程序是怎么一步步变成机器指令的?
2024年08月22日 12:03 四川
以下文章来源于码农的荒岛求生 ,作者码农的荒岛求生
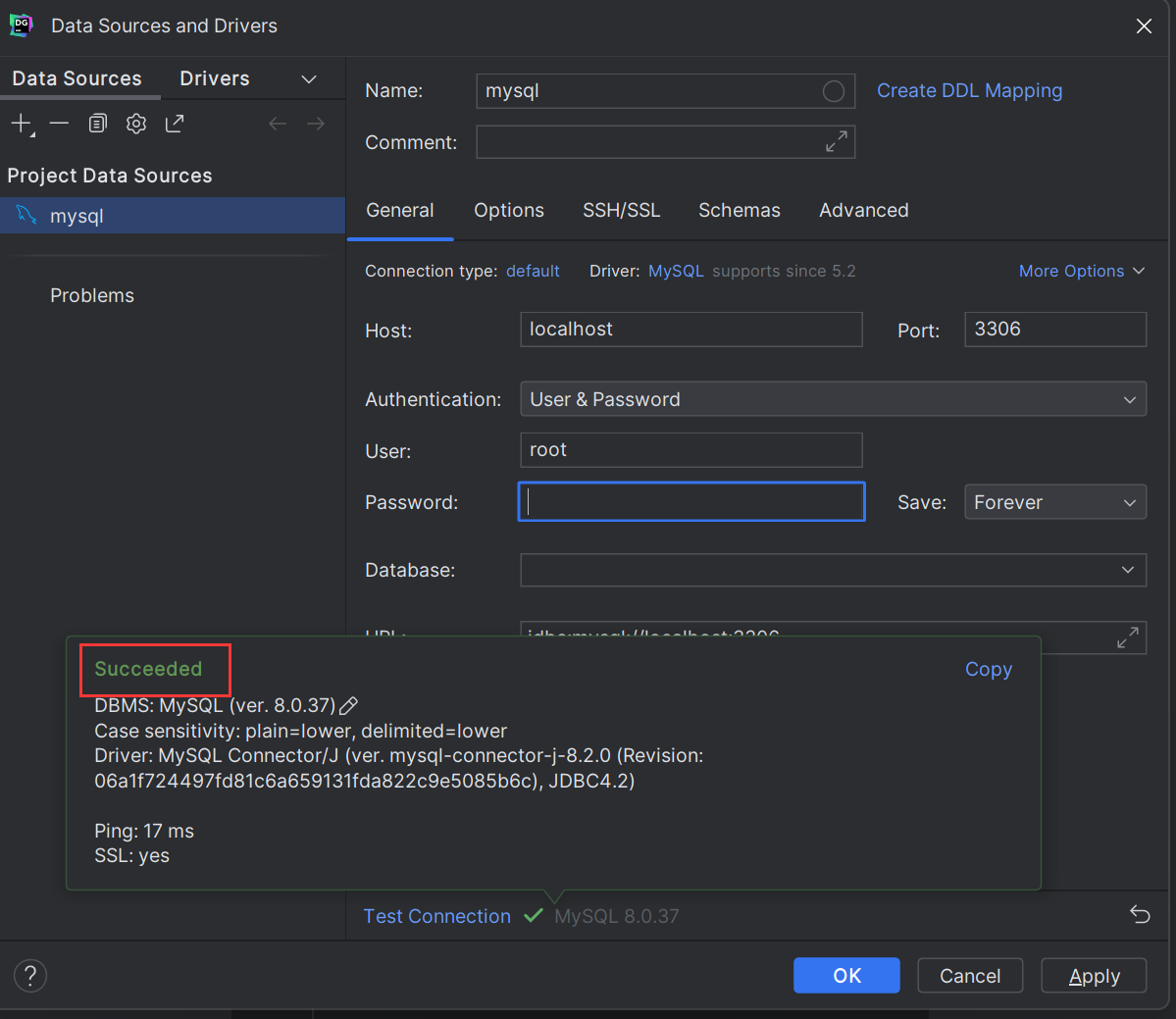
大家好,今天简单聊聊程序是怎么一步步变成机器指令的。
左边是我们写的代码,右边是CPU执行的机器指令:
想让CPU执行代码只需要简单的点击一下这个按钮:
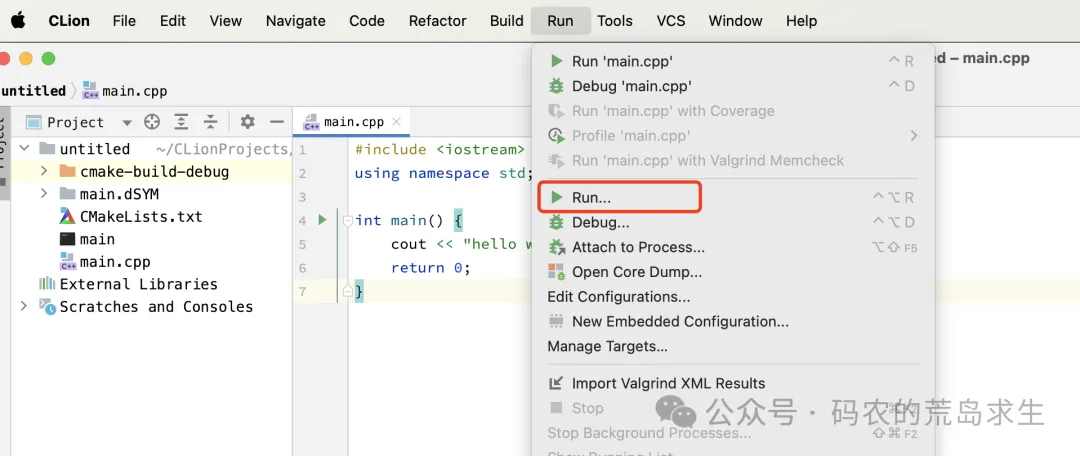
可是你知道这个按钮的背后经历了哪些复杂的操作,你有没有想过代码是怎么一步步变成机器指令的❓
