,可以是任何可用的代理(agent any)或特定的标签(agent { label 'my-defined-label' })。
- stages:流水线中的各个阶段,每个阶段包含一个或多个步骤,用于执行具体的任务,如编译、测试、部署等。
- steps:流水线中的具体操作步骤,如执行shell命令(sh)、输出信息(echo)等。
- environment:设置环境变量,影响流水线中后续步骤的执行环境。
- options:配置选项,如历史构建记录保留数量、超时时间、失败重试等。
- parameters:为流水线运行时设置的参数列表。
- triggers:定义流水线运行的触发方式,如定时触发、轮询SCM等。
- input:交互输入,流水线运行到input时会暂停,等待用户输入。
- when:条件判断,允许流水线根据给定的条件决定是否执行某个阶段。
- post:流水线或阶段完成后的一些附加步骤,根据完成状态执行不同的操作。
此外,Jenkins Pipeline还支持多种指令和步骤,如deleteDir、dir、fileExists、writeFile、readFile、stash、unstash、sh、error、tool、timeout、waitUntil、retry、sleep等,用于文件操作、命令执行、错误处理等。
以下是我Jenkinsfile的样例,内容仅供参考:
pipeline {// 定义agent,表示构建环境agent any// 定义参数,用于在运行时传入parameters {choice choices: ['uat'], name: 'platform'string defaultValue: 'saspre', name: 'branch'string defaultValue: '9666', name: 'port'string defaultValue: '2', name: 'replicas_num'string defaultValue: '1000', name: 'cpu'string defaultValue: '4096', name: 'memory'}// 定义选项,例如日志保留策略options {buildDiscarder logRotator(artifactDaysToKeepStr: '', artifactNumToKeepStr: '', daysToKeepStr: '', numToKeepStr: '5')}// 定义环境变量environment{tools="${env.WORKSPACE}/"}// 定义工具,例如JDK版本tools{jdk 'jdk1.8'}// 定义阶段,每个阶段包含一系列的步骤stages {// 清理工作空间stage('clean workspaces') {steps {script {deleteDir()}}}// 从GitLab拉取代码stage('gitlab_pull') {steps {echo 'gitlab_pull'checkout([$class: 'GitSCM', branches: [[name: '${branch}']], extensions: [], userRemoteConfigs: [[credentialsId: 'ee97b3a8-aac8-43f8-b058-5ca5bc619c01', url: 'https://gitlab地址/testpipeline.git']]])}}// 获取提交信息stage('get_commit') {steps {script {env.GIT_COMMIT_MSG = sh (script: 'git rev-parse HEAD', returnStdout: true).trim()}}}// 更新配置文件stage('config_update') {steps {echo 'config_update'sh '''cd $WORKSPACE/sed "s/9999/$port/" /opt/jenkins/docker/Dockerfile > Dockerfilesed -i "s/2048/${memory}/g" $WORKSPACE/Dockerfilecp /opt/jenkins/docker/docker-entrypoint.sh $WORKSPACE/docker-entrypoint.sh/bin/cp /opt/jenkins/env/testpipeline/pre/application.properties $WORKSPACE/src/main/resources//bin/cp /opt/jenkins/env/testpipeline/pre/logback.xml $WORKSPACE/src/main/resources/'''}}// 使用Maven进行构建stage('maven_build') {steps {echo 'maven_build'sh '''cd $WORKSPACE && /usr/local/apache-maven-3.8.6/bin/mvn clean install -Dmaven.test.skip=true -Dmaven.javadoc.skip=true -U'''}}// 构建Docker镜像并推送到仓库,最后发布到k8s集群stage('dockerimage_build') {steps {echo 'dockerimage_build'sh '''cd $WORKSPACEJobName=`echo $JOB_NAME|tr \'[A-Z]\' \'[a-z]\'|awk -F\'uat-\' \'{print$2}\'`current_date=`TZ=\'UTC-8\' date +\'%Y%m%d%H%M\'`Version=uat-$current_date-${GIT_COMMIT_MSG:0:8}if [ ! -f target/*.jar ];then find target/ -name \\*.jar|xargs -i mv {} target/;fidocker build -t 公司harbor仓库地址/testpipeline/$JobName:$Version .docker push 公司harbor仓库地址/testpipeline/$JobName:$Version/opt/jenkins/docker/init_public.sh $JobName aftersale/$JobName $Version $replicas_num $port $cpu $(($memory + 512)) "" default "" "" as-$platform gfskubectl apply -f /work/dchuat/$JobName.yaml'''}}// 健康检查stage('health_check') {steps {sh '''JobName=`echo $JOB_NAME|tr \'[A-Z]\' \'[a-z]\'|awk -F\'uat-\' \'{print$2}\'`/opt/jenkins/docker/health-as.sh $JobName $replicas_num'''}}}
}
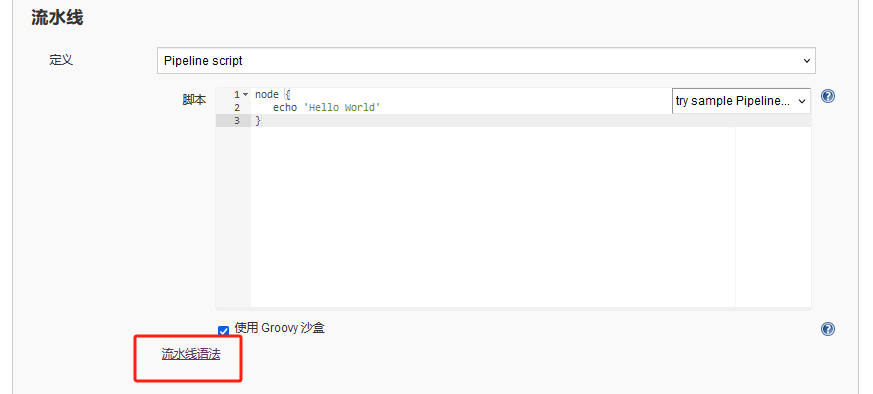
当然,第一次写pipeline的同学有可能会对语法不够熟悉,不过也没关系,Jenkins也提供了流水线语法生成器
点击流水线语法
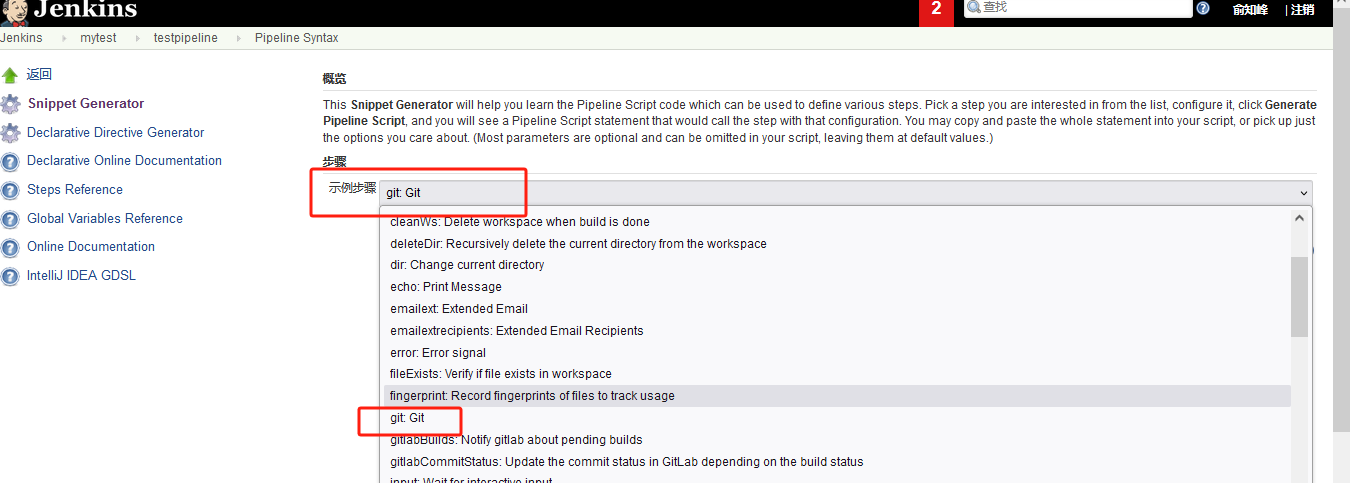
在示例步骤中选择你想要的步骤,比如git拉取
依次输入你项目的gitlab地址、分支、认证密码,最后点击生成流水线脚本就可以生成你想要的语句了
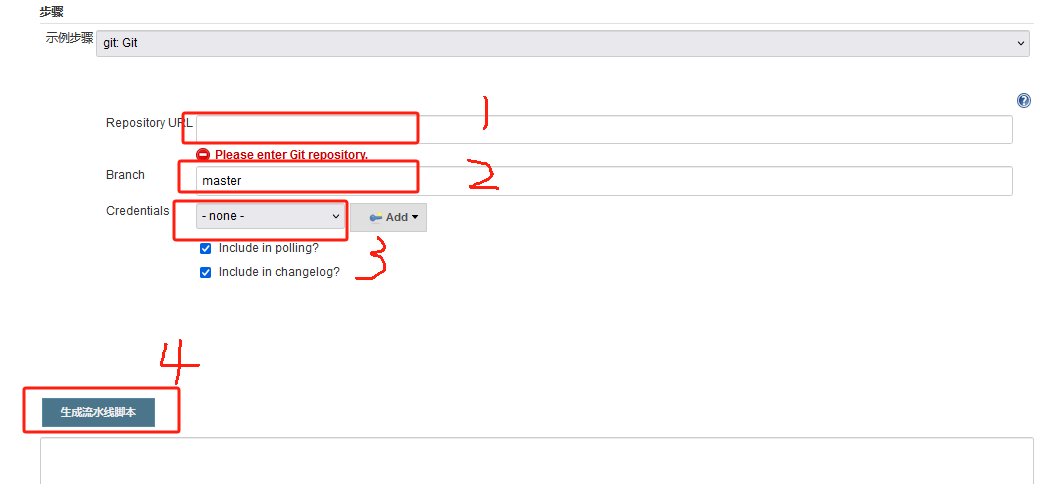
注意:示例步骤下拉框的内容有多少取决于你Jenkins插件装了多少
发布到K8S集群
当pipeline脚本执行完docker build并推送到公司harbor仓库后就需要将镜像信息转换成可发布于k8s集群的yaml文件,看下面的步骤
首先要通过init_public.sh这个shell脚本将服务名,image信息,版本号,副本数,cpu,内存等相关信息做一个初始化
以下是init_public.sh脚本,内容仅供参考:
#!/bin/bash cat /dev/null > /tmp/${9}${1}jenkins echo name:$1 > /tmp/${9}${1}jenkins echo image:$2 >> /tmp/${9}${1}jenkins echo version:$3 >> /tmp/${9}${1}jenkins echo replicas_num:$4 >> /tmp/${9}${1}jenkins echo port:$5 >> /tmp/${9}${1}jenkins echo cpu:$6 >> /tmp/${9}${1}jenkins echo memory:$7 >> /tmp/${9}${1}jenkins echo branch:$8 >> /tmp/${9}${1}jenkins echo namespace:$9 >> /tmp/${9}${1}jenkins echo env_name:${10} >> /tmp/${9}${1}jenkins echo env_value:${11} >> /tmp/${9}${1}jenkins echo servicename:$1 >> /tmp/${9}${1}jenkins echo project:${12} >> /tmp/${9}${1}jenkins echo pvc_name:${13} >> /tmp/${9}${1}jenkins if [[ ${12} == "项目名或者环境" ]];thenpython3 /opt/jenkins/docker/namespace_public.py ${9} ${1} > /work/xxx/$1.yaml elseecho "go to find ops" fi
因为shell脚本还需要调用python命令,所以Jenkins服务器上还需要安装python环境,本公司用到的是python3。
/tmp/目录下生成的文件内容:
name:testpipeline image:dch-sip-uat/test version:uat-202408081048-7a5eea9d replicas_num:1 port:9034 cpu:1000 memory:4608 branch: namespace:default env_name: env_value: servicename:test project:sip-uat pvc_name:testpv