程序员编写的程序实际上就是一个字符串,必须得有个什么东西把字符串转变从机器指令,它的输入是字符串,输出是01二进制机器指令,这就是编译器。
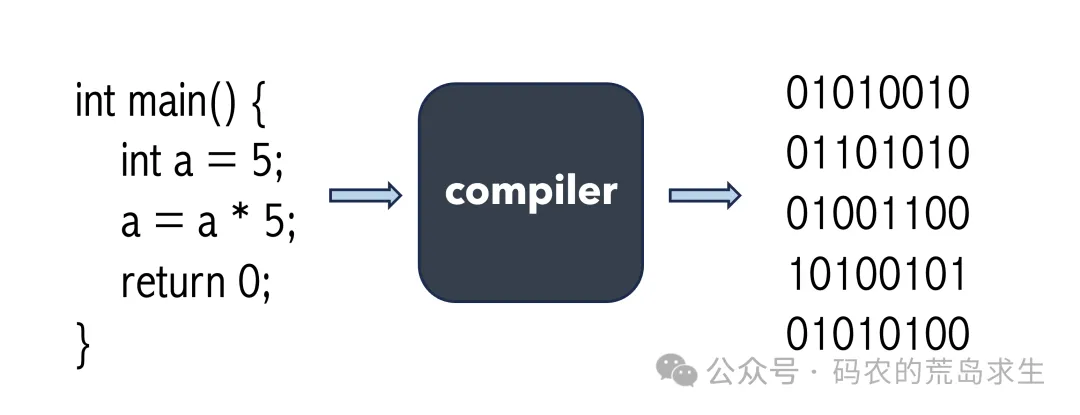
编译器本身就是一个程序,把人类认识的程序转为CPU可以执行的机器指令。
假设有这样一段代码:

这实际上就是一个字符串,编译器要做的第一件事就是遍历字符串并把有意义的字符组合提取出来,忽略掉空格换行等字符。
这里每一个字符组合实际上都有类型,比如int 和main都是关键字,0和5都是数字等,因此还需要标注好类型,这一步就是所谓的提取token。

提取出token之后还需要知道这些token组合在一起的含义是什么。
接下来遍历所有token进行解析。