以下是namespace_public.py脚本,内容仅供参考:
#!/usr/bin/env python #encoding=utf8 import sys from jinja2 import Template# 定义一个函数,用于根据传入的参数渲染模板并输出结果 def RenderTemplate(name="",image="",version="",replicas_num="",port="",branch="",namespace="",env_name="",env_value="",cpu="",memory=""):# 如果命名空间是发布环境如devif namespace == "发布环境如dev":# 如果项目名是后端项目名if name == "后端项目名":# 读取后端yaml模板文件with open('/opt/jenkins/docker/backend后端yaml模板', "r") as f:# 使用jinja2模板引擎渲染模板并输出结果print(Template(f.read()).render(name=name,image=image,version=version,replicas_num=replicas_num,port=port,branch=branch,namespace=namespace,env_name=env_name,env_value=env_value,cpu=cpu,memory=memory))# 如果项目名是前端项目名if name == "前端项目名":# 读取前端yaml模板文件with open('/opt/jenkins/docker/frontend前端yaml模板', "r") as f:# 使用jinja2模板引擎渲染模板并输出结果print(Template(f.read()).render(name=name,image=image,version=version,replicas_num=replicas_num,port=port,branch=branch,namespace=namespace,env_name=env_name,env_value=env_value,cpu=cpu,memory=memory))# 如果命名空间是发布环境如uatelif namespace == "发布环境如uat":# 如果项目名是后端项目名if name == "后端项目名":# 读取后端yaml模板文件with open('/opt/jenkins/docker/backend后端yaml模板', "r") as f:# 使用jinja2模板引擎渲染模板并输出结果print(Template(f.read()).render(name=name,image=image,version=version,replicas_num=replicas_num,port=port,branch=branch,namespace=namespace,env_name=env_name,env_value=env_value,cpu=cpu,memory=memory))# 如果项目名是前端项目名if name == "前端项目名":# 读取前端yaml模板文件with open('/opt/frontend前端yaml模板', "r") as f:# 使用jinja2模板引擎渲染模板并输出结果print(Template(f.read()).render(name=name,image=image,version=version,replicas_num=replicas_num,port=port,branch=branch,namespace=namespace,env_name=env_name,env_value=env_value,cpu=cpu,memory=memory))else:# 如果命名空间不是预期的值,输出错误信息print("something wrong, go to find matuoyi")# 创建一个字典用于存储从文件中读取的参数值 d = {} # 拼接jenkinsfile路径 jenkinsfile="/tmp/{0}{1}jenkins".format(sys.argv[1],sys.argv[2]) # 打开jenkinsfile文件 with open(jenkinsfile,'r') as f:# 逐行读取文件内容for line in f:# 以冒号分隔键值对(k,v) = line.split(':')# 如果键为空,则将键对应的值设为空字符串if k == '':d[str(k)] = ""else:# 否则,将键对应的值去掉换行符后存入字典d[str(k)] = v.replace(' ','')# 调用RenderTemplate函数,传入字典中的参数值进行模板渲染 RenderTemplate(**d)
frontend前端yaml模板文件内容:
{%- if replicas_num|length == 0 -%}{%- set replicas_num = 1 -%}
{%- endif -%}
{%- if cpu|length == 0 -%}{%- set cpu = '1000' -%}
{%- endif -%}