按照什么解析呢?答案是按照语法。

假设编译器接下来发现token是if,那么很显然,接下来会判定这是一个if语句,那么接下来就按照if语句的语法来解析。

编译器在按照语法解析时会生成一颗树,首先匹配的是if本身:
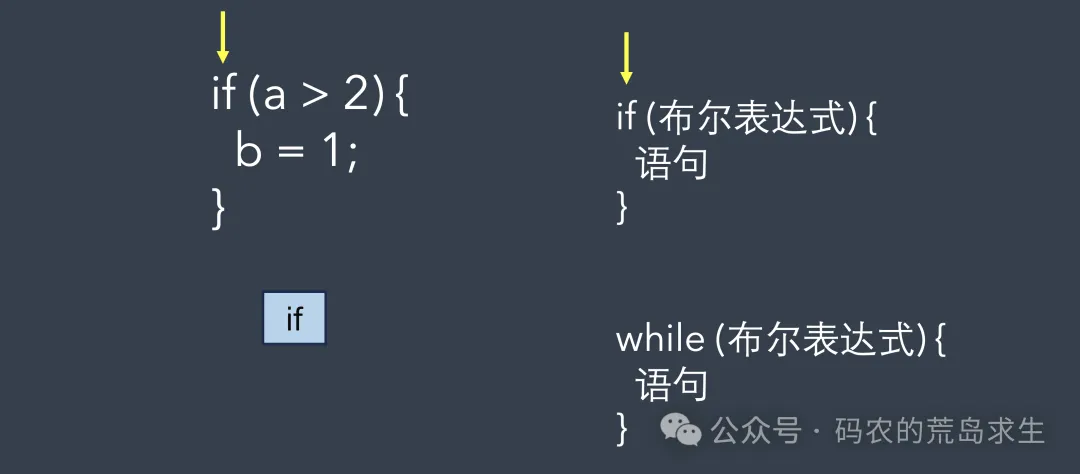
接下来是左括号:

括号之后是布尔表达式:

布尔表达式之后是右括号以及大的左括号。
接着是if内部的语句:

注意看,根据语法解析token后生成的这棵树就叫做抽象语法树:AST。
接下来,编译器遍历这颗抽象语法树并生成指令:
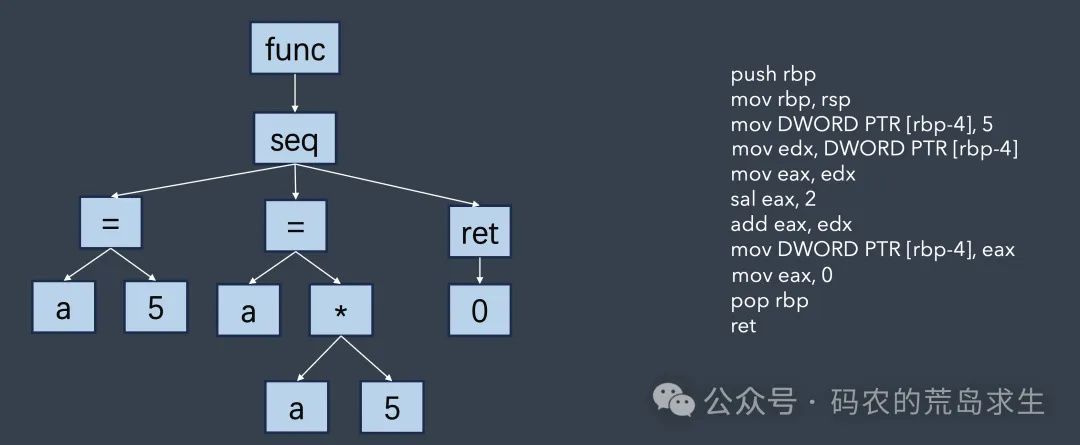