{%- if memory|length == 0 -%}{%- set memory = '1024Mi' -%}
{%- endif -%}
{%- if script|length == 0 -%}{%- set script = "" -%}
{%- endif -%}kind: Deployment
apiVersion: apps/v1
metadata:name: {{ name }}namespace: {{ namespace }}labels:app: {{ name }}annotations:kubernetes.io/change-cause: {{ version }}
spec:replicas: {{ replicas_num }}revisionHistoryLimit: 5minReadySeconds: 30progressDeadlineSeconds: 90strategy:rollingUpdate:maxSurge: 100%maxUnavailable: 0type: RollingUpdateselector:matchLabels:app: {{ name }}template:metadata:labels:app: {{ name }}spec:containers:- name: {{ name }}image: harbor.dchmotor.cn:8087/{{ image -}}:{{ version }}imagePullPolicy: IfNotPresentresources:limits:cpu: 4000mmemory: {{ memory }}Mirequests:cpu: 10mmemory: 256Miports:- containerPort: {{ port }}livenessProbe:tcpSocket:port: {{ port }}initialDelaySeconds: 20periodSeconds: 10failureThreshold: 5readinessProbe:failureThreshold: 5tcpSocket:port: {{ port }}initialDelaySeconds: 20periodSeconds: 10successThreshold: 1timeoutSeconds: 3volumeMounts:- name: {{ name }}-data-storagemountPath: /opt/imagePullSecrets:- name: harbor-secretvolumes:- name: {{ name }}-data-storagepersistentVolumeClaim:claimName: gfs---
kind: Service
apiVersion: v1
metadata:name: {{ servicename }}-comnamespace: {{ namespace }}labels:app: {{ name }}
spec:selector:app: {{ name }}
# type: NodePortports:- port: {{ port }}targetPort: {{ port }}
# nodePort: xxx
backend后端yaml模板文件内容:
{%- if replicas_num|length == 0 -%}{%- set replicas_num = 1 -%}
{%- endif -%}
{%- if cpu|length == 0 -%}{%- set cpu = '1000' -%}
{%- endif -%}
{%- if memory|length == 0 -%}{%- set memory = '1024Mi' -%}
{%- endif -%}
{%- if script|length == 0 -%}{%- set script = "" -%}
{%- endif -%}kind: Deployment
apiVersion: apps/v1
metadata:name: {{ name }}namespace: {{ namespace }}labels:app: {{ name }}annotations:kubernetes.io/change-cause: {{ version }}
spec:replicas: {{ replicas_num }}revisionHistoryLimit: 5minReadySeconds: 30progressDeadlineSeconds: 90strategy:rollingUpdate:maxSurge: 100%maxUnavailable: 0type: RollingUpdateselector:matchLabels:app: {{ name }}template:metadata:labels:app: {{ name }}