当然真正的编译器可能并不会在这里直接生成机器指令。
我们知道CPU只能执行一种类型的机器指令,x86处理器只能执行x86机器指令,arm处理器只能执行arm机器指令:
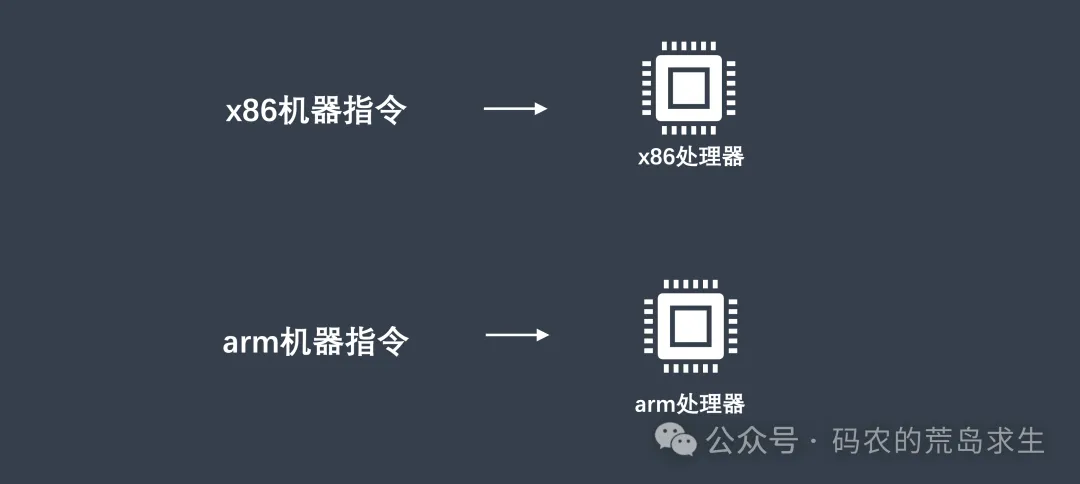
如果你发明了一种语言,为了适配不同的处理器自己需要针对每一种处理器编写相应的后端部分。
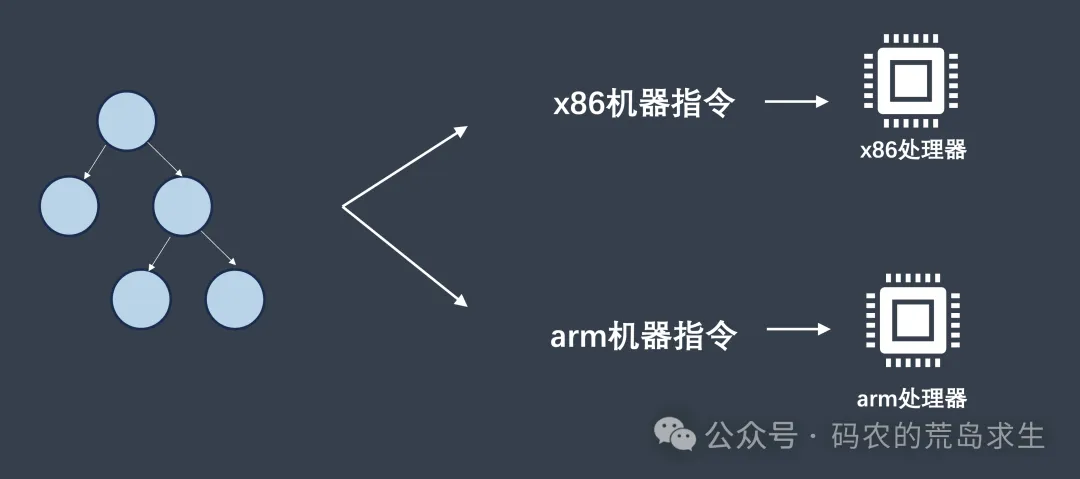
要是有一种工具能帮我们完成针对不同处理器的适配工作就好了,这就是LLVM,我们可以只生成针对LLVM的中间代码,由LLVM处理剩下的部分。
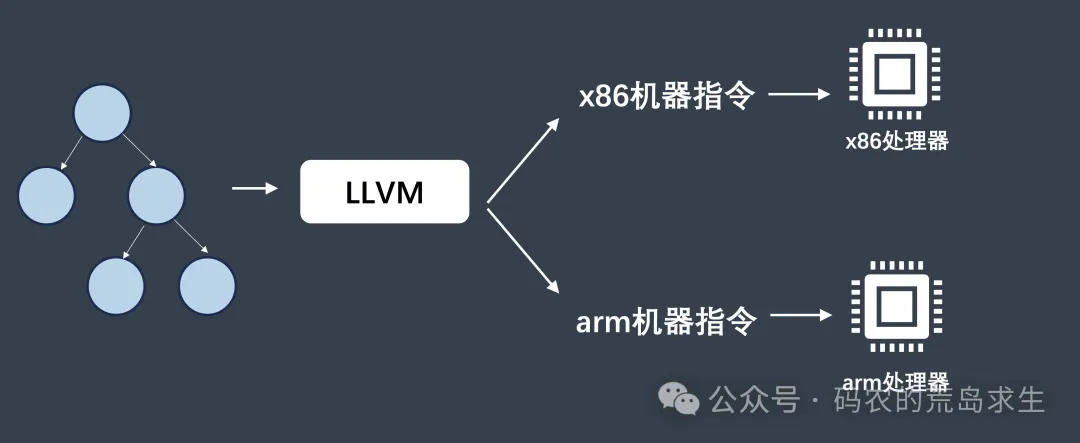
这就是生成中间代码的好处。
值得注意的是,编译器在生成指令时会进行优化,这个示例中变量a实际上没什么用处,编译器会注意到这一点并把针对变量a的赋值指令去掉。

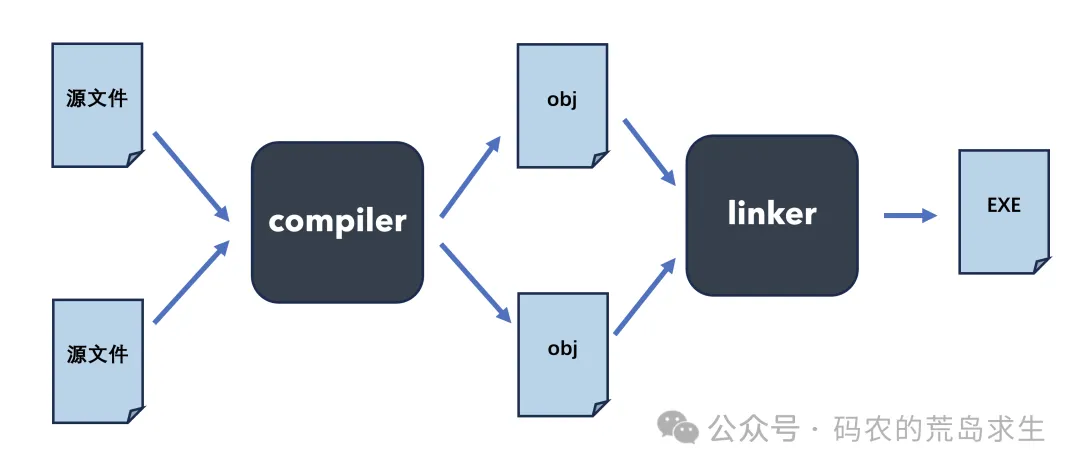
得到汇编指令后编译器会最终将其转为CPU可以认知的二进制机器指令,每个源文件被编译后都会生成一个目标文件,目标文件中就是转换后的二进制机器指令。
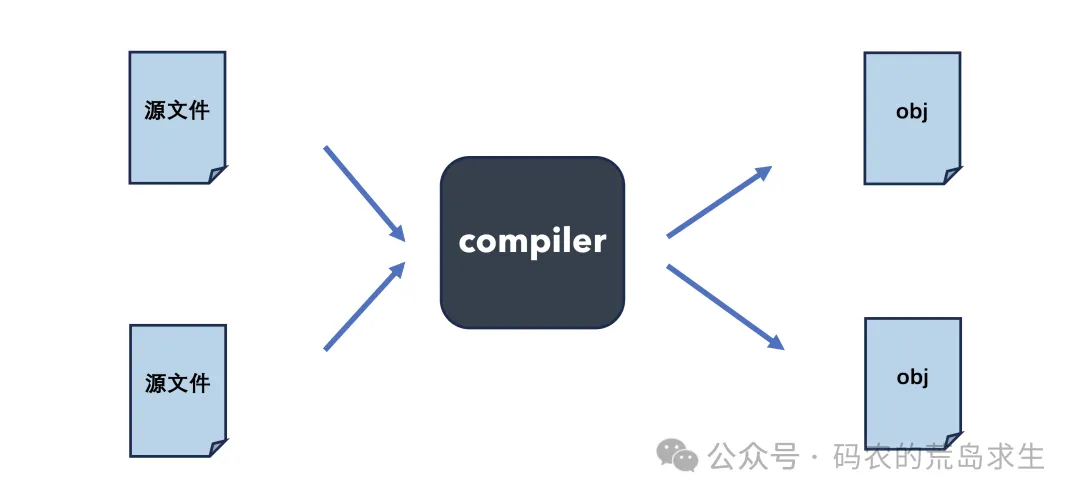
最后,链接器会把目标文件打包成最终的可执行程序,
原创 涛哥聊Python