# annotations:
# alicloud.service.tag: {{ version }}
# msePilotAutoEnable: 'on'
# msePilotCreateAppName: {{ name }}spec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- cndc02pshopod001- cndc02pshopod002- cndc02pshopod003- cndc02pshopod004-new- cndc02pshopod005spec:initContainers:- name: agent-containerimage: harbor.dchmotor.cn:8087/devops/skyagent:8.9.0volumeMounts:- name: skywalking-agentmountPath: /agentcommand: [ "/bin/sh" ]args: [ "-c", "cp -R /skywalking/agent /agent/" ]#hostcontainers:- name: {{ name }}image: harbor.dchmotor.cn:8087/{{ image -}}:{{ version }}imagePullPolicy: IfNotPresentresources:limits:cpu: 4000mmemory: {{ memory }}Mirequests:cpu: 10mmemory: 512Miports:- containerPort: {{ port }}livenessProbe:tcpSocket:port: {{ port }}initialDelaySeconds: 30periodSeconds: 20failureThreshold: 5readinessProbe:failureThreshold: 5tcpSocket:port: {{ port }}initialDelaySeconds: 30periodSeconds: 20successThreshold: 1timeoutSeconds: 3volumeMounts:- name: skywalking-agentmountPath: /skywalking- name: {{ name }}-data-storagemountPath: /opt/env:- name: JAVA_TOOL_OPTIONSvalue: "-javaagent:/skywalking/agent/skywalking-agent.jar"- name: SW_AGENT_NAMEvalue: {{ name }}- name: SW_AGENT_COLLECTOR_BACKEND_SERVICESvalue: "oap-com.monitoring:11800"imagePullSecrets:- name: harbor-secretvolumes:- name: skywalking-agentemptyDir: {}- name: {{ name }}-data-storagepersistentVolumeClaim:claimName: gfs---
kind: Service
apiVersion: v1
metadata:name: {{ servicename }}-comnamespace: {{ namespace }}labels:app: {{ name }}
spec:selector:app: {{ name }}
# type: NodePortports:- port: {{ port }}targetPort: {{ port }}
# nodePort: xxx
pipeline最后一步进行health_check,以下是health_check脚本内容:
#!/bin/bash # $JobName $replicas_num sleep 120 count=0 for (( k=0; k<25; k++ )) do# 获取pod信息,筛选出包含$1的行,提取第2、3列,然后按照'/'分割,输出前两列到临时文件/tmp/$1-healthprdas get po |grep -w $1|awk '{print$2,$3}'|awk -F'/' '{print $1,$2}' > /tmp/$1-health# 判断临时文件中的行数是否等于$2,且所有行的前两列相等且第三列为"Running"if [[ $(wc -l /tmp/$1-health|cut -d " " -f 1) == $2 ]]&& [[ $(grep -v Running /tmp/$1-health |wc -l |cut -d " " -f 1) == 0 ]]&&[[ $(awk '{if($1!=$2) print "no"}' /tmp/$1-health |grep no|wc -l|cut -d " " -f 1) == 0 ]];thencount=0breakelsecount=$(expr $count + 1)sleep 10echo $1 is undergoing a health check, it is the ${count}th timecontinuefi done if [ "$count" != "0" ]; thenecho service $1 is not pass health checkexit 1 elseecho service $1 is publishedexit 0 fi
注意:以上脚本或者模板文件都放于Jenkins服务器的/opt/jenkins/docker/目录下
至此,Jenkins pipeline部署Kubernetes服务已经完成,上面的脚本可以根据自己的实际情况进行修改,谢谢支持!!